数据结构函数
- 格式:ppt
- 大小:392.50 KB
- 文档页数:47

查找并返回值的函数在计算机编程中,函数用来执行特定任务并返回结果。
有些函数还需要查找特定数据并返回匹配结果。
这种查找并返回值的函数在编程中非常常见,并且可以应用于许多不同的领域。
本文将重点介绍查找并返回值的函数,其中包括常见的数据结构,如数组、列表和散列表,以及常见的算法,如线性搜索、二分查找和哈希表查找。
一、数组数组是一种最常用的数据结构之一,它可以在内存中存储一系列具有相同数据类型的值。
使用数组,我们可以轻松地找到特定索引处的值,并使代码具有可读性和可重复使用性。
要查找并返回数组中的值,我们可以使用以下代码:首先,我们需要定义数组并初始化它。
int[] arr = {1, 2, 3, 4, 5};然后,我们可以编写一个函数来查找值:public static int findValue(int[] arr, int value) { for (int i = 0; i < arr.length; i++) { if (arr[i] == value) { return i; } } return -1; }在这个函数中,我们使用一个循环来遍历数组,并在每个索引上比较值。
如果找到值,我们返回它的索引。
如果没有找到,我们将返回-1。
这个函数可以应用于任何类型的数组,只需要将数据类型作为参数传递给函数。
二、列表列表是一种与数组类似的数据结构,它可以包含不同类型的元素,并且可以动态调整大小。
与数组不同,列表的大小可以根据需要进行操作,并且不会在内存中占用多余的空间。
要查找并返回列表中的值,我们可以使用以下代码:首先,我们需要定义列表并添加元素。
List<Integer> list = new ArrayList<>();list.add(1); list.add(2); list.add(3); list.add(4); list.add(5);然后,我们可以编写一个函数来查找值:public static int findValue(List<Integer> list, int value) { for (int i = 0; i < list.size();i++) { if (list.get(i) == value){ return i; } } return -1; }在这个函数中,我们使用一个循环来遍历列表,并在每个元素上比较值。

数据结构union函数-回复数据结构中的union函数是一种常见的操作,它用于合并两个集合或者查找两个元素所属的集合。
本文将详细介绍union函数的实现原理以及其在数据结构中的应用。
一、union函数概述在数据结构中,union函数的主要作用是将两个不相交的集合合并为一个集合,从而构建一个更大的集合。
具体来说,union函数的输入是两个集合以及它们的代表元素,输出是合并后的集合。
二、union函数的实现原理对于union函数的实现,常见的方法是使用并查集(disjoint set)数据结构。
并查集是一种用于处理不相交集合的数据结构,它支持合并集合和查询元素所属集合的操作。
在并查集中,每个集合用一棵树来表示,树的根节点指向自身,其他节点指向它的父节点。
每个集合由一个代表元素来表示,代表元素是根节点。
假设有两个集合A和B,分别由代表元素a和b表示,union函数的目标就是将集合A和B合并为一个集合。
具体而言,union函数的实现可以分为以下步骤:1. 首先,找到集合A和B的代表元素a和b。
2. 将代表元素b的父节点设置为a,即将集合B合并到集合A中。
3. 如果集合B的规模比集合A大,则更新集合A的代表元素为b。
可以通过路径压缩来优化union函数的性能。
路径压缩是一种在查找代表元素的过程中优化树形结构的方法,它通过将路径上的每个节点直接连接到根节点,减少树的高度,提高查找效率。
三、union函数的应用union函数在数据结构中有广泛的应用,下面分别介绍两个典型的应用场景。
1. 连通性问题在图论中,连通性问题是指判断两个节点是否存在路径连接的问题。
利用union函数可以高效地解决这个问题。
具体而言,可以使用一个并查集来表示图中的节点集合,每个节点用一个元素来表示。
当两个节点之间存在边时,可以使用union函数将它们所属的集合合并。
最后,利用find函数来判断两个节点是否属于同一个连通分量。
2. 集合合并在某些场合,需要将多个集合合并为一个更大的集合。

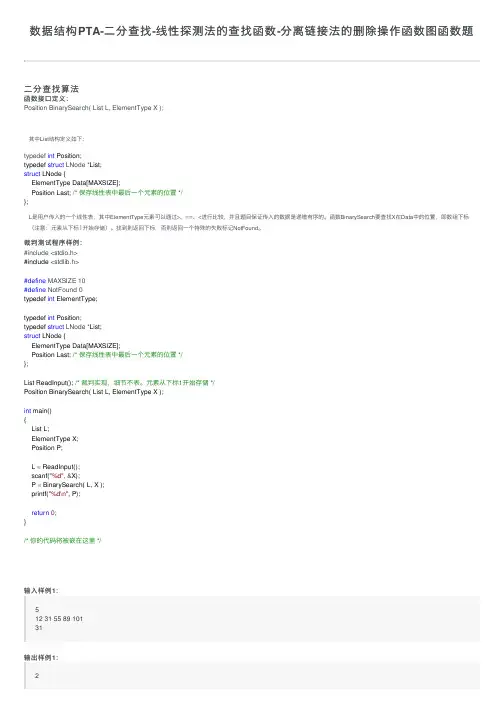
数据结构PTA-⼆分查找-线性探测法的查找函数-分离链接法的删除操作函数图函数题⼆分查找算法函数接⼝定义函数接⼝定义::其中List 结构定义如下:L 是⽤户传⼊的⼀个线性表,其中ElementType 元素可以通过>、==、<进⾏⽐较,并且题⽬保证传⼊的数据是递增有序的。
函数BinarySearch 要查找X 在Data 中的位置,即数组下标(注意:元素从下标1开始存储)。
找到则返回下标,否则返回⼀个特殊的失败标记NotFound 。
