监督分类
- 格式:doc
- 大小:33.50 KB
- 文档页数:2

监督分类实验报告监督分类实验报告一、引言监督分类是机器学习领域中的一项重要任务,它的目标是根据已知的样本和标签,构建一个能够自动对新样本进行分类的模型。
在本次实验中,我们使用了一个基于监督学习的分类算法,并通过对不同数据集的实验进行评估,来探索该算法的性能和适用范围。
二、数据准备在实验中,我们使用了两个不同的数据集,分别是鸢尾花数据集和手写数字数据集。
鸢尾花数据集包含了150个样本,每个样本有4个特征,分别是花萼长度、花萼宽度、花瓣长度和花瓣宽度。
手写数字数据集则包含了1797个样本,每个样本是一个8x8的灰度图像,表示了一个手写数字。
三、实验方法我们选择了支持向量机(SVM)作为分类算法,并使用Python中的scikit-learn 库进行实现。
SVM是一种二分类模型,通过在特征空间中构建一个最优超平面来实现分类。
在实验中,我们将SVM应用于鸢尾花数据集和手写数字数据集,并对其进行了以下几个方面的评估。
1. 特征选择在实验中,我们首先进行了特征选择,以确定对于不同数据集来说,哪些特征是最具有区分性的。
通过计算特征的方差和相关系数等指标,我们确定了鸢尾花数据集的四个特征都是有用的,而手写数字数据集的某些特征则可以被忽略。
2. 模型训练在特征选择之后,我们使用了80%的数据作为训练集,剩余的20%作为测试集。
通过调整SVM的参数,如核函数类型、正则化参数等,我们训练了不同的模型,并选择了最优模型进行评估。
3. 模型评估为了评估模型的性能,我们使用了准确率、召回率和F1值等指标。
准确率表示模型正确分类的样本比例,召回率表示模型正确预测正例的能力,而F1值则综合考虑了准确率和召回率。
通过计算这些指标,我们可以对模型的分类能力进行全面的评估。
四、实验结果与分析在鸢尾花数据集上,我们的SVM模型达到了97%的准确率,表现出很好的分类能力。
然而,在手写数字数据集上,模型的准确率仅为90%,略低于我们的期望。

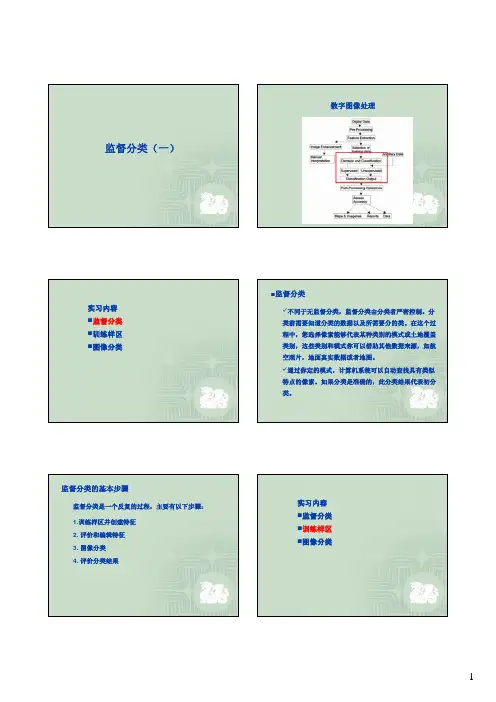
监督分类(一)数字图像处理实习内容 监督分类 训练样区 图像分类 监督分类9不同于无监督分类,监督分类由分类者严密控制。
分类前需要知道分类的数据以及所需要分的类。
在这个过程中,您选择像素能够代表某种类别的模式或土地覆盖类别,这些类别和模式你可以借助其他数据来源,如航空照片,地面真实数据或者地图。
9通过你定的模式,计算机系统可以自动查找具有类似特点的像素。
如果分类是准确的,此分类结果代表初分类。
监督分类的基本步骤监督分类是一个反复的过程,主要有以下步骤:1.训练样区并创建特征2. 评价和编辑特征3. 图像分类4. 评价分类结果实习内容 监督分类 训练样区 图像分类怎样定义训练样本?训练样本就是选择一组像素代表一定潜在类别。
在ERDAS image 中,用户可以选择以下方法完成:¾通过矢量层¾通过的AOI¾通过特定区域具有相似光谱特征的一组连续像素¾通过专题栅格层的某个类别,例如:无监督分类的输出结果打开germtm.img启动AOI 工具. 单击the AOI style 按纽设置AOI前景色和背景色为可识别的颜色尝试其他光谱颜色分配R: 4; G:5; B:3启动Classifier /Signature Editor应该创建多边形AOI 工具在图像上暗蓝色区域创建一AOI (可根据需要放大图像).在Signature Editor窗口采用Add AOI to signature按纽,添加水域样区1水域样区1找到另外一处水域样本,采用AOI growth tool添加单击AOI growth 按钮, 然后单击样本的中间可以自动产生复杂的多边形!单击Region Growing Properties 按钮在Region Growing Properties Dialog 调整AOI包含更多更纯的样本区,变换the Area and Spectral Distance, 然后单击Redo直到满意为止.在signature editor窗口添加第2个水域样本区融合相似的训练样本区融合相似的训练样本区如果此特征被应用,输出的分类结果如何?选择signature “water”View…/ Image Alarm…,在signature alarm dialog单击“OK”.