数学建模方法回归分析共52页文档
- 格式:ppt
- 大小:1.40 MB
- 文档页数:26




什么就是回归分析回归分析(regression analysis)就是确定两种或两种以上变数间相互依赖的定量关系的一种统计分析方法。
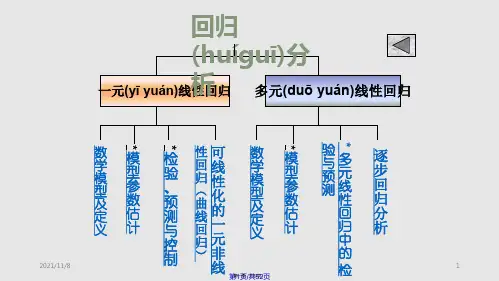
运用十分广泛,回归分析按照涉及的自变量的多少,可分为一元回归分析与多元回归分析;按照自变量与因变量之间的关系类型,可分为线性回归分析与非线性回归分析。
如果在回归分析中,只包括一个自变量与一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。
如果回归分析中包括两个或两个以上的自变量,且因变量与自变量之间就是线性关系,则称为多元线性回归分析。
回归分析之一多元线性回归模型案例解析多元线性回归,主要就是研究一个因变量与多个自变量之间的相关关系,跟一元回归原理差不多,区别在于影响因素(自变量)更多些而已,例如:一元线性回归方程为:毫无疑问,多元线性回归方程应该为:上图中的x1, x2, xp分别代表“自变量”Xp截止,代表有P个自变量,如果有“N组样本,那么这个多元线性回归,将会组成一个矩阵,如下图所示:那么,多元线性回归方程矩阵形式为:其中:代表随机误差, 其中随机误差分为:可解释的误差与不可解释的误差,随机误差必须满足以下四个条件,多元线性方程才有意义(一元线性方程也一样)1:服成正太分布,即指:随机误差必须就是服成正太分别的随机变量。
2:无偏性假设,即指:期望值为03:同共方差性假设,即指,所有的随机误差变量方差都相等4:独立性假设,即指:所有的随机误差变量都相互独立,可以用协方差解释。
今天跟大家一起讨论一下,SPSS---多元线性回归的具体操作过程,下面以教程教程数据为例,分析汽车特征与汽车销售量之间的关系。
通过分析汽车特征跟汽车销售量的关系,建立拟合多元线性回归模型。
数据如下图所示:(数据可以先用excel建立再通过spss打开)点击“分析”——回归——线性——进入如下图所示的界面:将“销售量”作为“因变量”拖入因变量框内, 将“车长,车宽,耗油率,车净重等10个自变量拖入自变量框内,如上图所示,在“方法”旁边,选择“逐步”,当然,您也可以选择其它的方式,如果您选择“进入”默认的方式,在分析结果中,将会得到如下图所示的结果:(所有的自变量,都会强行进入)如果您选择“逐步”这个方法,将会得到如下图所示的结果:(将会根据预先设定的“F统计量的概率值进行筛选,最先进入回归方程的“自变量”应该就是跟“因变量”关系最为密切,贡献最大的,如下图可以瞧出,车的价格与车轴跟因变量关系最为密切,符合判断条件的概率值必须小于0、05,当概率值大于等于0、1时将会被剔除)“选择变量(E)" 框内,我并没有输入数据,如果您需要对某个“自变量”进行条件筛选,可以将那个自变量,移入“选择变量框”内,有一个前提就就是:该变量从未在另一个目标列表中出现!,再点击“规则”设定相应的“筛选条件”即可,如下图所示:点击“统计量”弹出如下所示的框,如下所示:在“回归系数”下面勾选“估计,在右侧勾选”模型拟合度“与”共线性诊断“两个选项,再勾选“个案诊断”再点击“离群值”一般默认值为“3”,(设定异常值的依据,只有当残差超过3倍标准差的观测才会被当做异常值) 点击继续。



回归分析在数学建模中的应用回归分析是一种统计分析方法,用于研究自变量和因变量之间的关系。
它可以用于在数学建模中预测和解释变量之间的关系。
在本文中,我将讨论回归分析在数学建模中的应用以及其在解决实际问题中的重要性。
回归分析有两种主要类型:简单线性回归和多元线性回归。
简单线性回归是指只有一个自变量和一个因变量之间的关系,而多元线性回归是指有多个自变量和一个因变量之间的关系。
无论是简单线性回归还是多元线性回归,都可以用于预测和解释变量之间的关系。
在数学建模中,回归分析可以用于预测未知值。
