超大规模集成电路第四次作业2016秋_段成华
- 格式:doc
- 大小:102.19 KB
- 文档页数:11

第1题
解:20世纪60年代,英特尔公司的创始人摩尔预测集成电路中单位面积集成的晶体管数目大约每十八个月翻一番。
此后的三十多年,半导体工艺技术基本上按照摩尔定律的预测发展。
根据世界半导体行业共同制定的2005年国际半导体技术发展路线,2020年以前集成电路仍将按照摩尔定律持续高速发展。
根据世界半导体行业共同制定的2005年国际半导体技术发展路线图(ITRS)及其更新,2014年将采用22nm工艺,2017年将采用16nm工艺,2020年将采用11nm 工艺。
2013年高性能芯片上可集成的集体管数量突破8.8G,片上局部时钟频率达到22GHz;预计2020年将这些数据会分别突破超过35.3G和73GHz。
工艺的实现也存在很多制约的因素:晶体管特征尺寸达到nm量级,这使得物理设计的难度大大增加;微处理器芯片的功耗将超过封装功耗极限200W/mm2的5倍即1KW/mm2,功耗问题仍是一个不可规避的问题;而信号在一个时钟周期内传输的距离之相当于芯片尺寸的十分之一左右,导线延迟将会成为处理器主频提高的瓶颈;片内处理能力的进一步加强对封装能力提出了新的挑战,封装能力会成为系统性能提升的瓶颈。
在更遥远的未来,碳纳米管因其超常的能量及半导体性能而被认为是最有可能取代硅,成为未来信息革命的导火索。
第2题
解:表2-1所示。
表2-1 三极管数量和时钟频率
年代三极管数量时钟频率典型处理器(Inter) 70年代2300~60000.5MHz~2MHz 4004、8008、8080 80年代20000~134000 4MHz~20MHz 8086、8088、80286 00年代9500000~55000000 100MHz~1.6GHz Pentium II、III、4。
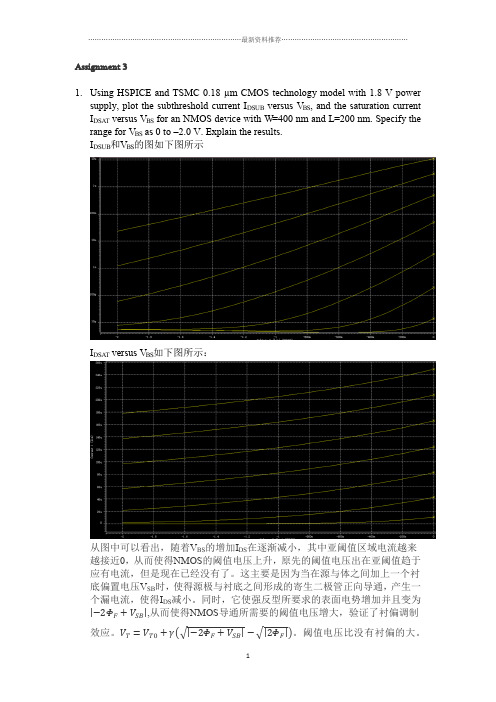
Assignment 3ing HSPICE and TSMC 0.18 µm CMOS technology model with 1.8 V powersupply, plot the subthreshold current I DSUB versus V BS, and the saturation currentI DSAT versus V BS for an NMOS device with W=400 nm and L=200 nm. Specify therange for V BS as 0 to –2.0 V. Explain the results.I DSUB和V BS的图如下图所示I DSAT versus V BS如下图所示:从图中可以看出,随着V BS的增加I DS在逐渐减小,其中亚阈值区域电流越来越接近0,从而使得NMOS的阈值电压上升,原先的阈值电压出在亚阈值趋于应有电流,但是现在已经没有了。
这主要是因为当在源与体之间加上一个衬底偏置电压V SB时,使得源极与衬底之间形成的寄生二极管正向导通,产生一个漏电流,使得I DS减小。
同时,它使强反型所要求的表面电势增加并且变为,从而使得NMOS导通所需要的阈值电压增大,验证了衬偏调制效应。
阈值电压比没有衬偏的大。
* SPICE INPUT FILE: problem.sp ID-VBS.param Supply=1.8 * Set value of Vdd.lib 'C:\synopsys\Hspice_A-2007.09\tsmc018\mm018.l' TT * Set 0.18um library .opt scale=0.1u * Set lambda*.model pch PMOS level=49 version=3.1*.model nch NMOS level=49 version=3.1mn Vdd gaten Gnd bn nch l=2 w=4 ad=20 pd=4 as=20 ps=4Vdd Vdd 0 'Supply'Vgsn gaten Gnd d cVbsn bn Gnd d c.dc Vbsn 0 -2 -0.05 Vgsn 0.6 1.8 0.2.print dc I1(mn).ending HSPICE and TSMC 0.18 um CMOS technology model with 1.8 V powersupply, plot log I DS versus V GS while varying V DS for an NMOS device withL=200 nm, W=800 nm and a PMOS with L=200 nm, W= 2 µm. Explain theresults.图中红线表示NMOS的I DS对V GS的曲线,从图中可以看出,随着V GS的增大I DS 的电流先为0,到后来逐渐增大,最后I DS对V GS的关系接近一个线性变化,且NMOS的导通电压约为0.43V,当V GS=0.43V的时候NMOS导通。


