第04章 Means过程和样本T检验
- 格式:ppt
- 大小:1.15 MB
- 文档页数:44

Spss16.0与统计数据分析均值比较和T检验20XX6月13日均值比较和T 检验统计分析常常采取抽取样本的方法,即从总体中随机抽取一定数量的样本进行研究来推论总体的特性。
但是,由于抽取的样本不一定具有完全代表性,样本统计量与总体参数间存在差异,所以不能完全的说明总体的特性。
同时,我们也可以知道,均值不等的两个样本不一定来自均值不同的整体。
对于如何避免这些问题,我们自然可以想均值比较和T 检验 1、Means 过程 1.1 Means 过程概述(1)功能:对数据进行进行分组计算,比较制定变量的描述性统计量包括均值、标准差 、总和、观测量数、方差等一系列单列变量描述性统计量,还可以给出方差分析表和线性检验结果。
(2)计算公式为: nxx ni i∑==1111.2问题举例:比较不同性别同学的体重平均值和方差。
数据如下表所示:体重表1.3用SPSS 操作过程截图:1.4 结果和讨论p{color:black;font-family:sans-serif;font-size:10pt;font-weight:normal} Your trial period for SPSS for Windows will expire in 14 days.p{color:0;font -family:Monospaced;font-size:13pt;font-style:normal;font-weight:normal;text-decoration:none}MEANS TABLES=体重 BY 性别/CELLS MEAN COUNT STDDEV VAR.MeansCase Processing SummaryCasesIncluded Excluded TotalN Percent N Percent N Percent体重* 性别24 100.0% 0 .0% 24 100.0%由SPSS 计算计算结果可知男同学体重平均值为:56.5,方差为54.091女同学体重平均值为43.833,方差为29.970。

