计量经济学(第四版)习题及参考答案详细版
- 格式:doc
- 大小:688.00 KB
- 文档页数:25

李子奈《计量经济学》(第4版)笔记和课后习题(含考研真题)详解李子奈《计量经济学》(第4版)笔记和课后习题详解第1章绪论一、计量经济学1计量经济学计量经济学,又称经济计量学,是由经济理论、统计学和数学结合而成的一门经济学的分支学科,其研究内容是分析经济现象中客观存在的数量关系。
2计量经济学模型(1)模型分类模型是对现实生活现象的描述和模拟。
根据描述和模拟办法的不同,对模型进行分类,如表1-1所示。
表1-1 模型分类(2)数理经济模型和计量经济学模型的区别①研究内容不同数理经济模型的研究内容是经济现象各因素之间的理论关系,计量经济学模型的研究内容是经济现象各因素之间的定量关系。
②描述和模拟办法不同数理经济模型的描述和模拟办法主要是确定性的数学形式,计量经济学模型的描述和模拟办法主要是随机性的数学形式。
③位置和作用不同数理经济模型可用于对研究对象的初步研究,计量经济学模型可用于对研究对象的深入研究。
3计量经济学的内容体系(1)根据所应用的数理统计方法划分广义计量经济学根据所应用的数理统计方法包括回归分析方法、投入产出分析方法、时间序列分析方法等;狭义计量经济学所应用的数理统计方法主要是回归分析方法。
需要注意的是,通常所述的计量经济学指的是狭义计量经济学。
(2)根据内容深度划分初级计量经济学的主要研究内容是计量经济学的数理统计学基础知识和经典的线性单方程计量经济学模型理论与方法;中级计量经济学的主要研究内容是用矩阵描述的经典的线性单方程计量经济学模型理论与方法、经典的线性联立方程计量经济学模型理论与方法,以及传统的应用模型;高级计量经济学的主要研究内容是非经典的、现代的计量经济学模型理论、方法与应用。
(3)根据研究目标和研究重点划分理论计量经济学的主要研究目标是计量经济学的理论与方法的介绍与研究;应用计量经济学的主要研究目标是计量经济学模型的建立与应用。
理论计量经济学的研究重点是理论与方法的数学证明与推导;应用计量经济学的研究重点是建立和应用计量模型处理实际问题。

计量经济学(第四版)习题参考答案第一章 绪论1.1 一般说来,计量经济分析按照以下步骤进行:(1)陈述理论(或假说) (2)建立计量经济模型 (3)收集数据 (4)估计参数 (5)假设检验 (6)预测和政策分析1.2 我们在计量经济模型中列出了影响因变量的解释变量,但它(它们)仅是影响因变量的主要因素,还有很多对因变量有影响的因素,它们相对而言不那么重要,因而未被包括在模型中。
为了使模型更现实,我们有必要在模型中引进扰动项u 来代表所有影响因变量的其它因素,这些因素包括相对而言不重要因而未被引入模型的变量,以及纯粹的随机因素。
1.3时间序列数据是按时间周期(即按固定的时间间隔)收集的数据,如年度或季度的国民生产总值、就业、货币供给、财政赤字或某人一生中每年的收入都是时间序列的例子。
横截面数据是在同一时点收集的不同个体(如个人、公司、国家等)的数据。
如人口普查数据、世界各国2000年国民生产总值、全班学生计量经济学成绩等都是横截面数据的例子。
1.4 估计量是指一个公式或方法,它告诉人们怎样用手中样本所提供的信息去估计总体参数。
在一项应用中,依据估计量算出的一个具体的数值,称为估计值。
如Y 就是一个估计量,1nii YY n==∑。
现有一样本,共4个数,100,104,96,130,则根据这个样本的数据运用均值估计量得出的均值估计值为5.107413096104100=+++。
第二章 计量经济分析的统计学基础2.1 略,参考教材。
2.2 NS S x ==45=1.25 用α=0.05,N-1=15个自由度查表得005.0t =2.947,故99%置信限为 x S t X 005.0± =174±2.947×1.25=174±3.684也就是说,根据样本,我们有99%的把握说,北京男高中生的平均身高在170.316至177.684厘米之间。
2.3 原假设 120:0=μH备择假设 120:1≠μH 检验统计量()10/25XX μσ-Z ====查表96.1025.0=Z 因为Z= 5 >96.1025.0=Z ,故拒绝原假设, 即此样本不是取自一个均值为120元、标准差为10元的正态总体。

伍德里奇-计量经济学(第4版)答案计量经济学答案第二章2.4 (1)在实验的准备过程中,我们要随机安排小时数,这样小时数(hours )可以独立于其它影响SAT 成绩的因素。
然后,我们收集实验中每个学生SAT 成绩的相关信息,产生一个数据集{}n i hours sat i i ,...2,1:),(=,n 是实验中学生的数量。
从式(2.7)中,我们应尽量获得较多可行的i hours 变量。
(2)因素:与生俱来的能力(天赋)、家庭收入、考试当天的健康状况①如果我们认为天赋高的学生不需要准备SAT 考试,那天赋(ability )与小时数(hours )之间是负相关。
②家庭收入与小时数之间可能是正相关,因为收入水平高的家庭更容易支付起备考课程的费用。
③排除慢性健康问题,考试当天的健康问题与SAT 备考课程上的小时数(hours )大致不相关。
(3)如果备考课程有效,1β应该是正的:其他因素不变情况下,增加备考课程时间会提高SAT 成绩。
(4)0β在这个例子中有一个很有用的解释:因为E (u )=0,0β是那些在备考课程上花费小时数为0的学生的SAT平均成绩。
2.7(1)是的。
如果住房离垃圾焚化炉很近会压低房屋的价格,如果住房离垃圾焚化炉距离远则房屋的价格会高。
(2)如果城市选择将垃圾焚化炉放置在距离昂贵的街区较远的地方,那么log(dist)与房屋价格就是正相关的。
