北邮 编译原理 词法分析器实验
- 格式:doc
- 大小:143.00 KB
- 文档页数:14

编译原理词法分析实验报告实验名称:词法分析器的设计与实现一、实验目的:1.熟悉编译原理中词法分析的基本概念和原理;2.掌握正则表达式的使用方法;3.实现一个简单的词法分析器。
二、实验内容:1.设计一个简单的编程语言,包含如下几种类型的词法单元:关键字、标识符、常量、运算符和界符。
2.使用正则表达式定义每种词法单元的模式。
3.设计一个词法分析器,将源代码中的每个词法单元识别出来并输出。
三、实验步骤:1. 确定编程语言的词法单元类型和正则表达式模式,定义相应的单词类型(如 TokenType)和模式(如 regex)。
2. 实现一个词法分析器的类 Lexer,包含以下方法:(1)一个构造方法,用于初始化词法分析器的输入源代码。
(2) 一个getNextToken方法,用于获取源代码中的下一个词法单元。
3. 在getNextToken方法中,使用正则表达式逐个识别源代码中的词法单元,并返回相应的Token对象。
4. 设计一个Token类,包含以下属性:词法单元类型、词法单元的值和位置信息等。
5.在主程序中使用词法分析器,将源代码中的每个词法单元识别出来并输出。
四、实验结果:1.设计一个简单的编程语言,包含如下词法单元类型(示例):(1) 关键字:if、else、while、for等;(2)标识符:变量名等;(3)常量:整数、浮点数、字符串等;(4)运算符:+、-、*、/、=等;(5)界符:(、)、{、}、;等。
2. 实现一个词法分析器,识别出源代码中的每个词法单元,并输出相应的Token对象。
五、实验总结:通过本次实验,我熟悉了编译原理中词法分析的基本概念和原理,并掌握了正则表达式的使用方法。
我成功完成了一个简单的词法分析器的设计与实现,实现了源代码中每个词法单元的识别与输出。
这次实验对我深化了对编译原理中词法分析的理解,并提高了我的编程能力。

编译原理实验词法分析实验报告一、实验目的词法分析是编译过程的第一个阶段,其主要任务是从左到右逐个字符地对源程序进行扫描,产生一个个单词符号。
本次实验的目的在于通过实践,深入理解词法分析的原理和方法,掌握如何使用程序设计语言实现词法分析器,提高对编译原理的综合应用能力。
二、实验环境本次实验使用的编程语言为_____,开发工具为_____。
三、实验原理词法分析的基本原理是根据编程语言的词法规则,将输入的字符流转换为单词符号序列。
单词符号通常包括关键字、标识符、常量、运算符和界符等。
词法分析器的实现方法有多种,常见的有状态转换图法和正则表达式法。
在本次实验中,我们采用了状态转换图法。
状态转换图是一种有向图,其中节点表示状态,有向边表示在当前状态下输入字符的可能转移。
通过定义不同的状态和转移规则,可以实现对各种单词符号的识别。
四、实验步骤1、定义单词符号的类别和编码首先,确定实验中要识别的单词符号种类,如关键字(if、else、while 等)、标识符、整数常量、浮点数常量、运算符(+、、、/等)和界符(括号、逗号等)。
为每个单词符号类别分配一个唯一的编码,以便后续处理。
2、设计状态转换图根据单词符号的词法规则,绘制状态转换图。
例如,对于标识符的识别,起始状态为“起始状态”,当输入为字母时进入“标识符中间状态”,在“标识符中间状态”中,若输入为字母或数字则继续保持该状态,直到遇到非字母数字字符时结束识别,确定为一个标识符。
3、编写词法分析程序根据状态转换图,使用所选编程语言实现词法分析器。
在程序中,通过不断读取输入字符,根据当前状态进行转移,并在适当的时候输出识别到的单词符号。
4、测试词法分析程序准备一组包含各种单词符号的测试用例。
将测试用例输入到词法分析程序中,检查输出的单词符号是否正确。
五、实验代码以下是本次实验中实现词法分析器的核心代码部分:```include <stdioh>include <ctypeh>//单词符号类别定义typedef enum {KEYWORD,IDENTIFIER,INTEGER_CONSTANT,FLOAT_CONSTANT,OPERATOR,DELIMITER} TokenType;//关键字列表char keywords ={"if","else","while","for","int","float","void"};//状态定义typedef enum {START,IN_IDENTIFIER,IN_INTEGER,IN_FLOAT,IN_OPERATOR} State;//词法分析函数TokenType getToken(char token, int tokenLength) {State state = START;int i = 0;while (1) {char c = getchar();switch (state) {case START:if (isalpha(c)){state = IN_IDENTIFIER;tokeni++= c;} else if (isdigit(c)){state = IN_INTEGER;tokeni++= c;} else if (c =='+'|| c ==''|| c ==''|| c =='/'|| c =='('|| c ==')'|| c ==';'|| c ==','){state = IN_OPERATOR;tokeni++= c;} else if (c ==''){state = IN_FLOAT;tokeni++= c;} else if (c == EOF) {tokeni ='\0';tokenLength = i;return -1;} else {tokeni ='\0';tokenLength = i;return -2;}break;case IN_IDENTIFIER:if (isalpha(c) || isdigit(c)){tokeni++= c;} else {ungetc(c, stdin);tokeni ='\0';tokenLength = i;//检查是否为关键字for (int j = 0; j < sizeof(keywords) / sizeof(keywords0); j++){if (strcmp(token, keywordsj) == 0) {return KEYWORD;}}return IDENTIFIER;}break;case IN_INTEGER:if (isdigit(c)){tokeni++= c;} else if (c ==''){state = IN_FLOAT;tokeni++= c;} else {ungetc(c, stdin);tokeni ='\0';tokenLength = i;return INTEGER_CONSTANT;}break;case IN_FLOAT:if (isdigit(c)){tokeni++= c;} else {ungetc(c, stdin);tokeni ='\0';tokenLength = i;return FLOAT_CONSTANT;}break;case IN_OPERATOR: tokeni ='\0';tokenLength = i;return OPERATOR; break;}}}int main(){char token100;int tokenLength;TokenType tokenType;while ((tokenType = getToken(token, &tokenLength))!