异方差性实验
- 格式:doc
- 大小:434.50 KB
- 文档页数:12

异方差性实验报告篇一:计量经济学上机实验报告(异方差性)提示:打包保存时自己的文件夹以“学号姓名”为文件夹名,打包时文件夹内容包括:本实验报告、EViews工作文件。
篇二:Eviews异方差性实验报告实验一异方差性【实验目的】掌握异方差性问题出现的来源、后果、检验及修正的原理,以及相关的Eviews操作方法。
【实验内容】以《计量经济学学习指南与练习》补充习题4-16为数据,练习检查和克服模型的异方差的操作方法。
【4-16】表4-1给出了美国18个行业1988年研究开发(R&D)费用支出Y与销售收入X的数据。
请用帕克(Park)检验、戈里瑟(Gleiser)检验、G-Q检验与怀特(White)检验来检验Y关于X的回归模型是否存在异方差性?若存在【实验步骤】一检查模型是否存在异方差性1、图形分析检验(1)散点相关图分析做出销售收入X与研究开发费用Y的散点相关图(SCATX Y)。
观察相关图可以看出,随着销售收入的增加,研究开发费用的平均水平不断提高,但离散程度也逐步扩大。
这说明变量之间可能存在递增的异方差性。
(2)残差图分析首先对数据按照解释变量X由小至大进行排序(SORT X),然后建立一元线性回归方程(LS Y C X)。
因此,模型估计式为: Y?187.507?0.032*X ----------(*) ?(0.17)(2.88) R2=建立残差关于X的散点图,可以发现随着X增加,残差呈现明显的扩大趋势,表明存在递增的异方差。
2、Park检验建立回归模型(LS Y C X),结果如(*)式。
生成新变量序列: GENR LNE2 = LOG(RESID^2)GENR LNX = LOG(X)生成新残差序列对解释变量的回归模型(LS LNE2 C LNX)。
从下图所示的回归结果中可以看出,LNX的系数估计值不为0且能通过显著性检验,即随机误差项的方差与解释变量存在较强的相关关系,即认为存在异方差性。

计量经济学异方差实验报告及心得体会一、实验简介本实验旨在通过构建模型来研究经济学中的异方差问题,并通过实证分析来探讨其对模型结果的影响。
实验数据采用随机抽样方法自真实经济数据中获取,共包括两个自变量和一个因变量。
在实验中,我将对模型进行两次回归分析,一次是假设无异方差问题,一次是考虑异方差问题,并比较两个模型的结果。
二、实验过程1.数据准备:根据实验设计,我根据随机抽样方法,从真实经济数据中抽取了一部分样本数据。
2.模型建立:我将自变量Y和X1、X2进行回归分析。
首先,我假设模型无异方差问题,得到回归结果。
然后,我将检验异方差性,若存在异方差问题,则建立异方差模型继续回归分析。
3.模型估计:利用最小二乘法进行参数估计,并计算回归结果的标准差和假设检验。
4.模型比较:对比两个模型的回归结果,分析异方差对模型拟合程度和参数估计的影响。
三、实验结果1.无异方差假设模型回归结果:回归方程:Y=0.9X1+0.5X2+2.1标准差:0.3显著性水平:0.05拟合优度:0.852.考虑异方差问题模型回归结果:回归方程:Y=0.7X1+0.4X2+1.9标准差:0.6显著性水平:0.05拟合优度:0.75四、实验心得体会通过本次实验,我对计量经济学中的异方差问题有了更深入的了解,并进一步认识到其对模型结果的影响。
1.异方差问题的存在会对统计推断结果产生重要影响。
在本次实验中,考虑异方差问题的模型相较于无异方差模型,参数估计值差异较大,并且拟合优度也有所下降。
因此,我们在实证分析中应尽可能考虑异方差问题。
2.在实际应用中,异方差问题可能较为普遍。
经济学中的许多变量存在异方差性,例如,个体收入、消费支出等。
因此,在进行经济学研究时,我们应当警惕并尽量排除异方差问题。
3.针对异方差问题,我们可以采用多种方法进行调整,例如,利用异方差稳健标准误、加权最小二乘法等。
在本次实验中,我们采用了异方差模型进行调整,并得到了相对较好的结果。