也就是说方程中u包含的因素(例如焚化炉的地理位置等)和距离(dist)相关,则E(u︱log(dist))≠0。
这就违背SLR4(零条件均值假设),而且最小二乘法估计可能有偏。
(3)房屋面积,浴室的数量,地段大小,屋龄,社区的质量(包括学校的质量)等因素,正如第(2)问所提到的,这些因素都与距离焚化炉的远近(dist,log(dist))相关2.11(1)当cigs(孕妇每天抽烟根数)=0时,预计婴儿出生体重=110.77盎司;当cigs(孕妇每天抽烟根数)=20时,预计婴儿出生体重(bwght)=109.49盎司。
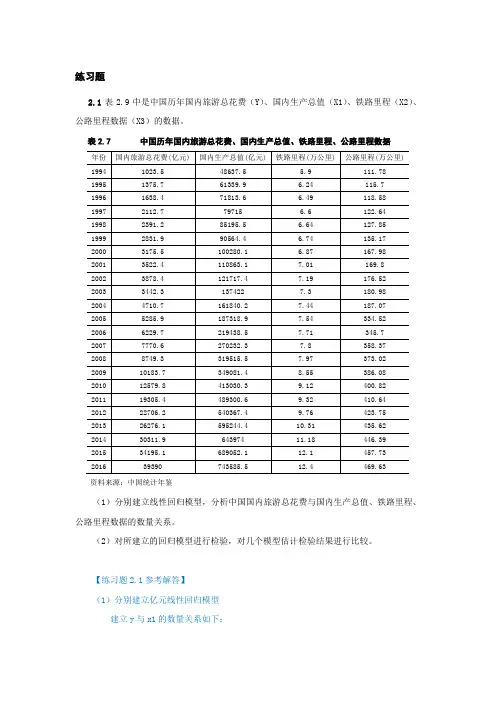
练习题2.1表2.9中是中国历年国内旅游总花费(Y)、国内生产总值(X1)、铁路里程(X2)、公路里程数据(X3)的数据。
表2.7 中国历年国内旅游总花费、国内生产总值、铁路里程、公路里程数据资料来源:中国统计年鉴(1)分别建立线性回归模型,分析中国国内旅游总花费与国内生产总值、铁路里程、公路里程数据的数量关系。
(2)对所建立的回归模型进行检验,对几个模型估计检验结果进行比较。
【练习题2.1参考解答】(1)分别建立亿元线性回归模型建立y与x1的数量关系如下:建立y与x2的数量关系如下:建立y与x3的数量关系如下:(2)对所建立的回归模型进行检验,对几个模型估计检验结果进行比较。
关于中国国内旅游总花费与国内生产总值模型,由上可知,,说明所建模型整体上对样本数据拟合较好。
对于回归系数的t检验:,对斜率系数的显著性检验表明,GDP 对中国国内旅游总花费有显著影响。
同理:关于中国国内旅游总花费与铁路里程模型,由上可知,,说明所建模型整体上对样本数据拟合较好。
对于回归系数的t检验:,对斜率系数的显著性检验表明,铁路里程对中国国内旅游总花费有显著影响。
关于中国国内旅游总花费与公路里程模型,由上可知,,说明所建模型整体上对样本数据拟合较好。
对于回归系数的t检验:,对斜率系数的显著性检验表明,公路里程对中国国内旅游总花费有显著影响。
2.2为了研究浙江省一般预算总收入与地区生产总值的关系,由浙江省统计年鉴得到如表2.8所示的数据。
年份一般预算总收入(亿元)地区生产总值(亿元)年份一般预算总收入(亿元)地区生产总值(亿元)Y X Y X 197827.45123.721998 401.80 5052.62 197925.87157.751999 477.40 5443.92198031.13179.922000 658.42 6141.03 198134.34204.862001 917.76 6898.34 198236.64234.012002 1166.58 8003.67 198341.79257.092003 1468.89 9705.02 198446.67323.252004 1805.16 11648.70 198558.25429.162005 2115.36 13417.68 198668.61502.472006 2567.66 15718.47 198776.36606.992007 3239.89 18753.73 198885.55770.252008 3730.06 21462.69 198998.21849.442009 4122.04 22998.24 1990101.59904.692010 4895.41 27747.65 1991108.941089.332011 5925.00 32363.38 1992118.361375.702012 6408.49 34739.13 1993166.641925.912013 6908.41 37756.58 1994209.392689.282014 7421.70 40173.03 1995 248.50 3557.55 2015 8549.47 42886.49 1996 291.75 4188.53 2016 9225.07 47251.36 1997 340.52 4686.11(1)建立浙江省一般预算收入与全省地区生产总值的计量经济模型,估计模型的参数,检验模型的显著性,用规范的形式写出估计检验结果,并解释所估计参数的经济意义(2)如果2017年,浙江省地区生产总值为52000亿元,比上年增长10%,利用计量经济模型对浙江省2017年的一般预算收入做出点预测和区间预测(3)建立浙江省一般预算收入的对数与地区生产总值对数的计量经济模型,估计模型的参数,检验模型的显著性,并解释所估计参数的经济意义。

庞皓计量经济学练习题及参考解答第四版Document serial number【UU89WT-UU98YT-UU8CB-UUUT-UUT108】练习题表中是中国历年国内旅游总花费(Y)、国内生产总值(X1)、铁路里程(X2)、公路里程数据(X3)的数据。
表中国历年国内旅游总花费、国内生产总值、铁路里程、公路里程数据资料来源:中国统计年鉴(1)分别建立线性回归模型,分析中国国内旅游总花费与国内生产总值、铁路里程、公路里程数据的数量关系。
(2)对所建立的回归模型进行检验,对几个模型估计检验结果进行比较。
【练习题参考解答】(1)分别建立亿元线性回归模型建立y与x1的数量关系如下:ŶY=−3228.02+0.05X1i建立y与x2的数量关系如下:ŶY=−39438.73+6165.25X1i建立y与x3的数量关系如下:ŶY=−9106.17+71.64X1i(2)对所建立的回归模型进行检验,对几个模型估计检验结果进行比较。
关于中国国内旅游总花费与国内生产总值模型,由上可知,Y2=0.987,说明所建模型整体上对样本数据拟合较好。
