关于checkpoint比较经典的解释
- 格式:doc
- 大小:38.50 KB
- 文档页数:4

checkpoint 的应用场景Checkpoint的应用场景引言:在现代社会,数据安全和恢复的重要性越来越被人们所重视。
数据丢失或被破坏可能导致灾难性的后果,因此,有必要采取相应的措施来确保数据的安全性和可恢复性。
在这方面,Checkpoint作为一种有效的工具被广泛应用于各种领域。
本文将详细探讨Checkpoint的应用场景。
第一部分:Checkpoint简介1.1 什么是CheckpointCheckpoint是一种技术或工具,用于创建和记录系统状态的快照。
它可以用来保存系统在某一时刻的状态,包括内存、寄存器和文件系统状态等。
这些快照可以用于系统的恢复和回退,以保护数据的安全性和完整性。
1.2 Checkpoint的特点- Checkpoint是非常快速的,可以在几秒钟内完成系统状态的保存。
- 它占用的存储空间相对较小,可以大大减少磁盘存储需求。
- Checkpoint可以递增地保存状态,从而减少对存储资源的占用。
- 快照可以进行差异化备份,并能够在需要恢复时快速回退到特定的状态。
第二部分:Checkpoint的应用场景2.1 数据库管理数据库是现代应用中不可或缺的组成部分,而Checkpoint在数据库管理中的应用具有重要的意义。
它可以定期保存数据库的状态快照,以防止重要数据的丢失或被破坏。
当数据库系统崩溃或发生故障时,可以通过恢复到最近的有效Checkpoint来快速恢复数据库的正常运行。
2.2 高性能计算在高性能计算领域,Checkpoint是必不可少的工具。
在执行复杂的计算任务时,系统可能会因为硬件故障或其他原因而崩溃,导致大量运算结果的丢失。
通过定期创建Checkpoint,可以在系统崩溃后快速回到之前的状态,从而节省时间和计算资源。
2.3 分布式系统在分布式系统中,数据的安全性和可靠性是关键问题。
Checkpoint可以在分布式系统中的不同节点之间同步状态,以避免数据的丢失。
当系统中的某个节点发生故障时,可以通过重新启动节点并恢复到最近的Checkpoint来恢复系统的运行。

checkpoint双机热备Cluster XL-----高可用性和负载均衡介绍Cluster XLCheck Point防火墙的ClusterXL功能是一个基于软件的高可用性和负载分担解决方案。
它能够在属于同一个ClusterXL群组里面的checkpoint网关上分配网络流量。
并且一个checkpoint网关出现故障不能工作的情况下,其他同组成员能过接替他的工作,保证网络能过正常、安全的为企业服务。
ClusterXL工作的条件是:Cluster 需要两台以上的checkpoint 防火墙,而且这两台防火墙的系统平台要一致,软件版本也要一致.拓扑图如下所示:群控制协议Cluster Control Protocol (CCP)将checkpoint网关加入的一个群组。
Ccp使用udp8116端口,群组内的设备使用此端口发送保活数据包报告他们的状态,同步成员时钟。
高可用性在故障切换期间能过保持所有链接的弹性安全,包括vpn链接。
如果一个主用网关不可用,所有的会话无需终端就可以安全的继续下去。
用户不需要重新连接和重新认证,也不需要知道备用网关接管了业务。
负载均衡通过负载均衡,在多个网关之见分配流量,ClusterXL可以扩展vpn的性能能力。
一个集群最多可以部署五个网关。
配置说明以两台checkpoint防火墙为例说明集群的配置过程。
实计环境如下:说明防火墙A、B使用三台交换机相连一台用于连入外网(outside)一台用于连入内网(inside)一台用于连接集群防火墙实现防火墙同步(心跳线)注意:若只有两台防火墙做集群心跳线可用网线直接相连1、新安装两台checkpoint防火墙(处不同地方均不在做说明)从ht tps登陆设备安装防火墙组件选择安装组件集群中的checkpoint防火墙此界面只选择安全网关VPN-1 Power,不需要在每个集群成员中安装管理服务Smartcenter。
Smartcenter组件需要安装到一个独立的服务器上(Windows/liunx均可),以便统一管理集群中的各个网关成员。

或的存储需求验传播的时链可能是不杂的# torch.cuda.is_initialized中就用到了该变量ctx.had_cuda_in_fwd = True#保存输入变量涉及的各个GPU设备的随机状态ctx.fwd_gpu_devices, ctx.fwd_gpu_states = get_device_states(*args)# Save non-tensor inputs in ctx, keep a placeholder None for tensors# to be filled out during the backward.ctx.inputs = []ctx.tensor_indices = []tensor_inputs = []for i, arg in enumerate(args):if torch.is_tensor(arg):tensor_inputs.append(arg)ctx.tensor_indices.append(i)ctx.inputs.append(None)else:ctx.inputs.append(arg)# save_for_backward()中保存反向传播中需要用到的输入和输出tensor量。
