非确定的有限状态自动机Non-deterministicFiniteAutomaton,
- 格式:ppt
- 大小:622.50 KB
- 文档页数:24

【编译原理】词法分析:正则表达式与有限⾃动机基础引⾔: 编译语⾔设计的精髓在于⾃动化过程,即如果要设计⼀门编程语⾔,那么⼀定要设计⼀个⾃动化系统,能够⾃⾏读⼊分析程序员写⼊的程序,将其翻译为机器能够识别的指令等信息。
当然⾼级语⾔的编译不是⼀蹴⽽就的,⽽是通过若⼲步的分解、规约、转换、优化,最后得到⽬标程序。
具体的编译步骤如下: 源程序就是我们写⼊的⾼级语⾔,编译的第⼀步叫做“词法分析”。
词法分析的本质,就是要拆解出语句的每⼀个单词,然后对这个单词的类型进⾏辨识。
⾸先拿中⽂来举例。
⽐如有⼀句话是“我喜欢你”,那么⾸先我们要把这句话拆成“我”、“喜欢”、“你”,然后再逐个分析他们的类型,得到“我”->主语;“喜欢”->谓语;“你”->宾语。
这样我们就把这句话每个单词都分析出来了,也就完成了中⽂的“词法分析”。
那么回到编程语⾔,它的词法分析就是将字符序列转换为单词(Token)序列的过程。
翻译成俗话,就是把我们写的⼤⽚语⾔⽂本分解为⼀个⼀个单词,再输出每个单词的类型。
举⼀个例⼦:int p = 3 + a; 这个语句⾮常简单,即定义⼀个变量p,它的初值为变量a与3的加和。
那么接下来我们要对这个语句进⾏词法分析,⾸先我们要把这段⽂本拆解成单词,拆出来就是'int'、'p'、'='、'3'、'+'、'a'、';'。
对这些单词再进⾏类型的辨识,那么就得到以下结果:语素语⾔类型int关键字p标识符=运算符3数字+运算符a标识符 这样我们就把这段⽂本中的每个单词的类型都分析出来了。
乍⼀看⾮常简单对不对,对于⼈类⽽⾔你只需要⽤⾁眼就可以轻松观察出来每个单词的类型,但对于计算机⽽⾔,它可没有⼈类那样的智能。
如果想要计算机能够识别并分析语素的类型,那就需要我们⼈类来为它构造⼀个⾃动化输⼊和分析的系统。

正则表达式(Regular Expression)是一种用于匹配字符串的强大工具,而NFA(Non-deterministic Finite Automaton,非确定性有限自动机)是一种可以用于匹配正则表达式的模型。
下面是将正则表达式转换为NFA的一般步骤:1. 将正则表达式转换为Brzozowski标准形式。
Brzozowski标准形式是一种将正则表达式转换为后缀形式的方法。
在Brzozowski标准形式中,每个操作符都被放在括号中,例如(ab)*c表示匹配零个或多个ab,后面跟着一个c。
2. 将Brzozowski标准形式转换为Thompson构造法。
Thompson构造法是一种通过构建一组字符串来模拟正则表达式的匹配过程的方法。
在Thompson构造法中,每个操作符都被表示为一个特定的字符串,例如星号(*)表示重复零个或多个次数的字符串,括号()表示匹配括号内字符串的重复次数。
3. 将Thompson构造法转换为NFA。
在Thompson构造法中,每个字符串都表示一个状态转换。
因此,可以将每个字符串转换为一个状态,并根据字符串之间的顺序将这些状态连接起来。
在NFA中,每个状态都表示一个可能的输入序列,而状态之间的转换则表示输入序列的下一个可能的输入。
4. 确定NFA的起始状态和终止状态。
在NFA中,起始状态是开始匹配正则表达式的状态,而终止状态是匹配结束的状态。
可以根据Thompson构造法中每个字符串的顺序来确定起始状态和终止状态。
例如,如果最后一个字符串是正则表达式的结尾,那么它对应的状态就是终止状态。
5. 确定NFA的转换函数和接受集。
转换函数是将一个状态和一个输入字符映射到下一个状态的函数。
接受集是一个状态集合,当自动机达到这个状态集合时,它就匹配成功。
可以根据NFA中的状态转换来确定转换函数和接受集。
通过以上步骤,可以将正则表达式转换为NFA,以便进行字符串匹配。

