第二章回归分析中的几个基本概念
- 格式:doc
- 大小:376.00 KB
- 文档页数:11


回归分析法概念及原理回归分析法是一种统计方法,用于探究自变量和因变量之间的关系。
通过建立一个数学模型,回归分析可以预测和研究变量之间的相关性。
回归分析法的原理是通过最小化预测值和实际值之间的差异,找到自变量与因变量之间的最佳拟合线。
回归分析法的基本概念包括自变量、因变量、回归方程和残差。
自变量是研究者控制或选择的变量,用于解释因变量的变化。
因变量是研究者感兴趣的变量,被自变量所影响。
回归方程是用来描述自变量和因变量之间关系的数学方程,通常采用线性或非线性形式。
残差是指回归模型中预测值与实际值之间的差异。
回归分析法的原理是通过最小二乘法来确定回归方程的系数,以使残差的平方和达到最小值。
最小二乘法的核心思想是使得回归方程的预测值与实际值之间的误差最小化。
具体来说,就是通过计算残差平方和的最小值,来找到最适合数据的回归方程。
在进行回归分析时,需要进行模型的选择、拟合和检验。
模型的选择通常基于理论、经验和数据。
拟合模型时,需要估计回归方程中的系数,通常采用最小二乘法进行估计。
检验模型时,需要检验回归方程的显著性和拟合优度。
回归分析法可以分为简单线性回归和多元回归。
简单线性回归是指只有一个自变量和一个因变量的情况,多元回归是指有多个自变量和一个因变量的情况。
多元回归可以有不同的形式,如线性回归、非线性回归和多项式回归等。
回归分析法的应用广泛,可以用于预测、解释和控制变量。
例如,在经济学中,回归分析可以用于预测消费者支出;在医学研究中,可以用于解释药物对疾病的治疗效果;在市场营销中,可以用于控制广告投入对销售额的影响。
总之,回归分析法是一种统计方法,通过建立数学模型来研究自变量和因变量之间的关系。
它的原理是通过最小化预测值与实际值之间的差异,来找到最佳拟合线。
回归分析法可以应用于各个领域,用于预测、解释和控制变量。

回归分析的基本概念与应用回归分析是一种重要的统计方法,用于研究两个或多个变量之间的关系。
它可以帮助我们理解和预测变量之间的因果关系,并进行相应的预测分析。
本文将介绍回归分析的基本概念和应用,并探讨其在实际问题中的应用。
一、回归分析的基本概念1.1 变量在回归分析中,我们需要研究的对象通常称为变量。
变量可以是因变量(被解释变量)或自变量(解释变量)。
因变量是我们希望解释或预测的变量,自变量是我们用来解释或预测因变量的变量。
1.2 简单线性回归简单线性回归是回归分析中最简单的一种情况,它研究的是两个变量之间的线性关系。
在简单线性回归中,我们假设因变量和自变量之间存在一个线性关系,并通过最小二乘法来拟合一条直线,以最好地描述这种关系。
1.3 多元回归多元回归是回归分析中更为复杂的情况,它研究的是多个自变量对因变量的影响。
在多元回归中,我们可以考虑多个自变量对因变量的影响,并建立一个多元回归模型来预测因变量。
二、回归分析的应用2.1 经济学中的应用回归分析在经济学中有着广泛的应用。
例如,我们可以利用回归分析来研究商品价格与销量之间的关系,从而优化定价策略。
另外,回归分析还可以用于分析经济增长与就业率之间的关系,为制定宏观经济政策提供依据。
2.2 医学研究中的应用回归分析在医学研究中也有着重要的应用。
例如,研究人员可以利用回归分析来探索某种药物对疾病的治疗效果,并预测患者的生存率。
此外,回归分析还可以用于分析不同因素对心脏病发作风险的影响,为预防和治疗心脏病提供科学依据。
2.3 营销策划中的应用回归分析在营销策划中也有着广泛的应用。
例如,我们可以利用回归分析来分析广告投入与销售额之间的关系,从而优化广告投放策略。
此外,回归分析还可以用于研究消费者行为和购买决策等问题,为制定更有效的市场营销策略提供指导。
三、回归分析的局限性尽管回归分析在实际问题中有着广泛的应用,但也存在一些局限性。
