统计学考研真题
- 格式:pdf
- 大小:63.12 KB
- 文档页数:2

10.在回归分析中,估计标准误差与相关系数的关系是()。
A估计标准误差越小,相关系数越大B估计标准误差越大,相关系数越大C估计标准误差越大,相关系数为1D估计标准误差为零,相关系数为零11.凡是变量值的连乘积等于总比率或总速度的现象,要计算其平均比率或平均速度适用的方法为()。
A算术平均B几何平均C调和平均D位置平均12.“统计”一词的三种涵义是()。
A统计调查、统计整理、统计分析B统计工作、统计资料、统计学C统计理论、统计方法、统计实践D统计信息、统计咨询、统计监督13.一个统计总体()。
A只能有一个指标B只能有一个标志C可以有多个指标D可以有多个标志14.抽样极限误差和抽样平均误差的关系()。
A抽样极限误差总是大于抽样平均误差B抽样极限误差总是小于抽样平均误差C抽样极限误差可以大于、小于或等于抽样平均误差D抽样极限误差总是等于抽样平均误差15.在500个抽样产品中,有95%的一级品,则在简单随机重复抽样下,一级品率的标准差为()。
A0.9645%B0.9747%C0.9573%D0.6827%16.随着样本单位数的无限增大,样本指标和未知的总体指标之差的绝对值小于任意小的正整数的可能性趋于必然性,称为抽样估计的()。
A无偏性B一致性C有效性D充足性17.下列指标中,属于时期指标的是()。
A某地区某年年中的人口总数B某银行某年年末居民储蓄存款余额C某地区某年秋季高校毕业生人数D某地区某年年末的粮食库存额18.抽样平均误差就是样本指标的()。
A标准差系数B平均差C标准差D平均数19.加权算术平均指数不属于()。
A平均指数B平均数指数C总指数D平均指标指数20.当时间数列的环比增长速度大体接近一个常数时,其趋势方程的形式()。
A直线B二次曲线C指数曲线D幂函数曲线21.若无季节变动,则各月(或各季)的季节比率为()。
A1B0C大于1D小于122.某银行2020年1—4月份居民储蓄存款的平均余额(单位:万元)分别为580,560,550,540,则第一季度居民储蓄存款的平均余额为()。
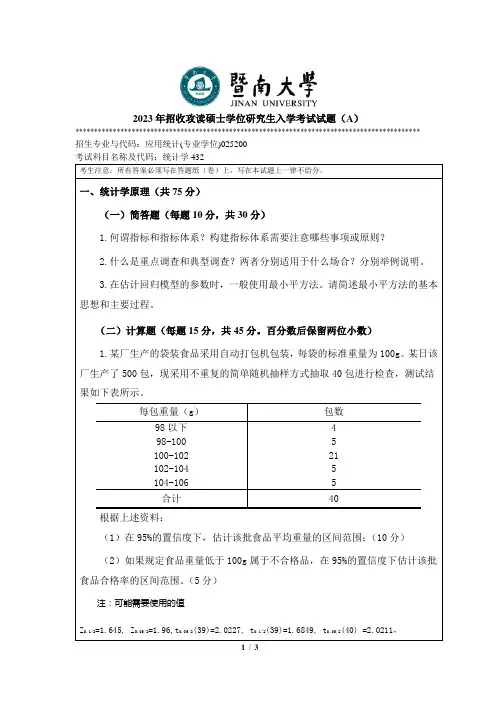
2023年招收攻读硕士学位研究生入学考试试题(A)********************************************************************************************招生专业与代码:应用统计(专业学位)025200考生注意:所有答案必须写在答题纸(卷)上,写在本试题上一律不给分。
一、统计学原理(共75分)(一)简答题(每题10分,共30分)1.何谓指标和指标体系?构建指标体系需要注意哪些事项或原则?2.什么是重点调查和典型调查?两者分别适用于什么场合?分别举例说明。
3.在估计回归模型的参数时,一般使用最小平方法。
请简述最小平方法的基本思想和主要过程。
(二)计算题(每题15分,共45分。
百分数后保留两位小数)1.某厂生产的袋装食品采用自动打包机包装,每袋的标准重量为100g。
某日该厂生产了500包,现采用不重复的简单随机抽样方式抽取40包进行检查,测试结果如下表所示。
每包重量(g)包数98以下 498-100 5100-102 21102-104 5104-106 5合计40根据上述资料:(1)在95%的置信度下,估计该批食品平均重量的区间范围;(10分)(2)如果规定食品重量低于100g属于不合格品,在95%的置信度下估计该批食品合格率的区间范围。
(5分)注:可能需要使用的值Z0.1/2=1.645, Z0.05/2=1.96,t0.05/2(39)=2.0227, t0.1/2(39)=1.6849, t0.05/2(40) =2.0211,二、概率论与数理统计部分(共4道大题,第1题15分,第2、3、4题各20分,合计75分)1. 设连续型随机变量X 的分布函数如下:F(x)=2/2,00,0xM Ne x x -⎧+≥⎪⎨<⎪⎩,(1)求常数M ,N ; (2)求(22)P X <<;(3)写出X 的密度函数f(x)。

心理统计学考研历年真题及答案心理统计学作为心理学考研中的重要科目,对于考生的逻辑思维和数据分析能力有着较高的要求。
