时间序列分析报告材料张能福第三章
- 格式:docx
- 大小:15.88 KB
- 文档页数:6




第一章绪论通过本章的学习,理解时间序列的概念,特别是随机时间序列的概念,掌握时间序列的建立过程,掌握确定性时序分析方法,掌握随机过程的概念,深刻理解平稳性和白噪声。
第一节时间序列分析的一般问题时间序列的含义时间序列是指被观察到的以时间为序排列的数据序列。
时间序列可以以表格的形式或图形的形式表现。
例:上海180 指数某时间段的变化国际航运乘客资料(单位:千人)1946―1970 美国各季生产者耐用品支出(单位:十亿美元)1952 年―1994 年我国社会消费品零售总额(单位:亿元)第二节时间序列的建立我们把获取时间序列以及对其进行检查、整理和预处理等工作,称为时间序列的建立。
时间序列数据的采集相应于时间的连续性,系统在不同的时刻上的响应常常是时间t的连续函数。
为了数字计算处理上的方便,往往只按照一定的时间间隔对所研究系统的响应进行记录和观察,我们称之为采样。
相应地把记录和观察时间间隔称为采样间隔。
通常采样采用等间隔采样。
离群点(Outlier )离群点(Outlier )是指一个时间序列中,远离序列一般水平的极端大值和极端小值。
对时间序列离群点分析的方法,有时也被称作稳健估计(Robust Estimation ),该方法最早由Box 和Anderson 于1955 年提出。
1. 离群点(Outlier )产生的原因:(1)采样误差;(2)系统各种偶然非正常因素影响。
2. 离群点的数理描述:(1) 它们是既定分布中的极端点(extreme point ),它们虽与数据主体来自同一分布,但本身应以极小的概率出现;(2) 这种点与数据集的主体并非采自同一分布,而是在采集数据过程中受到其他分布的“污染”,致使现有数据集掺入不应有的“杂质”。
3. 离群点(Outlier )的类型:(1)加性离群点(Additive Outlier ),造成这种离群点的干扰,只影响该干扰发生的那一个时刻T上的序列值,而不影响该时刻以后的序列值。


第一节线性差分方程一、后移算子B定义为三、齐次方程解的计算1 、AR(n) 过程自相关函数ACF 1阶自回归模型AR(1) Xt= Xt-1+ at 的k阶滞后自协方差为:Xt= 1Xt-1+ 2Xt-2 + at 该模型的方差0以及滞后1期与2期的自协方差1, 2分别为一般地,n阶自回归模型AR(n) Xt= 1Xt-1+ 2Xt-2 +…nXt-n + at 其中:zi 是AR(n) 特征方程(z)=0 的特征根,由AR(n) 平稳的条件知,|zi|<1; 因此,当zi 均为实数根时,k呈几何型衰减(单调或振荡);当存在虚数根时,则一对共扼复根构成通解中的一个阻尼正弦波项,k呈正弦波衰减。
对MA(1) 过程其自协方差系数为二、偏自相关函数从Xt 中去掉Xt-1 的影响,则只剩下随机扰动项at ,显然它与Xt-2 无关,因此我们说Xt 与Xt-2 的偏自相关系数为零,记为MA(1) 过程可以等价地写成at 关于无穷序列Xt ,Xt-1 ,…的线性组合的形式:与MA(1) 相仿,可以验证MA(m) 过程的偏自相关函数是非截尾但趋于零的。
ARMA(n,m) 的自相关函数,可以看作MA(m) 的自相关函数和AR(n) 的自相关函数的混合物。
当n=0 时,它具有截尾性质;当m=0 时,它具有拖尾性质;当n、m都不为0时,它具有拖尾性质从识别上看,通常:ARMA(n ,m) 过程的偏自相关函数(PACF )可能在n阶滞后前有几项明显的尖柱(spikes ),但从n阶滞后项开始逐渐趋向于零;而它的自相关函数(ACF )则是在m阶滞后前有几项明显的尖柱,从m阶滞后项开始逐渐趋向于零。
对k=1 ,2,3,…依次求解方程,得上述……序列为AR 模型的偏自相关函数。
偏自相关性是条件相关,是在给定的条件下,和的条件相关。
换名话说,偏自相关函数是对和所解释的相关的度量。
之间未被由最小二乘原理易得,是作为关于线性回归的回归系数。


