第二章描述统计
- 格式:ppt
- 大小:2.10 MB
- 文档页数:89
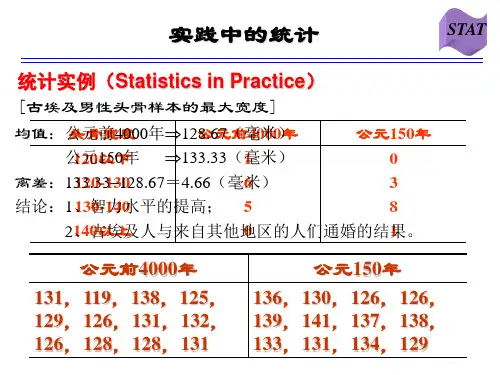




第二章统计数据的描述一、填空题:1.统计分组有等距分组与异距分组两大类。
2. 频率是每组数据出现的次数与全部次数之和的比值。
3. 统计分组的关键在于确定组数和组距。
4. 统计表从形式上看,主要由表头(总标题)、横行标题、纵栏标题和数字资料(指标数值)四部分组成。
5. 均值是测度集中趋势最主要的测度指标,标准差是测度离散趋势最主要的测度指标。
6.当平均水平和计量单位不同时,需要用变异系数(离散系数)来测度数据之间的离散程度。
7.众数是一组数据中出现次数最多的变量值。
8.对于一组数据来说,四分位数有 3 个。
二、单项选择题:1. 次数是分配数列组成的基本要素之一,它是指( B )。
A、各组单位占总体单位的比重B、分布在各组的个体单位数C、数量标志在各组的划分D、以上都不对2. 某连续变量数列,其末组为600以上。
又如其邻近组的组中值为560,则末组的组中值为( D )。
A、620B、610C、630D、6403. 变量数列中各组频率的总和应该是( B )。
A、小于1B、等于1C、大于1D、不等于14. 某连续变量数列,其首组为500以下。
又如其邻近组的组中值为520,则首组的组中值为( C )。
A、460B、470C、480D、4905. 在下列两两组合的指标中,哪一组的两个指标完全不受极端数值的影响(D )A、算术平均数和调和平均数B、几何平均数和众数C、调和平均数和众数D、众数和中位数6. 在编制等距数列时,如果全距等于56,组数为6,为统计运算方便,组距应取(D )A、9.3B、9C、6D、107. 一项关于大学生体重的调查显示,男生的平均体重是60公斤,标准差为5公斤;女生的平均体重是50公斤,标准差为5公斤.据此数据可以推断( B) 用变异系数算A、男生体重的差异较大B、女生体重的差异较大C、男生和女生的体重差异相同D、无法确定8. 某生产小组有9名工人,日产零件数分别为10,11,14,12,13,12,9,15,12.据此数据计算的结果是( A ) 众数12 中位数12 平均数12A、均值=中位数=众数B、众数>中位数>均值C、中位数>均值>众数D、均值>中位数>众数9. 按连续型变量分组,最后一组为开口组,下限值为2000。
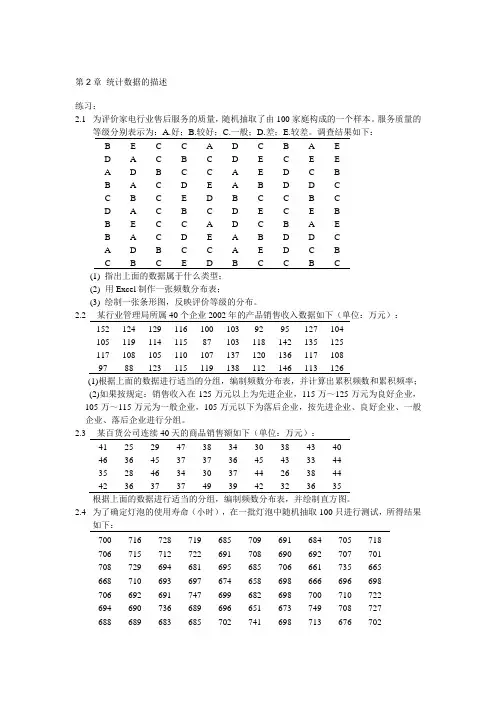
第2章统计数据的描述练习:2.1为评价家电行业售后服务的质量,随机抽取了由100家庭构成的一个样本。
服务质量的等级分别表示为:A.好;B.较好;C.一般;D.差;E.较差。
调查结果如下:B EC C AD C B A ED A C B C DE C E EA DBC C A ED C BB ACDE A B D D CC B C ED B C C B CD A C B C DE C E BB EC C AD C B A EB ACDE A B D D CA DBC C A ED C BC B C ED B C C B C(1) 指出上面的数据属于什么类型;(2)用Excel制作一张频数分布表;(3) 绘制一张条形图,反映评价等级的分布。
2.2某行业管理局所属40个企业2002年的产品销售收入数据如下(单位:万元):152 124 129 116 100 103 92 95 127 104105 119 114 115 87 103 118 142 135 125117 108 105 110 107 137 120 136 117 10897 88 123 115 119 138 112 146 113 126(1)根据上面的数据进行适当的分组,编制频数分布表,并计算出累积频数和累积频率;(2)如果按规定:销售收入在125万元以上为先进企业,115万~125万元为良好企业,105万~115万元为一般企业,105万元以下为落后企业,按先进企业、良好企业、一般企业、落后企业进行分组。