编译原理实验NFA确定化为DFA编译原理中的NFA(Non-deterministic Finite Automaton,非确定性有限自动机)是一种能够识别正则语言的形式化模型。
它的设计简单,但效率较低。
为了提高识别效率,需要将NFA转化为DFA(Deterministic Finite Automaton,确定性有限自动机)。
本文将介绍NFA确定化为DFA的一般方法,并以一个具体例子来说明该过程。
首先,我们来了解一下NFA和DFA的差异。
NFA可以有多个转移路径,每个输入符号可以对应多个状态转移,而DFA每个输入符号只能对应唯一的状态转移。
这使得NFA在识别过程中具有非确定性,无法确定下一个状态。
而DFA则能够准确地根据当前状态和输入符号确定下一个状态。
NFA确定化为DFA的一般方法如下:1.创建DFA的初始状态。
该状态对应NFA的起始状态以及从起始状态经过ε(空)转移可以到达的所有状态。
2.对DFA的每个状态进行如下处理:a)对当前状态的每个输入符号进行处理。
b)根据当前状态和输入符号,确定下一个状态。
如果有多个状态,需要将它们合并为一个DFA状态。
c)重复上述步骤,直到处理完所有输入符号。
3.对于合并的DFA状态,需要重复执行第2步的处理过程,直到没有新的合并状态产生为止。
4.最终得到的DFA包含的状态即为NFA确定化的结果。
下面以一个具体的例子来说明NFA确定化为DFA的过程。
考虑以下NFA:(状态)(输入符号)(转移状态)1a,ε1,22a33b44a5首先,创建DFA的初始状态,根据NFA的起始状态和通过ε转移可以到达的状态。
在该例子中,起始状态为1,通过ε转移可以到达状态1和2、因此,初始状态为{1,2}。
接下来,对初始状态{1,2}进行处理。
对于输入符号a,根据NFA的状态转移表可以得到DFA的下一个状态为{1,2,3},因为NFA的状态1通过a和ε可以到达状态3、对于输入符号b,当前状态没有转移。

编译原理nfa
编译原理中的NFA,是指非确定有限状态自动机(Nondeterministic Finite Automata)。
在计算机科学中,NFA是一种有限状态自动机,它可以用于描述一类模式匹配问题。
NFA由一组状态、一组输入符号、一个转移函数、一个初始状态和一组接受状态组成。
与确定性有限状态自动机(DFA)相比,NFA在某些方面具有更高的表达能力,因为它允许在同一时刻有多个状态,并且在输入符号为空时可以不进行转移。
但由于NFA的非确定性,使用NFA进行模式匹配时,需要进行转换和回溯,增加了计算的复杂度。
在编译原理中,NFA通常用于描述正则表达式的语法结构和匹配算法。
编译器在识别程序中的正则表达式时,会将其转换为NFA,并使用NFA进行模式匹配和语义分析。
通过这种方式,可以实现高效的正则表达式匹配和语法分析。
总之,NFA是编译原理中非常重要的概念,它为编译器设计和实现提供了一种有效的工具,能够实现正则表达式匹配和其他相关问题的解决。

第三章名词解释1.最小化(minimize)指DFA M状态数的最小化,是指构造一个等价的DFA M',而后者有最小的状态。
2.标示符(IDentifier)是指用来标识某个实体的一个符号。
在不同的应用环境下有不同的含义。
3.正规表达式(regular expression)是说明单词的模式(pattern)的一种重要的表示法(记号),是定义正规集的工具。
4.正规式(Normal form)正规式也称正则表达式,也是表示正规集的数学工具。
5.正规集(Normal set)如果把每类单词视作一种语言,那么每一类单词的全体单词组成了相应的正规集。
6. 有限状态自动机(finite state automaton)有限状态自动机拥有有限数量的状态,每个状态可以迁移到零个或多个状态,输入字串决定执行哪个状态的迁移。
有限状态自动机可以表示为一个有向图。
