《计算智能》综合性实验报告 -
- 格式:doc
- 大小:241.00 KB
- 文档页数:7

江苏科技大学计算智能实验计算机科学与工程学院实验一手写数字识别的神经网络算法设计与实现一、实验目的通过学习BP神经网络技术,对手写数字进行识别,基于结构的识别法及模板匹配法来提高识别率。
二、实验器材PC机 matlab软件三、实验内容按照BP神经网络设计方法选用两层BP网络,构造训练样本集,并构成训练所需的输入矢量和目标向量,通过画图工具,获得数字原始图像,截取图像像素为0的最大矩形区域,经过集合变换,变成16*16的二值图像,再进行反色处理,其图像数据特征提取为神经网络的输入向量。
通过实验证实,BP神经网络应用于手写数字识别具有较高的识别率和可靠性。
四、实验原理BP算法由数据流的前向计算(正向传播)和误差信号的反向传播两个过程构成. 正向传播时,传播方向为输入层→隐层→输出层,每层神经元的状态只影响下一层神经元. 若在输出层得不到期望的输出,则转向误差信号的反向传播流程. 通过这两个过程的交替进行,在权向量空间执行误差函数梯度下降策略,动态迭代搜索一组权向量,使网络误差函数达到最小值,从而完成信息提取和记忆过程.五、实验步骤1、首先对手写数字图像进行预处理,包括二值化、去噪、倾斜校正、归一化和特征提取,生成BP神经网络的输入向量m和目标向量target. 其中m选取40×10的矩阵,第1列到第10列代表0~9的数字.target为9×10的单位矩阵,每个数字在其所排顺序位置输出1,其他位置输出0.2、然后神经网络的训练过程是识别字符的基础,直接关系到识别率的高低。
输送训练样本至BP神经网络训练, 在梯度方向上反复调整权值使网络平方和误差最小。
学习方法采用最速下降方法,输入结点数为16*16=256,隐层传输函数为sigmoid函数(logsig),一个输出结点,输出传输函数为pureline(purelin),隐层结点数为sqrt(256+1)+a(a=1~10),取为25。

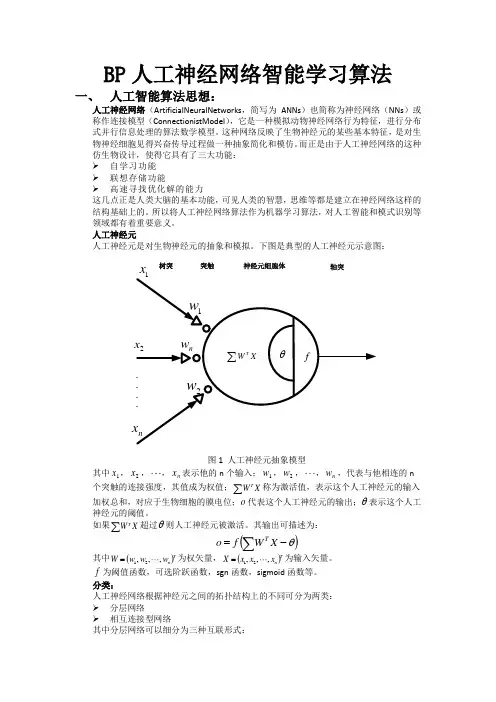
计算智能与模式识别实验报告感知器与ADALINE 网络一・感知器与ADALINE 网络的工作原理 1. 感知器工作原理感知器是美国心理学家Rrank Rosenblatt 基于MP 模型,利用学习算法的用于分类的对噪声敏感的线性分类器,利用训练样本完成特征空间的决策边界的划感知器的结构:多神经元感知器1i i i = ⎪⎝⎭ ⎪⎪⎭⎝⎛-=∑=n i i i ki k x w f y 1θ, or ()f W =-y x θ 其中,()1, 00, if x f x otherwise≥⎧=⎨⎩ ,()12,,,T n w w w =w ,1112112 ww n m m mn w w W w w ⎡⎤⎢⎥=⎢⎥⎢⎥⎣⎦两类分类,把n R 空间划分成两个区域 多类分类,把n R 空间划分成多个区域以两类为例:n R Class Class ⊂B A, . (1) 线性可分 Linear Separable称 A Class 和 B Class 是线性可分的,如果存在一个超平面将它们分开。
称超平面1:0ni i i S w x θ=-=∑为决策面(边界);称函数∑=-=n1i )g(θi i x w x 为决策函数(或判别函数);称区域{}g()0n R ∈>x x 和{}g()<0n R ∈x x 为决策区域;决策规则:对于新的模式n R ∈*x ,如果()0g *>x ,则 A Class *∈x ;如果()0g *<x ,则 B Class *∈x . (这里假设了决策面1:0ni i i S w x θ=-=∑的法向量指向 A Class )需要指出的是:对于同一个决策面,决策函数的取法并不是唯一的。
例如,我们可以取决策函数为()1n i i i g f w x θ=⎛⎫=- ⎪⎝⎭∑x ,其中,f 为硬限幅函数,则这时对应的决策规则为:对于新的模式n R ∈*x ,如果()1g *=x ,则 A Class *∈x ;如果()0g *=x ,则 B Class *∈x .(2) 非线性可分 Nonlinear Separable称 A Class 和 B Class 是非线性可分的,如果存在一个非线性曲面将它们分开,g>0 g=0 g<0同线性可分情况一样,称曲面()0g =x 为决策面(边界),称函数()g x 为决策函数,对应的决策规则为:对于新的模式n R ∈*x ,如果()0g *>x ,则*x 属于一类;如果()0g *<x ,则*x 属于另一类。

智能实训实习报告一、前言随着科技的飞速发展,人工智能技术已经深入到了我们生活的方方面面。
作为一名热衷于人工智能领域的学生,我十分荣幸能够参加这次智能实训实习项目,通过这次实习,我得以将理论知识与实践操作相结合,对于人工智能技术有了更为深入的了解。
二、实习内容本次智能实训实习主要分为两个部分:一是智能机器人组装与调试,二是人工智能算法实践。
在实习过程中,我们不仅要学习如何组装和调试智能机器人,还要掌握人工智能算法的实际应用,例如图像识别、语音识别等。
三、实习过程1.智能机器人组装与调试在实习的第一周,我们主要进行了智能机器人的组装与调试。
在这个过程中,我深刻理解了机器人各个部件的作用,以及如何将这些部件有效地结合起来,使其能够完成指定的任务。
