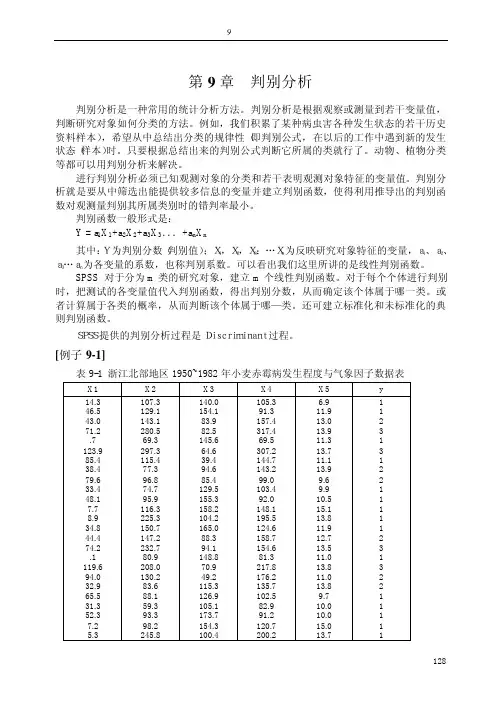
spss判别分析
- 格式:ppt
- 大小:340.50 KB
- 文档页数:49


判别分析作为一种多元分析技术应用相当广泛,和其他多元分析技术不同,判别分析并没有将降维作为主要任务,而是通过建立判别函数来概括各维度之间的差异,并且根据这个判别函数,将新加入的未知类别的样本进行归类,从这个角度讲,判别分析是从另一个角度对数据进行归类。
判别分析由于要建立判别函数,因此和回归分析类似,也有因变量和自变量,并且因变量应为分类变量,这样才能够最终将数据进行归类,而自变量可以是任意尺度变量,分类变量需要设置为哑变量。
既然和回归分析类似,那么判断分析也有一定的适用条件,这些适用条件也和回归分析类似1.自变量和因变量的关系符合线性假定违反时,可以使用曲线直线化、二次判别分析等方法2.因变量取值是独立的,并且必须事先就已确定这个很好理解,既然最终要归类,就要实现确定归为哪几类3.自变量服从多元正态分布违反时影响不大4.自变量各组间方差齐性,协方差矩阵齐违反时,可使用经典判别分析、非参数判别分析、距离判别分析5.自变量间不存在共线性违反时可以采用类似于线性回归中对共线性的处理,如逐步判别分析,岭判别分析等,和线性回归一样,共线性可以使判别函数的系数发生变化,但是对于判别结果则影响不大判别分析根据不同的判别准则可以分为经典判别分析、贝叶斯判别分析、非参数判别分析等,SPSS中将其和聚类共用一个过程,下面我们来介绍这几种方法在SPPS中的应用一、经典判别分析收集了一些鸢尾花的数据,其中spno为类别,有三个水平,其余四个为变量,想通过此数据进行判别分析,建立判别函数以对花进行区分,数据组成如下分析—分类—判别二、贝叶斯判别分析贝叶斯体系的主要思想是根据先验概率去推证后验概率也就是实验结果,将其引入判别分析之后,就变成计算后验概率及错判率,用最大后验概率来进行判别,并使错判率最小。
在SPSS中,贝叶斯判别和经典判别只是设置上稍有不同。






专题16 用SPSS进行判别分析1 用默认方法作判别分析2 选项的设置简介1 用默认方法作判别分析用默认方法作判别分析,可按如下步骤进行。
①建立或读入数据文件在数据窗中输入待分析的数据,或利用File菜单中的Open功能打开已存在的数据文件。
②展开主对话框在SPSS主界面中依次逐层选择“Analyze”、“Classify”、“Discriminant”,展开判别分析主对话框(如图)。
③选择分类变量及其取值范围在如图14.1的主对话框左边的矩形框中选定分类变量,并用上面一个箭头按钮将其移到“Grouping Variable”框中。
然后用其下面的“Define Range”按钮打开如图14.2的对话框。
分别在“Minimum”和“Maximum”后面的矩形框中键入分类变量的最大值与最小值,然后按“Continue”按钮返回主对话框。
分类变量须是数值型的,其值必须是整数,每个值代表一类,如1代表健将、2代表一级运动员、3代表二级运动员。
④选择判别变量在主对话框左边的矩形框中选择判别变量,并用下面一个箭头按钮将它们移到“Independents”矩形框中。
⑤选择是否作逐步判别若不用逐步判别筛选变量,在主对话框中选择“Enter independents together”。
若作逐步判别,则选择“Use stepwise method”。
⑥运行程序检查所选变量是否有误,若选择有误,则选定错误变量,用边上的箭头按钮将其移出。