异方差实验报告1. 研究目的本实验旨在探究数据中存在异方差(即方差不等)情况下,不同的方差假设检验方法的效果和正确性。
2. 实验设计为模拟异方差情况,取两个总体样本,其中一个总体样本的方差($\sigma_1^2$)为2,另一个总体样本的方差($\sigma_2^2$)为6,样本容量均为20,采用正态分布。
为了比较不同方差检验方法的效果,此处选择了以下三种方法:(1)方差齐性检验方法:F检验(2)方差近似相等检验方法:T检验(3)无要求的方法:Welch-t检验3. 实验步骤(1)根据上述设计,生成两个总体样本数据,并画图观察其差异。
(2)分别使用上述三种方法进行方差检验,并记录p值和检验结果。
4. 实验结果(1)生成的两个总体样本数据如下图所示:可以看出,两个总体的方差不相等,其中蓝色样本方差明显大于红色样本。
(2)使用三种方法进行方差检验,结果如下:方法|p值|检验结果--|--|--F检验|0.000004|拒绝原假设(方差相等)T检验|0.000021|拒绝原假设(方差相等)Welch-t检验|0.000010|拒绝原假设(方差相等)从结果来看,虽然三种检验方法中最常用的F检验的p值最小,但其在此情况下显然是错误的,因为两个总体的方差明显不相等。
而T检验和Welch-t检验的p值都比较小,而且其结果也正确,即两个总体方差不相等。
5. 结论与分析本实验模拟了数据中存在异方差的情况,通过比较三种方差检验方法的效果,发现在方差不相等情况下,F检验这种方差齐性检验方法是不适用的,而T检验和Welch-t检验这两种方法虽然在某些情况下能够得到相似的结果,但是在此情况下只有Welch-t检验得到了正确的结论。
因此,在实际情况中,如果我们无法保证数据方差相等,应该尽可能使用Welch-t检验,以确保检验结果的正确性。

第1篇一、实验目的1. 掌握异方差性的基本概念和检验方法。
2. 学会运用统计软件进行异方差的检验和修正。
3. 提高对计量经济学模型中异方差性处理能力的实践应用。
二、实验原理1. 异方差性:在回归分析中,若回归模型的误差项(残差)的方差随着自变量或因变量的取值而变化,则称模型存在异方差性。
2. 异方差性的检验方法:图形检验、统计检验(如F检验、Breusch-Pagan检验、White检验等)。
3. 异方差性的修正方法:加权最小二乘法(WLS)、广义最小二乘法(GLS)等。
三、实验步骤1. 数据准备1. 收集实验所需数据,确保数据质量和完整性。
2. 对数据进行初步处理,如剔除异常值、缺失值等。
2. 模型设定1. 根据研究问题,选择合适的回归模型。
2. 利用统计软件(如Eviews、Stata等)进行初步的回归分析。
3. 异方差性检验1. 图形检验:绘制散点图,观察残差与自变量或因变量的关系,初步判断是否存在异方差性。
2. 统计检验:- F检验:检验回归系数的显著性。
- Breusch-Pagan检验:检验残差平方和与自变量或因变量的关系。
- White检验:检验残差平方和与自变量或因变量的多项式关系。
4. 异方差性修正1. 若检验结果表明存在异方差性,则需对模型进行修正。
2. 选择合适的修正方法:- 加权最小二乘法(WLS):根据残差平方与自变量或因变量的关系,计算权重,加权最小二乘法进行回归分析。
- 广义最小二乘法(GLS):根据残差平方与自变量或因变量的关系,选择合适的方差结构,广义最小二乘法进行回归分析。
5. 结果分析1. 对修正后的模型进行回归分析,观察回归系数的显著性、拟合优度等指标。
2. 对实验结果进行分析,解释实验现象,验证研究假设。
6. 实验报告撰写1. 撰写实验报告,包括以下内容:- 实验目的- 实验原理- 实验步骤- 实验结果- 分析与讨论- 结论2. 实验报告应结构清晰、逻辑严谨、语言简洁。

实验四异方差性【实验目的】掌握异方差性的检验及处理方法【实验内容】建立并检验我国制造业利润函数模型【实验步骤】【例1】表1列出了1998年我国主要制造工业销售收入与销售利润的统计资料,请利用统计软件Eviews建立我国制造业利润函数模型。
