SPSS170在生物统计学中的应用实验指导-实验三、参数估计 实验四、t检验解读
- 格式:doc
- 大小:483.00 KB
- 文档页数:11

《生物统计学》上机实验—— SPSS for Windows 统计软件操作与应用陈光升编绵阳师范学院生命科学与技术学院实验一数据的管理及基本统计分析一、数据格式化:用户可根据具体资料的属性对数据进行格式化。
主要有以下3种数据类型:Numeric:数值型,同时定义数值的宽度(Width),即整数部分+小数点+小数部分的位数,默认为8位;定义小数位数(Decimal Places),默认为2位。
Date:日期型。
如选择mm/dd/yy形式,则1995年6月25日显示为06/25/95。
String:字符型,用户可定义字符长度(Characters)以便输入字符。
二、数据的输入:定义好变量并格式化数据之后,即可向数据管理窗口键入原始数据。
数据管理窗口的主要部分就是电子表格,横方向为电子表格的行,其行头以1、2、3、……表示,即第1、2、3、……行;纵方向为电子表格的列,其列头以var00001,var00002,var00003……表示变量名。
行列交叉处称为单元格,即保存数据的空格。
鼠标一旦移入电子表格内即呈十字形,这时按鼠标左键可激活单元格,被激活的单元格以加粗的边框显示;用户也可以按方向键上下左右移动来激活单元格。
单元格被激活后,用户即可向其中输入新数据或修改已有的数据。
三、数据管理器列宽定义:点击Column Format...钮,用户可定义数据管理器纵列的宽度,以便显示较长的数值或文字;同时用户还可指定数值或文字在数据管理器单元格中的位置:Left表示靠左、Center表示居中、Right表示靠右(此为默认方式)。
四、数据的增删:增加一个新的变量列: Data菜单的Insert Variable命令项。
增加一个新的行: Data菜单的Insert Case 命令项。
增加一个新的观察值:Edit菜单的Cut命令项。
删除一个行:Delete键或选Edit菜单的Clear命令项。
删除一个变量列:Delete键或选Edit菜单的Clear命令项。

SPSS在生物统计学中的应用——实验指导手册SPSS简介最初软件全称为“社会科学统计软件包”(Statistical Package for the Social Sciences),但是随着SPSS产品服务领域的扩大和服务深度的增加,SPSS公司已于2000年正式将英文全称更改为Statistical Product and Service Solutions “统计产品与服务解决方案”,标志着SPSS的战略方向正在做出重大调整。
20 世纪60 年代末,美国斯坦福大学的三位研究生研制开发了最早的统计分析软件SPSS,同时成立了SPSS 公司,并于1975 年在芝加哥组建了SPSS 总部。
20 世纪80年代以前,SPSS统计软件主要应用于企事业单位。
1984年SPSS 总部首先推出了世界第一个统计分析软件微机版本SPSS/PC+,开创了SPSS 微机系列产品的开发方向,极大地扩充了它的应用范围,并使其能很快地应用于自然科学、技术科学、社会科学的各个领域,世界上许多有影响的报刊杂志纷纷就SPSS 的自动统计绘图、数据的深入分析、使用方便、功能齐全等方面给予了高度的评价与称赞。
SPSS 名为社会科学统计软件包,这是为了强调其在社会科学应用的一面(因为社会科学研究中的许多现象都是随机的,要使用统计学来进行研究),而实际上广泛应用于经济学、社会学、生物学、教育学、心理学、医学以及体育、工业、农业、林业、商业和金融等各个领域。
SPSS 现已推广到多种各种操作系统的计算机上,它和SAS、BMDP并称为国际上最有影响的三大统计软件。
和国际上几种统计分析软件比较,它的优越性更加突出。
在众多用户统计要与大量的数据打交道,涉及繁杂的计算和图表绘制。
现代的数据分析工作如果离开统计软件几乎是无法正常开展。
在准确理解和掌握了各种统计方法原理之后,再来掌握几种统计分析软件的实际操作,是十分必要的。
SAS 和SPSS 是目前在大型企业、各类院校以及科研机构中较为流行的两种统计软件。

SPSS在生物统计学中的应用——实验指导手册实验五:方差分析一、实验目标与要求1.帮助学生深入了解方差及方差分析的基本概念,掌握方差分析的基本思想和原理2.掌握方差分析的过程。
3.增强学生的实践能力,使学生能够利用SPSS统计软件,熟练进行单因素方差分析、两因素方差分析等操作,激发学生的学习兴趣,增强自我学习和研究的能力。
二、实验原理在现实的生产和经营管理过程中,影响产品质量、数量或销量的因素往往很多。
例如,农作物的产量受作物的品种、施肥的多少及种类等的影响;某种商品的销量受商品价格、质量、广告等的影响。
为此引入方差分析的方法。
方差分析也是一种假设检验,它是对全部样本观测值的变动进行分解,将某种控制因素下各组样本观测值之间可能存在的由该因素导致的系统性误差与随即误差加以比较,据以推断各组样本之间是否存在显著差异。