对植被重复同样的步骤找出一块红色区域作sample 1 of forest创建一个仅包含植被的AOI ,并添加为特征区域找出一块亮红色区域作为the sample 2 of forest创建一个仅包含亮红色区域的AOI (采用polygon tool or AOI growth tool)将AOI sample 2 添加为植被的另外一个特征区找出一块暗红色区域作为the sample 3of forest创建一个仅包含暗红色区域的AOI (采用polygon tool or AOI growth将这三个植被样区融合为一个新特征命名为forest, 并将其颜色改为暗绿色删除以上最初的三个植被样本区选择“water”及“forest”signatures采用Image alarm 查看哪些象素被各自分类到water (light blue) 和forest(dark green)勾选the indicate overlap 并设置重叠颜色为黑色对农田(farmland)重复同样的步骤找出一块亮绿色区域作sample 1 of farmland创建一个仅包含farmland的AOI ,并添加为特征区域找出并添加farmland的另外一块样本区域将这两个农田(farmland)样区融合为一个新特征命名为farmland,并将其颜色改为黄色删除以上最初的二个农田样本区选择所有特征区,再次采用Image alarm查看潜在的分类区及分类重叠区对城镇居民点(urban)重复同样的步骤找出一块亮蓝色区域作sample 1 of urban创建一个仅包含urban的AOI ,并添加为特征区域融合相类似区域,并重新设置名称和颜色对农村居民点(suburban)重复同样的步骤找出一块红色和蓝色混合区域作为suburban的样本区创建一个仅包含suburban的AOI ,并添加为特征区域融合相类似区域,并重新设置名称和颜色选择所有signatures再次采用Image alarm 查看潜在的分类区和重叠区域仔细查找没有被分类的像素将白色和亮绿色混合区域设为裸土(bare soil)的样本区创建一个仅包含bare soil的AOI ,并添加为特征区域融合相类似区域,并重新设置名称和颜色再次, 选择signatures再次采用Image alarm 查看潜在的分类区和重叠区域仔细查找没有被分类的像素,并添加其他signatures重置class value“class value”为相应地物类分类图像的像元数.采用“class value”升序(ascending order)重置signature顺序保存signature file采用supclass.sig保存signature file保存AOI file以supclass.aoi为文件名保存AOI file实习内容监督分类训练样区图像分类执行监督分类(supervised classification)选择所有signaturesClassify…/ Supervised…设置:-Output file: supclass.img-Non-parametric Rule: Parallelepiped-Overlap Rule: Parametric Rule-Unclassified Rule: Parametric RuleParametric Rule: MaximumLikelihood单击Ok 开始classification!制作监督分类专题图(supclass.img)Save your AOI file as supclass_<UBITname>.aoi in assignment folder作业在你的作业文件夹中包括以下三个文件:Output Cluster File: supclass.imgSignature File: supclass.sigMap Composition File: supclass.map结束!。
影像的分类可分为监督与非监督分类。
监督分类器根据其原理有基于传统统计分析的、基于神经网络的、基于模式识别的等。
本专题以ENVI的监督与非监督分类的实际操作为例,介绍这两种分类方法。
有以下内容组成:∙ ∙ ●非监督分类∙ ∙ ●监督分类∙ ∙ ●分类后处理非监督分类非监督分类:也称为聚类分析或点群分类。
在多光谱图像中搜寻、定义其自然相似光谱集群的过程。
它不必对影像地物获取先验知识,仅依靠影像上不同类地物光谱(或纹理) 信息进行特征提取,再统计特征的差别来达到分类的目的,最后对已分出的各个类别的实际属性进行确认。
目前比较常见也较为成熟的是ISODATA、K-Mean和链状方法等。
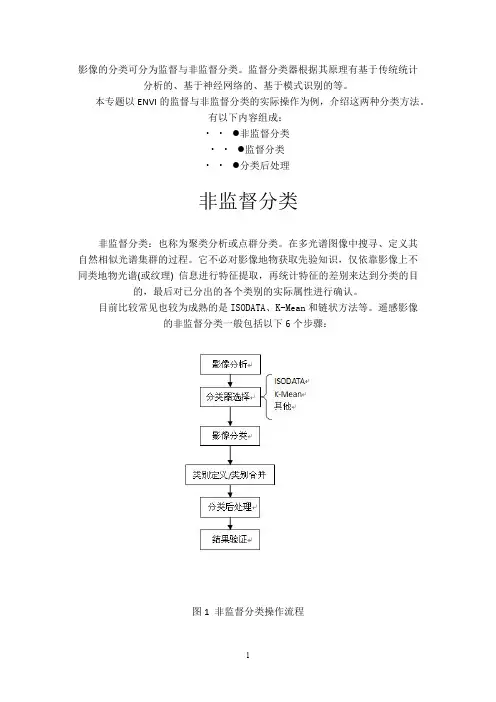
遥感影像的非监督分类一般包括以下6个步骤:图1 非监督分类操作流程1、影像分析大体上判断主要地物的类别数量。
一般监督分类设置分类数目比最终分类数量要多2-3倍为宜,这样有助于提高分类精度。
本案例的数据源为ENVI自带的Landsat tm5数据Can_tmr.img,类别分为:林地、草地/灌木、耕地、裸地、沙地、其他六类。
确定在非监督分类中的类别数为15。
2、分类器选择目前非监督分类器比较常用的是ISODATA、K-Mean和链状方法。
ENVI包括了ISODATA和K-Mean方法。