此外,我们还学习了如何使用编程软件对机器人进行编程,使其能够根据我们的指令完成各种复杂的动作。
2.人工智能算法实践在实习的第二周,我们开始学习人工智能算法实践。
通过对图像识别和语音识别两个项目的实践,我掌握了如何使用深度学习框架搭建神经网络模型,并使用大量的数据对模型进行训练,使其能够达到较高的识别准确率。
这个过程不仅提高了我的编程能力,还让我对人工智能算法有了更为深入的理解。
四、实习收获通过这次智能实训实习,我收获颇丰。
首先,我学会了如何将理论知识应用到实际操作中,提高了自己的实践能力。
其次,我对人工智能技术有了更为深入的了解,对于未来的职业规划有了更为明确的方向。
最后,我在实习过程中结识了一群志同道合的朋友,共同探讨和解决问题,培养了团队协作精神。
五、实习总结回顾这次智能实训实习,我认为它是我人生中一段宝贵的经历。
在实习过程中,我不仅提高了自己的专业技能,还培养了团队协作和解决问题的能力。
我相信,这次实习对于我未来的学术研究和职业发展都将产生积极的影响。
在今后的学习和工作中,我将继续努力,不断充实自己,为实现人工智能领域的突破贡献自己的力量。

人工智能与计算机基础实验报告《人工智能与计算机基础实验报告》嘿!同学们,你们知道吗?最近我参加了一个超级酷的活动——人工智能与计算机基础实验!这可真是让我大开眼界,就像走进了一个充满魔法的世界。
一开始,老师带着我们走进实验室,哇塞,那一排排的电脑,闪闪发光的屏幕,就好像在对我说:“快来探索我们的秘密吧!”我心里那个激动呀,简直没法形容。
我们分成了几个小组,每个小组都有一台电脑可以操作。
我和我的小伙伴们围坐在一起,眼睛都紧紧地盯着屏幕,迫不及待地想要开始实验。
老师先给我们介绍了什么是人工智能,他说:“人工智能就像是一个超级聪明的大脑,能帮我们解决很多复杂的问题。
”我心里想:“真的有这么神奇吗?”然后,我们开始了第一个实验,是关于图像识别的。
老师给我们展示了一张图片,让我们猜猜电脑能不能认出图片里的东西。
我心里直犯嘀咕:“这能行吗?”结果,电脑一下子就说出了图片里是一只可爱的小狗!这也太厉害了吧,难道电脑也有眼睛不成?接着,我们又尝试了语音识别的实验。
我对着麦克风说了一句话:“今天天气真好!”电脑居然一字不差地把我说的话显示在了屏幕上。
这难道不是像有一个隐形的小精灵在电脑里偷听我说话吗?在实验过程中,我和小伙伴们可兴奋啦!“哎呀,这个太好玩啦!”“快看,又成功啦!”我们的笑声和惊叹声在实验室里回荡。
小组里的小明还出了个主意,说:“咱们试试说一句很难的话,看看电脑能不能听懂。
”于是,我就说了一句绕口令:“打南边来了个吃葡萄不吐葡萄皮的喇嘛,打北边来了留恋榴莲甜的哑巴。
”结果电脑被我们弄得晕头转向,我们哈哈大笑起来。
后来,我们还学习了一些简单的计算机编程。
这就像是在给计算机下达命令,让它按照我们的想法做事。
我感觉自己就像是一个指挥官,指挥着计算机这个“小兵”冲锋陷阵。
通过这次实验,我深深地感受到了人工智能和计算机的神奇之处。
它们就像是一把神奇的钥匙,能打开无数未知的大门,带我们走进一个全新的世界。
难道我们不应该好好学习这些知识,去探索更多的奥秘吗?我相信,在未来,人工智能和计算机一定会给我们的生活带来更多的惊喜和便利!这就是我的实验报告,同学们,你们是不是也觉得很有趣呢?。

第1篇一、实验背景随着信息技术的飞速发展,计算课已成为现代教育中不可或缺的一部分。
通过计算课的学习,学生可以掌握计算机基本操作、编程语言以及算法设计等知识,为今后从事相关工作奠定基础。
本次实验旨在通过实际操作,加深对所学知识的理解,提高动手能力和团队协作能力。
二、实验目的1. 熟悉计算机基本操作,掌握常用软件的使用方法;2. 学习一种编程语言,理解编程思想,实现基本算法;3. 培养团队协作精神,提高动手实践能力;4. 提高对计算课重要性的认识,激发学习兴趣。
三、实验内容本次实验主要包括以下内容:1. 计算机基本操作:熟练使用计算机操作系统,掌握文件管理、系统设置等基本操作;2. 编程语言学习:选择一种编程语言(如Python、Java等),学习基本语法、数据结构、算法等知识;3. 算法实现:设计并实现一个简单算法,如排序、查找等;4. 项目实践:分组完成一个小型项目,如制作一个简单的网页、编写一个计算器程序等。
四、实验过程1. 实验准备:了解实验内容,预习相关理论知识,准备好实验所需的计算机和软件;2. 实验操作:按照实验指导书进行操作,记录实验步骤和结果;3. 团队协作:分组讨论,分工合作,共同完成实验任务;4. 结果分析:对实验结果进行分析,总结经验教训。
五、实验结果与分析1. 计算机基本操作:通过实验,掌握了计算机基本操作,如文件管理、系统设置等,提高了计算机应用能力;2. 编程语言学习:学习了所选编程语言的基本语法、数据结构、算法等知识,为今后深入学习打下了基础;3. 算法实现:实现了排序、查找等基本算法,加深了对算法原理的理解;4. 项目实践:分组完成了一个小型项目,如制作了一个简单的网页、编写了一个计算器程序等,提高了团队协作能力和动手实践能力。
六、实验总结1. 计算课实验对提高学生计算机应用能力具有重要意义,有助于培养学生动手实践能力和团队协作精神;2. 实验过程中,要注重理论与实践相结合,不断总结经验教训,提高实验效果;3. 在今后的学习中,要继续努力,深入学习计算课相关知识,为将来从事相关工作打下坚实基础。