若存在显著差异,则说明该因素对各总体的影响是显著的。
方差分析有3个基本的概念:观测变量、因素和水平。
●观测变量是进行方差分析所研究的对象;●因素是影响观测变量变化的客观或人为条件;●因素的不同类别或不通取值则称为因素的不同水平。
在上面的例子中,农作物的产量和商品的销量就是观测变量,作物的品种、施肥种类、商品价格、广告等就是因素。
在方差分析中,因素常常是某一个或多个离散型的分类变量。
⏹根据观测变量的个数,可将方差分析分为单变量方差分析和多变量方差分析;⏹根据因素个数,可分为单因素方差分析和多因素方差分析。
在SPSS中,有One-way ANOV A(单变量-单因素方差分析)、GLM Univariate(单变量多因素方差分析);GLM Multivariate (多变量多因素方差分析),不同的方差分析方法适用于不同的实际情况。
本节仅练习最为常用的单变量方差分析。
三、实验演示容与步骤㈠单变量-单因素方差分析单因素方差分析也称一维方差分析,对两组以上的均值加以比较。
检验由单一因素影响的一个分析变量由因素各水平分组的均值之间的差异是否有统计意义。
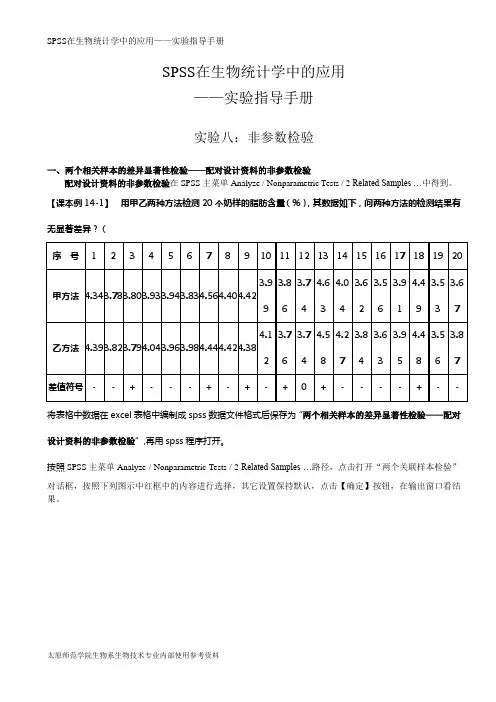
SPSS在生物统计学中的应用——实验指导手册实验八:非参数检验一、两个相关样本的差异显著性检验——配对设计资料的非参数检验配对设计资料的非参数检验在SPSS主菜单Analyze / Nonparametric Tests / 2 Related Samples …中得到。
【课本例14-1】用甲乙两种方法检测20个奶样的脂肪含量(%),其数据如下,问两种方法的检测结果有无显著差异?(将表格中数据在excel表格中编制成spss数据文件格式后保存为“两个相关样本的差异显著性检验——配对设计资料的非参数检验”,再用spss程序打开。
按照SPSS主菜单Analyze / Nonparametric Tests / 2 Related Samples …路径,点击打开“两个关联样本检验”对话框,按照下列图示中红框中的内容进行选择,其它设置保持默认,点击【确定】按钮,在输出窗口看结果。
Wilcoxon 带符号秩检验秩N 秩均值秩和乙方法 - 甲方法负秩6a7.58 45.50正秩13b11.12 144.50结1c总数20a. 乙方法 < 甲方法b. 乙方法 > 甲方法c. 乙方法 = 甲方法检验统计量b乙方法 - 甲方法Z -1.993a 渐近显著性(双侧) .046a. 基于负秩。
b. Wilcoxon 带符号秩检验符号检验频率N 检验统计量b乙方法 - 甲方法乙方法 - 甲方法负差分a 6正差分b13结c 1总数20a. 乙方法 < 甲方法b. 乙方法 > 甲方法c. 乙方法 = 甲方法本节中的检验比较两个相关变量的分布。
要使用的适当检验取决于数据类型。
●如果数据是连续的,可使用符号检验或Wilcoxon 符号秩检验。
符号检验计算所有个案的两个变量之间的差,并将差分类为正、负或平。
如果两个变量分布相似,则正差和负差的数目不会有很大的差别。
Wilcoxon 符号秩检验考虑关于各对之间的差的符号和差的幅度的信息。


生物统计学方法与应用生物统计学是一门应用数学的学科,它的目标是通过采集、整理、分析和解释生物学数据,以帮助我们更好地理解生命现象和进行科学研究。
本文将介绍一些主要的生物统计学方法及其在生物学研究中的应用。
一、描述统计学方法描述统计学方法用于对数据进行总结和描述,以揭示其特征和规律。
常用的描述统计学方法包括以下几种:1. 数据的中心趋势测量:包括均值、中位数和众数等指标,可以帮助我们了解数据的集中程度。
2. 数据的离散程度测量:包括方差、标准差和极差等指标,可以帮助我们了解数据的分散程度。
3. 频数分布表和直方图:用于展示数据的分布情况,帮助我们了解数据的分布特征。
二、推断统计学方法推断统计学方法用于基于样本数据对总体进行推断和预测,以了解总体的特征和规律。
常用的推断统计学方法包括以下几种:1. 参数估计:通过样本数据对总体参数进行估计,例如均值、方差等。
2. 假设检验:用于检验某个研究假设的可行性,例如是否拒绝零假设,是否存在显著差异等。
3. 置信区间:通过对参数估计结果进行区间估计,以反映估计结果的不确定度。
三、生物统计学的应用生物统计学方法在生物学研究中有着广泛的应用,以下是一些常见的应用领域:1. 实验设计与分析:生物统计学方法可以帮助研究人员设计合理的实验方案,并对实验数据进行分析,以确保实验结果的可靠性和有效性。
2. 遗传学研究:生物统计学方法可以用于分析遗传数据,帮助我们理解基因的传播规律和遗传疾病的发生机制。
3. 流行病学研究:生物统计学方法可以用于流行病学调查和疫情监测,帮助我们了解疾病的传播方式和危害程度,以制定相应的预防和控制策略。
4. 生态学研究:生物统计学方法可以用于分析生态系统的结构和功能,帮助我们了解物种多样性、生态相互作用和生态系统的稳定性。
总之,生物统计学作为一门重要的工具学科,在生物学研究中发挥着重要的作用。