ISODATA(Iterative Self-Orgnizing Data Analysize Technique)重复自组织数据分析技术,计算数据空间中均匀分布的类均值,然后用最小距离技术将剩余像元进行迭代聚合,每次迭代都重新计算均值,且根据所得的新均值,对像元进行再分类。
K-Means使用了聚类分析方法,随机地查找聚类簇的聚类相似度相近,即中心位置,是利用各聚类中对象的均值所获得一个“中心对象”(引力中心)来进行计算的,然后迭代地重新配置他们,完成分类过程。
3、影像分类打开ENVI,选择主菜单->Classification->Unsupervised->IsoData或者K-Means。

影像的分类可分为监督与非监督分类。
监督分类器根据其原理有基于传统统计分析的、基于神经网络的、基于模式识别的等。
本专题以ENVI的监督与非监督分类的实际操作为例,介绍这两种分类方法。
有以下内容组成:∙ ∙ ●非监督分类∙ ∙ ●监督分类∙ ∙ ●分类后处理非监督分类非监督分类:也称为聚类分析或点群分类。
在多光谱图像中搜寻、定义其自然相似光谱集群的过程。
它不必对影像地物获取先验知识,仅依靠影像上不同类地物光谱(或纹理) 信息进行特征提取,再统计特征的差别来达到分类的目的,最后对已分出的各个类别的实际属性进行确认。
目前比较常见也较为成熟的是ISODATA、K-Mean和链状方法等。
遥感影像的非监督分类一般包括以下6个步骤:图1 非监督分类操作流程1、影像分析大体上判断主要地物的类别数量。
一般监督分类设置分类数目比最终分类数量要多2-3倍为宜,这样有助于提高分类精度。
本案例的数据源为ENVI自带的Landsat tm5数据Can_tmr.img,类别分为:林地、草地/灌木、耕地、裸地、沙地、其他六类。
确定在非监督分类中的类别数为15。
2、分类器选择目前非监督分类器比较常用的是ISODATA、K-Mean和链状方法。
ENVI包括了ISODATA和K-Mean方法。
ISODATA(Iterative Self-Orgnizing Data Analysize Technique)重复自组织数据分析技术,计算数据空间中均匀分布的类均值,然后用最小距离技术将剩余像元进行迭代聚合,每次迭代都重新计算均值,且根据所得的新均值,对像元进行再分类。
K-Means使用了聚类分析方法,随机地查找聚类簇的聚类相似度相近,即中心位置,是利用各聚类中对象的均值所获得一个“中心对象”(引力中心)来进行计算的,然后迭代地重新配置他们,完成分类过程。
3、影像分类打开ENVI,选择主菜单->Classification->Unsupervised->IsoData或者K-Means。

监督分类的注意事项监督分类是指监管机构按照一定的标准和规则对企业或组织进行分类管理和监督。
分类监督的目的是为了加强对不同类型的企业或组织的监管力度,保障公众利益和市场秩序的正常运行。
本文将就监督分类的注意事项进行论述。
首先,分类准则要具有公正、公平、科学的特点。
监督分类依据的准则应当建立在公正、公平和科学的基础上,不能够给企业或组织留下任意性的判断空间。
准则的制定应当充分考虑企业或组织的实际情况,确保监督分类的准确性和客观性。
其次,监督分类要注重分类的精细化和细分化。
一个行业或领域中可能存在着各种不同类型的企业或组织,监督分类应当根据不同的特点和风险程度将其进行细分。
只有将监督分类划分得足够细致,才能更好地对企业或组织进行精准的监管,提高监督的效果和效率。
再次,监督分类需要根据不同类型的企业或组织的特点确定相应的监管要求。
不同类型的企业或组织在经营活动中可能存在着不同的风险和问题,监管要求也应当因此而异。
监督分类需要充分考虑各类企业或组织的特点,确定相应的监管要求,以确保监管的切实可行和有效性。
此外,监督分类要重视对监管对象进行全面、深入的调查和了解。
对于分类监管的对象,监管机构应当进行全面、深入的调查和了解,了解其经营状况、风险程度、治理水平等方面的情况。
只有充分了解监管对象的现状和问题,才能够制定出相应的监管措施和措施。
同时,监督分类需要加强对监管对象的跟踪监测和评估。
监督不是一次性的行为,而是一个长期的过程。
监管机构需要对监管对象进行跟踪监测和评估,及时发现和解决可能存在的问题和风险,确保监督分类能够持续发挥作用。
最后,监督分类需要加强与各相关方的沟通和合作。
监督分类不仅是监管机构的工作,也需要企业、组织以及行业协会等相关方的积极参与和配合。
监管机构应当与各相关方加强沟通和合作,形成合力,共同推动监督分类工作的顺利进行。
总之,监督分类是一项复杂而重要的工作。
在进行监督分类时,我们需要充分考虑公正公平、精细细分、对特点确定监管要求、全面了解、跟踪监测和评估、加强与相关方的沟通和合作等方面的注意事项。

当代监督的分类
当代监督可以分为以下几种分类:
1. 政府监督:政府监督是指政府通过制定相关法律法规,建立监督机构,并依法对各个行业、组织、公民行为进行监督。
政府监督的目的是保障公共利益,维护社会秩序和公正。
