函数依赖实例分析
- 格式:pptx
- 大小:1.28 MB
- 文档页数:11

计算最小函数依赖集示例举例:已知关系模式R<U,F>,U={A,B,C,D,E,G},F={AB→C,D→EG,C→A,BE→C,BC→D,CG→BD,ACD→B,CE→AG},求F的最小函数依赖集。
解:利用算法求解,使得其满足三个条件①利用分解规则,将所有的函数依赖变成右边都是单个属性的函数依赖,得F为:F={AB→C,D→E,D→G,C→A,BE→C,BC→D,CG→B,CG→D,ACD→B,CE→A,CE→G}②去掉F中多余的函数依赖。
A.设AB→C为冗余的函数依赖,则去掉AB→C,得:F1={D→E,D→G,C→A,BE→C,BC→D,CG→B,CG→D,ACD→B,CE→A,CE→G}计算(AB)F1+:设X(0)=AB计算X(1):扫描F1中各个函数依赖,找到左部为AB或AB子集的函数依赖,因为找不到这样的函数依赖。
故有X(1)=X(0)=AB,算法终止。
(AB)F1+= AB不包含C,故AB→C不是冗余的函数依赖,不能从F1中去掉。
B.设CG→B为冗余的函数依赖,则去掉CG→B,得:F2={AB→C,D→E,D→G,C→A,BE→C,BC→D,CG→D,ACD→B,CE→A,CE→G}计算(CG)F2+:设X(0)=CG计算X(1):扫描F2中的各个函数依赖,找到左部为CG或CG子集的函数依赖,得到一个C→A函数依赖。
故有X(1)=X(0)∪A=CGA=ACG。
计算X(2):扫描F2中的各个函数依赖,找到左部为ACG或ACG子集的函数依赖,得到一个CG→D函数依赖。
故有X(2)=X(1)∪D=ACDG。
计算X(3):扫描F2中的各个函数依赖,找到左部为ACDG或ACDG子集的函数依赖,得到两个ACD→B和D→E函数依赖。
故有X(3)=X(2)∪BE=ABCDEG,因为X(3)=U,算法终止。
(CG)F2+=ABCDEG包含B,故CG→B是冗余的函数依赖,从F2中去掉。
C.设CG→D为冗余的函数依赖,则去掉CG→D,得:F3={AB→C,D→E,D→G,C→A,BE→C,BC→D,ACD→B,CE→A,CE→G}计算(CG)F3+:设X(0)=CG计算X(1):扫描F3中的各个函数依赖,找到左部为CG或CG子集的函数依赖,得到一个C→A函数依赖。


函数依赖闭包⼀、函数依赖的逻辑蕴涵定义:设有关系模式R(U)及其函数依赖集F,如果对于R的任⼀个满⾜F的关系r函数依赖X→Y都成⽴,则称F逻辑蕴涵X→Y,或称X→Y可以由F推出。
例:关系模式 R=(A,B,C),函数依赖集F={A→B,B→C}, F逻辑蕴涵A→C。
证:设u,v为r中任意两个元组:若A→C不成⽴,则有u[A]=v[A],⽽u[C]≠v[C]⽽且A→B, B→C,知u[A]=v[A], u[B]=v[B], u[C]=v[C],即若u[A]=v[A]则u[C]=v[C],和假设⽭盾。
故F逻辑蕴涵A→C。
满⾜F依赖集的所有元组都函数依赖X→Y(X→Y不属于F集),则称F逻辑蕴涵X→Y(X→Y由F依赖集中所有依赖关系推断⽽出)⼆、Armstrong公理1、定理:若U为关系模式R的属性全集,F为U上的⼀组函数依赖,设X、Y、Z、W均为R的⼦集,对R(U,F)有:F1(⾃反性):若X≥Y(表X包含Y),则X→Y为F所蕴涵;(F1':X→X)F2(增⼴性): 若X→Y为F所蕴涵,则XZ→YZ为F所蕴涵;(F2':XZ→Y)F3(传递性): 若X→Y,Y→Z为F所蕴涵,则X→Z为F所蕴涵;F4(伪增性):若X→Y,W≥Z(表W包含Z)为F所蕴涵,则XW→YZ为F所蕴涵;F5(伪传性): 若X→Y,YW→Z为F所蕴涵, 则XW→Z为F所蕴涵;F6(合成性): 若X→Y,X→Z为F所蕴涵,则X→YZ为F所蕴涵;F7(分解性): 若X→Y,Z≤Y (表Z包含于Y)为F所蕴涵,则X→Z为F所蕴涵。
