激光推进数值模拟预处理并行算法研究
- 格式:pdf
- 大小:353.19 KB
- 文档页数:3


激光成形过程中的数值模拟与实验研究
激光成形是一种基于激光熔化和凝固制造工艺的新型加工方法。
它是一种以激
光加工为基础,利用数值模拟技术和实验手段研究工艺参数对材料成形过程的影响,以实现快速制造产品的成型技术。
在工业制造、航空航天、海洋开发等领域得到了广泛应用。
数值模拟是研究激光成形过程中工艺参数与成形质量关系的一种重要手段。
在
数值模拟中,建立准确的模型和模拟算法是关键。
目前,常用的数值模拟方法主要包括有限元方法、有限差分方法、流体力学方法等。
这些方法可以用于预测材料的熔化、凝固、塑性变形和残余应力等关键过程,有效地指导激光成形实验。
但是,数值模拟中的材料模型和各种物理参数的选取和精确度对模拟结果影响
很大。
因此,相对于数值模拟,实验验证更加直观有效。
实验是验证数值模拟结果正确性的一种直接手段。
实验可以直接测量各种工艺
参数和成形效果,同时也可以获取现有模型等数据用于模拟。
通过实验验证,可以改进数值模拟结果,提高成形预测的准确性。
同时,不同的工艺参数对激光成形效果的影响也需要进行深入研究。
例如,对
于激光成形过程中的熔化速度、成形速度、等离子体扰动和熔池温度等参数的研究,可以优化成形效果,提高成形质量和效率。
目前,激光成形技术的发展还需要更加深入的研究和实验验证。
更高效、更精
确的数值模拟方法和实验手段将极大的推动激光成形技术的发展。
未来的工业制造和航空航天等领域,激光成形技术将起到更加重要的作用。

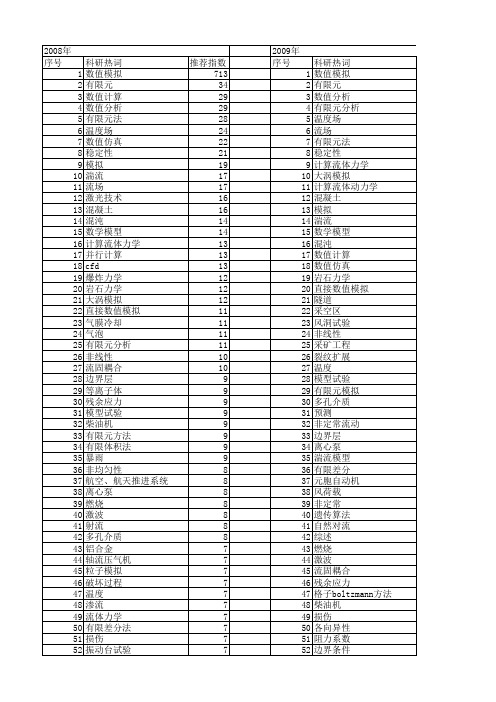
氧碘化学激光器数值模拟中的多块并行通信算法郭红;李艳;安恒斌【摘要】In this paper ,a parallel communication algorithm of supersonic chemical oxygen iodine laser (COIL )’s calculation using multiblock structured mesh has been designed and implemented . This communication algorithm that is designed for large scale supersonic chemical oxygen iodine laser ’s simulation is based on JASMIN (J parallel adaptive structured mesh applications infrastructure ) infrastructure . There are several communication problems in the large scale supersonic chemical oxygen iodine laser’s simulation such as the complexity of blocks’ connecting relationship description , the complexity of management of boundary conditions and the nonuniform of communication schedule . The communication algorithm in this paperi ncludes a blocks’ relationship recognition algorithm to compute blocks’ connecting relationship automatically , a special data structure to help managing boundary conditions and a unified