计量经济学第五章.
- 格式:ppt
- 大小:206.50 KB
- 文档页数:15




第五章经典单方程计量经济学模型:专门问题一、内容提要本章主要讨论了经典单方程回归模型的几个专门题。
第一个专题是虚拟解释变量问题。
虚拟变量将经济现象中的一些定性因素引入到可以进行定量分析的回归模型,拓展了回归模型的功能。
本专题的重点是如何引入不同类型的虚拟变量来解决相关的定性因素影响的分析问题,主要介绍了引入虚拟变量的加法方式、乘法方式以及二者的组合方式。
在引入虚拟变量时有两点需要注意,一是明确虚拟变量的对比基准,二是避免出现“虚拟变量陷阱”。
第二个专题是滞后变量问题。
滞后变量包括滞后解释变量与滞后被解释变量,根据模型中所包含滞后变量的类别又可将模型划分为自回归分布滞后模型与分布滞后模型、自回归模型等三类。
本专题重点阐述了产生滞后效应的原因、分布滞后模型估计时遇到的主要困难、分布滞后模型的修正估计方法以及自回归模型的估计方法。
如对分布滞后模型可采用经验加权法、Almon多项式法、Koyck方法来减少滞项的数目以使估计变得更为可行。
而对自回归模型,则根据作为解释变量的滞后被解释变量与模型随机扰动项的相关性的不同,采用工具变量法或OLS 法进行估计。
由于滞后变量的引入,回归模型可将静态分析动态化,因此,可通过模型参数来分析解释变量对被解释变量影响的短期乘数和长期乘数。
第三个专题是模型设定偏误问题。
主要讨论当放宽“模型的设定是正确的”这一基本假定后所产生的问题及如何解决这些问题。
模型设定偏误的类型包括解释变量选取偏误与模型函数形式选取取偏误两种类型,前者又可分为漏选相关变量与多选无关变量两种情况。
在漏选相关变量的情况下,OLS估计量在小样本下有偏,在大样本下非一致;当多选了无关变量时,OLS估计量是无偏且一致的,但却是无效的;而当函数形式选取有问题时,OLS估计量的偏误是全方位的,不仅有偏、非一致、无效率,而且参数的经济含义也发生了改变。
在模型设定的检验方面,检验是否含有无关变量,可用传统的t检验与F检验进行;检验是否遗漏了相关变量或函数模型选取有错误,则通常用一般性设定偏误检验(RESET检验)进行。
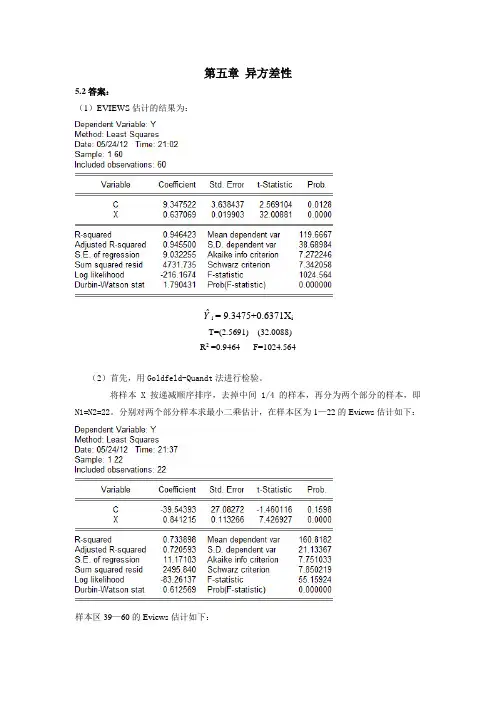
第五章异方差性5.2答案:(1)EVIEWS估计的结果为:Yˆi= 9.3475+0.6371X iT=(2.5691) (32.0088)R2 =0.9464 F=1024.564(2)首先,用Goldfeld-Quandt法进行检验。
将样本X按递减顺序排序,去掉中间1/4的样本,再分为两个部分的样本,即N1=N2=22。
分别对两个部分样本求最小二乘估计,在样本区为1—22的Eviews估计如下:样本区39—60的Eviews估计如下:得到两个部分各自的残差平方和,即∑e 12 =2495.840∑e 22 =603.0148求F 统计量为: F=∑∑e e 2221=2495.840/603.0148=4.1390给定α=0.05,查F 分布表,得临界值为F 0.05=(20,20)=2.12.比较临界值与F 统计量值,有F =4.1390>F 0.05=(20,20)=2.12,说明该模型的随机误差项存在异方差。
其次,用White 法进行检验结果如下:给定α=0.05,在自由度为2下查卡方分布表,得χ2=5.9915。
比较临界值与卡方统计量值,即nR2=10.8640>χ2=5.9915,同样说明模型中的随机误差项存在异方差。
(2)用权数W1=1/X,作加权最小二乘估计,得如下结果用White法进行检验得如下结果:F-statistic 3.138491 Probability 0.050925Obs*R-squared 5.951910 Probability 0.050999。
比较临界值与卡方统计量值,即nR2=5.9519<χ2=5.9915,说明加权后的模型中的随机误差项不存在异方差。
其估计的结果为:Yˆi= 10.3705+0.6309X iT=(3.9436) (34.0467)R2 =0.21144 F=1159.176 DW=0.95855.3答案:(1)EVIEWS估计结果:Yˆi= 179.1916+0.7195X iT=(0.808709) (15.74411)R2 =0.895260 F=247.8769 DW=1.461684 (2)利用White方法检验异方差,则White检验结果见下表:由上述结果可知,该模型存在异方差。


《计量经济学》第五章最新完整知识第五章多元线性回归模型在第四章中,我们讨论只有一个解释变量影响被解释变量的情况,但在实际生活中,往往是多个解释变量同时影响着被解释变量。
需要我们建立多元线性回归模型。
一、多元线性模型及其假定多元线性回归模型的一般形式是i iK K i i i x x x y εβββ++++= 2211令列向量x 是变量x k ,k =1,2,的n 个观测值,并用这些数据组成一个n ×K 数据矩阵X ,在多数情况下,X 的第一列假定为一列1,则β1就是模型中的常数项。
最后,令y 是n 个观测值y 1, y 2, …, y n 组成的列向量,现在可将模型写为:εββ++=K K x x y 11构成多元线性回归模型的一组基本假设为假定1. εβ+=X y我们主要兴趣在于对参数向量β进行估计和推断。
假定2. ,0][][][][21=?=n E E E E εεεε 假定3. n I E 2][σεε='假定4. 0]|[=X E ε我们假定X 中不包含ε的任何信息,由于)],|(,[],[X E X Cov X Cov εε= (1)所以假定4暗示着0],[=εX Cov 。
(1)式成立是因为,对于任何的双变量X ,Y ,有E(XY)=E(XE(Y|X)),而且])')|()([(])')((),(EY X Y E EX X E EY Y EX X E Y X Cov --=--=))|(,(X Y E X Cov =这也暗示βX X y E =]|[假定5 X 是秩为K 的n ×K 随机矩阵这意味着X 列满秩,X 的各列是线性无关的。
在需要作假设检验和统计推断时,我们总是假定:假定6 ],0[~2I N σε 二、最小二乘回归 1、最小二乘向量系数采用最小二乘法寻找未知参数β的估计量β,它要求β的估计β?满足下面的条件 22min ?)?(ββββX y X y S -=-? (2)其中()()∑∑==-'-=-?-nj Kj j ij i X y X y x y X y 1212ββββ,min 是对所有的m 维向量β取极小值。



![[经济学]计量经济学第五章](https://uimg.taocdn.com/a3cd2b7db307e87100f69620.webp)