应用多元统计分析-第五章 聚类分析
- 格式:pptx
- 大小:1.21 MB
- 文档页数:68


在多元统计分析中,因子分析和聚类分析是两种常用的数据分析方法。
它们可以帮助我们理解数据中的潜在结构和相似性,从而揭示数据背后的规律和关系。
首先,让我们来了解一下因子分析。
因子分析是一种主成分分析方法,用于研究多个变量之间的相关性。
通过对原始数据进行因子提取,可以将一组相关的变量转换为少数几个无关的维度,这些维度被称为因子。
因子分析的核心思想是将一组相关的变量解释为共同的因素或维度,从而减少数据的复杂性。
因子分析可以帮助我们理解变量之间的内在结构,并找到隐藏在数据背后的影响因素。
聚类分析是一种无监督学习方法,用于将数据集中的对象划分为不同的群组。
聚类分析的目标是找到数据中的相似性并将其归类到同一组中。
聚类分析可以帮助我们识别数据中的模式和群组,并进行数据的分类和分析。
聚类分析可以基于数据的相似性进行聚类,也可以基于数据的距离进行聚类。
通过聚类分析,我们可以发现数据中的群组结构,并推断这些群组之间的关系。
因子分析和聚类分析在多元统计分析中扮演着不同的角色。
因子分析更侧重于变量之间的相关性和潜在结构,可以帮助我们理解变量之间的共同特征和因素。
聚类分析则更侧重于数据的相似性和群组结构,可以帮助我们找到数据中的模式和群组。
由于它们的不同特点和应用场景,因子分析和聚类分析常常被结合使用,以获得更全面的数据分析结果。
在实际应用中,因子分析和聚类分析可以用于许多领域。
在社会科学中,因子分析可以用于分析调查问卷数据,找到共同的问题维度和影响因素。
聚类分析可以用于市场细分和受众分析,帮助企业发现潜在的目标市场并制定相应的营销策略。
在医学研究中,因子分析可以用于分析疾病的症状和因素,聚类分析可以用于发现疾病的亚型和患者的分类。
综上所述,因子分析和聚类分析在多元统计分析中发挥着重要作用。
它们可以帮助我们理解数据中的潜在结构和相似性,并用于数据分类、模式识别和关联分析。
因子分析和聚类分析是数据分析中常用的工具,研究人员可以根据具体问题和数据特点选择合适的方法。


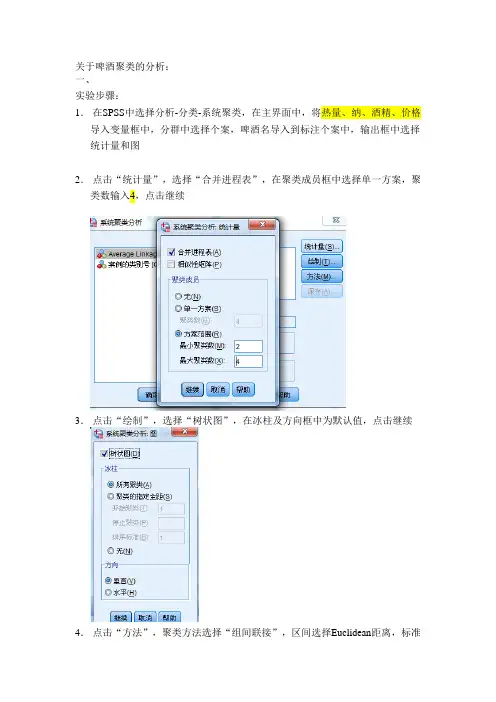
关于啤酒聚类的分析:一、实验步骤:1.在SPSS中选择分析-分类-系统聚类,在主界面中,将热量、纳、酒精、价格导入变量框中,分群中选择个案,啤酒名导入到标注个案中,输出框中选择统计量和图2.点击“统计量”,选择“合并进程表”,在聚类成员框中选择单一方案,聚类数输入4,点击继续3.点击“绘制”,选择“树状图”,在冰柱及方向框中为默认值,点击继续4.点击“方法”,聚类方法选择“组间联接”,区间选择Euclidean距离,标准化中选择Z得分,点击继续45.点击“保存”,选择单一方案,聚类数设置为二、输出结果:聚类表含义:在第一步,将1和17聚成一类,第二步将1和17的总体和11并在一起,在进行分类时,当后面的首次出现阶群集为0时,前面的群集组合为一类,当后面的首次出现不为0时,需按首次出现向前寻找,进行聚类,以此类推。
2. 冰柱图在分成19类时,17和1并在一起;分成18类时,11、17、1并在一起。
当分成四类时,在纵坐标等于4时画一条横线,四类分别为19/16,13/12/10/20/9,14/15/5/4,7/3/2/18/8/6/11/17/1。