有限状态自动机是自动机理论的研究对象。
7.词法分析器(Lexical analyzer)词法分析是指将我们编写的文本代码流解析为一个一个的记号,分析得到的记号以供后续语法分析使用。
8.确定的有限自动机(DFA: Deterministic Finite Automata)自动机的每个状态都有对字母表中所有符号的转移。
9.五元式(Five element type)由五个要素组成的式子K:由有限个状态组成的集合∑:由有限个输入字符组成的字母表f:从K到∑的单值映射,q),(,指明当前态为p,输入字符a,下一个状态为qf=pas:一个属于K的特定状态,称之为初始状态Z:若干个属于K的特定状态,它们组成的集合称之为终态集,记为Z。
10.非确定的有限自动机(NFA:Non deterministic finite automaton)自动机的状态对字母表中的每个符号可以有也可以没有转移,对一个符号甚至可以有多个转移。
自动机接受一个字,如果存在至少一个从q0 到 F 中标记(label)著这个输入字的一个状态的路径。
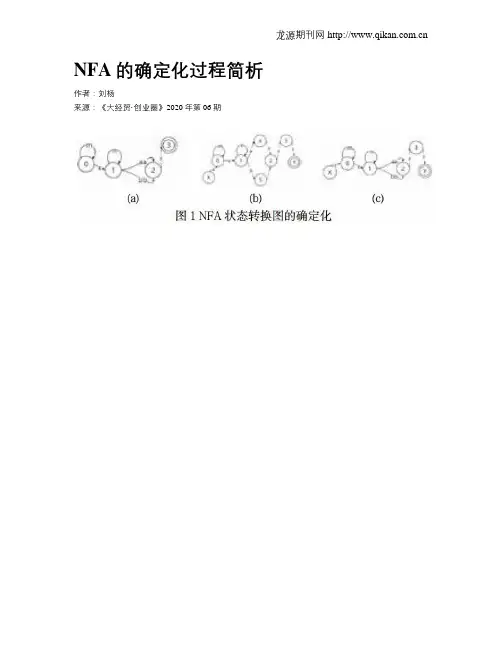
NFA的确定化过程简析作者:刘杨来源:《大经贸·创业圈》2020年第06期【摘要】在编译原理的学习中,从上下文无关文法的初步理解进阶到词法分析过程,是理解整个编译过程的关键一步;其中,确定性有限自动机(DFA)和非确定性有限自动机(NFA)的等价与转换,是这一部分的难点之一。
本文将首先介绍DFA和NFA相关的几个基本概念,然后着重介绍确定性有限自动机(DFA)和非确定性有限自动机(NFA)的等价变化过程。
【关键词】编译原理词法分析 DFA NFA 有限自动机一、基本概念(一)正规集和正规式所谓正规集,就是一个集合,是一个字符的集合。
正规指的就是,该集合中的字符,对于我们所研究的程序设计语言来说,是合法的。
正规式则是正规集的另一种表示方式。
或者说,在研究编译原理的过程中,用正规式来表示正规集。
二者的对应关系可以参考如下示例:设有字母表Σ,则Σ上的字符a和b都是正规式,它们分别表示Σ上的正规集{a}和{b}。
词法分析中的等价关系判定的充要条件,就是:被研究的两个对象,其所表示的正規式是否相同。
(二)DFA和NFA首先,FA(finite automaton),有限自动机,本质上就是状态转换图(表示词法分析器逐个识别输入字符并进行状态转换的过程)。
一个有限自动机由一个五元式组成:S:有穷状态集;Σ:有穷输入字母表;f:状态转换函数;S0:初始状态;F:终态有限自动机中的状态转换函数是其精髓所在。
状态转换函数将词法分析器的状态转换过程抽象为一个双输入单输出的函数,而这样的函数很容易使用矩阵来表示,从而使词法分析器的工作过程得以数字化,进而可以使用代码来实现。
DFA(deterministic finite automaton),确定的有限自动机;NFA(Nondeterministic finite automaton),非确定的有限自动机。
二者的区别主要有三点:DFA的初始状态是唯一的,但NFA的初始状态可以不唯一(注意,DFA和NFA的终态结点都可以不唯一);DFA中,每个状态的输入只能是单个字符,且不包括ε(空字符);但是在NFA中,可以是一个字或者单个字符或者ε;DFA中,每个状态接收输入后的转换关系是一定的,但是在这一转换关系NFA中不是确定的。



简述有限状态机的分类和区别
有限状态机是计算机科学中的一种数学模型,用于描述系统的状态转换行为。
根据状态转换的规则和方式,可以将有限状态机分为两类:确定性有限状态机和非确定性有限状态机。
确定性有限状态机(Deterministic Finite Automaton,DFA)
指的是状态转换是唯一的,即在任何时候,从任何状态出发,只要读入相同的输入符号,都会到达同一个状态。
这种状态机的状态转换图是一个有向无环图,每个状态只有一个后继状态。
