第九章 分布滞后模型
- 格式:ppt
- 大小:1.18 MB
- 文档页数:54
分布滞后模型的估计建立总量消费函数是进行宏观经济管理的重要手段。
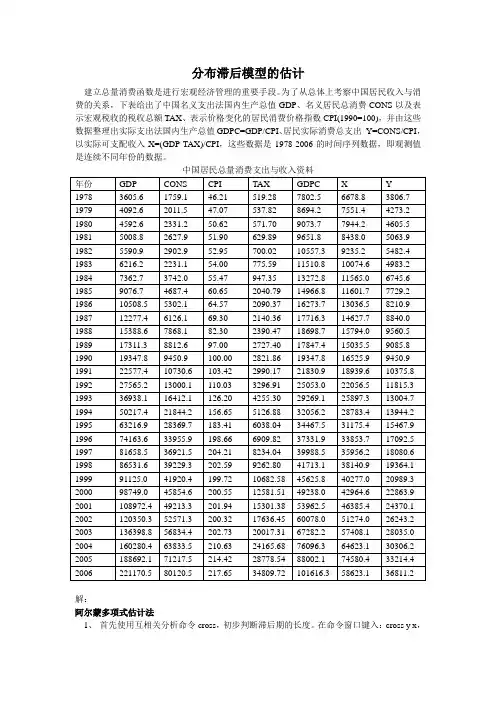
为了从总体上考察中国居民收入与消费的关系,下表给出了中国名义支出法国内生产总值GDP、名义居民总消费CONS以及表示宏观税收的税收总额TAX、表示价格变化的居民消费价格指数CPI(1990=100),并由这些数据整理出实际支出法国内生产总值GDPC=GDP/CPI、居民实际消费总支出Y=CONS/CPI,以实际可支配收入X=(GDP-TAX)/CPI,这些数据是1978-2006的时间序列数据,即观测值是连续不同年份的数据。
中国居民总量消费支出与收入资料解:阿尔蒙多项式估计法1、首先使用互相关分析命令cross,初步判断滞后期的长度。
在命令窗口键入:cross y x,输出结果如下图所示:x与y各期滞后值的相关系数从上图中可以看出,消费总支出y与当年和前四年的实际可支配收入相关,因此,利用阿尔蒙多项式估计法估计模型时,解释变量滞后阶数为5.利用EViews软件,输入样本数据,在命令窗口键入:LS y c pdl(x,5,2)得到以下回归分析结果:估计结果:xx x x x x yt t t t t t t5432104497.010270.013208.013311.010580.005015.0192.1794-----∧+++---= t = (2.07755) (6.63411) (6.51267) (7.90985) (6.26776) (0.99479)997444.02=R,250.2471=F ,955959.0..=W D其中括号内的数为相应参数的T 检验,R2是可决系数,F 和D.W.是有关的两个检验统计量。
2、模型检验从回归估计和残差图可以看出模型的拟合程度较好。
从截距项与斜率项的t 检验值看,均大于5%显著性水平下自由度为n-2=27的临界值052.2)27(025,0 t,认为中国总量消费与支出以及与各滞后消费间线性相关性显著,并且解释变量间不存在多重共线性。





第九章 案例分析【案例7.1】 为了研究1955—1974年期间美国制造业库存量Y 和销售额X 的关系,用阿尔蒙法估计如下有限分布滞后模型:tt t t t t u X X X X Y +++++=---3322110ββββα将系数i β(i =0,1,2,3)用二次多项式近似,即00αβ=2101αααβ++=210242αααβ++=210393αααβ++=则原模型可变为t t t t t u Z Z Z Y ++++=221100αααα其中3212321132109432---------++=++=+++=t t t t t t t t t t t t t X X X Z X X X Z X X X X Z在Eviews 工作文件中输入X 和Y 的数据,在工作文件窗口中点击“Genr ”工具栏,出现对话框,输入生成变量Z 0t 的公式,点击“OK ”;类似,可生成Z 1t 、Z 2t 变量的数据。
进入Equation Specification 对话栏,键入回归方程形式Y C Z0 Z1 Z2点击“OK ”,显示回归结果(见表7.2)。
表7.2表中Z0、 Z1、Z2对应的系数分别为210ααα、、的估计值210ˆˆˆααα、、。
将它们代入分布滞后系数的阿尔蒙多项式中,可计算出3210ˆˆˆˆββββ、、、的估计值为:-0.522)432155.0(9902049.03661248.0ˆ9ˆ3ˆˆ0.736725)432155.0(4902049.02661248.0ˆ4ˆ2ˆˆ 1.131142)432155.0(902049.0661248.0ˆˆˆˆ661248.0ˆˆ21012101210100=-⨯+⨯+=++==-⨯+⨯+=++==-++=++===αααβαααβαααβαβ从而,分布滞后模型的最终估计式为:32155495.076178.015686.1630281.0419601.6----+++-=t t t t t X X X X Y在实际应用中,Eviews 提供了多项式分布滞后指令“PDL ”用于估计分布滞后模型。

第九章 滞后变量回归模型回归分析经常遇到时间序列资料,如果在回归模型中不仅含有解释变量X 的当前值而且含有X 的滞后值,它就称为分布滞后模型(Distributed-Lag Model),如t t t t t X X X Y εβββα++++=--221100(9.0.1)就是一个分布滞后模型。