裁判测试程序样例:输⼊样例1:512 31 55 89 10131输出样例1:2Position BinarySearch( List L, ElementType X );typedef int Position;typedef struct LNode *List;struct LNode {ElementType Data[MAXSIZE];Position Last; /* 保存线性表中最后⼀个元素的位置 */};#include <stdio.h>#include <stdlib.h>#define MAXSIZE 10#define NotFound 0typedef int ElementType;typedef int Position;typedef struct LNode *List;struct LNode {ElementType Data[MAXSIZE];Position Last; /* 保存线性表中最后⼀个元素的位置 */};List ReadInput(); /* 裁判实现,细节不表。
元素从下标1开始存储 */Position BinarySearch( List L, ElementType X );int main(){List L;ElementType X;Position P;L = ReadInput();scanf("%d", &X);P = BinarySearch( L, X );printf("%d\n", P);return 0;}/* 你的代码将被嵌在这⾥ */输⼊样例2:326 78 23331输出样例2:分析:很简单的⼀道题,先是⽤正常的⼆分查找找了⼀遍,后来发现直接顺序查找也可以通过(⽼懒狗了Position BinarySearch( List L, ElementType X ){int low=1;int high=L->Last;int flag=-1;int mid;while(low<=high){mid=(mid+high)/2;if(X==L->Data[mid]){flag=mid;break;}else if(X<L->Data[mid])high=mid-1;elselow=mid;}if(flag>0)return flag;elsereturn NotFound;}Position BinarySearch( List L, ElementType X ){int i=1;int flag=-1;for(i=1;i<=L->Last;i++){if(L->Data[i]==X){flag=i;break;}}if(flag>0)return flag;elsereturn NotFound;}线性探测法的查找函数函数接⼝定义:Position Find( HashTable H, ElementType Key );其中HashTable是开放地址散列表,定义如下:#define MAXTABLESIZE 100000 /* 允许开辟的最⼤散列表长度 */typedef int ElementType; /* 关键词类型⽤整型 */typedef int Index; /* 散列地址类型 */typedef Index Position; /* 数据所在位置与散列地址是同⼀类型 *//* 散列单元状态类型,分别对应:有合法元素、空单元、有已删除元素 */typedef enum { Legitimate, Empty, Deleted } EntryType;typedef struct HashEntry Cell; /* 散列表单元类型 */struct HashEntry{ElementType Data; /* 存放元素 */EntryType Info; /* 单元状态 */};typedef struct TblNode *HashTable; /* 散列表类型 */struct TblNode { /* 散列表结点定义 */int TableSize; /* 表的最⼤长度 */Cell *Cells; /* 存放散列单元数据的数组 */};函数Find应根据裁判定义的散列函数Hash( Key, H->TableSize )从散列表H中查到Key的位置并返回。

链表头插法Node *insert_node(Node *head,Node* new_node) {if(head!=NULL){new_node->next=head;}head=new_node;return head;}头指针:头指针指向第一个结点!Node insert_node(Node head,Node* new_node) {if(head.next!=NULL){new_node->next=head.next;}head.next=new_node;return head;}头结点:结点在头结点后!尾插法:Node insert_node(Node head,Node *new_node){Node* tail;if(head.next==NULL)head.next=new_node;else{for(tail=head.next;tail->next!=NULL;tail=tail->next);tail->next=new_node;}return head;}头结点Node *insert_node(Node *head,Node *new_node){Node *p;if(head==NULL)head=new_node;else{for(p=head;p->next!