数据结构有向无环图及其应用
- 格式:ppt
- 大小:1.12 MB
- 文档页数:35




有向无环图有向无环图(DAG)是一种重要的图形数据结构,在计算机科学、网络和算法分析等领域中都有广泛的应用。
它与普通无向图有所不同,因为它会在连接时增加一个方向,这就意味着它可以表示有序的数据。
有向无环图被广泛应用于计算机科学领域,比如拓扑排序、分布式处理、编译器设计等等。
概念有向无环图是由一些顶点和一些有序的边组成,它将数据结构中的每个顶点连接起来。
每条边都有一个方向,这就决定了图中的有序性,也决定了如何遍历图中的每个顶点。
它只有在没有重复出现的边时,才能保证从一个顶点开始,能够遍历到整个图中的每个顶点。
另外一个特点是,它不能有环,也就是说,从一个顶点出发,不能回到该顶点本身。
拓扑排序有向无环图是一种很强大的数据结构,它可以用来实现拓扑排序(Topological Sorting)。
拓扑排序是一种重要的技术,可以根据有向边的方向,对顶点进行排序,以便给定时序性任务分配排序方式。
比如,在建筑工程中,需要用到拓扑排序,比如地基建完再搭框架,搭框架后再安装门窗等等。
拓扑排序能保证输出的顺序和输入的顺序一致,也可以用于求解最短路径问题,比如求解从一个城市到另外一个城市的最短路径。
分布式处理有向无环图也可以用来实现分布式处理(Distributed Processing),它可以把任务分解成一些独立的子任务,然后把它们连接起来,形成有向无环图,这样每一个子任务可以在不同的处理器上完成。
分布式处理可以使用有向无环图的拓扑排序算法,实现对任务的排序,从而保证任务的正确执行。
同时,由于它不存在环路,因此也可以保证它是安全的,不会出现死锁的情况,这样也就可以保证流程的有序性。
编译器设计有向无环图也可以用于编译器设计(Compiler Design)。
编译器是计算机科学中一种重要的应用,它可以把高级语言翻译成机器语言,从而可以让计算机处理高级语言编写的程序。
有向无环图可以用来构建编译器,因为它可以实现对语句的排序,这样可以保证编译器在编译过程中符合语法规则,并且能够正确翻译,从而使程序能够正确执行。

区块链 交易量与效率成正比,超越区块链的分布式账本:有向无环图(DAG)技术一、起源DAG(Directed Acyclic Graph,有向无环图)是一种数据结构,最早提出在区块链中加入DAG 概念作为算法,是在2013年的bitcointalk论坛,被称作为“Ghost协议”,这一提议也是为了解决当时比特币的扩容问题。
后来,在NXT社区,又有人提出了DAG of block,将DAG的拓扑结构用来存储区块,解决效率问题。
那时对于DAG的应用,还停留在类似于侧链的一个认识。
众所周知,扩展性是当前区块链技术急需解决的难点之一。
谈到扩展性,首当其冲的便是区块链的扩容问题,当区块链上的交易频繁时,区块链的性能也呈会线性下滑。
参考以太坊的容量,仅仅一个加密猫游戏就让区块链不堪重负,造成了巨大拥堵。
所以,如何有效地扩容,成为了当下区块链技术的一大重点。
在PoW算法的区块链中尤其如此,由于PoW机制是将交易数据打包成区块,在由算力高的节点进行记账,这种算法相对于PoS速度较慢,交易量上升更加会影响到整体的确认速度,以比特币为例,一开始比特币区块链大小为1M,后来交易量的上升使得社区不得不考虑扩容方案,还因此引发了扩容之争与分叉事件。
PoS在确认速度上大为改善,但仍然难以跟上需求。
同时,PoW和PoS算法都有趋向于中心化的理论风险,当拥有的算力或者代币达到了一定数量时,区块链就会变得中心化。