应用时间序列分析第三章课后答案第三章应用时间序列分析课后答案第3-5节,最近考试题目:第一节序列的定义与平稳性第二节相关系数矩阵与平稳过程第三节非平稳序列第四节非平稳序列的特征值与协方差第五节离散时间序列分析是对连续时间序列进行研究和分析的一种重要方法。
本章主要内容有:时间序列的定义、平稳性、相关性、时间序列的构成及其表示方式、离散时间序列的概念、离散时间序列的时间趋势、离散时间序列的一般模型、随机过程及其应用、连续时间序列分析等。
第四节非平稳序列的特征值与协方差特征值又称为特征向量或自协因子,它反映了该特征值与其他各特征值之间的关系。
如果已知某个时间序列的全部平稳序列,那么由这些平稳序列的特征值就可以计算出每个观测值的特征值;若只知道观测值,而不知道这些观测值与哪些特征值相关,则需利用相关系数矩阵计算各观测值的协方差阵。
本节还将介绍可变参数模型,即通过改变或增加参数的办法来得到另外一组新的平稳或非平稳序列。
第五节离散时间序列分析是对连续时间序列进行研究和分析的一种重要方法。
本章首先介绍了一些基本概念,如时间序列的平稳性、特征值、协方差、自相关函数、脉冲响应等;然后介绍了时间序列的一阶、二阶和高阶矩;接着介绍了一些常见的平稳序列;最后给出了两类时间序列分解方法。
第六节连续时间序列分析本章内容较多,在此仅举几例,望同学们能够理解并掌握。
如当时间序列在均值附近单调递减时,可假设 x 和 y 的斜率相同,记为x→/ y,再用相关系数矩阵公式计算相关系数,这样便简化了运算。
这也正是统计中时间序列处理的实际情况。
有时需要作几次回归拟合才能取得满意效果,这就是所谓的多元回归分析。
时间序列中的趋势项具有比较稳定的形态。
关于我国建国以来能源生产总量的时间序列分析摘要:众所周知,能源对于一个国家有着至关重要的作用。
能源影响着人们的衣食住行,也影响着一个国家的经济发展情况。
所以,对于能源的研究就显得很有必要。
尤其是,随着建国以来,各行各业都在复苏,严重加剧了对能源的需求。
所以,选择自1949到2008年这59年的能源生产总量进行分析。
利用sas软件对这组数据进行整理,建模分析。
并根据所建模型进行预测。
关键词:能源生产总量时间序列分析 SAS软件建国以来,我国各产业百废待兴,加剧了对能源的大量需求。
随着经济的迅猛发展,人们的生活质量得到大幅度提高,各种新兴产业也大量出现,加剧对能源的消耗。
所以,导致能源出现濒危局面。
为了合理预测未来能源的发展趋势,所以利用sas软件进行时间序列分析,根据预测模型,提出宝贵意见。
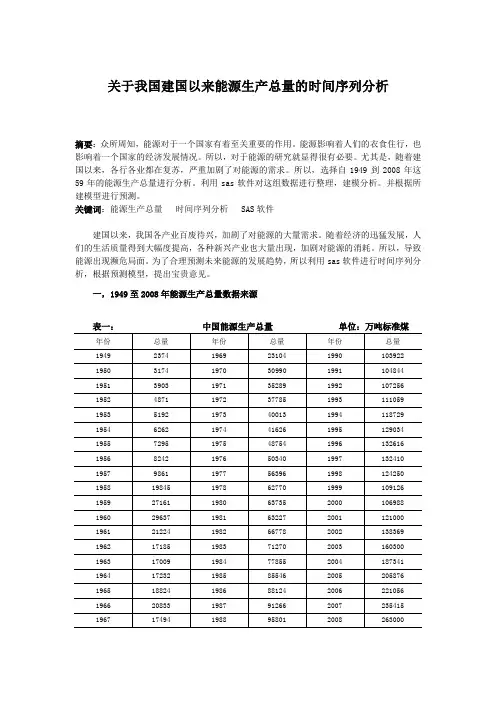
一,1949至2008年能源生产总量数据来源表一:中国能源生产总量单位:万吨标准煤二,数据分析结果(一)运用sas软件对原始数据做时序图。
如图一图一:原始数据时序图根据图一可以明显看出能源总产量呈现出递增趋势,所以选择对原始数据进行一阶差分(二)一阶差分后的时序图,图二图二:一阶差分后的时序图由图二可以看出,一阶差分后的时序图具有平稳性。
但由于时序图的判断可能具有主观主义色彩,会产生判别误差,所以进行自相关,偏自相关检验。
(三)自相关,偏自相关检验图三 :自相关图图四:偏自相关图由图三看出自相关图从2阶开始在两倍的标准差范围内波动,且二阶截尾。
由图四可以看出,偏自相关图从二阶开始在两倍的标准差范围内波动,且一阶截尾。
所以可以初步认为一阶差分后的序列有很强的短期相关性,并且平稳。
初步推断可以建立ARIMA(2,1,1))模型。
(四)对平稳的一阶差分序列进行白噪声检验 运用SAS 软件,输出结果如表二:表二: 1阶差分后序列白噪声检验由表二知,在检验的显著性水平取0.005时,由于延迟6阶的2χ检验统计量的P 值001.0<,所以该差分后不能视为白噪声序列,即差分后序列还蕴藏着不容忽视的相关信息可供提取。

基于时间序列分析预算支出与经济增长的关系随着中国经济的快速发展,预算支出规模不断扩大。
