主成分分析和因子分析 stata统计分析与应用
- 格式:ppt
- 大小:604.00 KB
- 文档页数:21

因子分析︱使用Stata做主成份分析因子分析是一种常用的多变量数据分析方法,可以用于降维、变量筛选和构建综合指标等方面。
在实际应用中,Stata是一款功能强大的统计软件,可以方便地进行因子分析。
本文将介绍如何使用Stata进行主成份分析。
首先,我们需要准备好需要进行因子分析的数据。
假设我们有一份包含10个变量的数据集,每一个变量都代表了某种特征或者指标。
我们希翼通过因子分析来找出这些变量的共同因素,并将其转化为更少的几个主成份。
在Stata中,我们可以使用“factor”命令来进行主成份分析。
首先,我们需要加载数据集。
假设我们的数据集名为“data”,我们可以使用以下命令加载数据:```use data```接下来,我们可以使用“factor”命令进行主成份分析。
以下是一个示例命令:```factor var1-var10, pcf```在上述命令中,“var1-var10”表示我们要进行因子分析的变量范围,而“pcf”表示使用主成份法进行因子分析。
执行该命令后,Stata会输出一份关于因子分析结果的报告。
报告中的一项重要指标是共同度(communality),它表示每一个变量与所有因子的相关程度。
共同度越高,说明变量与因子之间的关联越强。
我们可以根据共同度来判断每一个变量对应的主成份是否合适。
此外,报告还会给出每一个主成份的解释方差比例(proportion of variance explained)。
解释方差比例表示每一个主成份能够解释原始数据中的多少方差。
通常,我们希翼选择解释方差比例较高的主成份,以便更好地代表原始数据。
在进行因子分析后,我们还可以使用“rotate”命令对主成份进行旋转,以便更好地解释数据。
Stata提供了多种旋转方法,如方差最大旋转(varimax rotation)和直角旋转(orthogonal rotation)等。
我们可以根据需要选择合适的旋转方法。
除了使用命令行进行因子分析,Stata还提供了可视化工具来匡助我们更好地理解和解释数据。

因子分析在STATA中实现和案例因子分析是一种统计方法,用来研究一组变量之间的相关性,以及这些变量是否可以被归纳为更少的无关变量,即因子。
在STATA软件中,我们可以使用factor命令进行因子分析。
在本文中,我们将介绍STATA中因子分析的实现步骤,并给出一个案例来说明。
实现步骤:1. 数据准备:将需要进行因子分析的变量导入STATA软件,并确保变量为连续型变量。
如果变量中存在缺失值,可以使用命令“dropmiss”删除缺失值。
2. 因子分析模型的选择:在因子分析中,我们需要选择合适的因子数和因子分析模型。
常见的因子数选择方法有Kaiser准则、斯科马洛维准则和Cattell准则等。
常见的因子分析模型有主成分分析和最大似然估计法。
在STATA中,我们可以使用命令“factor”来估计主成分分析模型或最大似然估计法模型。
3. 进行因子分析:在STATA中,我们可以使用命令“factor”进行因子分析。
命令的一般语法如下:factor 变量列表,选项常用的选项有:-pca:使用主成分分析模型-ml:使用最大似然估计法模型-factors(n):指定因子的个数为n-rotation(r):选择因子旋转方法,常见的有方差最大旋转法(varimax)和极大似然估计法(method=ml)等4.结果解读:进行因子分析后,STATA会生成一份结果报告,其中包括每个因子的因子载荷、特征值、解释方差比等指标。
因子载荷可以用来解释原始变量与因子之间的关系,特征值可以用来衡量因子的重要性,解释方差比可以用来衡量因子分析模型的拟合度。
案例:假设我们现在有一组数据,包括10个变量:x1、x2、x3、x4、x5、x6、x7、x8、x9和x10。
我们希望对这组变量进行因子分析,以便找出潜在的结构。
步骤如下:1.数据准备:将数据导入到STATA软件中,并确保变量为连续型变量。
2. 因子分析模型的选择:我们首先通过计算相关性矩阵来选择合适的因子数。

主成分分析与因子分析(四):因子分析概述前面的文章我们介绍了使用SAS实现主成分分析。
从这篇文章开始介绍因子分析。
前面讨论的主成分分析是对现有的随机变量通过线性变换生成新的随机变量,由于新生成的随机变量是按照对变异贡献的大小排序的,因此仅仅考察前几个主成分就可以实现分析目的,使问题得到了简化。
因子分析的目的也是寻找潜在的少数几个(少于原始随机变量数目)新的变量,以便在实际工作中可以采取更合理的方案或措施,并揭示隐藏在数据中的基本规律。
主成分分析考察和解释的是方差,也就是数据的变异程度,而因子分析却是从随机变量协方差也就是相关性的角度进行研究的。
公共因子与特殊因子因子就是前面所说的试图寻找到的潜在的、个数较少、反映原始随机变量相关性的新随机变量。