对于回归系数的t检验:t(β1)=21.68>Y(21)=2.08,对斜率系0.025数的显着性检验表明,GDP对中国国内旅游总花费有显着影响。
同理:关于中国国内旅游总花费与铁路里程模型,由上可知,Y2= 0.971,说明所建模型整体上对样本数据拟合较好。
对于回归系数的t检验:t(β1)=26.50>Y(21)=2.08,对斜率系0.025数的显着性检验表明,铁路里程对中国国内旅游总花费有显着影响。
关于中国国内旅游总花费与公路里程模型,由上可知,Y2=0.701,说明所建模型整体上对样本数据拟合较好。
对于回归系数的t检验:t(β1)=7.02>Y(21)=2.08,对斜率系0.025数的显着性检验表明,公路里程对中国国内旅游总花费有显着影响。
为了研究浙江省一般预算总收入与地区生产总值的关系,由浙江省统计年鉴得到如表所示的数据。

计量经济学(第四版)习题参考答案潘省初第一章 绪论1.1 试列出计量经济分析的主要步骤。
一般说来,计量经济分析按照以下步骤进行:(1)陈述理论(或假说) (2)建立计量经济模型 (3)收集数据 (4)估计参数 (5)假设检验 (6)预测和政策分析 1.2 计量经济模型中为何要包括扰动项?为了使模型更现实,我们有必要在模型中引进扰动项u 来代表所有影响因变量的其它因素,这些因素包括相对而言不重要因而未被引入模型的变量,以及纯粹的随机因素。
1.3什么是时间序列和横截面数据? 试举例说明二者的区别。
时间序列数据是按时间周期(即按固定的时间间隔)收集的数据,如年度或季度的国民生产总值、就业、货币供给、财政赤字或某人一生中每年的收入都是时间序列的例子。
横截面数据是在同一时点收集的不同个体(如个人、公司、国家等)的数据。
如人口普查数据、世界各国2000年国民生产总值、全班学生计量经济学成绩等都是横截面数据的例子。
1.4估计量和估计值有何区别?估计量是指一个公式或方法,它告诉人们怎样用手中样本所提供的信息去估计总体参数。
在一项应用中,依据估计量算出的一个具体的数值,称为估计值。
如Y就是一个估计量,1nii YY n==∑。
现有一样本,共4个数,100,104,96,130,则根据这个样本的数据运用均值估计量得出的均值估计值为5.107413096104100=+++。
第二章 计量经济分析的统计学基础2.1 略,参考教材。
2.2请用例2.2中的数据求北京男生平均身高的99%置信区间NSS x ==45=1.25 用α=0.05,N-1=15个自由度查表得005.0t =2.947,故99%置信限为 x S t X 005.0± =174±2.947×1.25=174±3.684也就是说,根据样本,我们有99%的把握说,北京男高中生的平均身高在170.316至177.684厘米之间。

庞皓计量经济学练习题及参考解答第四版目录1.简介2.练习题及解答–第一章:引言–第二章:回归分析的基本步骤–第三章:多元回归分析–第四章:假设检验和检定–第五章:函数形式选择和非线性回归–第六章:虚拟变量和联合假设检验–第七章:时间序列回归分析–第八章:面板数据回归分析–第九章:工具变量法–第十章:极大似然估计3.总结1. 简介《庞皓计量经济学练习题及参考解答第四版》是一本与《庞皓计量经济学》教材配套的习题集,旨在帮助读者巩固和加深对计量经济学理论和方法的理解。
本书第四版相比前三版进行了全面的修订和更新,更加贴近实际应用环境,同时也增加了一些新的内容。
本文档为《庞皓计量经济学练习题及参考解答第四版》的摘要,包含了各章节的练习题及参考解答。
2. 练习题及解答第一章:引言1.什么是计量经济学?计量经济学的研究范围是什么?–答案:计量经济学是运用统计学方法研究经济理论及实证问题的学科。
它主要研究经济学中的理论模型和假设是否能得到实证支持,对经济变量之间的关系进行定量分析和预测。
2.计量经济学中常用的方法有哪些?–答案:常用的计量经济学方法包括线性回归分析、假设检验、面板数据分析、时间序列分析等。
这些方法能够帮助研究者解决实际经济问题,预测经济变量,评估政策效果等。
第二章:回归分析的基本步骤1.请解释什么是回归分析?–答案:回归分析是一种研究因变量和自变量之间关系的统计方法。
通过建立一个数学模型来描述二者之间的函数关系,并利用样本数据对该函数关系进行估计和推断。
回归分析的基本思想是找到自变量对因变量的解释能力,并进行统计推断。
2.利用最小二乘法进行回归分析的基本思想是什么?–答案:基本思想是通过最小化预测值与实际观测值之间的差异,来确定最佳的参数估计值。
也就是说,最小二乘法通过选择一组参数,使得预测值与实际观测值之间的平方差最小化。
3.如何判断回归模型的拟合优度?–答案:拟合优度可以通过判断回归方程的决定系数R2来评估。

计量经济学(第四版)习题参考答案潘省初第一章 绪论1.1 试列出计量经济分析的主要步骤。
一般说来,计量经济分析按照以下步骤进行:(1)陈述理论(或假说) (2)建立计量经济模型 (3)收集数据 (4)估计参数 (5)假设检验 (6)预测和政策分析 1.2 计量经济模型中为何要包括扰动项?为了使模型更现实,我们有必要在模型中引进扰动项u 来代表所有影响因变量的其它因素,这些因素包括相对而言不重要因而未被引入模型的变量,以及纯粹的随机因素。
1.3什么是时间序列和横截面数据? 试举例说明二者的区别。
时间序列数据是按时间周期(即按固定的时间间隔)收集的数据,如年度或季度的国民生产总值、就业、货币供给、财政赤字或某人一生中每年的收入都是时间序列的例子。
横截面数据是在同一时点收集的不同个体(如个人、公司、国家等)的数据。
如人口普查数据、世界各国2000年国民生产总值、全班学生计量经济学成绩等都是横截面数据的例子。