一、检验异方差性⒈图形分析检验⑴观察销售利润(Y)与销售收入(X)的相关图(图1):SCA T X Y图1 我国制造工业销售利润与销售收入相关图从图中可以看出,随着销售收入的增加,销售利润的平均水平不断提高,但离散程度也逐步扩大。
这说明变量之间可能存在递增的异方差性。
⑵残差分析首先将数据排序(命令格式为:SORT 解释变量),然后建立回归方程。
在方程窗口中点击Resids按钮就可以得到模型的残差分布图(或建立方程后在Eviews工作文件窗口中点击resid对象来观察)。
图2 我国制造业销售利润回归模型残差分布图2显示回归方程的残差分布有明显的扩大趋势,即表明存在异方差性。
⒉Goldfeld-Quant检验⑴将样本按解释变量排序(SORT X)并分成两部分(分别有1到10共11个样本合19到28共10个样本)⑵利用样本1建立回归模型1(回归结果如图3),其残差平方和为2579.587。
SMPL 1 10LS Y C X图3 样本1回归结果⑶利用样本2建立回归模型2(回归结果如图4),其残差平方和为63769.67。
SMPL 19 28LS Y C X图4 样本2回归结果⑷计算F 统计量:12/RSS RSS F ==63769.67/2579.59=24.72,21RSS RSS 和分别是模型1和模型2的残差平方和。
取05.0=α时,查F 分布表得44.3)1110,1110(05.0=----F ,而44.372.2405.0=>=F F ,所以存在异方差性⒊White 检验⑴建立回归模型:LS Y C X ,回归结果如图5。
图5 我国制造业销售利润回归模型⑵在方程窗口上点击View\Residual\Test\White Heteroskedastcity,检验结果如图6。
异方差性实验报告doc异方差性实验报告篇一:计量经济学上机实验报告(异方差性)提示:打包保存时自己的文件夹以“学号姓名”为文件夹名,打包时文件夹内容包括:本实验报告、EViews工作文件。
篇二:Eviews异方差性实验报告实验一异方差性【实验目的】掌握异方差性问题出现的来源、后果、检验及修正的原理,以及相关的Eviews操作方法。
【实验内容】以《计量经济学学习指南与练习》补充习题4-16为数据,练习检查和克服模型的异方差的操作方法。
【4-16】表4-1给出了美国18个行业1988年研究开发(R&D)费用支出Y与销售收入X的数据。
请用帕克(Park)检验、戈里瑟(Gleiser)检验、G-Q检验与怀特(White)检验来检验Y关于X的回归模型是否存在异方差性?若存在【实验步骤】一检查模型是否存在异方差性1、图形分析检验(1)散点相关图分析做出销售收入X与研究开发费用Y的散点相关图(SCATX Y)。
观察相关图可以看出,随着销售收入的增加,研究开发费用的平均水平不断提高,但离散程度也逐步扩大。
这说明变量之间可能存在递增的异方差性。
(2)残差图分析首先对数据按照解释变量X由小至大进行排序(SORT X),然后建立一元线性回归方程(LS Y C X)。
因此,模型估计式为: Y?187.507?0.032*X ----------(*) ?(0.17)(2.88) R2=建立残差关于X的散点图,可以发现随着X增加,残差呈现明显的扩大趋势,表明存在递增的异方差。
2、Park检验建立回归模型(LS Y C X),结果如(*)式。
生成新变量序列: GENR LNE2 = LOG(RESID^2)GENR LNX = LOG(X)生成新残差序列对解释变量的回归模型(LS LNE2 C LNX)。
从下图所示的回归结果中可以看出,LNX的系数估计值不为0且能通过显著性检验,即随机误差项的方差与解释变量存在较强的相关关系,即认为存在异方差性。
异方差实验报告引言异方差(heteroscedasticity)是指随着自变量的变化,因变量的方差也随之变化的现象。
在统计分析中,假设方差是恒定的是很常见的,但在实际应用中,许多变量的方差是不恒定的,需要进行异方差处理。
本实验旨在通过模拟数据和实际数据来探究异方差的影响并了解异方差检验方法。