通过分析一组已知的自变量和因变量之间的关系,可以建立一个数学模型,以便预测因变量的值。
这种预测能力可以在许多领域中得到应用,例如经济学、金融学、社会科学等。
举一个简单的例子,假设我们要建立一个模型来预测一个人的身高。
我们可以收集一组数据,包括自变量(例如年龄、性别、父母身高等)和因变量(身高)。
然后,我们可以使用回归分析来建立一个模型,以便根据给定的自变量来预测一个人的身高。
此外,回归分析还可以用来解释变量之间的关系。
通过分析已知的自变量和因变量之间的关系,可以得出结论,了解自变量对因变量的影响程度。
这对于解决实际问题非常重要。
例如,在经济学中,回归分析可以用来解释消费者支出与收入之间的关系。
通过分析已知的收入和消费者支出数据,可以得出结论,了解收入对消费者支出的影响程度。
这有助于制定经济政策和预测市场需求。
回归分析还可以用来评估自变量之间的相互作用。
在多元线性回归中,我们可以引入交互项,以考虑自变量之间的相互影响。
通过分析已知的自变量和因变量之间的关系,可以确定自变量之间的相互作用,并加以解释。
总的来说,回归分析在数学建模中有广泛的应用。
它可以用于预测和解释变量之间的关系,评估自变量之间的相互作用,解释因变量的变化程度,并评估模型的拟合程度。
回归分析在解决实际问题中起着重要的作用,帮助我们从数据中提取有价值的信息,并进行合理的预测和解释。



-141-第十二章 回归分析前面我们讲过曲线拟合问题。
曲线拟合问题的特点是,根据得到的若干有关变量的一组数据,寻找因变量与(一个或几个)自变量之间的一个函数,使这个函数对那组数据拟合得最好。
通常,函数的形式可以由经验、先验知识或对数据的直观观察决定,要作的工作是由数据用最小二乘法计算函数中的待定系数。
从计算的角度看,问题似乎已经完全解决了,还有进一步研究的必要吗?从数理统计的观点看,这里涉及的都是随机变量,我们根据一个样本计算出的那些系数,只是它们的一个(点)估计,应该对它们作区间估计或假设检验,如果置信区间太大,甚至包含了零点,那么系数的估计值是没有多大意义的。
另外也可以用方差分析方法对模型的误差进行分析,对拟合的优劣给出评价。
简单地说,回归分析就是对拟合问题作的统计分析。
具体地说,回归分析在一组数据的基础上研究这样几个问题:(i )建立因变量y 与自变量m x x x ,,,21 之间的回归模型(经验公式); (ii )对回归模型的可信度进行检验;(iii )判断每个自变量),,2,1(m i x i =对y 的影响是否显著;(iv )诊断回归模型是否适合这组数据;(v )利用回归模型对y 进行预报或控制。
§1 多元线性回归回归分析中最简单的形式是x y 10ββ+=,y x ,均为标量,10,ββ为回归系数,称一元线性回归。
它的一个自然推广是x 为多元变量,形如m m x x y βββ+++= 110 (1)2≥m ,或者更一般地)()(110x f x f y m m βββ+++= (2)其中),,(1m x x x =,),,1(m j f j =是已知函数。
这里y 对回归系数),,,(10m ββββ =是线性的,称为多元线性回归。
不难看出,对自变量x 作变量代换,就可将(2)化为(1)的形式,所以下面以(1)为多元线性回归的标准型。
1.1 模型在回归分析中自变量),,,(21m x x x x =是影响因变量y 的主要因素,是人们能控制或能观察的,而y 还受到随机因素的干扰,可以合理地假设这种干扰服从零均值的正态分布,于是模型记作⎩⎨⎧++++=),0(~2110σεεβββN x x y m m (3) 其中σ未知。
1、 多元线性回归在回归分析中,如果有两个或两个以上的自变量,就称为多元回归。
事实上,一种现象常常是与多个因素相联系的,由多个自变量的最优组合共同来预测或估计因变量,比只用一个自变量进行预测或估计更有效,更符合实际。
在实际经济问题中,一个变量往往受到多个变量的影响。