=-1) {switch (tokenType) {case KEYWORD:printf("Keyword: %s\n", token);break;case IDENTIFIER:printf("Identifier: %s\n", token);break;case INTEGER_CONSTANT:printf("Integer Constant: %s\n", token);break;case FLOAT_CONSTANT:printf("Float Constant: %s\n", token);break;case OPERATOR:printf("Operator: %s\n", token);break;case DELIMITER:printf("Delimiter: %s\n", token);break;}}return 0;}```六、实验结果对准备的测试用例进行输入,得到的词法分析结果如下:测试用例 1:```int main(){int num = 10;float pi = 314;if (num > 5) {printf("Hello, World!\n");}}```词法分析结果:```Keyword: int Identifier: main Delimiter: (Delimiter: ){Identifier: num Operator: =Integer Constant: 10;Identifier: float Identifier: pi Operator: =Float Constant: 314;Keyword: ifDelimiter: (Identifier: numOperator: >Integer Constant: 5){Identifier: printfDelimiter: (String: "Hello, World!\n" Delimiter: );}```测试用例 2:```for (int i = 0; i < 10; i++){double result = i 25;```词法分析结果:```Keyword: for Delimiter: (Keyword: int Identifier: i Operator: =Integer Constant: 0;Identifier: i Operator: <Integer Constant: 10;Identifier: i Operator: ++)Identifier: doubleIdentifier: resultOperator: =Identifier: iOperator:Float Constant: 25;}```通过对多个测试用例的分析,词法分析器能够正确识别出各种单词符号,实验结果符合预期。

实验报告编译原理与技术ytinrete程序设计1题目:词法分析程序的设计与实现。
实验内容:设计并实现C语言的词法分析程序,要求如下。
(1)、可以识别出用C语言编写的源程序中的每个单词符号,并以记号的形式输出每个单词符号。
(2)、可以识别并读取源程序中的注释。
(3)、可以统计源程序汇总的语句行数、单词个数和字符个数,其中标点和空格不计算为单词,并输出统计结果(4)、检查源程序中存在的错误,并可以报告错误所在的行列位置。
(5)、发现源程序中存在的错误后,进行适当的恢复,使词法分析可以继续进行,通过一次词法分析处理,可以检查并报告源程序中存在的所有错误。
|实验要求:方法1:采用C/C++作为实现语言,手工编写词法分析程序。
方法2:通过编写LEX源程序,利用LEX软件工具自动生成词法分析程序。
算法思路:首先通过遍历,统计行号和字符数,并记录所有的注释。
其次,再次读取,利用一个字符数组作为buffer保存一行的数据,在对其中的数据进行处理,完成之后再读下一行,跳过注释。
对于整行数据的处理,依靠空格将其分成单个单词再具体处理。
对于查错问题实在是一个难题,只能根据一些规则判定有错并记录。
&程序源代码:==*p || 'E'==*p || 'e'==*p)//小数和指数形式{(1,*p);p++;while(isdigit(*p)){(1,*p);p++;}}{sum_word++;(temp_word);cout<<endl<<"第"<<sum_word<<"个单词:"<<" 无符号数:" <<temp_word<<endl;}}elseif('#'==*p)//预处理文件特殊处理{while('\0'!=*p){(1,*p);》p++;}//p指向换行,完成直接退出(temp_word);}elseif('"'==*p)//字符串{();p++;while('"'!=*p)<{(1,*p);p++;}p++;sum_word++;cout<<endl<<"第"<<sum_word<<"个单词:"<<" 字符串:" <<temp_word<<endl;}elseif('+'==*p)//处理符号{。
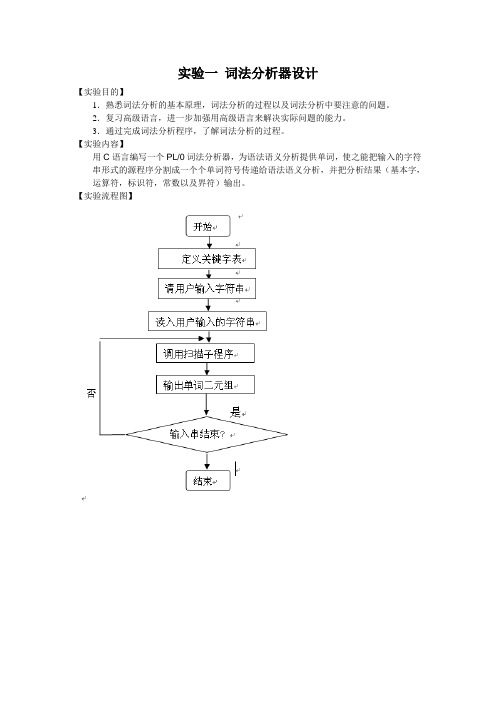
实验一词法分析器设计【实验目的】1.熟悉词法分析的基本原理,词法分析的过程以及词法分析中要注意的问题。
2.复习高级语言,进一步加强用高级语言来解决实际问题的能力。
3.通过完成词法分析程序,了解词法分析的过程。
【实验内容】用C语言编写一个PL/0词法分析器,为语法语义分析提供单词,使之能把输入的字符串形式的源程序分割成一个个单词符号传递给语法语义分析,并把分析结果(基本字,运算符,标识符,常数以及界符)输出。
【实验流程图】【实验步骤】1.提取pl/0文件中基本字的源代码while((ch=fgetc(stream))!='.'){int k=-1;char a[SIZE];int s=0;while(ch>='a' && ch<='z'||ch>='A' && ch<='Z'){if(ch>='A' && ch<='Z') ch+=32;a[++k]=(char)ch;ch=fgetc(stream);}for(int m=0;m<=12&&k!=-1;m++)for(int n=0;n<=k;n++){if(a[n]==wsym[m][n]) ++s;else s=0;if(s==(strlen(wsym[m]))) {printf("%s\t",wsym[m]);m=14;n=k+1;} }2.提取pl/0文件中标识符的源代码while((ch=fgetc(stream))!='.'){int k=-1;char a[SIZE]=" ";int s=0;while(ch>='a' && ch<='z'||ch>='A' && ch<='Z'){if(ch>='A' && ch<='Z') ch+=32;a[++k]=(char)ch;ch=fgetc(stream);}for(int m=0;m<=12&&k!=-1;m++)for(int n=0;n<=k;n++){if(a[n]==wsym[m][n]) ++s;else s=0;if(s==(strlen(wsym[m]))) {m=14;n=k+1;}}if(m==13) for(m=0;a[m]!