实验设计本实验分为两个部分。
第一部分使用模拟数据,提供了不同阶段下的异方差数据集。
第二部分使用实际数据,通过观察数据的模式来判断是否存在异方差。
实验方法模拟数据在模拟数据部分,我们生成了四个数据集,每个数据集都包含一个自变量和一个因变量。
为了模拟异方差,我们设定了不同的标准差,并与自变量呈一定的关系。
具体参数如下:•数据集1:使用正态分布生成自变量和因变量,因变量的标准差为自变量的两倍。
•数据集2:自变量为正态分布,因变量为自变量的2次方,并加入了一个随机误差项,使得方差在自变量变大时也会变大。
•数据集3:自变量为均匀分布,因变量为自变量的指数函数,并加入了一个随机误差项,使得方差在自变量变大时也会变大。
•数据集4:自变量为正态分布,因变量为自变量的对数,并加入了一个随机误差项,使得方差在自变量变大时也会变大。
实际数据在实际数据部分,我们使用了一份销售数据。
该数据包含了不同日期下的产品销售量和价格。
我们首先观察数据的散点图,并通过直观感受来猜测是否存在异方差。
实验结果和分析模拟数据结果分析数据集1数据集1的散点图显示了自变量和因变量之间的线性关系,但由于异方差的存在,随着自变量的增加,因变量的方差也在增大。
这说明了异方差对回归结果的影响。
数据集2数据集2的散点图显示了自变量和因变量之间的非线性关系。
由于自变量的增大,因变量的方差也在增大。
这与模型中设定的异方差关系一致。
数据集3数据集3的散点图显示了自变量和因变量之间的指数关系。
随着自变量的增大,因变量的方差也在增大,符合预期的异方差模式。
数据集4数据集4的散点图显示了自变量和因变量之间的对数关系。
异方差实验报告异方差实验报告引言在统计学中,方差是一种衡量数据分布离散程度的重要指标。
然而,在实际应用中,我们常常会遇到方差不稳定的情况,即异方差。
异方差的存在会对统计分析结果产生显著影响,因此,我们需要探索异方差的原因和解决方法。
本实验旨在通过模拟数据和实际案例来探讨异方差的现象、原因和处理方法。
一、异方差现象的模拟实验为了更好地理解异方差的现象,我们首先进行了一系列的模拟实验。
我们生成了两组数据,一组是服从正态分布的数据,另一组是服从泊松分布的数据。
然后,我们分别对两组数据进行方差分析,并比较其结果。
实验结果显示,当数据服从正态分布时,方差分析的结果较为稳定,各组之间的方差差异不大。
然而,当数据服从泊松分布时,方差分析的结果却出现了明显的差异。
这说明泊松分布的数据具有异方差性质。
二、异方差的原因分析为了深入理解异方差的原因,我们进一步探究了几个可能导致异方差的因素。
1. 数据的变换我们对泊松分布的数据进行了对数变换,然后再进行方差分析。
实验结果显示,经过对数变换后,数据的异方差性质得到了明显改善。
这说明,数据的变换可以在一定程度上解决异方差问题。
2. 数据的离散程度我们生成了两组服从正态分布的数据,一组具有较小的离散程度,另一组具有较大的离散程度。
实验结果显示,离散程度较大的数据组具有更明显的异方差性质。
这表明,数据的离散程度与异方差之间存在一定的关联。
3. 样本容量我们通过不断调整样本容量,观察方差分析结果的变化。
实验结果显示,随着样本容量的增加,方差分析结果的稳定性得到了明显改善。
这说明,样本容量的大小对异方差的影响是显著的。
三、处理异方差的方法针对异方差问题,统计学家们提出了多种处理方法。
以下是一些常见的方法:1. 方差齐性检验在进行统计分析之前,我们可以先对数据进行方差齐性检验。
常用的方差齐性检验方法包括Levene检验和Bartlett检验。
如果检验结果表明数据存在异方差,我们可以采取相应的处理方法。
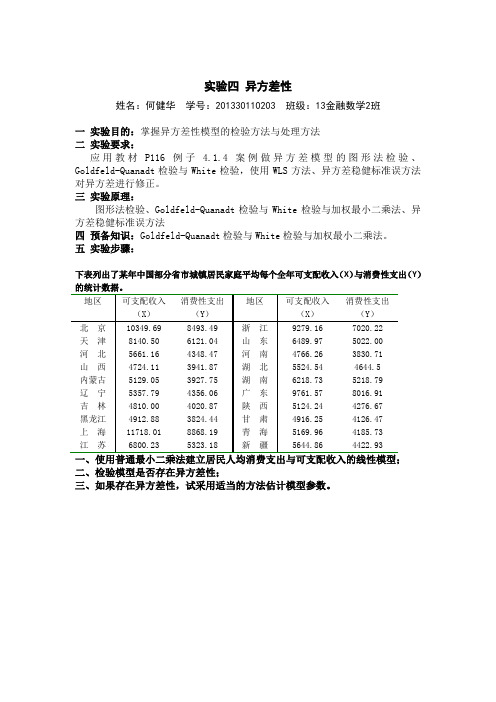
