主成分分析和因子分析习题答案
- 格式:docx
- 大小:96.09 KB
- 文档页数:11

7.1 设随机变量12X(X ,X )'=的协差阵为21,12⎡⎤∑=⎢⎥⎣⎦试求X的特征根和特征向量,并写出主成分。
解:先求X的特征根λ,λ满足方程:21012-λ=-λ,即2(2)10-λ-=,因此两个特征根分别为123, 1.λ=λ=设13λ=对应的单位特征向量为()1121a ,a ',则()1121a ,a '满足:1121a 110a 110-⎛⎫⎡⎤⎛⎫= ⎪ ⎪⎢⎥-⎣⎦⎝⎭⎝⎭,故可以取1121a a ⎛⎛⎫ = ⎪ ⎝⎭ ⎝,其对应主成分为:112F X X 22=+;设21λ=对应的单位特征向量为()1222a ,a ',则()1222a ,a '满足:1222a 110a 110⎛⎫⎡⎤⎛⎫=⎪ ⎪⎢⎥⎣⎦⎝⎭⎝⎭,故可以取1222a a ⎛⎫⎛⎫ ⎪= ⎪ ⎝⎭- ⎝,其对应的主成分为:212F 22=-.7.2设随机变量123X (X ,X ,X )'=的协差阵为120250,002-⎡⎤⎢⎥∑=-⎢⎥⎢⎥⎣⎦试求X的主成分及主成分对变量X的贡献率。
解:先求X的特征根λ,λ满足方程:12025002-λ---λ=-λ,即()2(2)610-λλ-λ+=,因此三个特征根分别为1235.8284,2,0.1716λ=λ=λ=设1 5.8284λ=对应的单位特征向量为()112131a ,a ,a ',则它满足:1121314.828420a 020.82840a 000 3.8284a 0--⎡⎤⎛⎫⎛⎫⎪ ⎪⎢⎥--=⎪ ⎪⎢⎥ ⎪ ⎪⎢⎥-⎣⎦⎝⎭⎝⎭,故可以取 112131a 10.38271a 2.41420.92392.6131a 00⎛⎫⎛⎫⎛⎫⎪ ⎪ ⎪=-=- ⎪ ⎪ ⎪ ⎪ ⎪ ⎪⎝⎭⎝⎭⎝⎭,其对应主成分为: 112F 0.3827X 0.9239X =-,其贡献率为5.828472.86%5.828420.1716=++;设22λ=对应的单位特征向量为()122232a,a ,a ',则它满足:122232120a 0230a 0000a 0--⎡⎤⎛⎫⎛⎫ ⎪ ⎪⎢⎥-= ⎪ ⎪⎢⎥ ⎪ ⎪⎢⎥⎣⎦⎝⎭⎝⎭,故可以取122232a 0a 0a 1⎛⎫⎛⎫⎪ ⎪= ⎪ ⎪ ⎪ ⎪⎝⎭⎝⎭,其对应主成分为: 23F X =,其贡献率为225%5.828420.1716=++;设30.1716λ=对应的单位特征向量为()132333a ,a ,a ',则它满足:1323330.828420a 02 4.82840a 000 1.8284a 0-⎡⎤⎛⎫⎛⎫⎪ ⎪⎢⎥-=⎪ ⎪⎢⎥ ⎪ ⎪⎢⎥⎣⎦⎝⎭⎝⎭,故可以取132333a 10.92391a 0.41420.38271.0824a 00⎛⎫⎛⎫⎛⎫⎪ ⎪ ⎪== ⎪ ⎪ ⎪ ⎪ ⎪ ⎪⎝⎭⎝⎭⎝⎭,其对应主成分为: 312F 0.9239X 0.3827X =+,其贡献率为0.17162.14%5.828420.1716=++.7.3 设随机变量12X (X ,X )'=的协差阵为14,4100⎡⎤∑=⎢⎥⎣⎦试从∑和相关阵R出发求出总体主成分,并加以比较。

1.(10分)数据中心化和标准化在回归分析中的意义是什么?在多元线性回归分析中,因为涉及多个自变量,自变量的单位往往不同,会给分析带来一定的困难,又由于涉及的数据量很大,就可能会以舍入误差而使得计算结果不理想.1.中心化处理后可以减少一个未知参数,减少了计算的工作量,对手工计算尤为重要.2.标准化处理后有利于消除量纲不同和数量级的差异所带来的影响,避免不必要的误差.2.(10分)在实际问题中运用多元线性回归应注意哪些问题?在实际问题中,人们用复相关系数R来表示回归方程对原有数据拟合程度的好坏,但是拟合优度并不是检验模型优劣的唯一标准,有时为了使模型从结构上有较合理的经济解释,R2等于0.7左右也给回归模型以肯定的态度.