计量经济学10(1)
- 格式:ppt
- 大小:871.50 KB
- 文档页数:18

第一章1、什么是计量经济学?计量经济学方法与一般经济学方法有什么区别?解答计量经济学是经济学的一个分支学科,以揭示经济活动中客观存在的经济关系为主要内容,是由经济理论、统计学、数学三者结合而成的交叉性学科。
计量经济学方法揭示经济活动中具有因果关系的各因素间的定量关系,它用随机性的数学方程加以描述;而一般经济数学方法揭示经济活动中各因素间的理论关系,更多的用确定性的数学方程加以描述。
2、计量经济学的研究对象和内容是什么?计量经济学模型研究的经济关系有哪两个基本特征?解答计量经济学的研究对象是经济现象,主要研究经济现象中的具体数量规律,换言之,计量经济学是利用数学方法,根据统计测定的经济数据,对反映经济现象本质的经济数量关系进行研究。
计量经济学的内容大致包括两个方面:一是方法论,即计量经济学方法或理论计量经济学;二是应用,即应用计量经济学。
无论理论计量经济学还是应用计量经济学,都包括理论、方法和数据三要素。
计量经济学模型研究的经济关系有两个基本特征:一是随机关系,二是因果关系。
3、为什么说计量经济学在当代经济学科中占据重要地位?当代计量经济学发展的基本特征与动向是什么?解答计量经济学子20世纪20年代末30年代初形成以来,无论在技术方法上还是在应用方面发展都十分迅速,尤其是经过20世纪50年代的发展阶段和20世纪60年代的扩张阶段,计量经济学在经济学科中占据了重要的地位,主要表现在以下几点。
第一,在西方大多数大学和学院中,计量经济学的讲授已成为经济学课程中最具有权威性的一部分。
第二,1969-2003诺贝尔经济学奖的53位获奖者中有10位于研究和应用计量经济学有关,居经济学各分支学科之首。
除此之外,绝大多数诺贝尔经济学奖获得者,即使其主要贡献不在计量经济学领域,但在他们的研究中都普遍的应用了计量经济学方法。
著名经济学家、诺贝尔经济学奖获得者萨缪尔森曾说过:“第二次世界大战后的经济学是计量经济学的时代。

第二篇时间序列数据的回归分析第10章时间序列数据的基本回归分析10.1 复习笔记考点一:时间序列数据★★1.时间序列数据与横截面数据的区别(1)时间序列数据集是按照时间顺序排列。
(2)时间序列数据与横截面数据被视为随机结果的原因不同。
(3)一个时间序列过程的所有可能的实现集,便相当于横截面分析中的总体。
时间序列数据集的样本容量就是所观察变量的时期数。
2.时间序列模型的主要类型(见表10-1)表10-1 时间序列模型的主要类型考点二:经典假设下OLS的有限样本性质★★★★1.高斯-马尔可夫定理假设(见表10-2)表10-2 高斯-马尔可夫定理假设2.OLS估计量的性质与高斯-马尔可夫定理(见表10-3)表10-3 OLS估计量的性质与高斯-马尔可夫定理3.经典线性模型假定下的推断(1)假定TS.6(正态性)假定误差u t独立于X,且具有独立同分布Normal(0,σ2)。
该假定蕴涵了假定TS.3、TS.4和TS.5,但它更强,因为它还假定了独立性和正态性。
(2)定理10.5(正态抽样分布)在时间序列的CLM假定TS.1~TS.6下,以X为条件,OLS估计量遵循正态分布。
而且,在虚拟假设下,每个t统计量服从t分布,F统计量服从F分布,通常构造的置信区间也是确当的。
定理10.5意味着,当假定TS.1~TS.6成立时,横截面回归估计与推断的全部结论都可以直接应用到时间序列回归中。
这样t统计量可以用来检验个别解释变量的统计显著性,F统计量可以用来检验联合显著性。
考点三:时间序列的应用★★★★★1.函数形式、虚拟变量除了常见的线性函数形式,其他函数形式也可以应用于时间序列中。
最重要的是自然对数,在应用研究中经常出现具有恒定百分比效应的时间序列回归。
虚拟变量也可以应用在时间序列的回归中,如某一期的数据出现系统差别时,可以采用虚拟变量的形式。
2.趋势和季节性(1)描述有趋势的时间序列的方法(见表10-4)表10-4 描述有趋势的时间序列的方法(2)回归中的趋势变量由于某些无法观测的趋势因素可能同时影响被解释变量与解释变量,被解释变量与解释变量均随时间变化而变化,容易得到被解释变量与解释变量之间趋势变量的关系,而非真正的相关关系,导致了伪回归。

第一章 绪论1.1 一般说来,计量经济分析按照以下步骤进行:(1)陈述理论(或假说) (2)建立计量经济模型 (3)收集数据(4)估计参数 (5)假设检验 (6)预测和政策分析 1.2 我们在计量经济模型中列出了影响因变量的解释变量,但它(它们)仅是影响因变量的主要因素,还有很多对因变量有影响的因素,它们相对而言不那么重要,因而未被包括在模型中。
