第七章_主成分分析
- 格式:ppt
- 大小:1.19 MB
- 文档页数:21



第七章主成分分析(一)教学目的通过本章的学习,对主成分分析从总体上有一个清晰地认识,理解主成分分析的基本思想和数学模型,掌握用主成分分析方法解决实际问题的能力。
(二)基本要求了解主成分分析的基本思想,几何解释,理解主成分分析的数学模型,掌握主成分分析方法的主要步骤。
(三)教学要点1、主成分分析基本思想,数学模型,几何解释2、主成分分析的计算步骤及应用(四)教学时数3课时(五)教学内容1、主成分分析的原理及模型2、主成分的导出及主成分分析步骤在实际问题中,我们经常会遇到研究多个变量的问题,而且在多数情况下,多个变量之间常常存在一定的相关性。
由于变量个数较多再加上变量之间的相关性,势必增加了分析问题的复杂性。
如何从多个变量中综合为少数几个代表性变量,既能够代表原始变量的绝大多数信息,又互不相关,并且在新的综合变量基础上,可以进一步的统计分析,这时就需要进行主成分分析。
第 - 213 - 页第一节 主成分分析的原理及模型一、主成分分析的基本思想及数学模型(一)主成分分析的基本思想主成分分析是采取一种数学降维的方法,找出几个综合变量来代替原来众多的变量,使这些综合变量能尽可能地代表原来变量的信息量,而且彼此之间互不相关。
这种将把多个变量化为少数几个互相无关的综合变量的统计分析方法就叫做主成分分析或主分量分析。
主成分分析所要做的就是设法将原来众多具有一定相关性的变量,重新组合为一组新的相互无关的综合变量来代替原来变量。
通常,数学上的处理方法就是将原来的变量做线性组合,作为新的综合变量,但是这种组合如果不加以限制,则可以有很多,应该如何选择呢?如果将选取的第一个线性组合即第一个综合变量记为1F ,自然希望它尽可能多地反映原来变量的信息,这里“信息”用方差来测量,即希望)(1F Var 越大,表示1F 包含的信息越多。
因此在所有的线性组合中所选取的1F 应该是方差最大的,故称1F 为第一主成分。
如果第一主成分不足以代表原来p 个变量的信息,再考虑选取2F 即第二个线性组合,为了有效地反映原来信息,1F 已有的信息就不需要再出现在2F 中,用数学语言表达就是要求0),(21 F F Cov ,称2F 为第二主成分,依此类推可以构造出第三、四……第p 个主成分。

sas主成分分析sas主成分分析第七章主成分分析实验目的:熟悉并掌握主成分分析和因子分析的原理和在变量分类、综合评价、主成分回归等几个方面的应用,以及相应的SAS程序实现。
实验内容:对我国钢铁行业上市公司的财务绩效状况进行主成分分析,选择的财务指标共有以下几个:流动比率,速动比率,存货周转率,总资产周转率,净资产收益率,经营净利率,每股收益,净资产收益率增长率,股东权益增长率。
数据如下:完成以下工作:(1)选取累积贡献率>85%的前几个主成分,分别计算得分;并对选取的主成分进行解释;(2)对各上市公司的财务绩效进行综合评价;(3)利用选取的主成分得分,借助聚类分析过程对钢铁行业上市公司进行分类。
datazcf;inputname$x1-x9;cards;邯郸钢铁1.5510.9717.1650.88910.7689.2680.451-16.0246.122武钢股份2.1921.828.0880.97515.05411.1140.336-3.0392.588钢联股份1.2860.9418.0441.1247.3894.5990.205-59.988122.041宝钢股份0.9790.5718.130.6019.7428.780.205-17.6853.989莱钢股份1.3640.4975.0780.9314.1039.1370.523-24.26114.16西宁特钢1.4330.6721.4620.4716.4297.2680.1559.3493.027杭钢股份2.1081.4988.3731.41816.7567.9370.531-18.72513.662邢台轧辊2.11.5951.8830.3966.4848.9810.1325.275-1.061宁夏恒力1.3641.0641