communication schedule which can reduce communication time . According to our calculation results , the communication problems can be resolved by the communication algorithm in this paper and supersonic chemical oxygen iodine laser based on this communication algorithm can be realized easily and simulated regularly . The simulation with 4 .5 million mesh cells in this paper can run efficiently on thousands of processor cores .%为实现氧碘化学激光器大规模数值模拟,基于 JASMIN (J parallel adaptive structured meshapplications infrastructure)框架设计实现了氧碘化学激光器数值模拟的多块并行通信算法。

第9卷 第4期 2009年2月167121819(2009)420845207 科 学 技 术 与 工 程Science Technol ogy and Engineering Vol 19 No 14 Feb .2009Ζ 2009 Sci 1Tech 1Engng 1三维多子区激光推进数值模拟的并行设计与分析曾瑶源 赵文涛 张理论 赵 军 李 倩1(国防科技大学计算机学院,长沙410073;装备指挥技术学院1,北京101416)摘 要 针对三维多子区激光推进并行数值模拟问题,基于按子区独立进行区域分解策略,引入物理网格点负载权重,实现了负载平衡。
通过提高Cache 命中率、优化消息传递、并行写文件等措施,使设计实现了所研究问题的并行化。
并在某国产巨型机上对不同算例进行了测试。
当并行度为16时,最低加速比高于8.96,实现了采用并行计算加快激光推进机理研究的目的。
关键词 多子区 激光推进 耦合计算 区域分解 负载平衡 并行I/O 中图法分类号 O246 TP311.1; 文献标志码 A2008年10月28日收到 国家“九七三”项目(61328)和国家自然科学基金项目(40505023)资助第一作者简介:曾瑶源(1984—),男,硕士生,研究方向:并行计算在激光推进中的应用。
E 2mail:yyzeng@hot m ail .com 。
相比传统的火箭推进,激光推进是一种全新的推进技术,即利用高功率激光与物质相互作用产生喷射动能,作为推进工具发射卫星。
激光推进技术具有高性能、低成本、机动快速、可重复使用等突出优点,可广泛应用于微小卫星发射,对未来国家安全和国防综合实力的提高具有深远意义。
目前,随着研究工作的逐步深入,激光推进技术的应用领域也越来越广泛[1,2]。
在国际上,激光推进技术正面临崭新的历史发展机遇,将逐步从机理研究和实验验证走上实用化道路。
激光推进系统中等离子体的流场演化规律及推力产生过程的数值模拟是激光推进从基础研究到实用化过程中的一个重要环节,它可以精细刻画实验很难测量的流场时空详细演化过程。
激光多点点火二维两相流数值模拟
李海庆;张小兵;李筱炜;袁亚雄
【期刊名称】《兵工学报》
【年(卷),期】2012(032)003
【摘要】激光点火技术是一种新型点传火技术,为了研究激光多点点火对膛内压力波动、燃烧稳定性等的影响进行了数值模拟.以某短身管30 mm火炮激光点火过程为研究对象,建立了二维两相流数学物理模型,采用MacCormack两步预估校正差分格式及“运动控制体”运动边界处理方法实现数值计算.数值计算结果与实验有较好的一致性,对激光点火系统设计具有参考意义.