=NULL;m++) printf("%c ",a[m]);3.提取pl/0文件中常数的源代码while((ch=fgetc(stream))!='.'){while(ch>='0' && ch<='9'){num=10*num+ch-'0';ch=fgetc(stream);}if(num!=0) printf("%d ",num);num=0;}4.提取pl/0文件中运算符的源代码int ch=fgetc(stream);while(ch!='.'){switch(ch){case'+': printf("+ ");break;case'-': printf("- ");break;case'*': printf("* ");break;case'/': printf("/ ");break;case'>': if(fgetc(stream)=='=')printf(">= "); else printf("> ");break;case'<': if(fgetc(stream)=='=')printf("<= "); else printf("< ");break;case':': printf(":= ");break;case'#': printf("# ");break;case'=': printf("= ");break;default: break;}ch=fgetc(stream);5.提取pl/0文件中界符的源代码int ch=fgetc(stream);while(ch!='.'){switch(ch){case',': printf(", ");break;case';': printf("; ");break;case'(': printf("( ");break;case')': printf(") ");break;default: break;}ch=fgetc(stream);}【实验结果】1.pl/0文件(222.txt)内容const a=10;var b,c;procedure p;beginc:=b+a;end;beginread(b);while b#0 dobegincall p;write(2*c);read(b)endend .2.实验运行结果【实验小结】1.了解程序在运行过程中对词法分析,识别一个个字符并组合成相应的单词,是机器能过明白程序,定义各种关键字,界符。

自底向上语法分析器实验报告一.问题描述编写语法分析程序,实现对算术表达式的语法分析。
要求所分析算术表达式由如下的文法产生。
E -> E+T | E-T | TT -> T*F | T/F | FF -> id | (E) | num实验要求:在对输入表达式进行分析的过程中,输出所采用的产生式。
编写语法分析程序实现自底向上的分析,要求如下:(1)构造识别所有活前缀的DFA。
(2)构造LR分析表。
(3)编程实现算法4.3,构造LR分析程序。
二.算法思想1.大体步骤:(1)根据题目所给出的文法构造相应的拓广文法,并求出该文法各非终结符的FIRST、FOLLOW集合;(2).构造拓广文法的项目集规范族,并构造出识别所有前缀的DFA;(3)构造文法的LR分析表;(4)由此构造LR分析程序。
2.数据结构:1.输入缓冲区为一个字符型数组,读入输入的算术表达式并保存在此,以’$’结束;2.构建一个相对应的整型数组,将输入缓冲区中的字符转换为相应的代号并保存;3.构造一个结构体,以保存文法的某个产生式,该结构包括三个元素:整形变量,保存产生式左部非终结符代号。
整型数组,保存产生式右部字符串的代号。
整型变量,保存产生式右部长度;4.定义该结构的数组,保存文法的所有产生式;5.定义两个二维整形数组,goto和action,其值大于零代表移进操作,小于零代表规约操作,引进的状态或规约用到的产生式又绝对值表示。
等于零代表出现错误。
等于特殊值999代表acc.状态。
3.计算过程:文法对应的拓广文法为:1 S -> E2 E -> E+T3 E -> E-T4 E -> T5 T -> T*F6 T -> T/F7 T -> F8 F -> (E)9 F -> id10 F -> num求的各个非终结符的FIRST、FOLLOW集合为:FIRST(S) = { id, num, ( } FOLLOW (S) = { $ }FIRST(E) = { id, num, ( } FOLLOW (E) = { $ , + , - , ) }FIRST(T) = { id, num, ( } FOLLOW (T) = { $ , + , - , * , / , ) }FIRST(F) = { id, num, ( } FOLLOW (F) = { $ , + , - , * , / , ) }构造项目集规范族:I0= closure({S->·E}) = {S->·E, E->·E+T, E->·E-T, E->·T, T->·T*F, T->·T/F, T->·F, F->·id, F->·(E), F->·num};从I0出发:I1 = go(I0, E) = closure({S->E·, E->E·+T, E->E·-T}) = {S->E·, E->E·+T, E->E·-T};I2 = go(I0, T) = closure({E->T·, T->T·*F, T->T·/F}) = {E->T·, T->T·*F, T->T·/F};I3 = go(I0, F) = closure({T->F·}) = {T->F·};I4 = go(I0, id) = closure({F->id·}) = {F->id·};I5= go(I0, () = closure({F->(·E)}) = {F->(·E), E->·E+T, E->·E-T, E->·T, T->·T*F, T->·T/F, T->·F, F->·id, F->·(E), F->·num};I6 = go(I0, num) = closure({F->num·}) = {F->num·};从I1出发:I7= go(I1, +) = closure({E->E+·T}) = {E->E+·T, T->·T*F, T->·T/F, T->·F, F->·id, F->·(E), F->·num};I8= go(I1, -) = closure({E->E-·T}) = {E->E-·T, T->·T*F, T->·T/F, T->·F, F->·id, F->·(E), F->·num};从I2出发:I9 = go(I2, *) = closure({T->T*·F}) = {T->T*·F, F->·id, F->·(E), F->·num};I10 = go(I2, /) = closure({T->T/·F}) = {T->T/·F, F->·id, F->(E), F->·num};从I5出发:I11 = go(I5, E) = closure({F->(E·), E->E·+T, E->E·-T}) = {F->(E·), E->E·+T, E->E·-T};从I7出发:I12 = go(I7, T) = closure({E->E+T·, T->T·*F, T->T·/F}) = {E->E+T·, T->T·*F, T->T·/F};从I8出发:I13 = go(I8, T) = closure({E->E-T·, T->T·*F, T->T·/F}) = {E->E-T·, T->T·*F, T->T·/F};从I9出发:I14 = go(I9, F) = closure({T->T*F·}) = {T->T*F·};从I10出发:I15 = go(I10, F) = closure({T->T/F·}) = {T->T/F·};从I11出发:I16 = go(I11, )) = closure({F->(E)·}) = {F->(E)·};下面构造文法的LR分析表:goto[0,E] = 1; goto[0,T] = 2; goto[0,F] = 3;action[0,id] = S4; action[0,(] = S5; action[0,num] = S6;action[1,$] = ACC.; action[1,+] = S7; action[1,-] = S8;;action[2,)] = action[2,+] = action[2,-] = action[2,$] = R4;action[2,*] = S9; action[2,/] = S10;action[3,)] = action[3,+] = action[3,-] = action[3,*] = action[3,/] = action[3,$] = R7;action[4,)] = action[4,+] = action[4,-] = action[4,*] = action[4,/] = action[4,$] = R8;goto[5,E] = 11; goto[5,T] = 2; goto[5,F] = 3;action[5,id] = S4; action[5,(] = S5; action[5,num] = S6;action[6,)] = action[6,+] = action[6,-] = action[6,*] = action[6,/] = action[6,$] = R10;goto[7,T] = 12; goto[7,F] = 3;action[7,id] = S4; action[7,(] = S5; action[7,num] = S6;goto[8,T] = 13; goto[8,F] = 3;action[8,id] = S4; action[8,(] = S5; action[8,num] = S6;goto[9,F] = 14;action[9,id] = S4; action[9,(] = S5; action[9,num] = S6;goto[10,F] = 15;action[10,id] = S4; action[10,(] = S5; action[10,num] = S6;action[11,)] = S16; action[11,+] = S7; action[11,-] = S8;action[12,)] = action[12,+] = action[12,-] = action[12,$] = R2; action[12,*] = S9; action[12,/] = S10;action[13,)] = action[13,+] = action[13,-] = action[13,$] = R3; action[13,*] = S9; action[13,/] = S10;action[14,)] = action[14,+] = action[14,-] = action[14,*] = action[14,/] = action[14,$] = R5;action[15,)] = action[15,+] = action[15,-] = action[15,*] = action[15,/] = action[15,$] = R6;action[16,)] = action[16,+] = action[16,-] = action[16,*] = action[16,/] = action[16,$] = R9;4.SLR(1)分析表为:E1: 缺少运算对象。

编译原理实验(一)——词法分析器一.实验描述运行环境:vc++2008对某特定语言A ,构造其词法规则。
该语言的单词符号包括:12状态转换图3程序流程:词法分析作成一个子程序,由另一个主程序调用,每次调用返回一个单词对应的二元组,输出标识符表、常数表由主程序来完成。
二.实验目的通过动手实践,使学生对构造编译系统的基本理论、编译程序的基本结构有更为深入的理解和掌握;使学生掌握编译程序设计的基本方法和步骤;能够设计实现编译系统的重要环节。
同时增强编写和调试程序的能力。
三.实验任务编制程序实现要求的功能,并能完成对测试样例程序的分析。
四.实验原理char set[1000],str[500],strtaken[20];//set[]存储代码,strtaken[]存储当前字符char sign[50][10],constant[50][10];//存储标识符和常量定义了一个Analyzer类class Analyzer{public:Analyzer(); //构造函数 ~Analyzer(); //析构函数int IsLetter(char ch); //判断是否是字母,是则返回 1,否则返回 0。
int IsDigit(char ch); //判断是否为数字,是则返回 1,否则返回 0。
void GetChar(char *ch); //将下一个输入字符读到ch中。
void GetBC(char *ch); //检查ch中的字符是否为空白,若是,则调用GetChar直至ch进入一个非空白字符。
void Concat(char *strTaken, char *ch); //将ch中的字符连接到strToken之后。
int Reserve(char *strTaken); //对strTaken中的字符串查找保留字表,若是一个保留字返回它的数码,否则返回0。
void Retract(char *ch) ; //将搜索指针器回调一个字符位置,将ch置为空白字符。
词法分析器实验报告实验目的:设计、编制、调试一个词法分析子程序-识别单词,加深对词法分析原理的理解。
功能描述:该程序要实现的是一个读单词过程,从输入的源程序中,识别出各个具有独立意义的单词,即基本保留字、标识符、常数、运算符、分隔符五大类。
并依次输出各个单词的内部编码及单词符号自身值。
(遇到错误时可显示“Error!”,然后跳过错误部分继续进行)设计思想:设计该词法分析器的过程中虽然没有实际将所有的状态转移表建立出来,但是所用的思想是根据状态转移表实现对单词的识别。
首先构造一个保留字表,然后,每输入一个字符就检测应该进入什么状态,并将该字符连接到d串后继续输入,如此循环,最后根据所在的接受状态以及保留字表识别单词。