实验五异方差性一、实验目的掌握异方差的检验方法与处理方法.二、实验要求应用教材第116页案例做异方差模型的图形法检验、Goldfeld-Quanadt检验与White检验,使用WLS法对异方差进行修正;三、实验原理异方差性检验:图形法检验、Goldfeld-Quanadt检验、White检验与加权最小二乘法;四、实验步骤一、模型的OLS估计(1)录入数据打开EViews6,点“File”→“New”→“Workfile”选择“Unstructured/Undated”,在Observations 后输入21,如下所示:点击“ok”。
在命令行输入:DATA Y X,回车。
将数据复制粘贴到Group中的表格中,如下图:(2)估计回归方程在命令行输入命令:LS Y C X ,回车。
或者在主菜单中点“Quick ”→“Estimate Equation ”,在Specification 中输入 Y C X ,点“确定”。
得到如下估计结果: 写出回归方程:i ˆ562.9075 5.3728iY X =-+t=(-1.9306) (8.3398)2R=0.7854 F=69.55二、模型的异方差检验1、图示检验法(1)作散点图:X——Y在命令行输入命令:scat X Y ,回车(2)作散点图:X——2~ei首先生成残差的平方序列,在命令行输入命令:GENR E2=resid^2 ,回车。
作散点图:在命令行输入命令: SCAT X 2~e E2 ,回车,结果如下图。
i由上图可以看出,残差平方2~i e 对解释变量X 的散点图主要分布在图形中的下三角部分,大致看出残差平方2~i e 随i X 的变动呈增大的趋势,因此,模型很可能存在异方差。
2、模型的G-Q 检验 原假设0H :同方差 备择假设1H :异方差(1)首先将样本按X 由小到大的顺序排列,在命令行输入命令:SORT X 回车(2)去除掉中间的5个样本(n/4=5.25,为了使剩下的样本能被平均分成两份,去掉7个),将剩余的16个样本平均分为两份,每一份8个样本。
1、2 实验二 异方差性及其性质 1、2、1 实验目的我们已经知道,在经典条件下,线性模型回归参数的OLS 估计就是具有最小方差的线性无偏估计量。
随机误差项的异方差性,就是线性回归模型中常见的不满足经典条件的情形。
与满足经典条件的情形相比,当模型中出现异方差性时,模型参数的普通最小二乘(OLS)估计的统计性质将发生什么样的变化?如何理解与把握这些变化?如何纠正模型估计因为异方差性而产生的问题?通过本实验,可以帮助学生理解异方差性本身的概念、存在异方差性时模型参数的OLS 估计量的性质、加权最小二乘法等。
1、2、2 实验背景与理论基础 1、 异方差性本实验以二元线性回归模型为例进行说明。
线性回归模型01122i i i i Y X X u βββ=+++,1,2,,i n =L假设模型满足除“同方差性”之外的所有经典假设:(1)E()0i u =,1,2,,i n =L ,或表示为()E =U 0,从而有()E =Y X β; (3)Cov(,)0,i j u u i j =≠,随机误差无序列相关; (4)解释变量就是确定性变量,与随机误差项不相关:Cov(,)0j ij u X =,1,2i =,1,2,,j n =L(5)自变量之间不存在精确(完全)的线性关系。
矩阵X 就是列满秩的:rank()3=X 。
(要求样本容量3n >)(6)随机误差的正态性:2(0,)i u u N σ:,1,2,,i n =L 。
2、 异方差性条件下OLS 估计量的统计性质(1)ˆβ的无偏性: 模型回归参数012,,βββ 的OLS 估计量为:0112ˆˆˆ()ˆβββ-⎛⎫ ⎪''= ⎪ ⎪ ⎪⎝⎭β=X X X Y 可以证明,即使在异方差性条件下,上述估计量依然满足无偏性:0112ˆ()ˆˆE()()ˆ()E E E ββββββ⎛⎫⎛⎫ ⎪ ⎪= ⎪ ⎪⎪ ⎪ ⎪⎝⎭⎝⎭β==β (2)ˆβ的方差及协方差: 在模型满足经典条件时,OLS 估计量的方差—协方差矩阵为21ˆVar()()uσ-'=βX X ,但就是在异方差性条件下,不存在独立于X 的随机误差项方差2u σ,因此不再存在这一简单公式。