【总页数】4页(P257-260)
【作者】李海庆;张小兵;李筱炜;袁亚雄
【作者单位】南京理工大学能源与动力工程学院,江苏南京210094;南京理工大学能源与动力工程学院,江苏南京210094;南京理工大学能源与动力工程学院,江苏南京210094;南京理工大学能源与动力工程学院,江苏南京210094
【正文语种】中文
【中图分类】TJ012.1
【相关文献】
1.大长径比点火管高密实火药床点传火过程两相流的数值模拟 [J], 王珊珊;张玉成;王浩;张博孜;陶如意
2.一种两相流点火模型及数值模拟 [J], 周彦煌;张领科;陆春义;余永刚
3.激光点火过程的二维数值模拟 [J], 王育维;张明安
4.稠密颗粒床中点火传火过程的两维两相流数值模拟 [J], 金志明;翁春生
5.中心点火装药结构三维两相流内弹道数值模拟 [J], 刘千里;王升晨;李启明
因版权原因,仅展示原文概要,查看原文内容请购买。
激光雷达点云数据预处理算法研究激光雷达技术作为一种重要的三维数据获取手段,广泛应用于机器人导航、地图构建、环境感知等领域。
然而,激光雷达所产生的原始数据量庞大,且其中包含各种噪声和无效点,给数据处理和应用带来了挑战。
因此,对激光雷达点云数据进行预处理是必不可少的。
激光雷达点云数据预处理算法主要包括去噪、滤波、分割和配准等步骤。
本文将重点研究这些预处理算法并进行综述。
首先,去噪是激光雷达点云数据预处理的首要任务。
去噪的目标是将原始点云数据中的干扰点和噪声点去除,以提取出真实的环境信息。
常用的去噪算法有滑动窗口法、统计学滤波法和基于空间域的滤波法等。
滑动窗口法根据点云密度变化对数据进行采样,以去掉噪声;统计学滤波法通过计算点云中点的邻域统计特性,判断其是否为噪声;基于空间域的滤波法则利用点云中的空间信息进行滤波,以去除噪声点。
其次,滤波是对激光雷达点云数据进行平滑处理的一种方法。
滤波可以进一步减少噪声,并使点云数据更加清晰和易于处理。
广泛使用的滤波算法有高斯滤波、中值滤波和均值滤波等。
高斯滤波通过对点云数据进行高斯核卷积,从而实现去噪和平滑的效果;中值滤波则将点云数据中的每个点替换为邻域中的中值,以消除孤立的噪声点;均值滤波则计算点云数据中每个点的邻域平均值,以减少局部噪声的影响。
接下来,分割是将激光雷达点云数据划分为不同的物体或区域的过程。
分割的目标是识别出点云中不同的物体,并将它们分开以便后续的处理和分析。
常用的分割算法包括基于区域的分割、基于模型的分割和基于几何特征的分割等。
基于区域的分割算法通过计算相邻点间的连通性和相似性,将点云数据分成连续的区域;基于模型的分割算法则提前确定一些特定物体的模型,并通过拟合模型与点云数据进行匹配以达到分割的效果;基于几何特征的分割算法则通过计算点云数据的几何属性,如曲率和法线方向等,将不同的物体区分开来。
最后,配准是将不同时刻或不同传感器采集的点云数据对齐到同一个坐标系中的过程。
收稿日期:2009唱11唱05;修回日期:2009唱12唱22 基金项目:国家重点基础研究发展规划项目(61328) 作者简介:杜洋(1985唱),男,湖南临湘人,硕士,主要研究方向为高性能计算(duyang533@yahoo.com.cn);赵军(1972唱),男,副研究员,博士,主要研究方向为高性能计算;赵文涛(1969唱),男,副研究员,博士,主要研究方向为高性能计算.激光推进数值模拟预处理并行算法研究倡杜 洋,赵 军,赵文涛(国防科学技术大学计算机学院,长沙410073)摘 要:激光推进数值模拟预处理程序为数值模拟主程序提供网格信息和设置边界条件,实现并行计算可以缩短大规模网格生成时间,从而提升高分辨率数值模拟的效率。
分析并利用公用数据的特点改进原有串行算法,进而实现并行计算。
算法测试结果表明,该并行算法有效地缩短了网格生成时间。