通过合理地应用生物统计学方法,我们可以对生物数据进行有效的分析和解释,从而推进生物学研究的进展,为人类的生存和健康做出贡献。

《生物统计学》实验教学教案[实验项目]实验一平均数标准差及有关概率的计算[教学时数]2课时。
[实验目的与要求]1、通过对平均数、标准差、中位数、众数等数据的计算,掌握使用计算机计算统计量的方法。
2、通过对正态分布、标准正态分布、二项分布、波松分布的学习,掌握使用计算机计算有关概率和分位数的方法。
为统计推断打下基础。
[实验材料与设备]计算器、计算机;有关数据资料。
[实验内容]1、平均数、标准差、中位数、众数等数据的计算。
2、正态分布、标准正态分布有关概率和分位数的计算。
3、二项分布有关概率和分位数的计算。
4、波松分布有关概率和分位数的计算。
[实验方法]1、平均数、标准差、中位数、众数等数据的计算公式。
平均数=Average(x1x2…x n)几何平均数=Geomean(x1x2…x n)调和平均数=Harmean(x1x2…x n)中位数=median(x1x2…x n)众数=Mode(x1x2…x n)最大值=Max(x1x2…x n)最小值=Min(x1x2…x n)平方和(Σ(x- )2)=Devsq(x1x2…x n)x样本方差=Var (x1x2…x n)样本标准差=Stdev(x1x2…x n)总体方差=Varp(x1x2…x n)总体标准差=Stdevp(x1x2…x n)2、正态分布、标准正态分布有关概率和分位数的计算。
一般正态分布概率、分位数计算:概率=Normdist(x,μ,σ,c) c 取1时计算 -∞-x 的概率 c 取0时计算 x 的概率 分位数=Norminv(p, μ, σ) p 取-∞到分位数的概率 练习:猪血红蛋白含量x 服从正态分布N(12.86,1.332),(1) 求猪血红蛋白含量x 在11.53—14.19范围内的概率。
(0.6826)(2) 若P(x <1l )=0.025,P(x >2l )=0.025,求1l ,2l 。
(10.25325) L1=10.25 L2=15.47标准正态分布概率、分位数计算:概率=Normsdist(x) c 取1时计算 -∞--x 的概率 c 取0时计算 x 的概率 分位数=Normsinv(p) p 取-∞到分位数的概率练习:1、已知随机变量u 服从N(0,1),求P(u <-1.4), P(u ≥1.49), P (|u |≥2.58), P(-1.21≤u <0.45),并作图示意。

S P S S17.0在生物统计学中的应用-实验七-卡方检验汇总SPSS在生物统计学中的应用——实验指导手册实验七:卡方检验一、实验目标与要求1.帮助学生深入了解卡方检验的基本概念,掌握卡方检验的基本思想和原理2.掌握卡方检验的过程。
二、实验原理卡方检验适用于次数分布的检验,比如次数分布是否与某种理想的分布一致,或者不同样本同类测量分数次数分布是否一致。
对于前者,先要确定一个理想的次数分布比例,然后将观测的某一次数分布与其比较,确定二者的差异性,并用X2来反映。
X2 越小,则差异越小,该样本的观测分布越有可能适合于理想分布;X2 越大,则差异越大,其服从于理想分布的可能性就越小。
当服从理想分布的伴随概率小于0.05时,就认为该次数分布与理想的分布有显著性差异。
不同样本中测量分数的次数分布使用卡方检验时,如果卡方足够大,该观测在两个样本中的次数分布服从于同一总体的概率小于0.05时,则认为样本间存在显著性差异。
三、实验演示内容与步骤㈠适合性检验比较观测数与理论数是否符合的假设检验(compatibility test),也称吻合性检验或拟合优度检验(goodness of fit test).。
【例】有一鲤鱼遗传试验,以红色和青灰色杂交,其F2代获得不同分离尾数,问观测值是否符合孟德尔3:1遗传定律.体色青灰色红色总数F2观测尾数1503 99 16021. 定义变量:2. 输入变量值3. 选择菜单1:点击菜单【数据】→【加权个案】→弹出“加权个案”对话框→4. 选择菜单2:点击菜单【分析】→【非参数检验】→【卡方】→弹出“卡方检验”对话框点击【选项】按钮,弹出“卡方检验:选项”对话框,选择“描述性”,点击【继续】点击【确定】在输出结果视图中看分析结果基本统计量Descriptive StatisticsN Mean Std. Deviation Minimum Maximum 观测尾数1602 1416.24 338.172 99 1503观测尾数Observed N 实测频数Expected N理论频数Residual偏差99 99 400.5 -301.5 1503 1503 1201.5 301.5 Total 1602Test Statistics观测尾数Chi-Square 卡方值302.629adf 1Asymp. Sig. .000a. 0 cells (.0%) have expectedfrequencies less than 5. The minimumexpected cell frequency is 400.5.㈡独立性检验又叫列联表(contigency table)χ2检验,它是研究两个或两个以上因子彼此之间是独立还是相互影响的一类统计方法。