.3. 树状图* * * * * * * * * * * * * * * * * * * H I E R A R C H I C A L C L U S T E R A N A L Y S I S * * * * * * * * * * * * * * * * * * *Dendrogram using Ward MethodRescaled Distance Cluster CombineC A S E 0 5 10 15 20 25 Label Num +---------+---------+---------+---------+---------+Budweiser 1 -+Hamms 17 -+-----+Coors 11 -+ +-+Strchsbohemi 8 -+---+ | |Heilemans 18 -+ +-+ +-------------------------------+Milnaukee 6 -----+ | |Schlitz 2 ---+-+ | |Ionenbrau 3 ---+ +---+ +-------+ Aucsberger 7 -----+ | | Heineken 5 -+ | | Kkirin 15 -+-----+ | | Kronensourc 4 -+ +---------------------------------+ | Secrs 14 -------+ | Miller-lite 9 -+-+ | Schlite 20 -+ +-+ | Sudeiser 10 ---+ +-----------+ | Coorslicht 12 ---+-+ +-------------------------------+ Michelos 13 ---+ |Pabst 16 -----+-----------+Olympia 19 -----+在树状图中,分成四类处画一条竖线,得到结果和冰柱图相同。

第一章多元分析概述第一节引言多元统计分析是运用数理统计方法来研究解决多指标问题的理论和方法。
近30年来,随着计算机应用技术的发展和科研生产的迫切需要,多元统计分析技术被广泛地应用于地质、气象、水文、医学、工业、农业和经济等许多领域,已经成为解决实际问题的有效方法。
然而,随着Internet的日益普及,各行各业都开始采用计算机及相应的信息技术进行管理和决策,这使得各企事业单位生成、收集、存储和处理数据的能力大大提高,数据量与日俱增,大量复杂信息层出不穷。
在信息爆炸的今天,人们已经意识到数据最值钱的时代已经到来。
显然,大量信息在给人们带来方便的同时也带来一系列问题。
比如:信息量过大,超过了人们掌握、消化的能力;一些信息真伪难辩,从而给信息的正确应用带来困难;信息组织形式的不一致性导致难以对信息进行有效统一处理等等,这种变化使传统的数据库技术和数据处理手段已经不能满足要求.Internet的迅猛发展也使得网络上的各种资源信息异常丰富,在其中进行信息的查找真如大海捞针。
这样又给多元统计分析理论的发展和方法的应用提出了新的挑战。
多元统计分析起源于上世纪初,1928年Wishart发表论文《多元正态总体样本协差阵的精确分布》,可以说是多元分析的开端。
20世纪30年代R.A. Fisher 、H.Hotelling、S.N.Roy、许宝騄等人作了一系列得奠基性工作,使多元分析在理论上得到了迅速得发展。
20世纪40年代在心理、教育、生物等方面有不少得应用,但由于计算量大,使其发展受到影响,甚至停滞了相当长得时间。
20世纪50年代中期,随着电子计算机得出现和发展,使多元分析方法在地质、气象、医学、社会学等方面得到广泛得应用。
20世纪60年代通过应用和实践又完善和发展了理论,由于新的理论、新的方法不断涌现又促使它的应用范围更加扩大。
20世纪70年代初期在我国才受到各个领域的极大关注,并在多元统计分析的理论研究和应用上也取得了很多显著成绩,有些研究工作已达到国际水平,并已形成一支科技队伍,活跃在各条战线上。




聚类算法在多元统计分析中的应用随着数据分析技术的发展,多元统计分析已经成为实现高质量决策的必备工具。
多元统计分析可以对多个变量之间的关系进行综合性分析,从而协助人们判断数据背后的含义,发掘出数据背后的规律和趋势。
作为多元统计分析的一种重要方法,聚类分析可以将数据样本的成员划分为若干个类别,每个类别内的成员相似度较高,在类别之间的成员相似度则较低。
聚类算法在多元统计分析中的应用非常广泛,可以用于市场细分、客户群体分析、新品定位、市场研究等多个领域。