DAG也是一种分布式账本技术,与区块链不同。
因为区块链是由区块组成的一条单链,而DAG则是由交易组成的网络。
但本质上,两者却有着很大的相似之处。
DAG中的交易,就可以看做是一个个“区块”,只不过这些区块也可以作为节点,形成一个复杂交织的网络拓扑结构。
DAG与PoW、PoS相比,DAG有着更加高的性能,甚至可以说交易越多、节点越多,处理速度越快。
二、工作原理DAG技术如何在作为一个分布式账本进行应用呢?IOTA是应用DAG技术较为知名的一个项区块链 目,它将DAG进行了改进,并提出Tangle(缠结)方案。





2一、 选择题1 1 1 .B 2.A 3.C 4.A 5.D 6.A 7.B 8.A 9.C 10.C1.B 12.C 13.A 14.C 15.B 16.D 17.D 18.D 19.A 20.A5 解释:线索二叉树中某结点是否有左孩子,不能通过左指针域是否为空来判 断,而要判断左标志是否为 1。
二、 填空题1 2 3 .归并排序。
. 能否将关键字均匀影射到哈希空间上.一端 先进后出有无好的解决冲突的方法4 5 6 7 8 9 . 顺序存储或链式存储 (1+n )/2.从任意节点出发都能访问到整个链表.时间 空间.n-1 n(n-1)/2.2n-1.n n三、 判断题 1 2 3 4 5 6 7 8 9 1 1 1 1 1 1 .F.F 非空才成立.F 有向的非强连通图,不成立.T.F 表头没有前驱,表尾没有后序.T.F 先序跟后序不行,中序才行.T.F 不可能0.T1.F2.T3.F4.F5.F四、 应用题1 .逻辑结构是从操作对象抽象出来的数学模型,结构定义中的“关系”描述的 是数据元素之间的逻辑关系;物理结构是数据结构在计算机中的表示(又称 映像),又称存储结构。
物理结构是指数据具体存放在哪个位置,逻辑结构是2 3.由 AOV 网构造拓扑序列的拓扑排序算法主要是循环执行以下两步,直到不存 在入度为 0的顶点为止。
(1) 选择一个入度为 0的顶点并输出之;(2) 从网 中删除此顶点及所有出边。
拓扑序列 1:abcdef 拓扑序列 2:adbcef.二叉树图如下:4 5 .略。
已经不纳入考纲.哈夫曼编码问题编码: 3: 000020: 10 10: 0001 22: 11 18: 001 37: 016.二叉排序树问题比根节点小的往左子树插,大的往右子树插。
图如下:删除50有两种做法:《数据结构》中的解析这里我用第二种做法:五.算法设计题1 & .算法填空(L.elem[i-1]) L.length-1 ++p *p L.length-1;2. 设计算法: 输入 n 个元素的值 创建带头结点的单链线性表 L 。
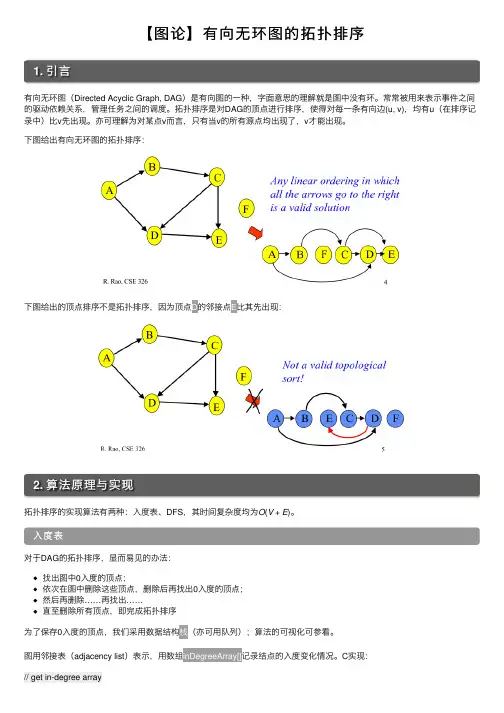
【图论】有向⽆环图的拓扑排序1. 引⾔有向⽆环图(Directed Acyclic Graph, DAG)是有向图的⼀种,字⾯意思的理解就是图中没有环。
常常被⽤来表⽰事件之间的驱动依赖关系,管理任务之间的调度。
拓扑排序是对DAG的顶点进⾏排序,使得对每⼀条有向边(u, v),均有u(在排序记录中)⽐v先出现。
亦可理解为对某点v⽽⾔,只有当v的所有源点均出现了,v才能出现。
下图给出有向⽆环图的拓扑排序:下图给出的顶点排序不是拓扑排序,因为顶点D的邻接点E⽐其先出现:2. 算法原理与实现拓扑排序的实现算法有两种:⼊度表、DFS,其时间复杂度均为O(V+E)。