首先,回归分析基于变量之间的线性关系假设,对于非线性关系的研究需要采用其他方法。

回归分析的基本概念与应用回归分析是一种常用的统计方法,用于研究两个或多个变量之间的关系。
它通过建立一个数学模型来描述因变量与自变量之间的关系,并利用样本数据对模型进行估计和推断。
回归分析可以帮助我们理解变量之间的影响关系,预测未来的观测值,以及对因素的调控进行优化。
本文将介绍回归分析的基本概念和应用,以帮助读者更好地理解和运用这一方法。
一、简介回归分析是统计学中的一种常用方法,它通过建立数学模型来描述因变量与自变量之间的关系。
因变量是研究者感兴趣的变量,也是我们希望解释和预测的主要对象;自变量是可能对因变量产生影响的变量,也是我们用来解释因变量的主要因素。
回归分析的目标是确定这种关系,并利用样本数据对模型进行估计和推断。
二、回归方程与模型在回归分析中,我们通常采用线性回归模型来描述因变量与自变量之间的关系。
线性回归模型可以表示为:Y = β0 + β1X1 + β2X2 + ... + βkXk + ε其中,Y表示因变量,X1、X2、...、Xk表示自变量,β0、β1、β2、...、βk表示回归系数,ε表示误差项。
回归方程将自变量的线性组合与因变量建立起联系,并通过回归系数来度量自变量对因变量的影响。
三、回归分析的基本步骤1. 数据收集:收集自变量和因变量的样本数据,确保数据的准确性和完整性。
2. 模型设定:根据研究目的和理论背景,选择适当的自变量,并设定回归模型的形式。
3. 模型估计:利用样本数据,通过最小二乘法或最大似然法等方法,估计回归模型的参数。
4. 模型检验:对估计的回归模型进行显著性检验,判断模型是否能够较好地拟合样本数据。
5. 模型诊断:对回归模型的残差进行分析,检验模型的假设条件是否满足。
6. 模型应用:利用已建立的回归模型进行因变量的预测和自变量的优化。
四、回归分析的应用领域回归分析在各个学科领域都有广泛的应用,以下是几个常见领域的具体应用举例:1. 经济学:回归分析被广泛用于经济学领域,用于解释经济变量之间的关系,如GDP与消费支出、利率与投资之间的关系等。


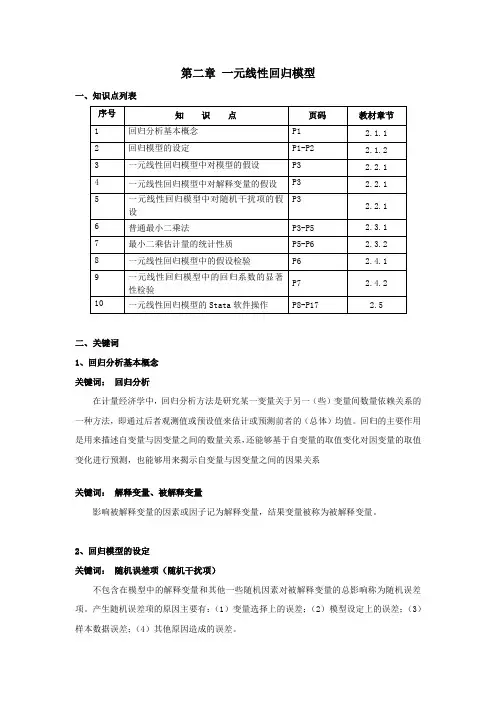
第二章一元线性回归模型一、知识点列表二、关键词1、回归分析基本概念关键词:回归分析在计量经济学中,回归分析方法是研究某一变量关于另一(些)变量间数量依赖关系的一种方法,即通过后者观测值或预设值来估计或预测前者的(总体)均值。
回归的主要作用是用来描述自变量与因变量之间的数量关系,还能够基于自变量的取值变化对因变量的取值变化进行预测,也能够用来揭示自变量与因变量之间的因果关系关键词:解释变量、被解释变量影响被解释变量的因素或因子记为解释变量,结果变量被称为被解释变量。
2、回归模型的设定关键词:随机误差项(随机干扰项)不包含在模型中的解释变量和其他一些随机因素对被解释变量的总影响称为随机误差项。
产生随机误差项的原因主要有:(1)变量选择上的误差;(2)模型设定上的误差;(3)样本数据误差;(4)其他原因造成的误差。
关键词:残差项(residual )通过样本数据对回归模型中参数估计后,得到样本回归模型。
通过样本回归模型计算得到的样本估计值与样本实际值之差,称为残差项。
也可以认为残差项是随机误差项的估计值。
3、一元线性回归模型中对随机干扰项的假设 关键词:线性回归模型经典假设线性回归模型经典假设有5个,分别为:(1)回归模型的正确设立;(2)解释变量是确定性变量,并能够从样本中重复抽样取得;(3)解释变量的抽取随着样本容量的无限增加,其样本方差趋于非零有限常数;(4)给定被解释变量,随机误差项具有零均值,同方差和无序列相关性。
(5)随机误差项服从零均值、同方差的正态分布。
前四个假设也称为高斯马尔科夫假设。
