编译原理之有限自动机
- 格式:ppt
- 大小:2.10 MB
- 文档页数:75


【编译原理】词法分析:正则表达式与有限⾃动机基础引⾔: 编译语⾔设计的精髓在于⾃动化过程,即如果要设计⼀门编程语⾔,那么⼀定要设计⼀个⾃动化系统,能够⾃⾏读⼊分析程序员写⼊的程序,将其翻译为机器能够识别的指令等信息。
当然⾼级语⾔的编译不是⼀蹴⽽就的,⽽是通过若⼲步的分解、规约、转换、优化,最后得到⽬标程序。
具体的编译步骤如下: 源程序就是我们写⼊的⾼级语⾔,编译的第⼀步叫做“词法分析”。
词法分析的本质,就是要拆解出语句的每⼀个单词,然后对这个单词的类型进⾏辨识。
⾸先拿中⽂来举例。
⽐如有⼀句话是“我喜欢你”,那么⾸先我们要把这句话拆成“我”、“喜欢”、“你”,然后再逐个分析他们的类型,得到“我”->主语;“喜欢”->谓语;“你”->宾语。
这样我们就把这句话每个单词都分析出来了,也就完成了中⽂的“词法分析”。
那么回到编程语⾔,它的词法分析就是将字符序列转换为单词(Token)序列的过程。
翻译成俗话,就是把我们写的⼤⽚语⾔⽂本分解为⼀个⼀个单词,再输出每个单词的类型。
举⼀个例⼦:int p = 3 + a; 这个语句⾮常简单,即定义⼀个变量p,它的初值为变量a与3的加和。
那么接下来我们要对这个语句进⾏词法分析,⾸先我们要把这段⽂本拆解成单词,拆出来就是'int'、'p'、'='、'3'、'+'、'a'、';'。
对这些单词再进⾏类型的辨识,那么就得到以下结果:语素语⾔类型int关键字p标识符=运算符3数字+运算符a标识符 这样我们就把这段⽂本中的每个单词的类型都分析出来了。
乍⼀看⾮常简单对不对,对于⼈类⽽⾔你只需要⽤⾁眼就可以轻松观察出来每个单词的类型,但对于计算机⽽⾔,它可没有⼈类那样的智能。
如果想要计算机能够识别并分析语素的类型,那就需要我们⼈类来为它构造⼀个⾃动化输⼊和分析的系统。




程序设计语言编译原理(第三版)第3章第3章词法分析任务:从左至右逐个字符地对源程序进行扫描,产生一个个的单词符号,把作为字符串的源程序改造成为单词符号串。
§3.1§3.2§3.3§3.4对于词法分析器的要求词法分析器的设计正规表达式与有限自动机词法分析器的自动产生(LE某)—略1§3.1对于词法分析器的要求一.功能和输出形式二.接口设计§3.1对于词法分析器的要求一.功能和输出形式1.功能:输入源程序,输出单词符号2.单词符号的分类(1)关键字:由程序语言定义的具有固定意义的标识符,也称为保留字或基本字。
例如:Pacal语言中begin(2)标识符:用来表示各种名字。
endifwhile等。
如变量名、数组名、过程名等。
(3)常数:整型、实型、布尔型、文字型等例:100(5)界符:,;3.14159()true等ample(4)运算符:+、-、某、/3§3.1对于词法分析器的要求3.输出的单词符号形式二元式:(单词种别,单词符号的属性值)通常用“整数编码”“单词符号的特征或特性”单词符号的编码:标识符:一般统归为一种常数:常按整型、实型、布尔型等分类关键字:全体视为一种/一字一种运算符:一符一种界符:一符一种4§3.1对于词法分析器的要求例:考虑下述C++代码段:while(i>=j)i--;经词法分析器处理后,它将被转换为如下的单词符号序列:<while,-><(,-><id,指向i的符号表项的指针><>=,-><id,指向j的符号表项的指针><),-><id,指向i的符号表项的指针><--,-><;,->§3.1对于词法分析器的要求二.接口设计1.词法分析器作为独立的一遍词法分析字符流(源程序)单词序列(输出在一个中间文件上)2.词法分析器作为一个独立的子程序,但并不一定作为独立的一遍语法分析器单词(至少一个)调用(取下一个单词)词法分析器优点:使整个编译程序的结构更简洁、清晰和条理化.6§3.2词法分析器的设计一.输入和预处理二.单词符号的识别三.状态转换图及其实现§3.2词法分析器的设计一.输入、预处理1.预处理:剔掉空白符、跳格符、回车符、换行符、注解部分等.原因:编辑性字符除了出现在文字常数中之外,在别处的任何出现都无意义.#注解部分不是程序的必要组成部分,它的作用仅在于改善程序的易读性和易理解性.8§3.2词法分析器的设计2.预处理子程序:每当词法分析器调用时,就处理出一串确定长度(如120个字符)的输入字符,并将其装进词法分析器所确定的扫描缓冲区中。