SPSS170在生物统计学中的应用实验七卡方检验汇总在生物统计学中,卡方检验(Chi-square test)被广泛应用于分析分类数据,特别是用于比较观察到的频数与期望频数之间的差异。
该检验可以用于研究不同组群的差异、评估变量之间的关系,以及分析遗传数据等。
下面将概述生物统计学中卡方检验的应用,并举例说明其在实验七中的具体应用。
卡方检验的基本假设是观察到的频数与期望频数之间没有显著差异。
在生物统计学中,卡方检验可以用于比较不同组群之间的离散变量,例如比较不同亚型的基因分布、不同药物治疗组的治疗效果等。
此外,卡方检验也可以用于分析遗传数据,例如遗传比例和基因型分布之间的差异。
在实验七中,我们可以运用卡方检验来分析两种不同的遗传特性之间是否存在关联。
例如,我们可以研究在果蝇种群中,翅膀颜色(黄色或灰色)与眼睛颜色(红色或白色)之间的关系。
我们可以观察到不同翅膀颜色和眼睛颜色组合的频数,并与期望频数进行比较。
如果观察到的频数与期望频数之间存在显著差异,则说明翅膀颜色和眼睛颜色之间存在关联。
下面是实验七中对卡方检验的具体步骤和操作:1.设定零假设和备择假设:-零假设(H0):翅膀颜色和眼睛颜色之间不存在关联。
-备择假设(H1):翅膀颜色和眼睛颜色之间存在关联。
2.收集数据:-记录不同翅膀颜色和眼睛颜色组合的频数。
3.计算期望频数:-根据零假设计算期望频数,期望频数等于每个组合的行边际频数乘以列边际频数,然后除以总频数。
4.计算卡方统计量:-计算卡方统计量,它衡量了观察到的频数与期望频数之间的差异程度。
5.计算自由度:-自由度等于(行数-1)乘以(列数-1)。
6.查找卡方分布表:-使用自由度找到相应的临界值,该值可以帮助我们决定是否拒绝零假设。
7.进行假设检验:-比较计算得到的卡方统计量和临界值,如果卡方统计量大于临界值,则拒绝零假设,否则不拒绝零假设。
8.解释结果:-如果拒绝零假设,说明翅膀颜色和眼睛颜色之间存在关联;如果不拒绝零假设,说明翅膀颜色和眼睛颜色之间没有关联。

SPSS统计软件在生物统计课程教学中的应用SPSS统计软件在生物统计课程教学中的应用摘要:生物统计课程是生命科学领域本科学生的必修课程,因其理论性强、内容抽象、计算公式繁多往往影响教学效果。
将易学好用的SPSS统计软件应用到大学生物统计课程教学过程中,既能锻炼学生的实际动手能力又能提升学生的学习兴趣,增强教学效果。
本文主要探讨SPSS软件的特点及在辅助生物统计教学新模式中的重要性和必要性,对生物统计课程的教学改革具有一定的积极意义。
关键词:生物统计SPSS软件课程教学教学效率生物统计学是研究数据资料的收集、整理、分析和解释的科学,是用数理统计原理和方法分析和解释生物界各种现象和试验调查资料的一门学科,是把数学语言引入具体生命科学领域进行搜集、分析和解释生物学数据的一门科学,是一门应用性很强的方法论学科。
随着生物学研究不断开展,生物统计学在各领域中的应用越来越广泛。
目前生物统计学已成为生物学和农业科学领域研究和实际工作必不可少的工具。
生物统计学这门课程的概念和原理比拟抽象,课程内容多、公式多,计算比拟复杂,学生想学好、教师想教好都有一定的难度,因此怎样增强这门课程教学效果,一直是生物统计课程教师不断思考和探索的问题。
目前国内高校统计相关课程教学中辅助统计软件的种类较多,有Excel、Matlab、SPSS、Origin、SAS、S-Plus、Stata、Minitab等,但适合高等院校非统计专业可使用的软件较少。
本文主要结合教学实践,阐述SPSS在生物统计课程教学中的应用。
SPSS软件是世界上应用最广泛的专业统计软件之一,在全球约有25万用户,分布于通信、医疗、银行、证券、保险、制造、商业、市场研究和科研教育等多个领域和行业,全球500强中约有80%的公司使用SPSS,而在市场研究和市场调查领域那么拥有超过80%的市场占有率,与SAS并称为当今最权威的两大统计软件。
SPSS原先是statistical package for the social science的缩写,SPSS的历史开始于1968年,斯坦福大学三位不同专业的研究生编制出了世界上最早的统计软件系统,并将其命名为SPSS,随后该软件和相应成立的SPSS公司走上了持续开展的创新之路。
SPSS在生物统计学中的应用——实验指导手册实验三:参数估计一、实验目的与要求1.理解参数估计的概念2.熟悉区间估计的概念与操作方法二、实验原理1. 参数估计的定义●参数估计(parameter estimation)是根据从总体中抽取的样本估计总体分布中的未知参数的方法。
它是统计推断的一种基本形式,是数理统计学的一个重要分支,分为点估计和区间估计两部分。
●点估计(point estimation):又称定值估计,就是用实际样本指标数值作为总体参数的估计值。