前面介绍的主成分可以由原始变量线性表示,是可以观测的。
与主成分不同,因子往往不能像主成分一样,由原始变量线性表示,因此是不可观测的。
在因子分析中,因子可以分为公共因子和特殊因子。
对原始数据若干个指标都起作用的称之为公共因子,仅仅对某个指标起作用的称之为特殊因子。
例如,对若干名高中学生的语文、数学与英语成绩进行分析,通过分析,得知每个科目的成绩和一个变量都相关,我们称这个变量为智力。
这个变量“智力”是虚构出来的、不可观测的,即因子。
该因子反映了三个科目成绩的变异,因此,是一个公共因子。
每个科目的成绩除了和智力相关,可能还和其他因素相关。
我们将其他因素笼统地用另外一个虚拟变量来表示,这个虚拟变量称为特殊因子。
因子分析的计算过程因子分析过程可以分为:因子载荷计算、因子旋转与因子得分三个部分。
因子载荷的计算方法主要有主成分法、主轴因子法、最小二乘法、极大似然法以及因子提取法。
这些方法求解的出发点不同,所得的结果也不尽相同。
在对因子载荷进行计算后,就要结合求解问题的背景去分析公共因子的意义了。
如果公共因子的实际意义不明显,可以尝试着进行因子旋转。
经过旋转,因子的结构会发生变化。

因子分析︱使用Stata做主成分分析文章来自计量经济学圈主成分分析在许多领域的研究与应用中,往往需要对反映事物的多个变量进行大量的观测,收集大量数据以便进行分析寻找规律。
多变量大样本无疑会为研究和应用提供了丰富的信息,但也在一定程度上增加了数据采集的工作量,更重要的是在多数情况下,许多变量之间可能存在相关性,从而增加了问题分析的复杂性,同时对分析带来不便。
如果分别对每个指标进行分析,分析往往是孤立的,而不是综合的。
盲目减少指标会损失很多信息,容易产生错误的结论。
因此需要找到一个合理的方法,在减少需要分析的指标同时,尽量减少原指标包含信息的损失,以达到对所收集数据进行全面分析的目的。
由于各变量间存在一定的相关关系,因此有可能用较少的综合指标分别综合存在于各变量中的各类信息。
主成分分析与因子分析就属于这类降维的方法。
主成分分析是设法将原来众多具有一定相关性(比如P个指标),重新组合成一组新的互相无关的综合指标来代替原来的指标。
主成分分析,是考察多个变量间相关性一种多元统计方法,研究如何通过少数几个主成分来揭示多个变量间的内部结构,即从原始变量中导出少数几个主成分,使它们尽可能多地保留原始变量的信息,且彼此间互不相关.通常数学上的处理就是将原来P个指标作线性组合,作为新的综合指标。
最经典的做法就是用F1(选取的第一个线性组合,即第一个综合指标)的方差来表达,即Var(F1)越大,表示F1包含的信息越多。
因此在所有的线性组合中选取的F1应该是方差最大的,故称F1为第一主成分。
如果第一主成分不足以代表原来P个指标的信息,再考虑选取F2即选第二个线性组合,为了有效地反映原来信息,F1已有的信息就不需要再出现在F2中,用数学语言表达就是要求Cov(F1, F2)=0,则称F2为第二主成分,依此类推可以构造出第三、第四,……,第P个主成分。
2. 问题描述下表1是某些学生的语文、数学、物理、化学成绩统计:首先,假设这些科目成绩不相关,也就是说某一科目考多少分与其他科目没有关系。

文章题目:深度探讨Stata中主成分分析和提取公因子的应用和理解1. 引言在社会科学研究中,主成分分析(PCA)和确认性因子分析(CFA)是常用的数据分析方法。
本文将深入探讨Stata中主成分分析和提取公因子的应用和理解,帮助读者更全面地掌握这两种方法的使用。
2. Stata中的主成分分析(PCA)主成分分析即PCA是一种用于降维和发现变量间相关性的方法。
在Stata中,我们可以使用“factor”命令进行主成分分析。
我们需要加载数据集并选择感兴趣的变量,然后使用“factor”命令进行主成分分析。
得到主成分之后,我们可以根据主成分载荷来解释每个主成分所代表的变量间关系。
在解释主成分时,我们需要关注载荷大小和方向,以确定不同变量之间的相关性和主成分的解释性。
3. Stata中的确认性因子分析(CFA)确认性因子分析即CFA是一种用于验证构念和测量模型的方法,常用于问卷调查和心理学领域。
在Stata中,我们可以使用“sem”命令进行CFA。
我们需要构建测量模型,并指定潜在变量和观测变量之间的关系。
我们可以使用“sem”命令进行模型拟合和参数估计。
得到CFA模型之后,我们可以通过拟合指标和因子载荷来评估模型的拟合度和测量指标的效度。
4. 应用实例分析以一个实际的研究案例为例,我们将结合主成分分析和确认性因子分析,探讨如何使用Stata进行数据分析和模型验证。
我们将使用实际数据集,并按照从简到繁的方式,逐步进行主成分分析和CFA。
通过具体的数据分析过程,读者可以更加直观地了解这两种方法的应用和解释。
5. 总结与展望主成分分析和确认性因子分析是重要的数据分析工具,对于研究者来说具有重要的实用价值。
