第六章 自相关 思考题
- 格式:doc
- 大小:365.00 KB
- 文档页数:10


第六章课后答案6.1(1)收入—消费模型为Se = (2.5043) (0.0075)t = (-3.7650) (125.3411)R2 = 0.9978,F = 15710.39,d f = 34,DW = 0.5234(2)对样本量为36、一个解释变量的模型、5%显著水平,查DW统计表可知,d L=1.411,d U= 1.525,模型中DW<d L,显然消费模型中有自相关。
(3)采用广义差分法查5%显著水平的DW统计表可知d L = 1.402,d U = 1.519,模型中DW= 2.0972>d U,说明广义差分模型中已无自相关。
同时,判定系数R2、t、F统计量均达到理想水平。
由差分方程式可以得出:所以最终的消费模型为:6.2(1)给定n=16, ,在的显著水平下,查DW统计表可知,。
模型中,所以可以判断模型中存在正自相关。
给定n=16, ,在的显著水平下,查DW统计表可知,。
模型中,所以可以判断模型中不存在自相关。
(2)自相关可能由于模型6.1的误设,因为它排除了趋势的平方项。
(3)虚假自相关是由于模型的误设造成的,因此就要求对可能的函数形式有先验知识。
真正的自相关是可以通过广义差分法等方法来修正。
6.3(1)收入—消费模型为(2)DW=0.575,取,查DW上下界,说明误差项存在正自相关。
(3)采用广义差分法使用普通最小二乘法估计的估计值,得DW=1.830,已知,模型中因此,在广义差分模型中已无自相关。
由差分方程式可以得出:因此,修正后的回归模型应为6.4(1)回归结果如下:(2)模型检验:从回归结果可以看出,参数均显著,模型拟和较好。
异方差的检验:通过white检验可以得知模型不存在异方差。
DW检验:给定n=25, ,在的显著水平下,查DW统计表可知,。
模型中,所以可以判断模型中存在正自相关。
(3)采用广义差分法修正模型中存在的自相关问题:给定n=24,,在的显著水平下,查DW统计表可知,。


第六章一、单项选择题1.下面的函数关系是( )A现代化水平与劳动生产率 B圆周的长度决定于它的半径C家庭的收入和消费的关系 D亩产量与施肥量2.相关系数r的取值范围( )A -∞< r <+∞B -1≤r≤+1C -1< r < +1D 0≤r≤+13.年劳动生产率x(干元)和工人工资y=10+70x,这意味着年劳动生产率每提高1千元时,工人工资平均( )A增加70元 B减少70元 C增加80元 D减少80元4.若要证明两变量之间线性相关程度高,则计算出的相关系数应接近于( )A +1B -1C 0.5D 15.回归系数和相关系数的符号是一致的,其符号均可用来判断现象( )A线性相关还是非线性相关 B正相关还是负相关C完全相关还是不完全相关 D单相关还是复相关6.某校经济管理类的学生学习统计学的时间(x)与考试成绩(y)之间建立线性回归方程ŷ=a+bx。
经计算,方程为ŷ=200—0.8x,该方程参数的计算( )A a值是明显不对的B b值是明显不对的C a值和b值都是不对的D a值和b值都是正确的7.在线性相关的条件下,自变量的均方差为2,因变量均方差为5,而相关系数为0.8时,则其回归系数为:( )A 8B 0.32C 2D 12.58.进行相关分析,要求相关的两个变量( )A都是随机的 B都不是随机的C一个是随机的,一个不是随机的 D随机或不随机都可以9.下列关系中,属于正相关关系的有( )A合理限度内,施肥量和平均单产量之间的关系B产品产量与单位产品成本之间的关系C商品的流通费用与销售利润之间的关系D流通费用率与商品销售量之间的关系10.相关分析是研究( )A变量之间的数量关系 B变量之间的变动关系C变量之间的相互关系的密切程度 D变量之间的因果关系11.在回归直线y c=a+bx,b<0,则x与y之间的相关系数 ( )A r=0B r=lC 0< r<1D -1<r <012.当相关系数r=0时,表明( )A现象之间完全无关 B相关程度较小C现象之间完全相关 D无直线相关关系13.下列现象的相关密切程度最高的是( )A某商店的职工人数与商品销售额之间的相关系数0.87B流通费用水平与利润率之间的相关系数为-0.94C商品销售额与利润率之间的相关系数为0.51D商品销售额与流通费用水平的相关系数为-0.8114.估计标准误差是反映( )A平均数代表性的指标 B相关关系的指标C回归直线方程的代表性指标 D序时平均数代表性指标二、多项选择题1.下列哪些现象之间的关系为相关关系( )A家庭收入与消费支出关系 B圆的面积与它的半径关系C广告支出与商品销售额关系D商品价格一定,商品销售与额商品销售量关系2.