非确定性有限状态机(Nondeterministic Finite Automaton,NFA)指的是状态转换不唯一,即在某些情况下,从同一状态出发,
读入相同的输入符号,可能会到达不同的状态。
这种状态机的状态转换图是一个有向图,每个状态可能有多个后继状态。
在实际应用中,有限状态机还可以根据状态的数量、输入符号的类型、输出符号的类型等进行分类。
例如,根据状态数量的不同,可以将有限状态机分为有限自动机和无限自动机;根据输入符号的类型,可以将有限状态机分为确定性和非确定性的输入符号型有限状态机等。
总之,有限状态机是一种非常重要的计算机模型,能够描述许多复杂的系统行为。
了解有限状态机的分类和区别,可以更好地理解和应用它们。
- 1 -。

编译原理NFANFA(Non-deterministic Finite Automaton,非确定有限自动机)是一种用于描述正则语言的有限状态自动机。
NFA可以由以下元素构成:一组状态,一个输入字母表,一个状态转移函数和一个初始状态及一组接受状态。
在编译原理中,NFA常常用于构建正则表达式的匹配器或者词法分析器。
下面是一个简单的NFA的定义和构造过程:1. NFA的定义:-状态集合:一组状态,每个状态用一个唯一的标识符表示。
-输入字母表:包含所有可能的输入符号。
-状态转移函数:描述状态之间的转移关系,它是一个映射函数,将一个状态和一个输入符号映射到一组可能的下一个状态。
对于NFA来说,一个状态和一个输入符号可能对应多个下一个状态,这是与确定有限自动机(DFA)的主要区别之一。
-初始状态:NFA的起始状态。
-接受状态:一组接受状态,表示匹配成功的状态。
2. 构造NFA:-对于每个正则表达式的元素(字符或操作符),构造相应的NFA片段。
-对于字符元素,构造一个简单的NFA片段,包含两个状态和一个输入转移。
-对于连接操作符(.),将两个NFA片段连接起来,即将第一个NFA片段的接受状态指向第二个NFA片段的初始状态。
-对于选择操作符(|),构造两个NFA片段,然后添加一个新的初始状态和两个ε(空)转移,将新的初始状态指向这两个NFA片段的初始状态,并将两个NFA片段的接受状态指向一个新的接受状态。
-对于闭包操作符(*),构造一个NFA片段,添加一个新的初始状态和两个ε转移,将新的初始状态指向原NFA片段的初始状态,并将原NFA片段的接受状态指向新的接受状态。
然后添加两个ε转移,将新的初始状态和新的接受状态连接起来。
通过这样的方式,可以逐步构建出完整的NFA,最终得到一个能够接受特定正则表达式定义的语言的NFA。
需要注意的是,NFA在状态转移时可以有多个选择,这种非确定性使得NFA在实际匹配过程中可能需要进行回溯。

计算机理论基础实验报告实验题目:从NFA到DFA的转化姓名:院(系):专业班级:学号:指导教师:设计日期:2013年11月1日一、实验目的:1.了解NFA和DFA的概念2.NFA和DFA之间的联系3.从NFA到DFA的转化程序编写二、实验原理1.NFANFA(nondeterministic finite-state automata)即非确定有限自动机, 一个非确定的有限自动机NFA M’是一个五元式:NFA M’=(S, Σ∪{ε}, δ, S0, F)其中 S—有限状态集Σ∪{ε}—输入符号加上ε,即自动机的每个结点所射出的弧可以是Σ中一个字符或是ε.S0—初态集 F—终态集δ—转换函数 S×Σ∪{ε} →2S(2S --S的幂集—S的子集构成的集合)2.DFADFA(deterministic finite-state automata)即确定有限自动机,一个确定的有限自动机DFA M是一个五元式:M=(S, Σ,δ, S0, Z)其中:S —有限状态集Σ—输入字母表δ—映射函数(也称状态转换函数)S×Σ→Sδ(s,a)=S’, S, S’ ∈S, a∈ΣS0 —初始状态 S0 ∈SZ—终止状态集 Z S3. NFA和DFA之间的联系在非确定的有限自动机NFA中,由于某些状态的转移需从若干个可能的后续状态中进行选择,故一个NFA对符号串的识别就必然是一个试探的过程。