2. 社会监督:社会监督是指社会各个层面的组织和公民对政府、企事业单位和其他社会成员的行为进行监督。
社会监督具有自发性和广泛性的特点,通过公众媒体、社交媒体、公民举报等方式,对违法乱纪行为进行曝光和追责。
3. 企业监督:企业监督是指对企业的经营活动、财务状况、社会责任等进行监督和评估,以促使企业合法经营、遵守道德规范和社会责任。
企业监督可以由内部机构、外部机构、社会公众、股东等进行。
4. 职业监督:职业监督是指对从事某一特定职业的人员的行为进行监督。
例如,医生、律师、会计师等职业都有相应的监督机构和规范,以确保从业者遵守道德规范和职业标准。
5. 自我监督:自我监督是指个人或组织对自身行为进行监督和评估。
例如,个人可以通过反思、自我反省和自我约束来规范自己的行为,组织可以通过内部管理机制和规章制度来监督成员的行为。
这些分类不是相互独立的,通常是相互关联和相互作用的。
各
种监督形式共同构成了当代社会中的监督体系,对于维护社会秩序、公正和公平起着重要的作用。

各自优缺点:监督分类的特点:主要优点:可充分利用分类地区的先验知识,预先确定分类的类别;可控制训练样本的选择,并可通过反复检验训练样本,以提高分类精度(避免分类中的严重错误);可避免非监督分类中对光谱集群组的重新归类。
主要缺点:人为主观因素较强;训练样本的选取和评估需花费较多的人力、时间;只能识别训练样本中所定义的类别,对于因训练者不知或因数量太少未被定义的类别,监督分类不能识别,从而影响分结果(对土地覆盖类型复杂的地区需特别注意)。
非监督分类特点:主要优点:无需对分类区域有广泛地了解,仅需一定的知识来解释分类出的集群组;人为误差的机会减少,需输入的初始参数较少(往往仅需给出所要分出的集群数量、计算迭代次数、分类误差的阈值等);可以形成范围很小但具有独特光谱特征的集群,所分的类别比监督分类的类别更均质;独特的、覆盖量小的类别均能够被识别。
主要缺点:对其结果需进行大量分析及后处理,才能得到可靠分类结果;分类出的集群与地类间,或对应、或不对应,加上普遍存在的“同物异谱”及“异物同谱”现象,使集群组与类别的匹配难度大;因各类别光谱特征随时间、地形等变化,则不同图像间的光谱集群组无法保持其连续性,难以对比。
一、什么是监督分类与非监督分类?非监督分类:没有训练样本,通过计算哪些相似,划分出不同类别。
先定义光谱可分性,再定义信息类。
是指人们事先对分类过程不施加任何的先验知识,而仅凭数据(遥感影像地物的光谱特征的分布规律),即自然聚类的特性,进行“盲目”的分类;其分类的结果只是对不同类别达到了区分,但并不能确定类别的属性。
监督分类:根据已知训练区提供的样本,通过计算选择特征参数,建立判别函数以对各待分类影像进行的图像分类。
先定义信息类,再定义光谱可分性。
二、它们包括什么?非监督分类包括:1.波谱图形识别分类2.聚类分析监督分类包括:1.最小距离法2.线形判别分析3.最大似然比分类4.最近邻域分类法5.特征曲线窗口法三、二者的优缺点:非监督分类优点:1.人为干预较少,自动化程度较高。

监督分类方法操作方法
监督分类方法是一种利用已知类别数据进行分类的方法,常见的监督分类方法包括决策树、支持向量机、逻辑回归、朴素贝叶斯等。
下面介绍其中一种操作方法:
以决策树为例,操作步骤如下:
1. 数据准备。
准备训练数据集和测试数据集,并对数据进行预处理,如缺失值填充、数据归一化等。
2. 特征选择。
选取最能代表样本特征的属性作为分割特征,一般可以使用信息增益或者Gini指数等方法进行特征选择。
3. 构建决策树。
根据选定的特征切分样本空间,直到满足条件(如准确度达到预设要求,树深度达到限制等),生成决策树。
4. 模型评估。
使用测试集进行模型评估,常用的评估指标包括准确率、召回率、F1值等。
5. 调参优化。
通过调整模型参数来提高模型准确度,如最大深度、节点划分方式等。
6. 模型应用。
将模型用于新数据的分类,预测新样本的标签类别。
以上是基本的操作步骤,具体实现还需要根据具体算法进行优化和调整。

实验四遥感影像分类——监督分类监督分类法:选择具有代表性的典型实验区或训练区,用训练区中已知地面各类地物样本的光谱特性来“训练”计算机,获得识别各类地物的判别函数或模式,并以此对未知地区的像元进行分类处理,分别归入到已知的类别中。
分类前操作:打开彼格哈恩.img,分别显示标准假彩色和真彩色,观察影像、识别地类。
1、具体步骤:打开彼格哈恩.img ——生成标准假彩色图像1.选取训练场1) Image—Overlay—Region of Interest(或是在主窗口上单击右键,在弹出的快捷菜单栏中选择ROI Tools…)进入训练样本选取对话框。
2)进行训练样本的选取,New Region 可以建立新的样本区,在ROI Name栏中双击,键入类的地物名,在Color栏中双击,可以输入类的颜色,ROI_Type菜单下可以进行样本类型的设置(多边形、线、点、长方形、椭圆)。
