【免费下载】对数正态分布log normal distribution
- 格式:pdf
- 大小:353.48 KB
- 文档页数:5




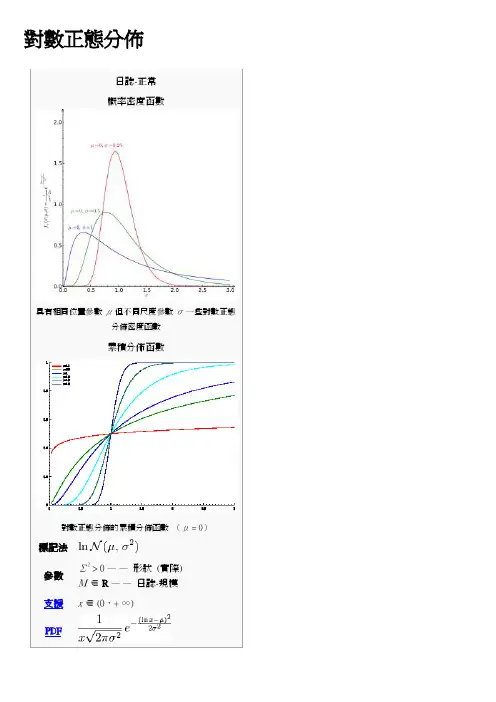
對數正態分佈概率密度函數具有相同位置參數μ但不同尺度參數σ一些對數正態分佈密度函數累積分佈函數對數正態分佈的累積分佈函數(μ = 0)在概率理論,對數正態分佈是連續概率分佈的隨機變數的對數是通常的分散式。
如果X 是一個隨機變數與一個正常的分佈,然後Y = exp (X ) 具有對數正態分佈 ;同樣,如果Y 是日誌通常分佈,然後X = (Y ) 日誌已正常分配。
一個隨機變數,日誌通常分發需要只有正面的真正價值。
日誌正常也會寫入日誌正常或對數。
法蘭西斯 · 高爾頓後的角度來看分佈可能偶爾提到的高爾頓分佈或高爾頓的分佈,作為。
[1]日誌正常分配也已經與其他的名稱,例如,麥卡利斯特、 Gibrat 和Cobb –Douglas 相關聯。
[1]可能作為日誌正常建模變數,如果它可以被看作乘法的產品很多獨立的隨機變數每個其中是積極。
(這被辯解通過考慮中日誌域的中心極限定理)例如,在金融領域,該變數可以表示複合返回從一個序列的多個行業 (每個表示,它的回歸 + 1) ;或者可以從產品的短期折扣因素派生一個長期折扣係數。
在無線通訊中,造成的陰影或緩慢衰落從隨機物件的 sas 常常假定日誌通常分發: 請參見日誌-距離路徑損失模型.對數正態分佈是最大熵概率分佈的隨機變數X 的帄均值和方差的固定的。
[2]內容[隱藏]∙ 1 Μ和σ∙2 表徵o 2.1 概率密度函數o2.2 累積分佈函數o 2.3 、 特徵函數及母函數的時刻∙3 屬性o3.1 位置及規模▪ 3.1.1 幾何的時刻▪3.1.2 算術的時刻o 3.2 模式和中位數 o 3.3 變異係數o 3.4 局部期望o3.5 其他∙ 4 發生∙ 5 最大似然估計的參數 ∙6 多元日誌-正常代表是漸近的分歧,但不足為數值的目的資∙7 生成日誌通常分佈隨機變數∙8 相關的分佈∙9 相似的發行∙10 又見∙11 筆記∙12 引用∙13 進一步閱讀∙14 外部連結[編輯] Μ和σ在對數正態分佈X,參數來表示μ和σ分別是,意思是和變數的自然對數的標準差(根據定義,該變數的對數通常分發),這意味著與Z標準正態變數。


偏态分布十大模型在统计学和概率论中,偏态分布是指数据的分布具有不对称性的特征。
而偏态分布的模型则是用来描述这种特点的数学表达式或函数。
下面是十个常见的偏态分布模型:1. 正态分布(Normal Distribution)- 正态分布是一个非常重要的偏态分布模型,也叫钟形曲线。
- 以均值和标准差为参数,可以用来描述许多自然现象和随机变量的分布。
2. 偏态正态分布(Skewed Normal Distribution)- 偏态正态分布是正态分布的一个变种,具有稍微向左或向右倾斜的特征。
- 可以通过调整参数来控制分布的偏斜程度。
3. 威布尔分布(Weibull Distribution)- 威布尔分布是描述可靠性或生存分析中的时间数据的偏态分布模型。
- 适用于描述正向偏斜(右偏)或负向偏斜(左偏)的数据。
4. 指数分布(Exponential Distribution)- 指数分布是描述事件发生时间间隔的偏态分布模型。
- 适用于描绘无记忆性随机事件的发生时间分布。
5. 拉普拉斯分布(Laplace Distribution)- 拉普拉斯分布是一个两个峰值的分布模型,具有较长的尾部。
- 适用于描述数据中存在离群值或异常值的情况。
6. 泊松分布(Poisson Distribution)- 泊松分布是描述稀有事件发生次数的偏态分布模型。