2.3某百货公司连续40天的商品销售额如下(单位:万元):41 25 29 47 38 34 30 38 43 4046 36 45 37 37 36 45 43 33 4435 28 46 34 30 37 44 26 38 4442 36 37 37 49 39 42 32 36 35根据上面的数据进行适当的分组,编制频数分布表,并绘制直方图。



第二章统计描述习题一、选择题1.描述一组偏态分布资料的变异度,以()指标较好。
A.全距B.标准差C.变异系数D.四分位数间距E.方差2.各观察值均加(或减)同一数后()。
A.均数不变,标准差改变B.均数改变,标准差不变C.两者均不变D.两者均改变E.以上都不对3.偏态分布宜用()描述其分布的集中趋势。
A.算术均数B.标准差C.中位数D.四分位数间距E.方差4.为了直观地比较化疗后相同时点上一组乳腺癌患者血清肌酐和血液尿素氮两项指标观测值的变异程度的大小,可选用的最佳指标是()。
A.标准差B.标准误C.全距D.四分位数间距E.变异系数5.测量了某地152人接种某疫苗后的抗体滴度,宜用()反映其平均滴度。
A.算术均数B.中位数C.几何均数D.众数E.调和均数6.测量了某地237人晨尿中氟含量(mg/L),结果如下:尿氟值:0.2~0.6~ 1.0~ 1.4~ 1.8~ 2.2~ 2.6~ 3.0~ 3.4~ 3.8~频数:7567302016196211宜用()描述该资料。
A.算术均数与标准差B.中位数与四分位数间距C.几何均数与标准差D.算术均数与四分位数间距 E.中位数与标准差7.用均数和标准差可以全面描述()资料的特征。
A.正偏态资料B.负偏态分布C.正态分布D.对称分布E.对数正态分布8.比较身高和体重两组数据变异度大小宜采用()。
A.变异系数B.方差C.极差D.标准差E.四分位数间距9.血清学滴度资料最常用来表示其平均水平的指标是()。
A.算术平均数B.中位数C.几何均数D.变异系数E.标准差10.最小组段无下限或最大组段无上限的频数分布资料,可用()描述其集中趋势。
A.均数B.标准差C.中位数D.四分位数间距E.几何均数11.现有某种沙门菌食物中毒患者164例的潜伏期资料,宜用()描述该资料。
A.算术均数与标准差B.中位数与四分位数间距C.几何均数与标准差D.算术均数与四分位数间距 E.中位数与标准差12.测量了某地68人接种某疫苗后的抗体滴度,宜用()反映其平均滴度。

第二章描述性统计命令与输出结果说明上述数据也可以用变量x表示血磷测定值,分组变量group=0表示患者组和group=1表示健康组(如:患者组中第一个数据为2.6,则x=2.6,group=0;又如:健康组中第三个数据为1.98,则x为1.98以及group为1),并假定这些数据已以STATA格式存入ex2a.dta文件中。
计算资料均数,标准差命令summarize,以述资料为例:. summarizeVariable Obs Mean Std. Dev. Min Maxx1 11 4.710909 1.302977 2.6 6.53x2 13 3.354615 1.304368 1.67 5.78Mean 均值;Std.Dev.标准差即:本例中急性克山病患者组的样本数为11,血磷测定值均数为4.711(mg%),相应的标准差为1.303,最小值为2.6以及最大值为6.53;健康组的样本量为13,血磷测定值均数为3.3546,相应的标准差为1.3044,最小值为1.67以及最大值为5.78。