《超大规模集成电路物理设计:从图分割到时序收敛》读书笔记目录一、内容概览 (1)二、关于本书的背景知识介绍 (2)三、内容概览 (3)3.1 主要章节概述 (4)3.2 重点概念解析 (6)四、详细读书笔记 (7)五、本书中的关键观点和论点分析 (8)5.1 关于超大规模集成电路物理设计的关键观点 (10)5.2 书中论点的深度分析 (11)六、比较与评价 (13)6.1 本书与其他相关书籍的比较 (14)6.2 本书的优点与不足评价 (15)七、实践应用与案例分析 (16)7.1 书中理论在实际设计中的应用 (18)7.2 案例分析 (19)八、总结与心得体会 (21)8.1 本书的主要收获和启示 (22)8.2 个人对超大规模集成电路物理设计的未来展望 (23)一、内容概览《超大规模集成电路物理设计:从图分割到时序收敛》是一本深入探讨超大规模集成电路(VLSI)物理设计过程的著作。
本书从图分割的基本原理出发,详细阐述了集成电路设计的各个阶段,包括布局、布线、时序分析和验证等。
在图分割部分,本书介绍了如何将复杂的集成电路设计问题简化为更易于处理的子问题。
通过图论和计算机辅助设计(CAD)技术,作者提出了一系列高效的图分割算法,从而为后续的物理设计过程奠定了坚实的基础。
在布局阶段,本书重点讨论了如何根据电路结构和约束条件选择合适的布局算法。
作者详细分析了不同布局策略的优缺点,并提出了针对复杂电路的优化方法。
布线是集成电路设计中的关键步骤之一,本书介绍了多种布线算法,包括基于启发式的布线方法、基于物理约束的布线方法和基于人工智能技术的布线方法等。
作者还探讨了布线过程中的优化问题和挑战。
时序分析是确保集成电路正常工作的关键环节,本书详细阐述了时序分析的基本原理和方法,包括静态时序分析、动态时序分析和时序收敛等。
作者通过理论分析和实例验证,介绍了如何有效地进行时序分析和优化,以确保设计的集成电路具有良好的时序性能。
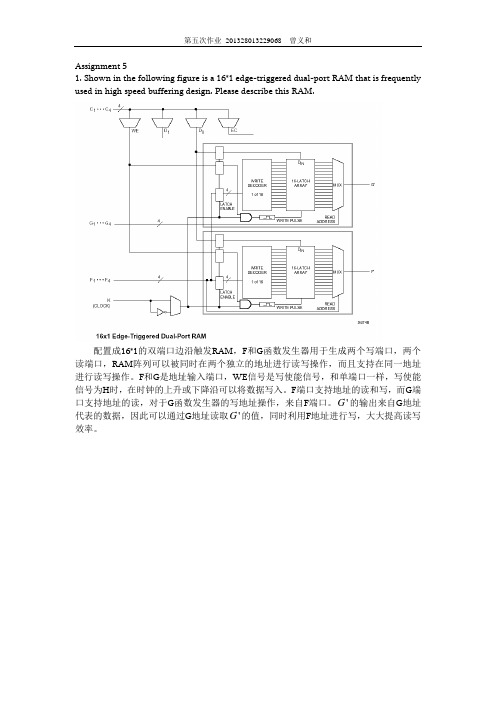
Assignment 51. Shown in the following figure is a 16*1 edge-triggered dual-port RAM that is frequently used in high speed buffering design. Please describe this RAM.配置成16*1的双端口边沿触发RAM,F和G函数发生器用于生成两个写端口,两个读端口,RAM阵列可以被同时在两个独立的地址进行读写操作,而且支持在同一地址进行读写操作。
F和G是地址输入端口,WE信号是写使能信号,和单端口一样,写使能信号为H时,在时钟的上升或下降沿可以将数据写入。
F端口支持地址的读和写,而G端G的输出来自G地址口支持地址的读,对于G函数发生器的写地址操作,来自F端口。
'G的值,同时利用F地址进行写,大大提高读写代表的数据,因此可以通过G地址读取'效率。
2. Metastability equations [Smith_ASICs]a. From Eq. 6.4: 0exp 1MTBF rcclock dataclock datat pf f T f f τ==,show that if we make twomeasurements of t r and MTBF then:1212ln MTBF ln MTBF r r c t t τ-=- (6.14)101exp MTBF r cc dt T f f τ=(6.15)解: 110expMTBF r cclock data t T f f τ=,220expMTBF r cclock datat T f f τ=得到101expMTBF r cc dt T f f τ=分别有:110=ln (MTBF )r clock data ct T f f τ,220=ln (MTBF )r clock data ct T f f τ121200-=ln (MTBF )-ln (MTBF )r r clock data clock data c ct t T f f T f f ττ⇒121200101220-=ln (MTBF )-ln (MTBF )ln (MTBF )==ln(MTBF MTBF )ln (MTBF )r r clock data clock data cclock data clock data t t T f f T f f T f f T f f τ⇒-1212ln MTBF ln MTBF r r c t t τ-⇒=-b. MTBU is extremely sensitive to variations in c τ, show that :()()22MTBU Maybe Wrong MTBU MTBU Maybe Right r c cr c ct dd t dd ττττ-=-= (6.16)颠倒的平均失效时间和颠倒的平均时间类似,可以用上式进行微分:由0expMTBU rcclock datat T f f τ=,201MTBU=exp ()r r cc clock data c t td d T f f τττ⋅- 有2MTBU=MTBU()r cc t dd ττ- c. Show that the variation in MTBU is related to the variation in c τ by the followingexpression:MTBU MTBU cr c ct τττ⎛⎫∆-∆⎛⎫=⎪ ⎪⎝⎭⎝⎭(6.17) 由2MTBU=MTBU()r cc t dd ττ-,得到MTBU =()MTBU c r c c d t d τττ⎛⎫- ⎪⎝⎭, 根据微分的性质可以得到:MTBU MTBU cr c ct τττ⎛⎫∆-∆⎛⎫=⎪⎪⎝⎭⎝⎭。