相关系数表明两个变量之间的( )A因果关系 C变异程度 D相关方向 E相关的密切程度3.对于一元线性回归分析来说( )A两变量之间必须明确哪个是自变量,哪个是因变量B回归方程是据以利用自变量的给定值来估计和预测因变量的平均可能值C可能存在着y依x和x依y的两个回归方程D回归系数只有正号4.可用来判断现象线性相关方向的指标有( )A相关系数 B回归系数 C回归方程参数a D估计标准误5.单位成本(元)依产量(千件)变化的回归方程为y c=78- 2x,这表示( ) A产量为1000件时,单位成本76元B产量为1000件时,单位成本78元C产量每增加1000件时,单位成本下降2元D产量每增加1000件时,单位成本下降78元6.估计标准误的作用是表明( )A样本的变异程度 B回归方程的代表性C估计值与实际值的平均误差 D样本指标的代表性7.销售额与流通费用率,在一定条件下,存在相关关系,这种相关关系属于( ) A完全相关 B单相关 C负相关 D复相关8.在直线相关和回归分析中( )A据同一资料,相关系数只能计算一个B据同一资料,相关系数可以计算两个C据同一资料,回归方程只能配合一个D据同一资料,回归方程随自变量与因变量的确定不同,可能配合两个9.相关系数r的数值( )A可为正值 B可为负值 C可大于1 D可等于-110.从变量之间相互关系的表现形式看,相关关系可分为( )A正相关 B负相关 C直线相关 D曲线相关11.确定直线回归方程必须满足的条件是( )A现象间确实存在数量上的相互依存关系B相关系数r必须等于1C y与x必须同方向变化D现象间存在着较密切的直线相关关系12.当两个现象完全相关时,下列统计指标值可能为( )A r=1B r=0C r=-1D S y=013.在直线回归分析中,确定直线回归方程的两个变量必须是( )A一个自变量,一个因变量 B均为随机变量C对等关系 D一个是随机变量,一个是可控制变量14.配合直线回归方程是为了( )A确定两个变量之间的变动关系 B用因变量推算自变量C用自变量推算因变量 D两个变量都是随机的15.在直线回归方程中( )A在两个变量中须确定自变量和因变量 B一个回归方程只能作一种推算C要求自变量是给定的,而因变量是随机的。

第六章 自相关一、判断题1.模型中的解释变量含有滞后被解释变量的时候可以使用DW 检验法检验自相关。
(F ) 2.可以作残差对某个解释变量的散点图来大概判断是否存在自相关。
(F ) 3.存在序列相关时,使用标准公式估计的随机扰动项的方差不再具有无偏性。
(T ) 4.杜宾—瓦尔森检验能够检验出任何形式的自相关。
( F ) 5.不存在负的自相关关系。
(F ) 6.LM 检验与DW 检验结果不一致是很有可能的。
(T ) 7. 存在序列相关时,有可能会高估或者低估随机扰动项的真实方差,但通常会低估。
(T )二、单项选择题1.如果模型t t 10t u x y ++=ββ存在序列相关,则( D )。
A. ()0x u Cov t t =,B. ()()s t 0u u Cov s t ≠=,C. ()0x u Cov t t ≠,D. ()()s t 0u u Cov s t ≠≠,2.DW 检验的零假设是(ρ为随机误差项的一阶相关系数)( B )。
A .DW =0B .0=ρC .DW =1D .1=ρ3.下列哪个序列相关可用DW 检验(t v 为具有零均值,常数方差且不存在序列相关的随机变量)( A )。
A . t 1t t v u u +=-ρB .t 2t 21t t v u u u +++=-- ρρC .t t v u ρ= ++=-1t 2t t v v u ρρ4.DW 的取值范围是( D )。
A .-1≤DW≤0B .-1≤DW≤1C .-2≤DW≤2D .0≤DW≤45.当DW =4时,说明( D )。
A .不存在序列相关B .不能判断是否存在自相关C .存在完全的正的自相关D .存在完全的负的自相关6.根据20个观测值估计的结果,一元线性回归模型的DW =2.3。
在样本容量n=20,解释变量k=1,显著性水平为0.05时,查得d L =1,d U =1.41,则可以决断( A )。
A .不存在自相关B .存在正的自相关C .存在负的自相关D .无法确定7.当模型存在序列相关现象时,适宜的参数估计方法是( C )。
第六章自相关二、问答题1、那些原因可以造成自相关;2、存在自相关时,参数的OLS估计具有哪些性质;3、如何检验是否存在自相关;4、当存在自相关时,如何利用广义差分法进行参数估计;5、当存在自相关时,如何利用广义最小平方估计法进行参数估计;6、异方差与自相关有什么异同;三、计算题1、证明:当样本个数较大时,)d。