若变量选择无误,按“OK”按钮即可运行程序。
返回2 选项的设置简介①在主对话框中单击“Statistics”按钮可以打开选择输出统计量的对话框。
●选定“Means”可得到各类的均数、标准差等统计量●选定“Univariate ANOVAs”可得到各单变量的方差分析●选定“Box’s M”可得到各类协差阵相等性的Box检验●选择“Fisher’s”可得到费歇的线性分类函数●选定“Unstandardized”可以得到非标准化的典型判别函数系数●选定“Within-groups covariance”可以得到合并组内协差阵。
判别分析1.基本理解判别分析用于处理已知分类情况的数据集,将未知分类数据归入已知的分类中。
判别分析过程基于对变量的函数组合,变量应能够充分地体现各个类别之间的差异。
从已知变量类别的样本中拟合判别函数,后根据判别函数将新样本进行类别归类。
在P维空间中,有K个相关已知类别的总体G1,G2,G3,....Gk,单个的预测样本记为Xi =(Xi1,Xi2,Xi3,....,Xip),i=1,2,3,....n,样本属于K个总体的一个,P个变量为判别指标,判别函数就是确定样本属于哪一类别。
判别函数的两种判别方法:(1)贝叶斯判别:是一种概率型的判别函数,开始需要知道各个类别的先验概率或分布密度,后计算每个样本属于某个类别的最大概率或最小错判损失,并以此归类。
类别概率计算公式:P(Gi|D)=P(D|Gi)P(Gi)/ΣP(D|Gi)P(Gi),其中P(Gi)为属于i类的先验概率,P(D|Gi)为在第i类中得D分的条件概率,而P(Gi|D)为在第i类中得D分的后验概率。
(2)Fisher判别:是一种依据方差分析原理建立的判别方法,基本思路为投影。
对P维空间中的点Xi =(Xi1,Xi2,Xi3, (X)in),i=1,2,3,....,n,找到一组线性函数Ym (Xi)=×B,m=1,2,3,....,m,一般m<p,依据组间均方差与组内均方差之比最大的原则,选择最优的线性函数。
判别分析的一般步骤:(1):依据已知类别的观测集建立分类规则或判别规则。
(2):运用所建规则对样本进行分类检验,得到各样本的判别准确率。
(3):选择拥有较高准确率的判别规则,应用于新样本的类别判断。
2.判别分析操作步骤判别函数第一步:首先将已确定分类情况的数据到spss软件中,点击分析、分类、判别式。
图1第一步第二步:进入判别分析勾选框后首先将变量列表中的变量放入右侧的变量框中,将因变量(已知分组情况变量)放入分组变量框并定义好范围,点击继续,将自变量放入自变量框中。
判别分析实验报告 SPSS一、实验目的判别分析是一种用于分类和预测的统计方法。
本次实验旨在通过使用 SPSS 软件,掌握判别分析的基本原理和操作流程,能够运用判别分析方法对实际数据进行分类,并对分类结果进行评估和解释。
二、实验数据本次实验使用的数据集包含了两个类别(类别 A 和类别 B)的样本,每个样本具有若干个特征变量,如年龄、收入、教育程度等。
数据集共有 200 个样本,其中类别 A 有 100 个样本,类别 B 有 100 个样本。
三、实验步骤1、数据导入首先,打开 SPSS 软件,选择“文件”菜单中的“打开”选项,将实验数据文件导入到 SPSS 中。
2、变量定义在 SPSS 数据视图中,对各个变量进行定义,包括变量名称、变量类型、变量标签等。
3、判别分析操作选择“分析”菜单中的“分类”子菜单,然后点击“判别分析”选项。
在弹出的判别分析对话框中,将类别变量选入“分组变量”框中,将其他特征变量选入“自变量”框中。