在多元线性回归分析中,我们并不看重简单相关系数,而认为偏相关系数才是真正反映因变量y与自变量x i以及自变量x i与x j的相关性的数量.用相关系数R2大小来衡量模型的拟合优度,不能仅由R2值很大来推断模型优劣.在实际应用回归方程进行控制和预测时,给定的x0值不能偏离样本均值太大,如果太大,用回归方程无论是作因素分析还是经济预测,效果都不会理想.得到实际问题的经验回归方程后,还不能马上用它去作分析和预测,还需运用统计方法对回归方程进行检验.3.(15分)主成分分析与因子分析的主要方法和思想是什么?两者有何联系与区别?求解主成分的方法:从协方差阵出发(协方差阵已知),从相关阵出发(相关阵R 已知),采用的方法只有主成分法。
一、主成分分析的基本思想在对某一事物进行实证研究中,为了更全面、准确地反映出事物的特征及其发展规律,人们往往要考虑与其有关系的多个指标,这些指标在多元统计中也称为变量。
这样就产生了如下问题:一方面人们为了避免遗漏重要的信息而考虑尽可能多的指标,而另一方面随着考虑指标的增多增加了问题的复杂性,同时由于各指标均是对同一事物的反映,不可避免地造成信息的大量重叠,这种信息的重叠有时甚至会抹杀事物的真正特征与内在规律。

主成分分析和因子分析
习题答案
SANY标准化小组 #QS8QHH-HHGX8Q8-GNHHJ8-HHMHGN#
第11章主成分分析和因子分析
司盈利能力有关,因此可命名为“盈利能力”。
因子2 与X5(资产负债率)、X6(流动比率)X8(资本积累率)这3个变量的载荷系数较大,这三个变量主要涉及企业的偿债能力,因此可命为“偿债能力因子”。
因子3与X1(主营业务利润)、 X4(总资产周转率)、X7(主营业务收增长率)这三个变量的载荷系数较大,这三个变量分别涉及了盈利能力、资产管理水平、企业成能力等,因此,这个因子的命名比较困难。
各公所的因子综合得分和排名如下:
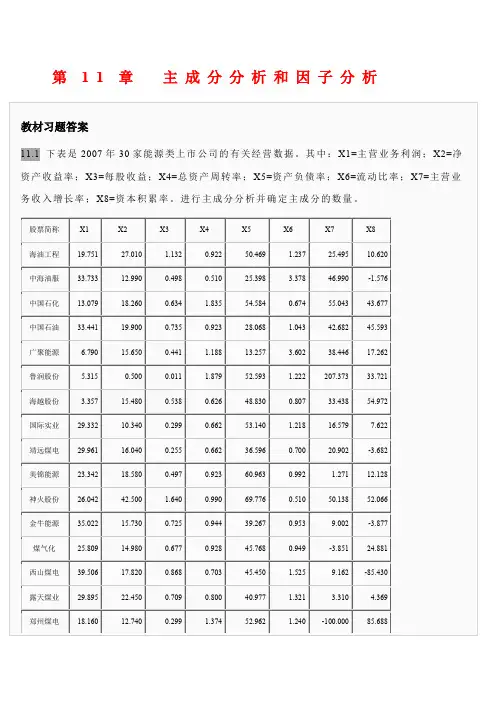
对下表中的50名学生成绩进行主成分分析,可以选择几个综合变量来代表这些学生的六门课程绩
学生代码数学物理化学语文历史英语
1716494526152
2789681808976
3695667759480
4779080686660
5846775607063
6626783718577。

主成分分析和因子分析法一、主成分分析概论主成分分析的工作对象是样本点×定量变量类型的数据表。
它的工作目标,就是要对这种多变量的平面数据表进行最佳综合简化。
也就是说,要在力保数据信息丢失最少的原则下,对高维变量空间进行降维处理。
很显然,识辨系统在一个低维空间要比一个高维空间容易得多。
英国统计学家斯格特(M.Scott )在1961年对157个英国城镇发展水平进行调查时,原始测量的变量有57个。
而通过主成分分析发现,只需5个新的综合变量(它们是原变量的线性组合),就可以95%的精度表示原数据的变异情况,这样,对问题的研究一下子从57维降到5维。
可以想象,在5维空间中对系统进行任何分析,都比在57维中更加快捷、有效。
另一项十分著名的工作是美国的统计学家斯通(Stone)在1947年关于国民经济的研究。
他曾利用美国1929~1938年各年的数据,得到了17个反映国民收入与支出的变量要素,例如雇主补贴、消费资料和生产资料、纯公共支出、净增库存、股息、利息和外贸平衡等等。
在进行主成分分析后,竟以97.4%的精度,用三个新变量就取代了原17个变量。
根据经济学知识,斯通给这三个新变量要别命名为总收入1F 、总收入变化率2F 和经济发展或衰退的趋势3F (是时间t 的线性项)。
更有意思的是,这三个变量其实都是可以直接测量的。