第1篇一、实验背景随着人工智能技术的快速发展,智能模型算法在各个领域得到了广泛应用。
本实验旨在研究并验证一种基于深度学习的智能模型算法在特定任务上的性能,通过对比实验,分析算法的优缺点,为后续研究提供参考。
二、实验目标1. 设计并实现一种基于深度学习的智能模型算法;2. 对比分析不同算法在特定任务上的性能;3. 评估算法的优缺点,为后续研究提供参考。
三、实验环境1. 操作系统:Windows 102. 编程语言:Python3. 深度学习框架:TensorFlow 2.04. 数据集:MNIST手写数字数据集四、实验方法1. 数据预处理:对MNIST数据集进行归一化处理,将像素值缩放到[0, 1]范围内;2. 模型设计:设计一个基于卷积神经网络(CNN)的智能模型,包含卷积层、池化层和全连接层;3. 训练过程:使用Adam优化器进行模型训练,设置学习率为0.001,训练100个epoch;4. 性能评估:使用准确率、召回率、F1值等指标评估模型在测试集上的性能。
五、实验结果与分析1. 模型结构实验中设计的智能模型结构如下:- 输入层:输入MNIST数据集的28x28像素图像;- 卷积层1:使用32个3x3卷积核,步长为1,激活函数为ReLU;- 池化层1:使用2x2的最大池化;- 卷积层2:使用64个3x3卷积核,步长为1,激活函数为ReLU;- 池化层2:使用2x2的最大池化;- 全连接层:使用128个神经元,激活函数为ReLU;- 输出层:使用10个神经元,表示10个数字类别,激活函数为softmax。
2. 性能评估实验在MNIST数据集上进行了训练和测试,性能评估结果如下:- 训练集准确率:98.76%- 测试集准确率:97.52%- 召回率:97.35%- F1值:97.10%3. 对比实验为了对比分析不同算法在特定任务上的性能,我们选取了以下几种算法进行对比:- 算法1:基于K近邻(KNN)的分类算法;- 算法2:基于支持向量机(SVM)的分类算法;- 算法3:基于决策树的分类算法。

智能计算实验报告学院:班级:学号:姓名:成绩:日期:实验名称:基于蚁群优化算法的TSP问题求解题目要求:利用蚁群优化算法对给定的TSP问题进行求解,求出一条最短路径。
蚁群优化算法简介:蚁群算法是一中求解复杂优化问题的启发式算法,该方法通过模拟蚁群对“信息素”的控制和利用进行搜索食物的过程,达到求解最优结果的目的。
它具有智能搜索、全局优化、稳健性强、易于其它方法结合等优点,适应于解决组合优化问题,包括运输路径优化问题。
TSP数据文件格式分析:本次课程设计采用的TSP文件是att48.tsp ,文件是由48组城市坐标构成的,文件共分成三列,第一列为城市编号,第二列为城市横坐标,第三列为城市纵坐标。
数据结构如下所示:实验操作过程:1、TSP文件的读取:class chengshi {int no;double x;double y;chengshi(int no, double x, double y) {this.no = no;this.x = x;this.y = y;}private double getDistance(chengshi chengshi) {return sqrt(pow((x - chengshi.x), 2) + pow((y - chengshi.y), 2));}}try {//定义HashMap保存读取的坐标信息HashMap<Integer, chengshi> map = new HashMap<Integer,chengshi>();//读取文件BufferedReader reader = new BufferedReader(new (new )));for (String str = reader.readLine(); str != null; str = reader.readLine()) { //将读到的信息保存入HashMapif(str.matches("([0-9]+)(\\s*)([0-9]+)(.?)([0-9]*)(\\s*)([0-9]+)(.?)([0-9]*)")) {String[] data = str.split("(\\s+)");chengshi chengshi = new chengshi(Integer.parseInt(data[0]),Double.parseDouble(data[1]),Double.parseDouble(data[2]));map.put(chengshi.no, chengshi);}}//分配距离矩阵存储空间distance = new double[map.size() + 1][map.size() + 1];//分配距离倒数矩阵存储空间heuristic = new double[map.size() + 1][map.size() + 1];//分配信息素矩阵存储空间pheromone = new double[map.size() + 1][map.size() + 1];for (int i = 1; i < map.size() + 1; i++) {for (int j = 1; j < map.size() + 