≈-1(2ρα2、通过D-W检验,判断下列模型中是否存在自相关,显著性水平%5=(1)样本大小:20;解释变量个数(包括常数项):2;d=0.73;(2)样本大小:35;解释变量个数(包括常数项):3;d=3.56;(3)样本大小:50;解释变量个数(包括常数项):3;d=1.87;(4)样本大小:80;解释变量个数(包括常数项):6;d=1.62;(5)样本大小:100;解释变量个数(包括常数项):5;d=2.41;3、假定存在下表所示的时间序列数据:请回答下列问题:(1)利用表中数据估计模型:t t t x y εββ++=10;(2)利用D-W 检验是否存在自相关?如果存在请用d 值计算估计自相关系数ρ;(3)利用广义差分法重新估计模型:'''1011(1)()t t tt t y y x x ρβρβρε---=-+-+。
第三部分 参考答案二、问答题1、那些原因可以造成自相关?答:造成自相关的原因大致包括以下六个方面:(1)经济变量的变化具有一定的倾向性。
在实际的经济现象中,许多经济变量的现值依赖于他的前期值。
也就是说,许多经济时间序列都有一个明显的相依性特点,这种现象称作经济变量所具有的惯性。
(2)缺乏应有变量的设定偏差。
(3)不正确的函数形式的设定错误。
(4)蛛网现象和滞后效应。
(5)随机误差项的特征。
(6)数据拟合方法造成的影响。
2、存在自相关时,参数的OLS 估计具有哪些性质?答:当存在自相关,即I D ≠ΩΩ=,)(2σε时,OLS 估计的性质有:(1)βˆ是观察值Y 和X 的线性函数;(2)βˆ是β的无偏估计;(3)βˆ的协方差矩阵为112)()()ˆ(--'Ω''=X X X X X X D σβ;(4)βˆ不是β的最小方差线性无偏估计;(5)如果nX X n Ω'∞→lim存在,那么βˆ是β的一致估计;(6)2σ 不是2σ的无偏估计;(7)2σ不是2σ的一致估计。

第一章绪论你能分别举出三个时间序列数据、截面数据、面板数据、虚拟变量数据的实际例子,并分别说明这些数据的来源吗?答:时间序列数据:中国1981年至2010年国内生产总值,可从中国统计年鉴查得数据。
截面数据:中国2010年各省、区、直辖市的国内生产总值,中国统计年鉴查得数据。
面板数据:中国1981年至2010年各省、区、直辖市的国内生产总值,中国统计年鉴查得数据。
虚拟变量数据:自然灾害状态,1表示该状态发生,0表示该状态不发生。
为什么对已经估计出参数的模型还要进行检验?你能举一个例子说明各种检验的必要性吗?答:模型中的参数被估计以后,一般说来这样的模型还不能直接加以应用,还需要对其进行检验。
首先,在设定模型时,对所研究经济现象规律性的认识可能并不充分,所依据的经济理论对所研究对象也许还不能作出正确的解释和说明。
或者经济理论是正确的,但可能我们对问题的认识只是从某些局部出发,或者只是考察了某些特殊的样本,以局部去说明全局的变化规律,可能导致偏差。
其次,我们用以估计参数的统计数据或其它信息可能并不十分可靠,或者较多地采用了经济突变时期的数据,不能真实代表所研究的经济关系,或者由于样本太小,所估计参数只是抽样的某种偶然结果。
此外,我们所建立的模型、采用的方法、所用的统计数据,都有可能违反计量经济的基本假定,这也可能导出错误的结论。
第二章简单线性回归模型2.1相关分析与回归分析的关系是什么?答:相关分析与回归分析有密切的关系,它们都是对变量间相关关系的研究,二者可以相互补充。
相关分析可以表明变量间相关关系的性质和程度,只有当变量间存在一定程度的相关关系时,进行回归分析才有实际的意义。
同时,在进行相关分析时如果要具体确定变量间相关的具体数学形式,又要依赖于回归分析,而且相关分析中相关系数的确定也是建立在回归分析基础上的。
相关分析与回归分析的区别。
从研究目的上看,相关分析是用一定的数量指标(相关系数)度量变量间相互联系的方向和程度;回归分析却是要寻求变量间联系的具体数学形式,是要根据解释变量的固定值去估计和预测被解释变量的平均值。

计量经济学思考题答案第一章绪论1.1怎样理解产生于西方国家的计量经济学能够在中国的经济理论研究和现代化建设中发挥重要作用?答:计量经济学的产生源于对经济问题的定量研究,这是社会经济发展到一定阶段的客观需要。
计量经济学的发展是与现代科学技术成就结合在一起的,它反映了社会化大生产对各种经济因素和经济活动进行数量分析的客观要求。
经济学从定性研究向定量分析的发展,是经济学逐步向更加精密、更加科学发展的表现。