=NULL;p=p->next);p->next=new_node;}return head;}头指针排序插入法:Node insert_node(Node head,Node* new_node){Node *p0,*p1,*p2;p1=head.next;p0=new_node;if(head.next==NULL){head.next=p0;//p0->next=NULL;}else{while((p0->data>p1->data)&&(p1->next!=NULL)){p2=p1;p1=p1->next;}if(p0->data<=p1->data)if(head.next==p1)head.next=p0;elsep2->next=p0;p0->next=p1;}else{p1->next=p0;// p0->next=NULL;}}return head;}头结点Node *insert_node(Node *head,Node* new_node) {Node *p0,*p1,*p2;p1=head;p0=new_node;if(head==NULL)head=p0;{while((p0->data>p1->data)&&(p1->next!=NULL)) {p2=p1;p1=p1->next;}if(p0->data<=p1->data){if(head==p1){p0->next=head;head=p0;}else{p2->next=p0;p0->next=p1;}}else{p1->next=p0;// p0->next=NULL;}}return head;}头指针创建:#include<stdio.h>#include<malloc.h>typedef struct node{int data;struct node *next;}Node;Node *create_node(int data){Node *new_node=(Node*)malloc(sizeof(Node));if(new_node!=NULL){new_node->data=data;new_node->next=NULL;}return new_node;}输出:void output(Node *head){Node *p=head;while(p!=NULL){printf("%3d",p->data);p=p->next;}printf("\n");}释放:void outfree(Node *head){Node *p;p=head->next;for(;p!=NULL;){head->next=p->next;free(p);p=head->next;}}void destory(Node *head) {Node *p=head;while(p!=NULL){head=head->next;// printf("%d",p->data);free(p);p=head;}}双链表:#include<stdio.h>#include<malloc.h>typedef struct node{struct node *fwd;int data;struct node *next;}Node;创建:Node *create_node(int data){Node *new_node;new_node=(Node*)malloc(sizeof(Node));if(new_node!=NULL){new_node->data=data;new_node->next=NULL;new_node->fwd=NULL;}return new_node;}头插法:Node *insert_node(Node *head,Node *new_node) {if(head!=NULL){head->fwd=new_node;new_node->next=head;}head=new_node;return head;}头指针int insert_node(Node **head,Node *new_node) {if(new_node==NULL){printf("the node is empty.\n");return -1;}if(*head!=NULL){(*head)->fwd=new_node;new_node->next=(*head);}(*head)=new_node;return 0;}队列链式对:#include<stdio.h>#include<malloc.h>创建:typedef int elemtype;typedef struct qnode{elemtype data;struct qnode *next;}Qnode;typedef struct queue{Qnode *front;Qnode *rear;}queue;初始化:void initqueue(queue *q)q->front=q->rear=(Qnode*)malloc(sizeof(Qnode));q->front->next=NULL;}加:int enqueue(queue *q,elemtype x){Qnode *p;p=(Qnode*)malloc(sizeof(Qnode));if(p==NULL)return -1;p->data=x;q->rear->next=p;p->next=NULL;q->rear=p;return 0;}删:int outqueue(queue *q,elemtype *x){if(is_empty(q)){printf("queue is empty'\n");return -1;}Qnode *p;p=q->front->next;*x=p->data;// if(q->rear==p)if(p->next==NULL)q->rear=q->front;q->front->next=p->next;free(p);return 0;}读取:int gottop(queue *q,elemtype *x) {if(is_empty(q)){printf("queue is empty'\n");return -1;}*x=q->front->next->data;return 0;}顺序对:#include<stdio.h>#define Maxsize 10创建:typedef int elemtype;typedef struct{elemtype data[Maxsize];int front;int rear;}queue;初始化:void initqueue(queue *s) {s->front=0;s->rear=0;}加:int enqueue(queue *s,elemtype x){if(is_full(s)){printf("queue is full.\n");return -1;}s->rear=(s->rear+1)%Maxsize;s->data[s->rear]=x;return 0;}读取:int gettop(queue *s,elemtype *x){if(is_empty(s)){printf("queue is empty.\n");return -1;}*x=s->data[(s->front+1)%Maxsize];return 0;}删:outqueue(queue *s,elemtype *x){if(is_empty(s)){printf("queue is empty.\n");return -1;}*x=s->data[(s->front+1)%Maxsize];s->data[(s->front+1)%Maxsize]=0;s->front=(s->front+1)%Maxsize;return 0;}空:int is_empty(queue *s){return s->front==s->rear;}满:int is_full(queue *s){return (s->rear+1)%Maxsize==s->front; }栈顺序栈:#include<stdio.h>#define Maxsize 5创建:typedef int elemtype;typedef struct node{elemtype data[Maxsize];int top;}stack;初始化:void initstack(stack *s) {s->top=-1;}压栈:int push(stack *s,elemtype x) {if(is_full(s)){return -1;}s->top++;s->data[s->top]=x;return 0;}出栈:int pop(stack *s,elemtype *x) {if(empty(s)){printf("\n stack is free!");return -1;}*x=s->data[s->top];s->top--;return 0;}读取:int GetTop(stack *s,elemtype *x) {if(empty(s)){printf("\n stack is free!");return -1;}*x=s->data[s->top];}空:int empty(stack *s){return s->top==-1;}满:int is_full(stack *s){return s->top==Maxsize-1; }动态顺序栈:#include<stdio.h>#include<malloc.h>#define Maxsize 5typedef int elemtype;typedef struct stack{elemtype *data;int top;} stack;void initstack(stack *s){s->top=-1;s->data=(elemtype*)malloc(Maxsize*sizeof(elemtype)); }int push(stack *s,elemtype x){if(is_full(s))return -1;s->top++;s->data[s->top]=x;return 0;}int pop(stack *s,elemtype *x) {if(empty(s)){printf("\n stack is free!");return -1;}(*x)=s->data[s->top];s->top--;return 0;}int gettop(stack *s,elemtype *x) {if(empty(s)){printf("\n stack is free!");return -1;}*x=s->data[s->top];}int is_full(stack *s){return s->top==Maxsize-1; }int empty(stack *s){return s->top==-1;}链式栈:#include<stdio.h>#include<malloc.h>typedef int elemtype;typedef struct node{elemtype data;struct node *next;}stack;void initstack(stack **top){(*top)=(stack*)malloc(sizeof(stack));(*top)->next=NULL;}int push(stack **top,elemtype x){stack *p;p=(stack*)malloc(sizeof(stack));if(p==NULL)return -1;p->data=x;p->next=(*top)->next;(*top)->next=p;return 0;}int pop(stack **top,elemtype *x) {stack *p;if(empty(top)){printf("stack is free!