1; j++) {//计算城市间的距离,并存入距离矩阵distance[i][j] = map.get(i).getDistance(map.get(j));//计算距离倒数,并存入距离倒数矩阵heuristic[i][j] = 1 / distance[i][j];//初始化信息素矩阵pheromone[i][j] = 1;}}} catch (Exception exception) {System.out.println("初始化数据失败!");}}2、TSP作图处理:private void evaporatePheromone() {for (int i = 1; i < pheromone.length; i++)for (int j = 1; j < pheromone.length; j++) {pheromone[i][j] *= 1-rate;}}3、关键源代码(带简单的注释):蚂蚁类代码:class mayi {//已访问城市列表private boolean[] visited;//访问顺序表private int[] tour;//已访问城市的个数private int n;//总的距离private double total;mayi() {//给访问顺序表分配空间tour = new int[distance.length+1];//已存入城市数量为n,刚开始为0n = 0;//将起始城市1,放入访问结点顺序表第一项tour[++n] = 1;//给已访问城市结点分配空间visited = new boolean[distance.length];//第一个城市为出发城市,设置为已访问visited[tour[n]] = true;}private int choosechengshi() {//用来random的随机数double m = 0;//获得当前所在的城市号放入j,如果和j相邻的城市没有被访问,那么加入mfor (int i = 1, j = tour[n]; i < pheromone.length; i++) {if (!visited[i]) {m += pow(pheromone[j][i], alpha) * pow(heuristic[j][i], beta);}}//保存随机数double p = m * random();//寻找随机城市double k = 0;//保存城市int q = 0;for (int i = 1, j = tour[n]; k < p; i++) {if (!visited[i]) {k += pow(pheromone[j][i], alpha) * pow(heuristic[j][i], beta);q = i;}}return q;}城市选择代码:private int choosechengshi() {//用来random的随机数double m = 0;//获得当前所在的城市号放入j,如果和j相邻的城市没有被访问,那么加入mfor (int i = 1, j = tour[n]; i < pheromone.length; i++) {if (!visited[i]) {m += pow(pheromone[j][i], alpha) * pow(heuristic[j][i], beta);}}//保存随机数double p = m * random();//寻找随机城市double k = 0;//保存城市int q = 0;for (int i = 1, j = tour[n]; k < p; i++) {if (!visited[i]) {k += pow(pheromone[j][i], alpha) * pow(heuristic[j][i], beta);q = i;}}return q;}4、算法运行收敛图(即运行到第几步,求得的最优值是多少):run:本次为倒数第100次迭代,当前最优路径长度为41634.60本次为倒数第99次迭代,当前最优路径长度为41514.21本次为倒数第98次迭代,当前最优路径长度为38511.61本次为倒数第97次迭代,当前最优路径长度为38511.61本次为倒数第96次迭代,当前最优路径长度为38511.61本次为倒数第95次迭代,当前最优路径长度为38511.61本次为倒数第94次迭代,当前最优路径长度为37293.07、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、本次为倒数第6次迭代,当前最优路径长度为37293.07本次为倒数第5次迭代,当前最优路径长度为37293.07本次为倒数第4次迭代,当前最优路径长度为37293.07本次为倒数第3次迭代,当前最优路径长度为37293.07本次为倒数第2次迭代,当前最优路径长度为37293.07本次为倒数第1次迭代,当前最优路径长度为37293.07得到的最优的路径长度为: 37293.075、最终求得的最优解的TSP图像:最优路径如下:→1→9→38→31→44→18→7→28→37→19→6→30→43→27→17→36→46→33→15→12→11→23→14→25→13→20→47→21→39→32→48→5→29→2→26→4→35→45→10→42→24→34→41→16→22→3→40→8→1成功生成(总时间:3 秒)实验结果分析:本次通过JA V A语言实现蚁群优化算法,我们发现虽然我们找到了问题的最优解,但是最优解的收敛性并不乐观,并不能求得问题的精确解,并且随着参数的调节运行结果有随机性。

