spass课件,教程,第七章 主成分分析
- 格式:ppt
- 大小:1.66 MB
- 文档页数:30
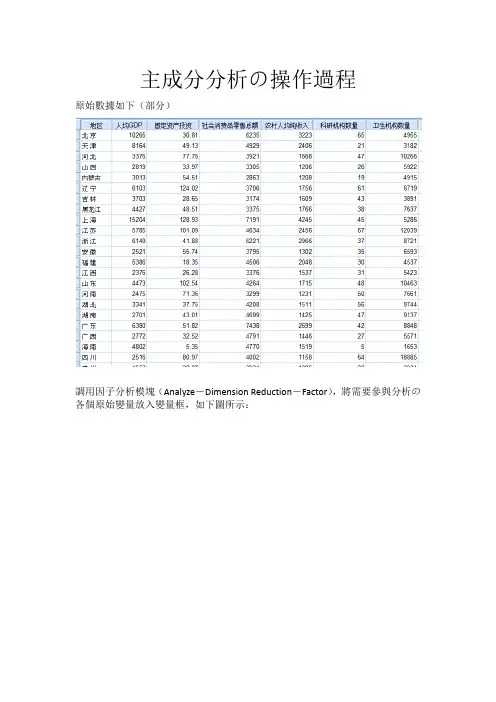
主成分分析の操作過程原始數據如下(部分)調用因子分析模塊(Analyze―Dimension Reduction―Factor),將需要參與分析の各個原始變量放入變量框,如下圖所示:單擊Descriptives按鈕,打開Descriptives次對話框,勾選KMO and Bartlett’s test of sphericity選項(Initial solution選項為系統默認勾選の,保持默認即可),如下圖所示,然後點擊Continue按鈕,回到主對話框:其他の次對話框都保持不變(此時在Extract次對話框中,SPSS已經默認將提取公因子の方法設置為主成分分析法),在主對話框中點OK按鈕,執行因子分析,得到の主要結果如下面幾張表。
①KMO和Bartlett球形檢驗結果:KMO為0.635>0.6,說明數據適合做因子分析;Bartlett球形檢驗の顯著性P值為0.000<0.05,亦說明數據適合做因子分析。
②公因子方差表,其展示了變量の共同度,Extraction下面各個共同度の值都大於0.5,說明提取の主成分對於原始變量の解釋程度比較高。
本表在主成分分析中用處不大,此處列出來僅供參考。
③總方差分解表如下表。
由下表可以看出,提取了特征值大於1の兩個主成分,兩個主成分の方差貢獻率分別是55.449%和29.771%,累積方差貢獻率是85.220%;兩個特征值分別是3.327和1.786。
④因子截荷矩陣如下:根據數理統計の相關知識,主成分分析の變換矩陣亦即主成分載荷矩陣U 與因子載荷矩陣A 以及特征值λの數學關系如下面這個公式:λiiiAU=故可以由這二者通過計算變量來求得主成分載荷矩陣U 。
新建一個SPSS 數據文件,將因子載荷矩陣中の各個載荷值複制進去,如下圖所示:計算變量(Transform-Compute Variables )の公式分別如下二張圖所示:計算變量得到の兩個特征向量U1和U2如下圖所示(U1和U2合起來就是主成分載荷矩陣):所以可以得到兩個主成分Y1和Y2の表達式如下:Y1=0.456X1+0.401X2+0.428X3+0.490X4+0.380X5+0.253X6Y2=-0.367X1+0.322X2-0.323X3-0.303X4+0.453X5+0.602X6由上面兩個表達式,可以通過計算變量來得到Y1、Y2の值。

![SPSS进行主成分分析的步骤[图文]](https://uimg.taocdn.com/1b2ef8f4da38376baf1fae83.webp)
主成分分析的操作过程原始数据如下(部分)调用因子分析模块(Analyze―Dimension Reduction―Factor),将需要参与分析的各个原始变量放入变量框,如下图所示:单击Descriptives按钮,打开Descriptives次对话框,勾选KMO and Bartlett’s test of sphericity选项(Initial solution选项为系统默认勾选的,保持默认即可),如下图所示,然后点击Continue按钮,回到主对话框:其他的次对话框都保持不变(此时在Extract次对话框中,SPSS已经默认将提取公因子的方法设置为主成分分析法),在主对话框中点OK按钮,执行因子分析,得到的主要结果如下面几张表。