通过研究历年真题,我们能够更好地把握考试的重点和命题规律,从而提高复习效率和考试成绩。
以下是为大家整理的部分心理统计学考研历年真题及答案。
一、选择题1、一组数据的均值为 50,标准差为 10。
现将每个数据都乘以 2,新数据的均值和标准差分别为()A 100,20B 100,10C 50,20D 50,10答案:A解析:当每个数据乘以 2 时,均值也乘以 2,即 50×2 = 100;标准差乘以数据变化的倍数,即 10×2 = 20。
2、对于正态分布,以下说法错误的是()A 正态分布曲线呈钟形B 正态分布的均值、中位数和众数相等C 正态分布的标准差越大,数据越分散D 正态分布的概率密度函数在正负无穷远处的值为 0答案:D解析:正态分布的概率密度函数在正负无穷远处的值趋近于 0,而不是为 0,D 选项错误。
3、进行独立样本 t 检验时,自由度为()A n 1B n1 + n2 1C n1 1 + n2 1D n1 1答案:C解析:独立样本t 检验的自由度为两组样本量分别减去1 之后相加,即 n1 1 + n2 1。
二、简答题1、简述标准分数的性质和用途。
答案:标准分数的性质包括:(1)平均数为 0,标准差为 1。
(2)标准分数的数值大小表明了原始分数在平均数之上或之下多少个标准差的位置。
(3)若原始分数呈正态分布,则转换得到的标准分数也呈正态分布。
标准分数的用途主要有:(1)比较不同测验分数的相对位置。
(2)对不同质的测验分数进行综合。
(3)确定个体在分布中的相对位置。
(4)比较不同单位的数据。
2、解释方差分析的基本思想。
答案:方差分析的基本思想是将观测数据的总变异分解为不同来源的变异。
具体来说,总变异可以分解为组间变异和组内变异。
组间变异反映了不同组之间的差异,组内变异反映了组内个体之间的差异。

统计学考研专业试题及答案一、选择题1. 在统计学中,描述数据集中趋势的度量是:A. 方差B. 标准差C. 均值D. 众数答案:C2. 以下哪个是正态分布的特点?A. 均值等于中位数B. 均值等于众数C. 均值小于中位数D. 均值大于众数答案:A3. 以下哪个统计量不是度量数据离散程度的?A. 方差B. 标准差C. 均值D. 四分位数间距答案:C二、填空题4. 假设检验中的两类错误是________和________。
答案:第一类错误;第二类错误5. 样本均值的抽样分布服从正态分布的条件是样本容量足够大,即n≥______。
答案:30三、简答题6. 请简述中心极限定理的内容。
答案:中心极限定理指出,即使原始总体分布不是正态分布,只要样本容量足够大,样本均值的分布将趋近于正态分布。
7. 描述性统计和推断性统计的区别是什么?答案:描述性统计主要关注数据的收集、组织、描述和展示,以提供对数据集的直观理解。
推断性统计则利用样本数据来推断总体的特征,包括参数估计和假设检验。
四、计算题8. 假设有一个总体均值为μ=100,标准差为σ=15。
从这个总体中随机抽取一个样本容量为n=36的样本,样本均值为x̄=102。
请计算并判断样本均值是否显著不同于总体均值。
答案:首先计算样本标准误差(SE),SE = σ/√n = 15/√36 =2.5。
然后计算z值,z = (x̄ - μ)/SE = (102 - 100)/2.5 = 0.8。
由于z值在标准正态分布的临界值范围内(例如,对于α=0.05,z临界值为±1.96),我们不能拒绝原假设,即样本均值不显著不同于总体均值。
五、论述题9. 论述总体参数估计的两种方法:点估计和区间估计,并给出它们的区别。
答案:点估计是指用样本统计量来估计总体参数的单个值。
它提供了一个具体的数值作为总体参数的估计。
而区间估计则提供了一个范围,在这个范围内总体参数有一定的置信水平(如95%)被认为包含在内。

统计学考研试题及答案一、单项选择题(每题2分,共10分)1. 在统计学中,总体是指()A. 研究对象的全体B. 研究对象的一部分C. 研究对象的样本D. 研究对象的统计量2. 下列哪项不是描述性统计的内容?()A. 数据的收集B. 数据的分类C. 数据的图表展示D. 相关性的度量3. 抽样误差是指()A. 抽样中的随机误差B. 抽样中的系统误差C. 统计量的抽样分布的期望D. 统计量的抽样分布的标准差4. 在回归分析中,如果自变量和因变量的关系是线性的,那么这种关系被称为()A. 正相关B. 负相关C. 线性回归D. 非线性回归5. 下列哪项是统计学中常用的离散程度的度量?()A. 均值B. 方差C. 标准差D. 众数二、简答题(每题5分,共20分)1. 简述统计学中的参数估计和假设检验的区别。