1.4估计量和估计值有何区别?估计量是指一个公式或方法,它告诉人们怎样用手中样本所提供的信息去估计总体参数。
在一项应用中,依据估计量算出的一个具体的数值,称为估计值。
如Y就是一个估计量,1nii YY n==∑。
现有一样本,共4个数,100,104,96,130,则根据这个样本的数据运用均值估计量得出的均值估计值为5.107413096104100=+++。
第二章 计量经济分析的统计学基础2.1 略,参考教材。
2.2请用例2.2中的数据求北京男生平均身高的99%置信区间NS S x ==45=1.25 用α=0.05,N-1=15个自由度查表得005.0t =2.947,故99%置信限为 x S t X 005.0± =174±2.947×1.25=174±3.684也就是说,根据样本,我们有99%的把握说,北京男高中生的平均身高在170.316至177.684厘米之间。
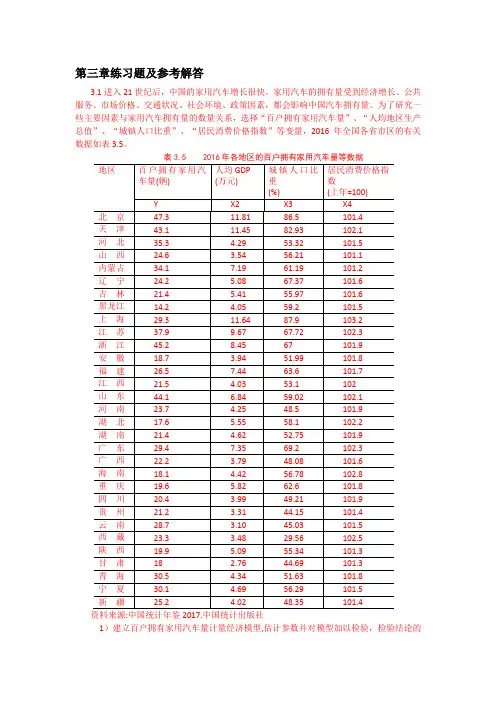
第三章练习题及参考解答3.1进入21世纪后,中国的家用汽车增长很快。
家用汽车的拥有量受到经济增长、公共服务、市场价格、交通状况、社会环境、政策因素,都会影响中国汽车拥有量。
为了研究一些主要因素与家用汽车拥有量的数量关系,选择“百户拥有家用汽车量”、“人均地区生产总值”、“城镇人口比重”、“居民消费价格指数”等变量,2016年全国各省市区的有关数据如表3.5。
表3.5 2016年各地区的百户拥有家用汽车量等数据资料来源:中国统计年鉴2017.中国统计出版社1)建立百户拥有家用汽车量计量经济模型,估计参数并对模型加以检验,检验结论的依据是什么?。
2)分析模型参数估计结果的经济意义,你如何解读模型估计检验的结果? 3) 你认为模型还可以如何改进?【练习题3.1 参考解答】:1)建立线性回归模型: 1223344t t t t t Y X X X u ββββ=++++ 回归结果如下:由F 统计量为14.69998, P 值为0.000007,可判断模型整体上显著, “人均地区生产总值”、“城镇人口比重”、“居民消费价格指数”等变量联合起来对百户拥有家用汽车量有显著影响。
解释变量参数的t 统计量的绝对值均大于临界值0.025(27) 2.052t =,或P 值均明显小于0.05α=,表明在其他变量不变的情况下,“人均地区生产总值”、“城镇人口比重”、“居民消费价格指数”分别对百户拥有家用汽车量都有显著影响。
2)X2的参数估计值为4.8117,表明随着经济的增长,人均地区生产总值每增加1万元,平均说来百户拥有家用汽车量将增加近5辆。
由于城镇公共交通的大力发展,有减少家用汽车的必要性,X3的参数估计值为-0.4449,表明随着城镇化的推进,“城镇人口比重”每增加1%,平均说来百户拥有家用汽车量将减少0.4449辆。
汽车价格和使用费用的提高将抑制家用汽车的使用, X4的参数估计值为-5.7685,表明随着家用汽车使用成本的提高, “居民消费价格指数”每增加1个百分点,平均说来百户拥有家用汽车量将减少5.7685辆。

第四章练习题及参考解答4.1 假设在模型i i i i u X X Y +++=33221βββ中,32X X 与之间的相关系数为零,有人建议你分别进行如下回归:1221i i i Y X u αα=++ 1332i i i Y X u γγ=++(1) 是否存在3322ˆˆˆˆβγβα==且?为什么? (2) 1ˆβ会等于1ˆα或1ˆγ或者两者的某个线性组合吗? (3) 是否有()()22ˆˆVar Var βα=且()()33ˆˆVar Var βγ=?【练习题4.1参考解答】(1) 存在2233ˆˆˆˆαβγβ==且 。
因为 ()()()()()()()22332322222323ˆi iii ii iiii iy x x y x x x x x x x β-=-∑∑∑∑∑∑∑当23X X 与 之间的相关系数为零时,离差形式的230i ix x =∑有 ()()()()223222222223ˆˆi i ii i iiiy x x y x xx x βα===∑∑∑∑∑∑ 同理有: 33ˆˆγβ= (2)会的。
(3) 存在 ()()()()2233ˆˆˆˆvar var var var βαβγ==且 因为 ()()2222223ˆvar 1ix r σβ=-∑当 230r = 时, ()()()22222222223ˆˆvar var 1iix x r σσβα===-∑∑ 同理,有 ()()33ˆˆvar var βγ=4.2 表4.4给出了1995—2016年中国商品进口额Y 、国生产总值GDP 、居民消费价格指数CPI 的数据。
表4.4 中国商品进口额、国生产总值、居民消费价格指数资料来源:《中国统计年鉴2017》考虑建立模型: i t t t u CPI GDP Y ++=ln ln ln 321βββ+ (1)利用表中数据估计此模型的参数。
(2)你认为数据中有多重共线性吗?(3)进行以下回归:121ln ln t t i Y A A GDP v =++ 122ln ln t t i Y B B CPI v =++ 123ln ln t t i GDP C C CPI v =++ 根据这些回归你能对多重共线性的性质有什么认识?(4)假设经检验数据有多重共线性,但模型中32ˆˆββ和在5%水平上显著,并且F 检验也显著,你对此模型的应用有何建议?【练习题4.2参考解答】建立模型: i t t t u CPI GDP Y ++=ln ln ln 321βββ+ (1)利用表中数据估计此模型的参数。

第一章导论第一节什么是计量经济学计量经济学是现代经济学的重要分支。