1.Shown below are buffer-chain designs.(1) Calculate the minimum delay of a chain of inverters for the overall effectivefan-out of 64/1.(2) Using HSPICE and TSMC 0.18 um CMOS technology model with 1.8 Vpower supply, design a circuit simulation scheme to verify them with their correspondent parameters of N, f, and t p.N=3.6 ∴N=3.246(1)γ=1 F=64∴f=√F所以最佳反相器数目约为3通过仿真可以得到tphl=1.3568E-11 tplh=1.7498E-11 tp0=1.5533E-11(2)N=1时,tphl= 5.2735E-10 tplh= 8.1605E-10 tpd= 6.7170E-10N=2时,tplh=2.2478E-10 tphl=2.5567E-10 tpd=2.4023E-10N=3时,tphl=2.0574E-10 tplh=2.1781E-10 tpd=2.1178E-10N=4时,tplh=2.1579E-10 tphl=2.2189E-10 tpd=2.1884E-10从仿真结果可以看出N=3或者N=4时延迟时间最优,且N=2、3、4得到的仿真延迟时间与理论推导的时间比较接近,比例基本上是18、15、15.3,而N=1时仿真得到的延迟时间远小于理论推导的时间,但是最优结果依旧是N=3,f=4,tp=15。
* SPICE INPUT FILE: Bsim3demo1.sp--a chain of inverters.param Supply=1.8.lib 'C:\synopsys\Hspice_A-2007.09\tsmc018\mm018.l' TT.option captab.option list node post measout.tran 10p 6000p************************************************************.param tdval=10p.meas tran tplh trig v(in) val=0.9 td=tdval rise=2+targ v(out) val=0.9 rise=2.meas tran tphl trig v(in) val=0.9 td=tdval fall=2+targ v(out) val=0.9 fall=2.meas tpd param='(tphl+tplh)/2'*macro definitions**************************************************************nmos1.subckt nmos1 n1 n2 n3mn n1 n2 n3 Gnd nch l=0.2u w=0.4u ad=0.2p^2 pd=0.4u as=0.2p^2 ps=0.4u.ends nmos1**pmos1*.subckt pmos1 p1 p2 p3mp p1 p2 p3 Vcc pch l=0.2u w=0.8u ad=0.4p^2 pd=0.8u as=0.4p^2 ps=0.8u.ends pmos1*.subckt inv1 in outxmn out in Gnd nmos1xmp out in Vcc pmos1vcc Vcc Gnd Supply.ends inv1**nmos2*.subckt nmos2 n1 n2 n3mn n1 n2 n3 Gnd nch l=0.2u w=1.12u ad=0.56p^2 pd=1.12u as=0.56p^2 ps=1.12u .ends nmos2**pmos2*.subckt pmos2 p1 p2 p3mp p1 p2 p3 Vcc pch l=0.2u w=2.24u ad=1.12p^2 pd=2.24u as=1.12p^2 ps=2.24u .ends pmos2*.subckt inv2 in outxmn out in Gnd nmos2xmp out in Vcc pmos2vcc Vcc Gnd Supply.ends inv2**nmos3*.subckt nmos3 n1 n2 n3mn n1 n2 n3 Gnd nch l=0.2u w=3.2u ad=1.6p^2 pd=3.2u as=1.6p^2 ps=3.2u.ends nmos3**pmos3.subckt pmos3 p1 p2 p3mp p1 p2 p3 Vcc pch l=0.2u w=6.4u