二、主成分分析的基本思想与理论1、主成分分析的基本思想在对某一事物进行实证研究中,为了更全面、准确地反映出事物的特征及其发展规律,人们往往要考虑与其有关系的多个指标,这些指标在多元统计中也称为变量。
这样就产生了如下问题:一方面人们为了避免遗漏重要的信息而考虑尽可能多的指标,而另一方面随着考虑指标的增多增加了问题的复杂性,同时也由于各指标均是对同一事物的反映,不可避免地造成信息的大量重叠,这种信息有时甚至会抹杀事物的真正特征与内在规律。
基于上述问题,人们就希望在定量研究中涉及的变量较少,而得到的信息量又较多。

一主成分分析法的原理主成分分析法是利用降维的思想,在损失很少信息的前提下把多个指标转化为几个综合指标的多元统计方法这些综合指标通常被称为主成分,主成分相比原始变量而言,具有更多的优越性,即在研究许多复杂问题时不至于丢失太多信息,从而使我们更容易抓住事物的主要矛盾,提高分析效率该方法的核心就是通过主成分分析,选择n个主分量Y1,Y2,…,Yn,其中Yi (i=1,2,,n)为第i个主成分的得分,以主分量Yi 的方差贡献率ai 作为权数,构造综合评价函数:Y=a1Y2+a2Y2+ +anYn,这样当我们把第i个主成分的得分算出来后,便可以很快求出综合得分,并且按照得分的高低来排序同时我们可以根据第i个主成分的得分来衡量某地区或某企业在第i个主成分所代表的经济效益方面的地位二、主成分分析的基本思想在实证问题研究中,为了全面、系统地分析问题,我们必须考虑众多影响因素。
这些涉及的因素一般称为指标,在多元统计分析中也称为变量。
因为每个变量都在不同程度上反映了所研究问题的某些信息,并且指标之间彼此有一定的相关性,因而所得的统计数据反映的信息在一定程度上有重叠。
在用统计方法研究多变量问题时,变量太多会增加计算量和增加分析问题的复杂性,人们希望在进行定量分析的过程中,涉及的变量较少,得到的信息量较多。
主成分分析正是适应这一要求产生的,是解决这类题的理想工具。
同样,在科普效果评估的过程中也存在着这样的问题。
科普效果是很难具体量化的。
在实际评估工作中,我们常常会选用几个有代表性的综合指标,采用打分的方法来进行评估,故综合指标的选取是个重点和难点。
如上所述,主成分分析法正是解决这一问题的理想工具。
因为评估所涉及的众多变量之间既然有一定的相关性,就必然存在着起支配作用的因素。
根据这一点,通过对原始变量相关矩阵内部结构的关系研究,找出影响科普效果某一要素的几个综合指标,使综合指标为原来变量的线性拟合。
这样,综合指标不仅保留了原始变量的主要信息,且彼此间不相关,又比原始变量具有某些更优越的性质,就使我们在研究复杂的科普效果评估问题时,容易抓住主要矛盾。
主成分分析和因子分析法一、主成分分析概论主成分分析的工作对象是样本点×定量变量类型的数据表。
它的工作目标,就是要对这种多变量的平面数据表进行最佳综合简化。
也就是说,要在力保数据信息丢失最少的原则下,对高维变量空间进行降维处理。
很显然,识辨系统在一个低维空间要比一个高维空间容易得多。
英国统计学家斯格特(M.Scott )在1961年对157个英国城镇发展水平进行调查时,原始测量的变量有57个。
而通过主成分分析发现,只需5个新的综合变量(它们是原变量的线性组合),就可以95%的精度表示原数据的变异情况,这样,对问题的研究一下子从57维降到5维。
可以想象,在5维空间中对系统进行任何分析,都比在57维中更加快捷、有效。
另一项十分著名的工作是美国的统计学家斯通(Stone)在1947年关于国民经济的研究。
他曾利用美国1929~1938年各年的数据,得到了17个反映国民收入与支出的变量要素,例如雇主补贴、消费资料和生产资料、纯公共支出、净增库存、股息、利息和外贸平衡等等。
在进行主成分分析后,竟以97.4%的精度,用三个新变量就取代了原17个变量。
根据经济学知识,斯通给这三个新变量要别命名为总收入1F 、总收入变化率2F 和经济发展或衰退的趋势3F (是时间t 的线性项)。