为了深入学习计量经济学的理论与方法,有必要首先从整体上对计量经济学有一些概略性的认识,了解计量经济学的性质、基本思想、基本研究方法以及若干常用的基本概念。
一、计量经济学的产生与发展在对实际经济问题的研究中,经常需要对经济活动及其数量变动规律作定量的分析。
例如,为了研究中国经济的增长,需要分析中国国内生产总值(GDP)变动的状况? 分析有哪些主要因素会影响中国GDP的增长?分析中国的GDP与各种主要影响因素关系的性质是什么?分析各种因素对中国GDP影响的程度和具体数量规律是什么?分析所得到的数量分析结果的可靠性如何?还要分析经济增长的政策效应,或者预测中国GDP发展的趋势。
显然,对这类经济问题的定量分析,需要解决一些共性问题:提出所研究的经济问题及度量方式,确定表现研究对象的经济变量(如用GDP的变动度量经济的增长);分析对研究对象变动有影响的主要因素,选择若干作为影响因素的变量;分析各种影响因素与所研究经济现象相互关系的性质,决定相互联系的数学关系式;运用科学的数量分析方法,确定所研究的经济对象与各种影响因素间具体的数量规律;运用统计方法分析和检验所得数量结论的可靠性;运用数量研究的结果作经济分析和预测。
对社会经济问题数量规律的研究具有普遍性,计量经济学是专门研究这类问题的经济学科。
计量经济学(Econometrics)这个词是挪威经济学家、第一届诺贝尔经济学奖获得者弗瑞希(R.Frisch)在其1926年发表的《论纯经济问题》一文中,按照”生物计量学”(Biometrics)一词的结构仿造出来的。
Econometrics一词的本意是指“经济度量”,研究对经济现象和经济关系的计量方法,因此有时也译为“经济计量学”。
将Econometrics译为计量经济学,是为了强调计量经济学是一门经济学科,不仅要研究经济现象的计量方法,而且要研究经济现象发展变化的数量规律。
庞皓计量经济学练习题及参考解答第四版Document serial number【UU89WT-UU98YT-UU8CB-UUUT-UUT108】练习题表中是中国历年国内旅游总花费(Y)、国内生产总值(X1)、铁路里程(X2)、公路里程数据(X3)的数据。
表中国历年国内旅游总花费、国内生产总值、铁路里程、公路里程数据资料来源:中国统计年鉴(1)分别建立线性回归模型,分析中国国内旅游总花费与国内生产总值、铁路里程、公路里程数据的数量关系。
(2)对所建立的回归模型进行检验,对几个模型估计检验结果进行比较。
【练习题参考解答】(1)分别建立亿元线性回归模型建立y与x1的数量关系如下:ŶY=−3228.02+0.05X1i建立y与x2的数量关系如下:ŶY=−39438.73+6165.25X1i建立y与x3的数量关系如下:ŶY=−9106.17+71.64X1i(2)对所建立的回归模型进行检验,对几个模型估计检验结果进行比较。
关于中国国内旅游总花费与国内生产总值模型,由上可知,Y2=0.987,说明所建模型整体上对样本数据拟合较好。
对于回归系数的t检验:t(β1)=21.68>Y(21)=2.08,对斜率系0.025数的显着性检验表明,GDP对中国国内旅游总花费有显着影响。
同理:关于中国国内旅游总花费与铁路里程模型,由上可知,Y2= 0.971,说明所建模型整体上对样本数据拟合较好。
对于回归系数的t检验:t(β1)=26.50>Y(21)=2.08,对斜率系0.025数的显着性检验表明,铁路里程对中国国内旅游总花费有显着影响。
关于中国国内旅游总花费与公路里程模型,由上可知,Y2=0.701,说明所建模型整体上对样本数据拟合较好。
对于回归系数的t检验:t(β1)=7.02>Y(21)=2.08,对斜率系0.025数的显着性检验表明,公路里程对中国国内旅游总花费有显着影响。
为了研究浙江省一般预算总收入与地区生产总值的关系,由浙江省统计年鉴得到如表所示的数据。
计量经济学(第四版)习题参考答案潘省初第一章 绪论1.1 试列出计量经济分析的主要步骤。
一般说来,计量经济分析按照以下步骤进行:(1)陈述理论(或假说) (2)建立计量经济模型 (3)收集数据 (4)估计参数 (5)假设检验 (6)预测和政策分析 1.2 计量经济模型中为何要包括扰动项?为了使模型更现实,我们有必要在模型中引进扰动项u 来代表所有影响因变量的其它因素,这些因素包括相对而言不重要因而未被引入模型的变量,以及纯粹的随机因素。
1.3什么是时间序列和横截面数据? 试举例说明二者的区别。
时间序列数据是按时间周期(即按固定的时间间隔)收集的数据,如年度或季度的国民生产总值、就业、货币供给、财政赤字或某人一生中每年的收入都是时间序列的例子。
横截面数据是在同一时点收集的不同个体(如个人、公司、国家等)的数据。
如人口普查数据、世界各国2000年国民生产总值、全班学生计量经济学成绩等都是横截面数据的例子。
1.4估计量和估计值有何区别?估计量是指一个公式或方法,它告诉人们怎样用手中样本所提供的信息去估计总体参数。
在一项应用中,依据估计量算出的一个具体的数值,称为估计值。
如Y 就是一个估计量,1nii YY n==∑。
现有一样本,共4个数,100,104,96,130,则根据这个样本的数据运用均值估计量得出的均值估计值为5.107413096104100=+++。
第二章 计量经济分析的统计学基础2.1 略,参考教材。
2.2请用例2.2中的数据求北京男生平均身高的99%置信区间NSS x ==45=1.25 用α=0.05,N-1=15个自由度查表得005.0t =2.947,故99%置信限为 x S t X 005.0± =174±2.947×1.25=174±3.684也就是说,根据样本,我们有99%的把握说,北京男高中生的平均身高在170.316至177.684厘米之间。