这种不确定性给识别过程带来的反复,无疑会影响到FA的工作效率。
而DFA则是确定的,将NFA转化为DFA将大大提高工作效率,因此将NFA转化为DFA是有其一定必要的。
三、实验设计通过本课程设计教学所要求达到的目的是:充分理解和掌握NFA,DFA以及NFA确定化过程的相关概念和知识,理解和掌握子集法的相关知识和应用,编程实现对输入NFA转换成DFA输出的功能。
程序总框图如图1所示:图1 程序总框图1、子集构造法已证明:非确定的有限自动机与确定的有限自动机从功能上来说是等价的,也就是说,我们能够从:NFA M使得L(M)=L(M’)为了使得NFA确定化,我们首先给出两个定义:定义1:集合I的ε-闭包:令I是一个状态集的子集,定义ε-closure(I)为:1)若s∈I,则s∈ε-closure(I);2)若s∈I,则从s出发经过任意条ε弧能够到达的任何状态都属于ε-closure(I)。
自动机正则表达式自动机(automaton)是一种数学模型,用于表示计算系统的运行行为。
正则表达式(regular expression)是一种语言,用于描述一类字符串的集合。
自动机和正则表达式之间存在着密切的关系。
一方面,自动机可以接受一个正则表达式所描述的字符串集合;另一方面,正则表达式可以通过构造一个对应的自动机来进行匹配。
自动机可以被看作是一种抽象的计算机,它可以根据一些预定义的规则对输入的序列进行处理。
自动机的行为通常是基于当前状态和输入字符所确定的。
根据状态的不同,自动机可以有不同的行为。
自动机通常可以分为有限自动机(finite automaton)和不确定自动机(nondeterministic automaton)。
有限自动机只有有限个状态,并且在每个状态下,只能有一个对应的输出动作。
而不确定自动机则可以在每个状态下有多个对应的输出动作。
正则表达式是用于描述字符模式的一种语法。
它由一系列的字符和特殊符号组成,用于匹配一类字符串的集合。
正则表达式中可以使用的特殊符号包括点号(.)、问号(?)、星号(*)、加号(+)、竖线()等。
这些特殊符号可以用来描述字符的重复次数、匹配任意字符等。
正则表达式可以通过自动机进行匹配。
对于每个正则表达式,可以构建一个对应的自动机,然后使用这个自动机来匹配输入的字符串。
匹配的过程通常从自动机的起始状态开始,不断根据输入字符和当前状态进行转移,直到到达自动机的终止状态。
在正则表达式中,使用星号(*)表示前一个字符可以重复任意次数,使用加号(+)表示前一个字符可以重复一次或多次,使用问号(?)表示前一个字符可以出现零次或一次。
通过使用这些特殊符号,可以描述重复的字符模式。
正则表达式还支持字符类(character class)的概念,可以用方括号([...])来表示一个字符集合。
方括号中可以列举出字符的取值范围,也可以使用特殊符号来表示某些常见的字符集合,例如\d表示数字字符集合,\w表示字母、数字和下划线字符集合,\s表示空白字符集合等。
编译原理课程实践报告设计名称:NFA转化为DFA的转换算法及实现二级学院:数学与计算机科学学院专业:计算机科学与技术班级:计科本091班*名:***学号: ********** 指导老师:***日期: 2012年6月摘要确定有限自动机确定的含义是在某种状态,面临一个特定的符号只有一个转换,进入唯一的一个状态。
不确定的有限自动机则相反,在某种状态下,面临一个特定的符号是存在不止一个转换,即是可以允许进入一个状态集合。
在非确定的有限自动机NFA中,由于某些状态的转移需从若干个可能的后续状态中进行选择,故一个NFA对符号串的识别就必然是一个试探的过程。