2. 描述统计学中常用的几种概率分布,并说明它们的应用场景。
3. 解释什么是标准正态分布,并说明其在统计学中的重要性。
4. 简述方差分析的基本原理及其在实际研究中的应用。
三、计算题(每题10分,共30分)1. 某工厂生产的产品,其长度服从正态分布N(12, 0.5^2)。
求:(1) 长度小于11.5的产品所占的比例;(2) 长度在11.8到12.2之间的产品所占的比例;(3) 平均每天生产1000个产品,求长度小于11.5的产品数量的期望值。
2. 已知两组数据,第一组数据的平均数为50,标准差为10,样本容量为100;第二组数据的平均数为60,标准差为15,样本容量为200。
请计算两组数据的合并平均数,并说明合并平均数的意义。
3. 某研究者想要测试一种新药对高血压患者血压的影响。
在实验前,他测量了50名患者的平均血压为150mmHg,标准差为20mmHg。
实验后,这50名患者的平均血压降低到了140mmHg。
请问这个结果是否具有统计学意义?(α=0.05)四、论述题(每题15分,共30分)1. 论述统计学在社会经济数据分析中的作用和重要性。

统计学考研真题精选12(总分:200.00,做题时间:150分钟)一、单项选择题(总题数:15,分数:15.00)1.多元线性回归模型中修正的判定系数()。
(分数:1.00)A.大于等于0,小于等于1B.大于等于-1,小于等于1C.可能出现负值√D.可能大于1解析:修正的判定系数是用样本量n和自变量的个数k去调整R2,计算出调整的多重判定系数记为R2,其计算公式为R2数值比较小,而模型包含的自变量数目较多时,即在回归方程拟合得极差时,其值可能出现负值。
2.在多元线性回归分析中,F检验时的F值越大,则意味着()。
(分数:1.00)A.随机误差的影响越大B.相关系数的值越小C.至少有一个自变量与因变量之间的线性关系越显著√D.所有自变量与因变量之间的线性关系越显著解析:在多元线性回归中,F检验用来进行总体显著性检验,即检验因变量y与k个自变量之间的关系是否显著。
F值越大,表明检验越显著,即k个自变量与因变量之间的线性关系越显著,复相关系数的值越大,但无法判断是由一个还是多个自变量引起。
1.00)A.t(n-k-1) √B.t(n-k-2)C.t(n-k+1)D.t(n-k+2)解析:在多元回归方程的系数检验时,统计量,的抽样分布的标准差,k为回归方程中自变量的个数。
4.多元线性回归分析中,如果F检验表明线性关系显著,则意味着()。
(分数:1.00)A.至少有一个自变量与因变量之间的线性关系显著√B.所有的自变量与因变量之间的线性关系都显著C.至少有一个自变量与因变量之间的线性关系不显著D.所有的自变量与因变量之间的线性关系都不显著解析:线性关系F检验主要是检验因变量同多个自变量的线性关系是否显著,在k个自变量中,只要有一个自变量与因变量的线性关系显著,F检验就能通过,但这不一定意味着每个自变量与因变量的关系都显著。
5.在模型Y i=β1+β2X2t+β3X3t+µ1的回归分析结果中,F=263489,对应的P =0.000,则表明()。
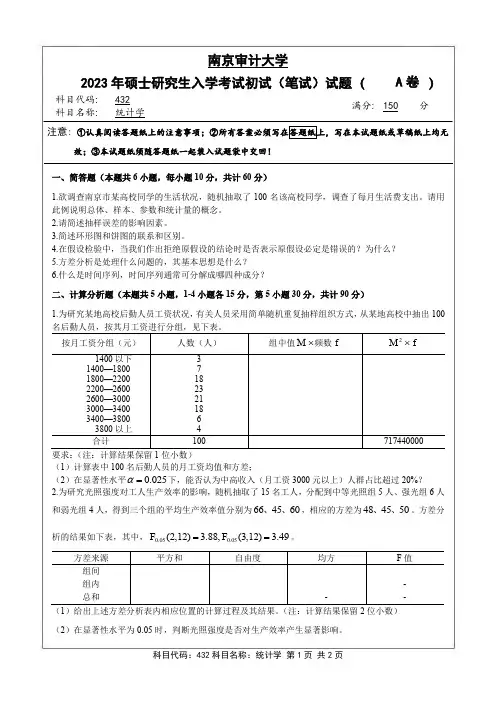
南京审计大学2023年硕士研究生入学考试初试(笔试)试题(A 卷 )科目代码: 432 满分: 150分科目名称:统计学注意: ①认真阅读答题纸上的注意事项;②所有答案必须写在答题纸上,写在本试题纸或草稿纸上均无效;③本试题纸须随答题纸一起装入试题袋中交回!一、简答题(本题共6小题,每小题10分,共计60分)1.欲调查南京市某高校同学的生活状况,随机抽取了100名该高校同学,调查了每月生活费支出。
请用此例说明总体、样本、参数和统计量的概念。
2.请简述抽样误差的影响因素。
3.简述环形图和饼图的联系和区别。