我们只要坚持以科学的经济理论为指导,紧密结合中国经济的实际,就能够使计量经济学的理论与方法在中国的经济理论研究和现代化建设中发挥重要作用。
1.2理论计量经济学和应用计量经济学的区别和联系是什么?答:计量经济学不仅要寻求经济计量分析的方法,而且要对实际经济问题加以研究,分为理论计量经济学和应用计量经济学两个方面。
理论计量经济学是以计量经济学理论与方法技术为研究内容,目的在于为应用计量经济学提供方法论。
所谓计量经济学理论与方法技术的研究,实质上是指研究如何运用、改造和发展数理统计方法,使之成为适合测定随机经济关系的特殊方法。
应用计量经济学是在一定的经济理论的指导下,以反映经济事实的统计数据为依据,用计量经济方法技术研究计量经济模型的实用化或探索实证经济规律、分析经济现象和预测经济行为以及对经济政策作定量评价。
1.3怎样理解计量经济学与理论经济学、经济统计学的关系?答:1、计量经济学与经济学的关系。
联系:计量经济学研究的主体—经济现象和经济关系的数量规律;计量经济学必须以经济学提供的理论原则和经济运行规律为依据;经济计量分析的结果:对经济理论确定的原则加以验证、充实、完善。
区别:经济理论重在定性分析,并不对经济关系提供数量上的具体度量;计量经济学对经济关系要作出定量的估计,对经济理论提出经验的内容。
2、计量经济学与经济统计学的关系。
联系:经济统计侧重于对社会经济现象的描述性计量;经济统计提供的数据是计量经济学据以估计参数、验证经济理论的基本依据;经济现象不能作实验,只能被动地观测客观经济现象变动的既成事实,只能依赖于经济统计数据。

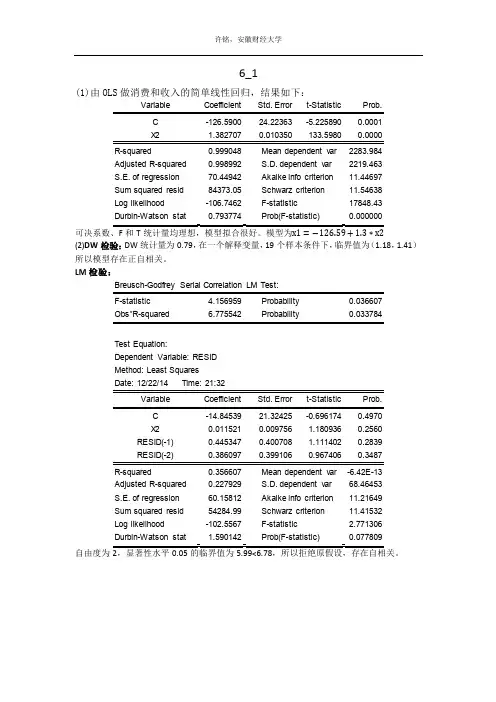
6_1(1)由OLS做消费和收入的简单线性回归,结果如下:Variable Coefficient Std. Error t-Statistic Prob.C -126.5900 24.22363 -5.225890 0.0001R-squared 0.999048 Mean dependent var 2283.984Adjusted R-squared 0.998992 S.D. dependent var 2219.463S.E. of regression 70.44942 Akaike info criterion 11.44697Sum squared resid 84373.05 Schwarz criterion 11.54638Log likelihood -106.7462 F-statistic 17848.43Durbin-Watson stat 0.793774 Prob(F-statistic) 0.000000可决系数、F和T统计量均理想,模型拟合很好。
模型为x1=−126.59+1.3∗x2(2)DW检验:DW统计量为0.79,在一个解释变量,19个样本条件下,临界值为(1.18,1.41)所以模型存在正自相关。
LM检验:F-statistic 4.156959 Probability 0.036607Test Equation:Dependent Variable: RESIDMethod: Least SquaresDate: 12/22/14 Time: 21:32C -14.84539 21.32425 -0.696174 0.4970X2 0.011521 0.009756 1.180936 0.2560RESID(-1) 0.445347 0.400708 1.111402 0.2839RESID(-2) 0.386097 0.399106 0.967406 0.3487R-squared 0.356607 Mean dependent var -6.42E-13Adjusted R-squared 0.227929 S.D. dependent var 68.46453S.E. of regression 60.15812 Akaike info criterion 11.21649Sum squared resid 54284.99 Schwarz criterion 11.41532Log likelihood -102.5567 F-statistic 2.771306Durbin-Watson stat 1.590142 Prob(F-statistic) 0.077809自由度为自相关分析:解释变量和被解释变量有显著二阶自相关。

第六章练习题及参考解答6.1 下表给出了美国1960-1995年36年间个人实际可支配收入X 和个人实际消费支出Y 的数据。
表6.6 美国个人实际可支配收入和个人实际消费支出 (单位:百亿美元)注:资料来源于Economic Report of the President ,数据为1992年价格。