通过本文的讨论,读者可以更深入地理解Stata中主成分分析和提取公因子的方法和意义。
未来,我们可以进一步探讨如何结合主成分分析和CFA,做出更加全面和深入的数据分析和模型验证。
6. 个人观点和理解个人认为,主成分分析和确认性因子分析是研究中不可或缺的方法,能够帮助我们更好地理解变量之间的关系和构念的测量。

数据分析中的因子分析和主成分分析在数据分析领域,因子分析和主成分分析是两种常用的多变量分析方法。
它们可以用来处理大量的数据,找出数据的内在规律,并将数据简化为更少的变量。
本文将介绍因子分析和主成分分析的定义、应用以及它们在数据分析中的区别和联系。
一、因子分析因子分析是一种用于研究多个变量之间的潜在因素结构及其影响的统计方法。
它通过将多个观测变量转化为少数几个无关的因子,来解释变量之间的相关性。
因子分析的基本思想是将多个相关观测变量归因于少数几个潜在因子,这些潜在因子不能被观测到,但可以通过观测变量的变化来间接地推断出来。
因子分析通常包括两个主要步骤:提取因子和旋转因子。
提取因子是指确定能够解释原始变量方差的主要共性因子,常用的方法有主成分分析法和最大似然估计法。
旋转因子是为了减少因子之间的相关性,使得因子更易于解释。
常用的旋转方法有正交旋转和斜交旋转。
因子分析的应用非常广泛,可以用于市场研究、社会科学调查、心理学、金融等领域。
例如,在市场研究中,因子分析可以用来确定消费者购买行为背后的潜在因素,从而更好地理解市场需求。
二、主成分分析主成分分析是一种通过线性变换将原始变量转化为一组线性无关的主成分的统计方法。
主成分是原始变量的线性组合,具有较大的方差,能够尽可能多地解释原始数据。
主成分分析的主要思想是将原始变量投影到一个新的坐标系中,使得新坐标系上的第一主成分具有最大方差,第二主成分具有次最大方差,以此类推。
通过选择解释原始数据方差较多的前几个主成分,我们可以实现数据的降维和主要信息提取。
主成分分析在数据降维、特征提取和数据可视化等领域有广泛的应用。
例如,在图像处理中,主成分分析可以用来压缩图像数据、提取重要特征,并且可以在保留图像主要信息的同时减少存储空间的需求。
三、因子分析和主成分分析的区别和联系因子分析和主成分分析在某些方面有相似之处,但也存在明显的区别。
首先,因子分析是用于研究多个观测变量之间的潜在因素结构,而主成分分析是通过线性变换将原始变量转化为一组线性无关的主成分。

stata学习笔记(四):主成份分析与因⼦分析1.判断是否适合做主成份分析,变量标准化Kaiser-Meyer-Olkin抽样充分性测度也是⽤于测量变量之间相关关系的强弱的重要指标,是通过⽐较两个变量的相关系数与偏相关系数得到的。
KMO介于0于1之间。
KMO越⾼,表明变量的共性越强。
如果偏相关系数相对于相关系数⽐较⾼,则KMO⽐较低,主成分分析不能起到很好的数据约化效果。
根据Kaiser(1974),⼀般的判断标准如下:0.00-0.49,不能接受(unacceptable);0.50-0.59,⾮常差(miserable);0.60-0.69,勉强接受(mediocre);0.70-0.79,可以接受(middling);0.80-0.89,⽐较好(meritorious);0.90-1.00,⾮常好(marvelous)。
SMC即⼀个变量与其他所有变量的复相关系数的平⽅,也就是复回归⽅程的可决系数。
SMC⽐较⾼表明变量的线性关系越强,共性越强,主成分分析就越合适。
. estat smc. estat kmo. estat anti//暂时不知道这个有什么⽤得到结果,说明变量之间有较强的相关性,适合做主成份分析。
Squared multiple correlations of variables with all other variables-----------------------Variable | smc-------------+---------x1 | 0.8923x2 | 0.9862y1 | 0.9657y2 | 0.9897y3 | 0.9910y4 | 0.9898y5 | 0.9769y6 | 0.9859y7 | 0.9735-----------------------变量标准化. egen z1=std(x1)2.对变量进⾏主成份分析. pca x1 x2 y1 y2 y3 y4 y5 y6 y7. pca x1 x2 y1 y2 y3 y4 y5 y6 y7, comp(1)得到下⾯两个表格,第⼀个表格中的各项分别为特征根、difference这个不知道是啥、⽅差贡献率、累积⽅差贡献率。
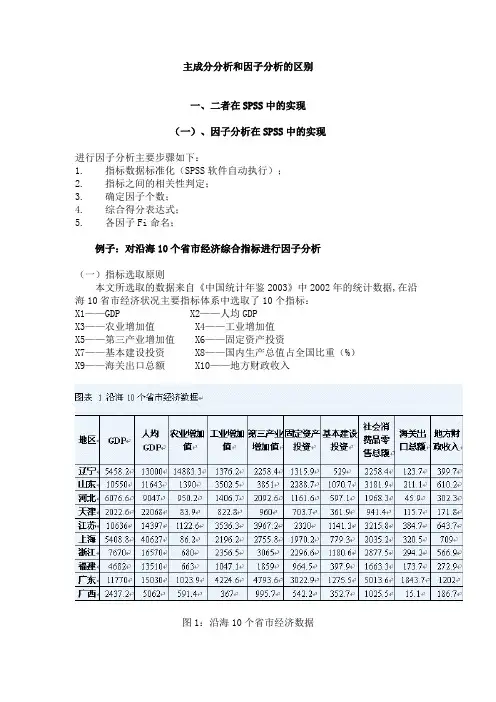