#由于在反向传播中需要重新计算记录梯度的output,所以就不要保存output了。
#并且后面的计算也不需要在梯度模式下计算。
ctx.save_for_backward(*tensor_inputs)with torch.no_grad():#不保存梯度的前向传播操作,也就是说这里的output是不会记录中间变量,无法直接计算梯度的。
outputs = run_function(*args)return outputs@staticmethoddef backward(ctx, *args):if not torch.autograd._is_checkpoint_valid():raise RuntimeError('Checkpointing is not compatible with .grad() or when an `inputs` parameter'' is passed to .backward(). Please use .backward() and do not pass its `inputs`'' argument.')# Copy the list to avoid modifying original list.inputs = list(ctx.inputs)tensor_indices = ctx.tensor_indicestensors = ctx.saved_tensors #获取前向传播中保存的输入tensor# Fill in inputs with appropriate saved tensors.for i, idx in enumerate(tensor_indices):inputs[idx] = tensors[i]# Stash the surrounding rng state, and mimic the state that was# present at this time during forward. Restore the surrounding state# when we're done.rng_devices = []if ctx.preserve_rng_state and ctx.had_cuda_in_fwd:rng_devices = ctx.fwd_gpu_devices#使用之前前向传播开始之前保存的随机数生成器的状态来进行一次一模一样的前向传播过程with torch.random.fork_rng(devices=rng_devices, enabled=ctx.preserve_rng_state):#使用上下文管理器保护原始的随机数生成器的状态,内部处理后在进行复原if ctx.preserve_rng_state:torch.set_rng_state(ctx.fwd_cpu_state)if ctx.had_cuda_in_fwd:set_device_states(ctx.fwd_gpu_devices, ctx.fwd_gpu_states)#这里将inputs从计算图中剥离开,但是其属性requires_grad和原来是一样的,这么做的目的是为了截断反向传播的路径。

checkpoint的使用方法标题,掌握Checkpoint的使用方法,提高工作效率。
在现代社会,人们经常面临着繁忙的工作和生活压力。
为了更好地管理时间和任务,许多人开始寻找各种方法来提高工作效率。
其中,使用Checkpoint是一种非常有效的方法。
本文将介绍Checkpoint的使用方法,帮助读者更好地利用这一工具来提高工作效率。
首先,什么是Checkpoint?Checkpoint是一种时间管理工具,它可以帮助人们将任务分解成小步骤,并设定时间节点来完成这些步骤。
通过这种方式,人们可以更好地掌控自己的工作进度,避免拖延和失控的情况发生。
要使用Checkpoint,首先需要明确自己的任务和目标。
将任务分解成小步骤,并为每个步骤设定一个时间节点。
这样一来,任务就会变得更加具体和可操作,而不是一团模糊的大任务。
例如,如果你的任务是写一篇文章,你可以将它分解成“收集资料”、“撰写大纲”、“写作初稿”、“修改”等步骤,并为每个步骤设定一个具体的时间。
其次,要合理安排时间。
在设定Checkpoint时,要考虑到自己的实际情况和工作习惯。
不要过于理想化地设定时间节点,以免造成压力和挫败感。
同时,也要考虑到任务的复杂程度和紧急程度,合理地安排时间节点。
最后,要严格执行Checkpoint。
设定好时间节点后,要努力按时完成每个步骤。
如果有一些步骤超出了时间节点,要及时调整,不要让拖延的情况发生。
另外,也要及时调整Checkpoint的设定,根据实际情况对任务进行重新分解和安排。
总的来说,Checkpoint是一种非常实用的时间管理工具,它可以帮助人们更好地掌控自己的工作进度,提高工作效率。
通过合理地设定时间节点和严格执行,人们可以更好地完成任务,减少拖延和失控的情况。
希望本文介绍的Checkpoint的使用方法能够帮助读者更好地应用这一工具,提高自己的工作效率。

深⼊浅出Spark的Checkpoint机制1 Overview当第⼀次碰到 Spark,尤其是 Checkpoint 的时候难免有点⼀脸懵逼,不禁要问,Checkpoint 到底是什么。
所以,当我们在说 Checkpoint 的时候,我们到底是指什么?⽹上找到⼀篇⽂章,说到 Checkpoint,⼤概意思是检查点创建⼀个已知的节点,SQL Server 数据库引擎可以在意外关闭或崩溃后从恢复期间开始应⽤⽇志中包含的更改。