.8680.2787.46919.8420.201-35.19455.428凌钢股份1.7721.0617.8411.11912.8838.8040.5285.34310.107南钢股份1.8181.3928.8661.54612.8855.1530.409-7.0286.131酒钢宏兴1.4410.88410.1681.07112.8317.8250.36744.0376.686抚顺特钢0.9550.6523.4160.5097.1476.8510.193-8.0741.93安阳钢铁1.8931.3335.1070.9810.9497.9150.3500上海科技1.3131.1824.6430.5689.5499.4230.19935.6353.582沪昌特钢10.8139.536.5850.5671.1031.6560.01915.031-7.171山川股份1.2520.5851.4850.45110.34414.6930.209-1.6159.799浦东不锈6.1865.1212.3630.2650.7542.5130.013-45.439-1.176新华股份1.8171.3143.2910.7469.9249.0280.137-3.5771.985工益股份1.8091.2674.0460.8280.6950.450.011104.419-4.714马钢股份1.5841.0694.3180.5692.0032.1830.03235.279-12.487宝信软件3.5943.2015.0140.82114.669.7210.147126.91123.243北特钢1.3851.0922.6910.467-11.21-7.917-0.14853.839-11.058广钢股份0.8590.513.8840.7224.2472.6850.096-32.409-4.004;procprincompn=9out=prin;varX1-x9;run;procprintdata=prin;varprin1-prin9;run;主要输出结果:相关阵的特征值和特征向量EigenvalueDifferenceProportionCumulative13.626730451.710877240.40300.403021.915853210.519337180.21290.615831.396516020.349008540.15520.771041.047507480.371047740.11640.887450.676459740.478913290.07520.962660.197546440.106501190.02190.984570.091045260.044878480.01010.994680.046166770.043992140.00510.999890.002174630.00021.0000EigenvectorsPrin1Prin2Prin3Prin4Prin5Prin6Prin7Prin8Prin9x1-.2632570.5528190.3251720.0999320.0123340.1292890.077190-.0215500.697189x2-.2696730.5512290.3176490.0909930.0600930.065411-.0196680.049407-.709595x30.3207430.454750-.227474-.1958410.013020-.7729000.0382700.0086860.033825x40.3790330.331485-.342911-.1840840.0144020.490904-.3231210.4986720.026498x50.4608530.1052280.1235360.3670920.0903870.094185-.486791-.610331-.003691x60.308953-.1918380.4762280.4505290.202663-.228562-.0285870.5848690.042126x70.4802260.1255120.0219100.155827-.2454280.2558630.762567-.122168-.082054x8-.1693840.077314-.5106640.4440140.6759650.0353110.220767-.0214310.005659x90.210440-.0652010.347445-.5918860.6553280.1132300.140544-.1355950.001607由输出特征值可知,第一主成分的贡献率为40.30%,第二个主成分的.