例如,家庭消费支出,除了受家庭可支配收入的影响外,还受诸如家庭所有的财富、物价水平、金融机构存款利息等多种因素的影响,表现在线性回归模型中的解释变量有多个。
这样的模型被称为多元线性回归模型。
(multivariable linear regression model )多元线性回归模型的一般形式为:其中k 为解释变量的数目,j β(j=1,2,…,k)称为回归系数(regression coefficient)。
上式也被称为总体回归函数的随机表达式。
它的非随机表达式为:j β也被称为偏回归系数(partial regression coefficient)。
2、 多元线性回归计算模型多元性回归模型的参数估计,同一元线性回归方程一样,也是在要求误差平方和(Σe)为最小的前提下,用最小二乘法或最大似然估计法求解参数。
设(11x ,12x ,…,1px ,1y ),…,(1n x ,2n x ,…,npx ,ny )是一个样本,用最大似然估计法估计参数:达到最小。
把(4)式化简可得:引入矩阵:方程组(5)可以化简得:可得最大似然估计值:3、Matlab 多元线性回归的实现多元线性回归在Matlab 中主要实现方法如下:(1)b=regress(Y, X ) 确定回归系数的点估计值其中(2)[b,bint,r,rint,stats]=regress(Y,X,alpha)求回归系数的点估计和区间估计、并检验回归模型①bint 表示回归系数的区间估计.②r 表示残差③rint 表示置信区间④stats 表示用于检验回归模型的统计量,有三个数值:相关系数r2、F 值、与F 对应的概率p说明:相关系数r2越接近1,说明回归方程越显著;F>F1-alpha(p,n-p-1) 时拒绝H0,F越大,说明回归方程越显著;与F 对应的概率p<α 时拒绝H0,回归模型成立。
回归分析1、有十个同类企业生产性固定资产年平均价值和工业总产值资料如下:1、说明两变量之间的相关方向;2、建立直线回归方程3、计算估计标准误差4、估计生产型固定资产(自变量)为1100万元是总产值(因变量)的可能值:解:1、自变量:生产型固定资产价值因变量:工业总产值2、(1)散点图x=[318 910 200 409 415 502 314 1210 1022 1225];>> y=[524 1019 638 815 913 928 605 1516 1219 1624];>> plot(x,y,'or')>> xlabel('生产型固定资产价值')>> ylabel('工业总产值')>>(2)方程x=[318 910 200 409 415 502 314 1210 1022 1225]; y=[524 1019 638 815 913 928 605 1516 1219 1624]; >> X=[ones(size(x))',x'];>> [b,bint,r,rint,stats]=regress(y',X);>> b,bint,statsb =395.56700.8958bint =210.4845 580.64950.6500 1.1417stats =1.0e+004 *0.0001 0.0071 0.0000 1.6035y=395.5670+0.8958 x有上面的结果看到R^2=1,F=71,显著性水平为0。
3、使用SPSS可以观察到:标准估计误差是186.78690万元4、又第二问中可以看到,bint的就是方程系数的置信区间,也就是可能取值。
所以:y1=210.4845+0.6500*x;y2=580.6495+1.1417*x;y=395.5670+0.8958*x;所以:x=1100y1=210.4845+0.6500*xy2=580.6495+1.1417*xy=395.5670+0.8958*xx =1100y1 =925.4845y2 =1.8365e+003y =1.3809e+003也就是说当X=1100万元时,Y的可能取值在925.4845到13809.9之间。