为了使模型更现实,我们有必要在模型中引进扰动项u 来代表所有影响因变量的其它因素,这些因素包括相对而言不重要因而未被引入模型的变量,以及纯粹的随机因素。
1.3时间序列数据是按时间周期(即按固定的时间间隔)收集的数据,如年度或季度的国民生产总值、就业、货币供给、财政赤字或某人一生中每年的收入都是时间序列的例子。
横截面数据是在同一时点收集的不同个体(如个人、公司、国家等)的数据。
如人口普查数据、世界各国2000年国民生产总值、全班学生计量经济学成绩等都是横截面数据的例子。
1.4 估计量是指一个公式或方法,它告诉人们怎样用手中样本所提供的信息去估计总体参数。
在一项应用中,依据估计量算出的一个具体的数值,称为估计值。
如Y 就是一个估计量,1nii YY n==∑。
现有一样本,共4个数,100,104,96,130,则根据这个样本的数据运用均值估计量得出的均值估计值为5.107413096104100=+++。
第二章 计量经济分析的统计学基础2.1 略,参考教材。
2.2N SS x ==45=1.25 用α=0.05,N-1=15个自由度查表得005.0t =2.947,故99%置信限为x S t X 005.0± =174±2.947×1.25=174±3.684也就是说,根据样本,我们有99%的把握说,北京男高中生的平均身高在170.316至177.684厘米之间。
2.3 原假设120:0=μH备择假设120:1≠μH检验统计量()10/25XX μσ-Z ====查表96.1025.0=Z 因为Z= 5 >96.1025.0=Z ,故拒绝原假设, 即此样本不是取自一个均值为120元、标准差为10元的正态总体。


一、解释概念:1、多重共线性:是指在多元线性回归模型中,解释变量之间存在的线性关系。
2、SRF:就是样本回归函数。
即是将样本应变量的条件均值表示为解释变量的某种函数。
3、解释变量的边际贡献:在回归模型中新加入一个解释变量所引起的回归平方和或者拟合优度的增加值。
4、一阶偏相关系数:反映一个经济变量与某个经济变量的线性相关程度时,剔除另一个变量对它们的影响的真实相关程度的指标。
5、最小方差准则:在模型参数估计时,应当选择其抽样分布具有最小方差的估计式,该原则就是最佳性准则,或者称为最小方差准则。
6、OLS:普通最小二乘估计。
是利用残差平方和为最小来求解回归模型参数的参数估计方法。
7、偏相关系数:反映一个经济变量与某个经济变量的线性相关程度时,剔除其它变量(部分或者全部变量)对它们的影响的真实相关程度的指标。
8、WLS:加权最小二乘法。
是指估计回归方程参数时,按照残差平方加权求和最小的原则进行的估计方法。
9、U t自相关:即回归模型中随机误差项逐项值之间的相关。
即Cov(U t,U s)≠0 t ≠s。
10、二阶偏相关系数:反映一个经济变量与某个经济变量的线性相关程度时,剔除另两个变量对它们的影响的真实相关程度的指标。
11、技术方程式:根据生产技术关系建立的计量经济模型。
13、零阶偏相关系数:反映一个经济变量与某个经济变量的线性相关程度时,不剔除任何变量对它们的影响的相关程度的指标。
也就是简单相关系数。
14、经验加权法:是根据实际经济问题的特点及经验判断,对滞后经济变量赋予一定的权数,利用这些权数构成各滞后变量的线性组合,以形成新的变量,再用最小二乘法进行参数估计的有限分布滞后模型的修正估计方法。
15、虚拟变量:在计量经济学中,我们把取值为0和1 的人工变量称为虚拟变量,用字母D表示。
(或称为属性变量、双值变量、类型变量、定性变量、二元型变量)16、不完全多重共线性:是指在多元线性回归模型中,解释变量之间存在的近似的线性关系。

计量经济学书后答案书第1 10章----d9239f6d-6ebb-11ec-a63b-7cb59b590d7d计量经济学书后答案--书第1-10章第一章导言1.计量经济学是一门什么样的学科?答:计量经济学的英文单词是econometrics,它最初的意思是“计量经济学”。
它研究经济问题的计量经济学方法,因此有时被翻译成“计量经济学”。
计量经济学被翻译成“计量经济学”,以强调它是现代经济学的一个分支。
不仅要研究经济问题的计量经济学方法,还要研究经济问题发展变化的数量规律。
