统计学 第五章 抽样推断课后答案
- 格式:doc
- 大小:346.94 KB
- 文档页数:11

思考与练习(第五章) BY 缪嘉伦 思考题1. 解释原假设与备择假设的含义,并归纳常见的几种建立原假设与备择假设的原则。
答:原假设(null hypothesis )通常是研究者想悼念证据予以反对的假设,也称零假设,用H 0表示。
备择假设(alternative hypothesis)通常是研究者想悼念证据予以支持的假设,也称研究假设,用H l 或 H a 表示。
几种常见的原则:第一, 原假设和备择假设是一个完备事件组,而且相互对立。
第二, 在建立原假设时,通常是先确定备择假设,然后再确定原假设。
第三, 在假设检验中,等号“=”总是放在原假设上。
第四, 在面对某一实际问题时,由于不同的研究者有不同的研究目的,即使对同一问题也可能提出截然相反的原假设和备择假设。
第五, 假设检验的目的主要是收集证据拒绝原假设。
3.什么是显著性水平?它对于假设检验决策的意义是什么?与置信水平的区别?答:显著性水平(level of significance )是指当原假设实际上是正确时,检验统计量落在拒绝域的概率,记为α。
它是人们事先指定的犯第I 类错误概率α的最大允许值。
显著性水平α越小,犯第I 类错误的可能性自然就越小,但犯第∏类错误的可能性随之增大。
置信水平是指变量落在置信区间的可能性,记为1-α。
4.什么是P 值?P 值检验和统计量检验有什么不同?答:P 值(P value )就是当原假设为真时所得到的样本观察结果或更极端结果出现的概率。
如果P 值很小,说明原假设情况的发生的概率很小,而如果出现了,根据小概率原理,我们就有理由拒绝原假设,P 值越小,我们拒绝原假设的理由越充分。
总之,P 值越小,表明结果越显著。
但是检验的结果究竟是“显著的”、“中度显著的”还是“高度显著的”需要我们自己根据P 值的大小和实际问题来解决。
区别:从显著性水平来比较,如果选择的α值相同,所有检验结论的可靠性都一样;通过计算P 值,可测量出样本观测数据与原假设的值0μ的偏离程度。

第五章练习题一、单项选择题1.抽样推断的目的在于()A.对样本进行全面调查B.了解样本的基本情况C.了解总体的基本情况D.推断总体指标2.在重复抽样条件下纯随机抽样的平均误差取决于()A.样本单位数B.总体方差C.抽样比例D.样本单位数和总体方差3.根据重复抽样的资料,一年级优秀生比重为10%,二年级为20%,若抽样人数相等时,优秀生比重的抽样误差()A.一年级较大B.二年级较大C.误差相同D.无法判断4.用重复抽样的抽样平均误差公式计算不重复抽样的抽样平均误差结果将()A.高估误差B.低估误差C.恰好相等D.高估或低估5.在其他条件不变的情况下,如果允许误差缩小为原来的1/2,则样本容量()A.扩大到原来的2倍B.扩大到原来的4倍C.缩小到原来的1/4D.缩小到原来的1/26.当总体单位不很多且差异较小时宜采用()A.整群抽样B.纯随机抽样C.分层抽样D.等距抽样7.在分层抽样中影响抽样平均误差的方差是()A.层间方差B.层内方差C.总方差D.允许误差二、多项选择题1.抽样推断的特点有()A.建立在随机抽样原则基础上 B.深入研究复杂的专门问题C.用样本指标来推断总体指标 D.抽样误差可以事先计算E.抽样误差可以事先控制2.影响抽样误差的因素有()A.样本容量的大小 B.是有限总体还是无限总体C.总体单位的标志变动度 D.抽样方法E.抽样组织方式3.抽样方法根据取样的方式不同分为()A.重复抽样 B.等距抽样 C.整群抽样D.分层抽样 E.不重复抽样4.抽样推断的优良标准是()A.无偏性 B.同质性 C.一致性D.随机性 E.有效性5.影响必要样本容量的主要因素有()A.总体方差的大小 B.抽样方法C.抽样组织方式 D.允许误差范围大小E.要求的概率保证程度6.参数估计的三项基本要素有()A.估计值 B.极限误差C.估计的优良标准 D.概率保证程度E.显著性水平7.分层抽样中分层的原则是()A.尽量缩小层内方差 B.尽量扩大层内方差C.层量扩大层间方差 D.尽量缩小层间方差E.便于样本单位的抽取三、填空题1.抽样推断和全面调查结合运用,既实现了调查资料的_______性,又保证于调查资料的 _______性。
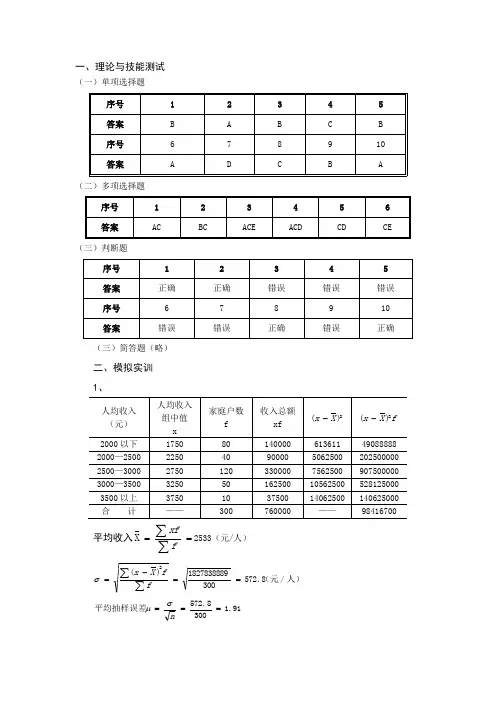