在主窗口按鼠标左键即可进行样本区选择,以双击右键结束样本区的选取。
选取完毕以后,选择File菜单—>Save ROIs,对数据进行保存。
a.Ellipse 画植被,选择相应的颜色和线型——保存为:vegetation.roi(命名植被时点击回车,应用所命新名)建立新的样本区,描画另一类样本b.Polygon 画水体,选择相应的颜色和线型——保存为:water.roiC.农业土壤农业1——保存为:农业1.roi农业2——保存为:农业2.roi岩性1——保存为:岩性1.roi岩性2——保存为:岩性2.roi……选中所有的项目,保存为:all.roi(不少于五种)4)进行最大似然法的分类:在ENVI主菜单栏中Classfication—>Supervised—>Maximum Likelihood,进入分类文件的选取对话框,选择相应的待分类文件。
(Classification—Supervised——Palallelepiped:平行六面体算法Minimum Distance:最小距离算法Mahalanobis Distance:马氏距离算法Maximum Likelihood:最大似然算法Spectral Angle Mapper:波谱角分类Blinary Encoding :二进制编码分类Neural Net :神经元网络分类)最大似然分类假定每个波段的每一类统计都呈均匀分布,并计算给定像元属于某一特定类别的似然度。

监督分类和非监督分类的异同监督分类是纪检监察机关的一项重要职责,是对监督对象开展监督的依据。
实践中经常会遇到两类监督分类的概念表述问题,如何准确把握这两类监督分类界定?如果两者不能区分清楚,容易出现问题。
本文将从二者的关系入手进行阐述。
•一、界定对监督分类,《中华人民共和国监察法》第四十三条第一款明确规定,监督是指国家行政机关、检察机关及其工作人员在行使权力、履行职责过程中,对公职人员行使职权情况进行监督,发现公职人员违纪违法问题线索,及时向有关部门移送或者采取其他必要措施以加强对公职人员监督。
监察机关应当在监察调查终结后五个工作日内将审查调查结论、处分决定等文书送达被调查人,并抄送被调查人所在单位党组织。
对监察对象实施监督的同时,监察机关应当会同有关部门建立健全协调机制,加强信息共享,实现监督资源共享与共用。
根据监督分类规则,《中国共产党纪律检查机关监督执纪工作规则》第二十一条规定“监督对象可以通过谈话、函询、要求说明材料等方式被监督对象如实向纪检监察机关反映问题,或者被监督对象因特殊情况不能如实说明问题而进行询问、质询、检查、问责等方式进行询问、质询或者进行检查;对涉及党和国家工作人员利益的其他方式进行监督的”以及《中华人民共和国监察法》第三十一条规定“监察机关应当依照法定权限和程序对监察对象进行工作评议后认为存在不应当被监督问题的”等情形下组织开展监督或者开展其他监督时可以采取相应措施实现监督目的或目标,属于监督分类规定的情形之一。
”由此可见,监督分类并非仅限于对纪检监察机关工作人员进行监督或者进行其他形式监督那么简单。
•二、特征这两类监督分类的特征表现在:一是“监督”是纪委监委履行监督责任中,运用监督执纪“四种形态”的重要内容,体现了对腐败行为的有效遏制,体现了“四种形态”协同作用;二是“监督”是纪检监察机关履行监督职责的主要方式之一,是纪检监察机关工作规范化、科学化的重要内容。
“监督”的主要区别在于:“监督”重在“发现问题”,是纪检监察机关开展监督的基本方式之一;“监督”重在“督促整改”,是纪检监察机关开展监督的主要方式之一。
1.训练区的选取应与研究区的特点和分类系统相适应;2.同类样本 -- 均质(检查其直方图)3.保证一定总数量。
4.典型性和代表性5.时间和空间一致性2)提取统计信息(1)对已知训练区土地类型的光谱特征数据进行多元统计分析,计算其基本统计值------ 如最大值、最小值、均值、方差、协方差矩阵、相关矩阵等;(2)评价样本的有效性,即各类别训练样本的分布、离散度和相关性-----图表显示(均值图、直方图、散度图)和统计测量样本间离散度定量计算。
(3)样本纯化,以选择最有效的样本与谱段,保证后续分类的可靠性。
ENVI 提供了一个N维可视化分析器(N — Dimensional Visualizer),通过它可对选择的训练区像元进行提纯。
若多维空间旋转时,某些像元始终聚集在一起,则为同一类别的较纯像元;若多维空间旋转时,所选像元分成了两个部分或散得较开,则说明选择的训练样本不纯,需把此训练区像元重新处理。
3)选择合适的监督分类算法平行算法---根据训练样本的亮度值范围(最大值、最小值)形成一个多维数据空间。
其他像元的光谱值如果落在训练样本的亮度值所对应的区域,就被划分到其对应的类别中。
最小距离法---是利用训练样本中各类别在各波段的均值,根据各像元离训练样本平均值距离的大小来决定其类别。