4、最小二乘估计量的统计性质关键词:普通最小二乘法(Ordinary Least Squares ,OLS )普通最小二乘法是通过构造合适的样本回归函数,从而使得样本回归线上的点与真实的样本观测值点的“总体误差”最小,即:被解释变量的估计值与实际观测值之差的平方和最小。
ββ==---∑∑∑nn n222i i 01ii=111ˆˆmin =min ()=min ()i i i i u y y y x关键词:无偏性由于未知参数的估计量是一个随机变量,对于不同的样本有不同的估计量。

第二章回归分析中的几个基本概念第一节回归的含义“回归”(Regression)一词最初是由英国生物学家兼统计学家F.Galton(F·高尔顿)在一篇著名的遗传学论文中引入的(1877年)。
他在研究中发现,具有较高身躯的双亲,或具有较矮身躯的双亲尔,其子女的身高表现为退回(即回归)到人的平均身高趋势。
这一回归定律后来被统计学家K·Pearson通过上千个家庭成员身高的实际调查数据进一步得到证实,从而产生了“回归”这一名称。
然而,现代意义上的“回归”比其原始含义要广得多。
一般来说,现代意义上的回归分析是研究一个变量(也称为explained variable或因变量dependent variable)对另一个或多个变量(也称为解释变量explanatory variable或自变量independent variable )的依赖关系,其目的在于通过解释变量的给定值来预测被解释变量的平均值或某个特定值。
具体而言,回归分析所要解决的问题主要有:(1)确定因变量与自变量之间的回归模型,并依据样本观测值对回归模型中的参数进行估计,给出回归方程。
(2)对回归方程中的参数和方程本身进行显著性检验。
(3)评价自变量对因变量的贡献并对其重要性进行判别。
(4)利用所求得的回归方程,并根据自变量的给定值对因变量进行预测,对自变量进行控制。
第二节统计关系与回归分析一、变量之间的统计关系现象之间的相互联系一般可以分为两种不同的类型:一类为变量间的关系是确定的,称为函数关系;而另一类变量之间的关系是不确定的,称为统计关系。
变量之间的函数关系表达的是变量之间在数量上的确定性关系,即一个或几个变量在数量上的变动就会引起另一个变量在数量上的确定性变动,它们之间的关系可以用函数关系y f x=准确地加以描述,这里x可以是一个向量。
当知道了变量x的值,就可以计算出一()个确切的y值来。
变量之间统计关系,是指一个或几个变量在数量上的变动会引起另一个变量数量上发生变动,但变动的结果不是惟一确定的,亦即变量之间的关系不是一一对应的,因而不能用函数关系进行表达。

第二章一元线性回归模型计量经济学在对经济现象建立经济计量模型时,大量地运用了回归分析这一统计技术,本章和下一章将通过一元线性回归模型、多元线性回归模型来介绍回归分析的基本思想。
第一节回归分析的几个基本问题回归分析是经济计量学的主要工具,下面我们将要讨论这一工具的性质。
一、回归分析的性质(一)回归释义回归一词最先由F •加尔顿(Francis Galt on )提出。
加尔顿发现,虽然有一个趋势,父母高,儿女也高:父母矮,儿女也矮,但给定父母的身高,儿女辈的平均身高却趋向于或者“回归” 到全体人口的平均身高。
或者说,尽管父母双亲都异常高或异常矮,而儿女的身高则有走向人口总体平均身高的趋势(普遍回归规律)。
加尔顿的这一结论被他的朋友K •皮尔逊(Karl pearson)证实。
皮尔逊收集了一些家庭出身1000多名成员的身高记录,发现对于一个父亲高的群体,儿辈的平均身高低于他们父辈的身高,而对于一个父亲矮的群体,儿辈的平均身高则高于其父辈的身高。
这样就把高的和矮的儿辈一同“回归”到所有男子的平均身高,用加尔顿的话说,这是“回归到中等” 。
