第9章_蛮力_贪婪法_数据结构与算法.pptx
- 格式:pptx
- 大小:2.21 MB
- 文档页数:28

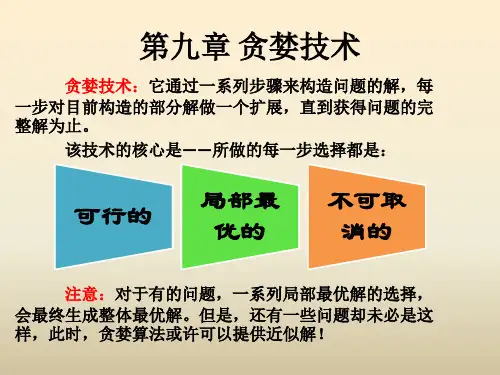

第 1 章 贪婪算法虽然设计一个好的求解算法更像是一门艺术,而不像是技术,但仍然存在一些行之有效的能够用于解决许多问题的算法设计方法,你可以使用这些方法来设计算法,并观察这些算法是如何工作的。
一般情况下,为了获得较好的性能,必须对算法进行细致的调整。
但是在某些情况下,算法经过调整之后性能仍无法达到要求,这时就必须寻求另外的方法来求解该问题。
本章首先引入最优化的概念,然后介绍一种直观的问题求解方法:贪婪算法。
最后,应用该算法给出货箱装船问题、背包问题、拓扑排序问题、二分覆盖问题、最短路径问题、最小代价生成树等问题的求解方案。
1.1 最优化问题本章及后续章节中的许多例子都是最优化问题( optimization problem),每个最优化问题都包含一组限制条件( c o n s t r a i n t)和一个优化函数( optimization function),符合限制条件的问题求解方案称为可行解( feasible solution),使优化函数取得最佳值的可行解称为最优解(optimal solution)。
例1-1 [ 渴婴问题] 有一个非常渴的、聪明的小婴儿,她可能得到的东西包括一杯水、一桶牛奶、多罐不同种类的果汁、许多不同的装在瓶子或罐子中的苏打水,即婴儿可得到n 种不同的饮料。
根据以前关于这n 种饮料的不同体验,此婴儿知道这其中某些饮料更合自己的胃口,因此,婴儿采取如下方法为每一种饮料赋予一个满意度值:饮用1盎司第i 种饮料,对它作出相对评价,将一个数值si 作为满意度赋予第i 种饮料。
通常,这个婴儿都会尽量饮用具有最大满意度值的饮料来最大限度地满足她解渴的需要,但是不幸的是:具有最大满意度值的饮料有时并没有足够的量来满足此婴儿解渴的需要。
设ai是第i 种饮料的总量(以盎司为单位),而此婴儿需要t 盎司的饮料来解渴,那么,需要饮用n种不同的饮料各多少量才能满足婴儿解渴的需求呢?设各种饮料的满意度已知。



中国数学建模-编程交流-贪婪算法feifei7 重登录隐身用户控制面板搜索风格论坛状态论坛展区社区服务社区休闲网站首页退出>> VC++,C,Perl,Asp...编程学习,算法介绍. 我的收件箱(0)中国数学建模→学术区→编程交流→贪婪算法您是本帖的第672 个阅读者* 贴子主题:贪婪算法b等级:职业侠客文章:472积分:951门派:黑客帝国注册:2003-8-28第11 楼1.3.6 最小耗费生成树在例1 - 2及1 - 3中已考察过这个问题。
因为具有n个顶点的无向网络G的每个生成树刚好具有n-1条边,所以问题是用某种方法选择n-1条边使它们形成G的最小生成树。
至少可以采用三种不同的贪婪策略来选择这n-1条边。
这三种求解最小生成树的贪婪算法策略是:K r u s k a l算法,P r i m算法和S o l l i n算法。
1. Kruskal算法(1) 算法思想K r u s k a l算法每次选择n-1条边,所使用的贪婪准则是:从剩下的边中选择一条不会产生环路的具有最小耗费的边加入已选择的边的集合中。
注意到所选取的边若产生环路则不可能形成一棵生成树。
Kr u s k a l算法分e 步,其中e 是网络中边的数目。
按耗费递增的顺序来考虑这e条边,每次考虑一条边。
当考虑某条边时,若将其加入到已选边的集合中会出现环路,则将其抛弃,否则,将它选入。
考察图1-12a 中的网络。
初始时没有任何边被选择。
图13-12b 显示了各节点的当前状态。
边(1 ,6)是最先选入的边,它被加入到欲构建的生成树中,得到图1 3 - 1 2 c。
下一步选择边(3,4)并将其加入树中(如图1 3 -1 2 d所示)。
然后考虑边( 2,7 ),将它加入树中并不会产生环路,于是便得到图1 3 - 1 2 e。
下一步考虑边(2,3)并将其加入树中(如图1 3 - 1 2f所示)。
在其余还未考虑的边中,(7,4)具有最小耗费,因此先考虑它,将它加入正在创建的树中会产生环路,所以将其丢弃。




贪婪算法(贪婪算法(GreedyAlgorithm)Greedy Algorithm《数据结构与算法——C语⾔描述》图论涉及的三个贪婪算法1. Dijkstra 算法2. Prim 算法3. Kruskal 算法Greedy 经典问题:coin change在每⼀个阶段,可以认为所作决定是好的,⽽不考虑将来的后果。
如果不要求最对最佳答案,那么有时⽤简单的贪婪算法⽣成近似答案,⽽不是使⽤⼀般说来产⽣准确答案所需的复杂算法。
所有的调度问题,或者是NP-完全的,或者是贪婪算法可解的。
NP-完全性:计算复杂性理论中的⼀个重要概念,它表征某些问题的固有复杂度。
⼀旦确定⼀类问题具有NP完全性时,就可知道这类问题实际上是具有相当复杂程度的困难问题。
贪⼼算法是⼀类算法的统称10.1.1 ⼀个简单的调度问题将最后完成时间最⼩化这个问题是NP-完全的。
因此,将++最后完成时间最⼩化++显然⽐++平均完成时间最⼩++化困难得多。
10.1.2 Huffman 编码让字符代码的长度从字符到字符是变化不等,同时保证经常出现的字符其代码更短。
最优编码的树将具有的性质:所有结点或者是树叶,或者有两个⼉⼦。
字符代码的长度是否不相同并不要紧,只要没有字符代码是别的字符代码的前缀即可。
基本的问题:找到总价值(编码总长度)最⼩的满⼆叉树。
Huffman 算法因为每⼀次合并都不进⾏全局的考虑,只是选择两棵最⼩的树,所以该算法是贪⼼算法。
由此可见,贪⼼算法是⼀类算法的统称。
在⽂件压缩这样的应⽤中,实际上⼏乎所有的运⾏时间都花费在读⼊⽂件和写⽂件所需的磁盘 I/O 上。
伪代码1. ⽣成 Huffman 树while(minHeap.size() > 1){tree->left = minHeap.get()tree->right = minHeap.get()tree->frequence = tree->left->frequence + tree->right->frequenceminHeap.insert(tree);}huffmanTree = minHeap.get();2. 从 Huffman 树到 Huffman 编码(递归调⽤)字符集⼀般是常数的数量级,所以这⾥使⽤递归虽不是最优解,但⾜矣解此题。