主成分分析和因子分析的区别一、二者在SPSS中的实现(一)、因子分析在SPSS中的实现进行因子分析主要步骤如下:1. 指标数据标准化(SPSS软件自动执行);2. 指标之间的相关性判定;3. 确定因子个数;4. 综合得分表达式;5. 各因子Fi命名;例子:对沿海10个省市经济综合指标进行因子分析(一)指标选取原则本文所选取的数据来自《中国统计年鉴2003》中2002年的统计数据,在沿海10省市经济状况主要指标体系中选取了10个指标:X1——GDP X2——人均GDPX3——农业增加值X4——工业增加值X5——第三产业增加值X6——固定资产投资X7——基本建设投资X8——国内生产总值占全国比重(%)X9——海关出口总额X10——地方财政收入图1:沿海10个省市经济数据(二)因子分析在SPSS中的具体操作步骤运用SPSS统计分析软件Factor过程[2]对沿海10个省市经济综合指标进行因子分析。
具体操作步骤如下:1. Analyzeà Data Reductionà Factor Analysis,弹出Factor Analysis对话框2. 把X1~X10选入Variables框3. Descriptives: Correlation Matrix框组中选中Coefficients等选项,然后点击Continue,返回Factor Analysis对话框4. 点击“OK”图2:Factor Analyze对话框与Descriptives子对话框SPSS在调用Factor Analyze过程进行分析时,SPSS会自动对原始数据进行标准化处理,所以在得到计算结果后指的变量都是指经过标准化处理后的变量,但SPSS不会直接给出标准化后的数据,如需要得到标准化数据,则需调用Descriptives过程进行计算。
我们可以通过Analyze-Descriptive Statistics- Descriptives对话框来实现:弹出Descriptives对话框后,把X1~X10选入Variables框,在Save standardized values as variables前的方框打上钩,点击“OK”,经标准化的数据会自动填入数据窗口中,并以Z开头命名。

主成分分析法stata主成分分析(PrincipalComponentAnalysis,PCA)是一种常见的多元统计分析方法,它有助于从原始数据中提取和表征重要的信息。
它的目的是确定数据集中的重要趋势,并且能够减少数据的维度。
最近,使用PCA统计分析中变得越来越流行,其中,Stata是一种强大的统计分析软件,能够帮助用户有效地应用PCA。
本文对Stata中主成分分析法的实施进行了介绍。
1. Stata 中的主成分分析Stata 中的主成分分析是一种用于降低数据维度的有用工具。
它可以识别和描述原始变量之间的关联结构。
用Stata实施主成分分析,可以有效地削减数据维度,从而帮助用户更好地了解他们的数据。
要实施PCA,用户可以通过两种方式调用Stata:factormatrix令和pca令。
factormatrix令常用于降维,而pca令用于获取完整的主成分分析输出,包括主成分贡献率、方差贡献率、贡献率比和特征向量。
2.用案例举例来说,假设我们想要研究一个市场调研项目,其中包含10 个变量,比如性别、年龄、收入等。
我们可以使用Stata中的PCA来将这10 个变量降维到3 个主成分,从而更容易了解这10 个变量之间的关系。
首先,我们需要用Stata调用pca令,输入要研究的变量。
然后,Stata将生成主成分分析的输出,包括主成分贡献率,方差贡献率和特征向量等。
根据PCA的输出,我们可以了解变量之间的关系,帮助我们进一步研究。
3.结本文介绍了Stata中主成分分析法的使用方法。
主成分分析是一种强大的统计分析方法,可以有效地提取和表征原始数据中的重要信息。
Stata软件可以有效地应用PCA,帮助用户削减数据的维度,使其容易掌握数据的重要趋势。
STATA中主成分分析与使用主成分法的因子分析的区别问题描述:在使用因子分析factor命令中,抽取共因子的方法包括主成分法、主因子法、迭代因子以及最大似然法。
后三种不难理解。
但是在stata做主成分分析有一个直接命令pca,那么pca主成分分析与factor中使用主成分法是否是一致的。
这个问题在spss中更为明显和严重。
下面就用实例来说明这个问题。
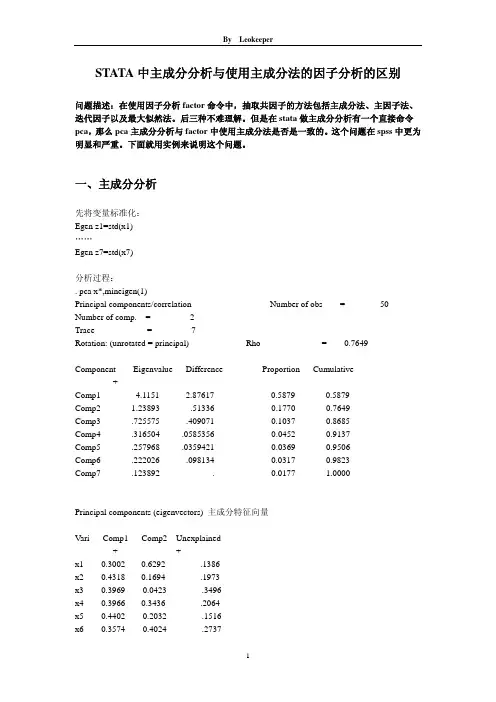
