编译原理 第十章 代码优化
- 格式:doc
- 大小:175.50 KB
- 文档页数:9








第十章代码优化某些编译程序在中间代码或目标代码生成之后要对生成的代码进行优化。
所谓优化,实质上是对代码进行等价变换,使得变换后的代码运行结果与变换前代码运行结果相同,而运行速度加大或占用存储空间少,或两者都有。
优化可在编译的不同阶段进行,对同一阶段,涉及的程序范围也不同,在同一范围内,可进行多种优化。
一般,优化工作阶段可在中间代码生成之后和(或)目标代码生成之后进行。
中间代码的优化是对中间代码进行等价变换。
目标代码的优化是在目标代码生成之后进行的,因为生成的目标代码对应于具体的计算机,因此,这一类优化在很大程度上依赖于具体的机器,我们不做详细讨论。
另外依据优化所涉及的程序范围,又可分为局部优化、循环优化和全局优化三个不同的级别。
局部优化指的是在只有一个入口、一个出口的基本程序块上进行的优化。
循环优化对循环中的代码进行的优化。
全局优化是在整个程序范围内进行的优化。
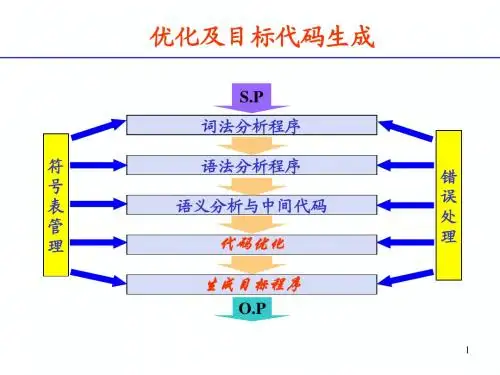
本章重点:局部优化基本块的DAG表示第一节优化技术简介为了说明问题,我们来看下面这个例子,源程序是:P :=0For I :=1 to 20 doP :=P+A[I]*B[I];经过编译得到的中间代码如图10-1-1所示,这个程序段由B1和B2两个部分组成,B2是一个循环,假定机器按字节编址。
那么,对于这个中间代码段,可进行如下这些优化。
1、删除多余运算(删除公共子表达式)优化的目的在于使目标代码执行速度较快。
图10-1-1中间代码(3)和(6)中都有4*I的运算,而从(3)到(6)没有对I赋值,显然,两次计算机的值是相等的。
所以,(6)的运算是多余的。
我们可以把(6)变换成:T4 :=T1。
这种优化称为删除多余运算或称为删除公共子表达式。
2、代码外提减少循环中代码总数的一个重要办法是代码外提。
这种变换把循环不变运算,即其结果独立于循环执行次数的表达式,提到循环的前面。
使之只在循环外计算一次,上例中,我们可以把(4)和(7)提到循环外。
经过删除多余运算和代码外提后,代码变成图10-1-2。


1.与机器有关的代码优化有那些种类,请分别举例说明。
解答:与机器有关的优化有:寄存器优化,多处理优化,特殊的指令优化,无用的指令消除等四类。
冗余指令删除假设源程序指令序列a:=b+c; c:=a-d;编译程序为其生成的代码很可能是下列指令序列:MOV b, R0ADD c, R0MOV R0,aSUB d, R0MOV R0,c假如第四条指令没有标号,上述两个赋值语句在一个基本块内,则第四条指令是多余的,可删除。
特殊指令的使用例如,如果目标机器指令系统包含增1指令INC,对于i:=i+1的目标代码MOV i, R0ADD #1, R0MOV R0, i便可被代之以1条指令Inc i说明:优化的特点是每个改进可能会引发新的改进机会,为了得到最好的改进,一般可能需要对目标代码重复扫描进行优化。
2.设有语句序列a:=20b:=a*(a+10);c:=a*b;试写出合并常量后的三元式序列。
解答:该语句序列对应的三元式序列为:(1)(:=, 20,a)(2)(+, a, 10)(3)(*, a, (2) )(4)(:=, a, b)(5)(* a, b)(6)(:=, (5), c)合并常量后的三元式序列为:(1)(:=, 20,a)(2)(:=, 600, b)(3)(:=, 12000, c)3、试写出算术表达式a+b*c-(c*b+a-e)/(b*c+d)优化后的四元式序列。