最小距离分类法原理简单,分类精度不高,但计算速度快,它可以在快速浏览分类概况中使用。
多级切割法--- 根据设定在各轴上的值域分割多维特征空间的分类方法。
通过选取训练区,详细了解分类类别(总体)的特征,并以较高的精度设定每个分类类别的光谱特征上限值和下限值,以便构成特征子空间。
对于一个未知类别的像素来说,它的分类取决于它落入哪个类别特征子空间中。
图8 多级切割法示意图最大似然法--- 是根据训练样本的均值和方差来评价其他像元和训练类别之间的相似性(即考虑到各类别在不同波段上的内部方差,以及不同类别其直方图重叠部分的频率分布),是一种广泛应用的分类器。
4.2 监督分类监督分类(supervised classification)又称训练场地法,是以建立统计识别函数为理论基础,依据典型样本训练方法进行分类的技术。
即根据已知训练区提供的样本,通过选择特征参数,求出特征参数作为决策规则,建立判别函数以对待分类影像进行的图像分类,是模式识别的一种方法。
要求训练区域具有典型性和代表性。
判别准则若满足分类精度要求,则此准则成立;反之,需重新建立分类的决策规则,直至满足分类精度要求为止。
常用算法有:判别分析、最大似然分析、特征分析、序贯分析和图形识别等。
其一般过程如图4-5所示:图4-5监督分类一般流程4.2.1 训练样本的选择(1)在主菜单中,选择File→Open Image File,打开分类图像;(2)选择图像视图窗口菜单Overlay→Region of Interest命令;(3)在Image视图窗口中选择Overlay→Region of Interest。
在ROI Tool窗口中,选择ROI_Type→Polygon;(4)在Window一栏中选择感兴趣区域绘制窗口,这里选择Image,然后在Image窗体中绘制一个多边形区域,然后右键单击两次结束,并在ROI Name中定义其类型。
依次定义其他的类型,这里定义了城镇建设用地、耕地、坑塘、河流以及农村居民地等5个类型(图4-6);图4-6 选择训练样本(5)选择Options→Compute ROI Separability进行训练样本可分离性计算;(6)在Select Input File for Separability窗口中选择计算训练可分离性的图像文件;(7)在ROI Separability Calculation窗口中选择计算可分离性的类型(图4-7);图4-7 ROI分离性计算(8)在ROI Separability Report窗口查看训练样本分离性报告,结果如图4-8所示。
实习目的和内容1 .选取研究区数据(512X512或者1024X1024),通过目视解译建立分类系统及其编码体 系2 .按照监督分类的步骤,在影像上找出对应各个土地利用/覆盖类型的参考图斑,利用ROI工具建立训练区,给出各个类别的特征统计表。
3 .计算各个分类类别之间的可分离性,整理成表格。
说明哪些地物类型之间较易区分,哪些类型之间难以区分。
4 .监督分类:利用最大似然法完成分类。
5 .分类精度评价,从随机采集100〜200个样本点,并确保每一类别不少于10个样本;进行分类精度评价,得到分类混淆矩阵,计算Kappa 系数,并对结果进行解释。
6 . 分类后处理(clump —sieve —majority)。
运用ISODATA 方法进行非监督分类:预先假定地表覆盖类型为30类,迭代次数选为15,由 系统完成非监督分类;然后进行类别定义与合并子类,最后进行结果的精度评价。
原理和方法1、监督分类:监督分类是在分类前人们已对遥感影像样本区中的类别属性有了先验知识, 进而可利用这些样本类别的特征作为依据建立和训练分类器(亦即建立判别函数),进而完 成整幅影像的类型划分,将每个像元归并到相对应的一个类别中去。
换句话说,监督分类就 是根据地表覆盖分类体系、方案进行遥感影像的对比分析,据此建立影像分类判别规则,最 后完成整景影像的分类;2、可分性度量:本次实习主要涉及J —M 距离和变换分散度,都是一种特征空间距离度量方 法,是指影像特征矢量与各个类中心的距离,变换分散度是 TDivercd=[1-exp(-Divercd/8)],J —M 距离 J=2*(1-e-B);3、最大似然分类法:在两类或多类判决中,假定各类分布函数为正态分布,并选择训练区, 用统计方法根据最大似然比贝叶斯判决准则法建立非线性判别函数集,计算各待分类样区的 归属概率,而进行分类的一种图像分类方法。
4、混淆矩阵:从随机点位上获取地面参考验证信息,并与遥感分类图进行逐像元比较,然 后将结果归纳到混淆矩阵,进而完成混淆矩阵分析。
监督分类(Supervised Classification)监督分类比非监督分类更多地要用户来控制,常用于对研究区域比较了解的情况。
在监督分类过程中,首先选择可以识别或者借助于其他信息可以断定其类型的像元建立模板,然后基于该模板使计算机系统自动识别具有相同特性的像元。