ad=3.2p^2 pd=6.4u as=3.2p^2 ps=6.4u.ends pmos3*.subckt inv3 in outxmn out in Gnd nmos3xmp out in Vcc pmos3vcc Vcc Gnd Supply.ends inv3**nmos4*.subckt nmos4 n1 n2 n3mn n1 n2 n3 Gnd nch l=0.2u w=9.04u ad=4.52p^2 pd=9.04u as=4.52p^2 ps=9.04u.ends nmos4**pmos4*.subckt pmos4 p1 p2 p3mp p1 p2 p3 Vcc pch l=0.2u w=18.08u ad=9.04p^2 pd=18.08u as=9.04p^2 ps=18.08u .ends pmos4*.subckt inv4 in outxmn out in Gnd nmos4xmp out in Vcc pmos4vcc Vcc Gnd Supply.ends inv4*main circuit netlistxinv1 in out1 inv1xinv2 out1 out2 inv2xinv3 out2 out3 inv3xinv4 out3 out inv4cl out Gnd 154.24fVin in Gnd 0.9 pulse(0.0 1.8 219p 40p 40p 1100p 2400p).print tran v(in) v(out).end2.Consider the logic network below, which may represent the critical path of a morecomplex logic block. The output of the。
1. Shown below are buffer-chain designs.(1) Calculate the minimum delay of a chain of inverters for the overalleffective fan-out of 64/1.Solution :由题可知:64=F 根据经验6.3=opt f 为最合适的值,所以6.364===N N F f ,所以24.3=N ,但是级数必须为整数所以取3=N ,又因为1=γ,所以:15)641(3,464303=+⨯===p p t t f ,所以时最合适4=f 。
(2) Using HSPICE and TSMC 0.18 um CMOS technology model with1.8 V power supply, design a circuit simulation scheme to verify themwith their correspondent parameters of N, f, and t p .Solution:根据(1)中计算知道三级最合适,所以验证如下:A )、一级无负载测本征延时代码如下:.title buffer-chain 1.lib 'C:\synopsys\Hspice_D-2010.03-SP1\tsmc018\mm018.l' TT * set0.18um library.opt scale=0.1u * set lambda.options post=2 list.temp 27.global vddVdd vdd gnd 1.8vin vin 0 0.9 pulse 0 1.8 25n 5p 5p 49.99n 100n $频率为10MhzCl vout gnd 0f $Cg1=2.46fF,负载为CL=157.44fF.subckt inv in out wn=3.5 wp=10 t=7.5mn out in gnd gnd NCH l=2 w=wn ad='wn*t' pd='wn+2*t' as='wn*t' ps='wn+2*t'mp out in vdd vdd PCH l=2 w=wp ad='wp*t' pd='wp+2*t' as='wp*t' ps='wp+2*t'.endsX1 vin vout inv wn=3.5 wp=10 t=7.5.op.tran 5p 5n.meas tran voutmax max v(vout) from=5p to=5n.meas tran voutmin min v(vout) from=5p to=5n$一级.meas tran tphl1+trig v(vin)+val=0.9+rise=1+targ v(vout)+val='0.5*(voutmax-voutmin)+voutmin'+fall=1.meas tran tplh1+trig v(vin)+val=0.9+fall=1+targ v(vout)+val='0.5*(voutmax-voutmin)+voutmin'+rise=1.end1)一级无负载测得本征延时约为17ps;2)带上64倍Cg1大小的负载测得延时为750.35ps,是本征延时的44倍B)、三级带负载测延时代码如下:.title buffer-chain 3.lib 'C:\synopsys\Hspice_D-2010.03-SP1\tsmc018\mm018.l' TT * set 0.18um library.opt scale=0.1u * set lambda.options post=2 list.temp 27.global vdd.param fan=4Vdd vdd gnd 1.8vin vin 0 0.9 pulse 0 1.8 25n 5p 5p 49.99n 100nCl vout gnd 0f $Cg1=2.46fF,负载为CL=157.44fF.subckt inv in out wn=3.5 wp=10 t=7.5mn out in gnd gnd NCH l=2 w=wn ad='wn*t' pd='wn+2*t' as='wn*t' ps='wn+2*t'mp out in vdd vdd PCH l=2 w=wp ad='wp*t' pd='wp+2*t' as='wp*t' ps='wp+2*t'.endsX1 vin 2 inv wn=3.5 wp=10 t=7.5X2 2 3 inv wn='fan*3.5' wp='fan*10' t=5X3 3 vout inv wn='fan*fan*3.5' wp='fan*fan*10' t=5.op.tran 50p 500n.meas tran voutmax max v(vout) from=50p to=500n.meas tran voutmin min v(vout) from=50p to=500n$三级.meas tran tphl3+trig v(vin)+val=0.9+rise=1+targ v(vout)+val='0.5*(voutmax-voutmin)+voutmin'+fall=1.meas tran tplh3+trig v(vin)+val=0.9+fall=1+targ v(vout)+val='0.5*(voutmax-voutmin)+voutmin'+rise=11)带上64倍Cg1大小的负载测得延时为174.6ps ,是本征延时的10.27倍总结如下:经过调整参数近似时每一级的1=γ,所以经过手工计算得到一级带负载和三级带负载的延时比值为:2344.065151300==p p t t tp tp ,而仿真得到的结果为2327.035.7506.174=,所以符合手工计算的比值,同理其他级的延时代码也是如上的写法,经过仿真得到三级延时最小。
超大规模集成电路2017年秋段成华老师第三次作业(总6页)--本页仅作为文档封面,使用时请直接删除即可----内页可以根据需求调整合适字体及大小--Assignment 3ing HSPICE and TSMC µm CMOS technology model with V power supply,plot the subthreshold current I DSUB versus V BS, and the saturation current I DSATversus V BS for an NMOS device with W=400 nm and L=200 nm. Specify the range for V BS as 0 to – V. Explain the results.I DSUB和V BS的图如下图所示I DSAT versus V BS如下图所示:从图中可以看出,随着V BS的增加I DS在逐渐减小,其中亚阈值区域电流越来越接近0,从而使得NMOS的阈值电压上升,原先的阈值电压出在亚阈值趋于应有电流,但是现在已经没有了。
这主要是因为当在源与体之间加上一个衬底偏置电压V SB时,使得源极与衬底之间形成的寄生二极管正向导通,产生一个漏电流,使得I DS减小。
同时,它使强反型所要求的表面电势增加并且变为|−2ΦF+V SB|,从而使得NMOS导通所需要的阈值电压增大,验证了衬偏调制效应。
V T=V T0+γ(√|−2ΦF+V SB|−√|2ΦF|)。
阈值电压比没有衬偏的大。
* SPICE INPUT FILE: ID-VBS.param Supply= * Set value of Vdd.lib 'C:\synopsys\\tsmc018\' TT * Set library.opt scale= * Set lambda*.model pch PMOS level=49 version=*.model nch NMOS level=49 version=mn Vdd gaten Gnd bn nch l=2 w=4 ad=20 pd=4 as=20 ps=4Vdd Vdd 0 'Supply'Vgsn gaten Gnd dcVbsn bn Gnd dc.dc Vbsn 0 -2 Vgsn.print dc I1(mn).ending HSPICE and TSMC um CMOS technology model with V power supply,plot log I DS versus V GS while varying V DS for an NMOS device with L=200 nm, W=800 nm and a PMOS with L=200 nm, W= 2 µm. Explain the results.图中红线表示NMOS的I DS对V GS的曲线,从图中可以看出,随着V GS的增大I DS的电流先为0,到后来逐渐增大,最后I DS对V GS的关系接近一个线性变化,且NMOS的导通电压约为,当V GS=的时候NMOS导通。