一、理论与技能测试(一)单项选择题(二)多项选择题(三)判断题(三)简答题(略)二、模拟实训 1、平均收入==∑∑fxf X 2533(元/人)人)/(元8.5723001827838889)(2==-=∑∑ffX x σ 91.13008.572平均抽样误差===nσμ极限抽样误差人/元73.591.13=⨯=⨯=∆x x t μ以99.73%的可靠性概率保证程度,估计人均收入在2527.3到2538.7之间。
2、样本比率p=35%,置信度F(t)=95.45% , 概率度t=2所以,以95.45%的可靠性估计%%之间。
3、样本比率p=10%,置信度F(t)=95.45% , 概率度t=2所以,以95.45%的可靠性估计收入在20000元以上的家庭在7%-13%之间。
三、拓展训练 1、第一步:,f (t )=95.45%,通过概率表查到t=2 第二步:通过数据计算样本标准差σ和均值x 第三步:nσμ=第四步:计算μ⨯=∆2x计算均值分布区间X =±x x ∆2、样本比率p=56%,置信度F(t)=95.45% , 概率度t=2所以,以95.45%的可靠性估计该企业产品一等频率在51%-159之间。
%95.36%95.1%35%05.33%95.1%35%95.160065.035.02)1(=+=∆+=-=∆-=⨯⨯=-==∆pp pp p p n p p t t μ%13%3%10%7%3%10%310090.010.02)1(=+=∆+=-=∆-=⨯⨯=-==∆p pp p p p n p p t t μ%59%5%56%51%5%56%510044.056.02)1(=+=∆+=-=∆-=⨯⨯=-==∆p p p p p p n p p tt μ3、样本平均成绩80分,置信度F(t)=95.45% , 概率度t=2分110010平均抽样误差===n σμ极限抽样误差分422=⨯=⨯=∆x x t μ76-844、略。


第五章抽样与抽样估计复习题一、填空题1、在实际工作中,人们通常把n≥30 的样本称为大样本,而把n<30 的样本称为小样本。
2、在抽样估计中,常见的样本统计量有样本均值、样本比例、样本标准差或样本方差以及它们的函数。
3、在研究目的一定的条件下,抽样总体是唯一确定的,而样本则有许多个。
4、在抽样调查中,登记性误差和系统性误差都可以尽量避免,而抽样误差则是不可避免的,但可以计算并加以控制。
5、在抽样估计中,抽样估计量是指用于估计总体参数的样本指标(统计量),评价估计量优劣的标准有无偏性、有效性和一致性。
二、选择题单选题:1、在其它条件不变的情况下,要使抽样平均误差为原来的1/3,则样本单位数必须((2))(1)增加到原来的3倍(2)增加到原来的9倍(3)增加到原来的6倍(4)也是原来的1/32、在总体内部情况复杂,且各单位之间差异程度大,单位数又多的情况下,宜采用((3))(1)简单随机抽样(2)等距抽样(3)分层抽样(4)整群抽样3、某厂产品质量检查,确定按5%的比率抽取,按连续生产时间顺序每20小时抽1小时的全部产进行检验,这种方式是((4))(1)简单随机抽样(2)等距抽样(3)分层抽样(4)整群抽样4、其它条件一定,抽样推断的把握程度提高,抽样推断的准确性就会((2))(1)提高(2)降低(3)不变(4)不一定降低5、在城市电话网的100次通话中,通话持续平均时间为3分钟,均方差为分钟,则概率为时,通话平均持续时间的抽样极限误差为((2))(1)(2)(3)(4)6、假定11亿人口大国和100万人口小国的居民年龄变异程度相同,现在各自用重复抽样方法抽取本国人口的1%计算平均年龄,则平均年龄抽样平均误差((3))(1)两者相等(2)前者比后者大(3)前者比后者小(4)不能确定大小多选题:1、降低抽样误差,可以通过下列那些途径((2)(4)(5))(1)降低总体方差(2)增加样本容量。