智能算法实验报告一、引言智能算法是指借助计算机技术模拟人类智能思维过程,通过不断学习和优化来解决问题的一种算法。
智能算法在近年来得到了广泛应用,例如在机器学习、数据挖掘、优化问题等领域都有重要的应用。
为了更好地了解智能算法的工作原理和应用场景,我们进行了一次智能算法实验。
二、实验目的本次实验的目的是了解智能算法的基本原理和应用,通过实际操作掌握智能算法在解决实际问题中的应用方法。
三、实验内容本次实验我们选择了遗传算法作为研究对象。
遗传算法是一种模拟生物进化过程的优化算法,通过模拟自然界中的遗传变异、选择等过程来最优解。
我们选取了一个经典的函数优化问题作为实验案例,通过遗传算法来求解该问题的最优解。
四、实验步骤1. 定义问题:选择一个经典的函数优化问题,如Rosenbrock函数。
2.初始化种群:随机生成初始种群,并给每个个体分配一个适应度值。
3.选择:根据适应度值选择种群中的个体,用于繁殖下一代。
4.交叉:从选中的个体中随机选择两个个体进行交叉操作,生成新的个体。
5.变异:对新生成的个体进行变异操作,引入新的基因。
6.替换:根据适应度值替换掉原来种群中的一些个体。
7.终止条件判断:判断是否达到终止条件,如达到最大迭代次数或找到最优解等。
8.迭代:如果没有达到终止条件,返回步骤3进行下一代的繁殖。
9.输出结果:输出找到的最优解。
五、实验结果与分析通过实验,我们成功地使用遗传算法求解了Rosenbrock函数的最优解。
经过多次迭代,算法逐渐靠近最优解,并最终找到了接近最优解的解。
实验结果证明了遗传算法的有效性和可行性。
六、实验总结本次实验通过实际操作学习了智能算法中的遗传算法。
通过实验,我们对智能算法的工作原理和应用场景有了更深入的理解。
同时,我们还对遗传算法的参数设置进行了调优,提高了算法的性能和收敛速度。
七、展望通过本次实验,我们对智能算法有了初步的了解,但是我们也发现智能算法还有很多问题有待解决。

一、实训背景随着科技的飞速发展,智能化技术已成为推动社会进步的重要力量。
为了更好地适应时代发展的需求,提高自身的实践能力和创新意识,我参加了为期一个月的智能综合实训。
本次实训旨在通过理论学习和实践操作,全面了解和掌握智能化技术的基本原理和应用,提升自己的综合素质。
二、实训内容1. 理论学习实训期间,我们学习了以下理论知识:(1)人工智能基础:了解了人工智能的发展历程、基本概念、主要技术及其应用领域。
(2)机器学习:学习了机器学习的基本原理、常用算法及其在智能系统中的应用。
(3)深度学习:了解了深度学习的基本概念、常见模型及其在图像识别、语音识别等领域的应用。
(4)数据挖掘:学习了数据挖掘的基本原理、常用算法及其在商业智能、舆情分析等领域的应用。
(5)物联网技术:了解了物联网的基本概念、架构、关键技术及其在智能家居、智能交通等领域的应用。
2. 实践操作在理论学习的基础上,我们进行了以下实践操作:(1)机器学习实验:通过Python编程,实现了线性回归、决策树、支持向量机等机器学习算法,并分析了实验结果。
(2)深度学习实验:利用TensorFlow框架,实现了卷积神经网络在图像识别任务中的应用。
(3)数据挖掘实验:使用Python进行数据预处理、特征选择和模型训练,完成了商业智能、舆情分析等数据挖掘任务。
(4)物联网实验:搭建了智能家居系统,实现了家电远程控制、环境监测等功能。
三、实训收获1. 理论知识方面通过本次实训,我对智能化技术有了更加深入的了解,掌握了人工智能、机器学习、深度学习、数据挖掘和物联网等基本理论。
2. 实践能力方面在实训过程中,我学会了使用Python、TensorFlow等工具进行编程,提高了自己的编程能力和算法实现能力。
同时,通过实际操作,锻炼了自己的动手能力和团队协作能力。
3. 创新意识方面实训过程中,我积极思考,勇于尝试,提出了一些创新性的解决方案,提高了自己的创新意识。
计算智能作业二BP网络设计自己构造一个非线性分类问题,设计并构造一个BP网络,把非线性问题解决。
目标:设有两个模式集合Ω1={(0,0), (1,1)},Ω2={(0,1),(1,0)},用BP网络将其分类实现方法:BP网络的有以下特点:1,网络实质上实现了一个从输入到输出的映射功能,而数学理论已证明它具有实现任何复杂非线性映射的功能。
这使得它特别适合于求解内部机制复杂的问题。
理论上,一个三层的神经网络,能够以任意精度逼近给定的函数;2,网络能通过学习带正确答案的实例集自动提取“合理的”求解规则,即具有自学习能力;3,网络具有一定的推广、概括能力。
使用matlab中集成的神经网络工具箱中的newff函数进行分类计算与仿真。
训练前馈网络的第一步是建立网络对象。
函数newff建立一个可训练的前馈网络。
这需要4个输入参数。
第一个参数是一个Rx2的矩阵以定义R个输入向量的最小值和最大值。
第二个参数是一个设定每层神经元个数的数组。
第三个参数是包含每层用到的传递函数名称的细胞数组。
最后一个参数是用到的训练函数的名称。
实验结果:经过7步可以达到分类要求。
现在测试一下其分类的准确性。
测试点P1(0.95,0.95)和P2(0,0.95)两点,其应该分属两类。