计算资料均数,标准差,中位数,低四分位数和高四分位数的命令summarize 以及子命令detail,仍以述资料为例:. summarize x1 x2,detailx1Percentiles Smallest1% 2.6 2.65% 2.6 3.2410% 3.24 3.73 Obs 1125% 3.73 3.73 Sum of Wgt. 1150% 4.73 Mean 4.710909Largest Std. Dev. 1.30297775% 5.78 5.5890% 6.4 5.78 Variance 1.69774995% 6.53 6.4 Skewness -.081344699% 6.53 6.53 Kurtosis 1.809951x2Percentiles Smallest1% 1.67 1.675% 1.67 1.9810% 1.98 1.98 Obs 1325% 2.33 2.33 Sum of Wgt. 1350% 3.6 Mean 3.354615Largest Std. Dev. 1.30436875% 4.17 4.1790% 4.82 4.57 Variance 1.70137795% 5.78 4.82 Skewness .296394399% 5.78 5.78 Kurtosis 1.875392.结果:Percentiles 显示了从1%到99%的分位数的取值。

1第二章 描述统计(计算题答案)1、某市工业企业按产值分组资料如下: 按产值分组(万元) 企业数(个)100—200 200—400 400—600 600—800 800—1000 1000—1200 501101301409030合 计 550解:27.577550317500===∑∑f xfx (万元)92.576200130160255040021=⨯-+=⨯-+=-∑i f S fL M m m e (万元)233.6332120=⨯∆+∆∆-=i U M (万元)2、某车间有两个小组,每组都是7人,每人日产量件数如下第一组:20、40、60、70、80、100、120第二组:67、68、69、70、71、72、73若这两组工人每人平均日产量件数都是70件,计算每人日产量的差异指标:①全距;②平均差;③标准差,并比较哪个组的平均数的代表性大?解:大。
第二组的平均数代表性,,件,件件件件件件∴<⋅<⋅<====⋅===⋅=12121221222111702,71.1,662.31,7.25,100σσσσD A D A R R x x D A R D A R Θ3、有两个生产作业班工人按其产品日产量分组的资料如下: 甲组 乙组日产量(件) 工人数(人) 日产量(件) 工人数(人)3 5 7 9 10 13 3 5 64 2 8 12 14 15 16 67331合 计 合 计数代表性大?解:乙组平均数代表性大。
,,件件,件,件,乙甲乙甲乙甲乙甲∴>======σσσσσσV V V V x x Θ%9.22%9.257.22.28.115.84、两种不同的水稻品种分别在5块试验田上试种,其产量资料如下:甲品种 乙品种4 田块面积(亩) 亩产(斤) 田块面积(亩) 亩产(斤)1.2 1.1 1.0 0.9 0.8 1000 950 1100 900 1050 1.2 1.1 1.0 0.9 0.8 136010001250750600合计 合计假定生产条件相同,试研究这两个品种的亩产水平,并确定哪个品种具有较大的推广价值 。