①KMO和Bartlett球形检验结果:KMO为0.635>0.6,说明数据适合做因子分析;Bartlett球形检验的显著性P值为0.000<0.05,亦说明数据适合做因子分析。
②公因子方差表,其展示了变量的共同度,Extraction下面各个共同度的值都大于0.5,说明提取的主成分对于原始变量的解释程度比较高。
本表在主成分分析中用处不大,此处列出来仅供参考。
③总方差分解表如下表。
由下表可以看出,提取了特征值大于1的两个主成分,两个主成分的方差贡献率分别是55.449%和29.771%,累积方差贡献率是85.220%;两个特征值分别是3.327和1.786。
④因子截荷矩阵如下:根据数理统计的相关知识,主成分分析的变换矩阵亦即主成分载荷矩阵U 与因子载荷矩阵A 以及特征值λ的数学关系如下面这个公式:λiiiAU=故可以由这二者通过计算变量来求得主成分载荷矩阵U 。
新建一个SPSS 数据文件,将因子载荷矩阵中的各个载荷值复制进去,如下图所示:计算变量(Transform-Compute Variables )的公式分别如下二张图所示:计算变量得到的两个特征向量U1和U2如下图所示(U1和U2合起来就是主成分载荷矩阵):所以可以得到两个主成分Y1和Y2的表达式如下:Y1=0.456X1+0.401X2+0.428X3+0.490X4+0.380X5+0.253X6Y2=-0.367X1+0.322X2-0.323X3-0.303X4+0.453X5+0.602X6由上面两个表达式,可以通过计算变量来得到Y1、Y2的值。
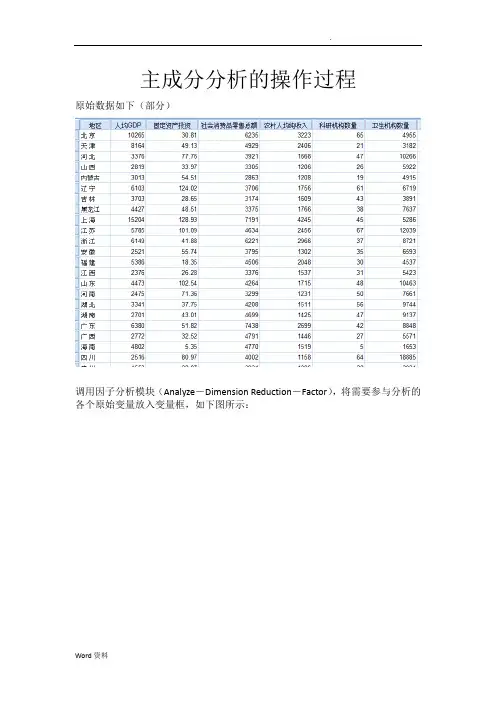
主成分分析的操作过程原始数据如下(部分)调用因子分析模块(Analyze―Dimension Reduction―Factor),将需要参与分析的各个原始变量放入变量框,如下图所示:单击Descriptives按钮,打开Descriptives次对话框,勾选KMO and Bartlett’s test of sphericity选项(Initial solution选项为系统默认勾选的,保持默认即可),如下图所示,然后点击Continue按钮,回到主对话框:其他的次对话框都保持不变(此时在Extract次对话框中,SPSS已经默认将提取公因子的方法设置为主成分分析法),在主对话框中点OK按钮,执行因子分析,得到的主要结果如下面几表。
①KMO和Bartlett球形检验结果:KMO为0.635>0.6,说明数据适合做因子分析;Bartlett球形检验的显著性P值为0.000<0.05,亦说明数据适合做因子分析。
②公因子方差表,其展示了变量的共同度,Extraction下面各个共同度的值都大于0.5,说明提取的主成分对于原始变量的解释程度比较高。
本表在主成分分析中用处不大,此处列出来仅供参考。
③总方差分解表如下表。
由下表可以看出,提取了特征值大于1的两个主成分,两个主成分的方差贡献率分别是55.449%和29.771%,累积方差贡献率是85.220%;两个特征值分别是3.327和1.786。
④因子截荷矩阵如下:根据数理统计的相关知识,主成分分析的变换矩阵亦即主成分载荷矩阵U与因子载荷矩阵A 以及特征值λ的数学关系如下面这个公式:λiii AU=故可以由这二者通过计算变量来求得主成分载荷矩阵U。