回归分析是用来研究一个变量(被解释变量Explained variable或因变量Dependent variable 与另一个或多个变量(解释变量Explanatory variable或自变量Independent variable之间的关系。
其用意在于通过后者(在重复抽样中)的已知或设定值去估计或预测前者的(总体)均值。
下面通过几个简单的例子,介绍一下回归的基本概念。
例子1.加尔顿的普遍回归规律。
加尔顿的兴趣在于发现为什么人口的身高分布有一种稳定性,我们关心的是,在给定父辈身高的条件下找出儿辈平均身高的变化。
也就是一旦知道了父辈的身高,怎样预测儿辈的平均身高。
为了弄清楚这一点,用图 1.1 表示如下图 1.1 对应于给定父亲身高的儿子身高的假想分布图 1.1 展示了对应于设定的父亲身高, 儿子在一个假想人口总体中的身高分布, 我们不难发现,对应于任一给定的父亲身高, 相对应都有着儿子身高的一个分布范围,同时随着父亲身高的增加,儿子的平均身高也增加,为了清楚起见,在1.1散点图中勾画了一条通过这些散点的直线,以表明儿子的平均身高是怎样随着父亲的身高增加而增加的。

回归分析知识点总结一、回归分析的基本概念1.1 回归分析的概念回归分析是一种通过数学模型建立自变量与因变量之间关系的方法。
该方法可以用来预测数据、解释变量之间的关系以及发现隐藏的模式。
1.2 回归分析的类型回归分析主要可以分为线性回归和非线性回归两种类型。
线性回归是指因变量和自变量之间的关系是线性的,而非线性回归则是指因变量和自变量之间的关系是非线性的。
1.3 回归分析的应用回归分析广泛应用于各个领域,例如经济学、金融学、生物学、医学等。
在实际应用中,回归分析可以用于市场预测、风险管理、医疗诊断、环境监测等方面。
二、回归分析的基本假设2.1 线性关系假设线性回归分析假设因变量和自变量之间的关系是线性的,即因变量的变化是由自变量的变化引起的。
2.2 正态分布假设回归分析假设误差项服从正态分布,即残差在各个预测点上是独立同分布的。
2.3 同方差假设回归分析假设误差项的方差是恒定的,即误差项的方差在不同的自变量取值上是相同的。
2.4 独立性假设回归分析假设自变量和误差项之间是独立的,即自变量的变化不受误差项的影响。
三、回归分析的模型建立3.1 简单线性回归模型简单线性回归模型是最基础的回归分析模型,它只包含一个自变量和一个因变量,并且自变量与因变量之间的关系是线性的。
3.2 多元线性回归模型多元线性回归模型包含多个自变量和一个因变量,它可以更好地描述多个因素对因变量的影响。
3.3 非线性回归模型当因变量和自变量之间的关系不是线性的时候,可以使用非线性回归模型对其进行建模。
非线性回归模型可以更好地捕捉因变量和自变量之间的复杂关系。
四、回归分析的模型诊断4.1 线性回归模型的拟合优度拟合优度是评价线性回归模型预测能力的指标,它可以用来衡量模型对数据的拟合程度。
4.2 回归系数的显著性检验在回归分析中,通常需要对回归系数进行显著性检验,以确定自变量对因变量的影响是否显著。
4.3 多重共线性检验多重共线性是指自变量之间存在高度相关性,这可能导致回归系数估计不准确。

第⼆章回归分析中的⼏个基本概念第四章⼀、练习题(⼀)简答题1、多元线性回归模型的基本假设是什么?试说明在证明最⼩⼆乘估计量的⽆偏性和有效性的过程中,哪些基本假设起了作⽤?2、多元线性回归模型与⼀元线性回归模型有哪些区别?3、某地区通过⼀个样本容量为722的调查数据得到劳动⼒受教育的⼀个回归⽅程为fedu medu sibs edu 210.0131.0094.036.10++-=R 2=0.214式中,edu 为劳动⼒受教育年数,sibs 为该劳动⼒家庭中兄弟姐妹的个数,medu 与fedu 分别为母亲与⽗亲受到教育的年数。
问(1)若medu 与fedu 保持不变,为了使预测的受教育⽔平减少⼀年,需要sibs 增加多少?(2)请对medu 的系数给予适当的解释。