第七章练习题及参考解答表中给出了1981-2015年中国城镇居民人均年消费支出(PCE)和城镇居民人均可支配收入(PDI)数据。
表 1981-2015年中国城镇居民消费支出(PCE)和可支配收入(PDI)数据(单位:元)估计下列模型:(1) 解释这两个回归模型的结果。
(2) 短期和长期边际消费倾向(MPC)是多少分析该地区消费同收入的关系。
(3) 建立适当的分布滞后模型,用库伊克变换转换为库伊克模型后进行估计,并对估计结果进行分析判断。
【练习题参考解答】(1) 解释这两个回归模型的结果。
Dependent Variable: PCEMethod: Least SquaresDate: 03/10/18 Time: 09:12Sample: 1981 2005Included observations: 25Variable CoefficientStd.Errort-StatisticProb.CPDIR-squared Mean dependentvarAdjusted R-squared . dependent var. of regression Akaike infocriterionSum squared resid Schwarz criterionLog likelihood F-statisticDurbin-Watsonstat Prob(F-statistic)收入跟消费间有显着关系。
收入每增加1元,消费增加元。
Dependent Variable: PCEMethod: Least SquaresDate: 03/10/18 Time: 09:13Sample(adjusted): 1982 2005Included observations: 24 after adjusting endpointsVariable CoefficientStd.Errort-StatisticProb.C PDIPCE(-1)R-squared Mean dependentvarAdjusted R-squared . dependent var. of regression Akaike infocriterionSum squared resid Schwarz criterionLog likelihood F-statisticDurbin-Watsonstat Prob(F-statistic)(2) 短期和长期边际消费倾向(MPC)是多少分析该地区消费同收入的关系。
计量经济学(第四版)习题参考答案潘省初第一章 绪论1.1 试列出计量经济分析的主要步骤。
一般说来,计量经济分析按照以下步骤进行:(1)陈述理论(或假说) (2)建立计量经济模型 (3)收集数据 (4)估计参数 (5)假设检验 (6)预测和政策分析 1.2 计量经济模型中为何要包括扰动项?为了使模型更现实,我们有必要在模型中引进扰动项u 来代表所有影响因变量的其它因素,这些因素包括相对而言不重要因而未被引入模型的变量,以及纯粹的随机因素。
1.3什么是时间序列和横截面数据? 试举例说明二者的区别。
时间序列数据是按时间周期(即按固定的时间间隔)收集的数据,如年度或季度的国民生产总值、就业、货币供给、财政赤字或某人一生中每年的收入都是时间序列的例子。
横截面数据是在同一时点收集的不同个体(如个人、公司、国家等)的数据。
如人口普查数据、世界各国2000年国民生产总值、全班学生计量经济学成绩等都是横截面数据的例子。
1.4估计量和估计值有何区别?估计量是指一个公式或方法,它告诉人们怎样用手中样本所提供的信息去估计总体参数。
在一项应用中,依据估计量算出的一个具体的数值,称为估计值。
如Y就是一个估计量,1nii YY n==∑。
现有一样本,共4个数,100,104,96,130,则根据这个样本的数据运用均值估计量得出的均值估计值为5.107413096104100=+++。
第二章 计量经济分析的统计学基础2.1 略,参考教材。
2.2请用例2.2中的数据求北京男生平均身高的99%置信区间NS S x ==45=1.25 用α=0.05,N-1=15个自由度查表得005.0t =2.947,故99%置信限为 x S t X 005.0± =174±2.947×1.25=174±3.684也就是说,根据样本,我们有99%的把握说,北京男高中生的平均身高在170.316至177.684厘米之间。
伍德里奇-计量经济学(第4版)答案计量经济学答案第二章2.4 (1)在实验的准备过程中,我们要随机安排小时数,这样小时数(hours )可以独立于其它影响SAT 成绩的因素。
然后,我们收集实验中每个学生SAT 成绩的相关信息,产生一个数据集{}n i hours sat i i ,...2,1:),(=,n 是实验中学生的数量。
从式(2.7)中,我们应尽量获得较多可行的i hours 变量。
(2)因素:与生俱来的能力(天赋)、家庭收入、考试当天的健康状况①如果我们认为天赋高的学生不需要准备SAT 考试,那天赋(ability )与小时数(hours )之间是负相关。
②家庭收入与小时数之间可能是正相关,因为收入水平高的家庭更容易支付起备考课程的费用。
③排除慢性健康问题,考试当天的健康问题与SAT 备考课程上的小时数(hours )大致不相关。
(3)如果备考课程有效,1β应该是正的:其他因素不变情况下,增加备考课程时间会提高SAT 成绩。
(4)0β在这个例子中有一个很有用的解释:因为E (u )=0,0β是那些在备考课程上花费小时数为0的学生的SAT平均成绩。
2.7(1)是的。
如果住房离垃圾焚化炉很近会压低房屋的价格,如果住房离垃圾焚化炉距离远则房屋的价格会高。