一、主成分分析先将变量标准化:Egen z1=std(x1)……Egen z7=std(x7)分析过程:. pca x*,mineigen(1)Principal components/correlation Number of obs = 50 Number of comp. = 2Trace = 7Rotation: (unrotated = principal) Rho = 0.7649--------------------------------------------------------------------------Component Eigenvalue Difference Proportion Cumulative-------------+------------------------------------------------------------Comp1 4.1151 2.87617 0.5879 0.5879Comp2 1.23893 .51336 0.1770 0.7649Comp3 .725575 .409071 0.1037 0.8685Comp4 .316504 .0585356 0.0452 0.9137Comp5 .257968 .0359421 0.0369 0.9506Comp6 .222026 .098134 0.0317 0.9823Comp7 .123892 . 0.0177 1.0000--------------------------------------------------------------------------Principal components (eigenvectors) 主成分特征向量------------------------------------------------Vari Comp1 Comp2 Unexplained-------------+--------------------+-------------x1 0.3002 -0.6292 .1386x2 0.4318 -0.1694 .1973x3 0.3969 0.0423 .3496x4 0.3966 -0.3436 .2064x5 0.4402 0.2032 .1516x6 0.3574 0.4024 .2737x7 0.2952 0.5023 .3288------------------------------------------------. loadingplot. estat loading,cnorm(eigen)Principal component loadings (unrotated) 主成分负荷component normalization: sum of squares(column) = eigenvalue----------------------------------Comp1 Comp2-------------+--------------------x1 .6091 -.7003x2 .8758 -.1886x3 .8051 .04705x4 .8046 -.3825x5 .8929 .2262x6 .725 .4479x7 .5988 .5591----------------------------------注:主成分向量=负荷/特征值的开方. estat kmo KMO检验Kaiser-Meyer-Olkin measure of sampling adequacy-----------------------Variable kmo-------------+---------x1 0.6759x2 0.8398x3 0.8517x4 0.8675x5 0.7961x6 0.6731x7 0.7318-------------+---------Overall 0.7836-----------------------. estat smcSquared multiple correlations of variables with all other variables-----------------------Variable smc-------------+---------x1 0.6093x2 0.7300x3 0.5951x4 0.6453x5 0.7948x6 0.7275x7 0.4858-----------------------. estat antiAnti-image correlation coefficients --- partialing out all other variables------------------------------------------------------------------------------------Va x1 x2 x3 x4 x5 x6 x7-------------+----------------------------------------------------------------------x1 1.0000x2 -0.3698 1.0000x3 -0.2740 -0.0700 1.0000x4 -0.2669 -0.3694 -0.0779 1.0000x5 -0.1825 -0.0386 -0.1297 -0.2412 1.0000x6 0.4149 -0.3903 -0.0029 0.1277 -0.6471 1.0000x7 0.2781 -0.0107 -0.4681 0.0538 -0.2887 0.0757 1.0000------------------------------------------------------------------------------------注:KMO、SMC和ANTI结合判断是否适合做主成分分析。