⼊度表对于DAG的拓扑排序,显⽽易见的办法:找出图中0⼊度的顶点;依次在图中删除这些顶点,删除后再找出0⼊度的顶点;然后再删除……再找出……直⾄删除所有顶点,即完成拓扑排序为了保存0⼊度的顶点,我们采⽤数据结构栈(亦可⽤队列);算法的可视化可参看。
图⽤邻接表(adjacency list)表⽰,⽤数组inDegreeArray[]记录结点的⼊度变化情况。
C实现:// get in-degree arrayint *getInDegree(Graph *g) {int *inDegreeArray = (int *) malloc(g->V * sizeof(int));memset(inDegreeArray, 0, g->V * sizeof(int));int i;AdjListNode *pCrawl;for(i = 0; i < g->V; i++) {pCrawl = g->array[i].head;while(pCrawl) {inDegreeArray[pCrawl->dest]++;pCrawl = pCrawl->next;}}return inDegreeArray;}// topological sort functionvoid topologicalSort(Graph *g) {int *inDegreeArray = getInDegree(g);Stack *zeroInDegree = initStack();int i;for(i = 0; i < g->V; i++) {if(inDegreeArray[i] == 0)push(i, zeroInDegree);}printf("topological sorted order\n");AdjListNode *pCrawl;while(!isEmpty(zeroInDegree)) {i = pop(zeroInDegree);printf("vertex %d\n", i);pCrawl = g->array[i].head;while(pCrawl) {inDegreeArray[pCrawl->dest]--;if(inDegreeArray[pCrawl->dest] == 0)push(pCrawl->dest, zeroInDegree);pCrawl = pCrawl->next;}}}时间复杂度:得到inDegreeArray[]数组的复杂度为O(V+E);顶点进栈出栈,其复杂度为O(V);删除顶点后将邻接点的⼊度减1,其复杂度为O(E);整个算法的复杂度为O(V+E)。
《数据结构》教学大纲第一部分大纲说明一、本课程的性质、目的与任务《数据结构》是信息与计算科学、信息管理与信息系统专业必修的一门主要专业基础课,通过本课程的学习,使学生能够掌握分析、研究计算机加工的数据结构的特性,为应用涉及的数据选择适当的逻辑结构、存储结构和运算算法,初步掌握对算法的评估方法,并培养学生具有较严谨、清晰的程序设计风格,掌握较复杂的程序设计的能力,为学习后续课程和专业技术工作打下基础。
二、与其它课程的联系本课程是计算机软件、应用专业的骨干核心课程。
要求先行课为:高级语言程序设计、离散数学、概率论。
通过学习该课程,为以后学习编译原理、操作系统, 程序设计方法学、面向对象的程序设计、数据库原理等课程打下坚实的基础。
三、课程的特点1.该课程既具有较强的理论性,又具有较强的实践性.2.教学中应注重抽象数据类型和具体的数据类型相结合,注重数据的逻辑结构和存储结构的对照分析,有意识地培养学生编写高质量程序的能力和风格。
3.教学中除采用讲授法外,可结合投影,CAI等助教学手段,同时加强实践性环节的教学。