(3)减少样本容量(4)改重复抽样为不重复抽样(5)改简单随机抽样为类型抽样2、抽样推断中的抽样误差((1)(5))(1)是不可避免要产生的(2)是可以通过改进调查方法来消除的(3)只有调查后才能计算(4)即不能减少,也不能消除(5)其大小是可以控制的3、抽样极限误差((1)(2)(4))(1)是所有可能的样本指标与总体指标之间的误差范围(2)也叫允许误差 (3)与所做估计的概率保证程度成反比 (4)通常用来表示抽样结果的精确度 4、影响样本容量的因素有((1)(2)(3)(4)(5) ) (1)总体方差(2)所要求的概率保证程度 (3)抽样方法(4)抽样的组织形式(5)允许误差法范围的大小 5、不重复抽样的抽样平均误差( (2)(4) )(1)总是大于重复抽样的抽样平均误差 (2)总是小于重复抽样的抽样平均误差(3)有时大于,有时小于重复抽样的平均误差(4)在Nn很小时,几乎等于重复抽样的抽样平均误差 6、从3000名职工中随机抽取400名调查收入水平,共抽了( (1) (3) (5) ) (1)一个样本 (2)400个样本(3)一个样本总体 (4)400各样本总体 (5)400个样本单位 7、简单随机抽样一般适合于( (1)(3) (5) )(1)具有某种标志的单位均匀分布的总体 (2)具有某种标志的单位存在不同类型的总体 (3)现象的标志变异程度较小的总体 (4)不能形成抽样框的单位 (5)总体单位可以编号的总体三、简答题1、 什么是抽样平均误差影响抽样平均误差的因素有哪些答:抽样平均误差是所有可能的样本指标与被估计的总体参数之间的平均离差,即样本指标的标准差。

《统计学原理》第五章习题河南电大贾天骐一.判断题部分题目1:从全部总体单位中按照随机原则抽取部分单位组成样本,只可能组成一个样本。
()答案:×题目2:在抽样推断中,全及指标值是确定的、唯一的,而样本指标值是一个随机变量。
()答案:√题目3:抽样成数的特点是:样本成数越大,则抽样平均误差越大。
()答案:×题目4:抽样平均误差总是小于抽样极限误差。
()答案:×题目5:在其它条件不变的情况下,提高抽样估计的可靠程度,则降低了抽样估计的精确程度。
()答案:√题目6:从全部总体单位中抽取部分单位构成样本,在样本变量相同的情况下,重复抽样构成的样本个数大于不重复抽样构成的样本个数。
()答案:√题目7:抽样平均误差反映抽样误差的一般水平,每次抽样的误差可能大于抽样平均误差,也可能小于抽样平均误差。
()答案:√题目8:在抽样推断中,抽样误差的概率度越大,则抽样极限误差就越大于抽样平均误差。
()答案:√题目9:抽样估计的优良标准有三个:无偏性、可靠性和一致性。
()答案:×题目10:样本单位数的多少与总体各单位标志值的变异程度成反比,与抽样极限误差范围的大小成正比。
()答案:×题目11:抽样推断的目的是,通过对部分单位的调查,来取得样本的各项指标。
()答案:×题目12:用来测量估计可靠程度的指标是抽样误差的概率度。
()答案:√题目13:总体参数区间估计必须具备三个要素即:估计值、抽样误差范围和抽样误差的概率度。
()答案:×二.单项选择题部分题目1:抽样平均误差是()。
A、抽增指标的标准差B、总体参数的标准差C、样本变量的函数D、总体变量的函数答案:A题目2:抽样调查所必须遵循的基本原则是()。
A、准确性原则B、随机性原则C、可靠性原则 C、灵活性原则答案:B题目3:在简单随机重复抽样条件下,当抽样平均误差缩小为原来的1/2时,则样本单位数为原来的()。

统计学第一章1.什么是统计学?怎样理解统计学与统计数据的关系?答:统计学是一门收集、整理、显示和分析统计数据的科学。
统计学与统计数据存在密切关系,统计学阐述的统计方法来源于对统计数据的研究,目的也在于对统计数据的研究,离开了统计数据,统计方法以致于统计学就失去了其存在意义。
2.简要说明统计数据的来源答:统计数据来源于两个方面:直接的数据:源于直接组织的调查、观察和科学实验,在社会经济管理领域,主要通过统计调查方式来获得,如普查和抽样调查。
间接的数据:从报纸、图书杂志、统计年鉴、网络等渠道获得。
3.简要说明抽样误差和非抽样误差答:统计调查误差可分为非抽样误差和抽样误差。
非抽样误差是由于调查过程中各环节工作失误造成的,从理论上看,这类误差是可以避免的。
抽样误差是利用样本推断总体时所产生的误差,它是不可避免的,但可以控制的。
4.答:(1)有两个总体:A品牌所有产品、B品牌所有产品(2)变量:口味(如可用10分制表示)(3)匹配样本:从两品牌产品中各抽取1000瓶,由1000名消费者分别打分,形成匹配样本。
(4)从匹配样本的观察值中推断两品牌口味的相对好坏。
第二章、统计数据的描述思考题1描述次数分配表的编制过程答:分二个步骤:(1)按照统计研究的目的,将数据按分组标志进行分组。
按品质标志进行分组时,可将其每个具体的表现作为一个组,或者几个表现合并成一个组,这取决于分组的粗细。