可以认为,计量经济学是以经济理论为指导,以经济数据为依据,以数学、统计方法为手段,通过建立、估计、检验经济模型,揭示客观经济活动中存在的随机因果关系的一门应用经济学的分支学科。
2.计量经济学与经济理论、数学和统计学之间有什么联系和区别?答:计量经济学是经济理论、数学、统计学的结合,是经济学、数学、统计学的交叉学科(或边缘学科)。
计量经济学与经济学、数学、统计学的联系主要是计量经济学对这些学科的应用。
计量经济学对经济学的应用主要体现在以下几个方面:第一,计量经济学模型的选择和确定,包括对变量和经济模型的选择,需要经济学理论提供依据和思路;第二,计量经济分析中对经济模型的修改和调整,如改变函数形式、增减变量等,需要有经济理论的指导和把握;第三,计量经济分析结果的解读和应用也需要经济理论提供基础、背景和思路。
计量经济学对统计学的应用,至少有两个重要方面:一是计量经济分析所采用的数据的收集与处理、参数的估计等,需要使用统计学的方法和技术来完成;一是参数估计值、模型的预测结果的可靠性,需要使用统计方法加以分析、判断。
计量经济学对数学的应用也是多方面的,首先,对非线性函数进行线性转化的方法和技巧,是数学在计量经济学中的应用;其次,任何的参数估计归根结底都是数学运算,较复杂的参数估计方法,或者较复杂的模型的参数估计,更需要相当的数学知识和数学运算能力,另外,在计量经济理论和方法的研究方面,需要用到许多的数学知识和原理。

![计量期末试卷(10[1].07)](https://uimg.taocdn.com/912ebd7ca26925c52cc5bf96.webp)
内蒙古财经学院2009—2010学年第二学期《计量经济学》期末试卷姓名: 班级: 学号:一、单选题(1分×20=20分)请将答案填写到下面的表格中。
1、为了分析随着解释变量变动一个单位,因变量的增长率变化情况,模型应该设定为( ) A. lnY=1β+2βlnX +u B. u X Y ++=ln 10ββ C. u X Y ++=10ln αα D. i Y =i X 21ββ+i u +2、设21,x x 为解释变量,则完全多重共线性是( ).(021.0.021.22121121=+=++==+x x e x D v v x x C e x B x x A 为随机误差项) 3、多元线性回归模型中,发现各参数估计量的t 值都不显著,但模型的,)(22很大或R R F 值确很显著,这说明模型存在( )A .多重共线性B .异方差C .自相关D .设定偏误4、DW 检验中要求有假定条件,在下列条件中不正确的是( )A .解释变量为非随机的 B. 随机误差项为一阶自回归形式C .线性回归模型中不应含有滞后内生变量为解释变量 D. 线性回归模型为一元回归形式5、假设估计出的库伊克模型如下:则( )916.1143897.0)91.11()70.4()6521.2(76.035.09.6ˆ21===-=++-=-DW F R t Y X Y t t tA.分布滞后系数的衰减率为0.34B.在显著性水平05.0=α下,DW 检验临界值为3.1=l d ,由于3.1916.1=<=l d d ,据此可以推断模型扰动项存在自相关C.即期消费倾向为0.35,表明收入每增加1元,当期的消费将增加0.35元D.收入对消费的长期影响乘数为1-t Y 的估计系数0.766、Goldfeld-Quandt 检验法可用于检验( )A.异方差性B.多重共线性C.序列相关D.设定误差 7、用于检验序列相关的DW 统计量的取值范围是( )A. 0≤DW ≤1B.-1≤DW ≤1C. -2≤DW ≤2D.0≤DW ≤4 8、20、回归分析中定义的( )A.解释变量和被解释变量都是随机变量B.解释变量为非随机变量,被解释变量为随机变量C.解释变量和被解释变量都为非随机变量D.解释变量为随机变量,被解释变量为非随机变量 9、在模型t t t t u X X Y +++=33221βββ的回归分析结果报告中,有23.263489=F ,000000.0=值的p F ,则表明( )A 、解释变量t X 2 对t Y 的影响是显著的B 、解释变量t X 3对t Y 的影响是显著的C 、解释变量t X 2和t X 3对t Y 的联合影响是显著的.D 、解释变量t X 2和t X 3对t Y 的影响是均不显著10、如果回归模型中解释变量之间存在完全的多重共线性,则最小二乘估计量( ) A.不确定,方差无限大 B.确定,方差无限大 C.不确定,方差最小 D.确定,方差最小 11、关于可决系数2R ,以下说法中错误的是( D )A.