(2)如果城市选择将垃圾焚化炉放置在距离昂贵的街区较远的地方,那么log(dist)与房屋价格就是正相关的。
也就是说方程中u包含的因素(例如焚化炉的地理位置等)和距离(dist)相关,则E(u︱log(dist))≠0。
这就违背SLR4(零条件均值假设),而且最小二乘法估计可能有偏。
(3)房屋面积,浴室的数量,地段大小,屋龄,社区的质量(包括学校的质量)等因素,正如第(2)问所提到的,这些因素都与距离焚化炉的远近(dist,log(dist))相关2.11(1)当cigs(孕妇每天抽烟根数)=0时,预计婴儿出生体重=110.77盎司;当cigs(孕妇每天抽烟根数)=20时,预计婴儿出生体重(bwght)=109.49盎司。
计量经济学(第四版)习题参考答案潘省初第一章 绪论1.1 试列出计量经济分析的主要步骤。
一般说来,计量经济分析按照以下步骤进行:(1)陈述理论(或假说) (2)建立计量经济模型 (3)收集数据 (4)估计参数 (5)假设检验 (6)预测和政策分析 1.2 计量经济模型中为何要包括扰动项?为了使模型更现实,我们有必要在模型中引进扰动项u 来代表所有影响因变量的其它因素,这些因素包括相对而言不重要因而未被引入模型的变量,以及纯粹的随机因素。
1.3什么是时间序列和横截面数据? 试举例说明二者的区别。
时间序列数据是按时间周期(即按固定的时间间隔)收集的数据,如年度或季度的国民生产总值、就业、货币供给、财政赤字或某人一生中每年的收入都是时间序列的例子。
横截面数据是在同一时点收集的不同个体(如个人、公司、国家等)的数据。
如人口普查数据、世界各国2000年国民生产总值、全班学生计量经济学成绩等都是横截面数据的例子。
1.4估计量和估计值有何区别?估计量是指一个公式或方法,它告诉人们怎样用手中样本所提供的信息去估计总体参数。
在一项应用中,依据估计量算出的一个具体的数值,称为估计值。
如Y就是一个估计量,1nii YY n==∑。
现有一样本,共4个数,100,104,96,130,则根据这个样本的数据运用均值估计量得出的均值估计值为5.107413096104100=+++。
第二章 计量经济分析的统计学基础2.1 略,参考教材。
2.2请用例2.2中的数据求北京男生平均身高的99%置信区间NSS x ==45=1.25 用α=0.05,N-1=15个自由度查表得005.0t =2.947,故99%置信限为 x S t X 005.0± =174±2.947×1.25=174±3.684也就是说,根据样本,我们有99%的把握说,北京男高中生的平均身高在170.316至177.684厘米之间。
2.3 25个雇员的随机样本的平均周薪为130元,试问此样本是否取自一个均值为120元、标准差为10元的正态总体? 原假设 120:0=μH备择假设 120:1≠μH 检验统计量()10/25XX μσ-Z ====查表96.1025.0=Z 因为Z= 5 >96.1025.0=Z ,故拒绝原假设, 即 此样本不是取自一个均值为120元、标准差为10元的正态总体。
2.4 某月对零售商店的调查结果表明,市郊食品店的月平均销售额为2500元,在下一个月份中,取出16个这种食品店的一个样本,其月平均销售额为2600元,销售额的标准差为480元。
试问能否得出结论,从上次调查以来,平均月销售额已经发生了变化? 原假设 : 2500:0=μH备择假设 : 2500:1≠μH()100/1200.83ˆX X t μσ-==== 查表得 131.2)116(025.0=-t 因为t = 0.83 < 131.2=c t , 故接受原假 设,即从上次调查以来,平均月销售额没有发生变化。
第三章 双变量线性回归模型3.1 判断题(说明对错;如果错误,则予以更正) (1)OLS 法是使残差平方和最小化的估计方法。
对(2)计算OLS 估计值无需古典线性回归模型的基本假定。
对(3)若线性回归模型满足假设条件(1)~(4),但扰动项不服从正态分布,则尽管OLS 估计量不再是BLUE ,但仍为无偏估计量。
错只要线性回归模型满足假设条件(1)~(4),OLS 估计量就是BLUE 。
(4)最小二乘斜率系数的假设检验所依据的是t 分布,要求βˆ的抽样分布是正态分布。
对(5)R 2=TSS/ESS 。
错R 2 =ESS/TSS 。
(6)若回归模型中无截距项,则0≠∑t e 。
对(7)若原假设未被拒绝,则它为真。
错。
我们可以说的是,手头的数据不允许我们拒绝原假设。
(8)在双变量回归中,2σ的值越大,斜率系数的方差越大。
错。
因为∑=22)ˆ(tx Var σβ,只有当∑2t x 保持恒定时,上述说法才正确。
3.2设YXβˆ和XY βˆ分别表示Y 对X 和X 对Y 的OLS 回归中的斜率,证明 YXβˆXY βˆ=2r r 为X 和Y 的相关系数。
证明:22222222ˆˆ()ˆˆi ii ii i YXXYiiii i YX XYi i x y y x x yxyyx y x yr x y ββββ===⎛⎫⋅===∑∑∑∑∑∑∑∑∑3.3证明:(1)Y 的真实值与OLS 拟合值有共同的均值,即Y nY nY ==∑∑ˆ;(2)OLS 残差与拟合值不相关,即 0ˆ=∑tt eY 。
(1),得两边除以,=n ˆ0ˆ)ˆ(ˆ∑∑∑∑∑∑∑∑=∴+=⇒+=⇒+=tt t tt t t tt t t t YY e e Y Y e YY e Y YY nY nY ==∑∑ˆ,即Y 的真实值和拟合值有共同的均值。
(2)的拟合值与残差无关。