按数量标志进行分组,可分为单项式分组与组距式分组单项式分组将每个变量值作为一个组;组距式分组将变量的取值范围(区间)作为一个组。
统计分组应遵循“不重不漏”原则(2)将数据分配到各个组,统计各组的次数,编制次数分配表。
2.解释洛伦兹曲线及其用途答:洛伦兹曲线是20世纪初美国经济学家、统计学家洛伦兹根据意大利经济学家帕累托提出的收入分配公式绘制成的描述收入和财富分配性质的曲线。
洛伦兹曲线可以观察、分析国家和地区收入分配的平均程度。
3. 一组数据的分布特征可以从哪几个方面进行测度?答:数据分布特征一般可从集中趋势、离散程度、偏态和峰度几方面来测度。

第六章抽样推断习题答案一、名词解释用规范性的语言解释统计学中的名词。
1. 随机原则:是指在抽样时排出主观上有意识地抽取调查单位,每个单位以相同概率被取到,从而增强样本对总体的代表性。
2. 统计量:是反映样本特征的综合指标,随样本不同而取不同的值,具有随机性。
3. 随机变量:是指变量的值无法预先确定仅以一定的可能性取值的量。
4. 样本容量:是指样本中的总体单位数量。
5. 中心极限定理:是概率论中讨论随机变量序列部分和的分布渐近于正态分布的一类定理。
这组定理是数理统计学和误差分析的理论基础,指出了大量随机变量近似服从正态分布的条件。
6. 抽样平均误差:是反应抽样误差一般水平的指标,它的实质含义是指抽样平均数的标准差。
7. 区间估计:通过从总体中抽取的样本,根据一定的可行度与精确度的要求,构造出适当的区间,以作为总体的分布参数(或参数的函数)的真值所在范围的估计。
8. 简单随机抽样:也称为单纯随机抽样、纯随机抽样、SPS抽样,是指从总体N个单位中任意抽取n个单位作为样本,使每个可能的样本被抽中的概率相等的一种抽样方式。
二、判断改错对下列命题进行判断,在正确命题的括号内打“√”;在错误命题的括号内打“×”,并在错误的地方下划一横线,将改正后的内容写入题下空白处。
1. 抽样推断中,如果获取的样本数据准确,那么,由此推断的总体参数也一定准确。
(×)不一定2. 极限误差越大,则抽样估计的可靠性就越小。
(×)越大3. 抽样平均误差的大小与样本容量的大小成正比关系。
(×)反比4. 在一般的抽样推断中,抽样平均误差小于极限误差。
(×)不一定5. 重复抽样条件下的抽样平均误差,一定比不重复抽样条件下的抽样平均误差大。
(×)在其他条件相同的情况下6. 在不重复抽样的情况下,若调查的单位数为全及总体的10%,则所计算的抽样平均误差比重复抽样计算的抽样误差少10%。
《统计学》习题五参考答案一、单项选择题:1、抽样误差是指()。
CA在调查过程中由于观察、测量等差错所引起的误差 B人为原因所造成的误差C随机抽样而产生的代表性误差 D在调查中违反随机原则出现的系统误差2、抽样平均误差就是()。
DA样本的标准差 B总体的标准差 C随机误差 D样本指标的标准差3、抽样估计的可靠性和精确度()。
BA是一致的 B是矛盾的 C成正比 D无关系4、在简单随机重复抽样下,欲使抽样平均误差缩小为原来的三分之一,则样本容量应()。
AA增加8倍 B增加9倍 C增加1.25倍 D增加2.25倍5、当有多个参数需要估计时,可以计算出多个样品容量n,为满足共同的要求,必要的样本容量一般应是()。
BA最小的n值 B最大的n值 C中间的n值 D第一个计算出来的n值6、抽样时需要遵循随机原则的原因是()。
CA可以防止一些工作中的失误 B能使样本与总体有相同的分布C能使样本与总体有相似或相同的分布 D可使单位调查费用降低二、多项选择题:1、抽样推断中哪些误差是可以避免的()。
A B DA工作条件造成的误差 B系统性偏差 C抽样随机误差D人为因素形成偏差 E抽样实际误差2、区间估计的要素是()。
A C DA点估计值 B样本的分布 C估计的可靠度D抽样极限误差 E总体的分布形式3、影响必要样本容量的因素主要有()。
A B C EA总体的标志变异程度 B允许误差的大小 C重复抽样和不重复抽样D样本的差异程度 E估计的可靠度三、填空题:1、抽样推断就是根据()的信息去研究总体的特征。
样本2、样本单位选取方法可分为()和()。
重复抽样不重复抽样3、实施概率抽样的前提条件是要具备()。
抽样框4、对总体参数进行区间估计时,既要考虑极限误差的大小,即估计的()问题,又要考虑估计的()问题。
准确性可靠性四、简答题:1、抽样调查与重点调查的主要不同点。