可决系数2R 的定义为被回归方程已经解释的变差与总变差之比 B. 可决系数2R 的大小不受到回归模型中所包含的解释变量个数的影响C.可决系数2R 反映了样本回归线对样本观测值拟合优劣程度的一种描述D. []102,∈R 12、在具体运用加权最小二乘法时, 如果变换的结果是x ux x x 1xy 21+β+β=则Var(u)是下列形式中的哪一种?( )13、时间序列数据大多存在序列相关性,在分布滞后模型中,这种序列相关性就转化为( ) A .异方差问题 B. 多重共线性问题 C .序列相关性问题 D. 模型设定误差 14、根据可决系数R2与F 统计量的关系可知,当R 2=1时有( )。


第10章时间序列数据的基本回归分析10.1复习笔记一、时间序列数据的性质时间序列数据与横截面数据的区别:(1)时间序列数据集是按照时间顺序排列。
(2)时间序列数据与横截面数据被视为随机结果的原因不同。
①横截面数据应该被视为随机结果,因为从总体中抽取不同的样本,通常会得到自变量和因变量的不同取值。
因此,通过不同的随机样本计算出来的OLS估计值通常也有所不同,这就是OLS统计量是随机变量的原因。
②经济时间序列满足作为随机变量是因为其结果无法事先预知,因此可以被视为随机变量。
一个标有时间脚标的随机变量序列被称为一个随机过程或时间序列过程。
搜集到一个时间序列数据集时,便得到该随机过程的一个可能结果或实现。
因为不能让时间倒转重新开始这个过程,所以只能看到一个实现。
如果特定历史条件有所不同,通常会得到这个随机过程的另一种不同的实现,这正是时间序列数据被看成随机变量之结果的原因。
(3)一个时间序列过程的所有可能的实现集,便相当于横截面分析中的总体。
时间序列数据集的样本容量就是所观察变量的时期数。
二、时间序列回归模型的例子1.静态模型假使有两个变量的时间序列数据,并对y t和z t标注相同的时期。
把y和z联系起来的一个静态模型(staticmodel)为:10 1 2 t t t y z u t nββ=++=⋯,,,,“静态模型”的名称来源于正在模型化y 和z 同期关系的事实。
若认为z 在时间t 的一个变化对y 有影响,即1t t y z β∆=∆,那么可以将y 和z 设定为一个静态模型。
一个静态模型的例子是静态菲利普斯曲线。
在一个静态回归模型中也可以有几个解释变量。
2.有限分布滞后模型(1)有限分布滞后模型有限分布滞后模型(finitedistributedlagmodel,FDL)是指一个或多个变量对y 的影响有一定时滞的模型。
考察如下模型:001122t t t t ty z z z u αδδδ--=++++它是一个二阶FDL。
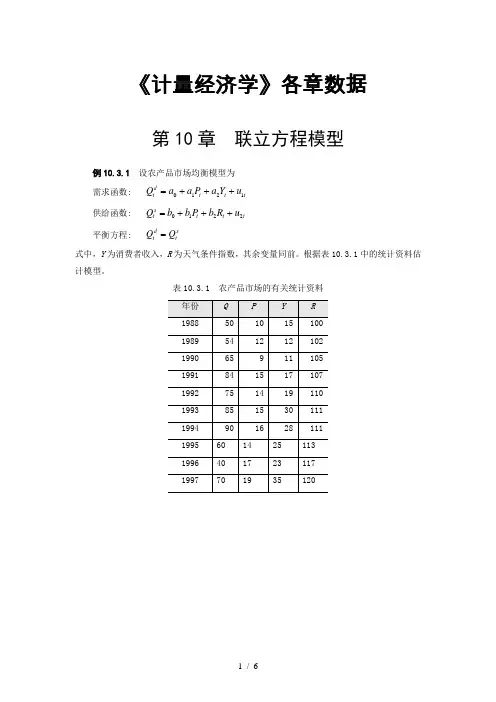
《计量经济学》各章数据第10章 联立方程模型例10.3.1 设农产品市场均衡模型为需求函数: t t t dt u Y a P a a Q 1210+++= 供给函数: t t t st u R b P b b Q 2210+++= 平衡方程: st d t Q Q =式中,Y 为消费者收入,R 为天气条件指数,其余变量同前。
根据表10.3.1中的统计资料估计模型。
表10.3.1 农产品市场的有关统计资料10.5 案例分析10.5.1 中国宏观经济模型中国1978-2003年居民宏观消费CONS、国内生产总值GDP、国内投资总额INV、政府支出GOV、净出口NEX(单位:亿元)统计数据,如表10.5.1所示:表10.5.1 中国宏观经济统计数据10.5.2 克莱因战争间模型根据美国1920~1941年的统计资料,如表10.5.6所示。
用2SLS和系统估计法等方法对模型参数进行估计。
表10.5.6 美国1920~1941年的统计数据思考与练习17.设我国的价格、消费、工资模型设定为t t t u I a a W 110++= t t t Pt u W b I b b C 2210+++= t pt t t t u C W I P 33210++++=γγγγ其中:I =固定资产投资(亿元);W =国营企业职工年平均工资(元);C =居民消费水平指数(%);P =价格指数(%)。
C 、P 均以上年为100%。
样本观察值如表2所示:表2 固定资产投资、职工平均工资与居民消费指数等统计资料(1)用递归模型参数估计法求出该模型的估计式;(2)用普通最小二乘法逐一估计每个方程;(3)比较以上两种做法的结果。