[stata代码模板]主成分分析及因子分析1. 主成分分析黄色字体为自己填写部分,红色字体为可缺省部分。
————————————模板————————————factor 变量名,pc factor(#) covariance means mineigen(#)————————————模板————————————pc代表是主成分分析,如果没有pc,则为因子分析。
factor(#)指定保留因子的个数,可缺省。
covariance指定主成分是从协方差阵计算,而不是从相关阵,也就是说,不加covariance意味着变量被标准化了,可缺省。
means给出各变量的均数、标准差、最小值、最大值,可缺省。
mineigen(#)指定保留的最小特征根。
2. 因子分析主成分分析是将原指标的综合,因子分析是将原指标分解。
(1)因子载荷估计黄色字体为自己填写部分,红色字体为可缺省部分。
————————————模板————————————factor 变量名, factor(#) covariance means 因子提取的方法————————————模板————————————factor(#)、covariance、means与前面意义一样。
因子提取的方法有:Pf 主因子法(缺省时默认)pcf 主成分因子法ipf 迭代因子法ml 极大似然法mineigen(#)指定保留的最小特征根,用主成分提取因子时,缺失值为1,其他情况缺失值为0。
(2)因子旋转当因子估计的模型中的公共因子含义不清或没有合理解释时,可对因子载荷阵进行旋转,使因子载荷的结构简化,以便于对公共因子进行解释。
其原理很像调节显微镜的焦点,以便看清楚观察物的细微之处。
————————————模板————————————rotate,因子旋转的方法————————————模板————————————因子旋转的方法可以缺省,常有以下三种:正交方差极大旋转(varimax),默认为此斜交旋转(promax(#),括号内数为参加旋转的因子数),一般取2或3个因子参加旋转,stata中promax(3)为缺省值。
主成分分析与因子分析的比较与应用引言:主成分分析(Principal Component Analysis,简称PCA)和因子分析(Factor Analysis)是常用的数据降维技术,可以用于分析数据之间的关系、提取重要特征等。
本文将对主成分分析和因子分析进行详细比较,并探讨它们的应用。
一、主成分分析主成分分析是一种无监督学习方法,用于将高维数据降低到低维空间。
其主要目标是找到一组最能代表原始数据信息的变量,称为主成分。
主成分具有以下特点:1. 无相关性:主成分之间相互独立,不存在相关性;2. 有序性:主成分按重要性排序,越靠前的主成分解释数据方差越多;3. 降维效果:通过选择前几个主成分,可以实现数据降维的效果。
主成分分析的步骤如下:1. 数据标准化:对原始数据进行标准化处理,确保各个变量具有相同的量纲;2. 构造协方差矩阵:计算各个变量之间的协方差,得到协方差矩阵;3. 特征值分解:对协方差矩阵进行特征值分解,得到特征值和特征向量;4. 选择主成分:按照特征值从大到小的顺序选择前几个主成分;5. 得分计算:计算原始数据在主成分上的投影得分;6. 降维表示:使用选取的主成分对原始数据进行降维表示。
二、因子分析因子分析也是一种数据降维技术,其目标是通过矩阵变换找到潜在的共同因子,用于解释原始数据的方差-协方差结构。
因子分析的特点包括:1. 因子解释:因子表示原始数据的共同因素,可以提取出潜在的数据模式;2. 因子相关性:因子之间可以存在相关性,反映变量之间的内在关系;3. 因子旋转:通过因子旋转可以使因子具有更好的解释性和可解释性。
因子分析的步骤如下:1. 数据标准化:对原始数据进行标准化处理,确保各个变量具有相同的量纲;2. 提取因子:通过主成分分析或最大似然估计等方法提取因子;3. 因子旋转:对提取的因子进行旋转,使得因子具有更好的解释性;4. 因子得分计算:计算各个样本在因子上的得分;5. 因子载荷计算:计算变量与因子之间的相关性;6. 解释方差:根据因子载荷矩阵解释原始数据的方差。
主成份分析和因子分析实例主成分分析和因子分析是常用的降维技术,用于对数据进行降维和探索性因子分析。
在本文中,我将为您介绍两种方法,并提供一个数据集的实例来说明它们的应用。