\n");return -1;}p=(*top)->next;*x=p->data;(*top)->next=p->next;free(p);return 0;}int gettop(stack **top,elemtype *x) {if(empty(top)){printf("stack is free!\n");return -1;}*x=(*top)->next->data;}int empty(stack **top){return (*top)->next==NULL; }。
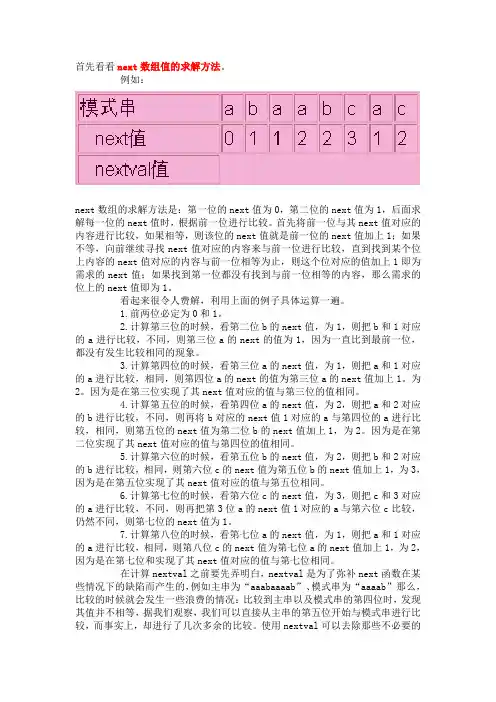
首先看看next数组值的求解方法。
例如:next数组的求解方法是:第一位的next值为0,第二位的next值为1,后面求解每一位的next值时,根据前一位进行比较。
首先将前一位与其next值对应的内容进行比较,如果相等,则该位的next值就是前一位的next值加上1;如果不等,向前继续寻找next值对应的内容来与前一位进行比较,直到找到某个位上内容的next值对应的内容与前一位相等为止,则这个位对应的值加上1即为需求的next值;如果找到第一位都没有找到与前一位相等的内容,那么需求的位上的next值即为1。
看起来很令人费解,利用上面的例子具体运算一遍。
1.前两位必定为0和1。
2.计算第三位的时候,看第二位b的next值,为1,则把b和1对应的a 进行比较,不同,则第三位a的next的值为1,因为一直比到最前一位,都没有发生比较相同的现象。
3.计算第四位的时候,看第三位a的next值,为1,则把a和1对应的a 进行比较,相同,则第四位a的next的值为第三位a的next值加上1。
为2。
因为是在第三位实现了其next值对应的值与第三位的值相同。
4.计算第五位的时候,看第四位a的next值,为2,则把a和2对应的b 进行比较,不同,则再将b对应的next值1对应的a与第四位的a进行比较,相同,则第五位的next值为第二位b的next值加上1,为2。
因为是在第二位实现了其next值对应的值与第四位的值相同。
5.计算第六位的时候,看第五位b的next值,为2,则把b和2对应的b 进行比较,相同,则第六位c的next值为第五位b的next值加上1,为3,因为是在第五位实现了其next值对应的值与第五位相同。
6.计算第七位的时候,看第六位c的next值,为3,则把c和3对应的a 进行比较,不同,则再把第3位a的next值1对应的a与第六位c比较,仍然不同,则第七位的next值为1。
7.计算第八位的时候,看第七位a的next值,为1,则把a和1对应的a 进行比较,相同,则第八位c的next值为第七位a的next值加上1,为2,因为是在第七位和实现了其next值对应的值与第七位相同。

头文件btree.h中定义数据结构并声明用于完成基本运算的函数。
对应基本运算的函数1.引言1.1 概述在计算机科学领域,数据结构是研究数据组织、存储和管理的方法。
它是计算机程序设计的基础,对于解决复杂的问题和优化算法至关重要。
本文主要讨论的是一个名为btree.h的头文件中所定义的数据结构,以及在该头文件中声明的用于完成基本运算的函数。
这些基本运算函数可以对该数据结构进行插入、删除、搜索等操作,为处理数据提供了方便和高效。
首先,在头文件btree.h中,我们定义了一种名为B树的数据结构。
B树是一种自平衡的二叉查找树,它在处理大量数据时具有出色的性能。
B树通常用于在数据库和文件系统中存储和管理数据。
其次,我们在头文件中声明了一些用于完成基本运算的函数。
这些函数包括插入数据、删除数据、搜索数据等操作。
通过这些函数的使用,我们可以在B树中灵活地操作数据,实现快速的查找、插入和删除。
本文的目的是介绍头文件btree.h中所定义的数据结构和基本运算函数的使用方法,以及它们在实际应用中的意义和优势。
通过深入了解和熟练掌握这些内容,读者可以在自己的程序中更好地利用B树这种数据结构,提高数据处理的效率和准确性。
接下来,将在文章的第2部分探讨头文件btree.h的定义,以及在第3部分总结整篇文章的内容以及展望未来可能的研究方向。
通过进行系统和全面的分析,读者将能够更好地理解并运用该头文件中定义的数据结构和函数。
1.2 文章结构本文的目的是介绍头文件btree.h中定义的数据结构以及声明用于完成基本运算的函数。
文章主要分为以下几个部分:1. 引言:在引言部分,将对本文的整体内容进行概述,介绍头文件btree.h 的目的和作用,以及本文的结构和目的。
2. 正文:正文部分主要包括两个小节。