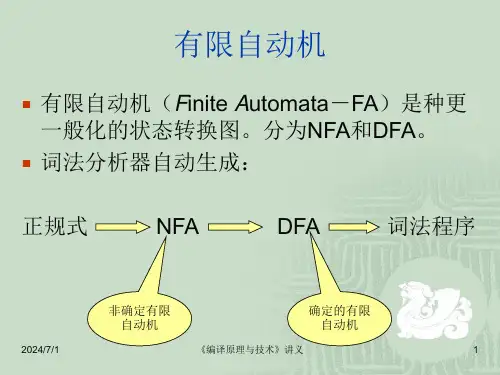
第三章词法分析本章要点1•词法分析器设计,2.正规表达式与有限自动机,3•词法分析器自动生成。
本章目标:1•理解对词法分析器的任务,掌握词法分析器的设计;2.掌握正规表达式与有限自动机;3•掌握词法分析器的自动产生。
本章重点:1. 词法分析器的作用和接口,用高级语言编写词法分析器等内容,它们与词法分析器的实现有关。
应重点掌握词法分析器的任务与设计,状态转换图等内容。
2 •掌握下面涉及的一些概念,它们之间转换的技巧、方法或算法。
(1)非形式描述的语言正规式(2)正规式NFA (非确定的有限自动机)(3)NFADFA (确定的有限自动机)(4)DFA最简DFA本章难点(1)非形式描述的语言正规式(2)正规式NFA (非确定的有限自动机)(3)NFADFA (确定的有限自动机)(4)DFA最简DFA作业题、单项选择题(按照组卷方案,至少15道) 1•程序语言下面的单词符号中,一般不需要超前搜索a.关键字b.标识符c.常数d.算符和界符2. 在状态转换图的实现中,一般对应一个循环语句a.不含回路的分叉结点b.含回路的状态结点c.终态结点d.都不是3. 用了表示字母,d表示数字,={1,d},则定义标识符的正则表达式可以是:。
(a)ld* (b)ll* (c)l(l | d) * (d)ll* | d*4. 正规表达式(e |ajb表示的集合是(a){ , ab, ba, aa, bb} (b){ab , ba, aa, bb}(c){a , b, ab, aa, ba, bb} (d){,込b, aa, bb, ab, ba}5. 有限状态自动机可用五元组( V T , Q , & q o , Q f)来描述,设有一有限状态自动机M的定义如下:V T={0 , 1}, Q={q 0 , q1 , q2}, Q f={q 2}, 3 的定义为:氷 q o , 0) =q1 3 (q1, 0) =q23(q2 , 1) =q2 3 (q2 , 0) =q2M所对应的状态转换图为。


第一章编译程序是一种程序,它把高级语言编写的源程序翻译成与之在逻辑上等价的机器语言或汇编语言的目标程序。
一个高级语言程序的执行通常分为两个阶段,即编译阶段和运行阶段。
如果编译生成的目标程序是汇编语言形式,那么在编译与运行阶段之间还要添加一个汇编阶段。
解释程序也是一种翻译程序,它将源程序作为输入,一条语句地读入并解释执行。
解释程序与编译程序的主要区别是:编译程序是将源程序翻译成目标程序后再执行该目标程序,而解释程序则是逐条读出源程序中的语句并解释执行,即在解释程序的执行过程中并不源程序产生目标程序。
编译过程可以划分成五个阶段:词法分析阶段、语法分词法分析器析阶段、语义分析和中间代码生成阶段、优化阶段和目单词符号标代码生成阶段。
词法分析的任务是对构成源程序的字语法分析器表出符串进行扫描和分解,根据语言的词法规则识别出一个语法单位个具有独立意义的单词;语法分析的任务是在词法分析格错语义分析与的基础上,根据语言的语法规则(文法规则)从单词符中间代码生成器管处号串中识别出各种语法单位并进行语法检查;语义分析四元式理和中间代码生成阶段的任务是首先对每种语法单位进行理优化静态语义检查,然后分析其含义,并用另一种语言形式四元式来描述这种语义即生成中间代码;优化的任务是对前阶目标代码生成器段产生的中间代码进行等价变换或改造,以期获得更为目标程序高效(节省时间和空间)的目标代码;目标代码生成阶段的任务是把中间代码(或经优化处、理之后)变换成特编译程序结构示意图定机器上的机器语言程序或汇编语言程序,实现最终的翻译工作。
自编译:用某种高级语言书写自己的编译程序。
交叉编译:指用A机器上的编译程序来产生可在B机器上运行的目标代码。
自展:首先确定一个非常简单的核心语言L0,然后用机器语言或汇编语言书写出它的编译程序T0:再把语言L0扩充到L1,此时有L0L1,并用L0编写L1的编译程序T1(即自编译)。