所以你可以简单理解成 Checkpoint 是⽤来容错的,当错误发⽣的时候,可以迅速恢复的⼀种机制,这⾥就不展开讲了。
A checkpoint creates a known good point from which the SQL Server Database Engine can start applying changes contained inthe log during recovery after an unexpected shutdown or crash.回到 Spark 上,尤其在流式计算⾥,需要⾼容错的机制来确保程序的稳定和健壮。
从源码中看看,在 Spark 中,Checkpoint 到底做了什么。
在源码中搜索,可以在 Streaming 包中的Checkpoint。
作为 Spark 程序的⼊⼝,我们⾸先关注⼀下 SparkContext ⾥关于 Checkpoint 是怎么写的。
SparkContext 我们知道,定义了很多 Spark 内部的对象的引⽤。
可以找到 Checkpoint 的⽂件夹路径是这么定义的。
// 定义 checkpointDirprivate[spark] var checkpointDir: Option[String] = None/*** Set the directory under which RDDs are going to be checkpointed. The directory must* be a HDFS path if running on a cluster.*/def setCheckpointDir(directory: String) {// If we are running on a cluster, log a warning if the directory is local.// Otherwise, the driver may attempt to reconstruct the checkpointed RDD from// its own local file system, which is incorrect because the checkpoint files// are actually on the executor machines.// 如果运⾏的是 cluster 模式,当设置本地⽂件夹的时候,会报 warning// 道理很简单,被创建出来的⽂件夹路径实际上是 executor 本地的⽂件夹路径,不是不⾏,// 只是有点不合理,Checkpoint 的东西最好还是放在分布式的⽂件系统中if (!isLocal && Utils.nonLocalPaths(directory).isEmpty) {logWarning("Spark is not running in local mode, therefore the checkpoint directory " +s"must not be on the local filesystem. Directory '$directory' " +"appears to be on the local filesystem.")}checkpointDir = Option(directory).map { dir =>// 显然⽂件夹名就是 UUID.randoUUID() ⽣成的val path = new Path(dir, UUID.randomUUID().toString)val fs = path.getFileSystem(hadoopConfiguration)fs.mkdirs(path)fs.getFileStatus(path).getPath.toString}}关于setCheckpointDir被那些类调⽤了,可以看以下截图。

flink中checkpoint的简单理解-回复Flink 中的CheckpointFlink 是一个开源的流式处理框架,它能够以低延迟和高吞吐量来处理大规模的数据流。
在一个分布式环境中,故障是不可避免的,例如机器崩溃、网络中断或者应用程序的错误等。
为了保证数据处理的正确性,Flink 引入了Checkpoint(检查点)机制。
本文将详细介绍Flink 中的Checkpoint,包括它的定义、作用、机制以及如何配置和使用。
一、Checkpoint 的定义和作用Checkpoint(检查点)是指将系统当前状态保存到外部存储介质中的操作。
在Flink 中,它的主要作用是实现Flink 作业的容错(fault-tolerance)。
通过定期生成检查点,Flink 能够在作业发生故障时恢复到最近的一个检查点,从而保证数据处理的正确性。
二、Checkpoint 的机制1. 生成CheckpointFlink 默认会每隔一段时间自动触发一个Checkpoint。
可以通过`ExecutionConfig.setCheckpointInterval` 方法来设置Checkpoint的时间间隔。
此外,还可以通过`CheckpointConfig.setMaxConcurrentCheckpoints` 方法来控制同时进行的最大Checkpoint 数量。
一旦触发一个Checkpoint,Flink 会执行以下步骤:- 首先,Flink 会将所有正在运行的任务暂停,确保数据的一致性。
- 然后,Flink 会将所有任务的状态信息保存到分布式文件系统(如HDFS)中,以便在发生故障时进行恢复。