答:第一,选取调查单位的方法不同。
抽样调查是按随机原则抽取调查单位的,重点调查中的重点单位是调查标志值占总体标志总量比重很大的单位,调查单位是明显的;第二,作用不同。
第五章 抽样推断一、单项选择题 1 2 3 4 5 6 7 8 9 10 C B A D B D C B A C 11 12 13 14 15 16 17 18 19 20 ADCADCACBD二、多项选择题1 2 3 4 5 ABCE ABDE BCE ABCE ABDE 6 7 8 9 10 ACE ADE ACD ABE CDE 11 12 13 14 15 BDE CD BC ABCD ABCDE 16 17 18 19 20 AD ACBCEABDEACE三、判断题 1 2 3 4 5 6 7 8 9 10 ×××√√×√√××四、填空题 1、变量 属性 2、正 反3、重复抽样 不重复抽样4、抽样总体 样本5、大于 N n -1 Nn 6、标准差7、样本 总体 抽样平均误差 抽样平均误差 △x = Z x σ 8、合适的样本估计量 一定的概率保证程度 允许的极限误差范围 9、随机抽样 统计分组 10、增大 增大 降低 11、大数定律 中心极限定理 12、样本容量不小(不小于30个单位) 13、大 0.514、缩小33(即0.5774) 扩大 1.1180 15、估计量(或统计量) 参数 五、简答题(略) 六、计算题1、已知条件:P = 0.5 ,n = 100 且重复抽样 求:p ≤0.45的概率 解:Z =1100)5.01(5.05.045.0)1(=-⨯-=--nP P P p则F (Z = 1) = 0.6827 所以p ≤0.45的概率为:26827.01-= 0.15865 2、解E (x 1) = E (0.5X 1 + 0.3X 2 + 0.2X 3) = 0.5 E (X ) + 0.3 E (X ) + 0.2E (X ) = E (X ) = XE (x 2) = E (0.5X 1 + 0.25X 2 + 0.25X 3)= 0.5 E (X ) + 0.25 E (X ) + 0.25E (X )= E (X ) = XE (x 3) = E (0.4X 1 + 0.3X 2 + 0.3X 3) = 0.4 E (X ) + 0.3 E (X ) + 0.3E (X ) = E (X ) = X 所以x 1、x 2、x 3都是X 的无偏估计量。
思考题与练习题参考答案【友情提示】请各位同学完成思考题和练习题后再对照参考答案。
回答正确,值得肯定;回答错误,请找出原因更正,这样使用参考答案,能力会越来越高,智慧会越来越多。
学而不思则罔,如果直接抄答案,对学习无益,危害甚大。
想抄答案者,请三思而后行!第一章绪论思考题参考答案1.不能,英军所有战机=英军被击毁的战机+英军返航的战机+英军没有弹孔的战机,因为英军被击毁的战机有的掉入海里、敌军占领区,或因堕毁而无形等,不能找回;没有弹孔的战机也不可能自己拿来射击后进行弹孔位置的调查。
即便被击毁的战机找回或没有弹孔的战机自己拿来射击进行实验,也不能从多个弹孔中确认那个弹孔是危险的。
2.问题:飞机上什么区域应该加强钢板?瓦尔德解决问题的思想:在他的飞机模型上逐个不重不漏地标示返航军机受敌军创伤的弹孔位置,找出几乎布满弹孔的区域;发现:没有弹孔区域是军机的危险区域。
3.能,拯救和发展自己的参考路径为:①找出自己的优点,②明确自己大学阶段的最佳目标,③拟出一个发扬自己优点,实现自己大学阶段最佳目标的可行计划。
练习题参考答案一、填空题1.调查。
2.探索、调查、发现。
3. 目的。
二、简答题1.瓦尔德;把剩下少数几个没有弹孔的区域加强钢板。
2.统计学解决实际问题的基本思路,即基本步骤是:①提出与统计有关的实际问题;②建立有效的指标体系;③收集数据;④选用或创造有效的统计方法整理、显示所收集数据的特征;⑤根据所收集数据的特征、结合定性、定量的知识作出合理推断;⑥根据合理推断给出更好决策的建议。
不解决问题时,重复第②-⑥步。
3.在结合实质性学科的过程中,统计学是能发现客观世界规律,更好决策,改变世界和培养相应领域领袖的一门学科。