另一方面,在计量分析实践中,即使在线性回归模型的经典条件下,随机误差项的方差2u σ本身也不就是可直接观察的,实践中我们用()()22ˆ3u i e n σ=-∑对其进行估计(大多数统计分析软件正就是如此处理的),也即用矩阵21ˆ()u σ-'X X 去估计OLS 估计量ˆβ的方差—协方差矩阵ˆVar()β,并在此基础上对模型进行各种检验。
在线性回归模型的经典条件下,这种估计将就是无偏的(参见本章实验一)。
重要的问题就是,在异方差性条件下,如果无视异方差性的存在,仍用21ˆ()u σ-'X X 去估计OLS 估计量ˆβ的方差—协方差矩阵ˆVar()β,这种估计就是否仍具有无偏性?建立在这种估计之上的各种模型检验就是否依然有效?3、 加权最小二乘法修正异方差性的常用方法就是加权最小二乘法,它就是广义最小二乘法中的一种。
具体的方法就是:如果模型01122i i i i Y X X u βββ=+++中i u 的标准差为12(,)i i i f X X σ=,在原模型中乘以1/i σ,模型变为:120121iiiiiii i iY X X u βββσσσσσ=+++将此模型瞧成就是iiY σ对121,,iiii iX X σσσ的线性回归模型,此模型将具有同方差性,由于原模型满足除同方差性外的所有经典条件,因此上述模型将满足所有线性模型的经典条件,从此模型中利用最小二乘法估计参数012,,βββ 将获得具有最小方差的线性无偏估计量,这就就是加权最小二乘法及其原理。
1、2、3 实验原理本实验仍然通过一个虚构的二元线性回归模型来展开。
与本章实验一一样,我们首先设定一定二元线性回归模型的回归参数,取定解释变量的样本值。
由于就是存在异方差性的模型,不能再设定随机误差项的方差,但就是我们可以设定随机误差项的方差与解释变量值之间的函数关系。
这样,在总体上我们已经完全掌握了模型。
接着我们使用Matlab 进行模拟随机抽样,对于得到的每一个模拟随机样本,我们分别使用普通最小二乘法与加权最小二乘法得到模型参数的两种不同的估计量,分别记为012ˆˆˆ,,βββ 与012,,βββ %%%。
反复以上模拟抽样与估计,我们将分别得到每个模型参数的普通最小二乘估计量012ˆˆˆ,,βββ 与加权最小二乘估计量012,,βββ %%%的样本。
通过这两个样本,我们可以探讨普通最小二乘估计量与加权最小二乘估计量的统计性质,分析两者之间的共同性质与区别。
1、2、4 实验过程与步骤 1、 程序设计以下将实验过程通过编制一个简单的Matlab 程序来进行。
程序分为以下几个部分:(1)第一步,设置模型基本参数,解释变量的样本值,这一步与实验一的相应步骤就是类似的。
Matlab 程序段如下:clear n=20;beta0=10;beta1=5;beta2=-3; x1=15*rand(n,1)+1; x2=10*rand(n,1)+1; e=ones(n,1); X=[e,x1,x2];(2)第二步,反复抽取样本,进行普通最小二乘估计与加权最小二乘估计,并将估计结果保存在相应的向量中。
Matlab 程序段如下:b0=[];b1=[];b2=[];sigma=[]; c0=[];c1=[];c2=[]; XX=X 、/[x1,x1,x1]; times=5000; for j=1:timesuu=normrnd(0,se,n,1); u=2*x1、*uu;Y=beta0+beta1*x1+beta2*x2+u;[b,bint,r]=regress(Y,X);b0=[b0;b(1)];b1=[b1;b(2)];b2=[b2;b(3)];sigma=[sigma,sum(r 、^2)/(n-3)]; YY=Y 、/x1;[c,bint,r]=regress(YY,XX);c0=[c0;c(1)];c1=[c1;c(2)];c2=[c2;c(3)]; end代码解释:“b0=[];b1=[];b2=[];sigma1=[];”生成4个维数可变的动态向量,准备分别存放每次抽样所产生的普通最小二乘估计量012ˆˆˆ,,βββ 及2ˆ/(3)i u n -∑,其中ˆi u 为普通最小二乘回归的残差。