- 最后,Flink 会将这个Checkpoint 的元数据写入一个持久化存储系统(如ZooKeeper 或者HDFS)中,以防止元数据的丢失。
2. 容错机制Flink 的Checkpoint 机制是基于Chandy-Lamport 算法(一种分布式快照算法)实现的。

android checkpoint原理Android Checkpoint是Android系统中的一个重要概念,它是为了保证系统的稳定性和安全性而设计的。
在Android系统中,Checkpoint可以理解为一个系统状态的快照,它记录了系统在某个时间点上的各种状态信息。
当系统发生故障或者异常时,可以通过恢复到某个Checkpoint状态来修复问题。
Android Checkpoint的原理是通过记录系统的各种状态信息来创建一个快照。
这些状态信息包括进程的运行状态、内存的分配情况、文件系统的状态、网络连接情况等。
Checkpoint会定期创建这些快照,并将其保存在系统中。
当系统出现问题时,可以通过恢复到之前的一个Checkpoint状态来解决问题。
在创建Checkpoint时,Android会记录系统的各种状态信息,并将其保存在内存中。
这些信息包括进程的运行状态、进程间通信的状态、内存分配情况、文件系统的状态等。
当系统出现故障时,可以通过恢复到之前的一个Checkpoint状态来解决问题。
恢复到Checkpoint状态的过程是通过系统的恢复机制来实现的。
当系统出现故障时,系统会自动检测到这个问题,并尝试恢复到之前的一个Checkpoint状态。
恢复过程中,系统会关闭一些异常进程,释放一些异常资源,并重新启动一些异常服务。
通过这样的恢复过程,系统可以从异常状态中恢复过来,保证系统的稳定性和安全性。
Android Checkpoint在系统稳定性和安全性方面起着重要的作用。
它可以帮助系统快速恢复到一个正常的状态,避免系统长时间处于异常状态。
同时,通过记录系统的各种状态信息,可以帮助开发者分析和解决系统的故障和问题。
Android Checkpoint是Android系统中的一个重要概念,通过记录系统的各种状态信息来创建一个快照。
当系统发生故障或异常时,可以通过恢复到之前的一个Checkpoint状态来解决问题。

checkpoint 的应用场景-回复Checkpoint 是一个自动化工具,用于监控和保护数据的一致性。
它在各种应用场景中发挥着重要作用,从数据库备份和恢复到跨不同计算机系统的数据传输,均可以应用Checkpoint。
本文将探讨Checkpoint 的主要应用场景,并逐步回答下列问题:什么是Checkpoint,Checkpoint 在数据库备份和恢复方面的应用场景是什么,Checkpoint 在数据传输方面的应用场景是什么,以及Checkpoint 如何提高数据的一致性和可靠性。
首先,什么是Checkpoint?Checkpoint 是一个自动化工具,用于监控和保护数据的一致性。
它可以记录和跟踪数据的状态,并在需要时恢复到先前的一致性点。
Checkpoint 的实现方式可以有多种,例如通过在数据库中创建数据库快照、在数据传输过程中使用事务日志等。
接下来,我们将讨论Checkpoint 在数据库备份和恢复方面的应用场景。
数据库备份是保护数据免受意外删除、硬件故障或灾难性事件的重要手段。
Checkpoint 可以在数据库备份过程中发挥关键作用。
当进行数据库备份时,Checkpoint 可以记录当前数据的一致性状态,并创建一个数据库快照。
在发生意外情况或需要恢复数据时,可以使用这个快照将数据库恢复到备份时的一致性状态。
这种方式可以避免数据丢失和数据不一致问题,提高数据库的可靠性。
其次,Checkpoint 在数据传输方面也有广泛的应用场景。
当从一个计算机系统传输数据到另一个计算机系统时,可能会面临数据一致性的问题。
特别是当数据传输中断或出错时,传输的数据可能处于不一致的状态。
Checkpoint 可以通过记录传输过程中的状态,并在需要时回滚到先前一致性点,确保数据的一致性和可靠性。
这在跨系统数据迁移、实时数据同步等场景下都非常有用。
最后,Checkpoint 如何提高数据的一致性和可靠性?Checkpoint 可以定期记录数据的一致性状态,并在需要时恢复到先前的一致性点。
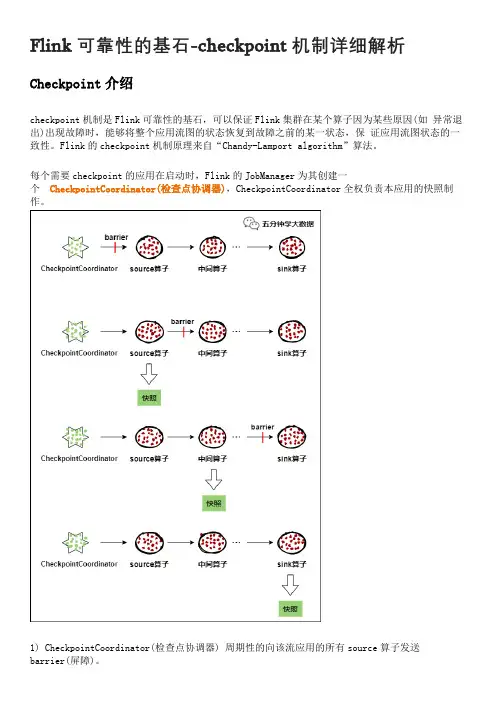
Flink可靠性的基石-checkpoint机制详细解析Checkpoint介绍checkpoint机制是Flink可靠性的基石,可以保证Flink集群在某个算子因为某些原因(如异常退出)出现故障时,能够将整个应用流图的状态恢复到故障之前的某一状态,保证应用流图状态的一致性。
Flink的checkpoint机制原理来自“Chandy-Lamport algorithm”算法。
每个需要checkpoint的应用在启动时,Flink的JobManager为其创建一个CheckpointCoordinator(检查点协调器),CheckpointCoordinator全权负责本应用的快照制作。
1) CheckpointCoordinator(检查点协调器) 周期性的向该流应用的所有source算子发送barrier(屏障)。