当总体的性质不清楚时,我们须利用某一量数(样本统计量)作为估计数,以帮助了解总体的性质,如:样本平均数乃是总体平均数μ的估计数,当我们只用一个特定的值,亦即数线上的一个点,作为估计值以估计总体参数时,就叫做点估计。
✧点估计的数学方法很多,常见的有“矩估计法”、“最大似然估计法”、“最小二乘估计法”、“顺序统计量法”等。
✧点估计的精确程度用置信区间表示。
●区间估计(interval estimation)是从点估计值和抽样标准误出发,按给定的概率值建立包含待估计参数的区间。
其中这个给定的概率值称为置信度或置信水平(confidence level),这个建立起来的包含待估计函数的区间称为置信区间,指总体参数值落在样本统计值某一区内的概率●置信区间(confidence interval)是指在某一置信水平下,样本统计值与总体参数值间误差范围。
置信区间越大,置信水平越高。
划定置信区间的两个数值分别称为置信下限(lower confidence limit,lcl)和置信上限(upper confidence limit,ucl)2. 参数估计的基本原理统计分析的目的就是由样本推断总体,参数估计即是实现这一目的的方法之一。
3. 参数估计的方法参数估计的结果,常用点估计值(样本均值)+置信区间(置信下限、置信上限)来表示。
三、实验内容与步骤1. 单个总体均值的区间估计打开数据文件“描述性统计(100名女大学生的血清蛋白含量).sav”选择菜单【分析】—>【描述统计】—>【探索】”,打开图3.1探索(Explore)对话框。
目录前言 (2)Excel 在描述统计中的应用 (2)Excel 在推断统计中的应用 (6)实验一常用计算方法及描述统计量分析 (12)试验二假设检验 (17)试验三方差分析 (20)试验四回归与相关分析 (25)试验五生物信息学研究与分析 (27)练习作业 (30)前言统计学是系统介绍有关如何测定、搜集、整理和分析客观现象总体数量特征的方法论科学。
随着科学技术和社会经济的不断发展,统计学的应用领域也越来越广阔,特别是随着计算机科学的发展,基于大量数据处理的统计学在探求客观事物规律性方面越发显得重要,而统计学与计算机数据处理的结合也越来越紧密。
统计分析软件是数据分析的主要工具,完整的数据分析过程包括:数据的收集,数据的整理,数据的分析。
统计学为数据分析过程提供一套完整的科学的方法论。
统计软件为数据分析提供了实现手段。
统计分析软件的一般特点:功能全面,系统地集成了多种成熟的统计分析方法;有完善的数据定义、操作和管理功能;方便地生成各种统计图形和统计表格;使用方式简单,有完备的联机帮助功能;软件开放性好,能方便地和其他软件进行数据交换。
常用统计软件简介:eviews是tsp(dos版)的windows版本,以界面的友善、使用的简单而著称,基本上操作是傻瓜式,但是非常实用,处理回归方程是它的长处,能处理一般的回归包括多元回归问题。
因为没有用dos操作系统了,所以这个软件很少用。
SAS真正的巨无霸,被誉为国际上的标准统计软件和最权威的组合式优秀统计软件。
但是图形操作界面比较糟糕,一切围绕编程设计;人机对话界面太不友好,学习起来较困难(要编程);说明书非常难懂;价格贵的人直跳。
SPSS软件。
这个软件的界面友好,使用简单,但是功能很强大,也可以编程,eviews能处理的它全能处理,另外横截面数据的处理是它的强项,能处理多变量问题,如进行因素分析、主成份分析、聚类分析、生存分析等。
matlab软件。
这是一种工科软件,功能非常强大,在建筑、工程中使用比较多,做出来的图形能够用完美来形容,编程能力很强,不过用在统计上有点大才小用,编程也相对复杂。
SPSS在生物统计学中的应用——实验指导手册实验五:方差分析一、实验目标与要求1.帮助学生深入了解方差及方差分析的基本概念,掌握方差分析的基本思想和原理2.掌握方差分析的过程。
3.增强学生的实践能力,使学生能够利用SPSS统计软件,熟练进行单因素方差分析、两因素方差分析等操作,激发学生的学习兴趣,增强自我学习和研究的能力。
二、实验原理在现实的生产和经营管理过程中,影响产品质量、数量或销量的因素往往很多。
例如,农作物的产量受作物的品种、施肥的多少及种类等的影响;某种商品的销量受商品价格、质量、广告等的影响。
为此引入方差分析的方法。
方差分析也是一种假设检验,它是对全部样本观测值的变动进行分解,将某种控制因素下各组样本观测值之间可能存在的由该因素导致的系统性误差与随即误差加以比较,据以推断各组样本之间是否存在显著差异。
若存在显著差异,则说明该因素对各总体的影响是显著的。
方差分析有3个基本的概念:观测变量、因素和水平。
●观测变量是进行方差分析所研究的对象;●因素是影响观测变量变化的客观或人为条件;●因素的不同类别或不通取值则称为因素的不同水平。
在上面的例子中,农作物的产量和商品的销量就是观测变量,作物的品种、施肥种类、商品价格、广告等就是因素。
在方差分析中,因素常常是某一个或多个离散型的分类变量。
⏹根据观测变量的个数,可将方差分析分为单变量方差分析和多变量方差分析;⏹根据因素个数,可分为单因素方差分析和多因素方差分析。