贡献率为61.58%,第三个主成分的贡献率为77.10%,前四个主成分累计贡献率为88.74%。

可编辑修改精选全文完整版主成分分析(principal component analysis, PCA)如果一组数据含有N个观测样本,每个样本需要检测的变量指标有K个, 如何综合比较各个观测样本的性质优劣或特点?这种情况下,任何选择其中单个变量指标对本进行分析的方法都会失之偏颇,无法反映样本综合特征和特点。
这就需要多变量数据统计分析。
多变量数据统计分析中一个重要方法是主成份分析。
主成分分析就是将上述含有N个观测样本、K个变量指标的数据矩阵转看成一个含有K维空间的数学模型,N个观测样本分布在这个模型中。
从数据分析的本质目的看,数据分析目标总是了解样本之间的差异性或者相似性,为最终的决策提供参考。
因此,对一个矩阵数据来说,在K维空间中,总存在某一个维度的方向,能够最大程度地描述样品的差异性或相似性(图1)。
基于偏最小二乘法原理,可以计算得到这个轴线。
在此基础上,在垂直于第一条轴线的位置找出第二个最重要的轴线方向,独立描述样品第二显著的差异性或相似性;依此类推到n个轴线。
如果有三条轴线,就是三维立体坐标轴。
形象地说,上述每个轴线方向代表的数据含义,就是一个主成份。
X、Y、Z轴就是第1、2、3主成份。
由于人类很难想像超过三维的空间,因此,为了便于直观观测,通常取2个或者3个主成份对应图进行观察。
图(1)PCA得到的是一个在最小二乘意义上拟合数据集的数学模型。
即,主成分上所有观测值的坐标投影方差最大。
从理论上看,主成分分析是一种通过正交变换,将一组包含可能互相相关变量的观测值组成的数据,转换为一组数值上线性不相关变量的数据处理过程。
这些转换后的变量,称为主成分(principal component, PC)。
主成分的数目因此低于或等于原有数据集中观测值的变量数目。
PCA最早的发明人为Karl Pearson,他于1901年发表的论文中以主轴定理(principal axis theorem)衍生结论的形式提出了PCA的雏形,但其独立发展与命名是由Harold Hotelling于1930年前后完成。
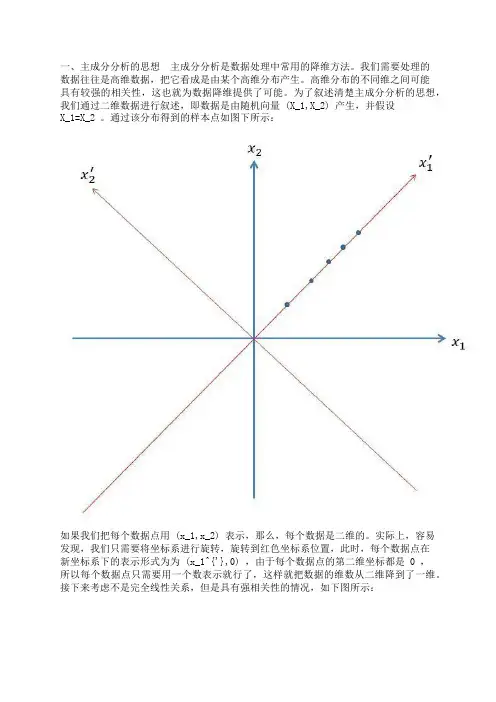
一、主成分分析的思想主成分分析是数据处理中常用的降维方法。
我们需要处理的数据往往是高维数据,把它看成是由某个高维分布产生。
高维分布的不同维之间可能具有较强的相关性,这也就为数据降维提供了可能。
为了叙述清楚主成分分析的思想,我们通过二维数据进行叙述,即数据是由随机向量 (X_1,X_2) 产生,并假设X_1=X_2 。
通过该分布得到的样本点如图下所示:如果我们把每个数据点用 (x_1,x_2) 表示,那么,每个数据是二维的。
实际上,容易发现,我们只需要将坐标系进行旋转,旋转到红色坐标系位置,此时,每个数据点在新坐标系下的表示形式为为 (x_1^{'},0) ,由于每个数据点的第二维坐标都是 0 ,所以每个数据点只需要用一个数表示就行了,这样就把数据的维数从二维降到了一维。
接下来考虑不是完全线性关系,但是具有强相关性的情况,如下图所示:在这种情况下,我们不可能通过坐标系的平移与旋转,使所有点都落在一根轴上,即不可能精确地把数据用一维表示。
但是注意到 (X_1,X_2) 仍然有强相关性,我们仍然将坐标轴旋转到红色位置,可以看出,将数据在 x_1^{'} 上的投影近似代表原数据,几乎可以完全反映出原数据的分布。
直观看,如果要将数据投影到某根轴,并用投影来表示原数据,将数据压缩成一维,那么投影到 x_1^{'} 是最好的选择。