2) 当某个source算子收到一个barrier时,便暂停数据处理过程,然后将自己的当前状态制作成快照,并保存到指定的持久化存储中,最后向CheckpointCoordinator报告自己快照制作情况,同时向自身所有下游算子广播该barrier,恢复数据处理3) 下游算子收到barrier之后,会暂停自己的数据处理过程,然后将自身的相关状态制作成快照,并保存到指定的持久化存储中,最后向CheckpointCoordinator报告自身快照情况,同时向自身所有下游算子广播该barrier,恢复数据处理。
4) 每个算子按照步骤3不断制作快照并向下游广播,直到最后barrier传递到sink算子,快照制作完成。
5) 当CheckpointCoordinator收到所有算子的报告之后,认为该周期的快照制作成功; 否则,如果在规定的时间内没有收到所有算子的报告,则认为本周期快照制作失败。
如果一个算子有两个输入源,则暂时阻塞先收到barrier的输入源,等到第二个输入源相同编号的barrier到来时,再制作自身快照并向下游广播该barrier。

CheckPoint技术简介一、CheckPoint主要产品部件1、FireWall-1/VPN-12、FloodGate-13、Reporting Module4、Meta IP5、SecuRemote6、SecureClient7、OPSEC SDK二、FireWall-1产品组成:CheckPoint FireWall-1产品包括以下模块:·基本模块√状态检测模块(Inspection Module):提供访问控制、用户认证、地址翻译和审计功能;√防火墙模块(FireWall Module):包含一个状态检测模块,另外提供用户认证、内容安全和多防火墙同步功能;√管理模块(Management Module):对一个或多个安全策略执行点(安装了FireWall-1的某个模块,如状态检测模块、防火墙模块或路由器安全管理模块等的系统)提供集中的、图形化的安全管理功能;·可选模块√连接控制(Connect Control):为提供相同服务的多个应用服务器提供负载平衡功能;√路由器安全管理模块(Router Security Management):提供通过防火墙管理工作站配置、维护3Com,Cisco,Bay等路由器的安全规则;√其它模块,如加密模块等。
·图形用户界面(GUI):是管理模块功能的体现,包括√策略编辑器:维护管理对象、建立安全规则、把安全规则施加到安全策略执行点上去;√日志查看器:查看经过防火墙的连接,识别并阻断攻击;√系统状态查看器:查看所有被保护对象的状态。
产品部件主要功能管理控制台·对一点或多点实行集中图形化安全管理检测模块·访问控制·客户和对话鉴别·网络地址转换·审查防火墙模块·检测模块的全部功能·用户鉴定·多防火墙同步·信息保护加密模块·加密连接控制模块·自动实现各应用服务器的负载平衡路由器安全管理·对一个或多个的路由器的路由器访问控制列表进行管理功能模块:·状态检查模块(Inspection Module)·访问控制(Access Control)·授权认证(Authentication)·加密(Encryption)·路由器安全管理(Router Security Management)·网络地址翻译(NAT)·内容安全(Content Security)·连接控制(Connection Control)·记帐(Auditing)·企业安全策略管理(Enterprise-wide Security Managemant)·高可靠性模块(High Availability)···Inspection状态检查模块FireWall-1采用CheckPoint公司的状态检测(Stateful Inspection)专利技术,以不同的服务区分应用类型,为网络提供高安全、高性能和高扩展性保证。

在细胞生物学中,"检验点"(checkpoint)是指一种细胞周期调控机制,用于确保细胞在进入下一个细胞周期阶段之前,对前一阶段的完成情况进行检查和评估。
检验点起到维持细胞周期正常进行的重要作用,确保细胞在适当的时间、在正确的条件下进行细胞分裂或细胞增殖。
细胞周期是细胞从诞生到分裂再到两个新细胞的形成的周期性过程。
检验点在细胞周期的不同阶段存在,并根据细胞内发生的特定事件来触发。
主要的检验点包括G1检验点、G2检验点和M检验点。
G1检验点位于细胞周期的G1期(第一个增殖期),其功能是检查细胞是否具备细胞分裂所需的条件,如是否存在足够的营养物质、是否有足够的细胞体积和是否存在DNA损伤。
如果细胞未能通过G1检验点,它可能会进入G0期,进入休眠状态或执行特定细胞功能,而不进行细胞分裂。
G2检验点位于细胞周期的G2期(第二个增殖期),在细胞分裂进入有丝分裂(M期)之前发生。
G2检验点的作用是检查细胞是否完成DNA复制和DNA损伤的修复,以确保细胞在进入有丝分裂之前处于适当的状态。
M检验点位于细胞周期的有丝分裂(M期),它监测细胞染色体的对
齐和连接情况。
M检验点的存在确保了细胞在染色体正确分离之前不会进入细胞分裂的下一个阶段。
通过检验点的存在,细胞可以在细胞周期的关键点进行控制和调节,确保细胞分裂和增殖的准确性和稳定性,同时防止异常细胞的形成,起到维护生物体正常发育和健康的重要作用。
checkpoint扫盲什么是checkpoint在数据库系统中,写日志和写数据文件是数据库中IO消耗最大的两种操作,在这两种操作中写数据文件属于分散写,写日志文件是顺序写,因此为了保证数据库的性能,通常数据库都是保证在提交(commit)完成之前要先保证日志都被写入到日志文件中,而脏数据块着保存在数据缓存(buffer cache)中再不定期的分批写入到数据文件中。