18.表3是我国1978-2003年国内生产总值(GDP )、货币供给量(2M )、政府支出(G )和投资支出(I )的统计资料,试用表中数据建立我国的收入——货币供给模型:t t t t t u G a I a M a a GDP 132210++++= t t t t u M b GDP b b M 2122102+++=-(1)判别模型的识别性。
计量经济学知识点1.假设检验:在计量经济学中,研究者通常会提出一些假设,然后使用统计方法来检验这些假设的有效性。
例如,研究者可能提出一个关于变量之间关系的假设,并使用样本数据来检验这个假设是否成立。
2.回归分析:回归分析是计量经济学中一种常用的统计方法,用于分析因变量与自变量之间的关系。
通过回归分析,研究者可以确定自变量对因变量的影响程度,并进一步预测因变量的数值。
回归模型的选择和估计是计量经济学中的核心内容之一3.模型设定:在计量经济学中,研究者通常会基于对经济理论的理解来设定一个经济模型,并使用实证分析来验证模型的有效性。
模型设定是计量经济学研究的第一步,决定了后续研究的方向和方法。
4.面板数据分析:面板数据是一种具有时间序列和截面维度的数据,可以用于研究变量的动态关系。
在面板数据分析中,研究者可以使用固定效应模型或者随机效应模型来估计变量的影响。
5.工具变量法:工具变量法是计量经济学中一种常用的估计方法,用于解决内生性问题。
内生性问题是由于自变量和误差项之间的相关性而导致的估计结果不准确的问题,在工具变量法中,研究者使用一个与自变量相关但与误差项无关的变量作为工具变量来解决内生性问题。
6.时间序列分析:时间序列分析是计量经济学中研究时间序列数据的方法。
研究者可以使用时间序列模型来分析和预测经济变量的发展趋势和波动性。
常用的时间序列模型包括ARMA模型、ARIMA模型等。
7.异方差问题:异方差问题是指误差项的方差不是恒定的,而是与自变量或其他变量相关的情况。
异方差问题会导致估计结果的不准确性,在计量经济学中,研究者可以使用加权最小二乘法或者稳健标准误等方法来解决异方差问题。
8.时间序列平稳性:时间序列平稳性是指时间序列数据的均值和方差在时间上不发生系统性的变化。
平稳时间序列数据能够提供可靠的统计推断结果,因此在时间序列分析中需要对数据的平稳性进行检验。
9.效应估计方法:在计量经济学中,研究者通常会使用OLS估计法来估计参数的值。
计量经济学第⼗章习题(龚志民)fixed第10章模型设定与实践问题10.1 模型设定误差有哪些类型?如何诊断?答:模型设定误差主要有以下四种类型:1.漏掉⼀个相关变量;2.包含⼀个⽆关的变量;3.错误的函数形式;4.对误差项的错误假定。
诊断的⽅法有:1.侦察是否含有⽆关变量;2.残差分析,拉姆齐(Ramsey)的RESET检验法,DM(Davidsion-MacKinnon:戴维森麦-克⾦龙)检验;3.拟合优度、校正拟合优度、系数显著性、系数符合的合理性。
10.2 模型遗漏相关变量的后果是什么?答:模型遗漏相关变量的后果是:所有回归系数的估计量是有偏的,除⾮这个被去除的变量与每⼀个放⼊的变量都不相关。
常数估计量通常也是有偏的,从⽽预测值是有偏的。
由于放⼊变量的回归系数估计量是有偏的,所以假设检验是⽆效的。
系数估计量的⽅差估计量是有偏的。
10.3 模型包含不相关变量的后果是什么?答:模型包含不相关变量的后果是:系数估计量的⽅差变⼤,从⽽估计量的精度下降。
10.4 什么是嵌套模型?什么是⾮嵌套模型?答:如果两个模型不能被互相包容,即任何⼀个都不是另⼀个的特殊情形,便称这两个模型是⾮嵌套的。
如果两个模型能互相包容,即其中⼀个是另⼀个的特殊情形,便称这两个模型是嵌套的。
10.5 ⾮嵌套模型之间的⽐较有哪些⽅法?答:⾮嵌套模型之间的⽐较⽅法有:拟合优度或校正拟合优度、AIC(Akaike’s information criterion)准则、SIC(Schwarz’s information criterion)准则和HQ(Hannnan-Qinn criterion)准则。
拉姆齐(Ramsey)的RESET检验法,DM(Davidsion-MacKinnon:戴维森麦-克⾦龙)检验。
习题10.6 对数线性模型在⼈⼒资源⽂献中有⽐较⼴泛的应⽤,其理论建议把⼯资或收⼊的对数作为因变量。
如果教育投资收益率为r ,则接受⼀年教育的⼯资为10(1)w r w =+,0w 是基准⼯资(未接受教育)。