要求:(1)用普通最小二乘法估计收入—消费模型;t t u X Y ++=221ββ(2)检验收入—消费模型的自相关状况(5%显著水平); (3)用适当的方法消除模型中存在的问题。
练习题6.1参考解答:(1)收入—消费模型为 tt X Y 0.93594287.9ˆ+-=Se = (2.5043) (0.0075)t = (-3.7650) (125.3411)R 2 = 0.9978,F = 15710.39,d f = 34,DW = 0.5234(2)对样本量为36、一个解释变量的模型、5%显著水平,查DW 统计表可知,d L =1.411,d U = 1.525,模型中DW<d L ,显然消费模型中有自相关。
(3)采用广义差分法e t = 0.72855 e t-1**9484.07831.3ˆtt X Y +-=)8710.1(=Se (0.0189)t = (-2.0220) (50.1682)R 2 = 0.9871 F = 2516.848 d f = 33 DW = 2.0972查5%显著水平的DW 统计表可知d L = 1.402,d U = 1.519,模型中DW = 2.0972> d U ,说明广义差分模型中已无自相关。
同时,可决系数R 2、t 、F 统计量均达到理想水平。
9366137285501783131...ˆ=--=β最终的消费模型为 Y t = 13.9366+0.9484 X t6.2 在研究生产中劳动所占份额的问题时,古扎拉蒂采用如下模型模型1 t t u t Y ++=10αα模型2 t t u t t Y +++=2210ααα其中,Y 为劳动投入,t 为时间。
计量经济学课后思考题答案第五章异⽅差性思考题5.1 简述什么是异⽅差?为什么异⽅差的出现总是与模型中某个解释变量的变化有关?答:设模型为,如果其他假定均不变,但模),....,,(....n 21i X X Y i i 33i 221i =µ+β++β+β=型中随机误差项的⽅差为,则称具有异⽅差性。
由于异⽅差性),...,,()(n 21i Var 2i i =σ=µi µ指的是被解释变量观测值的分散程度是随解释变量的变化⽽变化的,所以异⽅差的出现总是与模型中某个解释变量的变化有关。
5.2 试归纳检验异⽅差⽅法的基本思想,并指出这些⽅法的异同。
答:各种异⽅差检验的共同思想是,基于不同的假定,分析随机误差项的⽅差与解释变量之间的相关性,以判断随机误差项的⽅差是否随解释变量变化⽽变化。
其中,⼽德菲尔德-跨特检验、怀特检验、ARCH 检验和Glejser 检验都要求⼤样本,其中⼽德菲尔德-跨特检验、怀特检验和Glejser 检验对时间序列和截⾯数据模型都可以检验,ARCH 检验只适⽤于时间序列数据模型中。
⼽德菲尔德-跨特检验和ARCH 检验只能判断是否存在异⽅差,怀特检验在判断基础上还可以判断出是哪⼀个变量引起的异⽅差。
Glejser 检验不仅能对异⽅差的存在进⾏判断,⽽且还能对异⽅差随某个解释变量变化的函数形式进⾏诊断。
5.3 什么是加权最⼩⼆乘法?它的基本思想是什么?答:以⼀元线性回归模型为例:12i i i Y X u ββ=++经检验存在异⽅差,公式可以表i µ⽰为22var()()i i i u f X σσ==。
选取权数,当越⼩时,权数越⼤。
当 i w 2i σi w 越⼤时,权数越⼩。
将权数与残差平⽅相乘以后再求和,得到加权的残差平⽅和:2i σi w ,求使加权残差平⽅和最⼩的参数估计值。
这种2i 21i 2i i X Y w e w )(**β-β-=∑∑**??21ββ和求解参数估计式的⽅法为加权最⼩⼆乘法。
一、单项选择题1.在给定的显著性水平之下,若DW 统计量的下和上临界值分别为dL 和dU,则当L U d d d <<时,可认为随机误差项( )A.存在一阶正自相关B.存在一阶负相关C.不存在序列相关D.存在序列相关与否不能断定2.在序列自相关的情况下,参数估计值的方差不能正确估计的原因是( )A22() i E u σ≠ B ()0() i j E u u i j ≠≠ C ()0 i i E x u ≠ D ()0 i E u ≠ 3.在检验异方差的方法中,不正确的是( )A. Goldfeld-Quandt 方法B. X-Y 散点图检验法C. White 检验法D. DW 检验法4.在DW 检验中,当d 统计量为0时,表明( )A.存在完全的正自相关B.存在完全的负自相关C.不存在自相关D.不能判定5.在下列产生序列自相关的原因中,不正确的是( )A.经济变量的惯性作用B.经济行为的滞后作用C.