2.1 头文件btree.h 的定义:在这一小节中,将详细介绍头文件btree.h 的定义,包括其中定义的数据结构以及相关的宏定义和全局变量。

数据库函数类型数据库函数类型数据库函数是一种可重复使用的代码块,它定义在数据库中,用于执行一些特定的操作或计算。
它们可以是内置函数,也可以是用户定义的函数。
数据库函数类型有很多种,常见的包括以下几类:1. 聚合函数聚合函数用于计算某些列的统计值,如总数、平均值、最大值、最小值等。
常见的聚合函数有SUM、AVG、MAX、MIN等。
例如,我们可以使用以下SQL语句来计算某个表中某列的总和:SELECT SUM(column_name) FROM table_name;2. 字符串函数字符串函数用于处理字符或字符串类型的数据。
它们可以用于截取、替换、拼接、转换字符串等操作。
常见的字符串函数有CONCAT、SUBSTR、UPPER、LOWER、REPLACE等。
例如,我们可以使用以下SQL语句来将某个表中的字符串字段全部转换为大写:SELECT UPPER(column_name) FROM table_name;3. 数学函数数学函数用于执行数学计算,如求绝对值、平方、开方、自然对数等。
常见的数学函数有ABS、SQR、SIN、COS、LOG等。
例如,我们可以使用以下SQL语句来计算某个表中某列的平方值:SELECT SQR(column_name) FROM table_name;4. 日期时间函数日期时间函数用于处理日期和时间类型的数据。
它们可以用于格式化、计算、比较日期和时间。
常见的日期时间函数有DATE_FORMAT、DATEDIFF、NOW、TIMESTAMPDIFF等。
例如,我们可以使用以下SQL语句来计算某个表中某列的日期差:SELECT DATEDIFF(column_name1, column_name2) FROM table_name;在设计数据库时,我们可以使用函数来定义计算、检查和转换数据值的规则。
通过函数,我们可以避免重复性的数据转换和计算,提高代码的可重用性和可维护性。
因此,了解数据库函数类型和使用场景是非常重要的。

C语言中的data函数详解导言C语言是一种高效且广泛应用的编程语言。
在处理各种数据时,C语言提供了一系列的函数来处理不同类型的数据。
其中,data函数是一个特定的函数,用来处理数据的结构和表达,为程序员提供了灵活性和效率。
在本文中,我们将详细解释C语言中的data函数的定义、用途和工作方式。
同时,我们还将提供示例代码和描述,以帮助读者更好地理解和运用这些函数。
1. 函数定义data函数是C语言中用于处理数据的一组特定的函数。
它们旨在提供一种灵活和高效的方法来操作和转换不同类型的数据。
这些函数包括:memcpy、memset、memcmp、memmove等。
2. 函数用途这些data函数的主要用途是处理内存数据、字符串和数组。
它们可用于实现数据的复制、初始化、比较和移动等操作。
具体用途如下:•memcpy:用于将一个内存区域的内容复制到另一个内存区域。
•memset:用于将一个内存区域的内容设置为指定的值。
•memcmp:用于比较两个内存区域的内容是否相等。
•memmove:用于将一个内存区域的内容移动到另一个内存区域。
这些函数在数据处理和算法实现中广泛应用。
例如,在排序算法中,我们需要比较和移动数据;在字符串操作中,我们需要复制和比较字符串;在数据结构中,我们需要初始化和复制对象等。
3. 函数工作方式下面我们将逐个解释这些data函数的工作方式。
3.1 memcpy函数原型:void *memcpy(void *dest, const void *src, size_t n)memcpy函数将源内存区域(src)的内容复制到目标内存区域(dest)。
参数n指定要复制的字节数。
具体工作方式如下: 1. 检查n是否为0。
如果是,则直接返回dest。
2. 以字节为单位,从src开始的内存区域复制n个字节到dest开始的内存区域。
3. 返回dest的指针。
示例代码:#include <stdio.h>#include <string.h>int main() {char src[] = "Hello, World!";char dest[20];memcpy(dest, src, strlen(src) + 1);printf("Copied string: %s\n", dest);return 0;}运行结果:Copied string: Hello, World!3.2 memset函数原型:void *memset(void *s, int c, size_t n)memset函数将内存区域(s)的每个字节都设置为指定的值(c)。

QT中的常用数据结构及函数一、QT中常用数据结构1、QString:QString 是一种 Qt 类的字符串类,可以处理 Unicode字符,它可以和 C 字符串以及 std::string 之间相互转换。
它不仅可以存储文本,还可以处理文本相关的任务。
2、QVector:QVector 类定义了一个模板类,它实现了一个动态大小的数组。
它可以替代原始的 C 数组和 std::vector。
QVector 不能存放关联性数据,但是可以存放像 QMap 的键值对。
3、QPair:QPair 是 Qt 类的一个模板类,用于存放两个值的元组,可以是不同类型的值,同时 QPair 可以存放关联性数据,例如键值对,结构体等等。