- 适用于描述单位时间或单位面积内事件发生的频率。
7. 伽玛分布(Gamma Distribution)- 伽玛分布是描述连续随机变量的偏态分布模型,具有不对称性。
- 适用于描述持续时间、等待时间或其他正倾斜数据的分布。
8. 负二项分布(Negative Binomial Distribution)- 负二项分布是描述在二项分布试验中进行一系列独立试验所需的次数的偏态分布模型。
- 适用于描述在成功次数未知的情况下,达到指定数量成功所需的试验次数。
9. 对数正态分布(Lognormal Distribution)- 对数正态分布是描述一个变量的对数值的偏态分布模型。

16种常见概率分布概率密度函数意义及其应用1. 常数分布(Constant distribution):概率密度函数(Probability Density Function,PDF)为常数,表示特定区间内的概率相等。
这种分布常用于模拟实验或作为基线分布进行比较。
2. 均匀分布(Uniform distribution):概率密度函数为一个常数,表示在特定区间内的各个取值的概率相等。
均匀分布经常用于随机抽样,以确保样本的代表性。
3. 二项分布(Binomial distribution):概率密度函数描述了进行n次独立二类试验中成功次数的概率分布。
二项分布在实验设计、质量控制和市场研究中广泛应用。
4. 泊松分布(Poisson distribution):5. 正态分布(Normal distribution):概率密度函数为指数函数形式,常用来描述自然界中众多连续变量的分布,例如身高、体重等。
正态分布在统计学和金融学中广泛应用。
6. χ2分布(Chi-square distribution):概率密度函数描述了n个独立标准正态分布随机变量的平方和的分布,是假设检验和方差分析中常用的分布。
7. t分布(t-distribution):概率密度函数描述了标准正态分布随机变量与一个自由度为n的卡方分布随机变量的比值的分布。
t分布在小样本推断和回归分析中常用。
8. F分布(F-distribution):概率密度函数描述了两个自由度为m和n的卡方分布随机变量的比值的分布。
F分布在方差分析、回归分析和信号处理中常应用。
9. 负二项分布(Negative binomial distribution):概率密度函数描述了进行一系列独立二类试验中直到第r次取得第k 次成功的概率。
负二项分布在可靠性工程和传染病模型中常用。
10. 伽马分布(Gamma distribution):概率密度函数描述了多个指数分布随机变量的和的分布,常被用于描述连续事件的时间间隔。



对数正态分布lognormaldistribution为了⽅便后⾯的描述,我们先定义正态分布的两个参数为:均值mean表⽰为µN, 标准差standard deviation 表⽰为σN(对应⽅差Variance 表⽰为σ2N)。
为了区分,我们⽤m和v分别表⽰对数正态分布的均值和⽅差, 他们与其对应的正太分布的关系如下:lognormal均值: m LogN=eµN+σ2N/2;lognormal⽅差: v LogN=(eσ2N−1)e2µN+σ2N.另外:lognormal 众数(mode) = eµN−σ2N;lognormal 中位数(median) = eµN.