更有意思的是,这三个变量其实都是可以直接测量的。
二、主成分分析的基本思想与理论1、主成分分析的基本思想在对某一事物进行实证研究中,为了更全面、准确地反映出事物的特征及其发展规律,人们往往要考虑与其有关系的多个指标,这些指标在多元统计中也称为变量。
这样就产生了如下问题:一方面人们为了避免遗漏重要的信息而考虑尽可能多的指标,而另一方面随着考虑指标的增多增加了问题的复杂性,同时也由于各指标均是对同一事物的反映,不可避免地造成信息的大量重叠,这种信息有时甚至会抹杀事物的真正特征与内在规律。
基于上述问题,人们就希望在定量研究中涉及的变量较少,而得到的信息量又较多。

第七章 因子分析7.1 试述因子分析与主成分分析的联系与区别。
答:因子分析与主成分分析的联系是:①两种分析方法都是一种降维、简化数据的技术。
②两种分析的求解过程是类似的,都是从一个协方差阵出发,利用特征值、特征向量求解。
因子分析可以说是主成分分析的姐妹篇,将主成分分析向前推进一步便导致因子分析。
因子分析也可以说成是主成分分析的逆问题。
如果说主成分分析是将原指标综合、归纳,那么因子分析可以说是将原指标给予分解、演绎。
因子分析与主成分分析的主要区别是:主成分分析本质上是一种线性变换,将原始坐标变换到变异程度大的方向上为止,突出数据变异的方向,归纳重要信息。
而因子分析是从显在变量去提炼潜在因子的过程。
此外,主成分分析不需要构造分析模型而因子分析要构造因子模型。
7.2 因子分析主要可应用于哪些方面?答:因子分析是一种通过显在变量测评潜在变量,通过具体指标测评抽象因子的统计分析方法。
目前因子分析在心理学、社会学、经济学等学科中都有重要的应用。
具体来说,①因子分析可以用于分类。
如用考试分数将学生的学习状况予以分类;用空气中各种成分的比例对空气的优劣予以分类等等②因子分析可以用于探索潜在因素。
即是探索未能观察的或不能观测的的潜在因素是什么,起的作用如何等。
对我们进一步研究与探讨指示方向。
在社会调查分析中十分常用。
③因子分析的另一个作用是用于时空分解。
如研究几个不同地点的不同日期的气象状况,就用因子分析将时间因素引起的变化和空间因素引起的变化分离开来从而判断各自的影响和变化规律。
7.3 简述因子模型中载荷矩阵A 的统计意义。
答:对于因子模型1122i i i ij j im m i X a F a F a F a F ε=++++++ 1,2,,i p =因子载荷阵为11121212221212(,,,)m m m p p pm a a a a a a A A A a a a ⎡⎤⎢⎥⎢⎥==⎢⎥⎢⎥⎢⎥⎣⎦Ai X 与j F 的协方差为:1Cov(,)Cov(,)mi j ik k i j k X F a F F ε==+∑=1Cov(,)Cov(,)mikk j i j k aF F F ε=+∑=ij a若对i X 作标准化处理,=ij a ,因此 ij a 一方面表示i X 对j F 的依赖程度;另一方面也反映了变量iX对公共因子jF的相对重要性。


第七章 因子分析7.1 试述因子分析与主成分分析的联系与区别。
答:因子分析与主成分分析的联系是:①两种分析方法都是一种降维、简化数据的技术。
②两种分析的求解过程是类似的,都是从一个协方差阵出发,利用特征值、特征向量求解。
因子分析可以说是主成分分析的姐妹篇,将主成分分析向前推进一步便导致因子分析。
因子分析也可以说成是主成分分析的逆问题。
如果说主成分分析是将原指标综合、归纳,那么因子分析可以说是将原指标给予分解、演绎。
因子分析与主成分分析的主要区别是:主成分分析本质上是一种线性变换,将原始坐标变换到变异程度大的方向上为止,突出数据变异的方向,归纳重要信息。
而因子分析是从显在变量去提炼潜在因子的过程。
此外,主成分分析不需要构造分析模型而因子分析要构造因子模型。