三、案例分析题1.总体:我班所有学生;单位:我班每个学生;样本:我班部分学生;品质标志:姓名;数量标志:每个学生课程的成绩;指标:全班学生课程的平均成绩;指标体系:上学期全班同学学习的科目;统计量:我班部分同学课程的平均成绩;定性数据:姓名;定量数据:课程成绩;离散型变量:学习课程数;连续性变量:学生的学习时间;确定性变量:全班学生课程的平均成绩;随机变量:我班部分同学课程的平均成绩,每个同学进入教室的时间;横截面数据:我班学生月门课程的出勤率;时间序列数据:我班学生课程分别在第一个月、第二个月、第三个月、第四个月的出勤率;面板数据:我班学生课程分别在第一个月、第二个月、第三个月、第四个月的出勤率;选用描述统计。
统计学第五章抽样推断二、单项选择题1、对总体的数量特征进行抽样估计的前提是抽样必须遵循(B)。
A.大量性B.随机性C.可靠性D.准确性2、一般认为大样本的样本单位数至少要大于(A)。
A.30B.50C.100D.2003、抽样平均误差是指(D)。
A.抽中样本的样本指标与总体指标的实际误差B.抽中样本的样本指标与总体指标的误差范围C.所有可能样本的抽样误差的算术平均数D.所有可能样本的样本指标的标准差4、在其它条件相同的情况下,重复抽样的抽样误差(A)不重复抽样的抽样误差。
A.大于B.小于C.总是等于D.通常小于或等于5、在其它条件不变的情况下,要使抽样误差减少1/3,样本单位数必须增加(D)。
A.1/3B.1.25倍C.3倍D.9倍6、从产品生产线上每隔10分钟抽取一件产品进行质量检验。
推断全天产品的合格率时,其抽样平均误差常常是按(C)的误差公式近似计算的。
A.简单随机抽样B.整群抽样C.等距抽样D.类型抽样7、通常使样本单位在总体中分布最不均匀的抽样组织方式是(B)。
A.简单随机抽样B.整群抽样C.分层抽样D.等距抽样9、抽样平均误差和极限误差的关系是(D)A抽样平均误差大于极限误差B抽样平均误差等于极限误差C抽样平均误差小于极限误差D抽样平均误差大于、等于、小于极限误差都可能10、抽样平均误差的实质是(D)A、总体标准差B、样本标准差C、抽样误差的标准差D、全部可能样本平均数的标准差三、多项选择题C、可以计算抽样误差D、以概率论和数理统计学为理论基础2、影响抽样平均误差大小的因素有(ABCD)。
A、总体各单位标志值的差异程度B、抽样数目C、样本各单位标志值的差异程度D、抽样组织方式E、抽样推断的把握程度3、影响必要的抽样数目的因素有(BCDE)。
A、总体各单位标志值的差异程度B、样本各单位标志值的差异程度C、抽样方法和抽样组织方式D、抽样推断的把握程度E、允许误差4、计算抽样平均误差时,由于总体方差是未知的,通常有下列代替方法(ACE)。
第五章 抽样推断一、单项选择题 1 2 3 4 5 6 7 8 9 10 C B A D B D C B A C 11 12 13 14 15 16 17 18 19 20 ADCADCACBD二、多项选择题1 2 3 4 5 ABCE ABDE BCE ABCE ABDE 6 7 8 9 10 ACE ADE ACD ABE CDE 11 12 13 14 15 BDE CD BC ABCD ABCDE 16 17 18 19 20 AD ACBCEABDEACE三、判断题 1 2 3 4 5 6 7 8 9 10 ×××√√×√√××四、填空题 1、变量 属性 2、正 反3、重复抽样 不重复抽样4、抽样总体 样本5、大于 N n -1 Nn 6、标准差7、样本 总体 抽样平均误差 抽样平均误差 △x = Z x σ 8、合适的样本估计量 一定的概率保证程度 允许的极限误差范围 9、随机抽样 统计分组 10、增大 增大 降低 11、大数定律 中心极限定理 12、样本容量不小(不小于30个单位) 13、大 0.514、缩小33(即0.5774) 扩大 1.1180 15、估计量(或统计量) 参数 五、简答题(略) 六、计算题1、已知条件:P = 0.5 ,n = 100 且重复抽样 求:p ≤0.45的概率 解:Z =1100)5.01(5.05.045.0)1(=-⨯-=--nP P P p则F (Z = 1) = 0.6827 所以p ≤0.45的概率为:26827.01-= 0.15865 2、解E (x 1) = E (0.5X 1 + 0.3X 2 + 0.2X 3) = 0.5 E (X ) + 0.3 E (X ) + 0.2E (X ) = E (X ) = XE (x 2) = E (0.5X 1 + 0.25X 2 + 0.25X 3)= 0.5 E (X ) + 0.25 E (X ) + 0.25E (X )= E (X ) = XE (x 3) = E (0.4X 1 + 0.3X 2 + 0.3X 3) = 0.4 E (X ) + 0.3 E (X ) + 0.3E (X ) = E (X ) = X 所以x 1、x 2、x 3都是X 的无偏估计量。