在SPSS中,有One-way ANOV A(单变量-单因素方差分析)、GLM Univariate(单变量多因素方差分析);GLM Multivariate (多变量多因素方差分析),不同的方差分析方法适用于不同的实际情况。
本节仅练习最为常用的单变量方差分析。
三、实验演示内容与步骤㈠单变量-单因素方差分析单因素方差分析也称一维方差分析,对两组以上的均值加以比较。
检验由单一因素影响的一个分析变量由因素各水平分组的均值之间的差异是否有统计意义。
《SPSS方差分析在生物统计的应用》篇一一、引言在生物统计领域,数据分析是一种至关重要的研究方法。
SPSS(Statistical Package for the Social Sciences)作为一款常用的统计分析软件,在生物统计领域的应用尤为广泛。
其中,方差分析(ANOVA)是SPSS中一种重要的统计方法,它可以帮助研究者对不同组间的差异进行量化分析。
本文将探讨SPSS方差分析在生物统计中的应用,以及其在实验设计、数据分析和结果解读等方面的具体操作步骤。
二、SPSS方差分析的原理及适用性方差分析是一种基于F检验的统计方法,主要用于检验多个样本间的平均数是否存在显著差异。
当我们在生物实验中收集了多组数据,并希望了解这些组之间的差异是否具有统计学意义时,就可以使用SPSS方差分析。
该方法适用于处理具有重复观测值的数据集,如不同处理组或不同时间点的生物样本数据。
三、SPSS方差分析在生物统计的应用步骤1. 实验设计:在生物实验中,首先需要设计合理的实验方案。
这包括确定实验组和对照组的数量、选择合适的样本量以及设定合理的实验条件等。
在实验设计阶段,应充分考虑各组之间的可比性和数据的可收集性。
2. 数据收集:根据实验设计,收集各组的数据。
这些数据应包括各组间的重复观测值,以便进行方差分析。
在数据收集过程中,应确保数据的准确性和完整性。
3. 数据处理:将收集到的数据导入SPSS软件中,进行数据处理和清洗。
这包括检查数据的缺失值、异常值以及数据格式等。
在处理过程中,应遵循生物统计的相关规范和要求。
4. 方差分析:在SPSS软件中,选择合适的方差分析方法(如单因素方差分析、多因素方差分析等),并设置相应的参数。
然后,根据所设置的参数进行方差分析,计算各组间的差异显著性水平。
5. 结果解读:根据方差分析的结果,解读各组之间的差异是否具有统计学意义。
如果P值小于设定的显著性水平(如0.05),则认为该组与其他组之间存在显著差异。
《基于SPSS应用的生物统计学实验》课程教学大纲1、课程简介《生物统计学》是运用数理统计的原理和方法来分析和解释生物界各种现象和试验调查资料的一门学科,是生物类各专业的专业基础课。
统计方法是现代生物学研究不可缺少的工具。
正确的统计分析能够帮助我们正确认识事物客观存在的规律性。
而《基于SPSS应用的生物统计学实验》是把SPSS软件和生物统计学有机的糅合到了一起,课程中系统地介绍了生物统计学的基本原理和方法,在简要叙述了生物统计学的概念、产生、发展和作用、生物学研究中试验资料的整理、特征数的计算、概率和概率分布、抽样分布、试验设计等的基础上,着重介绍了SPSS软件在生物统计中的应用,如平均数的t 检验、X2检验、方差分析、直线回归与相关分析、可直线化的非线性回归分析、协方差分析、多元回归与相关分析和多项式回归分析,同时简要介绍聚类分析、判别分析、主成分分析、因子分析、典型相关、时间序列分析等多元分析。
本课程的主要目的是培养学生具有生物学试验设计的能力和对试验资料进行统计分析处理的能力。
2、教学对象四年制制药工程专业二年级学生。
3、教学目的通过本课程的学习,学生应达到以下要求:(1)理论知识方面了解生物统计学的基本原理;弄清试验误差的概念、来源及其控制途径;掌握试验设计的基本原则和常用设计方法的要点及特点;掌握常用统计分析方法的意义、功用、应用条件,方法步骤与结果解释等基本知识。
(2)技能技巧方面根据所给试验条件,会正确选用试验设计方法,并做出试验设计;能正确的应用SPSS 软件对于试验资料进行整理,并能够选用适当的统计分析方法进行分析及对分析结果作出合理的解释;掌握统计软件SPSS的主要功能,并能够熟练地使用该软件。
4、教学要求《基于SPSS应用的生物统计学实验》是一门工具学科,是数理统计原理和方法在生物学中的具体应用。
因此在开设本课程之前,学生应具备数理统计、计算机应用以及一定的专业基础或专业知识。
SPSS在生物统计学中的应用——实验指导手册实验三:参数估计一、实验目的与要求1.理解参数估计的概念2.熟悉区间估计的概念与操作方法二、实验原理1. 参数估计的定义●参数估计(parameter estimation)是根据从总体中抽取的样本估计总体分布中的未知参数的方法。
它是统计推断的一种基本形式,是数理统计学的一个重要分支,分为点估计和区间估计两部分。
●点估计(point estimation):又称定值估计,就是用实际样本指标数值作为总体参数的估计值。