设定偏误D.解释变量的共线性6.加权最小二乘法是( )的一个特例A.广义差分法B.普通最小二乘法C.广义最小二乘法D.两阶段最小二乘法8.设为随机误差项,则一阶线性自相关是指( )A cov(,)0()t s u u t s ≠≠B 1t t t u u ρε-=+C 1122t t t t u u u ρρε--=++ D21t t t u u ρε-=+ 9.在自相关情况下,常用的估计方法( )A .普通最小二乘法 B. 广义差分法 C .工具变量法 D. 加权最小二乘法10.在DW 检验中,不能判定的区域是( )A 0,44l l d d d d <<-<<B 4u u d d d <<-C ,44l u u l d d d d d d <<-<<-D 上述都不对11.用于检验序列相关的DW 统计量的取值范围是( )。
A.0≤DW ≤1B.-1≤DW ≤1C.-2≤DW ≤2D.0≤DW ≤412.已知DW 统计量的值接近于2,则样本回归模型残差的一阶自相关系数ρˆ近似等于( )。
第六章 自相关 思考题6.1 如何使用 DW 统计量来进行自相关检验 ? 该检验方法的前提条件和局限性有哪些 ?6.2 当回归模型中的随机误差项为 AR(1) 自相关时 , 为什么仍用OLS 法会低估的ˆjβ标准误差 ? 6.3 判断以下陈述的真伪,并给出合理的解释。
1) 当回归模型随机误差项有自相关时 , 普通最小二乘估计量是有偏误的和非有效的。
2)DW 检验假定随机误差项i u 的方差是同方差。
3) 用一阶差分法消除自相关是假定自相关系数ρ为-1。
4)当回归模型随机误差项有自相关时 , 普通最小二乘估计的预测值的方差和标准误差不再是有效的。
6.4 对于四个解释变量的回归模型011223344t t t t t t Y X X X X u βββββ=+++++如果样本量 n=50, 当 DW 统计量为以下数值时 , 请判断模型中的自相关状况。
1)DW=1.05 2)DW=1.40 3)DW=2.50 4)DW=3.97 6.5 如何判别回归模型中的虚假自相关 ? 6.6 在回归模型12t t t Y X u ββ=++中 ,t u 无自相关。
如果我们错误地判定模型中有一阶自相关 , 即1t t t u u v ρ-=+,并使用了广义差分模型1121(1)()t t t t t Y Y X X v βρβρ---=-+-+将会产生什么问题 ? 练习题6.1 表 6.6 给出了美国 1960~1995 年 36 年个人实际可支配收入 X 和个人实际消费支出Y 的数据。
1) 用普通最小二乘法估计收入-消费模型 ;12t t t Y X u ββ=++表 6.6 美国个人实际可支配收入和个人实际消费支出 ( 单位 :1010注 : 数据为 1992 年价格2) 检验收入 -消费模型的自相关状况 (5% 显著水平 ): 3) 用适当的方法消除模型中存在的问题。
6.2 在研究生产中劳动所占份额的问题时 , 古扎拉蒂采用以下模型。
第六章 自相关 思考题6.1 如何使用 DW 统计量来进行自相关检验 ? 该检验方法的前提条件和局限性有哪些 ?6.2 当回归模型中的随机误差项为 AR(1) 自相关时 , 为什么仍用OLS 法会低估的ˆjβ标准误差 ? 6.3 判断以下陈述的真伪,并给出合理的解释。
1) 当回归模型随机误差项有自相关时 , 普通最小二乘估计量是有偏误的和非有效的。
2)DW 检验假定随机误差项i u 的方差是同方差。
3) 用一阶差分法消除自相关是假定自相关系数ρ为-1。
4)当回归模型随机误差项有自相关时 , 普通最小二乘估计的预测值的方差和标准误差不再是有效的。
6.4 对于四个解释变量的回归模型011223344t t t t t t Y X X X X u βββββ=+++++如果样本量 n=50, 当 DW 统计量为以下数值时 , 请判断模型中的自相关状况。
1)DW=1.05 2)DW=1.40 3)DW=2.50 4)DW=3.97 6.5 如何判别回归模型中的虚假自相关 ? 6.6 在回归模型12t t t Y X u ββ=++中 ,t u 无自相关。
如果我们错误地判定模型中有一阶自相关 , 即1t t t u u v ρ-=+, 并使用了广义差分模型1121(1)()t t t t t Y Y X X v βρβρ---=-+-+ 将会产生什么问题 ? 练习题 6.1 表 6.6 给出了美国 1960~1995 年 36 年个人实际可支配收入 X 和个人实际消费支出Y 的数据。
