计算语言学讲义(03)词法分析(一)
- 格式:pdf
- 大小:609.11 KB
- 文档页数:93



编译原理中的词法分析与语法分析原理解析编译原理是计算机科学中的重要课程,它研究的是如何将源程序翻译成目标程序的过程。
而词法分析和语法分析则是编译过程中的两个重要阶段,它们负责将源程序转换成抽象语法树,为接下来的语义分析和代码生成阶段做准备。
本文将从词法分析和语法分析的原理、方法和实现技术角度进行详细解析,以期对读者有所帮助。
一、词法分析的原理1.词法分析的定义词法分析(Lexical Analysis)是编译过程中的第一个阶段,它负责将源程序中的字符流转换成标记流的过程。
源程序中的字符流是没有结构的,而编程语言是有一定结构的,因此需要通过词法分析将源程序中的字符流转换成有意义的标记流,以便之后的语法分析和语义分析的进行。
在词法分析的过程中,会将源程序中的字符划分成一系列的标记(Token),每个标记都包含了一定的语义信息,比如关键字、标识符、常量等等。
2.词法分析的原理词法分析的原理主要是通过有限状态自动机(Finite State Automaton,FSA)来实现的。
有限状态自动机是一个数学模型,它描述了一个自动机可以处于的所有可能的状态以及状态之间的转移关系。
在词法分析过程中,会将源程序中的字符逐个读取,并根据当前的状态和字符的输入来确定下一个状态。
最终,当字符读取完毕时,自动机会处于某一状态,这个状态就代表了当前的标记。
3.词法分析的实现技术词法分析的实现技术主要有两种,一种是手工实现,另一种是使用词法分析器生成工具。
手工实现词法分析器的过程通常需要编写一系列的正则表达式来描述不同类型的标记,并通过有限状态自动机来实现这些正则表达式的匹配过程。
这个过程需要大量的人力和时间,而且容易出错。
而使用词法分析器生成工具则可以自动生成词法分析器的代码,开发者只需要定义好源程序中的各种标记,然后通过这些工具自动生成对应的词法分析器。
常见的词法分析器生成工具有Lex和Flex等。
二、语法分析的原理1.语法分析的定义语法分析(Syntax Analysis)是编译过程中的第二个阶段,它负责将词法分析得到的标记流转换成抽象语法树的过程。
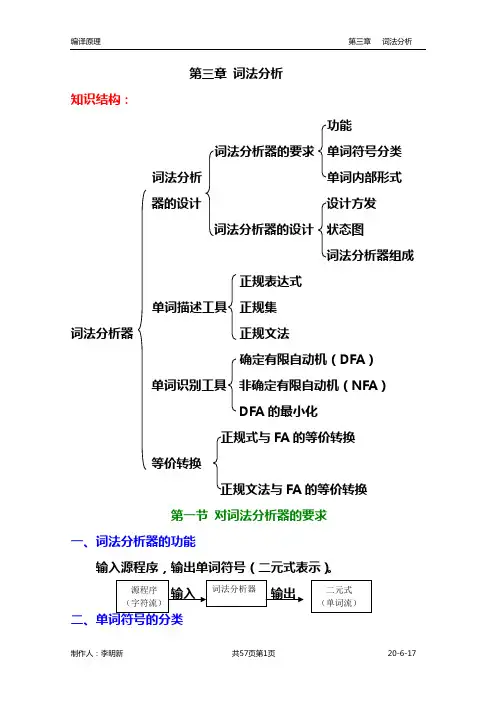
第三章 词法分析知识结构:功能 词法分析器的要求 单词符号分类 词法分析 单词内部形式器的设计 设计方发词法分析器的设计 状态图词法分析器组成正规表达式单词描述工具 正规集词法分析器 正规文法确定有限自动机(DFA )单词识别工具 非确定有限自动机(NFA )DFA 的最小化FA 的等价转换等价转换FA 的等价转换第一节 对词法分析器的要求一、词法分析器的功能输入源程序,输出单词符号(二元式表示)。
关键字:是由程序语言定义的具有固定意义的标识符。
标识符:用来表示各种名字,如变量等。
常数:常数的类型有整型,实型等。
运算符:算术运算符,关系运算符,逻辑运算符。
界限符:逗号,分号等。
三、单词符号内部的表示形式内部的单词符号TOKEN字(二元式),TOKEN字占用机器字的长度,依据信息量的多少而定。
1、TOKEN字结构CLASS:用整数表示。
VALUE:表示单词符号的属性(符号表指针)。
2、TOKEN的作用CLASS:用于语法分析器对源程序结构的分析。
VALUE:用于语义分析器对源程序具体操作的分析。
3、单词种别码划分原则CLASS:关键字,运算符,界限符(编译程序定义的符号)使用一字一种编码。
VALUE值省略。
VALUE:标识符,常数(用户定义的符号),存放符号表常数表的指针。
标识符,常数每一类为一种编码。
例:BEGIN A:= B END;词法分析结果:符号表(BEGIN,---- )Array(A ,K1 ) K1(:= ,--- )(B ,K3 ) K3(END ,--- )(;,--- )四、词法分析器的结构1、一遍扫描(交互式结构)。
2、多遍扫描(独立式结构)。
第二节词法分析器的设计一、设计步骤1、确定词法分析器的接口关系;2、确定单词分类和TOKEN字的结构;3、对每一类单词构造状态转换图;4、根据状态转换图设计算法。