如果模型中包含一个或若干个因变量的滞后值,它就称为自回归模型(Autoregressive Model),如t t t t Y X Y εγβα+++=-1(9.0.2)就是一个自回归模型。
分布滞后模型与自回归模型都属于滞后变量回归模型,它在经济领域有广泛的应用。
一个当前的经济指针,经常受到过去某些经济指针(包括自身的)影响,这是件很常见很容易理解的事情。
我们在处理这一类问题时要考虑下列问题:1.经济分析中滞后起什么作用? 2.滞后的原因是什么?3.在实证分析中对滞后有没有什么理论判别方法?4.自回归与分布滞后有什么关系?能否从一个导出另一个? 5.滞后变量模型中有哪一些统计问题?6.变量之间的滞后是否意味着灾难?如果是,如何度量它? 这些问题有些是不能给出精确定义或精确解答的,只可体会其意思。
我们以下主要是从经济模型的数学形式来展开讨论。
第一节 模型概念:消费滞后、通胀滞后与存款创生实际经济活动中,因变量Y 经常是与经济自变量的过去值有关,而与当前值有关反而少一些。
为了具体说明这种滞后关系,我们看一些实例。
1.消费滞后假如一个消费者从今年起每年工资增加2000元,并将持续一段时间。
他的消费行为将受到怎样的影响呢?一般来说,他不会把当年增加的收入全部花光。
很可能是,他把每增加的2000元当年花掉800元,第二年花掉600元,第三年花掉400元,余下的永久储蓄起来。
这样到第三年,他的消费增加额将是1800元。
这样的消费函数写下就是t t t t t X X X C Y ε++++=--212.03.04.0(9.1.1)这里Y 是消费开支,C 是常数,X 是收入。




一、数据选取某地区制造行业统计资料单位:亿元表1二、阿尔蒙法分布滞后期确定图中第一栏是y 与x 各滞后相关系数的可以看出,库存额与当年及前三年的销售额相关。
因此可以设:t t t t t u x b x b x b x b y +++++=---3322110α假定ib 可以由一个二次多项式逼近。
2.阿尔萌发估计模型直接求法 命令式T T T Z Z Z y 210545.0134.0261.19152ˆ-++-=2.方程式T T T Z Z Z y 210545.0134.0261.19152ˆ-++-=1071172.2996.0997.0115.3794.065.609.422====--F DW R R t还原后的分布滞后模型为:71.292.465.644.309.465.085.0261.15825.09152ˆ321---+++-=---tx x x x y t t t t 3.直接求模型X X(-2 ) X(-3)系数不过关。
概率不好对比上一个模型,系数检验不显著三、滞后期阿尔蒙模型调整:PDL(X,3,2)、PDL(X,4,2)、PDL(X,5,2)四期五期四期变为负的·不可取对比过后直接求的效果不如逼近好,最后选择滞后四期68.494.255.624.1122.709.49223.01917.08487.00488.17919.05.8401ˆ321---++++-=---tx x x x x y t t t t t四/阿尔蒙估计模型手工模拟过程1.做新变量Z0 ,Z1,Z2建立新序列2.回归方程115.341.244.309.4545.022.158.09152ˆ210---++-=tZ Z Z y t t t 1071,172.2,996.0,997.022====F DW R R 模型显著 3.返回原方程 设原估计方程为3322110ˆˆˆˆˆˆ---++++=t t t t x b x b x b x b y α由上一个方程有:=0ˆa0.58 =1ˆa 1.22 =2ˆa -0.545 根据almon 变换原理58.0ˆˆ00==a b265.1545.022.158.0ˆˆˆˆ2101=-+=++=a a a b 85.0ˆ4ˆ2ˆˆ2102=++=a a a b 65.0ˆ9ˆ3ˆˆ2103=++=a a a b 原模型32165.085.0265.158.09152ˆ---++++-=t t t t x x x x y五、不同权重的模型 1.建立不同权重变量Z3=x+(1/2)*x(-1)+(1/4)*x(-2)+(1/8)*x(-3)Z4=(1/4)*x+(1/2)*x(-1)+(2/3)*x(-2)+(1/4)x(-3) Z5=(1/4)*x+(1/4)*x(-1)+(1/4)*x(-2)+(1/4)*x(-3) Z6=(1/2)*x+(2/3)*x(-1)+(1/4)*x(-2)+(1/8)*x(-3) 2. 