第二章描述统计:表格与图形方法第一节数据的预处理一、数据审核1、准确性审核的对象就登记性误差〔非抽样误差〕采取逻辑检查和计算检查方法·逻辑检查:主要看调查数据的容是否合理,工程之间是否有矛盾的地方,以及与有关数据进展对照,或者检查数据的平衡关系,以暴露逻辑上的矛盾·计算检查:主要是从数字上检查,如各分项之和是否等于总计,计量单位是否适宜,计算方法上是否合理等等2、全面性核对应调查的单位是否有遗漏,应调查的容是否齐全3、及时性即是否按规定的时间获取数据资料二、数据筛选1、当数据中的错误不能予以纠正,或者有些数据不符合调查的要求而又无法弥补时,需要对数据进展筛选2、数据筛选的容〔1〕将*些不符合要求的数据或有明显错误的数据予以剔除〔2〕将符合*种特定条件的数据筛选出来,而不符合特定条件的数据予以剔除3、数据筛选可借助计算机完成三、数据排序1、按一定顺序将数据排列,以发现一些明显的特征或趋势,找到解决问题的线索2、排序有助于对数据检查纠错,以及为重新归类或分组等提供依据3、在*些场合,排序本身就是分析的目的之一4、排序可借助于计算机完成第二节定性数据的图表分析一、频数分布:将统计数据分组后,各组数据出现的次数被称为频数〔次数〕。
把各个组以及相应的频数依一定的次序全部列出来,就形成了频数分布〔次数分布〕1、频率:各组单位数占总体单位总数的比重××定性数据本身就是对事物的一种分类,在列出所分的类别的同时,再列出对应的频数或频率,就形成了分类数据的频数分布。
2、顺序数据的整理(可计算的统计量)〔1〕累积频数:各类别频数的逐级累加。
包括向上累积和向下累积两类。
〔2〕累积频率:各类别频率(百分比)的逐级累加。
包括向上累积和向下累积两类。
&&补充:1>向上累计:从变量值低的组开场,将各组次数〔频率〕逐次向变量值高的组累计,说明*一组上限以下各组的累计次数〔频率〕。
第二章统计数据的描述【说明】(一)统计数据的分类、表达形式1.按数据的计量尺度不同划分•分类数据---列名尺度、定类尺度、名义尺度的计量结果对事物进行分类的结果,数据表现为类别,用文字来表述⏹表现为类别,用文字来表述⏹•顺序数据----定序尺度的计量结果对事物类别顺序的测度⏹数值型数据----定距尺度、定比尺度的计量结果⏹对事物的精确测度⏹结果表现为具体的数值⏹2.按采集方法划分1、观测数据(observational data)2、试验数据(experimental data)3.按时间状况划分•截面数据(cross-sectional data)在相同或者近似相同的时间点上采集的数据⏹描述现象在某一时刻的变化情况⏹•时间序列数据(time series data)在不同时间上采集到的数据⏹描述现象随时间变化的情况⏹(二)数据的表现形式绝对数按其所反映的时间状况不同,划分为:时期数、时点数⏹(计量单位有实物单位、价值单位、复合单位)相对数包括:比例(Proportion)、比率(Ratio)⏹(计量单位有百分比、千分比)统计数据的描述过程一、第一个环节——统计数据的搜集(一)统计数据的来源(渠道)(二)统计数据的搜集方式、方法(三)统计数据的质量要求(评价标准)1. 精度:最低的抽样误差或者随机误差2. 准确性:最小的非抽样误差或者偏差3. 关联性:满足用户决策、管理和研究的需要4. 及时性:在最短的时间里取得并发布数据5. 一致性:保持时间序列的可比性6. 最低成本:以最经济的方式取得数据二、第二个环节——统计数据的整理【重点】数据的整理与显示的基本原则:要弄清所面对的数据类型,因为不同类型的数据,所采取的处理方式和方法是不同的;•对分类数据和顺序数据主要是进行分类整理;•对数值型数据则主要是进行分组整理;•适合于低层次数据的整理和显示方法也适合于高层次的数据;但适合于高层次数据的整理和显示方法并不适合于低层次的数据。