4、选择判别方法SPSS 提供了多种判别方法,如费希尔判别法、贝叶斯判别法等。
本次实验选择费希尔判别法。
5、模型评估在判别分析结果中,查看判别函数的系数、判别函数的显著性检验、分类结果的准确性等指标,以评估模型的性能。
四、实验结果与分析1、判别函数系数判别函数的系数反映了各个自变量对判别函数的贡献程度。
通过查看系数的大小和符号,可以了解各个变量在区分不同类别中的重要性。
例如,年龄变量的系数为正,说明年龄越大,越有可能属于某个类别;而收入变量的系数为负,说明收入越低,越有可能属于另一个类别。
2、判别函数的显著性检验通过对判别函数的显著性检验,可以判断判别函数是否能够有效地区分不同的类别。
如果检验结果显著,说明判别函数具有统计学意义,可以用于分类。
3、分类结果SPSS 会给出每个样本的分类结果,以及分类的准确性。
通过比较实际类别和预测类别,可以评估模型的分类效果。
如果分类准确性较高,说明模型能够较好地对样本进行分类;如果分类准确性较低,则需要进一步分析原因,可能是数据质量问题、变量选择不当或者判别方法不合适等。
SPSS判别分析SPSS(Statistical Package for the Social Sciences)是一款广泛使用的统计分析软件,也提供了强大的判别分析功能。
本文将介绍SPSS中判别分析的步骤、应用以及结果的解读。
一、判别分析的步骤1.数据准备:首先,将已知类别的样本数据录入SPSS中,每个样本对应一个实例,每个实例有一组预测变量和一个类别变量。
2.变量选择:选择要作为预测变量的特征或属性,并将其加入模型。
通常,只有连续型或分类型的自变量(预测变量)可以用于判别分析。
3.数据分割:将已知类别的样本数据分为训练集和测试集,一般按照70%的比例划分。
4.判别模型:使用SPSS中的判别分析功能建立判别模型。
在SPSS中,可以通过路径“分析-分类-判别”打开判别分析对话框。
5.模型评估:使用测试集来评估模型的准确性和性能。
可以查看分类结果的混淆矩阵,计算预测准确率、召回率、F1值等指标。
6.结果解读:根据模型的解读提示,分析各个预测变量对判别结果的重要性,找出主要影响判别的变量。
二、判别分析的应用领域判别分析广泛应用于各个领域,包括社会科学、医学、市场营销等。
以下是几个常见的应用案例:1.疾病诊断:通过患者的生物特征(如血液检测结果、基因表达谱等)来判断是否患有其中一种疾病。
2.风险评估:用于评估贷款申请者的信用风险,根据一些个人特征(如年龄、收入、居住地等)来预测违约概率。
3.市场细分:根据消费者的特征(如年龄、性别、购买行为等)将市场区分为不同的细分市场,以制定更精准的市场营销策略。
4.情感识别:通过分析文本数据(如社交媒体评论、产品评论等)来判断用户的情感倾向,以评估产品或服务的满意度。
三、结果解读判别分析的结果包括判别函数、判别系数和预测结果。
判别函数可以看作是一组线性加权的预测变量,用于将实例划分到不同的类别中。
判别系数表示了每个预测变量对判别结果的贡献程度,可以用于解释影响判断的主要变量。
SPSS数据的判别分析判别分析(Discriminant Analysis)是一种统计分析方法,用于确定一组变量如何能够最好地区分或判别不同的群体。
该方法可以用于解决分类问题,即将多个已知类别的观测对象分配到新的未知类别中。
SPSS是一种功能强大的统计软件,可以进行各种统计分析,包括判别分析。
在SPSS中,进行判别分析的步骤如下:1.打开SPSS软件并导入数据集。