函数依赖推理规则F1∽F7都是正确的。
2、Armstrong公理:推理规则F1、F2、F3合称Armstrong公理;F4 ∽ F7可由F1、F2、F3推得,是Armstrong公理的推论部分。
三、函数依赖的闭包定义:若F为关系模式R(U)的函数依赖集,我们把F以及所有被F逻辑蕴涵的函数依赖的集合称为F的闭包,记为F+。

数据库-部分函数依赖,传递函数依赖,完全函数依赖,三种范式的区别要讲清楚范式,就先讲讲几个名词的含义吧:部分函数依赖:设X,Y是关系R的两个属性集合,存在X→Y,若X’是X的真子集,存在X’→Y,则称Y部分函数依赖于X。
举个例子:学生基本信息表R中(学号,身份证号,姓名)当然学号属性取值是唯一的,在R关系中,(学号,身份证号)->(姓名),(学号)->(姓名),(身份证号)->(姓名);所以姓名部分函数依赖与(学号,身份证号);完全函数依赖:设X,Y是关系R的两个属性集合,X’是X的真子集,存在X→Y,但对每一个X’都有X’!→Y,则称Y完全函数依赖于X。
例子:学生基本信息表R(学号,班级,姓名)假设不同的班级学号有相同的,班级内学号不能相同,在R关系中,(学号,班级)->(姓名),但是(学号)->(姓名)不成立,(班级)->(姓名)不成立,所以姓名完全函数依赖与(学号,班级);传递函数依赖:设X,Y,Z是关系R中互不相同的属性集合,存在X→Y(Y !→X),Y→Z,则称Z传递函数依赖于X。
例子:在关系R(学号 ,宿舍, 费用)中,(学号)->(宿舍),宿舍!=学号,(宿舍)->(费用),费用!=宿舍,所以符合传递函数的要求;在任何一个关系数据库中,第一范式(1NF)是对关系模式的基本要求,不满足第一范式(1NF)的数据库就不是关系数据库。
所谓第一范式(1NF)是指数据库表的每一列(即每个属性)都是不可分割的基本数据项,同一列中不能有多个值,即实体中的某个属性不能有多个值或者不能有重复的属性。
简而言之,第一范式就是无重复的列。
2、第二范式(2NF)第二范式(2NF)是在第一范式(1NF)的基础上建立起来的,即满足第二范式(2NF)必须先满足第一范式(1NF)。
第二范式(2NF)要求数据库表中的每个实例或行必须可以被唯一地区分。
为实现区分通常需要为表加上一个列,以存储各个实例的唯一标识。


一:大部分是对一个关系模式分解成两个模式的考察,分解为三个以上模式时无损分解和保持依赖的判断比较复杂,考的可能性不大,因此我们只对“一个关系模式分解成两个模式”这种类型的题的相关判断做一个总结。
以下的论述都基于这样一个前提:R是具有函数依赖集F的关系模式,(R1 ,R2)是R的一个分解。
首先我们给出一个看似无关却非常重要的概念:属性集的闭包。
令α为一属性集。
我们称在函数依赖集F下由α函数确定的所有属性的集合为F下α的闭包,记为α+ 。
下面给出一个计算α+的算法,该算法的输入是函数依赖集F和属性集α,输出存储在变量result中。
算法一:result:=α;while(result发生变化)dofor each 函数依赖β→γ in F dobeginif β∈result then result:=result∪γ;end属性集闭包的计算有以下两个常用用途:·判断α是否为超码,通过计算α+(α在F下的闭包),看α+ 是否包含了R中的所有属性。