单样本t检验的原理和步骤
单样本t检验,也被称为student t检验,主要用于样本含量较小(n < 30),且总体标准差σ未知的正态分布。
这种检验方法是用t分布理论来推论差异发生的概率,从而比较两个平均数的差异是否显著。
单样本t检验的步骤:
1. 提出原假设和备择假设:原假设H0认为总体均值与检验值之间不存在显著差异,即原假设H0:μ=μ0,备择假设H1:μ≠μ0。
2. 确定检验统计量:检验统计量为t统计量。
3. 计算检验统计量的观测值和p值:这一步通常需要使用统计软件如SPSS或R语言等进行计算。
4. 确定显著性水平α,并作出决策:一般情况下,最常用的α值是
0.05,但也可以结合具体情况使用0.001、0.005、0.0001等。
如果计算出的p 值小于或等于显著性水平α,那么就拒绝原假设,认为总体均值与检验值之间存在显著差异;如果p值大于显著性水平α,那么就接受原假设,认为总体均值与检验值之间无显著差异。
单样本t检验的目的是通过比较样本均值与某个特定值(如理论值、历史值或其他样本的均值)的大小,以确定样本所代表的总体均值与该特定值是否存在显著性差异。
同时在进行单样本t检验时,需要满足样本来自正态或近似正态总体,样本量足够大等一些前提条件。
如果不能满足这些条件,会导致检验结果的准确性受到影响。
因此在进行单样本t检验前,需要对数据进行适当的检验和处理。
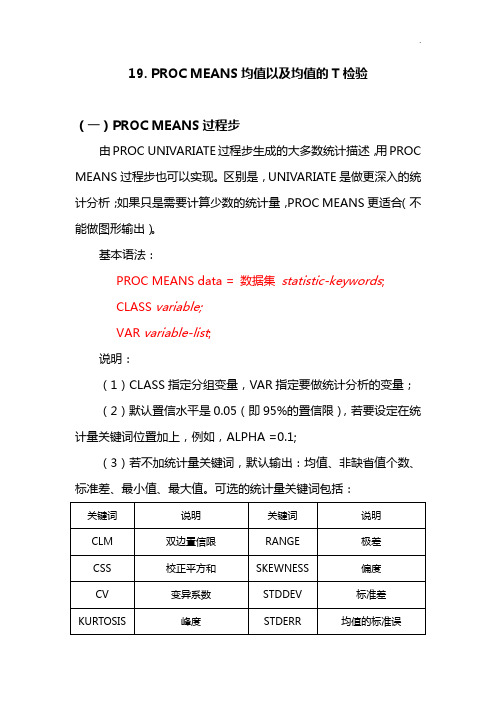
19. PROC MEANS均值以及均值的T检验(一)PROC MEANS过程步由PROC UNIVARIATE过程步生成的大多数统计描述,用PROC MEANS过程步也可以实现。
区别是,UNIVARIATE是做更深入的统计分析;如果只是需要计算少数的统计量,PROC MEANS更适合(不能做图形输出)。
基本语法:PROC MEANS data = 数据集statistic-keywords;CLASS variable;VAR variable-list;说明:(1)CLASS指定分组变量,VAR指定要做统计分析的变量;(2)默认置信水平是0.05(即95%的置信限),若要设定在统计量关键词位置加上,例如,ALPHA =0.1;(3)若不加统计量关键词,默认输出:均值、非缺省值个数、标准差、最小值、最大值。
可选的统计量关键词包括:例1 儿童书作家考察市面上儿童书的页数作为出书的参考,搜集数据(C:\MyRawData\Picbooks.dat)如下:读入数据,计算数据个数、均值、中位数,以及90%的置信限。
代码:data booklengths;infile'c:\MyRawData\Picbooks.dat';input NumberOfPages @@;run;*Produce summary statistics;proc means data = booklengths N MEAN MEDIAN CLM ALPHA = 0.10 MAXDEC = 2;title'Summary of Picture Book Lengths';run;运行结果:说明:有90%的把握说“儿童书的页数范围是:[26.44, 29.56]”.(二)假设检验的P值法一、什么是假设检验?实际中,我们只能得到抽取的样本(部分)的统计结果,要进一步推断总体(全部)的特征,但是这种推断必然有可能犯错,犯错的概率为多少时应该接受这种推断呢?为此,统计学家就开发了一些统计方法进行统计检定,通过把所得到的统计检定值,与统计学家树立了一些随机变量的概率分布进行对比,我们可以知道在百分之多少的机遇下会得到目前的结果。



实验四均值检验一、实验目的学习利用SPSS进行单样本、两独立样本以及成对样本的均值检验。
二、实验内容及步骤(一)描述统计(Means过程)实验内容:某医师测得血红蛋白值(g%)如表3.1,试利用Means过程作基本的描述性统计分析。
界面说明:【Dependent List框】:用于选入需要分析的变量。
【Independent List框】:用于选入分组变量。
【Options钮】:弹出Options对话框,选择需要计算的描述统计量和统计分析。
o Statistics框可选的描述统计量。
它们是:1.sum,number of cases 总和,记录数2.mean, geometric mean, harmonic mean 均数,几何均数,修正均数3.standard deviation,variance,standard error of the mean 标准差,均数的标准误,方差4.median, grouped median 中位数,频数表资料中位数(比如30岁组有5人,40岁组有6人,则在计算grouped median时均按组中值35和45进行计算)。
5.minimum,maximum,range 最小值,最大值,全距6.kurtosis, standard error of kurtosis 峰度系数,峰度系数的标准误7.skewness, standard error of skewness 偏度系数,偏度系数的标准误8.percentage of total sum, percentage of total N 总和的百分比,样本例数的百分比o Cell Statistics框选入的描述统计量。
o Statistics for First layer复选框组1.Anova table and eta 对分组变量进行单因素方差分析,并计算用于度量变量相关程度的eta值。
2.Test for linearity 检验线性相关性,实际上就是上面的单因素方差分析。