D (x 1) = D (0.5X 1 + 0.3X 2 + 0.2X 3) = 0.25 D (X ) + 0.09 D (X ) + 0.04D (X ) = 0.38D (x 2) = D (0.5X 1 + 0.25X 2 + 0.25X 3)= 0.25 D (X ) + 0.0625D (X ) + 0.0625D (X )= 0.375D (x 3) = D (0.4X 1 + 0.3X 2 + 0.3X 3) = 0.16D (X ) + 0.09D (X ) + 0.09D (X ) = 0.34由于0.38>0.375>0.34 ,所以x 3最有效。
3、已知条件:P = 0.1 ,n = 500 求:p ≥ 0.12的概率 解:Z ==-⨯-=--500)1.01(1.01.012.0)1(nP P P p 1.49则查表得F (Z = 1.49) = 0.8638 所以p ≥ 0.12的概率为:28638.01-= 0.0681 4、已知条件: X = 68公斤,σ= 12公斤,则Z ==-=-50126872nXx σ2.36查表得F (Z = 2.36) = 0.9817 所以,x >72公斤的概率为:29817.01-= 0.0091 在计算概率时,假设了旅客的体重呈正态分布。
如果旅客体重不呈正态分布,则超重的概率就可能增大;此外,根据本例的计算结果,旅客不能有任何随身携带的行李,否则超重的概率也将大大增加。
5、在重复抽样条件下,抽样单位数n 若增加了3倍,即为4n ,则新的抽样平均误差x σ’为原抽样平均误差x σ的二分之一,即x σ’=n x4σ=n xσ21 = 21x σ如果抽样单位数n 减少了50%,即为0.5n ,则新的抽样平均误差x σ’为原抽样平均误差x σ的1.414倍,即x σ’=n x5.0σ= 1.414n xσ= 1.414x σ6、设该种袋装花生的平均粒数为x ,标准差为σ。
已知:F (Z ) = 1- 2×0.0668 = 0.8664,所以袋装花生130粒的临界值Z = 1.5 又:F (Z ) = 1- 2×0.1586 = 0.6828,所以袋装花生100粒的临界值Z = 1.0 根据Z =σxx -有1.5σ= 130 -x 1.0σ= x - 100解得x = 112(粒)σ= 12(粒)7、已知条件:σ= 3克 ,n = 36袋 ,要求x ≥ 250克的概率达95% ,临界值Z 为1.645 。
求:X 根据Z =nXx σ-有1.645 =363250X -=21250-X X = 250.82(克)应将机器调节至平均装250.82克的位置上。
8、已知条件:n = 144 、x = 4.95 m 3 、σx2= 2.25 、F (Z )= 95.45%时,Z = 2(而且条件为重复抽样)nxx 2σσ==14425.2= 0.125 m 3 △x = Z x σ= 2×0.125 = 0.275 m 3x - △x ≤X ≤x + △x4.95 – 0.25 ≤X ≤4.95 + 0.25 4.7(m 3)≤X ≤5.2(m 3)10000名工人的平均工作量,将落在4.7(m 3)至5.2(m 3)范围内的可靠程度可达95.45% 。
9、抽样平均误差计算表:(条件为不重复抽样) 收入分组 (元/人) 组中值 x 工人数 f 其中: 女工人数100650-x 100650-x f (100650-x )2f 500以下 500—600 600—700 700—800 800—900 900以上 450 550 650 750 850 950 20 50 100 40 30 10 4 10 208 5 3 -2 -1 0 1 2 3 -40 -500 40 60 30 80 50 0 4012090 合 计—25050—40380设x 0 = 650,d = 100 ①工人收入的标准差:2020)()(⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎣⎡---=∑∑∑∑f