四个回归方程对比6379.178.10393ˆz y +-=302.1983453.1993.0994.053.4454.422====-F DW R R t321t 172.0345.092.0x 69.078.10393ˆ---++++-=t t t x x x y33.18302.1983453.1993.0994.022=====AIC F DW R R 通过对比选择第四个模型数据对比误差比阿尔蒙估计模型要大一些,所以最后选择阿尔蒙模型。
第九章 动态分布滞后模型在经济活动中,广泛存在着时间滞后效应,即动态性。
某些经济变量不仅受到同期各因素的影响,而且也受到过去某些时期的各种因素甚至自身的过去值的影响。
通常把这种过去时期的具有滞后作用的变量叫做滞后变量(lagged variable),含有滞后变量的模型称为滞后变量模型。
由于其考虑了时间因素的作用,使静态分析成为动态分析,故又称为动态模型(dynamic models )。
9.1 滞后变量模型9.1.1 滞后效应与产生滞后效应的原因一般说来被解释变量与解释变量的因果关系不一定就在瞬时发生,可能存在时间滞后,或者说解释变量的变化可能需要经过一段时间才能完全对被解释变量产生影响。
同样,被解释变量当前的变化也可能受其自身过去水平的影响,这种被解释变量受到自身或另一解释变量的前几期值影响的现象称为滞后效应,表示前几期值的变量称为滞后变量。
例如消费函数,本期消费除了受本期的收水平影响之外,还受前一期收入及前期消费水平的影响。
012131t t t t t C y y C u ββββ--=++++现实经济生活中,产生滞后效应的原因很多,主要有以下几个方面:1)经济变量自身原因。
有些变量的发展有很强的继往性,当期水平与前期水平有极为密切的关系。
例如,固定资产总量,不仅与期的固定资产投资有关,还与前期的投资有关。
2)心理原因。
由于 们固有的心理定势和行为习惯,其行为方式 往往滞后于经济形势的变化,如中彩票的人不可能很快改变其生活方式 。
因此,以往的行为延续产生的滞后效应。
3)技术原因。
在现实经济运行中,从生产到流通再到使用,每一个环节都需要一段时间,从而形成滞后期。
如当年的产在某种程度上依赖于过去若干期内投资形成的固定资产。
当年的家产吕产量主要取决于过去一年价格的高低,等待。
4)制度原因。
契约、管理制度等因素也会造成经济行为的滞后。
如定期存款到期才能提取,赞成了它对社会购买力的影响具有滞后性;过去的订货合同影响着当前产品的产量。
自回归分布滞后模型自回归分布滞后模型(ARIMA)是一种可用于自回归过程的统计建模技术。
它的主要优点是它能够使用时间序列数据预测未来或者检测和调整自回归过程中可能存在的性质变化。
ARIMA是一种重要的时间序列分析技术,它可以用来预测变量的自回归过程(AR),如动量(MA)和季节性过程(I)。
一、什么是自回归分布滞后模型(ARIMA)自回归分布滞后模型(ARIMA)是一种用于分析和预测时间序列数据的统计学方法。
ARIMA模型可以帮助研究者分析并预测事件的发生情况,以及由事件的发生情况产生的结果。
ARIMA模型的结构可以被定义为简单的一般线性二阶拟合模型。
二、ARIMA模型的有效性ARIMA模型通常证明是有效预测时间序列数据的一种有效方法。
无论是实现和应用于单变量和多变量时间序列上,ARIMA模型都可以为研究者提供可靠的预测结果。
在单变量的时间序列数据分析中,ARIMA 模型可以帮助研究者发现一些未知的趋势,从而判断该变量在未来的运动趋势。
三、ARIMA模型的应用ARIMA模型的应用,可以分为零度模型和非零度模型应用。
它们可以应用于单变量时间序列(零度模型)和多变量时间序列(非零度模型)上。
零度模型可以用来描述和预测单变量时间序列,而非零度模型可以用来描述和预测多变量时间序列中变量之间的关系。
此外,ARIMA模型还可以应用于时间序列平滑、广义线性模型、转换型自回归等领域。
四、ARIMA模型的优缺点ARIMA模型的优点是它能够有效地描述时间序列的差异性,可以使用时间序列数据预测未来或者检测已经发生的变化,进而找出时间序列中可能存在的自回归过程的特征,从而可以有效的预测和预测时间序列的发展趋势。
缺点是在使用自回归过程时,数据分析人员必须对变量进行较小的调整,以保持变量在ARIMA模型中是稳定的,而如果调整失败,将无法得到良好的分析结果。