4.在假设检验中,当我们作出拒绝原假设的结论时是否表示原假设必定是错误的?为什么?5.方差分析是处理什么问题的,其基本思想是什么?6.什么是时间序列,时间序列通常可分解成哪四种成分?二、计算分析题(本题共5小题,1-4小题各15分,第5小题30分,共计90分)1.为研究某地高校后勤人员工资状况,有关人员采用简单随机重复抽样组织方式,从某地高校中抽出100按月工资分组(元)人数(人)组中值M ⨯频数f2M f ⨯1400以下 1400—1800 1800—2200 2200—2600 2600—3000 3000—3400 3400—3800 3800以上 3 7 18 23 21 18 6 4 合计100717440000要求:(注:计算结果保留1位小数)(1)计算表中100名后勤人员的月工资均值和方差;(2)在显著性水平0.025α=下,能否认为中高收入(月工资3000元以上)人群占比超过20%? 2.为研究光照强度对工人生产效率的影响,随机抽取了15名工人,分配到中等光照组5人、强光组6人和弱光组4人,得到三个组的平均生产效率值分别为664560、、,相应的方差为484550、、。
方差分析的结果如下表,其中,0.050.05(2,12) 3.88,(3,12) 3.49F F ==。
方差来源 平方和 自由度 均方 F 值 组间 组内 - 总和--(1)给出上述方差分析表内相应位置的计算过程及其结果。

统计学考研真题精选2(总分:100.00,做题时间:120分钟)一、单项选择题(总题数:30,分数:30.00)1.按照随机性原则,从研究现象的总体中抽取出一部分单位进行调查,从数量上对总体进行推断,这种调查方式是()。
(分数:1.00)A.重点调查B.典型调查C.统计报表D.抽样调查√解析:重点调查和典型调查属于非概率调查,不需要注重随机性;抽样调查是按照随机原则,从调查总体中抽取部分调查单位进行观察,并根据这一部分调查单位的观察结果,从数量方面推断总体指标的一种非全面调查。
2.为了调查某校学生的购书费用支出,将全校学生的名单按拼音顺序排列后,每隔50名学生抽取一名学生进行调查,这种调查方法是()。
(分数:1.00)A.简单随机抽样B.整群抽样C.系统抽样√D.分层抽样解析:系统抽样是将总体中的所有单位(抽样单位)按一定顺序排列,在规定的范围内随机地抽取一个单位作为初始单位,然后按事先规定好的规则确定其他样本单位。
所以将学生排序后,每隔50名学生抽一名进行调查,属于系统抽样。
3.为了解大学生的消费状况,调查员在食堂门口任意拦截100名学生进行了问卷调查。
关于这种调查方式,以下说法正确的是()。
(分数:1.00)A.这是分层抽样B.这是方便抽样√C.这是简单随机抽样D.这是配额抽样解析:方便抽样是调查过程中由调查员依据方便的原则,自行确定入样单位的非概率抽样方法。
例如,调查员在街头、公园、商店等公共场所进行拦截式的调查;厂家在出售产品的柜台前对路过的顾客进行调查,等等。
4.在检验人的血压与年龄之间是否有某种近似的线性关系,对0〜20, 20 ~30, 30 ~40, 40〜50, 50 ~60及60岁以上的人进行随机抽样检测,该抽样方法属于()。
(分数:1.00)A.简单抽样B.分层抽样C.系统抽样√D.整群抽样解析:分层抽样是将抽样单位按某种特征或某种规则划分为不同的层,然后从不同的层中独立、随机地抽取样本,再将各层的样本结合起来,对总体的目标量进行估计的抽样方法。

华中农业大学2021年《统计学》考研真题一、单项选择题1、缺2.设A,B为两事件且P(AB)=0,则().A.A与B互不相容B.AB是不可能事件C.AB未必是不可能事件D.P(A)=0或P(B)=03.缺4.设随机变量X、Y相互独立,其概率分布如下表,则下列正确的是().5.设(X,Y)服从二维正态分布,随机变量巳=X+Y,η=X-Y,则已与η不相关的充分必要条件是().A.EX=EYB.DX=DYC.E(X2)=E(Y2)D.E(X2)+(EX)2=E(Y2)+(EY)26.t分布比标准正态分布().A.中心位置左移,但分布曲线相同B.中心位置右移,但分布曲线相同C.中心位置不变,但分布曲线峰高D.中心位置不变,但分布曲线峰低,两侧较伸展7.如果由某一次数分布计算得SK=O,则该次数分布为〈).A.对称分布B.正偏态分布C.负偏态分布D.低阔峰分布8.一个好的估计量应具备的特点是().A.充分性、必要性、无偏性、一致性B.充分性、无偏性、一致性、有效性c.必要性、无偏性、一致性、有效性D.充分性、无偏性、一致性、有效性9.三位研究者评价人们对四种速食面品牌的喜好程度。