fd x x f f d x x d x σ = 100225040250380⎥⎦⎤⎢⎣⎡- = 122.2457(元)工人收入的抽样平均误差:)1(2Nnnxx -=σσ =%)51(25014944- = 7.5357(元) 女工比重的抽样平均误差:(女工比重 p = 20%))1()1(N n n p p p --=σ=%)51(2508.02.0-⨯= 0.0247 ②工人的平均收入00)(x d f f d x x x +⋅-=∑∑ =⨯25040100 + 650 = 666(元) 当F (Z )= 95.45%时,Z = 2 所以△x = Z x σ= 2×7.5357 = 15.0714 (元)则5000名工人的平均收入范围为:x - △x ≤X ≤x + △x666 – 15.0714 ≤X ≤666 + 15.0714 650.9286(元)≤X ≤681.0714(元)而5000名工人的总收入范围为:650.9286×5000 ~ 681.0714×5000 3254643(元)~ 3405357(元)当F (Z )= 86.64%时,Z = 1.5 所以△p = Z p σ= 1.5×0.0247 = 0.03705则女工比重的范围为:p – △p ≤P ≤p + △p 20% - 3.705% ≤P ≤20% + 3.705%16.295% ≤P ≤23.705%③关于平均收入的样本容量根据要求:△x = 666×2% = 13.32(元),F (Z )= 95%时,Z = 1.9622222x x xZ N NZ n σσ+∆= = 1494496.132.135********96.15000222⨯+⨯⨯⨯ = 303.9 = 304(人) 关于女工成数的样本容量根据要求:△p = 3.5% ,F (Z )= 95%时,Z = 1.96)1()1(222p p Z N p p NZ n p -+∆-= = 8.02.096.1035.050008.02.096.15000222⨯⨯+⨯⨯⨯⨯ = 456(人)以后调查同一总体时,应该确定的样本容量应为456人。
10、条件:n = 500件 、Nn= 5% 则N = 10000件,p = 95%,△p = 2%(条件为不重复抽样))1()1(Nnn p p p --=σ = %)51(50005.095.0-⨯= 0.0095p – △p ≤P ≤p + △p 95% - 2% ≤P ≤95% + 2%93 % ≤P ≤97 %根据△p = Z p σ得Z =ppσ∆=0095.002.0= 2.11Z = 2.11查表得F (Z )为96.52%,即一级品率落在93 %至97 %范围内的可靠程度可达到96.52% 。
另外,在此范围内的一级品数量是9300件至9700件。
11、已知条件:n = 400台,不重复抽样但Nn为很小部分。
①使用时间10年以下车床台数的比重区间,p = 25% ,Z = 2n p p p )1(-=σ =40075.025.0⨯ = 0.0217 △p = Z p σ= 2×0.0217 = 4.34% p – △p ≤P ≤p + △p25% - 4.34% ≤P ≤25% + 4.34%20.66% ≤P ≤29.34%②使用时间10-20年的车床台数的比重区间,p = 48% ,Z = 2np p p )1(-=σ =40052.048.0⨯ = 0.0250△p = Z p σ= 2×0.0250 = 5.00%p – △p ≤P ≤p + △p 48% - 5% ≤P ≤48% + 5%43% ≤P ≤53%③使用时间20年以上车床台数的比重区间,p = 27% ,Z = 2n p p p )1(-=σ =40073.027.0⨯ = 0.0222 △p = Z p σ= 2×0.0217 = 4.44%p – △p ≤P ≤p + △p27% - 4.44% ≤P ≤27% + 4.44%22.56% ≤P ≤31.44%12、根据Z =xXx σ-可得F (Z )= F (xXx σ-)= F (44246-)+ F (44652-) = F (1)+ F (1.5) =28664.026827.0+= 0.7746居民家庭平均每月的书报费支出有77.46%的可能在42~52元之间。