移植:指A机器上的某种高级语言的编译程序稍加改动后能够在B机器上运行。

编译原理dfa编译原理DFA。
有限自动机(DFA)是编译原理中的重要概念,它在词法分析和语法分析中扮演着重要的角色。
在编译原理中,DFA用于识别和分析输入的字符序列,帮助编译器理解源代码的结构和含义。
本文将介绍DFA的基本概念、原理和应用,以及它在编译原理中的重要作用。
DFA的基本概念。
DFA是有限自动机(Deterministic Finite Automaton)的缩写,它是一种抽象的数学模型,用于描述有限个状态和在这些状态之间转移的输入字符序列。
DFA由五元组(Q, Σ, δ, q0, F)组成,其中:Q是有限状态集合;Σ是输入字符的有限集合;δ是状态转移函数,描述了状态之间的转移关系;q0是初始状态;F是接受状态集合。
DFA的原理。
DFA的工作原理是通过状态转移函数δ来识别和分析输入字符序列。
编译器将源代码转换为字符流,然后通过DFA进行词法分析,将字符流转换为标记流。
在词法分析过程中,DFA根据输入字符的转移关系,逐步从初始状态转移到接受状态,从而识别出源代码中的各种标记,如关键字、标识符、常量和运算符等。
DFA的应用。
DFA在编译原理中有着广泛的应用,它是词法分析器和语法分析器的核心组成部分。
在词法分析阶段,编译器利用DFA识别并提取源代码中的各种标记,为后续的语法分析和语义分析提供输入。
在语法分析阶段,DFA可以帮助编译器理解源代码的结构和语法,从而生成抽象语法树(AST)或中间代码。
此外,DFA还可以应用于模式匹配、文本搜索和自动机器人等领域。
在模式匹配和文本搜索中,DFA可以帮助我们快速地识别和匹配目标字符串;在自动机器人中,DFA可以帮助我们设计和实现自动化的决策系统。
DFA在编译原理中的重要作用。
在编译原理中,DFA是词法分析和语法分析的基础,它可以帮助编译器理解源代码的结构和含义。
通过DFA的识别和分析,编译器可以将源代码转换为抽象语法树(AST)或中间代码,为后续的优化和代码生成提供基础。
第一章1.解答:程序设计语言:程序设计语言是遵守一定规范的、描述“计算”(Computing)过程的形式语言。
一般可以划分为低级语言和高级语言两大类。
低级语言是面向机器的语言,它是为特定的计算机系统设计的语言,机器指令、汇编语言是低级语言。
高级语言是与具体计算机无关的“通用”语言,它更接近于人类的自然语言和数学表示,例如FORTRAN、Pascal、C等等我们熟悉的语言是高级语言。
语言处理程序:由于目前的计算机只能理解和执行机器语言,因此必须有一个程序将用程序设计语言书写的程序等价(执行效果完全一致)地转换为计算机能直接执行的形式,完成这一工作的程序称为“语言处理程序”。
它一般可分为解释程序和翻译程序两大类。
翻译程序:翻译程序(Translator)是一种语言处理程序,它将输入的用程序设计语言书写的程序(称为源程序)转换为等价的用另一种语言书写的程序(称为目标程序)。
若源语言是汇编语言,目标程序是机器语言,称这种翻译程序为汇编程序。
若源语言是高级语言,目标程序是低级语言,称这种翻译程序为编译程序。
解释程序:解释程序(Interpreter)是一种语言处理程序,它对源程序逐个语句地进行分析,根据每个语句的含义执行语句指定的功能。
2.解答:编译程序的总框图见图1.2。
其中词法分析器,又称扫描器,它接受输入的源程序,对源程序进行词法分析,识别出一个个的单词符号,其输出结果是单词符号。
语法分析器,对单词符号串进行语法分析(根据语法规则进行推导或归约),识别出程序中的各类语法单位,最终判断输入串是否构成语法上正确的“程序”。
语义分析及中间代码产生器,按照语义规则对语法分析器归约出(或推导出)的语法单位进行语义分析并把它们翻译成一定形式的中间代码。
编译程序可以根据不同的需要选择不同的中间代码形式,有的编译程序甚至没有中间代码形式,而直接生成目标代码。
优化器对中间代码进行优化处理。
一般最初生成的中间代码执行效率都比较低,因此要做中间代码的优化,其过程实际上是对中间代码进行等价替换,使程序在执行时能更快,并占用更小的空间。