若是,则α为R的超码。
·通过检验是否β∈α+,来验证函数依赖是否成立。
也就是说,用属性闭包计算α+,看它是否包含β。
(请原谅我用∈符号来表示两个集合之间的包含关系,那个表示包含的符号我找不到,大家知道是什么意思就行了。
)看一个例子吧,2005年11月系分上午37题:● 给定关系R(A1,A2,A3,A4)上的函数依赖集F={A1→A2,A3→A2,A2→A3,A2→A4},R的候选关键字为________。
(37)A. A1 B. A1A3 C. A1A3A4 D. A1A2A3首先我们按照上面的算法计算A1+ 。
result=A1,由于A1→A2,A1∈result,所以resul t=result∪A2=A1A2由于A2→A3,A2∈result,所以result=result∪A3=A1A2A3由于A2→A4,A2∈result,所以result=result∪A3=A1A2A3A4由于A3→A2,A3∈result,所以result=result∪A2=A1A2A3A4通过计算我们看到,A1+ =result={A1A2A3A4},所以A1是R的超码,理所当然是R的候选关键字。

数据库函数依赖及范式(最通俗易懂)⼀、基础概念 要理解范式,⾸先必须对知道什么是关系数据库,如果你不知道,我可以简单的不能再简单的说⼀下:关系数据库就是⽤⼆维表来保存数据。
表和表之间可以……(省略10W字)。
然后你应该理解以下概念: 实体:现实世界中客观存在并可以被区别的事物。
⽐如“⼀个学⽣”、“⼀本书”、“⼀门课”等等。
值得强调的是这⾥所说的“事物”不仅仅是看得见摸得着的“东西”,它也可以是虚拟的,不如说“⽼师与学校的关系”。
属性:教科书上解释为:“实体所具有的某⼀特性”,由此可见,属性⼀开始是个逻辑概念,⽐如说,“性别”是“⼈”的⼀个属性。
在关系数据库中,属性⼜是个物理概念,属性可以看作是“表的⼀列”。
元组:表中的⼀⾏就是⼀个元组。
分量:元组的某个属性值。
在⼀个关系数据库中,它是⼀个操作原⼦,即关系数据库在做任何操作的时候,属性是“不可分的”。
否则就不是关系数据库了。
码:表中可以唯⼀确定⼀个元组的某个属性(或者属性组),如果这样的码有不⽌⼀个,那么⼤家都叫候选码,我们从候选码中挑⼀个出来做⽼⼤,它就叫主码。
全码:如果⼀个码包含了所有的属性,这个码就是全码。
主属性:⼀个属性只要在任何⼀个候选码中出现过,这个属性就是主属性。
⾮主属性:与上⾯相反,没有在任何候选码中出现过,这个属性就是⾮主属性。
外码:⼀个属性(或属性组),它不是码,但是它别的表的码,它就是外码。
⼆、6个范式 好了,上⾯已经介绍了我们掌握范式所需要的全部基础概念,下⾯我们就来讲范式。
⾸先要明⽩,范式的包含关系。
⼀个数据库设计如果符合第⼆范式,⼀定也符合第⼀范式。
如果符合第三范式,⼀定也符合第⼆范式…第⼀范式(1NF):属性不可分。
在前⾯我们已经介绍了属性值的概念,我们说,它是“不可分的”。
⽽第⼀范式要求属性也不可分。
那么它和属性值不可分有什么区别呢?给⼀个例⼦:name tel age⼤宝136****567822⼩明139****6655010-123456721Ps:这个表中,属性值“分”了。

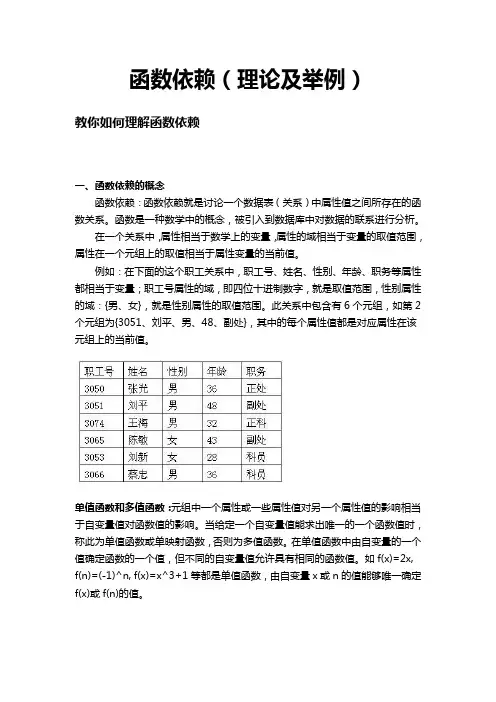