当总体的性质不清楚时,我们须利用某一量数(样本统计量)作为估计数,以帮助了解总体的性质,如:样本平均数乃是总体平均数μ的估计数,当我们只用一个特定的值,亦即数线上的一个点,作为估计值以估计总体参数时,就叫做点估计。
✧点估计的数学方法很多,常见的有“矩估计法”、“最大似然估计法”、“最小二乘估计法”、“顺序统计量法”等。
✧点估计的精确程度用置信区间表示。
●区间估计(interval estimation)是从点估计值和抽样标准误出发,按给定的概率值建立包含待估计参数的区间。
其中这个给定的概率值称为置信度或置信水平(confidence level),这个建立起来的包含待估计函数的区间称为置信区间,指总体参数值落在样本统计值某一区内的概率●置信区间(confidence interval)是指在某一置信水平下,样本统计值与总体参数值间误差范围。
置信区间越大,置信水平越高。
划定置信区间的两个数值分别称为置信下限(lower confidence limit,lcl)和置信上限(upper confidence limit,ucl)2. 参数估计的基本原理统计分析的目的就是由样本推断总体,参数估计即是实现这一目的的方法之一。
3. 参数估计的方法参数估计的结果,常用点估计值(样本均值)+置信区间(置信下限、置信上限)来表示。
三、实验内容与步骤1. 单个总体均值的区间估计打开数据文件“描述性统计(100名女大学生的血清蛋白含量).sav”选择菜单【分析】—>【描述统计】—>【探索】”,打开图3.1探索(Explore)对话框。
♦从源变量清单中将“血清蛋白含量”变量移入因变量列表(Dependent List)框中。
图3.1 Explore对话框♦单击上图右方的“统计量”按钮打开“探索:统计量”对话框。
在设置均值的置信水平,如键入95%,完成后单击“继续”按钮回到主窗口。
图3.2 探索统计量设置窗口♦返回主窗口点击“确定”运行操作。
♦分析结果简单说明:表3.1 描述统计量Descriptive♦如上表显示。
从上表“95%Confidence Interv al for Mean ”中可以得出,女大学生区间估计(置信度为95%)为:(72.4932,74.0848),其中lower Bound 表示置信区间的下限,Upper Bound表示置信区间的上限。
点估计是:73.2890。
说明女大学生血清蛋白含量总体水平有平百分之九十五的机率落72.4932g/L和74.0848g/L之间,总体水平低于72.4932g/L和高于74.0848g/L的可能性小于百分之五。
2.两个总体均值之差的区间估计【课本例14-2 】现有两组饲料喂猪的料重比数据如下。
饲料A 3.08 2.73 3.03 2.95 2.21 3.03 2.86 3.13 2.59 2.89饲料B 3.43 3.04 3.37 3.29 2.46 3.37 3.19 2.89 3.49要求对饲料A喂猪的平均料重比与饲料B喂猪的平均料重比之差进行区间估计,预设的置信度为95%。
♦打开SPSS,打开数据文件:“两组饲料喂猪的料重比数据.xls”。
♦计算两总体均值之差的区间估计,采用“独立样本T 检验”方法。
选择菜单“【分析】→【比较均值】→【独立样本T检验】”,图3.3 “独立样本T检验”菜单选择打开“独立样本T检验”对话框。
♦变量选择(1)从源变量清单中将“料重比”变量移入检验变量框中。
表示要求该变量的均值的区间估计。
从源变量清单中将“饲料”变量移入分组变量框中。
表示总体的分类变量。
图3.4 独立样本T检验对话框♦定义分组单击定义组按钮,打开Define Groups 对话框。
在Group1 中输入A,在Group2 中输入B (A表示饲料A,B表示饲料B)。
图3.5 定义组define groups设置窗口完成后单击“继续”按钮返回到“独立样本T检验”对话框。
♦确定置信水平单击“独立样本T检验”对话框右上方的“选项”按钮,弹出“独立样本T检验:选项”对话框,图3.6 “独立样本T检验:选项”对话框确定置信区间为95%,单击“继续”按钮返回到“独立样本T检验”对话框。
♦计算结果单击“确定”按钮,输出结果如下图所示。
(1)Group Statistics(分组统计量)表分别给出不同总体下的样本容量、均值、标准差和平均标准误。
从该表中可以看出,A饲料的平均增重为2.8500,B饲料的平均增重为3.1700。