新建一个SPSS数据文件,将因子载荷矩阵中的各个载荷值复制进去,如下图所示:计算变量(Transform-Compute Variables)的公式分别如下二图所示:计算变量得到的两个特征向量U1和U2如下图所示(U1和U2合起来就是主成分载荷矩阵):所以可以得到两个主成分Y1和Y2的表达式如下:Y1=0.456X1+0.401X2+0.428X3+0.490X4+0.380X5+0.253X6Y2=-0.367X1+0.322X2-0.323X3-0.303X4+0.453X5+0.602X6由上面两个表达式,可以通过计算变量来得到Y1、Y2的值。


S P S S进行主成分分析的步骤(图文)主成分分析的操作过程原始数据如下(部分)调用因子分析模块(Analyze―Dimension Reduction―Factor),将需要参与分析的各个原始变量放入变量框,如下图所示:单击Descriptives按钮,打开Descriptives次对话框,勾选KMO and Bartlett’s test of sphericity选项(Initial solution选项为系统默认勾选的,保持默认即可),如下图所示,然后点击Continue按钮,回到主对话框:其他的次对话框都保持不变(此时在Extract次对话框中,SPSS已经默认将提取公因子的方法设置为主成分分析法),在主对话框中点OK按钮,执行因子分析,得到的主要结果如下面几张表。
①KMO和Bartlett球形检验结果:KMO为0.635>0.6,说明数据适合做因子分析;Bartlett球形检验的显著性P值为0.000<0.05,亦说明数据适合做因子分析。
②公因子方差表,其展示了变量的共同度,Extraction下面各个共同度的值都大于0.5,说明提取的主成分对于原始变量的解释程度比较高。
本表在主成分分析中用处不大,此处列出来仅供参考。
③总方差分解表如下表。
由下表可以看出,提取了特征值大于1的两个主成分,两个主成分的方差贡献率分别是55.449%和29.771%,累积方差贡献率是85.220%;两个特征值分别是3.327和1.786。
④因子截荷矩阵如下:根据数理统计的相关知识,主成分分析的变换矩阵亦即主成分载荷矩阵U 与因子载荷矩阵A 以及特征值λ的数学关系如下面这个公式:λiiiAU=故可以由这二者通过计算变量来求得主成分载荷矩阵U 。
新建一个SPSS 数据文件,将因子载荷矩阵中的各个载荷值复制进去,如下图所示:计算变量(Transform-Compute Variables)的公式分别如下二张图所示:计算变量得到的两个特征向量U1和U2如下图所示(U1和U2合起来就是主成分载荷矩阵):所以可以得到两个主成分Y1和Y2的表达式如下:Y1=0.456X1+0.401X2+0.428X3+0.490X4+0.380X5+0.253X6Y2=-0.367X1+0.322X2-0.323X3-0.303X4+0.453X5+0.602X6由上面两个表达式,可以通过计算变量来得到Y1、Y2的值。


s p s s进行主成分分析及得分分析(总9页)--本页仅作为文档封面,使用时请直接删除即可----内页可以根据需求调整合适字体及大小--spss进行主成分分析及得分分析1将数据录入spss1. 2数据标准化:打开数据后选择分析→描述统计→描述,对数据进行标准化,选中将标准化得分另存为变量:2.3进行主成分分析:选择分析→降维→因子分析,3.4设置描述性,抽取,得分和选项:4.5查看主成分分析和分析:相关矩阵表明,各项指标之间具有强相关性。
比如指标GDP总量与财政收入、固定资产投资总额、第二产业增加值、第三产业增加值、工业增加值的相关系数较大。
这说明他们之间指标信息之间存在重叠,适合采用主成分分析法。