函数依赖(理论及举例)教你如何理解函数依赖一、函数依赖的概念函数依赖:函数依赖就是讨论一个数据表(关系)中属性值之间所存在的函数关系。
函数是一种数学中的概念,被引入到数据库中对数据的联系进行分析。
在一个关系中,属性相当于数学上的变量,属性的域相当于变量的取值范围,属性在一个元组上的取值相当于属性变量的当前值。
例如:在下面的这个职工关系中,职工号、姓名、性别、年龄、职务等属性都相当于变量;职工号属性的域,即四位十进制数字,就是取值范围,性别属性的域:{男、女},就是性别属性的取值范围。
此关系中包含有6个元组,如第2个元组为{3051、刘平、男、48、副处},其中的每个属性值都是对应属性在该元组上的当前值。
单值函数和多值函数:元组中一个属性或一些属性值对另一个属性值的影响相当于自变量值对函数值的影响。
当给定一个自变量值能求出唯一的一个函数值时,称此为单值函数或单映射函数,否则为多值函数。
在单值函数中由自变量的一个值确定函数的一个值,但不同的自变量值允许具有相同的函数值。
如f(x)=2x, f(n)=(-1)^n, f(x)=x^3+1等都是单值函数,由自变量x或n的值能够唯一确定f(x)或f(n)的值。
属性的单值函数决定(依赖):在一个关系中,若一个或一组属性的值对另一个或一组属性值起到决定性的作用,则称为单值函数决定(依赖)。
如上表中职工号的值就能够函数决定其余每个属性的值,也就是说,当职工号给定后,其他每个属性的值就跟着唯一地确定了。
如假定职工号为3074,则他的姓名必定是王海,性别必定为男,年龄必定为32岁,职务必定为正科。
这就叫做职工号能够分别单值函数决定姓名、性别和年龄属性,反过来,可以说姓名、性别和年龄等属性单值函数依赖于职工号属性。
二、函数依赖的定义定义:设一个关系为R(U),X和Y为属性集U上的子集,若对于X上的每个值都有Y上的一个唯一值与之对应,则称X和Y具有函数依赖关系,并称X 函数决定Y,或称Y函数依赖于X,记作X→Y,称X为决定因素。


FD原理及例子FD,即函数依赖(Functional Dependency),是数据库设计中的一个重要概念。
它描述了在关系数据库中,一个数据集合中的一些属性(属性集合A)的值决定了另外一些属性(属性集合B)的值。
换句话说,当两个元组在属性集合A上的取值相同,那么它们在属性集合B上的取值也必须相同。
FD原理:1.函数依赖是在关系模型中定义的。
在关系模型中,数据被组织为表格(关系),每个表格包含了行(元组)和列(属性)。
2.函数依赖是通过属性之间的关系来定义的。
对于给定的关系R,如果属性集合A的取值决定了属性集合B的取值,则称B函数依赖于A,记作A->B。
3.函数依赖可以是单值的,也可以是多值的。
单值函数依赖是指属性集合A的任意两个元组在属性集合B上的取值都相同;多值函数依赖是指属性集合A的任意两个元组在属性集合B上的取值可能不同。
4.函数依赖可以是传递的。
如果A->B,B->C,则可以推断出A->C,即A函数依赖于C。
FD例子:考虑一个简单的学生数据库,包含了学生的学号、姓名、年龄和班级等属性。
假设我们要设计一个关系模式R,其中包含了这些属性。
1.学号->姓名:一个学号对应唯一的姓名,即学号决定了姓名。
2.学号->年龄:一个学号对应唯一的年龄,即学号决定了年龄。
3.班级->学号:一个班级对应多个学号,即班级决定了学号。
4.学号->班级:一个学号对应唯一的班级,即学号决定了班级。
通过上述例子,我们可以看到函数依赖在数据库设计中的作用。
它帮助我们理解数据之间的关系,并且可以用来规范化数据库模式,减少冗余和重复数据的存储。