2.选择“分析”菜单下的“判别分析”选项。
3.在弹出的对话框中,将要分类的变量(被解释变量)放入“因子”框中,用于判别的变量(解释变量)放入“变量”框中。
点击“分类图”按钮可以选择是否绘制分类图表。
4.点击“确定”按钮,进行判别分析。
判别分析的目标是找到一个线性组合,能够最好地将样本区分开来。
在SPSS的结果中,输出了多种统计量,包括判别系数,判别函数的系数,标准化判别函数系数等信息。
这些统计量可以帮助我们理解分类问题的解释力和判别函数的重要性。
判别函数是判别分析的核心输出,它可以根据变量的值来预测被解释变量的分类。
判别函数通常以线性函数的形式表示,例如:D = a1X1 + a2X2 + ... + anXn + b其中,D是判别函数的值,X1, X2, ..., Xn是解释变量的值,a1,a2, ..., an是判别函数的系数,b是常数项。
通过计算判别函数的值,就可以将新的观测对象分配到相应的分类中。
在SPSS中,可以使用“分类评估”功能来检验判别函数的准确性。
该功能可以计算被正确分类的对象的百分比,以及各个分类中的正确分类的百分比。
同时,SPSS还提供了一些可视化工具来帮助我们理解判别分析的结果。
例如,通过绘制分类图表,可以直观地了解不同分类之间的分隔情况。
此外,还可以通过散点图来展示解释变量和被解释变量之间的关系,以及如何影响判别函数的值。
判别分析在实际应用中具有广泛的应用。
例如,在医学领域,可以使用判别分析将患者分为不同的疾病分类,以便进行诊断和治疗。
用SPSS软件来实现判别分析判别分析是一种统计模型和机器学习方法,可用于研究两个或更多群体之间的差异。
通过使用SPSS软件,我们可以对数据进行判别分析,并评估自变量的贡献程度,以及如何使用这些自变量来预测因变量。
要进行判别分析,首先需要准备数据。
在SPSS中,数据应该被整理为一个数据框,每一行代表一个样本,每一列代表一个特征或变量。
在判别分析中,我们需要明确选择一个因变量和若干个自变量。
在SPSS软件中,进行判别分析的步骤如下:步骤1:导入数据在SPSS中,首先需要导入我们的数据集。
点击“文件(File)”选项卡,选择“打开(Open)”,然后选择数据文件。
确保数据文件是一个包含正确数据格式的数据框。
如果数据集过大,可以选择只导入部分数据进行分析,可以通过“变量视图(Variable View)”进行选择。
步骤2:选择判别分析方法点击“分析(Analyze)”选项卡,选择“描述统计(Descriptive Statistics)”,选择“判别(Discriminant)”。
步骤3:设置因变量和自变量在弹出的“判别函数(Discriminant Function)”对话框中,将被解释的变量(因变量)从左边的“因变量(Dependent)”栏拖到右边的“因变量(Dependent)”栏。
然后,将讲自变量(特征)从左边的“自变量(Independent(s))”栏拖到右边的“自变量(Independent(s))”栏。
函数使用的哪些变量将取决于数据中可用的变量数。
步骤4:选择分类方法在“类型(Method)”选项中,选择判别分析的分类方法。
SPSS提供了两种方法:“协方差矩阵相等(Covariance matrices equal)”和“协方差矩阵不等(Covariance matrices not equal)”。
前者使用默认参数,即假设所有群体具有相同的协方差矩阵。
后者提供了更具灵活性的选项,可以允许不同群体拥有不同的协方差矩阵。