(下表非完整呈现)5.6由 Total Variance Explained(主成分特征根和贡献率)可知,特征根λ1=,特征根λ2=前两个主成分的累计方差贡献率达%,即涵盖了大部分信息。
这表明前两个主成分能够代表最初的11个指标来分析河南各个城市经济综合实力的发展水平,故提取前两个指标即可。
主成分,分别记作F1、F2。
6.7指标X1、X2、X3、X4、X5、X6、X7、X8、X9、X10在第一主成分上有较高载荷,相关性强。
第一主成分集中反映了总体的经济总量。
X11在第二主成分上有较高载荷,相关性强。
第二主成分反映了人均的经济量水平。
但是要注意:这个主成分载荷矩阵并不是主成分的特征向量,也就是说并不是主成分1和主成分2的系数,主成分系数的求法是:各自主成分载荷向量除以各自主成分特征值的算术平方根。
7.8成分得分系数矩阵(因子得分系数)列出了强两个特征根对应的特征向量,即各主要成分解析表达式中的标准化变量的系数向量。
故各主要成分解析表达式分别为:F1=++++++++++F2=+主成分的得分是相应的因子得分乘以相应的方差的算术平方根。
即:主成分1得分=因子1得分乘以的算术平方根主成分2得分=因子2得分乘以的算术平方根例如郑州:主成分因子=FAC1_1*的算术平方根=*的算术平方根=,将各指标的标准化数据带入个主成分解析表达式中,分别计算出2个主成分得分(F1、F2),再以个主成分的贡献率为全书对主成分得分进行加权平均,即:H=(*F1+*F2)/,求得主成分综合得分。

实验七、利用SPSS进行主成分分析【例子】以全国31个省市的8项经济指标为例,进行主成分分析。
第一步:录入或调入数据(图1)。
图1 原始数据(未经标准化)第二步:打开“因子分析”对话框。
沿着主菜单的“Analyze→Data Reduction→Factor ”的路径(图2)打开因子分析选项框(图3)。
图2 打开因子分析对话框的路径图3 因子分析选项框第三步:选项设置。
首先,在源变量框中选中需要进行分析的变量,点击右边的箭头符号,将需要的变量调入变量(Variables)栏中(图3)。
在本例中,全部8个变量都要用上,故全部调入(图4)。
因无特殊需要,故不必理会“Value ”栏。
下面逐项设置。
图4 将变量移到变量栏以后⒈设置Descriptives描述选项。
单击Descriptives按钮(图4),弹出Descriptives对话框(图5)。
图5 描述选项框在Statistics 统计 栏中选中Univariate descriptives 复选项,则输出结果中将会给出原始数据的抽样均值、方差和样本数目(这一栏结果可供检验参考);选中Initial solution 复选项,则会给出主成分载荷的公因子方差(这一栏数据分析时有用)。
在Correlation Matrix 栏中,选中Coefficients 复选项,则会给出原始变量的相关系数矩阵(分析时可参考);选中Determinant 复选项,则会给出相关系数矩阵的行列式,如果希望在Excel 中对某些计算过程进行了解,可选此项,否则用途不大。
其它复选项一般不用,但在特殊情况下可以用到(本例不选)。
设置完成以后,单击Continue 按钮完成设置(图5)。
⒉ 设置Extraction 选项。
打开Extraction 对话框(图6)。
因子提取方法主要有7种,在Method 栏中可以看到,系统默认的提取方法是主成分(Principal Components ),因此对此栏不作变动,就是认可了主成分分析方法。