,=,即因此,(教材中已证明),由于Y 0ˆˆ),ˆ(0ˆ0,0e ˆˆ)ˆˆ(ˆ22t∑∑∑∑∑∑∑∑∑∑====+=+=tttt tttt tt tt ttttt eY e Y e Y Cov e Ye X eX e e X e Y βαβα 3.4证明本章中(3.18)和(3.19)两式:(1)∑∑=222)ˆ(tt x n X Var σα(2)∑-=22)ˆ,ˆ(txX Cov σβα(1)222222222221112222222ˆˆ,ˆˆ()ˆˆˆ2u()()ˆ()2()()()()ˆ2()()ˆ2()iit tti n n n t ii j i ii j i ji j i jtY X Y X u u X u X X u u x uX X nn xu u u x u x u X X nn x uu u x ux x u u X nn x αβαβααββααββββββββββ≠≠=+=++-=---=--+-=-⋅⋅+-++=-⋅+-+++=-⋅+-∑∑∑∑∑∑∑∑∑∑∑()2X2222222222222222()ˆˆ2E()1(()2())()2i i j i i i j i j i j i j t i i j i j i i j i j i i i j i j i jt u u u x u x x u u E E XE X n n x u u u E E u E u u n n n nx u x x u u XE n x ααββσσ≠≠≠≠≠⎛⎫⎡⎤+++ ⎪⎢⎥-=-⎪⎢⎥ ⎪⎢⎥⎝⎭⎣⎦⎛⎫+ ⎪=+==⎪⎪⎝⎭++∑∑∑∑∑∑∑∑∑∑∑∑两边取期望值,有:()-+等式右端三项分别推导如下:22222222222222222222212(()()())200ˆE()()ˆ[]0ii i i j i j ii jt t t t tt tt x Xx E u x x E u u Xx n x n x X X x x nX X X E n x n x n x σσββσσσσαα≠⎛⎫ ⎪ ⎪⎪⎝⎭=++==-=+-=-+==∑∑∑∑∑∑∑∑∑∑∑∑∑(=)因此()∑∑=222)ˆ(tt x n X Var σα即(2)2222ˆˆ,ˆˆ()ˆˆˆˆˆˆ(,)[()][(())()]ˆˆ[(()][()]ˆ0()01ˆ()t Y X Y X u u X Cov E E u X E u XE XE XVar X x αβαβααββαβααβββββββββββββσ=+=++-=--=--=---=---=--=-=-∑()(第一项为的证明见本题())3.5考虑下列双变量模型: 模型1:i i i u X Y ++=21ββ模型2:i i i u X X Y +-+=)(21αα(1)β1和α1的OLS 估计量相同吗?它们的方差相等吗? (2)β2和α2的OLS 估计量相同吗?它们的方差相等吗?(1)X Y 21ˆˆββ-=,注意到 nx n x x x n x Var x n X Var Y x Y x x X X x ii i i ii i i i 22222221222121)()ˆ()ˆ(ˆˆ,0,0,σσσασβαα==-==-==-=∑∑∑∑∑∑∑==则我们有从而由上述结果,可以看到,无论是两个截距的估计量还是它们的方差都不相同。
(2)∑∑∑∑∑∑∑==---==222222222)ˆ()ˆ()())((ˆ,ˆiiiiiiiiii xVar Var xyx x x Y Y x x xy x σαβαβ=容易验证,这表明,两个斜率的估计量和方差都相同。
3.6有人使用1980-1994年度数据,研究汇率和相对价格的关系,得到如下结果:)333.1()22.1(:528.0318.4682.6ˆ2Se R X Yt t =-=其中,Y =马克对美元的汇率X =美、德两国消费者价格指数(CPI )之比,代表两国的相对价格 (1)请解释回归系数的含义; (2)X t 的系数为负值有经济意义吗?(3)如果我们重新定义X 为德国CPI 与美国CPI 之比,X 的符号会变化吗?为什么?(1)斜率的值 -4.318表明,在1980-1994期间,相对价格每上升一个单位,(GM/$)汇率下降约4.32个单位。
也就是说,美元贬值。
截距项6.682的含义是,如果相对价格为0,1美元可兑换6.682马克。
当然,这一解释没有经济意义。
(2)斜率系数为负符合经济理论和常识,因为如果美国价格上升快于德国,则美国消费者将倾向于买德国货,这就增大了对马克的需求,导致马克的升值。
(3)在这种情况下,斜率系数被预期为正数,因为,德国CPI 相对于美国CPI 越高,德国相对的通货膨胀就越高,这将导致美元对马克升值。
3.7随机调查200位男性的身高和体重,并用体重对身高进行回归,结果如下:)31.0()15.2(:81.031.126.76ˆ2Se R Height eight W =+-=其中Weight 的单位是磅(lb ),Height 的单位是厘米(cm )。
(1)当身高分别为177.67cm 、164.98cm 、187.82cm 时,对应的体重的拟合值为多少?(2)假设在一年中某人身高增高了3.81cm ,此人体重增加了多少? (1)78.16982.187*31.126.76ˆ86.13998.164*31.126.76ˆ49.15667.177*31.126.76ˆ=+-==+-==+-=eight Weight Weight W(2)99.481.3*31.1*31.1ˆ==∆=∆height eight W3.8设有10名工人的数据如下: X 10 710 5886 7910Y11 10 12 6 10 7 910 11 10其中 X=劳动工时, Y=产量(1)试估计Y=α+βX + u (要求列出计算表格); (2)提供回归结果(按标准格式)并适当说明; (3)检验原假设β=1.0。