7.2 因子分析主要可应用于哪些方面? 答:因子分析是一种通过显在变量测评潜在变量,通过具体指标测评抽象因子的统计分析方法。
目前因子分析在心理学、社会学、经济学等学科中都有重要的应用。
具体来说,①因子分析可以用于分类。
如用考试分数将学生的学习状况予以分类;用空气中各种成分的比例对空气的优劣予以分类等等②因子分析可以用于探索潜在因素。
即是探索未能观察的或不能观测的的潜在因素是什么,起的作用如何等。
对我们进一步研究与探讨指示方向。
在社会调查分析中十分常用。
③因子分析的另一个作用是用于时空分解。
如研究几个不同地点的不同日期的气象状况,就用因子分析将时间因素引起的变化和空间因素引起的变化分离开来从而判断各自的影响和变化规律。
7.3 简述因子模型中载荷矩阵A 的统计意义。
答:对于因子模型1122i i i ij j im m i X a F a F a F a F ε=++++++ 1,2,,i p =因子载荷阵为11121212221212(,,,)m m m p p pm a a a a a a A A A a a a ⎡⎤⎢⎥⎢⎥==⎢⎥⎢⎥⎢⎥⎣⎦Ai X 与j F 的协方差为:1Cov(,)Cov(,)mi j ik k i j k X F a F F ε==+∑=1Cov(,)Cov(,)mikk j i j k aF F F ε=+∑=ij a若对i X 作标准化处理,=ij a ,因此 ij a 一方面表示i X 对j F 的依赖程度;另一方面也反映了变量iX 对公共因子jF 的相对重要性。

主成分和因子分析一、问题介绍为评估马里地区(西非)斯卡索地区自然资源是否可以支持扩大的食物需求的安全线,一项研究得到一组调查数据,总共调查了n=20个农夫,得到了关于9个变量的观测,变量罗列如下:X:Family(家中人口数)1X:DistRd(到最近大路的距离(km))2X:Cotton(2000年种植棉花的公顷数)3X:Maize(2000年种植玉米的公顷数)4X:Sorg(2000年种植高粱的公顷数)5X: Millet(2000年种植黍子的公顷数)6X:Bull(饲养的骟牛或其他骟家畜的总头数)7X:Cattle(奶牛总数)8X:Goats(山羊总数)9数据见表2-1:表2-1 马里家庭农场数据X1 X2 X3 X4 X5 X6 X7 X8 X91 12 80 1.5 13 0.25 2 0 12 54 8 6 4 0 1 6 32 53 11 13 0.5 1 0 0 0 0 04 21 13 2 2.5 1 0 1 0 55 61 30 3 5 0 0 4 21 06 20 70 0 2 3 0 2 0 37 29 35 1.5 2 0 0 0 0 08 29 35 2 3 2 0 0 0 09 57 9 5 5 0 0 4 5 210 23 33 2 2 1 0 2 1 711 20 0 1.5 1 3 0 1 6 012 27 41 1.1 0.25 1.5 1.5 0 3 113 18 500 2 1 1.5 0.5 1 0 014 30 19 2 2 4 1 2 0 515 77 18 8 4 6 4 6 8 616 21 500 5 1 3 4 1 0 517 13 100 0.5 1.5 0 1 0 0 418 24 100 2 3 0 0.5 3 14 1019 29 90 2 1.5 1.5 1.5 2 0 220 57 90 10 7 0 1.5 7 8 7二、主成分分析1、表2-2,是描述统计表,显示了各个变量的均值、标准误差和参与计算的样品数。
第七章因子分析7.1试述因子分析与主成分分析的联系与区别。
答:因子分析与主成分分析的联系是:①两种分析方法都是一种降维、 简化数据的技术。
②两种分析的求解过程是类似的,都是从一个协方差阵出发,利用特征值、特征向量求解。