在实际应用中,函数依赖可以被用于优化查询操作,提高数据库系统的性能。
通过分析函数依赖关系,我们可以设计合适的索引,加快查询速度。
同时,函数依赖也可以用于数据完整性的检查和维护,确保数据库中的数据符合预期的约束。
总结:函数依赖是数据库设计中的一个重要概念,用于描述属性之间的关系。
数据库函数依赖例题函数依赖是数据库中一种重要的概念,用于描述数据库表中数据之间的关系。
函数依赖的概念非常重要,它能够帮助我们理解和优化数据库表的设计,提高数据库的性能。
函数依赖可以分为两种基本类型:完全函数依赖和部分函数依赖。
完全函数依赖是指在一个关系中,如果在R(A1,A2,...,An)中有一个函数依赖X→Y,那么对于X的任何真子集X',都不能有X'→Y成立。
简单来说,X完全决定了Y。
举个例子,考虑一个学生选课关系表(S,C)中,学生ID(SID)确定了课程ID(CID),也就是说SID→CID是完全函数依赖。
如果我们再考虑学生ID和课程ID之间是否还存在其他完全函数依赖,我们可能会得出只有SID→CID的结论。
这是因为对于学生ID和课程ID之间的其他属性,如学生姓名(SNAME)和课程名称(CNAME),它们与学生ID和课程ID并不是完全函数依赖。
也就是说,通过学生ID无法完全确定学生的姓名,需要通过课程ID来获取学生的姓名。
另一种类型的函数依赖是部分函数依赖。
部分函数依赖是指在一个关系中,如果在R(A1,A2,...,An)中有一个函数依赖X→Y,那么对于X的任何真子集X',如果X'→Y成立,那么X→Y就是一个部分函数依赖。
简单来说,X部分决定了Y。
继续以学生选课关系表为例,如果我们考虑学生ID和课程ID以及学生名称(SNAME)之间的函数依赖关系,我们可能会观察到SID→CID,CID→SNAME,而SID→SNAME不成立。
这说明学生ID和课程ID部分决定了学生姓名,因为通过课程ID无法完全确定学生的姓名,需要通过学生ID来获取。
对于数据库设计和优化来说,理解函数依赖非常重要。
通过了解函数依赖,我们可以避免数据重复和冗余,减小数据库的存储空间和查询时间。
在数据库设计中,我们可以使用函数依赖来拆分表,将数据分解成更小的关系,从而提高数据库的性能。
在数据库查询优化中,我们可以使用函数依赖来消除冗余的数据,减少表的连接操作,从而提高查询性能。
函数依赖实例
1. 完全依赖:通过{学生学号,选修课程名}可以得到{该生本门选修课程的成绩},而通过单独的{学生学号}或者单独的{选修课程名}都无法得到该成绩,则说明{该生本门选修课程的成绩}完全依赖于{学生学号,选修课程名}
2. 部分函数依赖:通过{学生学号,课程号}可以得到{该生姓名},而通过单独的{学生学号}已经能够得到{该生姓名},则说明{该生姓名}部分依赖于{学生学号,课程号};又比如,通过{学生学号,课程号}可以得到{课程名称},而通过单独的{课程号}已经能够得到{课程名称},则说明{课程名称}部分依赖于{学生学号,课程号}。
(部分依赖会造成数据冗余及各种异常。
)
3. 传递函数依赖:在关系R(学号,宿舍,费用)中,通过{学号}可以得到{宿舍},通过{宿舍}可以得到{费用},而反之都不成立,则存在传递依赖{学号}->{费用}。
(传递依赖也会造成数据冗余及各种异常。
)。
保持函数依赖算法的例子以下是 6 条关于保持函数依赖算法的例子:1. 你知道在安排课程表的时候吗?这就好像给不同颜色的珠子按顺序串起来,每门课都有它特定的位置和依赖关系,就像数学和物理,学了数学很多知识才能更好地理解物理,这就是一种保持函数依赖。