符号表:记号类别属性值ws - -const 保留字 1var 保留字 1call 保留字 1begin 保留字 1if 保留字 1while 保留字 1do 保留字 1odd 保留字 1end 保留字 1then 保留字 1procedure 保留字 1= 运算符 2< 运算符 2<= 运算符 2<> 运算符 2> 运算符 2>= 运算符 2* 运算符 2+ 运算符 2- 运算符 2/ 运算符 2:= 运算符 2ident 标识符 3number 常数 4 ( 分隔符 5) 分隔符 5; 分隔符 5, 分隔符 5. 分隔符 5状态转换图:①标识符及保留字:letter or digittStart letter②number:③关系操作符:0 21 435startdigit.digit E+ | -digitdigitdigitdigitEdigit otherother④分隔符:start< other =(<=, 2) >= other>=* * (<>, 2)(<,2)(=, 2)(>=, 2)(>, 2):=(:=,2)⑤算术运算符:使用环境:Windows xp 下的visual c++6.0程序测试: input1 : int a,b;start;( ),.( ; ,5)( (,5)( ),5) ( , ,5)( . ,5)start+- * /( + ,2) ( -,2)( *,2) ( / ,2). a=b+2;input2:while(a>=0)do7x=x+6.7E+23;end;input3:begin:x:=9if x>0 then x:=x+1;while a:=0 dob:=2*x/3,c:=a;end;output1: 3,int 3,a 5,,3,b 5,;3,a2,=3,b2,+4,2 5,; output2:output2:1,while5,(3,a2,>=4,05,)1,doerror line 32,=3,x2,+4,6.7E+235,;1,end5,;output3:output3:1,beginerror line 13,x2,:=4,91,if3,x2,>4,01,then3,x2,:=3,x2,+4,15,;1,while3,a2,:=4,01,do 3,b 2,:= 4,2 2,* 3,x 2,/4,35,,3,c2,:=3,a5,;1,end5,;测试结果与预期结果一致源程序代码:#include<stdio.h>#include<string.h>void main(){int i=0,j,k=0,state=1,f=0,linenum=1;chara[11][10]={"const","var","call","begin","if","while","do","odd","end","then","proc edure"};char b,d[40]={"\0"};freopen("input.txt","r",stdin);freopen("output.txt","w",stdout);b=getchar();while(b!=EOF)/*判断所输入字符是否为结束符*/{if(b==' '||b=='\n'||b=='\t')/*滤过空格、换行等分隔符号*/{ if(b='\n') linenum++;b=getchar();}else if((b>='a'&&b<='z')||(b>='A'&&b<='Z'))/*识别标识符以及保留字*/{d[i++]=b;b=getchar();while((b>='a'&&b<='z')||(b>='A'&&b<='Z')||(b>='0'&&b<='9')){d[i++]=b;b=getchar();}for(j=0;j<11;j++)/*查询保留字表确定该单词是否是保留字*/{ if(strcmp(d,a[j])==0){ printf("1,%s\n",d);k=1;break;}}if(k==0)/*在保留字表中没有查到该单词,是标识符*/printf("3,%s\n",d);for(j=0;j<=i;j++)d[j]='\0';i=0;k=0;}else if(b>='0'&&b<='9')/*识别常数*/{ d[i++]=b;b=getchar();while(f!=1){switch (state) {case 1:if(b>='0'&&b<='9') {state=1;d[i++]=b;b=getchar();}else if(b=='.') { state=2;d[i++]=b;b=getchar();}else if(b=='E') { state=4;d[i++]=b;b=getchar();}else state=7;break;case 2:if(b>='0'&&b<='9') {state=3;d[i++]=b;b=getchar();}else state=8;break;case 3:if(b>='0'&&b<='9') {state=3;d[i++]=b;b=getchar();}else if(b=='E') { state=4;d[i++]=b;b=getchar();}else state=7;break;case 4:if(b=='+'||b=='-') { state=5;d[i++]=b;b=getchar();}else if(b>='0'&&b<='9'){ state=6;d[i++]=b;b=getchar();} else state=8;break;case 5:if(b>='0'&&b<='9'){ state=6;d[i++]=b;b=getchar();}else state=8;break;case 6:if(b>='0'&&b<='9'){ state=6;d[i++]=b;b=getchar();}else state=7;break;case 7: f=1;break;case 8: f=1;break;}}if(state==7&&(b<'a'||b>'z')&&(b<'A'||b>'Z'))printf("4,%s\n",d);else if(state==7&&(b>='a'&&b<='z')||(b>='A'&&b<='Z'))/*数字后接字母的出错控制*/{while((b>='a'&&b<='z')||(b>='A'&&b<='Z')){ d[i++]=b;b=getchar();}printf("error line %d\n",linenum);}else printf("error line %d\n",linenum);for(j=0;j<=i;j++)d[j]='\0';i=0;f=0;state=1;}else if(b=='<')/*识别'<'、'<='和'<>'*/{ d[i++]=b;b=getchar();if(b=='='||b=='>'){ d[i++]=b;b=getchar();printf("2,%s\n",d);for(j=0;j<=i;j++)d[j]='\0';i=0;}else{ printf("2,%s\n",d);for(j=0;j<=i;j++)d[j]='\0';i=0;}}else if(b=='>')/*识别'>'和'>='*/{ d[i++]=b;b=getchar();if(b=='='){ d[i++]=b;b=getchar();printf("2,%s\n",d);for(j=0;j<=i;j++)d[j]='\0';i=0;}else{ printf("2,%s\n",d);for(j=0;j<=i;j++)d[j]='\0';i=0;}}else if(b==':')/*识别':='*/{ d[i++]=b;b=getchar();if(b=='='){ d[i++]=b;b=getchar();printf("2,%s\n",d);}else printf("error line %d\n",linenum);for(j=0;j<=i;j++)d[j]='\0';i=0;}else if(b=='*'||b=='+'||b=='-'||b=='/'||b=='=')/*识别运算符*/{ printf("2,%c\n",b);b=getchar();}else if(b=='('||b==')'||b==','||b==';'||b=='.')