1.集成电路的发展过程经历了哪些发展阶段?划分集成电路的标准是什么?集成电路的发展过程:•小规模集成电路(Small Scale IC,SSI)•中规模集成电路(Medium Scale IC,MSI)•大规模集成电路(Large Scale IC,LSI)•超大规模集成电路(Very Large Scale IC,VLSI)•特大规模集成电路(Ultra Large Scale IC,ULSI)•巨大规模集成电路(Gigantic Scale IC,GSI)划分集成电路规模的标准2.超大规模集成电路有哪些优点?1. 降低生产成本VLSI减少了体积和重量等,可靠性成万倍提高,功耗成万倍减少.2.提高工作速度VLSI内部连线很短,缩短了延迟时间.加工的技术越来越精细.电路工作速度的提高,主要是依靠减少尺寸获得.3. 降低功耗芯片内部电路尺寸小,连线短,分布电容小,驱动电路所需的功率下降.4. 简化逻辑电路芯片内部电路受干扰小,电路可简化.5.优越的可靠性采用VLSI后,元件数目和外部的接触点都大为减少,可靠性得到很大提高。
6.体积小重量轻7.缩短电子产品的设计和组装周期一片VLSI组件可以代替大量的元器件,组装工作极大的节省,生产线被压缩,加快了生产速度.3.简述双阱CMOS工艺制作CMOS反相器的工艺流程过程。
1、形成N阱2、形成P阱3、推阱4、形成场隔离区5、形成多晶硅栅6、形成硅化物7、形成N管源漏区8、形成P管源漏区9、形成接触孔10、形成第一层金属11、形成第一层金属12、形成穿通接触孔13、形成第二层金属14、合金15、形成钝化层16、测试、封装,完成集成电路的制造工艺4.在VLSI设计中,对互连线的要求和可能的互连线材料是什么?互连线的要求低电阻值:产生的电压降最小;信号传输延时最小(RC时间常数最小化)与器件之间的接触电阻低长期可靠工作可能的互连线材料金属(低电阻率),多晶硅(中等电阻率),高掺杂区的硅(注入或扩散)(中等电阻率)5.在进行版图设计时为什么要制定版图设计规则?—片集成电路上有成千上万个晶体管和电阻等元件以及大量的连线。
1. Shown below are buffer-chain designs.(1) Calculate the minimum delay of a chain of inverters for the overalleffective fan-out of 64/1.Solution :由题可知:64=F 根据经验6.3=opt f 为最合适的值,所以6.364===N N F f ,所以24.3=N ,但是级数必须为整数所以取3=N ,又因为1=γ,所以:15)641(3,464303=+⨯===p p t t f ,所以时最合适4=f 。
(2) Using HSPICE and TSMC 0.18 um CMOS technology model with1.8 V power supply, design a circuit simulation scheme to verify themwith their correspondent parameters of N, f, and t p .Solution:根据(1)中计算知道三级最合适,所以验证如下:A )、一级无负载测本征延时代码如下:.title buffer-chain 1.lib 'C:\synopsys\Hspice_D-2010.03-SP1\tsmc018\mm018.l' TT * set0.18um library.opt scale=0.1u * set lambda.options post=2 list.temp 27.global vddVdd vdd gnd 1.8vin vin 0 0.9 pulse 0 1.8 25n 5p 5p 49.99n 100n $频率为10MhzCl vout gnd 0f $Cg1=2.46fF,负载为CL=157.44fF.subckt inv in out wn=3.5 wp=10 t=7.5mn out in gnd gnd NCH l=2 w=wn ad='wn*t' pd='wn+2*t' as='wn*t' ps='wn+2*t'mp out in vdd vdd PCH l=2 w=wp ad='wp*t' pd='wp+2*t' as='wp*t' ps='wp+2*t'.endsX1 vin vout inv wn=3.5 wp=10 t=7.5.op.tran 5p 5n.meas tran voutmax max v(vout) from=5p to=5n.meas tran voutmin min v(vout) from=5p to=5n$一级.meas tran tphl1+trig v(vin)+val=0.9+rise=1+targ v(vout)+val='0.5*(voutmax-voutmin)+voutmin'+fall=1.meas tran tplh1+trig