(3)如果两个劳动⼒都没有兄弟姐妹,但其中⼀个的⽗母受教育的年数为12年,另⼀个的⽗母受教育的年数为16年,则两⼈受教育的年数预期相差多少? 4、以企业研发⽀出(R&D )占销售额的⽐重为被解释变量(Y ),以企业销售额(X1)与利润占销售额的⽐重(X2)为解释变量,⼀个有32容量的样本企业的估计结果如下:099.0)046.0()22.0()37.1(05.0)log(32.0472.0221=++=R X X Y其中括号中为系数估计值的标准差。
(1)解释log(X1)的系数。
如果X1增加10%,估计Y 会变化多少个百分点?这在经济上是⼀个很⼤的影响吗?(2)针对R&D 强度随销售额的增加⽽提⾼这⼀备择假设,检验它不虽X1⽽变化的假设。
分别在5%和10%的显著性⽔平上进⾏这个检验。
(3)利润占销售额的⽐重X2对R&D 强度Y 是否在统计上有显著的影响? 5、什么是正规⽅程组?分别⽤⾮矩阵形式和矩阵形式写出模型:i ki k i i i u x x x y +++++=ββββΛ22110,n i ,,2,1Λ=的正规⽅程组,及其推导过程。
第二章回归分析中的几个基本概念1. 回归模型(Regression Model):回归模型是回归分析的基础,用来描述两个或多个变量之间的关系。
回归模型通常包括一个或多个自变量和一个或多个因变量。
常用的回归模型有线性回归模型和非线性回归模型。
线性回归模型是最简单的回归模型,其中自变量和因变量之间的关系可以用一条直线来表示。
线性回归模型的表达式为:Y=β0+β1*X1+β2*X2+...+βn*Xn+ε其中,Y表示因变量,X1、X2、…、Xn表示自变量,β0、β1、β2、…、βn表示回归系数,ε表示误差项。
2. 回归系数(Regression Coefficients):回归系数是回归模型中自变量的系数,用来描述自变量对因变量的影响程度。
回归系数可以通过最小二乘法估计得到,最小二乘法试图找到一组系数,使得模型的预测值和实际观测值的误差平方和最小。
回归系数的符号表示了自变量与因变量之间的方向关系。
如果回归系数为正,表示自变量的增加会使因变量增加,即存在正向关系;如果回归系数为负,表示自变量的增加会使因变量减少,即存在负向关系。
3. 拟合优度(Goodness-of-fit):拟合优度是用来评估回归模型对样本数据的拟合程度。
通常使用R方(R-squared)来度量拟合优度。
R 方的取值范围在0到1之间,越接近1表示模型对数据的拟合程度越好。
R方的解释是,回归模型中自变量的变异能够解释因变量的变异的比例。
例如,如果R方为0.8,表示模型中自变量解释了因变量80%的变异,剩下的20%可能由其他未考虑的因素引起。
4. 显著性检验(Significance Test):显著性检验用于判断回归模型中自变量的系数是否显著不为零,即自变量是否对因变量有显著影响。
常用的方法是计算t值和p值进行检验。
t值是回归系数除以其标准误得到的统计量。
p值是t值对应的双侧检验的概率。
如果p值小于给定的显著性水平(通常是0.05),则可以拒绝原假设,即认为回归系数显著不为零,即自变量对因变量有显著影响。
第二章回归分析的基本思想第一节回归分析的含义回归分析的基本思想根据经济理论建立计量经济学模型时,计量经济学家会大量地用到回归分析(Regression Analysis)技术,这一节我们将根据最简单的线性回归模型--双变量模型介绍回归分析的基本思想。
回归分析的含义回归分析是研究一个变量与另一个(或一些)变量依赖关系的计算方法和理论。
其中,前一个变量称为被解释变量(Explained Variable)或因变量(Dependent Variable),后一个变量称为解释变量(Explanatory Variable)或自变量(Independent Variable)。