本文分析了1952-2006年中国经济发展过程中预算支出规模的变化趋势,并运用协整理论和因果关系检验理论,按照不同的时间序列对中国预算支出的经济带动作用进行了经验分析。
关键词:预算支出经济增长协整因果检验本文借鉴国外学者对预算支出与经济增长的研究成果,在分析1952-2006年中国预算支出与经济增长变化趋势的基础上,运用协整理论和因果关系检验两种分析方法,按照不同的时间序列对中国预算支出的经济带动作用进行了深入地研究。
预算支出与经济总量的变化趋势建国以来,中国预算支出和经济总量均出现大幅增长,预算支出从1952年的172.1 亿元增加到1977年的843.5亿元,再增长到2006年的40422.73 亿元,年均增速分别为6.56%、13.66%。
GDP由1952年的679.0 亿元增加到1977年的3201.9亿元。
改革开放后,中国经济增长迅猛,2006年GDP达210871亿元。
1953-1977年和1978-2006年两个不同历史时期,中国GDP的增长率分别为6.39%、15.62%。
总的来看,中国预算支出与经济增长表现出如下特点:预算支出规模与经济总量不断扩大。
1952-2006年,中国预算支出总体上呈增长趋势,55个年份中有10个年份的预算支出增长率为负,其中有8个年份属于计划经济时期。
降幅最大的是1961年,预算支出较上年下降44.7%。
从1978年开始,中国预算支出规模出现根本性转变,当年预算支出增长率高达33%。
在改革开放的三十年间,中国预算支出规模增长了35倍,仅1980年、1981年的预算支出增长出现下降,降幅分别为4.1%和7.4%。
在国内生产总值的增长中,55年中仅有5个年份的GDP出现负增长,均集中在计划经济时期。
而改革开放后,中国经济总量持续增加,2006年中国GDP分别相当于1952年、1978年的311倍、58倍。

第8章时间序列分析六、计算及推导1.ADF法对居民消费总额时间序列进行平稳性检验。
数据如下:2.用1中数据,对居民消费总额时间序列进行单整性分析。
3.以t Q表示粮食产量,t A表示播种面积,t C表示化肥施用量,经检验,CI关系。
同时经过检验并剔除不它们取对数后都是)1(I变量且互相之间存在)1,1(显著的变量(包括滞后变量),得到如下粮食生产模型:t t t t t t C C A Q Q μααααα+++++=--1432110ln ln ln ln ln (1) ⑴ 写出长期均衡方程的理论形式; ⑵ 写出误差修正项ecm 的理论形式; ⑶ 写出误差修正模型的理论形式;⑷ 指出误差修正模型中每个待估参数的经济意义。
4.固定资产存量模型t t t t t I I K K μαααα++++=--132110中,经检验,)1(~),2(~I I I K t t ,试写出由该ADL 模型导出的误差修正模型的表达式。
四、名词解释:1.伪回归:在用一个时间序列对另一个时间序列做回归时,虽然两者之间并无任何有意义的关系,但经常会得到一个很高的2R 的值,这种情况说明存在伪回归问题。
2.平稳序列:如果时间序列{t X }满足下列条件:1)均值μ=)(t X E 与时间t 无关的常数; 2)方差2σ)var(=t X 与时间t 无关的常数;3)协方差k k t t X X γ=+)cov( 只与时期间隔k 有关,与时间t 无关的常数。
则称该随机时间序列是平稳的。
3.协整:若两个时间序列)(~d I y t ,)(~d I x t ,并且这两个时间序列的线性组合)(~21b d I x a y a t t -+,0≥≥b d ,则t y 和t x 被称为是),(b d 阶协整的。
记为t y ,),(~b d CI x t4.单整:若一个非平稳序列必须经过d 次差分之后才能变换成一个平稳序列,则称原序列是d 阶单整的,表示为I(d )。
基于ARIMA模型的工业总产值时间序列分析摘要:工业的发展情况能在某种程度上反映当地的经济水平,对大量的工业总产值数据进行定性与定量的分析,能够在一定程度上刻画数据变化的规律,并根据得出的规律建立适当的数学模型,从而预测以后的工业总产值数据。