A=[0.95 0;0.95 0.95];out=sim(net,A);输出得到out= -0.0006 1.0087,也就是将P1分在了第一类,P2分在第二类,与预测结果一致,说明该训练结果是有效的。
实验代码:axis([-0.5,1.5,-0.5,1.5]);hold on;plot(0,0,'o');hold on;plot(1,1,'o');hold on;plot(0.1,0.1,'o');hold on;plot(0.9,0.9,'o');hold on;plot(1,0,'x');hold on;plot(0.9,0,'x');hold on;plot(0,1,'x');hold on;plot(0,0.9,'x');hold on;p=[0 1 0.1 0.9 1 0.9 0.1 0;0 1 0.1 0.9 0 0 1 0.9];t=[0 0 0 0 1 1 1 1];net=newff(minmax(p),[3,1],{'tansig','purelin'},'trainlm');net.trainParam.epochs=500;net.trainParam.goal=0.001;LP.lr=0.5;net.trainParam.show=20;net=train(net,p,t);out=sim(net,p);注意的问题:1、BP算法的学习速度较慢,其原因主要是由于BP算法本质上为梯度下降法,而它所要优化的目标函数又非常复杂,因此,必然会出现“锯齿形现象”,这使得BP算法低效2、网络训练失败的可能性较大,其原因是从数学角度看,BP算法为一种局部搜索的优化方法,但它要解决的问题为求解复杂非线性函数的全局极值,因此,算法很有可能陷入局部极值,使训练失败3、网络结构的选择没有一种统一而完整的理论指导,参数一般只能由经验选定。
计算机人工智能实习报告一、实习目的随着人工智能技术的飞速发展,越来越多的行业开始运用人工智能技术来提高工作效率,降低成本,创造更大的价值。
作为一名计算机专业的学生,我深知人工智能技术的重要性,因此,在大学期间,我积极参加了人工智能实习,以期提高自己在人工智能领域的理论知识和实际操作能力。
本次实习的主要目的是:1. 学习和掌握人工智能的基本理论、方法和应用。
2. 培养实际动手能力,将理论知识应用到实际项目中。
3. 了解人工智能行业的发展趋势和市场需求。
4. 提高团队协作和沟通能力,为将来的工作打下坚实基础。
二、实习内容及体会1. 实习内容在实习期间,我参与了以下几个方面的工作:(1)学习人工智能基本理论,包括机器学习、深度学习、自然语言处理等。
(2)实际操作,使用Python编程语言和TensorFlow、Keras等深度学习框架进行项目实践。
(3)参与团队项目,与团队成员一起完成指定任务。
(4)参加实习单位组织的讲座和培训,了解行业动态和发展趋势。
2. 实习体会(1)理论学习通过实习,我深入学习了人工智能的基本理论,对机器学习、深度学习、自然语言处理等技术有了更清晰的认识。
同时,我也明白了理论知识的重要性,只有扎实的理论基础,才能在实际项目中游刃有余。
(2)实际操作在实际操作环节,我使用了Python编程语言和TensorFlow、Keras等深度学习框架进行项目实践。
通过动手实践,我将理论知识转化为实际能力,掌握了模型构建、训练和优化的整个过程。
同时,我也学会了如何处理实际项目中遇到的问题,提高了解决问题的能力。
(3)团队协作在实习过程中,我与团队成员紧密合作,共同完成指定任务。
我明白了团队协作的重要性,学会了如何与他人沟通、协作,为团队的目标共同努力。
这对我的个人成长和社会适应能力的提高具有重要意义。
(4)行业了解通过参加实习单位组织的讲座和培训,我了解了人工智能行业的发展趋势和市场需求,对我未来的职业规划具有指导意义。
华北科技学院基础部综合性实验实验报告课程名称计算智能实验学期 2013 至 2014 学年第 2 学期学生所在系部基础部年级 12 专业班级计算B121 学生姓名郭春元学号 201209014115 任课教师杨文光实验成绩《计算智能》课程综合性实验报告开课实验室:数学应用实验室2014 年7月12 日实验题目自动倒车简易模糊差值控制一、实验目的1.了解一些算法,知道matlab的应用2.上机实验操作,熟悉matlab的程序二、设备与环境Matlab软件。
三、实验内容及要求内容:针对倒车问题的程序模仿实验。
第一步:简易模糊插值的控制方法:对于双输入单输出系统而言,设输入量x,y的论域分别为X,Y,输出变量为z,论域为Z。
基于模糊控制系统可以表示成为一个二元分片插值函数:第二步:模型的建立对输入变量y的实际物理论域[-10,10]划分为5个三角模糊集,对输入变量θ的实际物理论域[-pi,pi]划分为7个三角模糊集,对于输出变量(即控制量)η的实际物理论域[-pi/9,pi/9]划分为7个单点模糊集,具体隶属函数见下图:这是输入变量y的隶属函数模糊集模型这是输入变量θ的隶属函数模糊集模型的建立这是控制量η的隶属函数的模糊集模型有这三个隶属函数就可以对这个模型进行控制。