对分类结果进行评价后再对模板进行修改,多次反复后建立一个比较准确的模板,并在此基础上最终进行分类。
监督分类一般要经过以下几个步骤:建立模板(训练样本)、评价模板、确定初步分类结果、检验分类结果、分类后处理、分类特征统计、栅格矢量转换。
1.建立模板(训练样本、定义分类模板Define Signatures)ERDAS IMAGINE的监督分类是基于分类模板(Classification Signature)来进行的,而分类模板的生成、管理、评价和编辑等功能是由分类模板编辑器(Signature Editor)来负责的。
在分类模板编辑器中生成分类模板的基础是原图像和(或)其特征空间图像。
第一步:显示需要分类的图像在视窗Viewer中显示图像aaa.img第二步:打开分类模板编辑器(两种方式)①ERDAS图标面板菜单条:Main →Image Classification → Classification菜单→ Signature Editor菜单项→ Signature Editor对话框②ERDAS图标面板工具条:点击Classifier图标→Classification菜单→Signature Editor菜单项→ Signature Editor对话框从上图中可以看到分类模板编辑器由菜单条、工具条和分类模板属性表(CellArray)三大部分组成。
第三步:调整分类属性字段Signature Editor对话框中的分类属性表中有很多字段,分类名称(将带入分类图像)分类颜色(将带入分类图像)分类代码(只能用正整数)分类过程中的判断顺序分类样区中的像元个数分类可能性权重(用于分类判断)不同字段对于建立分类模板的作用或意义是不同的,为了突出作用比较大的字段,需要进行必要的调整。
实验报告实验九遥感图像的分类—监督分类一、原理及方法简介监督分类又称训练场地法,是一种以统计识别函数为理论基础,依据典型样本训练方法进行分类的技术,即:根据已知训练区提供的样本,通过选择特征参数,建立判别函数对各待分类像元进行的分类。
在监督分类过程中,首先选择可以识别或者借助其它信息可以断定其类型的像元建立模板,然后基于该模板使计算机系统自动识别具有相同特性的像元。
对模板进行评价后再对其进行修改,多次反复后建立一个比较准确的模板,并在此基础上最终进行分类。
监督分类一般要经过以下几个步骤:定义分类模板(Define Signatures)、评价分类模板(Evaluate Signatures)、进行监督分类(Perform Supervised Classification)、评价分类结果(Evaluate Classification)。
二、实验目的1、理解监督分类方法的基本原理。
2、掌握利用ERDAS进行监督分类的操作流程。
3、了解分类后评价过程。
三、实验内容在ERDAS软件中,对TM影像进行监督分类,将图像中的植被、水体、城镇等地物特征提取出来。
实验数据:实验九\TM_bjcity.img四、实验步骤(一)定义分类模板定义分类模板操作包括模版的生成、管理、评价和编辑等,主要利用分类模板编辑器(Signature Editor)完成,具体步骤包括:步骤一:从ERDAS主界面中,打开Viewer视窗,然后选择输入文件:实验九\TM_bjcity.img,并在Raster Option(图像设置)中设置Red|Green|Blue对应的波段值分别为4|3|2,选择Fit to Frame(合适窗口大小),如图。
步骤二:单击OK,在Viewer视窗中显示待分类图像。
打开分类模板编辑器。
在ERDAS图标面板工具条中点击Classifier(分类器)图标,选择Classification(分类)→Signature Editor(特征编辑器)菜单,打开分类模板编辑器Signature Editor,如图。
五.监督分类和制图输出
1.添加文件:打开ENVI4.8主页面,单击File下拉菜单中的Open Image File。
添加进来“融
合”。
2.添加形状文件:单击ENVI4.8主页面File下拉菜单中的Open Vector File,在弹出的Select
Vector Filenames对话框中,选择“jiaozuo.shp”形状文件,单击打开。
3.再剪切:在弹出的Import Vector Files Param。
对话框中单击OK即可。
在弹出的对话
框中选中Layer:jiaozuo.shp,单击Load Selected。
在弹出的小对话框(Load Vec.。
)(加载到哪个图像)中选中Display #1,在弹出的对话框中不要操作。
单击Available Vectors List(可用矢量列表)对话框中单击File下拉菜单下的Export Layers to Roi…(将图层导出到Roi),在弹出的对话框中选中“镶嵌”,单击OK。