本模型以某地1990年--1997年的工业总产值历史数据为基础,基于Eviews以及spss的分析与检验,对数据进行了变化特征的分析处理,在此基础上进行了差分和取对数等数据处理后,得到平稳序列。
除此之外,本文还运用Eviews软件分离出季节因子之后,同时求出季节因子,并建立了适当的ARIMA模型,然后再对模型进行检验。
最后将预测结果与真实值进行比较,结果表明拟合度较好,具有一定的实用性。
关键词:时间序列工业产值季节因子 EViews SPSS ARIMA模型一、问题重述在科学技术迅速发展的当今时代,一个国家的工业化水平是衡量一个国家的综合国力大小强弱的重要指标。
它直接影响这个国家的政治经济的发展。
所以每个国家都在积极发展自己的工业,提高工业化的水平跻身于世界工业强国之列。
对工业总产量进行研究,找出其内在规律,预测未来,从而能根据预测数据提出相关政策建议,对促进工业乃至整个国家的经济发展具有重大的意义。
根据所给的某地工业总产值的历年数据(数据见附录1),从而来探究以下的问题:1)根据数据分析当地工业总产值的变化特征.2)根据变化特征试建立合理的模型描绘这种特征..3)若有季节性变化,试分离出季节性变化因子,求出季节性因子.二、数据处理1)我们来用Excel软件求出来各年度的工业总产值之和,平均数以及各个月份的平均数据,并画出来相关图像(见附录2)。
另外,我们还运用了SPSS 软件对个年份之间的数据进行相关性分析[1],找出个年份工业总产值之间的关系。
表1 生产总值的年度数据表2 各个月份的平均数据2)根据表中工业总产值的数据,我们先生成时间序列图进行分析,利用Eviews程序得到图1。
第一节线性差分方程一、后移算子B定义为三、齐次方程解的计算1、AR(n)过程自相关函数ACF 1阶自回归模型AR(1) Xt= Xt-1+ at 的k 阶滞后自协方差为:Xt= 1Xt-1+ 2Xt-2 + at 该模型的方差0以及滞后1期与2期的自协方差1, 2分别为一般地,n 阶自回归模型AR(n) Xt= 1Xt-1+ 2Xt-2 + …nXt-n + at 其中:zi是AR(n)特征方程⑵=0的特征根,由AR(n)平稳的条件知,|zi|<1; 因此,当zi均为实数根时,k呈几何型衰减(单调或振荡);当存在虚数根时,则一对共扼复根构成通解中的一个阻尼正弦波项,k呈正弦波衰减。
对MA(1)过程其自协方差系数为二、偏自相关函数从Xt 中去掉Xt-1的影响,则只剩下随机扰动项at ,显然它与Xt-2无关, 因此我们说Xt与Xt-2的偏自相关系数为零,记为MA(1)过程可以等价地写成at 关于无穷序列Xt , Xt-1 ,…的线性组合的形式:与MA(1)相仿,可以验证MA(m)过程的偏自相关函数是非截尾但趋于零的。
ARMA(n,m)的自相关函数,可以看作MA(m)的自相关函数和AR(n)的自相关函数的混合物。
当n=0时,它具有截尾性质;当m=0时,它具有拖尾性质;当n、m都不为0时,它具有拖尾性质从识别上看,通常:ARMA(n , m)过程的偏自相关函数(PACF ) 可能在n阶滞后前有几项明显的尖柱(spikes ),但从n阶滞后项开始逐渐趋向于零;而它的自相关函数(ACF )则是在m阶滞后前有几项明显的尖柱,从m阶滞后项开始逐渐趋向于零。
对k=1 , 2 , 3,…依次求解方程,得上述……序列为AR模型的偏自相关函数。
偏自相关性是条件相关,是在给定的条件下,和的条件相关。
换名话说,偏自相关函数是对和所解释的相关的度量。
之间未被由最小二乘原理易得,是作为关于线性回归的回归系数。
如果自回归过程的阶数为n,则对于k>n 应该有kk=O。
L + + + = - - 2 2 1 t t t t X X X q q a或t t t t X X X a q q + - - - = - - L 2 2 1 这是一个AR()过程,它的偏自相关函数非截尾但却趋于零,因此MA(1)的偏自相关函数是非截尾但却趋于零的。