解答:该表达式的四元式序列为:(1)(*,b,c,T1)(2)(+,a,T1,T2)(3)(*,c,b,T3)(4)(+,T3,a,T4)(5)(-,T4,e,T5)(6)(*,b,c,T6)(7)(+,T6,d,T7)(8)(/,T5,T7,T8)(9)(-,T2,T8,T9)可对该表达式进行删除公共子表达式的优化。
优化后的四元式序列为:(1)(*,b,c,T1)(2)(+,a,T1,T2)(3)(-,T2,e,T5)(4)(+,T1,d,T7)(5)(/,T5,T7,T8)(6)(-,T2,T8,T9)4.设有算术表示式(a*b+c)/(a*b-c)+(c*b+a-d)/(a*b+c)试给出其优化后的三元式序列。
第十章代码优化某些编译程序在中间代码或目标代码生成之后要对生成的代码进行优化。
所谓优化,实质上是对代码进行等价变换,使得变换后的代码运行结果与变换前代码运行结果相同,而运行速度加大或占用存储空间少,或两者都有。
优化可在编译的不同阶段进行,对同一阶段,涉及的程序范围也不同,在同一范围内,可进行多种优化。
一般,优化工作阶段可在中间代码生成之后和(或)目标代码生成之后进行。
中间代码的优化是对中间代码进行等价变换。
目标代码的优化是在目标代码生成之后进行的,因为生成的目标代码对应于具体的计算机,因此,这一类优化在很大程度上依赖于具体的机器,我们不做详细讨论。
另外依据优化所涉及的程序范围,又可分为局部优化、循环优化和全局优化三个不同的级别。
局部优化指的是在只有一个入口、一个出口的基本程序块上进行的优化。
循环优化对循环中的代码进行的优化。
全局优化是在整个程序范围内进行的优化。
本章重点:局部优化基本块的DAG表示第一节优化技术简介为了说明问题,我们来看下面这个例子,源程序是:P :=0For I :=1 to 20 doP :=P+A[I]*B[I];经过编译得到的中间代码如图10-1-1所示,这个程序段由B1和B2两个部分组成,B2是一个循环,假定机器按字节编址。
那么,对于这个中间代码段,可进行如下这些优化。
1、删除多余运算(删除公共子表达式)优化的目的在于使目标代码执行速度较快。
图10-1-1中间代码(3)和(6)中都有4*I的运算,而从(3)到(6)没有对I赋值,显然,两次计算机的值是相等的。
所以,(6)的运算是多余的。
我们可以把(6)变换成:T4 :=T1。
这种优化称为删除多余运算或称为删除公共子表达式。
2、代码外提减少循环中代码总数的一个重要办法是代码外提。
这种变换把循环不变运算,即其结果独立于循环执行次数的表达式,提到循环的前面。
使之只在循环外计算一次,上例中,我们可以把(4)和(7)提到循环外。
经过删除多余运算和代码外提后,代码变成图10-1-2。
法运算等等。
在图10-1-2的循环中,每循环一次,I的值增1,T1的值与I保持线性关系,每次总是增加4。
因此,我们可以把循环中计算T1值的乘法运算变换成在循环前进行一次乘法运算,而在循环中将其变换成加法运算。
变换后如图10-1-3所示。
4、变换循环控制条件图10-1-3的代码中,I和T1始终保持T1= 4 * I的线性关系,这样可以把(12)的循环控制条件I≤20变换成T1≤80,这样整个程序的运行结果不变。
这种变换称为变换循环控制条件。
经过这一变换后,循环中I的值在循环后不会被引用,四元式(11)可以从循环中删除,这就是我们的目的所在。
5、合并已知量与复写传播图10-1-3中,四元式(3)计算4 * I时,I必为1。
所以(3)中的4 * I的两个运算对象都是编码时的已知量,可在编译时计算出它的值,即(3)可变为T1= 4这种变换称为合并已知量。
图10-1-3中,(6)把T1的值复写到T4中,四元式(8)要引用T4的值,而(6)到(8)之间未改变T4和T1的值,则(8)改为T6 : =T5[T1],之后运算结果保持不变。