表3.2 分组统计量饲料N Mean Std. Deviation Std. Error Mean料重比 A 10 2.8500 .27877 .08815B 9 3.1700 .32867 .10956(2)Independent Sample Test (独立样本T 检验)表表3.3 独立样本T检验结果Independent Samples TestLevene's Test for Equality ofVariances方差齐性检验t-test for Equality of Means检验总体均值是否相等的t 检验95% ConfidenceInterval of theDifferenceF Sig. t dfSig.(2-tailed)MeanDifferenceStd. ErrorDifferenceLower Upper料重比Equal variancesassumed等方差假设.275 .607 -2.296 17 .035 -.32000 .13935 -.61399 -.02601Independent Samples TestLevene's Test for Equality ofVariances方差齐性检验t-test for Equality of Means检验总体均值是否相等的t 检验95% ConfidenceInterval of theDifferenceF Sig. t dfSig.(2-tailed)MeanDifferenceStd. ErrorDifferenceLower Upper料重比Equal variancesassumed等方差假设.275 .607 -2.296 17 .035 -.32000 .13935 -.61399 -.02601Equal variancesnot assumed不等方差假设-2.276 15.818 .037 -.32000 .14062 -.61838 -.02162结果说明,在当前抽样方式下,由样本均数差值-.32000(A饲料的平均增重2.8500与B饲料的平均增重3.1700之差。
)估计两种饲料喂猪的总体增重水平差值有95%的可能性在-.61399与-.02601之间。
T检验结果:⑴方差同质性检验:F值为0.275,其概率P=0.670>0.05,表明两未知总体方差差异不显著,可按照等方差假设进行检验。
(Levene检验统计量W服从自由度为 1=k-1, 2=N-k的F分布。
)⑵检验:t 值为-2.296,其概率P=0.035<0.05,表明B饲料增重效果显著地好于A饲料。
⑶置信区间为-.61399与-.02601,推断总体参数的差异为0的可能性很小。
实验四:t检验一、实验目的与要求1. 理解t 检验的基本原理和用途2. 熟练掌握T检验的SPSS操作3. 学会利用T检验方法解决身边的实际问题二、实验原理●有三类t 检验可用:✧独立样本t 检验(双样本t 检验)。
利用成组设计获取样本数据,比较一个变量中两组个案的均值,以推断两组个案所在总体的差异是否显著。
提供了每组的描述统计和Levene 方差相等性检验,以及相等和不等方差t 值和均值差分的95% 置信区间。
✧配对样本t 检验(相关t 检验)。
利用配对设计获取成对样本数据,比较单个组的两个变量的均值。
此检验还用于匹配对或个案控制研究设计。
输出包括检验变量的描述统计、变量之间的相关性、配对差分的描述统计、t 检验和95% 置信区间。
✧单样本t 检验。
将一个变量的均值与已知值或假设值进行比较。
检验变量的描述统计随t 检验一起显示。
检验变量的均值和假设的检验值之间差的95% 置信区间是缺省输出的一部分。
三、实验演示内容与步骤㈠独立样本t 检验在“实验三”内容里“2.两个总体均值之差的区间估计”中,已完成独立样本t检验的操作,大家可重复其操作步骤,以熟练操作步骤。
应记住独立样本t检验的数据结构,可在SPSS中创建数据文件,也可以在EXCEL中创建数据文件。
独立样本t检验的重点在于先根据方差齐性检验的结果,确定方差的同质性,再选择t检验的结果。
㈡配对样本t 检验【课本例5.7 】在研究饮食中缺乏维生素E 与肝中维生素A 的关系时,将试验动物按性别、体重等配成8对,并将每对中的两头试验动物用随机分配法分配在正常饲料组和维生素E 缺乏组,然后将试验动物杀死,测定其肝中的维生素A 的含量,其结果如下表,试检验两组饲料对试验动物肝脏中维生素A 含量的作正常饲料组3550 2000 3000 3950 3800 3750 3450 3050 维生素E 缺乏组2450 2400 1800 3200 3250 2700 2500 1750♦选择菜单“【分析】→【比较均值】→【配对样本T检验】”,弹出“配对样本T检验”对话框,图4.1 “配对样本T检验”菜单选择图4.2 “配对样本T检验”对话框Paired-Samples T Tes如图4.2所示,将两个配对变量移入右边的成对变量Pair Variables列表框中。
移动的方法是先选择其中的一个配对变量,再选择第二个配对变量,接着单击中间的箭头按钮。
♦选项按钮的用于设置置信度选项,这里保持系统默认的95%♦在主对话框中单击ok按钮,执行操作。
♦在输出视图中看分析结果表4.1 两组饲料饲养后样本肝中的维生素A 的含量的描述统计量Paired Samples StatisticsMean N Std. Deviation Std. Error Mean正常饲料组3318.75 8 632.420 223.594Pair 1维生素E缺乏组2506.25 8 555.130 196.268表3.4给出了两组饲料饲养后样本肝中的维生素A 的含量的均值、标准差、均值标准误差。