/*识别分隔符*/{ printf("5,%c\n",b);b=getchar();}else{ printf("error line %d\n",linenum);b=getchar();}}}实验心得:此次实验让我了解了如何设计、编制并调试词法分析程序,并加深了我对词法分析器原理的理解;熟悉了直接构造词法分析器的方法和相关原理,并学会使用c语言直接编写词法分析器;同时更熟练的掌握用c语言编写程序,实现一定的实际功能。
编译技术班级学号姓名指导老师20xx年 7 月 4 日一、目的编译技术是理论与实践并重的课程,而其实验课要综合运用一、二年级所学的多门课程的内容,用来完成一个小型编译程序。
从而巩固和加强对词法分析、语法分析、语义分析、代码生成和报错处理等理论的认识和理解;培养学生对完整系统的独立分析和设计的能力,进一步培养学生的独立编程能力。
二、任务及要求基本要求:1.词法分析器产生下述小语言的单词序列这个小语言的所有的单词符号,以及它们的种别编码和内部值如下表:单词符号种别编码助记符内码值DIMIFDO STOP END标识符常数(整)=+***,()1234567891011121314$DIM$IF$DO$STOP$END$ID$INT$ASSIGN$PLUS$STAR$POWER$COMMA$LPAR$RPAR------内部字符串标准二进形式------对于这个小语言,有几点重要的限制:首先,所有的关键字(如IF﹑WHILE等)都是“保留字”。
所谓的保留字的意思是,用户不得使用它们作为自己定义的标示符。
例如,下面的写法是绝对禁止的:IF(5)=x其次,由于把关键字作为保留字,故可以把关键字作为一类特殊标示符来处理。
也就是说,对于关键字不专设对应的转换图。
但把它们(及其种别编码)预先安排在一张表格中(此表叫作保留字表)。
当转换图识别出一个标识符时,就去查对这张表,确定它是否为一个关键字。
再次,如果关键字、标识符和常数之间没有确定的运算符或界符作间隔,则必须至少用一个空白符作间隔(此时,空白符不再是完全没有意义的了)。
例如,一个条件语句应写为IF i>0 i= 1;而绝对不要写成IFi>0 i=1;因为对于后者,我们的分析器将无条件地将IFI看成一个标识符。
这个小语言的单词符号的状态转换图,如下图:2.语法分析器能识别由加+ 减- 乘* 除/ 乘方^ 括号()操作数所组成的算术表达式,其文法如下:E→E+T|E-T|TT→T*F|T/F|FF→P^F|Pp→(E)|i使用的算法可以是:预测分析法;递归下降分析法;算符优先分析法;LR分析法等。
编译原理实验—词法分析器一、实验目的通过动手实践,使学生对构造编译系统的基本理论、编译程序的基本结构有更为深入的理解和掌握;使学生掌握编译程序设计的基本方法和步骤;能够设计实现编译系统的重要环节。
同时增强编写和调试程序的能力。
二、实验内容及要求对某特定语言A ,构造其词法规则。
该语言的单词符号包括:保留字(见左下表)、标识符(字母大小写不敏感)、整型常数、界符及运算符(见右下表) 。
功能要求如下所示:·按单词符号出现的顺序,返回二元组序列,并输出。
·出现的标识符存放在标识符表,整型常数存放在常数表,并输出这两个表格。
·如果出现词法错误,报出:错误类型,位置(行,列)。
·处理段注释(/* */),行注释(//)。
·有段注释时仍可以正确指出词法错误位置(行,列)。
三、实验过程1、词法形式化描述使用正则文法进行描述,则可以得到如下的正规式:其中ID表示标识符,NUM表示整型常量,RES表示保留字,DEL表示界符,OPR表示运算符。
A→(ID | NUM | RES | DEL | OPR) *ID→letter(letter | didit)*NUM→digit digit*letter→a | … | z | A | … | Zdigit→ 0 | … | 9RES→ program | begin | end | var | int | and | or | not | if | then | else | while | doDEL→( | ) | . | ; | ,OPR→+ | * | := | > | < | = | >= | <= | <>如果关键字、标识符和常数之间没有确定的算符或界符作间隔,则至少用一个空格作间隔。
空格由空白、制表符和换行符组成。
2、单词种别定义;A语言中的单词符号及其对应的种别编码如下表所示:单词符号种别编码单词符号种别编码3、状态转换图;语言A的词法分析的状态转换图如下所示:空格符,制表符或回车符字母或数字4、java旗舰版5、关键算法的流程图及文字解释;程序中用到的函数列表:A类定义各种类函数以及包含主函数public static void main()变量ch储存当前最新读进的字符的地址strToken存放当前字符串main() //主函数Analysis()//分析函数,每次读入一行文件,进行识别处理;char GetChar(); //取得当前位置的字符的内容放入ch,并提前指向下一个字符;char GetNextChar();//取得当前位置的下一位置的字符,String ConCat(); //将ch指向的字符连接到strToken后面isLetter(); //判断ch指向的字符是否字母isDigit(); //判断ch指向的字符是否数字add(p,str); //向p表中插入当前strToken的字符串Boolean findKeyWord(str); //检测当前strToken中的字符串是否保留字,若是,则执行getKeyWordKey(str),返回保留字的id,否则,判别其是否是已存在的标示符,若是,返回标示符的id以及该标示符在表中的位置;findPunctuation()//判断是否是一个保留的符号;getindex() //返回已经识别的标示符或者是数字的位置下标;Boolean exist(); //检测当前strToken中的字符串是否在标识符表中已存在,若是,则返回true,否则返回falsevoid callError(); //出错处理过程,将错误的位置报告出来(1)main()函数的流程图如下:)具体分析流程图:开始类初始化,变量的初始化,准备执行main()函数调用Analyse()函数分析输出结果表结束Analyse(str)函数读取第一个字符赋给变量Ch继续判读IndexoutofBound6、测试报告(测试用例,测试结果);首先输入一个不含错误的程序(两种注释)进行检测:运行后在控制台上得到的结果如下所示:得到的二元组序列如下:经检验,输出的是正确的二元组序列。
词法分析程序设计一.问题描述1.可以识别出用C语言编写的源程序中的每个单词符号,并以记号的形式输出每个单词符号。