这种变换称为复写传播。
图10-1-3经过变换循环控制条件,合并已知量和复写传播等变换后,变为图10-1-4。
6、删除无用赋值在图10-1-4中,(6)对T4赋值,但T4未被引用;另外,(2)和(11)对I赋值,但只有(11)引用I。
所以,只要程序中其它地方不需要引用T4和I,则(6),(2)和(11)对程序的运行结果无任何作用。
我们称之为无用赋值,无用赋值可以从程序中删除,如图10-1-5所示(设(6)(2)(11)为无用赋值)。
比较图10-1-1和图10-1-5可看出,经过优化后的代码的执行效率提高了很多。
当然,实现这些优化的代价也是很大的。
第二节局部优化我们所说的局部优化是指基本块内的优化,所谓基本块,是指程序中一顺序执行语句序列,其中只有一个入口语句和一个出口语句。
执行时只能从其入口语句进入,从其出口语句退出。
对于一个给定的程序,我们可以把它划分为一系列的基本块。
在各基本块的范围内分别进行优化。
一、基本块的划分在介绍基本块的构造之前,我们先定义基本块的入口语句,所谓入口语句,严格地说来就是:1、程序的第一语句;或者,2、条件转移语句或无条件转移语句的转移目标语句;或者,3、紧跟在条件转移语句后面的语句。
有了入口语句的概念之后,我们就可以给出划分中间代码(四元式程序)为基本块的算法,其步骤如下:1、求出四元式程序中各个基本块的入口语句。
2、对每一入口语句,构造其所属的基本块。
它是由该入口语句到下一入口语句(不包括下一入口语句),或到一转移语句(包括该转移语句),或到一停语句(包括该停语句)之间的语句序列组成的。
3、凡未被纳入某一基本块的语句、都是程序中控制流程无法到达的语句,因而也是不会被执行到的语句,我们可以把它们删除。
我们仍以上一节所述的例子来说明,对于图10-1-1中的代码段,由规则1,语句(1)是入口语句,由规则2,语句(3)是入口语句。
由规则3,跟随语句(12)的语句是入口语句,这样,语句(1)和(2)构成一个基本块,语句(3)—(12)构成一个基本块,也即图10-1-1中的B1和B2。
二、基本块的变换很多变换可作用于基本块而不改变它计算的表达式集合,这样的变换对改进代码的质量是很有用的。
有两类重要的局部等价变换可用于基本块,它们是保结构的变换和代数变换。
基本块的主要保结构变换是 1、删除公共子表达式 2、删除无用代码 3、重新命名临时变量 4、交换语句次序对于1和2,我们在第一节已经讨论过,在此简单讨论一下3和4。
重新命名临时变量:假如有语句t : = b + c ,其中t 是临时变量。
如果把这个语句改为u : = b + c , 其中u 是新的临时变量,并且把这个t 的所有引用改成u ,那么基本块的运算结果不变。
交换语句次序:如果基本块有两个相邻的语句: t 1 : = b + c t 2 : = x + y当且仅当x 和y 都不是t 1,b 和c 都不是t 2时我们可以交换这两个语句的次序。
有许多代数变换可以把基本块计算的表达式集合变换成代数等价的集合。
其中有用的变换是那些可以简化表达式或用较快运算代替较慢运算的变换。
例如:x : = x + 0 或 x : = x * 1这样的语句可以从基本块中删除而不改变它计算的表达式集合,又如 x : = y * * 2的指数算符通常要用函数调用来实现,使用代数变换,这个语句可由快速、等价的语句x : = y * y 来代替。
第三节 基本块的DAG 表示这一小节介绍如何应用有向图来进行基本块的优化工作。
先将我们所需使用的DAG 作一说明。
在一个有向图中,我们称任一有向边n i →n j (或表示为有序对(n i ,n j ))中的结点n i 为结点n j 的前驱(父结),结点n j 为结点n i 的后继(子结)。