也就是说日志写入和提交操作是同步的,而数据写入和提交操作是不同步的。
这样就存在一个问题,当一个数据库崩溃的时候并不能保证缓存里面的脏数据全部写入到数据文件中,这样在实例启动的时候就要使用日志文件进行恢复操作,将数据库恢复到崩溃之前的状态,保证数据的一致性。
检查点是这个过程中的重要机制,通过它来确定,恢复时哪些重做日志应该被扫描并应用于恢复。
一般所说的checkpoint是一个数据库事件(event),checkpoint事件由checkpoint 进程(LGWR/CKPT进程)发出,当checkpoint事件发生时DBWn会将脏块写入到磁盘中,同时数据文件和控制文件的文件头也会被更新以记录checkpoint信息。
checkpoint的作用checkpoint主要2个作用:1.保证数据库的一致性,这是指将脏数据写入到硬盘,保证内存和硬盘上的数据是一样的;2.缩短实例恢复的时间,实例恢复要把实例异常关闭前没有写出到硬盘的脏数据通过日志进行恢复。
如果脏块过多,实例恢复的时间也会很长,检查点的发生可以减少脏块的数量,从而提高实例恢复的时间。
通俗的说checkpoint就像word的自动保存一样。
检查点分类∙完全检查点(Normal checkpoint)∙增量检查点(Incremental checkpoint)checkpoint相关概念术语在说明checkpoint工作原理之前我们先了解一些相关的术语。
RBA(Redo Byte Address), Low RBA(LRBA), High RBA(HRBA)RBA就是重做日志块(redo log block)的地址,相当与数据文件中的ROWID,通过这个地址来定位重做日志块。
CheckPoint:推动网络主动安全作者:暂无来源:《计算机世界》 2015年第49期文陈哲CheckPoint 是全球首屈一指的互联网安全解决方案供货商,致力于保护互联网通信及重要数据的安全、提高其可靠性及可用性。
CheckPoint 提供全方位的安全解决方案,包括从企业网络到移动设备的安全保护,以及最全面和可视化的安全管理方案,为各界客户提供业界领先的解决方案,以抵御各种恶意软件和威胁。
CheckPoint以FireWall 获得专利的状态检测技术(Stateful inspection)发明而成为IT 安全行业的先驱。
目前状态检测技术仍是大多数网络安全技术的基础。
作为IT 安全行业的领军企业,CheckPoint 已经超越了传统的被动防御模式,主动监管网络安全事件状态。
推出移动威胁防御解决方案近年来,自带设备办公(BYOD)渐成风潮,企业需要管理和减轻自带设备的风险,并保护员工和企业资产不受移动网络攻击。
为了让企业自如应对复杂的移动威胁环境,CheckPoint 于2015 年推出移动威胁防御解决方案。
该解决方案可以阻止苹果iOS 和安卓操作系统上的移动威胁,并可为现有的安全和移动架构添加实时威胁情报和可视性。
CheckPoint 移动威胁防御解决方案具有很高的移动威胁捕获率,可检测设备、应用和网络层面的威胁,此外还可以提供透明的用户体验,并允许即时检测和清除移动威胁,让用户可以保持安全连接,无需妥协。
打造CPU 级别威胁防御功能2015 年初,CheckPoint 宣布收购Hyperwise。
Hyperwise 成立于2013 年,总部位于以色列特拉维夫市,是一家隐身模式技术的私有公司。
CheckPoint 通过本次收购获得了先进的技术和由业界领先的工程师组成的高级技术团队,大大提高了其威胁仿真恶意软件的捕获率。
Hyperwise 发明了一种独特的、尖端的CPU 级别威胁防御引擎,可在感染之前消除威胁攻击,从而实现了一个更高的威胁捕获率,可大大提升用户预防攻击的能力。
mysql checkpoint机制MySQL是目前常见的一种数据库管理系统,在进行数据的存储和管理时,存在着一定的数据恢复和一致性问题。
为了解决这些问题,MySQL引入了checkpoint机制。
本文将对MySQL的checkpoint机制进行详细的解释和简述。
一、checkpoint的概念和原理CheckPoint(检查点)是指在MySQL中,将所有已修改的和未被提交的事务所产生的日志记录,统一写入磁盘的一个操作。
通过checkpoint机制,MySQL将在一段时间内所有的数据操作(增、删、改)都写至log buffer中,当log buffer满了或者时间到达一定水平时,数据会被写进磁盘中。
在真正写入磁盘之前,MySQL将会先将每个事务进行数据更新并记录许多redoa日志和硬盘日志。
在MySQL的启动过程中,需要进行数据库的初始化工作,建立数据库系统自身的数据结构,同时恢复文件系统的数据。
由于MySQL中的操作历史是通过redo日志和undo 日志来记录的,所以数据的恢复是通过这些日志来进行的。
如果数据库在上一次关闭时没有正常关闭,那么MySQL 的恢复机制会对数据的一致性进行检查并进行修复。
在数据库退出时,所有未提交的事务都会被撤销,所有修改的页都会被写入磁盘。
二、checkpoint的好处和作用Checkpoint机制的主要功能是保证MySQL中数据的一致性。
在进行数据库操作时,可能会因为各种原因导致数据的不一致性,影响到MySQL的正常工作。
此时,checkpoint就可以将所有已经提交的操作写入磁盘中,从而保证数据的一致性。
Checkpoint机制还可以加快MySQL的恢复速度。
在MySQL启动过程中,需要对数据库进行恢复操作。