编译原理DFA(有限确定⾃动机)的构造原题:1、⾃⼰定义⼀个简单语⾔或者⼀个右线性正规⽂法⽰例如(仅供参考) G[S]:S→aU|bV U→bV|aQV→aU|bQ Q→aQ|bQ|e2、构造其有穷确定⾃动机,如3、利⽤有穷确定⾃动机M=(K,Σ,f, S,Z)⾏为模拟程序算法,来对于任意给定的串,若属于该语⾔时,该过程经有限次计算后就会停⽌并回答“是”,若不属于,要么能停⽌并回答“不是”K:=S;c:=getchar;while c<>eof do{K:=f(K,c);c:=getchar; };if K is in Z then return (‘yes’)else return (‘no’)开始编程!1.状态转换式构造类:current——当前状态next——下⼀状态class TransTile{public:char current;char next;char input;TransTile(char C,char I,char Ne){current = C;next = Ne;input = I;}};2.DFA的构造类此处包括DFA的数据集,字母表,以及过程P的定义。
包括了初始化,遍历转换,以及最终的字符串识别。
class DFA{public://构造状态集各个元素string States;char startStates;string finalStates;string Alphabets;vector <TransTile> Tile;DFA(){init();}void init(){cout << "输⼊有限状态集S:" << endl;cin >> States;cout << "输⼊字符集A:" << endl;cin >> Alphabets;cout << "输⼊状态转换式(格式为:状态-输⼊字符-下⼀状态,输⼊#结束):" << endl;cout << "例如:1a1 \n 1a0 \n 2a1 \n #" << endl;int h = 0;//while (cin>>input){// TransTile transval(input[0], input[1], input[2]);// Tile.push_back(transval);//}while(true){char input[4];cin>>input;if(strcmp(input,"#")==0)break;TransTile transval(input[0],input[1],input[2]);Tile.push_back(transval);}cout << "输⼊初态:" << endl;cin >> startStates;cout << "输⼊终态:" << endl;cin >> finalStates;}//遍历转换表char move(char P,char I){for (int i = 0; i < Tile.size(); i++){if (Tile[i].current == P&&Tile[i].input == I){return Tile[i].next;}}return'E';}//识别字符串函数void recognition(){string str;cout << "输⼊需要识别的字符串:" << endl;cin >> str;int i = 0;char current = startStates;while (i < str.length()){current = move(current, str[i]);if (current == 'E'){break;}i++;}if (finalStates.find(current) != finalStates.npos){cout << "该⾃动机识别该字符串!" << endl;}else{cout << "该⾃动机不能识别该字符串!" << endl;}}};3.测试Main函数int main(){DFA dfa;bool tag;while(1){cout<<"你想要继续吗?是请输⼊1,否输⼊0:"<<endl; cin>>tag;if(tag){dfa.recognition();}elsebreak;}return0;}。