4.学生学习过程中,同样应该拿抽象数据类型和具体数据类型相结对照,加强实践性环节的训练。
四、教学总体要求该课程包括八个方面的内容:线性表(包括操作受限的线性表、和队列)、串、数组和广义表、树和二叉树、图、动态存储管理、查找和排序、文件。
1.掌握数据结构中三种基本结构(线性表、树和图)的概念、存储结构与分析方法。
2.掌握用类C语言的语法,并掌握用类C语言来描绘数据结构和算法。
3.通过实验课,使学生在数据结构的逻辑特性和存贮表示、基本数据结构的选择和应用、算法设计及其实现等方面加深对课程基本内容的理解。
同时,在课程设计方法及上机操作等基本技能和科学作风方面受到比较系统的、严格的训练,增强动手能力,掌握必要的用类C语言来实现数据结构和算法的能力。
五、本课程的学时分配表(按各章编写)六、教材及教学参考资料《数据结构(C语言版)》,严蔚敏、吴伟民清华大学出版社1997《数据结构实用教程(C/C++描述),徐孝凯清华大学出版社1999《数据结构—用C语言描述》,宁正元中国水利水电出版社2000《实用数据结构》,徐士良清华大学出版社2000《数据结构》,晋良颖人民邮电出版社2002第二部分教学内容和教学要求第一章:概论教学内容:1.什么是数据结构2.基本概念3.抽象数据类型的表示与实现4.算法和算法分析教学要求:使学生了解数据和数据结构等名词和术语的基本概念,理解数据的逻辑结构和存储结构的概念,它们各自对应的性质和两种结构之间的关系;了解算法的五个要素;理解掌握计算语句的频度和时间。
有向无环图的最优路径有向无环图(Directed Acyclic Graph,简称DAG)是一种图的数据结构,它定义了一组有向边,并且不存在任何环路。
在此基础上,我们将讨论有向无环图的最优路径问题。
一、什么是最优路径在有向无环图中,最优路径指的是从图中的某一起点到终点的最短路径或者最长路径,其长度可根据具体情况来决定。
这里我们将重点讨论求解最短路径的问题。
二、最优路径的应用最优路径在许多领域都有广泛的应用。
例如,在交通规划中,我们希望找到最短路径以减少行程时间和交通拥堵。
在电信网络中,最短路径算法使得数据能够高效地传输。
另外,最优路径还可以应用于任务调度、路径规划等领域。
三、有向无环图的最优路径算法有向无环图的最优路径可以通过动态规划算法来求解。
下面介绍两种较为常用的算法:迪杰斯特拉算法和贝尔曼-福特算法。
1. 迪杰斯特拉算法迪杰斯特拉算法是一种典型的单源最短路径算法,适用于有向无环图。
它的基本思想是从起点开始,逐步确定到达各个顶点的最短路径。
算法步骤如下:(1)初始化:将起点的最短路径设置为0,其他顶点的最短路径设置为无穷大。
(2)选择:选择一个未被访问过的顶点,使得当前被访问的顶点到该顶点的路径长度最短。
(3)更新:通过比较当前路径长度和新路径长度的大小,更新到达其他未被访问过的顶点的最短路径。
(4)重复:重复选择和更新步骤,直到所有顶点都被访问过。
2. 贝尔曼-福特算法贝尔曼-福特算法是一种通用的最短路径算法,适用于一般的有向图,包括带有负权边的图。
算法步骤如下:(1)初始化:将起点的距离设置为0,其他顶点的距离设置为无穷大。
(2)迭代:重复对所有边进行松弛操作,即通过比较当前路径和新路径的长度,更新距离数组中的值。
(3)判断负权环:若经过上述迭代,距离数组仍然在更新,则存在负权环,无法求解最短路径。
四、最优路径的应用举例以城市之间的交通规划为例,假设我们已经构建了一个有向无环图,其中城市之间的道路表示为有向边,而道路的长度表示为边的权重。