v(vin)+val=0.9+fall=1+targ v(vout)+val='0.5*(voutmax-voutmin)+voutmin'+rise=1.end1)一级无负载测得本征延时约为17ps;2)带上64倍Cg1大小的负载测得延时为750.35ps,是本征延时的44倍B)、三级带负载测延时代码如下:.title buffer-chain 3.lib 'C:\synopsys\Hspice_D-2010.03-SP1\tsmc018\mm018.l' TT * set 0.18um library.opt scale=0.1u * set lambda.options post=2 list.temp 27.global vdd.param fan=4Vdd vdd gnd 1.8vin vin 0 0.9 pulse 0 1.8 25n 5p 5p 49.99n 100nCl vout gnd 0f $Cg1=2.46fF,负载为CL=157.44fF.subckt inv in out wn=3.5 wp=10 t=7.5mn out in gnd gnd NCH l=2 w=wn ad='wn*t' pd='wn+2*t' as='wn*t' ps='wn+2*t'mp out in vdd vdd PCH l=2 w=wp ad='wp*t' pd='wp+2*t' as='wp*t' ps='wp+2*t'.endsX1 vin 2 inv wn=3.5 wp=10 t=7.5X2 2 3 inv wn='fan*3.5' wp='fan*10' t=5X3 3 vout inv wn='fan*fan*3.5' wp='fan*fan*10' t=5.op.tran 50p 500n.meas tran voutmax max v(vout) from=50p to=500n.meas tran voutmin min v(vout) from=50p to=500n$三级.meas tran tphl3+trig v(vin)+val=0.9+rise=1+targ v(vout)+val='0.5*(voutmax-voutmin)+voutmin'+fall=1.meas tran tplh3+trig v(vin)+val=0.9+fall=1+targ v(vout)+val='0.5*(voutmax-voutmin)+voutmin'+rise=11)带上64倍Cg1大小的负载测得延时为174.6ps ,是本征延时的10.27倍总结如下:经过调整参数近似时每一级的1=γ,所以经过手工计算得到一级带负载和三级带负载的延时比值为:2344.065151300==p p t t tp tp ,而仿真得到的结果为2327.035.7506.174=,所以符合手工计算的比值,同理其他级的延时代码也是如上的写法,经过仿真得到三级延时最小。
.end2. Consider the logic network below, which may represent the criticalpath of a more complex logic block. The output of the network isloaded with a capacitance which is 5 times larger than the inputcapacitance of the first gate, which is a minimum-sized inverter. Theeffective fanout of the path hence equals F = C L /Cg1 = 5.Using HSPICE and TSMC 0.18 um CMOS technology model with 1.8 Vpower supply, design a circuit simulation scheme to verify theOPTIMAZATION parameters of g , f , and s for each of the inverter andgates.Solution: 由题得到路径逻辑努力925135351=⨯⨯⨯=G ,由于没有分支B =1,所以9125==GFB H ,所以使延时最小的逻辑努力为93.191254===N H h ,得到如下的扇出系数:93.1,16.1,16.1,93.14321====f f f f ,利用书上公式6.18计算得到尺寸系数6.2/,34.1/,16.1/,14132143121321121=======g g f f f S g g f f S g g f S S 。