1) 用普通最小二乘法估计收入-消费模型 ;12t t t Y X u ββ=++表 6.6 美国个人实际可支配收入和个人实际消费支出 ( 单位 :1010 美元 )资料来源:Economic Report of the Prsident 注 : 数据为 1992 年价格2) 检验收入 -消费模型的自相关状况 (5% 显著水平 ): 3) 用适当的方法消除模型中存在的问题。
6.2 在研究生产中劳动所占份额的问题时 , 古扎拉蒂采用以下模型。
模型 6.101t t Y a a t u =++模型 6.22012t t Y a a t a t u =+++其中 ,Y 为劳动投入 ,t 为时间。
据 1949-1964 年数据 , 对初级金属工业得到以下结果。
模型 6.3ˆtY =0.4529-0.0041t t= (-3.9608)2R =0.5284 DW=0.8252模型 6.4ˆtY =0.4786-0.0127t+0.00052t t= (-3.2724)(2.7777) 2R =0.6629 DW=1.82其中 , 括号内的数字为 t 统计量。
1) 模型 6.1 和模型 6.2 中是否有自相关 ? 2) 如何判定自相关的存在 ?3) 怎样区分虚假自相关和真正的自相关 ?6.3 表6.7是北京市连续 19 年城镇居民家庭人均收入与人均支出的数据。
表 6.7 北京市连续 19 年城镇居民家庭人均收入与支出数据表 ( 单位 : 元 )1) 建立居民收入一消费函数 ;2) 检验模型中存在的问题 , 并采取适当的补救措施予以处理 ; 3) 对模型结果进行经济解释。
.6.4 表 6.8 给出了日本工薪家庭实际消费支出与可支配收入数据。
表 6.8 日本工薪家庭实际消费支出与实际可支配收人 ( 单位 :103 日元 )资料来源 : 日本银行 .经济统计年报 注 : 数据为 1990 年价格1) 建立日本工薪家庭的收入一消费函数 ;2) 检验模型中存在的问题 , 并采取适当的补救措施予以处理 ; 3) 对模型结果进行经济解释。
6.5 表 6.9 给出了中国进口需求 (Y) 与国内生产总值 (X) 的数据。
表 6.91985~2003 年中国实际 GDP 和进口额 ( 单位 : 亿元 )实际进口额 (Y , 亿元) 2543.2 2983.4 3450.1 3571.6 3045.9 2950.4 3338 4182.2 5244.4 6311.9 7002.2 7707.2 8305.4 9301.3 9794.8数据来源:中国统计年鉴 2004( 光盘 )注 : 实际 GDP 和实际进口额均为 1985 年可比价指标。
1) 检测进口额模型12t t t Y X u ββ=++的自相关性 ; 2) 采用科克伦 -奥克特迭代法处理模型中的自相关问题。
6.6 表 6.10 给出了某地区 1980~2000 年地区生产总值 (Y) 与固定资产投资额 (X)的数据。
表 6.10 地区生产总值(Y)与固定资产投资额(X )( 单位 : 亿元 )1) 使用对数线性模型12ln ln t t Y X u ββ=++进行回归,并检验回归模型的自相性 ; 2) 采用广义差分法处理模型中的自相关问题。
3) 令*1/t t t X X X -=(固定资产投资指数 ),*1/t t t Y Y Y -=(地区生产总值增长指数 ), 使用模型**12ln ln t t t Y X v ββ=++, 该模型中是否有自相关 ?第六章 自相关性1. 见P113 2. 见P113、P1163.解答:将tt t u r I ++=10ββ回归,得到残差序列t u ∧,然后将该序列用于tt t u u ερ+=-1的ols 估计,便可以得到ρ的估计量∧ρ。
最后又对tt t t u r I ερββ+++=-∧110回归,便可以得到1β的消除序列相关的估计量。
4.解答:(1)查表得到A 模型d L =1.106,d U =1.371,而DW=0.8252小于这两者,所以按D-W 检验,认为A 模型存在正自相关性;对B 模型:d L =0.982,d U =0.539,而DW=1.82,大于这两者,又小于2,所以按D-W 检验,认为B 模型不存在自相关性; (2)。
(3)要结合经济意义、模型是否同时存在异方差综合判断。