如果这个过程需要遍历整个数据文件,那么恢复的过程就会非常耗时,因此checkpoint机制的引入,可以提高方案的恢复速度。
通过checkpoint机制,MySQL可以更加灵活的进行内存管理。
checkpoint是个数据库事件,他将已修改的数据从高速缓存刷新到磁盘,并更新控制文件和数据文件。
什么时候发生checkpoint?我们知道了checkpoint会刷新脏数据,但什么时候会发生checkpoint呢?以下几种情况会触发checkpoint。
1.当发生日志组转换的时候2.当符合LOG_CHECKPOINT_TIMEOUT,LOG_CHECKPOINT_INTERVAL,fast_start_io_target,fast_start_mttr_target 参数设置的时候3.当运行ALTER SYSTEM SWITCH LOGFILE的时候4.当运行ALTER SYSTEM CHECKPOINT的时候5.当运行alter tablespace XXX begin backup,end backup的时候6.当运行alter tablespace ,datafile offline的时候;检查点分为三类:1)局部检查点:单个实例执行数据库所有数据文件的一个检查点操作,属于此实例的全部脏缓存区写入数据文件。
触发命令:svmrgrl>alter system checkpoint local;这条命令显示的触发一个局部检查点。
2)全局检查点:所有实例(对应并行数据服务器)执行数据库所有所有数据文件的一个检查点操作,属于此实例的全部脏缓存区写入数据文件。
触发命令svrmgrl>alter system checkpoint global;这条命令显示的触发一个全局检查点。
3)文件检查点:所有实例需要执行数据文件集的一个检查点操作,如使用热备份命令alter tablespace USERS begin backup,或表空间脱机命令alter tablespace USERS offline,将执行属于USERS表空间的所有数据文件的一个检查点操作。
检查点处理步骤:1)获取实例状态队列:实例状态队列是在实例状态转变时获得,ORACLE获得此队列以保证检查点执行期间,数据库处于打开状态;2)获取当前检查点信息:获取检查点记录信息的结构,此结构包括当前检查点时间、活动线程、进行检查点处理的当前线程、日志文件中恢复截止点的地址信息;3)缓存区标识:标识所有脏缓存区,当检查点找到一个脏缓存区就将其标识为需进行刷新,标识的脏缓存区由系统进程DBWR进行写操作,将脏缓存区的内容写入数据文件;4)脏缓存区刷新:DBWR进程将所有脏缓存区写入磁盘后,设置一标志,标识已完成脏缓存区至磁盘的写入操作。
CheckPoint Process 的深入研究
“三个钟”的故事:假设一个公司只有三个员工,每个员工有自己的一个钟。
该公司规定,每天早晨8:30上班。
有一天,非常不幸,三个员工的钟的时间各不相同,在没有其他外部因素的帮助下,他们无法确定当前的确切时间,他们无法上班,该公司无法正常的OPEN 运作。
这个故事,帮助我们说明,在实例经过分配内存结构,加载控制文件后,然后要打开数据库的时候,需要做到控制文件,数据文件,联机重做日志保持相互状态一致性,数据库才可以打开。
当数据库发生实例不正常关闭时(比如系统掉电或者Shutdown abort 进行关闭),要进行实例恢复,Oracle 数据库具有相应的机制来实现这一点。
像任何一家公司一样,不同的员工具有不同的技能专长,负责不同的工作,但是一个成功的项目,需要一个优秀的项目经理,来保持,督促项目中的成员各自工作步调相互一致。
在Oracle 实例中,这样的一个重要角色,被检查点(CheckPoint) 进程(CKPT)担任。
Oracle 实例在必要的时候,出现检查点,当检查点出现时,CKPT 进程一方面催促DBWR 进程及时地把该检查点时刻前DB_Buffer 中被一些Service_Process 进程修改过的数据及时写入数据文件中,写完之后,CKPT 进程更新相关的数据文件和控制文件的同步时刻点。
也就是说,Oracle 实例在运行过程中,需要CKPT 进程来定期同步控制文件、数据文件和联机日志文件的“时间点”。
在这篇文章当中,我们将详细,深入的讨论检查点和检查点进程的作用。
注:这篇文章主要参考上的一篇文章
大多数关系型数据库都采用“在提交时并不强迫针对数据块的修改完成”而是“提交时保证修改记录(以重做日志的形式)写入日志文件”的机制,来获得性能的优势。
这句话的另外一种描述是:当用户提交事务,写数据文件是“异步”的,写日志文件是“同步”的。
这就可能导致数据库实例崩溃时,内存中的DB_Buffer 中的修改过的数据,可能没有写入到数据块中。
数据库在重新打开时,需要进行恢复,来恢复DB Buffer 中的数据状态,并确保已经提交的数据被写入到数据块中。
检查点是这个过程中的重要机制,通过它来确定,恢复时哪些重做日志应该被扫描并应用于恢复。
检查点和检查点进程的操作的三个步骤:
A、系统触发一个检查点,系统并记录该检查点时刻的Checkpoint SCN 号,并记录该时刻修改的DB Buffer的块所参考的RBA 作为Checkpoint RBA RBA (Redo Byte Address)。
B、该Checkpoint RBA 之前的日志实体所参考的DB_Buffer 中数据块的修改,要被写出到数据文件中。
C、完成2步骤后,CKPT 进程记录该检查点完成信息到控制文件。