电路仿真代码如下:.title INV 2NAND 2NOR.lib 'C:\synopsys\Hspice_D-2010.03-SP1\tsmc018\mm018.l' TT * set0.18um library.options post=2 list.temp 27.global vddVdd vdd gnd 1.8vin vin 0 0.9 pulse 0.0 1.8 150p 5p 5p 290p 600pC1 vout gnd 12.3f $Cg1=2.46fF,所以负载为12.3fF.subckt inv1 in out wn=0.35u wp=1u t=0.75umn out in gnd gnd NCH l=0.2u w=wn ad='wn*t' pd='wn+2*t' as='wn*t' ps='wn+2*t'mp out in vdd vdd PCH l=0.2u w=wp ad='wp*t' pd='wp+2*t' as='wp*t' ps='wp+2*t'.ends.subckt nand3 NAND-A1 NAND-D1 NAND-B1 NAND-C1 wn='0.35u*1.16' wp='1u*1.16't=0.5u $优化尺寸系数S2*.subckt nand3 NAND-A1 NAND-D1 NAND-B1 NAND-C1 wn=0.35u wp=1u t=0.5u $未优化尺寸系数S2mn3 NAND-S2 NAND-C1 gnd gnd NCH l=0.2u w=wn ad='wn*t' pd='wn+2*t' as='wn*t' ps='wn+2*t'mn2 NAND-S1 NAND-B1 NAND-S2 gnd NCH l=0.2u w=wn ad='wn*t' pd='wn+2*t' as='wn*t' ps='wn+2*t'mn1 NAND-D1 NAND-A1 NAND-S1 gnd NCH l=0.2u w=wn ad='wn*t'pd='wn+2*t' as='wn*t' ps='wn+2*t'mp1 NAND-D1 NAND-A1 vdd vdd PCH l=0.2u w=wp ad='wp*t' pd='wp+2*t' as='wp*t' ps='wp+2*t'mp2 NAND-D1 NAND-B1 vdd vdd PCH l=0.2u w=wp ad='wp*t' pd='wp+2*t' as='wp*t' ps='wp+2*t'mp3 NAND-D1 NAND-C1 vdd vdd PCH l=0.2u w=wp ad='wp*t' pd='wp+2*t' as='wp*t' ps='wp+2*t'.ends.subckt nor2 NOR-A1 NOR-D1 NOR-B1 wn='0.35u*1.34' wp='1u*1.34' t=0.5u $优化尺寸系数S3*.subckt nor2 NOR-A1 NOR-D1 NOR-B1 wn=0.35u wp=1u t=0.5u $未优化尺寸系数S3mn2 NOR-D1 NOR-B1 gnd gnd NCH l=0.2u w=wn ad='wn*t' pd='wn+2*t' as='wn*t' ps='wn+2*t'mn1 NOR-D1 NOR-A1 gnd gnd NCH l=0.2u w=wn ad='wn*t' pd='wn+2*t' as='wn*t' ps='wn+2*t'mp1 NOR-S1 NOR-A1 vdd vdd PCH l=0.2u w=wp ad='wp*t' pd='wp+2*t' as='wp*t' ps='wp+2*t'mp2 NOR-D1 NOR-B1 NOR-S1 vdd PCH l=0.2u w=wp ad='wp*t' pd='wp+2*t' as='wp*t' ps='wp+2*t'.ends.subckt inv2 in out wn='0.35u*2.6' wp='1u*2.6' t=0.5u $优化尺*.subckt inv2 in out wn=0.35u wp=1u t=0.5u $未优化尺寸系数S4mn out in gnd gnd NCH l=0.2u w=wn ad='wn*t' pd='wn+2*t' as='wn*t' ps='wn+2*t'mp out in vdd vdd PCH l=0.2u w=wp ad='wp*t' pd='wp+2*t' as='wp*t' ps='wp+2*t'.endsX1 vin 2 inv1X2 2 3 vdd vdd nand3X3 3 4 gnd nor2X4 4 vout inv2.op.tran 5p 3000p.meas tran voutmax max v(vout) from=5p to=3000p.meas tran voutmin min v(vout) from=5p to=3000p.meas tran tphl+trig v(vin)+val=0.9+rise=2+targ v(vout)+val='0.5*(voutmax-voutmin)+voutmin'.meas tran tplh+trig v(vin)+val=0.9+fall=2+targ v(vout)+val='0.5*(voutmax-voutmin)+voutmin'+fall=2.end$Cg1=2.46fF,所以负载为12.3fF仿真结果如下:尺寸系数全部优化得到的tphl和tplh尺寸系数全部未优化得到的tphl和tplhVout对比图:粉线是尺寸系数全部未优化、浅蓝线是尺寸系数未优化的输出电压、绿线是输入电压波形;..从结果上来看,未优化的tphl和tplh均比优化过的tphl和tplh值要小几十个ps,所以计算得到的尺寸系数是有效的减少了总的延时时间。