又称任一有向边序列n 1→n 2, n 2→n 3,…,n k —1→n k 为从结点n 1到结点n k 的一条通路。
如果其中n 1=n k ,则称通路为环路。
该结点序列也记为(n 1 ,n 2,…,n k )。
例如,图10-3-1中有向图的通路(n 2 ,n 2)和(n 3 ,n 4 ,n 3)就是环路。
如果有向图中任一通路都不是环路,则称该有向图为无环路有向图,简称DAG 。
图10-3-2的有向图就是一个DAG 。
在DAG 中,如果(n 1 ,n 2,…, n k )是其中一条通路,则称结点n 1为结点n k 的祖先,结点n k 为结点n 1的后代。
我们这一节中要用到的有向图,是一种其结点带有下述标记或附加信息的DAG :1、图的叶结点,即无后继的结点,以一标识符(变量名)或常数作为标记,表示该结点代表该变量或常数的值。
如果叶结点用来代表某变量A 的地址,则用addr (A )作为该结点的标记。
通常把叶结点上作为标记的标识符加上下标0,以表示它是该变量的初值。
2、图的内部结点,即有后继的结点以一运算符作为标记,表示该结点代表应用该运算符对其后继结点所代表的值进行运算的结果。
3、图中各个结点上可能附加一个或多个标识符,表示这些变量具有该结点所代表的值。
上述这种DAG 可用来描述计算过程,又称描述计算过程的DAG 。
在以下的讨论中,我们简称DAG 。
下面讨论基本块的DAG表示与构造。
一个基本块,可用一个DAG来表示。
下面(图10-3-3)列出各种四元式及相对应的DAG的结点形式。
图中n i为结点编号,结点下面的符号(运算符、标识符或常数)是各结点的标记,各结点右边的标识符是结点的附加标识符。
四元式DAG结点(0)A:=B(:=,B,—,A)(1)A:=op B(op,B,—,A)(2)A:=B op C(op,B,C,A)(3)A:=B [C](=[ ],B[C],—,A)(4)if B rop C goto (s) (jrop, B, C, (S))(5)D[C]:=B ([]=,B,—,D[C])(6)goto(s) (j,—,—,(S))图10-3-3 四元式与DAG结点接着给出一种构造基本的DAG算法。
假设DAG各结点信息将用某种适当的数据结构来存放。
并设有一个标识符(包括常数)与结点的对应表。
NODE(A)是描述这种对应关系的一个函数,它的值或者是一个结点的编号n,或者无定义。
前一个情况代表DAG中存在一个结点n, A是其上的标记或附加标识符。
我们把图10-3-3中各形式的四元式按其对应结点的后继个数分为四类。
其中,四元式(0)称为0型,(1)称为1型;(2)和(3)称为2型;(5)称为3型。
对于3型四元式,由于对数组元素赋值的情形需特殊考虑,因此暂不讨论,对四元式(6)也不涉及,下面是仅含0,1,2型四元式的基本块的DAG构造算法。
首先,DAG为空。
对基本块的每一四元式,依次执行:1、如果NODE(B)无定义,则构造一标记为B的叶结点并定义NODE(B)为这个结点;如果当前四元式是0型,则记NODE(B)的值为n,转4。
如果当前四元式是1型,则转2.(1)。
如果当前四元式是2型,则:(1)如果NODE(C)无定义,则构造一标记为C的叶结点并定义NODE(C)为这个结点,(2)转2.(2)。
2、(1)如果NODE(B)的标记为常数的叶结点,则转2(3),否则转3.(1)。
(2)如果NODE(B)和NODE(C)都是标记为常数的叶结点,则转2.(4),否则转3.(2)。
(3)执行op B(即合并已知量),令得到的新常数为P。
如果NODE(B)是处理当前四元式时新构造出来的结点,则删除它。
如果NODE(P)无定义,则构造一用P做标记的叶结点n。