2.可以并识别读取源程序中的注释。
3.可以统计源程序中的语句行数、单词个数和字符数,其中标点和空格不计为单词,并输出统计结果。
4.检察源程序中存在的错误,并可以报告错误所在行列的位置。
5.发现原程序中存在的错误,进行适当修复,使词法分析可以继续进行,通过一次词法分析处理,可以检查并报告源程序中存在的所有错误。
二.算法思想编写一个词法分析程序,它从左到右逐个字符的对源程序进行扫描,产生一个个的单词形成记号流文件输出。
其中,具体子问题有:(1)源程序文件读入缓冲区中(注意要删除空格和无用符号)(2)确定读入的为关键字还是运算符还是变量名,对于普通标识符和常量,分别建立标识符表和常量表当遇到一个标识符或常量时,查找标识符表或常量表,若存在,则返回位置,否则进入符号表或常量表中并返回表的入口地址。
(3)对于各类运算符、标点符号、以及注释符号等,准确识别出来并打印输出结果(4)对于源文件中出现的数字常量,不但能按要求加入常量表中,还进行了字符型到float型数值的转换,便于后续程序操作处理。
(4)尽量精简整合各种情况,使算法复杂度降低,精简易读。
三、实验程序设计说明1.主要函数说明void readChar();//读字符过程,每调用一次,从输入缓冲区读一个字符,并把它放入变量C 中,且向前扫描指针pointer指向下一个字符void ignoreSpace();//每次调用时,检查C中的字符是否为空字符,若是,则反复调用该过程,直到C进入一个非空字符为止void link();//把C中的字符与token中的字符串连接起来bool alphabet();//布尔函数,判断C中的字符是否为字母,若是则返回true,否则返回false bool digit();//布尔函数,判断C中的字符是否为数字,若是则返回true,否则返回false int searchForKeywords();//查关键字表,若此函数的返回值为0,则表示token中的字符串是标识符,否则为关键字int searchForToken();//查符号表,若此函数的返回值为0,则表示token中的字符串是新出现的,否则为已出现过的标识符int searchForNum(); //查常数表,若此函数的返回值为0,则表示token中的数字是新出现的,否则为已出现的常数void insertTokenList();//将标识符插入符号表void insertNumList();//将数字插入常数表void fillBuffer(int a);//填充buff的半区函数2.程序源代码#include<stdio.h>#include<stdlib.h>#include<string.h>#include<math.h>int pointer=0;//int i=0,j=0,c=0,appear,d=0,num_location;//int row_num=0,letter_num=0,word_num=0;int z=1;char C=' ';//char token[30];//char buff[4095];//char token_list[200][30];//char number[200][10];//char next_charac,charac,file_name[20];charkeywords[32][10]={"auto","break","case","char","const","continue","default","do","d ouble","else","enum","extern","float","for","goto","if","int","long","register","re turn","short","signed","sizeo","fstatic","struct","switch","typedef","union","unsig ned","void","volatile","while"};double num;FILE *file_pointer;void fillBuffer(int a)//{//i=0;while((!feof(file_pointer))&& i<2048){//buff[a+i]=charac;if(charac!=' '){//if(charac=='\n'){row_num++;//}else{letter_num++;}}charac=fgetc(file_pointer);i++;}if(feof(file_pointer)){buff[a+i]='\0';}};void readChar()//{C=buff[pointer];if(pointer==1023){//fillBuffer(1024);//pointer++;//}else if(pointer==2047){//fillBuffer(0);//pointer==0;//}else{pointer++;}};void ignoreSpace()//{if(C==' '||C=='\n'||C=='\t'){ C=buff[pointer];if(pointer==1023){//fillBuffer(1024);// pointer++;//}else if(pointer==2047){// fillBuffer(0);//pointer=0;//}else{pointer++;}ignoreSpace();}};void link()//{token[j++]=C;};bool alphabet()//{if((C>=97 && C<=122)||(C>=65 && C<=90)){ return true;}else{return false;}};bool digit()//{if(C>=48 && C<=57){return true;}else{return false;}};int searchForKeywords()//{for(int x=0;x<32;x++){if(strcmp(token,keywords[x])==0){return 0;//}}return 1;};int searchForToken()//{int i=0;while(i<=c-1){if(strcmp(token,token_list[i])==0){ appear=i;return 0;}//i++;}word_num++;return 1;};int searchForNum()//{int i=0;while(i<=d-1){if(strcmp(token,number[i])==0){num_location=i;return 0;}//i++;}word_num++;return 1;};void insertTokenList()//{strcpy(token_list[c++],token);};void insertNumList()//{strcpy(number[d++],token);};main(){printf("输入源文件的路径:\n");scanf("%s",file_name);file_pointer=fopen(file_name,"r");if(file_pointer==NULL) printf("无法查找到文件,发生错误!