注意:上式只有当| |<1时才有意义,否则意味着距Xt 越远的X值,对Xt的影响越大,显然不符合常理。
因此,我们把| |<1称为MA(1)的可逆性条件(invertibility condition ) 或可逆域。
MA(m)模型的识别规则:若随机序列的自相关函数截尾,即自m以后,k=0 (k>m );而它的偏自相关函数是拖尾的,则此序列是移动平均MA(m)序列。
同样需要注意的是:在实际识别时,由于样本自相关函数rk是总体自相关函数k的一个估计,由于样本的随机性,当k>m 时,rk不会全为0,而是在0的上下波动。
但可以证明,当k>m 时,r k服从如下渐近正态分布:rk~N(0,1/n) 式中n表示样本容量。
因此,如果计算的rk满足:我们就有95.5%的把握判断原时间序列在m之后截尾。
ARMA(n, m)过程*,从而前面的MA(m)模型、AR(n)模型和ARMA(n,m) 模型可分别表示为:其中:后移算子的性质:二、线性差分方程差分方程的通解为:可写成这里这里,C (t)是齐次方程通解,l(t)是特解。
假定G1 ,G2,…, Gn是互不相同,则在时刻t的通解:其中Ai为常数(可由初始条件确定)。
无重根考虑齐次差分方程重根设有d个相等的根,可验证通解为对一般情形,因此,齐次方程解是由衰减指数项、多项式、衰减正弦项,以及这些函数的组合混合生成的。
齐次方程解便是请看例题定义:设零均值平稳序列第二节格林函数(Green ' s function)和平稳性(Stationarity) —、格林函数(Green ' s function) 能够表示为则称上式为平稳序列的传递形式,式中的加权系数称为格林(Green )函数,其中格林函数的含义:格林函数是描述系统记忆扰动程度的函数。
(1)式可以记为其中式(1)表明具有传递形式的平稳序列可以由现在时刻以前的白噪声通过系统“”的作用而生成,是j个单位时间以前加入系统的干扰项对现实响应的权,亦即系统对的“记忆”。
二、AR ( 1)系统的格林函数由AR ( 1)模型即:则AR(1)模型的格林函数例:下面是参数分别为0.9、0.1和-0.9的AR ( 1)系统对扰动的记忆情况。
(演示试验)比较前后三个不同参数的图,可以看出:取正值时,响应波动较平坦。
取负值时,响应波动较大。
越大,系统响应回到均衡位置的速度越慢,时间越长。
三、格林函数与AR (n)系统的平稳性平稳性的涵义就是干扰项对系统的影响逐渐减弱,直到消失,对于一个AR ( n)系统,将其写成格林函数的表示形式,如果系统是平稳的,则预示随着j宀乂,扰动的权数对于AR(1)系统即这要求上述条件等价于AR(1)系统的特征方程的根在单位圆内(或方程的根在单位圆外).AR (n)模型,即其中:的平稳性条件为:的根在单位圆外(或的根在单位圆内)。
AR (n) 系统的平稳性条件:(请同学们观察平稳性AR(n)与非平稳性AR(n) 的区别。
)AR(1)的结论可以推广到AR(n)图示如右图几个例题ARMA模型格林函数的通用解法ARMA(n,m)模型且则令则化为比较等式两边B的同次幕的系数,可得由上式,格林函数可从开始依次递推算出。
例:求AR(2,1)系统的格林函数。
是零均值平稳序列,如果白噪声序列第三节逆函数和可逆性(In vertibility )能够表示为一、逆函数的定义设则称上式为平稳序列式中的加权系数称为逆函数。
可逆。
ARMA (n,m )模型逆函数通用解法对于ARMA (n,m ) 模型的逆函数求解模型格林函数求解方法相同。
令二、ARMA模型的逆函数的逆转形式则平稳序列可表示为由ARMA( n,m)模型可得仍由先前定义的和,则上式可化为比较上式两边B的同次幕的系数,得到即可从由此开始推算出。
对于MA (m)模型的可逆性讨论与AR ( n)模型平稳性的讨论是类似的,即:MA ( m)模型的可逆性条件为其特征方程的特征根满足ARMA( n,m)系统格林函数与逆函数的关系在格林函数的表达式中,用代替,代替代替,,即可得到相对应的逆函数。