∕∙E10.1∙∕USe w C:∖Us∙ε≡∖asus∖D^9⅛top∖Guns.dta wset BlOXe OrCXwet scateid yrar∕a HP/GCn InViC e ln(ViO)reg InViO ShaIlrXeat a tore CIIreg InViO Shail incarc rate density avginc POP pblO64 PMlO^4 FnlO2$λXC3t >torc n2/∙(2>*/×τx⅞q InVIO shall InCarCeraτe αe∏8ity avgιnc FOP 匸Q1064 PV丄034 FlIUJ20. r⅜ ι (scaτ⅜i3) eσt StOre ∏3∕∙(3M∕xτxeσ InVXo □ħall incarcerate dcn□ιty arcme rop rb丄064 rv!061 匸nu」29, tc ι(Vear)est StOre »4κcxeg InVlo shall incarcerate density avcxnc FOP FbIO64 E乜丄064 FlrLB J29 ι.yea∑ 工・ataceιdrIe VCe(XObUSOeat 3tore m3catcab XInUn3 Di4i 比5 U0ing IIVIPaaI9iC3t∙zzι,JC∑2 a∑2(⅞>/*(4>*/gen InXCt=In(XCO)reσ InXCt shall, Zest store alreσ InXCt SnalI incarcerate avαιno PCr Dr丄064 pxl064 r<ιl029, Xest store a2XCXeg Inrob □nall InCarCeraZe αcnaιty avgιnc FOP pi>lD64 丄064 FBUJ29. re ι(0CaZeIaI eat atore a3×τx⅞g InrOb SnalI InCarCe raτe α⅜naιty avgιnc FOP pi>1064 PVIOe4 FBU^29fr« ι(y⅛ar)eat 3tore d£×LX⅜9 InXOb Shall InCarC xaZe ClenslLy avginc POP fI>1064 PVlO€4 PMLL929 丄・year !.・SLazeldrXe VCe(XQbUSCl e□t StOre aSestcab al ∂2 a3 a4 aS USlng soaad.rtf Se r2 ar214>gen InnUr^丄二(EIUr)reg InnUC 9hall, rt>t ∙tor⅜ DXreg InnUr shall incarc rate density avginc pop DbIo64 PXIO6⅛ ral029#T37⅜>t sror∙ b238xτrcg InirUr 3bdll incarc-raτe density avjinc POP rιbl064 pwl0€4 rml029, fe i (ata^cid)39⅛β‰ 8LOX⅛ b340xτrcσ 丄ΠXUH ShaIL InCaXC e xcτc αcnsιt5* avjιnc POP rb-061 PW(1064 Zm-O29#fc ι (year)41esr a^ore b442xτxeg .nxux shall InCaXC_xaτe αensιty avgιnc POP Fb-O64 PW丄064 PlrUo29 工・year 工・staτexdrf e VCe (XCbXIsx⅛43est StOre b544«fttaD bl b2 Q3 D4 匕5 UBXng sorrow・rcr•■冷∑2a∑2(4)铝∕∙E10.2t∕4€us« n CAuSVXsXasusXC^skcopVSeacBelus.ατα∙47 ×zscz firs year45/<(1)*/49gen In^n□oas=-n(xnocine)50reg fatalityrate sperd65 5peed*0 be08 drinkβgc IninCOBr βoe, r5丄*st ιror∙CI52/∙(2)*/53×zxeg XazallLyxaze ∂t>-u∂vαg* βρ⅛<⅛αc5 ap⅛⅛α70 ^a08 Oxlnlugv IninCooC ag⅜rf⅛ 1 (flpaf54Unt □core c255∕*(3)∙∕Se xτreg ±a^alιtyxate SbeUSeage SPee^feS apeed70 ca08 drxnk2ge InXnCo∞ age =・yea∑ 丄・tips, fe VCe(XotU3t> est store c3 Se ∕∙ (5»∙/59 San vwτ€0∕∙(«)∙/61XCa nbβu□ecσe PXXriary 3econdary 0ceed6S opeed70 baO8 dr3∏teσc2丄丄mr:COaLC aςc, r62esr S^Ore c4€3 Xtreg SbS Udeage PrIXaXy secondary GPCea65 apcεd70 ba J8 e∑xnkage2丄InXnCCiae age 丄.year 丄.