4、QList:QList 是一种 Qt 类的模板列表。
它包含动态大小的双向链表,可以用来存放任何类型的值,同时也可以存放关联数据,如键值对。
5、QMap:QMap 是 Qt 类的一个模板类,用于存放键值对。
它是一个“有序”映射,可以用来达到直接以键访问值的目的。
二、QT中常用函数1、QString.toInt()函数:可以将一个QString类型的字符串转换为int类型的数据。
例如:QString str = "123"; int i = str.toInt(; // i = 123;2、QString.toFloat()函数:可以将一个QString类型的字符串转换为float类型的数据。
例如:QString str = "123.45"; float f = str.toFloat(; // f = 123.45;3、QString.split()函数:可以将一个QString类型的字符串根据指定字符分割成多个QString类型的字符串。
例如:QString str ="a,b,c,d"; QStringList list = str.split(",");// list = {"a", "b", "c", "d"}。

pandas 数据结构:SeriesDataFrame ;python 函数:rangearange1. Series Series 是⼀个类数组的数据结构,同时带有标签(lable )或者说索引(index )。
1.1 下边⽣成⼀个最简单的Series 对象,因为没有给Series 指定索引,所以此时会使⽤默认索引(从0到N-1)。
# 引⼊Series 和DataFrameIn [16]: from pandas import Series,DataFrameIn [17]: import pandas as pdIn [18]: ser1 = Series([1,2,3,4])In [19]: ser1Out[19]:0 11 22 33 4dtype: int64 1.2 当要⽣成⼀个指定索引的Series 时候,可以这样: # 给index 指定⼀个listIn [23]: ser2 = Series(range(4),index = ["a","b","c","d"])In [24]: ser2Out[24]:a 0b 1c 2d 3dtype: int64 1.3 也可以通过字典来创建Series 对象In [45]: sdata = {'Ohio': 35000, 'Texas': 71000, 'Oregon': 16000, 'Utah': 5000}In [46]: ser3 = Series(sdata)# 可以发现,⽤字典创建的Series 是按index 有序的In [47]: ser3Out[47]:Ohio 35000Oregon 16000Texas 71000Utah 5000dtype: int64 在⽤字典⽣成Series 的时候,也可以指定索引,当索引中值对应的字典中的值不存在的时候,则此索引的值标记为Missing ,NA ,并且可以通过函数(pandas.isnull ,pandas.notnull )来确定哪些索引对应的值是没有的。
数据结构----名词解释数据结构----名词解释1. 数据结构的概念数据结构是计算机科学中一种用来组织和存储数据的方式。
它涉及到数据的组织方式、存储方式以及对数据的操作和访问方式。
不同的数据结构适用于不同的应用场景,能够提供高效的数据存储和访问。
2. 数组(Array)数组是一种线性数据结构,它由一系列相同类型的元素组成,这些元素在内存中是连续存储的。
数组可以通过下标快速访问和修改其中的元素,时间复杂度为O(1)。
但是数组的大小固定,插入和删除元素时需要移动其他元素,时间复杂度为O(n)。
3. 链表(Linked List)链表是一种线性数据结构,它由一系列节点组成,每个节点包括数据和指向下一个节点的指针。
链表中的元素在内存中可以是不连续存储的,因此插入和删除元素时不需要移动其他元素,时间复杂度为O(1)。
但是访问链表中的任意位置元素需要从头节点开始遍历,时间复杂度为O(n)。
4. 栈(Stack)栈是一种具有后进先出(Last In First Out,LIFO)特性的数据结构。
栈有两个基本操作:push(入栈)和pop(出栈)。
入栈将元素放入栈顶,出栈将栈顶元素删除并返回。
栈可以用于实现递归算法、表达式求值和函数调用等。
5. 队列(Queue)队列是一种具有先进先出(First In First Out,FIFO)特性的数据结构。
队列有两个基本操作:enqueue(入队)和dequeue (出队)。
入队将元素放入队尾,出队将队首元素删除并返回。
队列可以用于实现BFS广度优先搜索、任务调度和消息传递等。
6. 树(Tree)树是一种非线性的数据结构,它由一系列节点组成。
每个节点有一个父节点和零个或多个子节点。
树的一个节点称为根节点,没有父节点的节点称为叶节点。
树的常见应用包括二叉搜索树、AVL 树、红黑树等。
7. 图(Graph)图是一种非线性的数据结构,它由一组节点和一组边组成。
节点表示实体,边表示节点之间的关系。
表格结构数据函数类型
表格结构数据一直被广泛应用于各个领域,例如金融、医疗和学
术研究等等。
由于表格结构数据的灵活性和易于处理,数据的处理和
分析变得非常简便。