理论自协方差函数和自相关函数对于ARMA系统来说,设序列的均值为零,则自协方差函数第四节自相关函数与偏自相关函数自相关函数样本自相关函数的计算在拟合模型之前,我们所有的只是序列的一个有限样本数据,无法求得理论自相关函数,只能求样本的自协方差函数和自相关函数。
样本自协方差有两种形式:一、自相关函数则相应的自相关函数为在通常情况下,我们采用第一种算法。
0 1 1 )) ( ( g j jg a j g k k t t k t k X X E = = + = - - - =1,2, …因此,AR(1)模型的自相关函数为=1,2,…由AR(1)的稳定性知| |<1 ,因此,k时,呈指数形衰减,直到零。
这种现象称为拖尾或称AR(1)有无穷记忆(infinite memory )。
注意,<0时,呈振荡衰减状。
2阶自回归模型AR(2) 2 2 2 1 1 0 a s g j g j g + + = 类似地,可写出一般的k期滞后自协方差:2 2 1 1 2 2 1 1 )) ( ( ----------- +=+ + = k k t t t k t k r X X X E j g j a j j g (K=2,3, …)于是,AR(2) 的k阶自相关函数为:(K=2,3,…)其中:1= 1/(1- 2), 0=1如果AR(2)平稳,则由1+ 2<1知| k|衰减趋于零,呈拖尾状。
至于衰减的形式,要看AR(2)特征根的实虚性,若为实根,则呈单调或振荡型衰减,若为虚根,则呈正弦波型衰减。
k期滞后协方差为:n k n k k t n t n t t K t k X X X X E ------------ + + + = + + + + = g j gj g j a j j j g L L 2 2 1 1 2 2 1 1 ))(( 从而有自相关函数:可见,无论k有多大,k的计算均与其1到n阶滞后的自相关函数有关,因此呈拖尾状。
如果AR(n)是平稳的,则| k|递减且趋于零。
事实上,自相关函数是一n阶差分方程,其通解为2、MA(m)过程1 - - = t t t X qa a 可容易地写出它的自协方差系数:0 ) 1 ( 3 2 2 1 2 2 0 ===-=+ = L g g qs g s q g a a 于是,MA(1)过程的自相关函数为:可见,当k>1时,k>0 ,即Xt与Xt-k不相关,MA(1)自相关函数是截尾的。
一般地,m阶移动平均过程MA(m) 相应的自相关函数为可见,当k>m 时,Xt与Xt-k不相关,即存在截尾现象,因此,当k>m 时,k=0是MA(m)的一个特征。
于是:可以根据自相关系数是否从某一点开始一直为0来判断MA(m)模型的阶。
自相关函数ACF(k)给出了Xt与Xt-1的总体相关性,但总体相关性可能掩盖了变量间完全不同的隐含关系。
例如,在AR(1)随机过程中,Xt与Xt-2间有相关性可能主要是由于它们各自与Xt-1间的相关性带来的:即自相关函数中包含了这种所有的“间接”相关。
与之相反,Xt与Xt-k间的偏自相关函数(partial autocorrelation ,简记为PACF)则是消除了中间变量Xt-1 ,…,Xt-k+1带来的间接相关后的直接相关性,它是在已知序列值Xt-1 ,…,Xt-k+1的条件下,Xt与Xt-k间关系的度量。
在AR(1)中,0 ) , ( 2 * 2 = = - t t XCorr a r同样地,在AR(n)过程中,对所有的k>n , Xt与Xt-k间的偏自相关系数为零。
AR(n)的一个主要特征是:k>n时,k*=Corr(Xt,Xt-k)=0 即k*在n以后是截尾的。
一随机时间序列的识别原则:若Xt的偏自相关函数在n以后截尾,即k>n时,k*=0 , 而它的自相关函数k是拖尾的,则此序列是自回归AR(n)序列。
对于一个k阶AR模型,有:由此得到Yule-Walker方程,记为:已知时,由该方程组可以解出。
遗憾的是,用该方程组求解时,需要知道自回归过程的阶数。
因此,我们可以对连续的k值求解Yule-Walker 方程。