一、主成分分析(PCA)主成分分析是一种广泛应用的数据降维技术,它可以将高维数据转换为低维数据,同时尽可能以保留最大方差的方式来解释数据。
主成分分析的目标是找到一个新的低维度空间,使得投影到该空间的数据具有最大的方差。
下面是一个用于说明主成分分析的实例:假设我们有一组包含5个变量的数据,分别是身高、体重、BMI指数、血压和血糖。
我们希望使用主成分分析将这些变量降维到2维并通过可视化来分析数据。
首先,我们需要对原始数据进行标准化,以消除变量之间的单位差异。
然后,我们计算协方差矩阵,并通过对协方差矩阵进行特征值分解来找到数据的主成分。
在这个例子中,我们得到了两个主成分,分别称为PC1和PC2、PC1是与身高、体重和BMI指数等相关的主成分,而PC2是与血压和血糖相关的主成分。
这两个主成分解释了数据总方差的大部分。
接下来,我们可以使用这两个主成分来可视化数据,并分析数据的聚集和分布情况。
例如,我们可以使用散点图可视化数据的主成分得分,并根据不同类别对数据进行颜色编码,以便观察数据的聚集情况。
通过主成分分析,我们可以将原始高维数据转换为低维数据,并通过可视化来分析数据的分布和聚集情况,进而进行更深入的研究和分析。
二、因子分析(FA)因子分析是一种用于探索性数据分析的统计技术,其目的是揭示变量之间的潜在因子结构。
因子分析假设观测数据由一组潜在因子引起,并尝试将这些因子解释为一组不可观测的变量。
下面是一个用于说明因子分析的实例:假设我们有一组包含10个观测变量的数据,我们希望了解这些变量之间的潜在因子结构。
我们可以使用因子分析来识别可能存在的潜在因子,并了解它们对观测变量的影响。
在进行因子分析之前,我们首先需要检验数据的合适性。
我们可以使用Kaiser-Meyer-Olkin (KMO)测度和巴特利特球形检验来评估数据的适合度。
数据分析中的主成分分析和因子分析比较在数据分析领域,主成分分析(Principal Component Analysis,PCA)和因子分析(Factor Analysis)是常用的降维技术。
它们可以帮助我们理解和处理高维数据,找到其中的主要特征与隐藏结构。
本文将对主成分分析和因子分析进行比较,并探讨它们的应用场景和优缺点。
一、主成分分析(PCA)主成分分析是一种广泛应用于数据降维的统计方法。
其主要目标是将原始变量转换为一组无关的主成分,这些主成分按重要性递减排列。
主成分分析的基本思想是通过线性变换,将原始变量映射到一个新的坐标系中,在新的坐标系下保留下最重要的特征。
主成分分析的步骤如下:1.标准化数据:将原始数据进行标准化处理,确保各变量具有相同的尺度和方差。
2.计算相关系数矩阵:计算标准化后的数据的相关系数矩阵,用于度量变量之间的线性关系。
3.计算特征值和特征向量:通过对相关系数矩阵进行特征值分解,得到特征值和对应的特征向量。
4.选择主成分:按照特征值降序排列,选择前k个特征值对应的特征向量作为主成分。
5.映射数据:将原始数据映射到主成分空间,得到降维后的数据。
主成分分析的优点包括:1.降维效果好:主成分分析能够有效地降低数据维度,减少冗余信息,保留主要特征。
2.无信息损失:主成分之间相互无关,不同主成分之间不会出现信息重叠。
3.易于解释:主成分分析的结果可以通过特征向量进行解释,帮助我们理解数据背后的规律和因果关系。
二、因子分析(Factor Analysis)因子分析是一种用于解释变量之间相关性的统计方法。
它假设多个观察变量共同受到一个或多个潜在因子的影响。
通过因子分析,我们可以发现隐藏在多个观察变量背后的共同因素,并将原始数据转换为更少数量的因子。
因子分析的基本思想是通过寻找协方差矩阵的特征值和特征向量,找到一组潜在因子,使得在这组因子下观察变量之间的协方差最小。
因子分析的步骤如下:1.设定因子个数:根据实际情况和需要,设定潜在因子的个数。
主成分分析、因子分析、聚类分析的比较与应用一、本文概述在数据分析与统计学的广阔领域中,主成分分析(PCA)、因子分析(FA)和聚类分析(CA)是三种重要的数据分析工具。
它们各自具有独特的功能和应用领域,对数据的理解和解释提供了不同的视角。
本文将对这三种分析方法进行详细的比较,并探讨它们在各种实际场景中的应用。
我们将对每种分析方法进行简要的介绍,包括其基本原理、数学模型以及主要的应用场景。
然后,我们将详细比较这三种分析方法在数据降维、变量解释以及数据分类等方面的优势和劣势。
主成分分析(PCA)是一种常见的数据降维技术,通过找出数据中的主要变量(即主成分),可以在保留数据大部分信息的同时降低数据的维度。
因子分析(FA)则是一种通过寻找潜在因子来解释数据变量之间关系的方法,它在心理学、社会学等领域有着广泛的应用。
聚类分析(CA)则是一种无监督学习方法,通过将数据点划分为不同的类别,揭示数据的内在结构和分布。
接下来,我们将通过几个具体的案例,展示这三种分析方法在实际问题中的应用。