关键词:并行计算;激光推进;数值模拟;网格生成中图分类号:TP301.6 文献标志码:A 文章编号:1001唱3695(2010)06唱2054唱03doi:10.3969/j.issn.1001唱3695.2010.06.016ParallelcomputingresearchonpreprocessingofnumericalsimulationforlaserpropulsionDUYang,ZHAOJun,ZHAOWen唱tao(SchoolofComputerScience,NationalUniversityofDefenseTechnology,Changsha410073,China)Abstract:Preprocessingofthenumericalsimulationforlaserpropulsionprovidesgridinformationandboundaryconditionofflowfieldformainprogram.Parallelcomputingabbreviatesthetimeoflargescalegridgenerating,thenadvancedthesimula唱tionefficiencyinhighresolution.Thepapermadeuseofthecharacteristicofpublicdatatoimprovethealgorithm,andrea唱lizedaparallelalgorithm.Thealgorithmtestresultindicatesthatparallelalgorithmabbreviatesthetimeofgridgeneratingef唱fectively.Keywords:parallelcomputing;laserpropulsion;numericalsimulation;gridgenerating 激光推进是一种新兴的推进技术,由美国学者Kantrowi唱tz[1]于1972年首次提出。
与传统推进技术相比,激光推进技术有比冲大、成本低、污染小以及有效载荷高等许多优势,因此有着十分广阔的应用前景,受到各航天大国的广泛重视。
目前对激光推进研究的主要手段是数值模拟,这不仅可以节约研究经费,更能精细地描绘出实验中难以测量的流场时空演化过程。
经过多年的研究发展,激光推进领域涌现出了许多优秀的数值模拟程序[2~7],极大地促进了激光推进技术的发展。
激光推进数值模拟遵循计算流体力学(CFD)[8]的过程,流场离散为网格,针对定义在网格点的特征量进行反复迭代计算。
本文所涉及的激光推进数值模拟预处理程序对Gambit生成的网格数据进行处理,包括网格点的重排和边界条件的设置等,从而为主程序提供可识别的计算数据,其生成的网格规模直接影响模拟的精细度。
随着激光推进技术研究的深入,对流场演化描绘的精细度要求也逐渐提高,这就需要减小网格间距,从而导致网格点数剧增,需要生成更大规模的网格。
然而原有程序的时间复杂度为O(n2)(其中n为网格点规模),显然网格点数增大导致的时间代价增加过于迅速。
例如,在CPU主频为3.0GHz的系统上生成30万网格点规模耗时766s,而生成120万网格点规模耗时达到了14015s,这显然严重影响了研究进展,有必要实现并行计算。
但是原串行算法程序中频繁地修改公用数组信息,导致并行计算实现困难。
本文对输入的公用数组信息进行分析,利用信息中各网格点编号的惟一性来替代原程序中频繁对数组修改而惟一确定后继点的算法,由于减少比较次数,提高了程序的运行速度;另外无须对公用数组进行修改,使得并行计算易于实现,从而极大地缩短了大规模网格生成时间。
1 串行算法分析激光推进数值模拟采用Gambit软件构造网格,但是其所构造的网格不能完全满足主程序读取网格信息的输入顺序要求,因此需扫描网格文件,按照要求对网格点进行重排。
输入的网格文件包含两部分数据,即网格点信息(网格点的坐标)和网格单元信息(每个单元包含的四个网格点编号)。
程序采用三个数组保存这些信息,即X[PN]、Y[PN]、POINT[CN][4]。
其中PN表示网格点数(pointnumber);CN表示网格单元数(cellnumber)。
另外使用两个大小为PN的数组PX、PY保存顺序化之后的网格点坐标。
网格点的位置有三种情况,即顶点、边界点和内点,如图1所示的点A、B、C。
显然此三类网格点在网格单元信息中的情况也有三种:分别出现1、2、4次,也即三类网格点分别包含在1、2、4个网格单元中。
原串行算法步骤设计如下:a)从文件读入数据到相应数组。
b)程序采用findminx函数找到第一个点,在二维条件下即为i最小、j最大的点。
c)对于i=1,imax-1:(a)列的第一个网格点保存至临时变量;(b)查找下一个网格点;(c)按顺序将网格点坐标保存至第27卷第6期2010年6月 计算机应用研究ApplicationResearchofComputersVol.27No.6Jun.2010数组PX、PY;(d)该列是否结束,是转(e),否转(b);(e)一列扫描完毕,使用findprp函数找到位于下一列列首的点;(f)if(i<imax-1)将访问过的网格单元的网格点信息置0。