因为投影到这跟轴,相比于投影到其他轴,对原数据保留的信息量最多,损失最小。
如何衡量保留的信息量呢?在主成分分析中,我们用数据在该轴的投影的方差大小来衡量,即投影后方差越大(即投影点越分散),我们认为投影到该轴信息保留量最多。
从这种观点看,投影到 x_1^{'} 确实是最好的选择,因为投影到这根轴,可使得投影点最分散。
我们将数据的中心平移到原点(即新坐标轴的原点在数据的中心位置),为了消除单位的影响,我们将数据的方差归一化。
进一步考虑如下数据分布:根据上述,如果要将数据压缩为一维的,那么应该选择 F_1 轴进行投影,如果用该投影表示原数据的损失过大,我们可以再选择第二根轴进行投影,第二根轴应该与 F_1 垂直(保证在两根轴上的投影是不相关的)并且使得数据在该轴上投影方差最大,即图中的 F_2 轴(如果是二维情况,第一根轴确定后,第二根轴就确定了。

7.1 设随机变量12X(X ,X )'=的协差阵为21,12⎡⎤∑=⎢⎥⎣⎦试求X的特征根和特征向量,并写出主成分。
解:先求X的特征根λ,λ满足方程:21012-λ=-λ,即2(2)10-λ-=,因此两个特征根分别为123, 1.λ=λ=设13λ=对应的单位特征向量为()1121a ,a ',则()1121a ,a '满足:1121a 110a 110-⎛⎫⎡⎤⎛⎫= ⎪ ⎪⎢⎥-⎣⎦⎝⎭⎝⎭,故可以取1121a a ⎛⎛⎫ = ⎪ ⎝⎭ ⎝,其对应主成分为:112F X X 22=+;设21λ=对应的单位特征向量为()1222a ,a ',则()1222a ,a '满足:1222a 110a 110⎛⎫⎡⎤⎛⎫=⎪ ⎪⎢⎥⎣⎦⎝⎭⎝⎭,故可以取1222a a ⎛⎫⎛⎫ ⎪= ⎪ ⎝⎭- ⎝,其对应的主成分为:212F 22=-.7.2设随机变量123X (X ,X ,X )'=的协差阵为120250,002-⎡⎤⎢⎥∑=-⎢⎥⎢⎥⎣⎦试求X的主成分及主成分对变量X的贡献率。
解:先求X的特征根λ,λ满足方程:12025002-λ---λ=-λ,即()2(2)610-λλ-λ+=,因此三个特征根分别为1235.8284,2,0.1716λ=λ=λ=设1 5.8284λ=对应的单位特征向量为()112131a ,a ,a ',则它满足:1121314.828420a 020.82840a 000 3.8284a 0--⎡⎤⎛⎫⎛⎫⎪ ⎪⎢⎥--=⎪ ⎪⎢⎥ ⎪ ⎪⎢⎥-⎣⎦⎝⎭⎝⎭,故可以取 112131a 10.38271a 2.41420.92392.6131a 00⎛⎫⎛⎫⎛⎫⎪ ⎪ ⎪=-=- ⎪ ⎪ ⎪ ⎪ ⎪ ⎪⎝⎭⎝⎭⎝⎭,其对应主成分为: 112F 0.3827X 0.9239X =-,其贡献率为5.828472.86%5.828420.1716=++;设22λ=对应的单位特征向量为()122232a,a ,a ',则它满足:122232120a 0230a 0000a 0--⎡⎤⎛⎫⎛⎫ ⎪ ⎪⎢⎥-= ⎪ ⎪⎢⎥ ⎪ ⎪⎢⎥⎣⎦⎝⎭⎝⎭,故可以取122232a 0a 0a 1⎛⎫⎛⎫⎪ ⎪= ⎪ ⎪ ⎪ ⎪⎝⎭⎝⎭,其对应主成分为: 23F X =,其贡献率为225%5.828420.1716=++;设30.1716λ=对应的单位特征向量为()132333a ,a ,a ',则它满足:1323330.828420a 02 4.82840a 000 1.8284a 0-⎡⎤⎛⎫⎛⎫⎪ ⎪⎢⎥-=⎪ ⎪⎢⎥ ⎪ ⎪⎢⎥⎣⎦⎝⎭⎝⎭,故可以取132333a 10.92391a 0.41420.38271.0824a 00⎛⎫⎛⎫⎛⎫⎪ ⎪ ⎪== ⎪ ⎪ ⎪ ⎪ ⎪ ⎪⎝⎭⎝⎭⎝⎭,其对应主成分为: 312F 0.9239X 0.3827X =+,其贡献率为0.17162.14%5.828420.1716=++.7.3 设随机变量12X (X ,X )'=的协差阵为14,4100⎡⎤∑=⎢⎥⎣⎦试从∑和相关阵R出发求出总体主成分,并加以比较。