5.解答: (1)回归结果为:Dependent Variable: LN_CMethod: Least SquaresDate: 05/20/03 Time: 11:09Sample: 1951 1980Included observations: 29Excluded observations: 1Variable Coefficient Std. Error t-Statistic Prob.LN_A 0.002109 0.035573 0.059277 0.9532LN_H -0.092590 0.176814 -0.523659 0.6053LN_I 0.621243 0.207801 2.989602 0.0064LN_L 0.382541 0.148529 2.575521 0.0166C -0.678260 1.231607 -0.550712 0.5869R-squared 0.892890 Mean dependent var 3.746803Adjusted R-squared 0.875038 S.D. dependent var 0.432004S.E. of regression 0.152713 Akaike info criterion -0.764925Sum squared resid 0.559712 Schwarz criterion -0.529184Log likelihood 16.09141 F-statistic 50.01699Durbin-Watson stat 0.652136 Prob(F-statistic) 0.000000在显著性水平为0.05时,只有LN_I, LN_L显著。
模型的整体拟合教好。
出现这个情况的主要原因可能是模型中引入了与LN_C没多大关系的变量(LN_A ,LN_H)以及有多重共线性存在(LN_I,LN_L),当然也有可能存在自相关性。
(2)对残差和滞后一期的残差回归,结果如下:Dependent Variable: RESID01Method: Least SquaresDate: 05/20/03 Time: 11:23Sample(adjusted): 1952 1980Included observations: 27Excluded observations: 2 after adjusting endpointsVariable Coefficient Std. Error t-Statistic Prob.RESID_LG01 0.712928 0.151257 4.713356 0.0001R-squared 0.460509 Mean dependent var 0.003077Adjusted R-squared 0.460509 S.D. dependent var 0.146298S.E. of regression 0.107456 Akaike info criterion -1.587132Sum squared resid 0.300218 Schwarz criterion -1.539138Log likelihood 22.42629 Durbin-Watson stat 1.356284其t检验显著。
直接求其相关系数如下:0.679871652963。
根据上面回归结果,可以认为存在自回归。
(3)由第一个回归结果知道DW统计量d=0.652136。
查表知:dL =1.124,dU=1.743而d=0.652136,小于这两者,所以按D-W检验,认为残差存在正自相关性;若是去掉不显著的LN_A ,LN_H,回归结果如下:Dependent Variable: LN_CMethod: Least SquaresDate: 05/20/03 Time: 11:10Sample: 1951 1980Included observations: 30Variable Coefficient Std. Error t-Statistic Prob.LN_I 0.656181 0.187982 3.490653 0.0017LN_L 0.368859 0.140095 2.632914 0.0138C -1.432749 0.348715 -4.108657 0.0003R-squared 0.890773 Mean dependent var 3.721145Adjusted R-squared 0.882682 S.D. dependent var 0.447149S.E. of regression 0.153156 Akaike info criterion -0.820083Sum squared resid 0.633331 Schwarz criterion -0.679963Log likelihood 15.30124 F-statistic 110.0962Durbin-Watson stat 0.669905 Prob(F-statistic) 0.000000L(3)去掉不显著变量LN_A ,LN_H,用广义差分法修正。