\n");//charac=fgetc(file_pointer);fillBuffer(0);//while(C!='\0'){readChar();//ignoreSpace();//switch(C){//case 65:case 66:case 67:case 68:case 69:case 70:case 71:case 72: case 73:case 74:case 75:case 76:case 77:case 78:case 79:case 80:case 81:case 82:case 83:case 84:case 85:case 86:case 87:case 88:case 89:case 90:case 97: case98:case99:case 100:case 101:case102:case 103:case104:case 105:case 106: case 107:case 108:case 109:case 110:case 111:case 112:case 113:case 114:case 115:case 116:case 117:case 118:case 119:case 120:case 121:case 122:case'_'://ǰזΪזĸʽז ϟwhile(alphabet()||digit()||C=='_'){//link();//readChar();//}//token[j]='\0';//j=0;//pointer--;//if(searchForKeywords()==1){//if(searchForToken()==1){//insertTokenList();//printf("< ID, %d >\n",c-1);}else{printf("< ID, %d >\n",appear);}//}else{ז >\n",token);//printf("< %s, ؼ}break;case 48:case 49:case 50:case 51:case 52:case 53:case 54:case 55:case 56:case 57: num=(C-48);link();readChar();while(digit()){link();num=num*10+(C-48);//readChar();}if(C=='.'){link();readChar();while(digit()){link();num=num+(C-48)*pow(0.1,z++);// readChar();}}token[j]='\0';//j=0;//pointer--;if(searchForNum()==1){//insertNumList();//printf("< %f, %d >\n",num,d-1);}else{printf("< %f, %d >\n",num,num_location);}//break;case '+':readChar();if(C=='='){printf("< +=, 赋值运算符 >\n");}else if(C=='+'){printf("< ++, 自加>\n");}else{pointer--;printf("< +, 加号 >\n");}break;case '-':readChar();if(C=='-'){printf("< --, 自减>");}else if(C=='='){printf("< -= , 赋值运算符>\n");}else{pointer--;printf("< -, 减号 >\n");}break;case '*':printf("< *, 乘号 >\n");break;case '/':readChar();if(C=='*'){readChar();next_charac=buff[pointer];while(C!='*' && next_charac!='/'){readChar();next_charac=buff[pointer];}readChar();printf("< /*, 多行注释 >\n");}else if(C=='/'){readChar();while(C!='\n'){readChar();}printf("< //, 单行注释 >\n");}else{pointer--;printf("< /, 除号 >\n");}break;case '%':printf("< %, 取模 >\n");break;case '(':printf("< (, 左小括号 >\n");break;case ')':printf("< ), 右小括号 >\n");break;case '[':printf("< [, 左中括号 >\n");break;case ']':printf("< ], 右中括号 >\n");break;case '{':printf("< {, -左大括号 >\n");break;case '}':printf("< }, 右大括号 >\n");break;case ':':printf("< :, 冒号 >\n");break;case ';':printf("< ;, 分号 >\n");break;case ',':printf("< , 逗号 >\n");break;case '.':printf("< ., 句号 >\n");break;case '?':printf("< ?, 问号 >\n");break;case '"':printf("< "", 引号 >\n");break;case '#':printf("< #, 井号 >\n");break;case '>':readChar();if(C=='='){printf("< >=, 大于等于 >\n");}pointer--;printf("< >, 大于 >\n");}break;case '<':readChar();if(C=='='){printf("< <=, 小于等于 >\n");}else{pointer--;printf("< <, 小于 >\n");}break;case '=':readChar();if(C=='='){printf("< ==, 判等 >\n");}else{pointer--;printf("< =, 赋值等 >\n");}break;case '&':readChar();if(C=='&'){printf("< &&, 且 >\n");}else{pointer--;printf("< &, 取地址符 >\n");}break;case '|':readChar();if(C=='|'){printf("< ||, 或 >\n");}else{pointer--;printf("< |, 运算符 >\n");}case '!':readChar();if(C=='='){printf("< !=, 不等 >\n");}else{pointer--;printf("< !, 非 >\n");}break;}}printf("该源文件的行数为:%d,单词数为%d,字符数为%d.\n",row_num,word_num,letter_num);system("pause");return 0;}3.程序的执行结果测试程序为:运行结果为:四、有待改进的地方。