第三步:自动倒车仿真实验在matlab软件编写程序不难实现倒车模型在各种倒车环境下仿真曲线,自动倒车的方程函数如下:控制规则:有matlab程序可以知道倒车图像:5101520258.28.48.68.899.29.49.69.81010.2x/my /mθ=pi/3 y=10m5101520258.599.510x/my /mθ=pi/4 y=10m050100150200250-10-8-6-4-20246x/my /m050100150200250-10-8-6-4-20246x/my /m不同的角度和初始变量的值对应的倒车图像不同。
中科院ai智慧运算实验报告本报告基于中科院AI智慧运算实验,探究了AI在智能医疗、智慧城市和智能制造方面的应用与优化。
实验所采用的技术包括深度学习、自然语言处理、机器学习和数据挖掘等。
本报告将结合实验数据和分析结果,探讨AI在三个领域的具体应用以及优化方案。
一、智能医疗领域AI在智能医疗领域的应用主要包括疾病诊断、药物研发、医疗图像分析和患者管理等方面。
本实验中,我们针对医疗图像分析和患者管理两个方面开展了实验。
1、医疗图像分析医疗图像分析是AI在智能医疗领域的一个应用重点。
我们针对X光胸片图像进行了实验,采用了基于卷积神经网络(CNN)的深度学习方法。
实验结果表明,这一方法在预测肺部疾病时具有较高的准确率和精度。
同时,为了进一步降低误诊率和提高预测准确度,我们还在CNN模型中加入了Attention机制,优化了模型的表现。
2、患者管理患者管理是智能医疗领域的另一个重要应用。
我们结合患者数据和机器学习技术,设计了一个基于患者风险评估的智能医疗平台。
该平台能够对患者的健康状况和风险进行全面评估,为医生提供更好的决策支持。
平台还支持患者自我管理和在线咨询等功能,为患者提供更个性化和便捷的医疗服务。
二、智慧城市领域智慧城市是AI在城市管理和生活服务中的又一重要应用。
我们以城市交通和环境监测为例,探讨了AI在智慧城市领域的应用。
1、城市交通城市交通是智慧城市应用中的重头戏,也是AI技术涉足的较早领域之一。
我们在实验中采用了基于时间序列的机器学习算法,对城市交通流量进行预测和优化。
实验结果表明,该算法能够较为准确地预测城市交通状况,有望为城市交通管理和规划提供依据。
2、环境监测环境监测是智慧城市应用中同样重要的一个领域。
我们以PM2.5监测为例,探讨了基于深度学习的环境数据建模和预测方法。
实验结果表明,该方法的预测精度较高,已经达到了实用水平。
未来,我们将进一步完善该方法,扩展到其他环境数据的建模和预测中。
第1篇一、实验背景随着计算机科学、人工智能、大数据等领域的快速发展,智能计算技术逐渐成为当前研究的热点。
为了更好地掌握智能计算的基本原理和应用,我们进行了为期两周的智能计算实验。
本次实验旨在让学生通过实践操作,加深对智能计算理论知识的理解,提高解决实际问题的能力。
二、实验内容1. 实验环境本次实验所使用的软件平台为Python,主要利用NumPy、Pandas、Scikit-learn等库进行智能计算实验。
硬件环境为个人计算机,操作系统为Windows或Linux。
2. 实验步骤(1)数据预处理数据预处理是智能计算实验的第一步,主要包括数据清洗、数据集成、数据转换等。
通过NumPy和Pandas库对实验数据进行预处理,为后续的智能计算模型提供高质量的数据。
(2)特征工程特征工程是智能计算实验的关键环节,通过对原始数据进行降维、特征选择等操作,提高模型的预测性能。
本实验采用特征选择方法,利用Scikit-learn库实现。
(3)模型选择与训练根据实验需求,选择合适的智能计算模型进行训练。
本次实验主要涉及以下模型:1)线性回归模型:通过线性回归模型对实验数据进行预测,分析模型的拟合效果。
2)支持向量机(SVM)模型:利用SVM模型对实验数据进行分类,分析模型的分类性能。
3)决策树模型:采用决策树模型对实验数据进行预测,分析模型的预测性能。
4)神经网络模型:使用神经网络模型对实验数据进行分类,分析模型的分类性能。
(4)模型评估与优化对训练好的模型进行评估,根据评估结果对模型进行优化。
主要采用以下方法:1)交叉验证:利用交叉验证方法评估模型的泛化能力。
2)参数调整:通过调整模型参数,提高模型的预测性能。
3)特征选择:根据模型评估结果,重新进行特征选择,进一步提高模型的性能。
三、实验结果与分析1. 数据预处理经过数据清洗、数据集成、数据转换等操作,实验数据的质量得到了显著提高。
预处理后的数据满足后续智能计算模型的需求。
计算智能随着时代的发展, 目前的一些计算方法已不能满足人们处理复杂问题时想要达到的效果。
人们从生命现象中受到启示, 发明了模拟生命系统的某些行为、功能和特性的智能计算方法。
计算智能主要有三个分支:进化计算是一种对人类智能的演化模拟方法,它是通过对生物遗传和演化过程的认识,用进化算法去模拟人类智能的进化规律的;神经网络是一种对人类智能的结构模拟方法,它是通过对大量人工神经元的广泛并行互联,构造人工神经网络系统去模拟生物神经系统的智能机理的;模糊计算是一种对人类智能的逻辑模拟方法,它是通过对人类处理模糊现象的认知能力的认识,用模糊逻辑去模拟人类的智能行为的。
其中遗传算法的原理大致是这样,在自然界,由于组成生物群体中各个体之间的差异,对所处环境有不同的适应和生存能力,遵照自然界生物进化的基本原则,适者生存、优胜劣汰,将要淘汰那些最差个体,通过交配将父本优秀的染色体和基因遗传给子代,通过染色体核基因的重新组合产生生命力更强的新的个体与由它们组成的新群体。