主成分分析法的原理和步骤主成分分析(Principal Component Analysis,简称PCA)是一种常用的多元统计分析方法,它通过线性变换将高维数据转换为低维数据,从而实现降维和数据可视化。
PCA的基本思想是通过选取少数几个主成分,将原始变量的方差最大化,以便保留大部分的样本信息。
下面我将详细介绍PCA的原理和步骤。
一、主成分分析的原理主成分分析的核心原理是将n维的数据通过线性变换转换为k维数据(k<n),这k维数据是原始数据最具有代表性的几个维度。
主成分是原始数据在新坐标系中的方向,其方向与样本散布区域最大的方向一致,而且不同主成分之间互不相关。
也就是说,新的坐标系是通过原始数据的协方差矩阵的特征值分解得到的。
具体来说,假设我们有一个m个样本、维度为n的数据集X,其中每个样本为一个n维向量,可以表示为X=\left ( x_{1},x_{2},...,x_{m} \right )。
我们的目标是找到一组正交的基变量(即主成分)U=\left ( u_{1},u_{2},...,u_{n} \right ),使得原始数据集在这组基变量上的投影方差最大。
通过对协方差矩阵的特征值分解,可以得到主成分对应的特征向量,也就是新的基变量。
二、主成分分析的步骤主成分分析的具体步骤如下:1. 标准化数据:对于每一维度的数据,将其减去均值,然后除以标准差,从而使得数据具有零均值和单位方差。
标准化数据是为了消除不同维度上的量纲差异,确保各维度对结果的影响是相等的。
2. 计算协方差矩阵:对标准化后的数据集X,计算其协方差矩阵C。
协方差矩阵的元素c_{ij}表示第i维度与第j维度之间的协方差,可以用以下公式表示:\[c_{ij}=\frac{\sum_{k=1}^{m}\left ( x_{ik}-\bar{X_{i}} \right )\left( x_{jk}-\bar{X_{j}} \right )}{m-1}\]其中,\bar{X_{i}}表示第i维度的平均值。


第七章因子分析7.1试述因子分析与主成分分析的联系与区别。
答:因子分析与主成分分析的联系是:①两种分析方法都是一种降维、 简化数据的技术。
②两种分析的求解过程是类似的,都是从一个协方差阵出发,利用特征值、特征向量求解。
因子分析可以说是主成分分析的姐妹篇, 将主成分分析向前推进一步便导致因子分析。
因子分析也可以说成是主成分分析的逆问题。
如果说主成分分析是将原指标综合、归纳,那么因子分析可以说是将原指标给予分解、演绎。
因子分析与主成分分析的主要区别是:主成分分析本质上是一种线性变换,将原始坐标 变换到变异程度大的方向上为止,突出数据变异的方向, 归纳重要信息。
而因子分析是从显在变量去提炼潜在因子的过程。
此外,主成分分析不需要构造分析模型而因子分析要构造因 子模型。
7.2 因子分析主要可应用于哪些方面?答:因子分析是一种通过显在变量测评潜在变量,通过具体指标测评抽象因子的统计分析方法。
目前因子分析在心理学、社会学、经济学等学科中都有重要的应用。
具体来说,①因子 分析可以用于分类。
如用考试分数将学生的学习状况予以分类;用空气中各种成分的比例对 空气的优劣予以分类等等②因子分析可以用于探索潜在因素。
即是探索未能观察的或不能观测的的潜在因素是什么,起的作用如何等。
对我们进一步研究与探讨指示方向。
在社会调查分析中十分常用。
③因子分析的另一个作用是用于时空分解。
如研究几个不同地点的不同日期的气象状况,就用因子分析将时间因素引起的变化和空间因素引起的变化分离开来从而判 断各自的影响和变化规律。
7.3简述因子模型、一 m 卜中载荷矩阵A 的统计意义。
答:对于因子模型X i =a i 1F 1 - mF ?a j F j I" a m F m•;ii =1,2,Hl , pX i 与F j 的协方差为:mCov(X i , F j ) =Cov(' a ik F k °F j )k=im= Cov(' a ik F k ,F j ) Cov(「F j )k d= a ij若对X i 作标准化处理,=a j ,因此a ij 一方面表示X i 对F j 的依赖程度;另一方面也反映了 变量X i 对公共因子F j的相对重要性。