二、功能描述1、组织源程序输入;2、按词法规则拼读单词符号,并转换成二元式;3、删除注解行,空格和无用符号;4、检查词法错误。


编译原理的词法分析与语法分析编译原理是计算机科学中的一门重要课程,它研究如何将源代码转换为可执行的机器代码。
在编译过程中,词法分析和语法分析是其中两个基本的阶段。
本文将分别介绍词法分析和语法分析的基本概念、原理以及实现方法。
1. 词法分析词法分析是编译过程中的第一个阶段,主要任务是将输入的源代码分解成一个个的词法单元。
词法单元是指具有独立意义的最小语法单位,比如变量名、关键字、操作符等。
词法分析器通常使用有限自动机(finite automaton)来实现。
在词法分析的过程中,需要定义词法规则,即描述每个词法单元的模式。
常见的词法规则有正则表达式和有限自动机。
词法分析器会根据这些规则匹配输入的字符序列,并生成相应的词法单元。
2. 语法分析语法分析是编译过程中的第二个阶段,它的任务是将词法分析器生成的词法单元序列转换为语法树(syntax tree)或抽象语法树(abstract syntax tree)。
语法树是源代码的一种抽象表示方式,它反映了源代码中语法结构和运算优先级的关系。
语法分析器通常使用上下文无关文法(context-free grammar)来描述源代码的语法结构。
常见的语法分析算法有递归下降分析法、LR分析法和LL分析法等。
递归下降分析法是一种自顶向下的分析方法,它从源代码的起始符号开始,递归地展开产生式,直到匹配到输入的词法单元。
递归下降分析法的实现比较直观,但对于左递归的文法处理不方便。
LR分析法是一种自底向上的分析方法,它使用一个自动机来分析输入的词法单元,并根据文法规则进行规约操作,最终生成语法树。
常见的LR分析法有LR(0)、SLR、LR(1)和LALR等。
LL分析法是一种自顶向下的分析方法,它从源代码的起始符号开始,预测下一个要匹配的词法单元,并进行相应的推导规则。
LL分析法常用于编程语言中,如Java和Python。
3. 词法分析和语法分析的关系词法分析是语法分析的一个子阶段,它为语法分析器提供了一个符号序列,并根据语法规则进行分析和匹配。


编译原理词法分析与语法分析在计算机科学领域,编译器是一个非常重要的工具,它将高级程序语言转换为能够被计算机处理的低级机器语言。
编译器的设计与开发离不开以下两个主要部分:词法分析和语法分析。
本文将着重介绍编译原理中的词法分析和语法分析的定义、原理、方法以及它们之间的关系。
一、词法分析词法分析是编译器的第一个阶段,负责将源代码转化为一个个“词法单元”,也称为“记号”。
词法单元是计算机程序中的最小语义单位,例如变量名、关键字、操作符等。
词法分析器会从源代码中连续读取字符,并将其组成具有独立意义的词法单元。
词法分析的主要任务是识别代码中的词法单元,并将其分类。
它采用正则表达式来定义词法单元的模式,并通过有限状态自动机(FSM)进行匹配。
以下是词法分析的一般步骤:1. 输入源代码,逐字符读取。
2. 将字符组合成词法单元。
3. 跳过空格、换行符等不相关的字符。
4. 使用正则表达式判断词法单元的类型。
5. 将识别出的词法单元传递给语法分析阶段。
二、语法分析语法分析是编译器的第二个阶段,它将从词法分析器获得的词法单元串转换为语法树。
语法树是一种树状结构,用于表示程序的语法结构。
它通过分析词法单元之间的关系来检查程序是否符合语法规则。
在语法分析过程中,会根据源代码中的语法规则使用上下文无关文法(Context-Free Grammar)进行分析。
常用的语法分析算法有自顶向下分析(Top-Down Parsing)和自底向上分析(Bottom-Up Parsing)。
自顶向下分析是从语法的起始符号开始,逐步展开已识别的符号,直到生成源代码。
这种分析方法常用的算法有LL(k)和递归下降(Recursive Descent)。
自顶向下分析器按照语法规则从上到下预测并展开符号。
自底向上分析是从词法单元串的底部开始,逐步归约已识别的符号,直到生成源代码。
这种分析方法常用的算法有LR(k)和LALR(k)。
自底向上分析器按照语法规则从下往上扫描,并进行归约操作。