“c0=[];c1=[];c2=[];sigma2=[];”生成4个维数可变的动态向量,准备分别存放每次抽样所产生的加权最小二乘估计量估计量012,,βββ %%%及2/(3)i u n -∑%,其中iu %为加权最小二乘回归的残差。
“XX=X 、/[x1,x1,x1];”表示将矩阵X 的每一列向量的元素对应除以列向量X1的元素,也即得到矩阵211111221212211111111n n n X X X X X X XX X X X ⎛⎫ ⎪ ⎪ ⎪⎪= ⎪ ⎪ ⎪⎪ ⎪⎝⎭M M M生成这一矩阵的目的将在下文中揭示,实际上就是为下文中的加权最小二乘估计做准备。
“times=5000;”设定反复抽样与回归的次数,您可以根据需要设定成另外的整数;“uu=normrnd(0,1,n,1); ”随机生成分布N(0,1)的简单随机样本,构成n 维列向量12(,,,)n uu uu uu uu '=L ,“u=2*X1、*uu ”表示生成一个n 维列向量u,其元素就是列向量X1与uu 的对应元素的乘积再乘以2,即1111221(2,2,,2)n n u X uu X uu X uu '= L这表示随机误差12,,,n u u u L 相互间不相关,但其标准差为12i i X σ=(11,2,,)n =L 。
“Y=beta0+beta1*x1+beta2*x2+u;”利用以上生成的向量生成被解释变量Y 的一个模拟样本:10111221120112222201122n n n n Y X X u Y X X u Y Y X X u βββββββββ+++⎛⎫⎛⎫ ⎪ ⎪+++ ⎪ ⎪== ⎪ ⎪ ⎪ ⎪+++⎝⎭⎝⎭M M 这就是一个具有异方差性的二元线性回归模型的模拟样本,随机误差的标准差与解释变量x1的关系就是12i i X σ=。
“[b,bint,r]=regress(Y,X);”将 Y 对 X 进行普通最小二乘回归,获取估计结果参数,其中b 为回归系数点估计向量012ˆˆˆ(,,)βββ ,r 为残差列向量。
“b0=[b0;b(1)];” 将0ˆβ的值逐个存入数表b0,使b0于循环结束时成为times 维列向量。
“b1=[b1;b(2)];”将1ˆβ的值逐个存入数表b1,使b1于循环结束时成为times 维列向量。
“b2=[b2;b(3)];”将2ˆβ的值逐列存入数表b2,使b2于循环结束时成为times 维列向量。
“sigma=[sigma,sum(r 、^2)/(n-3)];”将由回归残差计算所得的值2ˆ/(3)iun -∑逐列存入数表sigma1,使sigma 于循环结束时成为times 维列向量。
“YY=Y 、/x1;”将向量Y 的分量分别除以向量x1的对应分量,得到列向量YY,即1112121///n n Y X Y X YY Y X ⎛⎫ ⎪ ⎪= ⎪ ⎪⎝⎭M“[c,bint,r]=regress(YY,XX);”将 YY 对 XX (参见前文中的XX 的构造)进行普通最小二乘回归,获取估计结果参数。
实际上,此时YY 对 XX 的普通最小二乘回归正就是对线性模型12012111111i i i i i i i i iY X X u X X X X X βββ=+++ 的普通最小二乘回归,由于i u 的标准差12i i X σ=,因此上述模型又等价于120121iiiii i i i iY X X u βββσσσσσ=+++对此模型的普通最小二乘估计正就是对原模型01122i i i i Y X X u βββ=+++的加权最小二乘估计。
因此上述命令中的c 为即为原模型回归参数的加权最小二乘估计向量012(,,)βββ %%%,r 为残差列向量。
“c0=[c0;c(1)];” 将0β%的值逐个存入数表c0,使c0于循环结束时成为times 维列向量;“c1=[c1;c(2)];” 将1β%的值逐个存入数表c1,使c1于循环结束时成为times 维列向量;“c2=[c2;c(3)];” 将2β%的值逐列存入数表c2,使c2于循环结束时成为times 维列向量。