这种不确定性给识别过程带来的反复,无疑会影响到FA的工作效率。
而DFA则是确定的,将NFA转化为DFA将大大提高工作效率,因此将NFA转化为DFA是有其一定必要的。
对于任意的一个不确定有限自动机(NFA)都会存在一个等价的确定的有限自动机(DFA),即L(N)=L(M)。
本文主要是介绍如何将NFA转换为与之等价的简化的DFA,通过具体实例,结合图形,详细说明转换的算法原理。
关键词:有限自动机;确定有限自动机(DFA),不确定有限自动机(NFA)AbstractFinite automata is determinate and indeterminate two class. Determine the meaning is in a certain state, faces a particular symbol only one conversion, enter only one state. Not deterministic finite automata is the opposite, in a certain state, faces a particular symbol is the presence of more than one conversion, that is to be allowed to enter a state set.Non deterministic finite state automata NFA, because of some state are transferred from a number of possible follow-up state are chosen, so a NFA symbol string recognition must be a trial process. This uncertainty to the recognition process brought about by repeated, will undoubtedly affect the efficiency of the FA. While the DFA is determined, converting NFA to DFA will greatly improve the working efficiency, thus converting NFA to DFA is its necessary.For any a nondeterministic finite automaton ( NFA ) can be an equivalent deterministic finite automaton ( DFA ), L ( N ) =L ( M ). This paper mainly introduces how to convert NFA to equivalent simplified DFA, through concrete examples, combined with graphics, a detailed description of the algorithm principle of conversion.Keywords::finite automata; deterministic finite automaton ( DFA ), nondeterministic finite automaton ( NFA目录1.前言: (1)1.1背景 (1)1.2实践目的 (1)1.2课程实践的意义 (1)2.NFA和DFA的概念 (2)2.1 不确定有限自动机NFA (2)2.2确定有限自动机DFA (3)3.从NDF到DFA的等价变化步骤 (5)3.1转换思路 (5)3.2.消除空转移 (5)3.3子集构造法 (7)4程序实现 (9)4.1程序框架图 (9)4.2 数据流程图 (9)4.3实现代码 (10)4.4运行环境 (10)4.5程序实现结果 (10)5.用户手册 (12)6.课程总结: (12)7.参考文献 (12)8. 附录 (13)1.前言:1.1背景有限自动机作为一种识别装置,它能准确地识别正规集,即识别正规文法所定义的语言和正规式所表示的集合,引入有穷自动机这个理论,正是为词法分析程序的自动构造寻找特殊的方法和工具。