这里我们将简要介绍一下表格结构数据函数类型。
在表格结构数据中,函数是用来处理数据的工具。
Excel等软件
提供了许多不同类型的函数来处理表格数据,以便更好地分析和解释
数据。
在这里,我们将介绍一些最常用的函数类型:
一、数值函数:用于处理表格中的数字,例如运算、求和、平均
值等等。
二、逻辑函数:用于判断表格中的数据是否符合特定的条件,例
如 IF 函数和 AND 函数可以根据不同的判断条件返回特定的结果。
三、文本函数:用于处理表格中的文本数据,例如 LEFT 函数和RIGHT 函数可以截取文本数据的左侧和右侧。
四、日期和时间函数:用于处理表格中的日期和时间数据,例如DATE 函数和 TIME 函数可以计算两个日期或时间之间的差异。
五、查找和引用函数:用于在表格数据中查找和引用特定的值,
例如 VLOOKUP 函数可以在数据中查找匹配的值并返回相应的结果。
以上是表格结构数据函数类型的基本介绍,这些函数可以大大简
化数据的处理和分析,提高工作效率并减少出错率。
值得注意的是,
在使用这些函数时,需要注意数据结构的一致性和正确性,以确保得
出准确、可靠的分析结论。
常用内部函数介绍常用内部函数是指在编程语言中提供给开发者使用的一组预定义的函数,这些函数可以直接在程序中调用,无需开发者自行编写。
常用内部函数通常是编程语言提供的标准库函数或者是常见的第三方库函数。
它们为开发者提供了一系列常用的、经过测试和优化的功能,并且可以大大提高开发效率。
下面将详细介绍一些常用的内部函数。
1. print(函数:print(函数是一种用于打印输出的常用内部函数。
它可以输出字符串、数字以及其他类型的数据,并且可以通过参数设置输出的格式。
2. len(函数:len(函数是一种用于获取长度的常用内部函数。
它可以返回一个字符串、列表、字典或元组的长度。
长度指的是该数据结构中包含的元素的个数。
3. range(函数:range(函数是一种用于生成整数序列的常用内部函数。
它接受一个起始值、一个终止值和一个步长参数,并生成一个符合条件的整数序列。
4. input(函数:input(函数是一种用于接收用户输入的常用内部函数。
它提示用户输入信息,并将用户输入的内容作为字符串返回给程序。
5. type(函数:type(函数是一种用于获取变量类型的常用内部函数。
它可以返回一个变量的数据类型,例如字符串、整数、列表等。
6. str(函数:str(函数是一种用于将其他类型转换为字符串类型的常用内部函数。
它可以将数字、列表、字典等类型的数据转换为字符串类型。
7. int(函数:int(函数是一种用于将字符串或其他类型转换为整数类型的常用内部函数。
它可以将字符串表示的整数、浮点数或其他类型的数据转换为整数类型。
8. float(函数:float(函数是一种用于将字符串或其他类型转换为浮点数类型的常用内部函数。
它可以将字符串表示的浮点数、整数或其他类型的数据转换为浮点数类型。
9. max(函数:max(函数是一种用于获取最大值的常用内部函数。
它可以接受一个或多个参数,并返回其中的最大值。
10. min(函数:min(函数是一种用于获取最小值的常用内部函数。
C语言中的数据结构与算法实现在计算机科学中,数据结构和算法是构建程序的基础。
C语言作为一种强大而广泛使用的编程语言,提供了丰富的库函数和语法特性来支持数据结构和算法的实现。
本文将讨论C语言中常见的数据结构和算法,并通过示例代码来展示其实现方法。
一、线性数据结构1. 数组(Array)数组是C语言中最基本的数据结构之一,能够存储相同类型的数据元素。
通过索引,可以快速访问数组中的任意元素。
以下是一个简单的数组示例:```c#include <stdio.h>int main() {int arr[5] = {1, 2, 3, 4, 5};for(int i=0; i<5; i++) {printf("%d ", arr[i]);}return 0;}```2. 链表(Linked List)链表是一种动态数据结构,由节点组成,并通过指针相互连接。
链表具有灵活性,能够高效地插入和删除节点。
以下是一个简单的链表示例:```c#include <stdio.h>#include <stdlib.h>typedef struct Node {int data;struct Node* next;} Node;int main() {Node* head = NULL;Node* second = NULL;Node* third = NULL;// 分配内存并赋值head = (Node*)malloc(sizeof(Node));second = (Node*)malloc(sizeof(Node));third = (Node*)malloc(sizeof(Node)); head->data = 1;head->next = second;second->data = 2;second->next = third;third->data = 3;third->next = NULL;// 遍历链表Node* ptr = head;while (ptr != NULL) {printf("%d ", ptr->data);ptr = ptr->next;}return 0;}```二、非线性数据结构1. 栈(Stack)栈是一种后进先出(LIFO)的数据结构,只允许在栈的顶部进行插入和删除操作。