在特定的条件下,基因会发生突变,产生新基因和生命力更强的新个体;但突变是非遗传的,随着个体不断更新,群体不断朝着最优方向进化,遗传算法是真实模拟自然界生物进化机制进行寻优的。
在此算法中,被研究的体系的响应曲面看作为一个群体,相应曲面上的每一个点作为群体中的一个个体,个体用多维向量或矩阵来描述,组成矩阵和向量的参数相应于生物物种组成染色体的基因,染色体用固定长度的二进制串表述,通过交换、突变等遗传操作,在参数的一定范围内进行随机搜索,不断改善数据结构,构造出不同的向量,相当于得到了被研究的不同的解,目标函数值较优的点被保留,目标函数值较差的点被淘汰。
能跳出局部较优点,到达全局最优点。
遗传算法是一种迭代算法,它在每一次迭代时都拥有一组解,这组解最初是随机生成的,在每次迭代时又有一组新的解由模拟进化和继承的遗传操作生成,每个解都有一目标函数给与评判,一次迭代成为一代。
华北科技学院基础部综合性实验
实验报告
课程名称计算智能
实验学期 2013 至 2014 学年第 2 学期学生所在系部基础部
年级 12 专业班级计算B121 学生姓名郭春元学号 201209014115 任课教师杨文光
实验成绩
《计算智能》课程综合性实验报告
开课实验室:数学应用实验室2014 年7月12 日
实验题目自动倒车简易模糊差值控制
一、实验目的
1.了解一些算法,知道matlab的应用
2.上机实验操作,熟悉matlab的程序
二、设备与环境
Matlab软件。
三、实验内容及要求
内容:针对倒车问题的程序模仿实验。
第一步:简易模糊插值的控制方法:
对于双输入单输出系统而言,设输入量x,y的论域分别为X,Y,输出变量为z,论域为Z。
基于模糊控制系统可以表示成为一个二元分片插值函数:
第二步:模型的建立
对输入变量y的实际物理论域[-10,10]划分为5个三角模糊集,对输入变量θ的实际物理论域[-pi,pi]划分为7个三角模糊集,对于输出变量(即控制量)η的实际物理论域[-pi/9,pi/9]划分为7个单点模糊集,具体隶属函数见下图:
这是输入变量y的隶属函数模糊集模型
这是输入变量θ的隶属函数模糊集模型的建立
这是控制量η的隶属函数的模糊集模型
有这三个隶属函数就可以对这个模型进行控制。
第三步:自动倒车仿真实验
在matlab软件编写程序不难实现倒车模型在各种倒车环境下仿真曲线,自动倒车的方程函数如下:
控制规则:
有matlab程序可以知道倒车图像:
5
10
15
20
25
8.28.48.68.89
9.29.49.69.81010.2x/m
y /m
θ=pi/3 y=10m
510
152025
8.599.5
10
x/m
y /m
θ=pi/4 y=10m
050100
150200250-10
-8-6-4-20
24
6
x/m
y /m
050100
150200250
-10
-8-6-4-20
2
4
6
x/m
y /m
不同的角度和初始变量的值对应的倒车图像不同。
第四步:根据仿真实验找到合适的初值:
在完成自动倒车的模型建立和规则数据集的提取工作后,根据以上图像的核心函数知道:
为了更好的实现仿真实验的拟合更好的位置纵坐标的y 量化因子k (y )=0.4,输入量θ的量化因子k (θ)=2,控制量η的比例因子k (η)=20. 由上知道:
在倒车实验中,均采用相同的量化因子和比例因子,显示出各种参数具
有很好的普遍性。
Matlab程序如下:
clc
clear all;
N=5000;
h=0.05;
l=4;
v=1;
x(1)=0;
y(1)=-10;
z(1)=pi/2;
a=readfis('Untitled2');
for t=1:N
if y(t)>=10
y(t)=10;
elseif y(t)<=-10
y(t)=-10;
end
if z(t)>=pi
z(t)=pi;
elseif z(t)<=-pi
z(t)=-pi;
end
x(t+1)=x(t)+h*v*cos(z(t));
y(t+1)=y(t)-v*h*sin(z(t));
et(t)=evalfis([y(t),z(t)],a);
z(t+1)=z(t)+(v/l)*h*tan(et(t));
end
plot(x,y)
xlabel('x/m');ylabel('y/m');
总结:
这学期,杨文光老师的指导教学我们学习了《计算智能》这门课程,起初对这门课很是不理解。
然而,杨老师严谨的教学方法让我们找到了学习的方向和动力,也知道了什么是计算智能。
计算智能(简称CI)并不是一个新的术语,早在1988年加拿大的一种刊物便以CI为名。
这门课程讨论了神经网络、模式识别与智能之间的关系,并将留能分为一片关于计算留能和人工留能的区别文章,对于神经网络(ICNN)、模糊系统(FuZZ)和进化计算(ICEc)三个年度性议合为一体。
特别是“蚁群算法”很是重要它可以解决和多问题比如:TSP问题
等的求解,蚁群算法都发挥了很大的作用,还有“遗传算法”这些很有用的算法。
在科学发展的旅程中扮演着重要的角色。
在这一学期的学习中,我深深地体会到了科学的强大,知识的无穷。
我要学的还有很多啊!我要努力好好地去学习那些属于我的知识。
教师评价
评定项目 A B C D 评定项目 A B C D 算法正确界面美观,布局合理
程序结构合理操作熟练
语法、语义正确解析完整
实验结果正确文字流畅
报告规范题解正确
其他:
评价教师签名:
年月日。