非确定有限自动机例题
非确定有限自动机(Nondeterministic Finite Automaton,NFA)是一种有限自动机,其在同一时刻可以处于多个状态之一,从而可以具有多个可能的转移。
以下是一个简单的非确定有限自动机的例子。
考虑一个有限字母表 {0, 1} 的 NFA,它接受以 "01" 结尾的字符串。
1. 状态集合:
• Q = {q0, q1, q2}
2. 字母表:
•Σ = {0, 1}
3. 转移函数:
•δ(q0, 0) = {q0}
•δ(q0, 1) = {q0, q1}
•δ(q1, 0) = {q2}
•δ(q2, 1) = {q2}
4. 初始状态:
• q0
5. 接受状态:
• q2
在这个例子中,NFA 从初始状态 q0 开始,读取输入串中的每个符号,并根据转移函数可能处于多个状态之一。
如果字符串以"01" 结尾并且最终状态为 q2,则NFA接受该字符串。
例如,对于输入串 "00101",NFA 的状态转移可以如下:
• q0 (读取 0) -> q0
• q0 (读取 0) -> q0
• q0 (读取 1) -> q0, q1
• q1 (读取 0) -> q2
• q2 (读取 1) -> q2
在这个例子中,最终状态是 q2,因此 NFA 接受输入串 "00101"。
需要注意的是,NFA 具有非确定性,即在某些情况下有多个可能的状态转移。
这与确定有限自动机(DFA)不同,DFA 在任何时刻只能有一个确定的状态。
02|词法分析:识别Token也可以很简单吗?《手把手带你写一门编程语言》上一节课,我们用了很简单的方法就实现了语法分析。
但当时,我们省略了词法分析的任务,使用了一个 Token 的列表作为语法分析阶段的输入,而这个 Token 列表呢,就是词法分析的结果。
其实,编译器的第一项工作就是词法分析,也是你实现一门计算机语言的头一项基本功。
今天,我们就来补补课,学习一下怎么实现词法分析功能,词法分析也就是把程序从字符串转换成 Token 串的过程。
词法分析难不难呢?我们来对比一下,语法分析的结果是一棵 AST 树,而词法分析的结果是一个列表。
直观上看,列表就要比树结构简单一些,所以你大概会猜想到,词法分析应该会更简单一些。
那么,具体来说,词法分析要用什么算法呢?词法是不是也像语法一样有规则?词法规则又是如何表达的?这一节课,我会带着你实现一个词法分析器,来帮你掌握这些技能。
在这里,我有个好消息告诉你。
你在上一节课学到的语法分析的技能,很多可以用在词法分析中,这会大大降低你的学习难度。
好了,我们开始了。
词法分析的任务你已经知道,词法分析的任务就是把程序从字符串转变成 Token 串,那它该怎么实现呢?我们这里先不讲具体的算法,先来看看下面这张示意图,分析一下,我们人类的大脑是如何把这个字符串断成一个个 Token 的?图1:词法分析是把字符串转变为Token串你可能首先会想到,借助字符串中的空白字符(包括空格、回车、换行),把这个字符串截成一段段的,每一段作为一个 Token,行不行?按照这个方法,function 关键字可以被单独识别出来。
但是你看,我们还有一些圆括号、花括号等等,这些符号跟前一个单词之间并没有空格或回车,我们怎么把它们断开呢?OK,你可以说,凡是遇到圆括号、花括号、加号、减号、点号等这些符号,我们把它们单独作为 Token 识别出来就好了。
比如,对于 cat.weight 这样的对象属性访问的场景,点符号就是一个单独的 Token。