d)对于i=imax,根据首个网格点findLast查找下一个,直到完成整个网格的扫描。
e)输出顺序网格信息(数组PX和PY)到文件。
其中:步骤c)中的(b)查找下一个点的算法为:扫描整个网格单元数组,如果网格单元第j个网格点是前网格点(j=1,2,3,4),则下一网格点为网格单元的第1(j=4)or第j+1(1,2,3)个网格点,并设置网格点编号取相反数作为访问标志。
查找网格点算法的时间复杂度为O(n)。
由于整个流场的每个点都要进行搜索,网格扫描算法的时间复杂度为O(n2)。
算法中需要对point数组进行两种修改:a)找到一个点后将网格单元信息对应位置取相反数;b)在一列网格点扫描完成后,将该列网格单元的信息置0。
以第一列为列,先扫描到包含A的网格单元,则D可惟一确定,按第一种方式修改该网格单元信息,则包含D的网格单元惟一。
扫描到本列结束,按第二种方式修改本列网格单元。
通过这样的修改,将网格单元设置为三种状态,即已扫描、未扫描和正在扫描。
已扫描的网格单元无网格点信息,而正在扫描的网格单元,由于前一列网格单元已扫描,则与其公有的网格点信息只存在于本列网格单元之中,这样处于扫描过程中的每一列都可以看成第一列,由上至下进行本列扫描,只有一个网格单元包含该点,从而保证搜索的正确性。
然而这样的数据修改不仅耗时长,也使并行计算难以实现。
因为无论数据如何划分,每个进程对point数组进行的修改都应该适时地通知其他进程,以维护各进程中数组拷贝的一致性。
如果通知不及时,在一个时刻就可能有多个网格单元包含目标网格点,从而导致错误的产生,由此可见各数据块有很强的数据依赖关系。
如果使用集合通信对point数组进行更新,由于通信非常频繁而导致巨大的通信开销让并行效率异常低下,甚至不如串行算法,该算法不适合进行并行计算,需要加以改进。
2 串行算法改进实现并行计算的关键在于保证公用数据point数组的稳定性,即不能进行写操作,这样才可以使各个进程并行扫描point数组寻找属于本区域的网格点。
由于每一个点在point中最多出现四次,且在四个网格单元中的编号不同,网格点在各网格单元中按逆时针顺序排列的编号有两种情况:a)网格点的编号在各网格单元中完全一致,如图2所示。
横向扫描根据如下条件确定下一个网格单元:前一个网格单元右上的网格点编号为k(图2中第2个网格点)是下一个网格单元左上的网格点,编号为k%4+1;纵向扫描则根据如下条件确定:前一个网格单元左下网格点编号为k是下一个网格单元左上网格点,编号为j-1(k=1是为4)。
b)编号顺序有两种,有公共边的不同,只有公共点的网格单元相同,如图3所示。
这种情况的扫描与情况a)正好相反。
由于网格点的编号在各网格单元中是惟一的,从而根据编号搜索到的网格单元也是惟一的。
在新算法中,新增一个seq数组记录网格点顺序,如seq[i]=j表示原有网格中第j点在新的网格中的排序为i,可以设定如下扫描算法:a)从文件读入数据;b)搜索第一个点,并确定网格单元的网格点编号方式;c)根据两种不同编号方式选择不同的横向扫描算法,得到第一行的各网格单元;d)由得到的各列首个网格单元依次进行纵向扫描,找到一个网格点顺序号赋予seq当前指标指向位置,并将seq的指标加1;e)最后一列网格点的扫描与该编号方式下的横向扫描类似,按照上述相同的方式修改seq数组;f)根据seq数组中网格点的顺序,将x,y中的数据保存至文件,也即savex[seq[i]],y[seq[i]]tofile。
算法比较:原算法在整个网格扫描中,需对各网格单元编号为1、2、3、4的点依次进行判断,改进后的算法只需对网格单元的一个编号进行判断,减少了冗余判断次数。
另外,改进后的算法无须对point数组进行修改即可准确搜索目标网格点,减少了修改数组的耗时。
在第一行扫描完毕后,各列之间无数据依赖关系,可独立执行纵向扫描,因此易实现并行计算。
原程序使用五个数组,即四个一维双精度浮点数组X[PN]、Y[PN]、PX[PN]、PY[PN],一个二维整形数组point[CN][4]。
由于双精度占8Byte,整形数占2Byte,原算法占用的内存可以近似表示为(2+8×4)×PN=34×PN。
改进的算法中需增加一个整形数组seq[PN],删除了两个浮点数组PX、PY,内存占用可以表示为(2+2+8×2)×PN=20×PN。