⽣成符合lognromal distribution 的随机数(n个数),⽆论是Python还是Matlab, 都利⽤µN和σN来⽣成对数正态分布随机数:1. Python (numpy)import numpy as npy0 = np.random.lognormal(mu_N, sigma_N, n)⽰例:我们取µN=0.5,σN=0.5, n=10000, 执⾏并画出Python⽣成的随机数histogram (bin数量取50)如下:2. Matlab%% method 1: build-in matlab makedist functionpd = makedist('Lognormal', 'mu' ,mu_N,'sigma',sigma_N);rng('default'); % For reproducibilityy1 = random(pd,n,1);% logx = log(y1); %logx distributed as normal distribution with mu and sigma% mean(logx); % 可以验证为 mu_N%% method 2: build-in matlab lognrnd functionrng('default'); % For reproducibilityy2 = lognrnd(mu_N, sigma_N, [n,1]);%% method 3: from normal distriutionrng('default'); % For reproducibilityz = randn([n,1]); %standard normalx = mu_N + sigma_N.*z;% x follows normal distribution N(mu_N, sigma_N)y3 = exp(x); % y follows lognormal distribution⽰例:我们取µN=0.5,σN=0.5, n=10000, 执⾏并画出Matlab⽣成的随机数histogram (bin数量取50)如下:Processing math: 100%。
对数正态分布对数正态分布机率密度函数μ=0累积分布函数μ=0参数值域概率密度函数累积分布函数期望值中位数eμ众数方差偏态峰态熵值动差生成函数(参见原始动差文本)特征函数isasymptotically divergent but sufficientfor numerical purposes在概率论与统计学中,对数正态分布是对数为正态分布的任意随机变量的概率分布。
如果X 是正态分布的随机变量,则exp(X) 为对数分布;同样,如果Y是对数正态分布,则 ln(Y) 为正态分布。
如果一个变量可以看作是许多很小独立因子的乘积,则这个变量可以看作是对数正态分布。
一个典型的例子是股票投资的长期收益率,它可以看作是每天收益率的乘积。
对于x > 0,对数正态分布的概率分布函数为其中μ与σ分别是变量对数的平均值与标准差。
它的期望值是方差为给定期望值与标准差,也可以用这个关系求μ与σ目录[隐藏]∙ 1 与几何平均值和几何标准差的关系∙ 2 矩∙ 3 局部期望∙ 4 参数的最大似然估计∙ 5 相关分布∙ 6 进一步的阅读资料∙7 参考文献∙8 参见[编辑]与几何平均值和几何标准差的关系对数正态分布、几何平均数与几何标准差是相互关联的。
在这种情况下,几何平均值等于exp(μ),几何平均差等于 exp(σ)。
如果采样数据来自于对数正态分布,则几何平均值与几何标准差可以用于估计置信区间,就像用算术平均数与标准差估计正态分布的置信区间一样。
其中几何平均数μgeo = exp(μ),几何标准差σgeo = exp(σ)[编辑]矩原始矩为:或者更为一般的矩[编辑]局部期望随机变量X在阈值k上的局部期望定义为其中f(x) 是概率密度。
对于对数正态概率密度,这个定义可以表示为其中Φ是标准正态部分的累积分布函数。
对数正态分布的局部期望在保险业及经济领域都有应用。
[编辑]参数的最大似然估计为了确定对数正态分布参数μ与σ的最大似然估计,我们可以采用与正态分布参数最大似然估计同样的方法。