±ιpsr±e VCe(robust!C4 est Store c5CS ⅞∙ttΛD CI C2 C3 C4 CS UBLna cn∙∙xupi∙r = i■■芒r2 ⅛∑2 (⅜)66/∙E11.1*/67us« M CΛus<eX3∖a9us∖C'⅛skcop∖Sπ^lClng.dta∙68/∙(1>*/£9Suin IC sxtt>an≡=l70t ZeSZ 9ΛZ ke∑ x± 3n3^er≡=∙r by ιe≡Jccan)丄evel(9S>71IogOUtrnd化(1) VOreI IePleCe: Ctest 3≡0ker if 3Λckrr-JΛ by (3t1kban) IeVel (95)/* (2)*/reg SmolCeX SIrJcfoan. ∑ est StOre dl /A ∣3)a /gen age2-ace*agereg SinojCeJr SlrJCban female age age2 hsdrop hsgrad CCISoXle CClgrad 匕JLa=IC hi ∙spanic f X est StOre 02∕Λ (4)A ∕CeSt ( asιkfcan =0)log©Ut r sav# (2} Werd replace: t ⅜βt ( SInkban ≡0)∕a IS)a /二USC ( hsdxop -0) ( hsgcαd -0)IOgOUt r save (3∣ WCrd replace: test ( hsdxcp ≡0)( hsgrad ≡0) test ( COlscire ≡0) ( COIarad ≡0)IogOUC r 3dve (<i) WOXcl replace: teat ( COISCmC ∙0∣ ( COLgIad ≡0∣ ∕* (€)a /tuoway(fαnction y ■ O. D345∙戈-0.0G0463a x ∙x + O. l∈4r rang<⅛ (18 65)) /<E11.2*/ /*ID*/PrObit ainokGr omkban female age agc2 hadxcj: hagrad colaoxtc COIgXad black hlspanic, VCe ∣∑cbu3^) est Store d3esttaD aι 02 α3 USIng ιcan.rtr,Se r2 ar2 ∣⅞) ∕*(2)Vtest ( 9ΛkkAn ≡0)loσout^ SaVe (51 VCrCi replace: teat ( Snkran ≡0)/A (3)Vteat ( hadxcp ≡0)( hograd ≡0) IOgOUt r sav# (β) VCrd r ⅜plac^! t ⅜st ( h≡drcp ≡0)( hsgrad ≡0) ZeSt ( COlScrce ≡0)( COLgraa ≡□)IOgOUC r 30Ve (7) WQXd replace; teat ( GO 13GXΠC -Ol ( ColgXad —0)∕∙E11.3∙∕Ufle R C:\Uaeis\d3Us\Des)C5Op\lnauxance.<ltβt, ∕∙ (1)∙∕CteSt SelIemP Ir InSUrea≡≡ιr Dy(SelrenX)IeVeI195)ICCOUt^ SaVe (8)WOra replace: CteSt SelleliD Ir InSUreα≡≡ι, Dy(Seirerrr )Ievei(95) ttest SeIfenP If InSUred≡≡3z by(selfe∏r )IeVeI ∣95) rec InSUred SeIfemp, rStOr» 八(2)*/ger age2=ag^t ageXeg InSUXed SeIfemP age a?e2 healthy anyIin XIale deg nd deg ged deg hs deg baCeg_Phd deg_oxh