只有上面三个步骤完成,才表示系统的检查点已经被推进,推进了日志文件,数据文件,控制文件到一个新的“同步点”。
检查点只发生在下列情形:
管理员使用:Alter system checkpoint 命令;
实例被正常的关闭;
特别注意:日志切换并不导致一个完全检查点的发生。
如何确定哪些DB_Buffer中的数据块需要被写到磁盘上,是一个蛮复杂的算法。
大致思想就是:所有dirty data按照Low RBA 的升序进行链接成一个list,当CKPT被唤醒的时候,首先先从控制文件读取上次check point,把中间这段时间的dirty data 写到磁盘上。
二、触发的条件
这里需要明白两个概念“完全检查点和增量检查点”的区别。
增量检查点(incremental checkpoint)
oracle8以后推出了incremental checkpoint的机制,在以前的版本里每checkpoint时都会做一个full thread checkpoint,这样的话所有脏数据会被写到磁盘,巨大的i/o对系统性能带来很大影响。
为了解决这个问题,oracle引入了checkpoint queue机制,每一个脏块会被移到检查点队列里面去,按照low rdb(第一次对此块修改对应的redo block address)来排列,靠近检查点队列尾端的数据块的low rba值是最小的,而且如果这些赃块被再次修改后它在检查点队列里的顺序也不会改变,这样就保证了越早修改的块越早写入磁盘。
每隔3秒钟ckpt会去更新控制文件和数据文件,记录checkpoint执行的情况。
在运行的Oracle 数据中,有很多事件、条件或者参数来触发检查点。
比如
λ当已通过正常事务处理或者立即选项关闭例程时;(shutdown immediate或者Shutdown normal;)
λ当通过设置初始化参数LOG_CHECKPOINT_INTERVAL、
LOG_CHECKPOINT_TIMEOUT 和FAST_START_IO_TARGET 强制时;
λ当数据库管理员手动请求时;(ALter system checkpoint)
λ alter tablespace ... offline;
λ每次日志切换时;(alter system switch logfile)
需要说明的是,alter system switch logfile也将触发完全检查点的发生。
alter database datafile ... offline不会触发检查点进程。
如果是单纯的offline datafile,那么将不会触发文件检查点,只有针对offline tablespace的时候才会触发文件检查点,这也是为什么online datafile需要media recovery 而online tablespace不需要。
对于表空间的offline后再online这种情况,最好做个强制的checkpoint比较好。
上面几种情况,将触发完全检查点,促使DBWR 将检查点时刻前所有的脏数据写入数据文件。
另外,一般正常运行期间的数据库不会产生完全检查点,下面很多事件将导致增量检查点,比如:
在联机热备份数据文件前,要求该数据文件中被修改的块从DB_Buffer 写入数据文件中。
所以,发出这样的命令:
λALTER TABLESPACE tablespace_name BIGEN BACKUP & end backup; 也将触发和该表空间的数据文件有关的局部检查点;另外,
λALTER TABLESPACE tablespace_name READ ONLY;
λALTER TABLESPACE tablespace_name OFFLINE NORMAL;
等命令都会触发增量检查点。
三、检查点位置的影响因素
相比传统检查点(也就是指那些有明确含义的检查点),增量检查点可以平缓的、持续的推进日志文件和数据文件的同步点。
理解这一点是学习Checlpoint 有关原理的关键点。
很多
朋友(包括我自己),总是将增量检查点和那些有明确含义的检查点做对比联系起来,竭力去探求,什么时候该出现增量检查点?很难得到确定的答案,是大家学习的难点。
实际上,对于增量检查点,主要讨论的并不是什么时候出现增量检查点,而是:如何控制增量检查点推进的速率?检查点本质上是为了推进写日志和写数据.
文件的“异步机制”的同步,我们感兴趣的内容终究要归结到:系统崩溃时,“异步的距离”
将需要系统多少时间来进行恢复?事实上,Oracle 正是这样设计的,数据库提供了一些参数设置(以oracle 9.2 为例)
A、FAST_START_MTTR_TARGET 参数来控制增量检查点的推进速率
我们都希望当实例崩溃后,恢复需要读取的日志流尽可能的短,恢复需要的时间尽可能的短。
这样,我们会将FAST_START_MTTR_TARGET 设置值更小, 增量检查点会出现的更加密集频繁。
但设置值太小,将显剧增加DBWR 写数据文件的工作量,写数据文件的I/O 的增加将降低系统的性能,降低“写日志文件和写数据文件的异步机制”所带来的性能效益。
难以说明设置FAST_START_MTTR_TARGET 为多少是合适的设置,这和我们各自的数据库应用业务有关。
Oracle 提供了一个视图V$MTTR_TARGET_ADVICE 作为我们设置参考,从该视图中,Oracle 会给出一些估计,当您设置不同的FAST_START_MTTR_TARGET 的值时,对应的物理写数据文件的数量的估计值。
我们可以选择一个合适的值,可以降低恢复时间,但是不让DBWR 的工作量增加太大。