词法分析知识点总结一、词法分析的基本概念1. 词法分析的定义词法分析是自然语言处理和计算机语言处理中的一个重要领域,它涉及到研究自然语言的词法结构、词法规则、单词辨识和语言模式匹配等内容。
通过词法分析,我们可以更好地理解和解释文本中的语言现象,处理和管理大量的文本数据,并且可以进行文本分类、关键词提取、信息检索和语言模式匹配等各种应用。
2. 词法分析的基本任务词法分析的基本任务包括:单词辨识、分词和断句。
单词辨识是指根据相应的词法规则将文本中的单词和标点符号识别出来;分词是指将文本按照相应的语言规则进行分割,形成一个个有意义的词单元;断句是指将文本按照相应的语言规则进行分割,形成一个个有意义的句子。
3. 词法分析的基本方法词法分析的基本方法包括:基于规则的词法分析和基于统计的词法分析。
基于规则的词法分析是指根据语言的词法规则和语法规则,通过对文本进行分析和处理,得到相应的词法信息;基于统计的词法分析是指根据大量的语料库数据,通过统计分析和机器学习等技术,得到文本中的词法信息。
4. 词法分析的基本原理词法分析的基本原理包括:正则表达式、自动机理论和语言模型。
正则表达式是一种描述文本模式的表达式,通过对文本进行匹配和识别,得到相应的词法信息;自动机理论是一种描述文本结构的理论,通过对文本进行分析和处理,得到相应的词法信息;语言模型是一种描述文本语言现象的模型,通过对文本进行建模和分析,得到相应的词法信息。
二、词法分析的相关知识点1. 词法规则的设计词法规则是词法分析的基础,它包括:单词的形态、语义和用法规则。
单词的形态规则是指单词的结构、词根、词缀、词性和语法等规则;单词的语义规则是指单词的含义、词义和搭配等规则;单词的用法规则是指单词的用法、谓词、主语、宾语和修饰等规则。
2. 分词和断句的处理方法分词和断句是词法分析的基本任务,它包括:正向最大匹配、逆向最大匹配、最短路径匹配和动态规划匹配。
正向最大匹配是指从文本的左边开始匹配,匹配长度最大的词;逆向最大匹配是指从文本的右边开始匹配,匹配长度最大的词;最短路径匹配是指通过路径规划算法,得到最短路径匹配结果;动态规划匹配是指根据文本的属性和上下文,得到最佳的匹配结果。
编译原理基础:词法分析与语法分析一、引言- 编译器是一种将高级语言翻译成机器语言的重要工具,是计算机科学中的核心概念之一。
编译器的基本工作分为两个阶段:词法分析和语法分析。
本文将详细介绍和分析这两个步骤的内容和流程。
二、词法分析1. 定义- 词法分析是编译器的第一个阶段,也是最基本的阶段。
它负责对源代码进行词法单位的划分,生成词法单元流。
每个词法单元包括一个标识符和一个属性值。
2. 步骤- 读入源代码:编译器首先从源代码文件中读入整个代码内容。
- 去除空格和注释:通过正则表达式或其他方法,编译器去除源代码中的空格和注释,以便更好地处理剩余的代码。
- 划分词法单元:编译器根据一定的规则将代码划分为不同的词法单元,如关键字、标识符、运算符、常量等。
- 构建符号表:编译器将关键字和标识符添加到符号表中,以便后续的语法分析和语义分析过程中使用。
三、语法分析1. 定义- 语法分析是编译器的第二个阶段,它将词法分析生成的词法单元流作为输入,根据语法规则生成语法树或抽象语法树。
2. 步骤- 定义语法规则:编译器根据语言的语法规范定义语法规则,通常使用上下文无关文法(Context-Free Grammar)来描述。
- 构建语法分析器:编译器使用递归下降法或者LR分析法等算法来实现语法分析器。
递归下降法通过递归地调用子过程来实现语法分析,而LR分析法则通过建立一个有限状态机来分析源代码。
- 生成语法树或抽象语法树:编译器根据语法规则和输入的词法单元流,生成对应的语法树或抽象语法树。
语法树表示源代码的语法结构,抽象语法树还会剔除掉不必要的细节。
- 错误处理:在生成语法树或抽象语法树的过程中,编译器会检测到一些语法错误。
此时,编译器会输出错误信息,并尽可能恢复到正常的语法分析流程。
四、词法分析与语法分析的关系- 词法分析和语法分析是紧密关联的两个阶段。
词法分析阶段提供给语法分析阶段的词法单元流作为输入,语法分析阶段通过分析词法单元的序列来理解源代码的语法结构。