Xarried familysz Xeg_ne Xeg_nv reg_SO reg_We race_hl XaCe_Ot XaCe_Wht r r est StOXe e2 ∕* (4)>∕gen age*selfenp=age* sel£expreg InOUXCd □clfemp age age2 CgUXSUafUItF healthy anyliΛ nale deg nd CCg gcd deg hn deg ba deg Ila deg Phd deg_Oth XarrXeQ fartilyoz Xeg ne reg mw reg ^□ Zeg We XoCC bI XaCe Ot race wh ∙r e□t stOXe c3∕* (5)w ∕Xeg heclthy 3elfeΛp r £ esc acoxe e4Xeg ħedlchy aelCemp age ag±2r Xeat StoXe eδIeC neaιt ħy SeIreInP aαe aαe2 any 丄IItl πi ∂ie aea_na dea_aea aea_ns aea_Da CeC e IIA aβσ-p ħa aea_Otn Harrleelramιiysz rej βne reo__niw re ς-ao Tea_We race -bi race -ot race -w ħt^ r est store e6esttab ¢1 e2 e3 e4 e5 e6 using end ∙rtf.se r2 ar2 (4)∣72 73 74 75 7€ 777879 80aι82 03 8485ββ 87 898990 919293 94 &59697 9B gg IOQ 101 102 103 104丄05106 10? 108 109 110 111 112 113 114 115 IIe 117 118 119 120 121 122 123 0丄23126 12? 128E10.1(1) lnvio (2) lnvio (3) lnvio (4) lnvio (5) lnvioshall -0.443***-0.368***-0.0461 *-0.288***-0.0280(0.0475) (0.0348) (0.0189) (0.0337) (0.0278)incarc_rate 0.00161***-0.0000710 0.00193***0.0000760(0.000181) (0.0000936) (0.000114) (0.0000720)density 0.0267 -0.172*-0.00887 -0.0916(0.0143) (0.0850) (0.0139) (0.0485)avginc 0.00121 -0.00920 0.0129 0.000959(0.00728) (0.00591) (0.00796) (0.00729)pop 0.0427***0.0115 0.0408***-0.00475(0.00315) (0.00872) (0.00252) (0.00781)pb1064 0.0809***0.104***0.1000***0.0292(0.0200) (0.0178) (0.0182) (0.0183)pw1064 0.0312**0.0409***0.0401***0.00925(0.00973) (0.00507) (0.00912) (0.00538)pm1029 0.00887 -0.0503 ***-0.0444 *0.0733***(0.0121) (0.00640) (0.0175) (0.0129)_cons 6.135*** 2.982*** 3.866*** 2.948*** 4.348***(0.0193) (0.609) (0.385) (0.569) (0.435)N 1173 1173 1173 1173 11730.087 0.564 0.218 0.580 0.955R2adj. R20.0859 0.5613 0.1771 0.5690 0.9525State Effects No No Yes No YesTime Effects No No No Yes YesStandard errors in parentheses* p < 0.10, ** p < 0.05, *** p < 0.01(1)①回归(2)中shall 的系数是-0.368 ,这意味着隐蔽武器法律,也即“准予”携带法律,约使暴力犯罪减少36.8% 。