一、聚类算法的基本原理聚类分析的基本任务是将样本划分为若干个类别。
聚类算法的基本原理是将样本之间相似的特征放在同一类别中,不相似的放在不同类别中。
聚类算法首先需要确定一种距离或相似性度量方式,根据样本之间的距离或相似程度,将样本划分为若干个类别,从而实现聚类分析。
聚类算法通常分为层次聚类和划分聚类两种类型。
层次聚类是一种可视化的聚类方法,它把样本点逐渐合并到一个大的集群中。
划分聚类则是将样本集分成很多不相交的子集群。
二、聚类算法的应用聚类算法在多元统计分析中的应用非常广泛,下面列举了几个常见的应用领域:1. 市场细分在市场细分中,聚类算法可以通过对客户基本信息、消费行为、品味偏好等多个因素的综合分析,将客户划分为若干个类别,用以指导公司产品营销策略。
例如,在服装公司中,聚类算法可以将客户划分为不同的购物类型,如时尚、休闲、商务等不同的消费类型,从而为店铺的定位及推广方案提供科学依据。
2. 客户群体分析客户群体分析通常是为了了解客户的需求、偏好、行为等特征,从而为企业提供更加精准的服务。
聚类算法可以将不同客户划分为不同的分群类别,针对性地开展宣传、销售等各种活动以提高客户忠诚度和满意度。
3. 新品定位新品定位需要了解消费者的需求与偏好,从而确定新产品的定位和市场竞争策略。
聚类算法可以将消费者划分为不同的习惯消费模式,了解消费者的需求和喜好,从而帮助企业做出更加科学、合理的决策。
应用多元统计分析习题解答聚类分析Revised by Jack on December 14,2020第五章 聚类分析判别分析和聚类分析有何区别答:即根据一定的判别准则,判定一个样本归属于哪一类。
具体而言,设有n 个样本,对每个样本测得p 项指标(变量)的数据,已知每个样本属于k 个类别(或总体)中的某一类,通过找出一个最优的划分,使得不同类别的样本尽可能地区别开,并判别该样本属于哪个总体。
聚类分析是分析如何对样品(或变量)进行量化分类的问题。
在聚类之前,我们并不知道总体,而是通过一次次的聚类,使相近的样品(或变量)聚合形成总体。
通俗来讲,判别分析是在已知有多少类及是什么类的情况下进行分类,而聚类分析是在不知道类的情况下进行分类。
试述系统聚类的基本思想。
答:系统聚类的基本思想是:距离相近的样品(或变量)先聚成类,距离相远的后聚成类,过程一直进行下去,每个样品(或变量)总能聚到合适的类中。
对样品和变量进行聚类分析时, 所构造的统计量分别是什么简要说明为什么这样构造 答:对样品进行聚类分析时,用距离来测定样品之间的相似程度。
因为我们把n 个样本看作p 维空间的n 个点。
点之间的距离即可代表样品间的相似度。
常用的距离为 (一)闵可夫斯基距离:1/1()()pq qij ikjk k d q XX ==-∑q 取不同值,分为(1)绝对距离(1q =) (2)欧氏距离(2q =)(3)切比雪夫距离(q =∞) (二)马氏距离 (三)兰氏距离对变量的相似性,我们更多地要了解变量的变化趋势或变化方向,因此用相关性进行衡量。
将变量看作p 维空间的向量,一般用 (一)夹角余弦 (二)相关系数在进行系统聚类时,不同类间距离计算方法有何区别选择距离公式应遵循哪些原则 答: 设d ij 表示样品X i 与X j 之间距离,用D ij 表示类G i 与G j 之间的距离。
(1). 最短距离法 (2)最长距离法(3)中间距离法其中(4)重心法 (5)类平均法 (6)可变类平均法其中是可变的且 <1 (7)可变法22221()2kr kp kq pq D D D D ββ-=++ 其中是可变的且 <1 (8)离差平方和法通常选择距离公式应注意遵循以下的基本原则:22222121pqkq kp kr D D D D β++= 2222(1)()pqkrkpkq pq r rn n D D D D n n ββ=-++(1)要考虑所选择的距离公式在实际应用中有明确的意义。