在本书中,为统一符号,统一用y表示因变量,x代表自变量,如果有多个自变量,则用适当的下标表示各个不同的自变量,如有n个自变量,则用x1,x2,…,xn表示。
例如,我们可能对某种商品的需求量与该商品的价格、消费者的收入以及其他竞争性商品的价格之间的关系感兴趣;可能对失业率变动与产出增长之间的关系感兴趣;可能对股票价格指数与利率、GDP增长率等因素之间的关系感兴趣;可能对职工工资与受教育年限之间的关系感兴趣;也可能对购买书报支出金额与收入之间的关系感兴趣。
在这些例子中,有的有理论基础,如需求定理就提供了这样的一个理论基础,即某种产品的需求量依赖于该产品的价格、消费者的收入以及竞争性产品的价格等因素;而奥肯定律则表明失业率的降低依赖于实际产出的增长。
一、回归分析与因果关系要特别注意的是,变量之间的因果关系是回归分析的前提,在被解释变量与解释变量之间存在因果关系的基础上,才能进行回归分析,否则,回归分析没有任何意义。
例如,某段时间内,河水与股市都上涨,显然,如果进行回归分析,则也能建立起回归模型,但得到的结果没有什么意义,因为,河水的上涨与股市的上涨之间并没有什么依赖关系。
二、回归分析与相关分析相关分析是讨论变量之间相关程度的一种统计分析方法。
第四章一、练习题 (一)简答题1、多元线性回归模型的基本假设是什么?试说明在证明最小二乘估计量的无偏性和有效性的过程中,哪些基本假设起了作用?2、多元线性回归模型与一元线性回归模型有哪些区别?3、某地区通过一个样本容量为722的调查数据得到劳动力受教育的一个回归方程为fedu medu sibs edu 210.0131.0094.036.10++-=R 2=0.214式中,edu 为劳动力受教育年数,sibs 为该劳动力家庭中兄弟姐妹的个数,medu 与fedu 分别为母亲与父亲受到教育的年数。
问(1)若medu 与fedu 保持不变,为了使预测的受教育水平减少一年,需要sibs 增加多少?(2)请对medu 的系数给予适当的解释。
(3)如果两个劳动力都没有兄弟姐妹,但其中一个的父母受教育的年数为12年,另一个的父母受教育的年数为16年,则两人受教育的年数预期相差多少? 4、以企业研发支出(R&D )占销售额的比重为被解释变量(Y ),以企业销售额(X1)与利润占销售额的比重(X2)为解释变量,一个有32容量的样本企业的估计结果如下:099.0)046.0()22.0()37.1(05.0)log(32.0472.0221=++=R X X Y其中括号中为系数估计值的标准差。
(1)解释log(X1)的系数。
如果X1增加10%,估计Y 会变化多少个百分点?这在经济上是一个很大的影响吗?(2)针对R&D 强度随销售额的增加而提高这一备择假设,检验它不虽X1而变化的假设。
分别在5%和10%的显著性水平上进行这个检验。
(3)利润占销售额的比重X2对R&D 强度Y 是否在统计上有显著的影响? 5、什么是正规方程组?分别用非矩阵形式和矩阵形式写出模型:i ki k i i i u x x x y +++++=ββββ 22110,n i ,,2,1 =的正规方程组,及其推导过程。
6、假设要求你建立一个计量经济模型来说明在学校跑道上慢跑一英里或一英里以上的人数,以便决定是否修建第二条跑道以满足所有的锻炼者。
你通过整个学年收集数据,得到两个可能的解释性方程:方程A :3215.10.10.150.125ˆX X X Y +--= 75.02=R 方程B :4217.35.50.140.123ˆX X X Y -+-= 73.02=R 其中:Y ——某天慢跑者的人数1X ——该天降雨的英寸数 2X ——该天日照的小时数3X ——该天的最高温度(按华氏温度) 4X ——第二天需交学期论文的班级数请回答下列问题:(1)这两个方程你认为哪个更合理些,为什么?(2)为什么用相同的数据去估计相同变量的系数得到不同的符号?7、设货币需求方程式的总体模型为t t t ttRGDP r P M εβββ+++=)ln()ln()ln(210 其中M 为广义货币需求量,P 为物价水平,r 为利率,RGDP 为实际国内生产总值。