因子分析可以说是主成分分析的姐妹篇, 将主成分分析向前推进一步便导致因子分析。
因子分析也可以说成是主成分分析的逆问题。
如果说主成分分析是将原指标综合、归纳,那么因子分析可以说是将原指标给予分解、演绎。
因子分析与主成分分析的主要区别是:主成分分析本质上是一种线性变换,将原始坐标 变换到变异程度大的方向上为止,突出数据变异的方向, 归纳重要信息。
而因子分析是从显在变量去提炼潜在因子的过程。
此外,主成分分析不需要构造分析模型而因子分析要构造因 子模型。
7.2 因子分析主要可应用于哪些方面?答:因子分析是一种通过显在变量测评潜在变量,通过具体指标测评抽象因子的统计分析方法。
目前因子分析在心理学、社会学、经济学等学科中都有重要的应用。
具体来说,①因子 分析可以用于分类。
如用考试分数将学生的学习状况予以分类;用空气中各种成分的比例对 空气的优劣予以分类等等②因子分析可以用于探索潜在因素。
即是探索未能观察的或不能观测的的潜在因素是什么,起的作用如何等。
对我们进一步研究与探讨指示方向。
在社会调查分析中十分常用。
③因子分析的另一个作用是用于时空分解。
如研究几个不同地点的不同日期的气象状况,就用因子分析将时间因素引起的变化和空间因素引起的变化分离开来从而判 断各自的影响和变化规律。
7.3简述因子模型、一 m 卜中载荷矩阵A 的统计意义。
答:对于因子模型X i =a i 1F 1 - mF ?a j F j I" a m F m•;ii =1,2,Hl , pX i 与F j 的协方差为:mCov(X i , F j ) =Cov(' a ik F k °F j )k=im= Cov(' a ik F k ,F j ) Cov(「F j )k d= a ij若对X i 作标准化处理,=a j ,因此a ij 一方面表示X i 对F j 的依赖程度;另一方面也反映了 变量X i 对公共因子F j的相对重要性。
《统计分析与SPSS的应用(第五版)》(薛薇)课后练习答案第11章SPSS的因子分析1、简述因子分析的主要步骤是什么因子分析的主要步骤:一、前提条件:要求原有变量之间存在较强的相关关系。
二、因子提取。
三、使因子具有命名解释性:使提取出的因子实际含义清晰。
四、计算样本的因子得分。
2、对“基本建设投资分析.sav ”数据进行因子分析。
要求:1)利用主成分方法,以特征根大于1为原则提取因子变量,并从变量共同度角度评价因子分析的效果。
如果因子分析效果不理想,再重新指定因子个数并进行分析,对两次分析结果进行对比。
2)对比未旋转的因子载荷矩阵和利用方差极大法进行旋转的因子载荷矩阵,直观理解因子旋转对因子命名可解释性的作用。
“基本建设投资分析”因子分析步骤:分析降维因子分析导入全部变量到变量框中详细设置描述、抽取的设置如下: -相黄性舸阵[3□逆模型迥)显1F 性水平逞)□再生迟) □柠別式也)上厦映象追)V 邕M 。
和Bartiettm 形度橙验旋转、得分、选项的设置如下:./丘示圜子卷敘粗胖I 』[ai~J匚淙存n 欝童海© BarJet瞅■!圖丽药亟T 矗匸Q 脚dii*A3R 迟》0晰平即口甘描因亶除■£洞&式E 卜曲/ 牺削'■:诩|型J®J(3S1T ;■■ ■昌同子分疔信辻统计Statistics(1)表一是原有变量的相关系数矩阵。
由表可知,一些变量的相关系数都较高,呈较强的线由表二可知,巴特利特球度检验统计量的观测值为,相应的概率 性水平为,由于概率P-值小于显著性水平a,则应拒绝原假设,认为相关系数矩阵与单位P-值接近0.如果显著阵有显著差异,原有变量适合做因子分析。
同时, 量可以进行因子分析。
KMO 直为,根据KMC 度量标准可知原有变由表三可知,利用外资、自筹资金、其他投资等变量的绝大部分信息(大于 因子解释,这些变量的信息丢失较少。
但国家预算内资金这个变量的信息丢失较为严重(近80%。