在弹出的Select Date File to associate with new ROIs对话框中选择Convert all records of an EVF layer to one ROI。
点击OK。
返回操作原来的对话框(#1Vector Parameters:。
)中,单击Apply。
单击主页面Basic Tools下拉菜单下的Subset Data via ROIs (ROI日期文件子集),在弹出的对话框Select Input File to Subset via ROI中选中“镶嵌”,单击OK,在弹出的对话框中选中Select Input ROIs下面的文件,,选择Mask pixels outside of ROI?,后面的箭头,选择yes. 单击Choose选择文件保存路径,并命名“再剪切”打开。
单击OK即可。
4.监督分类:打开“再剪切”影像,主页面File---Open Image File ,在Available Band
中以RGB打开,为真彩色,即地物的真实颜色。
5.选择监督分类样本(感兴趣区域):在影像的工具栏中选择,Overlay---Region of interest,
在打开的#1 ROI Tool 工具栏中,以多边形的方式选择感兴趣区:ROI-Type----Polygon 在zoom窗口中进行选择,选择类别,水体,林地,农田1,农田2 ,居民地,未利用土地。
查看分离程度,继续在ROI Tool 工具栏中,选择Option—compute ROI separability ,选择影像ok., 相关度大于1.8的说明分类较好。
保存文件。
6.用最大似然法进行监督分类,主菜单栏中,Classification —Supervised—Maximum
Likelihood,进入选择参数的对话框。
Select all Item 阈值Probability Threshold一般在0~1之间。
不需输出真实值。
因为还要分类后处理,储存至memory.
7.分类后处理:①分类合并,在主菜单中Classification—post classification(分类比较法)
—Sieve Classes(筛选)选择刚才分类好的,memory影像,改变Group Min Threshold 数值,由2改到8.即改变每类别最小像元值,保存文件,即要求交的分类结果图。
②生成混淆矩阵主菜单中,Classification—post classification—confusion Matrix—Using Ground Truth ROIS.将所有类别都选上。
保存混淆矩阵
8.合并同类:选择主页面Classification—post classification——combine classes在弹出的对
话框中“分类”,单击OK,在弹出的combine classes parameters对话框中select input class 一栏选择“农田1 ”在select output class一栏中选择农田2 ,单击add combination ,单击OK,在弹出的combine classes output 对话框中选择choose,选择保存路径和文件名“合并”,单击OK。
9.剪切“合并”:方法同步骤3.文件名保存为“剪切‘合并’”。
ARCGIS制图输出
1.利用ARCMAP输出遥感影像图:将“合并”修改文件名,加上文件类型.img。
加载到
ARCMAP10.0中,同时加载jiaozuo-country.shp文件。
2.右击“合并”选择“属性”,在弹出的图层属性对话框中选择符号系统,将背景色改为
无色,设置拉伸方式和比例后单击确定。
3.右击jiaozuo-country.shp选择属性,在图层属性对话框中选择符号系统,类别-唯一值-
选择KML-FOLDER,去掉其他所有制前面的勾,添加所有制,把不需要的去掉,比如,
这里不需要行政村,单击,点击下面的移除,双击需要标注的类别可以修改标注的样式。
单机上面的标注选项卡,方法设为定义要数类并且为每个累加不同的标注。
点击添加,造一个类“县”,单击确定。
在“类”后面的框中选择“默认”,然后点击下面的删除,点击SQL查询,表达式为KML-FOLDER=区、县,单击确定。
继续添加“乡镇”同上。
在左上角的标注此图层中的要数前打勾。
单击确定。
4.在ARC主页面中单击视图下的布局视图,单击文件下拉菜单下的页面和打印设置,勾
掉使用打印机纸张设置,设置高度和宽度,单击确定,
5.点击插入,下的指北针,比例尺,等
6.点击文件,保存地图,jpeg格式。
即可。
土地利用现状图
1.右键单击剪切“合并”,选择属性,符号系统-唯一值-,设置个地雷颜色,
2.点击插入指北针,比例尺等
3.右击选择图层--属性-格网----新建个网---房里网---设置个网格式为刻度和标注,完
成,点击应用,确定即可。
4.到处地图。