研究者甲让评定者先挑出最喜欢的品牌,然后挑出剩下三种品牌中最喜欢的,最后再挑出剩下两种品牌中比较喜欢的。
研究者乙让评定者将四种品牌分别给予1-5的等级评定,Cl表示非常不喜欢,5表示非常喜欢〉,研究者丙只是让评定者挑出自己最喜欢的品牌。
研究者甲、乙、丙所使用的数据类型分别是().A.类目型一顺序型一计数型B.顺序型一等距型一类目型c.顺序型一等距型一类目型D.顺序型一等比型一计数型10.有一个64名学生的班级,语文历年考试成绩的σ=5,又知今年期中考试平均成绩是85分,如果按95%的概率推测,那么该班语文学习的真实成绩可能为().A.83B.86C.87D.8811.已知X和Y的相关系数r1是0.38,在0.05的水平上显著,A与B的相关系数r2是0.18,在0.05的水平上不显著,那么().A.r1与n在0.05水平上差异显著B.r1与r2在统计上肯定有显著差异C.无法推知r1与r2在统计上差异是否显著D.r1与r2在统计上不存在显著差异12.为调查某高校教师的收入情况,从教授、副教授、讲师和助教中依次抽取若干人进行分析,这种抽样方法属于().A.简单随机抽样B.分层抽样 c.系统抽样D.整群抽样13.下面选项中不是方差分析的前提条件是().A.总体正态且相关c.总体正态且相互独立B.总体正态D.各实验处理内的方差要一致14.若采用有放回的等概率抽样,如果样本容量增加4倍,则样本均值抽样分布的标准差将〈〉.A.不受影响B.为原来的4倍c.为原来的ν4D.为原来的1/215.特别适用于描述具有百分比结构的分类数据的统计分析图().A.散点图B.圆形图C.条形图D.线形图16.一位教授计算了全班20个同学考试成绩的均值、中数和众数,发现大部分同学的考试成绩集中于高分段。

统计学考研专业试题及答案一、单项选择题(每题2分,共20分)1. 下列哪项不是描述性统计学的主要功能?A. 计算数据的均值B. 数据的分类C. 数据的图形表示D. 推断总体参数答案:D2. 在总体中随机抽取一个样本,样本容量为n,总体方差为σ²,样本均值为x̄,若要进行假设检验,以下哪个是正确的零假设形式?A. μ = σ²B. μ ≠ σ²C. μ = x̄D. μ ≠ x̄答案:C3. 以下哪个统计量是度量数据集中趋势的?A. 方差B. 标准差C. 众数D. 极差答案:C4. 在回归分析中,如果自变量X增加一个单位,因变量Y预期将增加多少,这是指的哪个统计量?A. 相关系数B. 回归系数C. 决定系数D. 标准误差答案:B5. 下列哪项不是统计学中常见的概率分布?A. 正态分布B. 二项分布C. 泊松分布D. 均匀分布答案:D6. 一个随机变量X服从二项分布B(n, p),若要求X的方差,以下哪个公式是正确的?A. Var(X) = np(1-p)B. Var(X) = npC. Var(X) = np/pD. Var(X) = n/p答案:A7. 在统计学中,为了减少抽样误差,通常采用哪种方法?A. 增加样本容量B. 减少样本容量C. 只选择特定群体D. 随机抽样答案:A8. 下列哪项是时间序列分析的主要目的?A. 预测未来趋势B. 分析变量间的关系C. 确定因果关系D. 描述数据分布答案:A9. 在统计学中,如果两个变量的相关系数为0,这意味着什么?A. 两个变量之间存在线性关系B. 两个变量之间不存在线性关系C. 两个变量之间一定存在非线性关系D. 两个变量之间一定没有关系答案:B10. 下列哪项是统计学中的抽样误差?A. 抽样过程中的随机误差B. 样本选择的偏差C. 测量过程中的错误D. 抽样过程中的系统误差答案:A二、简答题(每题10分,共20分)11. 简述统计学中的中心极限定理,并说明其在实际应用中的意义。

考研统计学试题及答案一、单项选择题(每题2分,共20分)1. 下列哪项不是描述性统计学的研究内容?A. 数据收集B. 数据分析C. 数据解释D. 数据预测答案:D2. 在统计学中,总体是指什么?A. 研究对象的全体B. 研究对象的一部分C. 研究对象的样本D. 研究对象的统计量答案:A3. 以下哪个统计量是衡量数据集中趋势的?A. 方差B. 标准差C. 平均数D. 极差答案:C4. 一个变量的方差越小,说明该变量的什么特性越强?A. 波动性B. 稳定性C. 相关性D. 独立性答案:B5. 以下哪项是统计推断的内容?A. 求样本均值B. 求样本方差C. 根据样本数据推断总体特征D. 根据总体数据推断样本特征答案:C二、简答题(每题10分,共20分)1. 简述正态分布的特点。