假定根据容量为n =19的样本,用最小二乘法估计出如下样本回归模型;1.09.0)3()13()ln(54.0)ln(26.003.0)ln(2==++-=DW R e RGDP r P M t t t tt其中括号内的数值为系数估计的t 统计值,t e 为残差。
(1)从经济意义上考察估计模型的合理性;(2)在5%显著性水平上.分别检验参数21,ββ的显著性; (3)在5%显著性水平上,检验模型的整体显著性。
(二)计算题1、下面给出依据15个观察值计算得到的数据:693.367=Y , 760.4022=X ,0.83=X ,269.660422=∑i y096.8485522=∑ix,0.28023=∑i x , 346.747782=∑iixy9.42503=∑iixy ,0.479632=∑i ix x其中小写字母代表了各值与其样本均值的离差。
要求:(1)估计三个多元回归系数;(2)估计它们的标准差;并求出2R 与2R ?(3)估计2β、3β95%的置信区间;(4)在%5=α下,检验估计的每个回归系数的统计显著性(双边检验); (5)检验在%5=α下所有的部分系数都为零,并给出方差分析表。
2、表3—1是以进出车站的乘客为主要服务对象的10家便利店的数据。
y 是日均销售额,1x 是店铺面积,2x 是作为选址条件的店铺距车站的距离。
(1)对多元回归模型εβββ+++=22110x x y 进行OLS 估计; (2)求决定系数2R 和自由度调整后的决定系数2R ;(3)假设其他条件不变,店铺面积增加1平方米,日均销售额能增加多少元?(4)假设其他条件不变,店铺距车站的距离比现在远100米,日均销售额会减少多少元? (5)假设有人想新建一个店铺K 店,计划店铺面积为80平方米,距车站300米,试预测其日均销售额K y。
3、已知线性回归模型U X Y +=B 式中~U (0,I 2σ),13=n 且3=k (n 为样本容量,k 为参数的个数),由二次型)()'(B B X Y X Y --的最小化得到如下线性方程组:3ˆˆ2ˆ321=++βββ 9ˆˆ5ˆ2321=++βββ 8ˆ6ˆˆ321-=++βββ要求:(1)把问题写成矩阵向量的形式;用求逆矩阵的方法求解之;(2)如果53='Y Y ,求2ˆσ; (3)求出βˆ的方差—协方差矩阵。
4、已知数据如下表:要求:(1)先根据表中数据估计以下回归模型的方程(只估计参数不用估计标准差):i i i u x y 1110++=αα i i i u x y 2220++=λλ i i i i u x x y +++=22110βββ(2)回答下列问题:11βα=吗?为什么?22βλ=吗?为什么? (三)证明题1、考虑下列两个模型:Ⅰ、i i i i u x x y +++=33221βββ Ⅱ、i i i i i u x x x y '+++=-332212)(ααα要求:(1)证明:1ˆˆ22-=βα ,11ˆˆβα= ,33ˆˆβα= (2)证明:残差的最小二乘估计量相同,即:i i u u'=ˆˆ (3)在何种情况下,模型Ⅱ的拟合优度22R 会小于模型Ⅰ拟合优度21R 。
2、对模型i ki k i i i u x x x y +++++=ββββ 22110应用OLS 法,得到回归方程如下:kik i i i x x x y ββββˆˆˆˆˆ22110++++= 要求:证明残差i i i yy ˆ-=ε与i y ˆ不相关,即:0ˆ=∑ii yε。
二、答案 (一)简答题1、多元线性回归模型的基本假定有:零均值假定、随机项独立同方差假定、解释变量的非随机性假定、解释变量之间不存在线性相关关系假定、随机误差项i u 服从均值为0方差为2σ的正态分布假定。