比如说,要是先安排物理课,没有数学基础那怎么能行呢?那可就乱套啦!2. 想象一下装修房子,你得先搞定水电布局,才能去弄墙面和地板呀!这和保持函数依赖算法多像呀!就好比水电布局就是那个基础,墙面和地板就是依赖它的部分。
如果乱了顺序,那不是糟糕透顶啦?就像你先铺地板再弄水电,那得费多大劲去改造啊!3. 网购的时候,你得先选好商品,然后填写地址,最后支付,这一系列流程就是保持函数依赖呀!选好商品不就是那个关键的源头嘛,地址是后续依赖它的,支付又是依赖前面那些环节的。
如果顺序乱了,哎呀,那还不得出大乱子啊!难道不是吗?4. 好比做一顿丰盛的大餐,你得先准备食材吧,然后再烹饪,最后才能装盘上桌。
这食材就像是保持函数依赖里的基础,烹饪是依赖它的步骤,装盘又是在烹饪之后。
要是先装盘再准备食材,这能叫做饭吗?这不是太荒唐了嘛!5. 去旅行规划行程的时候也是一样呀!你得先确定目的地,再去考虑交通方式和住宿安排。
目的地就是那个起头的,后面的都是依赖它的。
难道有人会先想好住哪里再决定去哪里旅行吗?那不是搞笑嘛!这可不就是保持函数依赖算法的生动体现嘛!6. 要是在公司安排工作任务,也得遵循保持函数依赖呀!先有大目标,然后分解为具体的步骤,每个步骤之间都有相互的依赖关系。
比如要完成一个项目,得先做调研,再做设计,最后才是实施。
如果跳过调研直接实施,那结果会怎样?肯定一塌糊涂呀!我觉得保持函数依赖算法真的特别重要,它让事情变得有序、合理,不然真的会乱成一团麻!。
非平凡函数依赖是指在数据库关系模型中,一个属性完全依赖于码中的一部分而不是整个码。
在关系模型中,一个关系R的属性A对关系R的一个候选键K而言是非平凡函数依赖的条件是:属性A依赖于码K,且对于K的任意真子集K'来说,A不依赖于K'。
这种依赖关系在数据库设计中十分重要,因为它能够规定数据的完整性,避免数据冗余和更新异常。
1. 非平凡函数依赖的特点非平凡函数依赖有以下几个特点:1) 依赖:非平凡函数依赖表示属性A对码K的依赖关系,即属性A的取值是由码K的取值唯一确定的。
2) 非平凡:非平凡函数依赖要求属性A不能完全依赖于关系R的所有属性,而是只能依赖于码K的一部分。
3) 完整性:非平凡函数依赖能够规定数据的完整性,保证数据的准确性和一致性。
2. 非平凡函数依赖的应用非平凡函数依赖在数据库设计中起着重要的作用,它能够帮助数据库设计者规范化数据库结构,避免数据冗余和更新异常。
在实际的数据库设计和应用中,非平凡函数依赖经常用于以下方面:1) 数据规范化:在数据库设计中,通过识别和利用非平凡函数依赖,可以将数据规范化为符合第三范式或更高范式的关系模式,提高数据存储和查询的效率。
2) 数据完整性:非平凡函数依赖能够规定数据的完整性约束条件,保证数据的准确性和一致性,避免信息的丢失和混乱。
3) 索引优化:数据库索引的建立和优化可以利用非平凡函数依赖,提高数据库查询的性能和效率。
3. 非平凡函数依赖的实例分析对于一个员工信息表,假设员工号(E_ID)、尊称(E_Name)、部门号(D_ID)和部门名称(D_Name)是该表的属性,其中员工号是关系的候选键。
如果我们发现员工尊称完全依赖于员工号,即一个员工号对应唯一的员工尊称,而不是依赖于员工号和部门号的组合,那么员工尊称对员工号就存在非平凡函数依赖的关系。
4. 总结非平凡函数依赖在数据库设计和应用中具有重要的作用,它能够帮助数据库设计者规范化数据库结构,保证数据的完整性和一致性。