答案:正态分布是一种连续概率分布,具有以下特点:- 钟形曲线,关于均值对称;- 均值、中位数和众数相等;- 大多数数据集中在均值附近,分布的尾部延伸至无穷;- 曲线下面积总和为1;- 标准差越大,曲线越平坦,数据分布越分散;- 标准差越小,曲线越陡峭,数据分布越集中。
2. 什么是置信区间?它在统计推断中有什么作用?答案:置信区间是指在一定置信水平下,用于估计总体参数的上下限范围。
它在统计推断中的作用是:- 提供对总体参数的估计;- 给出估计的精确度,即置信水平;- 用于假设检验,比较不同总体或样本间的差异;- 帮助研究者做出决策,如市场分析、政策制定等。
三、计算题(每题15分,共30分)1. 某工厂生产的产品中,次品率为3%。
假设从这批产品中随机抽取100件进行检查,请问:- (1) 计算至少有3件次品的概率。
- (2) 如果希望没有次品的概率超过0.95,至少需要抽取多少件产品?答案:- (1) 至少有3件次品的概率可以通过计算没有次品和只有1件次品的概率,然后用1减去这个概率来得到。
- 没有次品的概率:P(X=0) = C(100,0) * (0.97)^100 *(0.03)^0- 只有1件次品的概率:P(X=1) = C(100,1) * (0.97)^99 * (0.03)^1- 至少有3件次品的概率:P(X≥3) = 1 - P(X=0) - P(X=1)- (2) 使用二项分布的累积分布函数(CDF)来解决这个问题。
统计学考研科目试题及答案一、单项选择题(每题2分,共10分)1. 在总体分布未知的情况下,进行假设检验时,常用的统计量是()。
A. 方差B. Z统计量C. t统计量D. 卡方统计量2. 下列哪项不是描述性统计的研究内容?()A. 数据的收集B. 数据的图表展示C. 数据的数学期望D. 数据的分布形态3. 某工厂生产的产品中,次品率为0.01。
若随机抽取3件产品进行检测,使用二项分布来描述这一过程,下列哪项是错误的?()A. 试验是独立的B. 每次试验发生的概率相同C. 试验次数为3D. 每次试验是重复的4. 在回归分析中,如果自变量和因变量不相关,那么回归系数为()。
A. 0B. 1C. 无法确定D. 一个非零的值5. 下列哪项不是方差分析的步骤?()A. 建立假设B. 计算检验统计量C. 确定显著性水平D. 进行相关性分析二、简答题(每题10分,共20分)6. 请简述样本均值和总体均值的区别。
7. 请解释什么是标准正态分布,并说明其特点。
三、计算题(每题15分,共30分)8. 某地区对100名成年人进行了血压测量,得到的平均血压为120mmHg,标准差为15mmHg。
请问在95%的置信水平下,该地区成年人平均血压的置信区间是多少?9. 某公司想要评估其新生产线的效率。
通过对旧生产线和新生产线生产的产品进行质量检测,得到以下数据:旧生产线生产的100个产品中有10个不合格,新生产线生产的150个产品中有8个不合格。
请问在5%的显著性水平下,新生产线的生产效率是否显著高于旧生产线?四、论述题(每题20分,共20分)10. 论述在实际应用中,如何选择合适的统计图表来展示数据。
统计学考研科目试题答案一、单项选择题1. C2. C3. D4. A5. D二、简答题6. 样本均值是指从总体中抽取的样本数据的算术平均数,它用于估计总体均值,但本身是一个随机变量,可能存在抽样误差。
总体均值是指总体所有数据的算术平均数,是一个固定的未知值,通常我们无法直接得知总体均值,而是通过样本均值来估计。