这些案例将涵盖不同的领域,如社会科学、生物医学、商业分析等,以展示这些方法的多样性和实用性。
我们将对全文进行总结,并提出未来研究方向。
通过本文的比较和应用研究,我们希望能为读者提供一个全面、深入的理解这三种重要数据分析方法的视角,同时也为实际问题的解决提供一些有益的启示。
二、主成分分析(PCA)主成分分析(Principal Component Analysis,简称PCA)是一种常用的数据分析方法,它旨在通过正交变换将原始数据转换为一组线性不相关的变量,即主成分。
这些主成分按照方差大小进行排序,第一个主成分具有最大的方差,后续主成分方差依次递减。
通过这种方式,PCA可以在保持数据主要特征的同时降低数据的维度,简化数据结构,便于进一步的分析和可视化。
PCA的核心思想是数据降维,它通过计算协方差矩阵的特征值和特征向量来实现。
特征值代表了各个主成分的方差大小,而特征向量则构成了转换矩阵,用于将原始数据转换为主成分。
因子分析在STATA中实现和案例因子分析是一种利用统计方法对多个变量进行综合分析的方法,通过对变量之间的相关性进行分析,将多个相关变量归纳为较少的无关因子,从而简化数据分析和数据解读的过程。
STATA是一款常用的统计分析软件,对因子分析提供了较为全面的支持和功能。
本文将介绍如何在STATA中实现因子分析,并通过一个实例来解释因子分析的应用。
首先,我们需要明确本次因子分析的研究目的。
假设我们的研究目的是分析一些国家的经济发展水平,使用了10个指标作为判断经济发展水平的变量,这些指标包括国内生产总值(GDP)、人均收入、就业率、失业率、消费水平、投资水平、贸易额、通货膨胀率、教育水平和医疗水平。
现在我们希望将这些指标归纳为几个综合的指标,即因子。
那么,我们首先需要进行因子分析的准备工作。
我们可以使用STATA中的`factor`命令来实现因子分析。
首先,我们需要先加载数据集。
假设我们的数据集名为"EconData",则可以使用如下命令加载数据:```use EconData```接下来,我们可以使用`factor`命令进行因子分析。
在进行因子分析之前,我们需要先进行一些参数设置。
常用的参数设置包括因子数目和因子旋转方式。
我们可以使用如下命令来设置参数:```factor varlist, factors(num_factors) rotation(method)```其中,`varlist`是要进行因子分析的变量列表,`num_factors`是要分析的因子数目,`method`是因子旋转的方法。
在本例中,我们假设选择提取3个因子,并使用最大方差法进行因子旋转。
则我们可以使用如下命令进行因子分析:``````执行以上命令后,STATA会对所选变量进行因子分析,并给出因子载荷矩阵、特殊因子方差、因子复合得分等结果。
接下来,我们来解释一下上述结果。
因子载荷矩阵显示了每个变量和每个因子之间的关系,也称为因子负荷。
因子分析︱使用Stata做主成分分析主成分分析(Principal Component Analysis,PCA)是一种常用的多变量数据降维方法,通过将原始变量转化为一组线性无关的主成分,实现数据的简化和解释。
本文将介绍如何使用Stata软件进行主成分分析。
首先,我们需要准备一组多变量数据,以便进行主成分分析。
假设我们有一个包含5个变量的数据集,变量分别为A、B、C、D和E。
我们将使用这些变量来进行主成分分析。
第一步,打开Stata软件并导入数据集。
可以使用命令`use`或`import`来导入数据集。
假设我们的数据集文件名为"dataset.dta",则可以使用以下命令导入数据集:```use "dataset.dta"```第二步,进行主成分分析。
在Stata中,可以使用命令`pca`来进行主成分分析。
该命令的基本语法如下:```pca varlist [if] [in] [, options]```其中,`varlist`是要进行主成分分析的变量列表,`if`和`in`是可选的条件语句,`options`是可选的参数。
假设我们要对变量A、B、C、D和E进行主成分分析,可以使用以下命令:```pca A B C D E```第三步,查看主成分分析结果。
主成分分析后,Stata会生成一些与主成分相关的结果。
可以使用命令`pca list`来查看主成分分析的结果。
该命令会显示每个主成分的方差解释比例、特征值、载荷和贡献度等信息。
除了`pca list`命令外,还可以使用其他命令来进一步分析和解释主成分分析的结果。
例如,使用`pca components`命令可以查看每个主成分的系数,使用`pca scores`命令可以计算每个样本在主成分上的得分。
第四步,解释主成分分析结果。
主成分分析的一个重要任务是解释主成分的含义和贡献。
可以使用命令`pca loadings`来查看每个变量在每个主成分上的载荷。