在证明最小二乘估计量的无偏性中,利用了解释变量与随机误差项不相关的假定;在有效性的证明中,利用了随机项独立同方差假定。
2、多元线性回归模型与一元线性回归模型的区别表现在如下几方面:一是解释变量的个数不同;二是模型的经典假设不同,多元线性回归模型比一元线性回归模型多了“解释变量之间不存在线性相关关系”的假定;三是多元线性回归模型的参数估计式的表达更复杂;3、(1)根据多元回归模型偏回归系数的含义,sibs 前的参数估计值-0.094表明,在其他条件不变的情况下,每增加1个兄弟姐妹,受教育年数会减少0.094年,因此,要减少1年受教育的时间,兄弟姐妹需增加1/0.094=10.6个。
(2)medu 的系数表示当兄弟姐妹数与父亲受教育的年数保持不变时,母亲每增加1年受教育的机会,其子女作为劳动者就会预期增加0.131年的教育机会。
(3)首先计算两人受教育的年数分别为:10.36+0.131⨯12+0.210⨯12=14.452 10.36+0.131⨯16+0.210⨯16=15.816因此,两人的受教育年限的差别为15.816-14.452=1.364 4、(1)log(x1)的系数表明在其他条件不变时,log(x1)变化1个单位,Y 变化的单位数,即∆Y=0.32∆log(X1)≈0.32(∆X1/X1)=0.32⨯100%,换言之,当企业销售X1增长100%时,企业研发支出占销售额的比重Y 会增加0.32个百分点。
由此,如果X1增加10%,Y 会增加0.032个百分点。
这在经济上不是一个较大的影响。
(2)针对备择假设H1:01>β,检验原假设H0:01=β。
易知计算的t 统计量的值为t=0.32/0.22=1.468。
在5%的显著性水平下,自由度为32-3=29的t 分布的临界值为1.699(单侧),计算的t 值小于该临界值,所以不拒绝原假设。
意味着R&D 强度不随销售额的增加而变化。
在10%的显著性水平下,t 分布的临界值为1.311,计算的t 值小于该值,拒绝原假设,意味着R&D 强度随销售额的增加而增加。
(3)对X 2,参数估计值的t 统计值为0.05/0.46=1.087,它比在10%的显著性水平下的临界值还小,因此可以认为它对Y 在统计上没有显著的影响。
5、答:含有待估关系估计量的方程组称为正规方程组。
正规方程组的非矩阵形式如下:⎪⎪⎪⎩⎪⎪⎪⎨⎧=++++-=++++-=++++-=++++-∑∑∑∑∑∑∑∑0)ˆˆˆˆ(0)ˆˆˆˆ(0)ˆˆˆˆ(0)ˆˆˆˆ(221102221102122110122110ki ki k i i ki i i ki k i i i i i ki k i i i i kik i i i x x x x x y x x x x x y x x x x x y x x x y ββββββββββββββββ 正规方程组的矩阵形式如下:BˆX X '=Y X ' 推导过程略。
6、⑴方程B 更合理些。
原因是:方程B 中的参数估计值的符号与现实更接近些,如与日照的小时数同向变化,天长则慢跑的人会多些;与第二天需交学期论文的班级数成反向变化,这一点在学校的跑道模型中是一个合理的解释变量。
⑵解释变量的系数表明该变量的单位变化在方程中其他解释变量不变的条件下对被解释变量的影响,在方程A 和方程B 中由于选择了不同的解释变量,如方程A 选择的是“该天的最高温度”而方程B 选择的是“第二天需交学期论文的班级数”,由此造成2X 与这两个变量之间的关系不同,所以用相同的数据估计相同的变量得到不同的符号。
7、(1)该估计模型:反映了货币需求量随利率的升高而下降和随国民生产总值的增加而上升的关系,具有经济意义上合理性。
(2)查表有t 0.025(16)=2.120,从而)16(025.02t t ≥β,)16(025.03t t ≥β,知参数2β和3β显著。