统计学考研初试题及答案一、单项选择题(每题2分,共20分)1. 下列哪项是描述数据集中趋势的统计量?A. 方差B. 标准差C. 平均数D. 中位数答案:C2. 总体参数与样本统计量之间的区别在于:A. 总体参数是固定的,样本统计量是变化的B. 总体参数是变化的,样本统计量是固定的C. 两者都是固定的D. 两者都是变化的答案:A3. 在统计学中,以下哪种分布是描述二项分布的?A. 正态分布B. t分布C. 泊松分布D. F分布答案:A4. 以下哪种方法用于估计总体均值?A. 回归分析B. 假设检验C. 置信区间D. 方差分析5. 以下哪种图形用于展示变量之间的关系?A. 直方图B. 散点图C. 箱线图D. 饼图答案:B6. 统计学中的“误差”通常指的是:A. 测量误差B. 抽样误差C. 系统误差D. 所有上述选项答案:D7. 以下哪个不是描述离散程度的统计量?A. 方差B. 标准差C. 平均数D. 极差答案:C8. 以下哪种方法用于确定两个变量之间是否存在关系?A. 相关系数B. 回归分析C. 假设检验D. 所有上述选项答案:D9. 在统计学中,以下哪种分布用于描述正态分布的样本均值?B. F分布C. 正态分布D. 卡方分布答案:A10. 以下哪种检验用于确定两个独立样本的均值是否存在显著差异?A. t检验B. 卡方检验C. 相关性检验D. 方差分析答案:A二、多项选择题(每题3分,共15分)1. 下列哪些是描述数据分布形状的统计量?A. 偏度B. 峰度C. 标准差D. 方差答案:A B2. 在统计分析中,以下哪些方法可以用于预测未来值?A. 回归分析B. 时间序列分析C. 假设检验D. 描述性统计答案:A B3. 以下哪些是统计学中的抽样方法?A. 简单随机抽样B. 系统抽样C. 分层抽样D. 整群抽样答案:A B C D4. 以下哪些是统计学中的非参数检验?A. 卡方检验B. 曼-惠特尼U检验C. 克鲁斯卡尔-瓦利斯检验D. 斯皮尔曼等级相关系数答案:B C D5. 下列哪些是数据收集的方法?A. 观察法B. 实验法C. 调查法D. 文献法答案:A B C三、简答题(每题5分,共20分)1. 简述什么是中心极限定理,并说明其在统计学中的应用。
统计学考研真题精选6(总分:120.00,做题时间:150分钟)一、单项选择题(总题数:27,分数:27.00)1.在抽样推断中,样本统计量是( )(分数:1.00)A.未知但确定的量B.—个已知的量C.随机变量√D.唯一的解析:统计量是用来描述样本特征的概括性数字度量。
它是根据样本数据计算出来的一个量,由于抽样是随机的,因此统计量是样本的函数,是随机变量。
2.在一个饭店门口等待出租车的时间是左偏的,均值为12分钟,标准差为3分钟。
如果从饭店门口随机抽取100名顾客并记录他们等待出租车的时间,则该样本均值的分布服从 ( )。
(分数:1.00)A.正态分布,均值为12分钟,标准差为0.3分钟√B.正态分布,均值为12分钟,标准差为3分钟C.左偏分布,均值为12分钟,标准差为3分钟D.左偏分布,均值为12分钟,标准差为0.3分钟解析:中心极限定理:设从均值为µ、方差为(有限)的任意一个总体中抽取样本量为n的样本,当n充分大(通常是大于36)时,样本均值文的抽样分布近似服从均值为µ、的正态分布。
故即使总体是左偏分布,该样本均值仍服从正态分布,其均值为 12,标准差为3/10 =0.3。
3.设总体是来自总体X)。
(分数:1.00)A.t(15)B.t(16)C.X2(15)D.N(0,1) √4.1000名学生参加某课程的考试,平均成绩是82分,标准差是8分,从学生中随机抽取100个同学作为样本,则样本均值的数学期望和抽样分布的标准差分别为()。
(分数:1.00)A.82, 8B.82, 0.8 √C.82, 64D.86,1解析:由中心极限定理得,在大样本条件下,样本均值无的抽样分布近似服从均值为µ的正态分布。
故该样本均值的数学期望为82,标准差为8/10 =0.8。
5.某批产品的合格率为90%,从中抽出n= 100的简单随机样本,以样本合格率估计总体合格率P,的期望值和标准差分别为()。
统计学考研真题精选11(总分:300.00,做题时间:150分钟)一、单项选择题(总题数:28,分数:28.00)1.对于线性回归模型为了进行统计推断,通常假定模型中各随机误差项的方差( )。
(分数:1.00)A.均等于0B.均相等√C.不相等D.均不为0解析:线性回归模型对随机误差项的假定为:随机误差项ε的期望值为0;对于所有的x值ε的方差σ2都相等;ε是一个服从正态分布的随机变量且各随机误差项之间相互独立,即ε~N(0,σ2)2.在线性回归分析中,残差平方和SSE相对总平方和SST越小意味着()。
(分数:1.00)A.线性关系越不显著B.随机误差产生的影响相对越小,模型越有效√C.线性关系之外的其他因素的影响相对越大D.统计软件中的F值越小解析:在线性回归分析中,残差平方和SSE相对总平方和SST越小,则回归平方和 SSR相对总平方和越大,F检验统计量的值越大;从而线性关系越显著,线性关系之外的其他因素(随机误差等)产生的影响相对越小,故模型也越有效。
3.回归分析中的估计标准误差()。
(分数:1.00)A.可以是负值B.等于因变量的平方根C.是根据残差平方和计算的√D.等于自变量的平方根解析:回归分析中的估计标准误差是度量各实际观测点在直线周围的散布状况的一个统计量,它是均方残差(MSE)的平方根,用s e来表示,其计算公式为:4.产量(X,台)与单位产品成本(Y,元/释合理的是()。
(分数:1.00)A.产量每增加一台,单位产品成本增加248元B.产量每增加一台,单位产品成本减少2. 6元C.产量每增加一台,单位产品成本平均增加245. 4元D.产量每增加一台,单位产品成本平均减少2. 6元√解析:一元线性回归方程的形式为:E(y)=β0+β1x其中A是直线的斜率,它表示当x每变动一个单位时,y的平均变动值。
题中,回归方程的回归系数为-2.6,表示产量每增加一台,单位产品成本平均减少2. 6元。
2012年统计学考研真题
统计学考研题目去年的真题有两道题朝纲了后来老师说他都不知道有考纲这一回事,所以今年应该是要严格按照大纲来出
(一)五道问答题
1.两地区的什么比例(好像是收入的均值吧),运用t检验得出p值为0.132,据此能否得出这两个地区的均值相等的结论?
【分析】首先从前提假设来看,题目中没有给出假设条件,如果用t检验的话,需要的假设条件有
1、两个总体正态分布
2、总体方差未知
3、两个总体的样本独立抽取(否则为匹配样本)
4、小样本(n<30)
5、每一个总体样本内部也相互独立(否则为有限总体情况)
题目中除了假设条件没有以外,还缺少为判断标准的显著水平a,如果a>0.132则还是要拒绝原假设的。
如果还要写可以加上原假设未写明。
2.在参数统计中,卡方分布有哪些应用,并举例说明
【分析】在参数统计中,卡方分布有
时序:检验白噪声的lb统计量、q统计量
检验异方差相关性的Q统计量、lm统计量
GARCH模型六部最后一步检验正态性的偏度峰度服从自由度为2的开放分布;
多元:wills统计量(就是多元中的F统计量)当不满足n、p的情况时就为卡方分布。
典型相关分析中检验典型相关系数的卡方分布。
多元中两个总体均值的假设检验,只要两个总体中最小的总体的数目趋于无穷则也服从卡方分布。
统计学:单个总体的方差假设检验或者是参数估计也服从卡方分布。
(有人说还有列联分析中拟合优度和独立性检验,不过我认为列联分析根本就不属于参数统计,列联分析是非参数统计的内容,所以这两个不能写入,其实多元中还有一个和马氏距离非常相似的公式也服从卡方分布,但是这台机子上没法打出符号,就请各位童鞋自己注意一下)
3.贝叶斯统计与经典统计的区别
【分析】贝叶斯统计的思想是假如对某一个总体有一定的了解,那么用先验分布来描述这种认识,然后从总体中抽取样本,用样本来修正这种认识得到后验分布,以后的推断通过都通过后验分布进行。
经典统计分描述统计和推断统计,其中描述统计是将数据通过图表进行分析,而推断统计则是直接通过样本来描述总体,并未涉及先验分布。
4.时间序列的弱平稳的含义
【分析】这个题目书上有,就不写了。
5.对于多元回归中的多重共线性的解决方法加以评价
【分析】这个题目书上也有明确的答案,但是要注意多重共线性解决方法中——剔除不重要的变量,要注意使用VIF而不要用特征根因为在特征值都很小的情况下,即使特征根不大也包含多重共线性,而且在使用这个方法的时候要注明,要和分析数据专业上的意义相结合共同决定一个变量是否剔除。
还有在有偏估计中主成分法对多重共线性的解决无能为力。
(二)给出三个运动员10次射击的数据,问哪些统计图图可以表示这些数据,及这些图的适用场合和特点。
用哪些统计量综合分析三个运动员的表现,这些统计量各有什么特点。
(15分)【分析】这个题还是写一下思路吧,因为这个数据时定量数据,所以一些定性和定序数据的分析方法可以应用其中,比如条形图,帕累托图,对比条形图、环形图。
由于数据不是分组数据,所以可以用茎叶图和箱线图进行分析。
统计量方面,应该有众数、中位数、方差、标准差、极差等等。