SAS中的SQL语句大全
- 格式:doc
- 大小:88.50 KB
- 文档页数:49

SAS中的SQL语句完全教程之一:SQL简介与基本查询功能本系列全部内容主要以《SQL Processing with the SAS System (Course Notes)》为主进行讲解,本书是在网上下载下来的,但忘了是在哪个网上下的,故不能提供下载链接了,需要的话可以发邮件向我索取,我定期邮给大家,最后声明一下所有资料仅用于学习,不得用于商业目的,否则后果自负。
1 SQL过程步介绍SQL过程步可以实现下列功能:查询SAS数据集、从SAS数据集中生成报表、以不同方式实现数据集合并、创建或删除SAS数据集、视图、索引等、更新已存在的数据集、使得SAS系统可以使用SQL语句、可以和SAS的数据步进行替换使用。
注意,SQL过程步并不是用来代替SAS数据步,也不是一个客户化的报表工具,而是数据处理用到的查询工具。
SQL过程步的特征SQL过程步并不需要对每一个查询进行重复、每条语句都是单独处理、不需要print过程步就能打印出查询结果、也不用sort过程步进行排序、不需要run、要quit来结束SQL 过程步SQL过程步语句SELECT:查询数据表中的数据ALTER:增加、删除或修改数据表的列CREATE:创建一个数据表DELETE:删除数据表中的列DESCRIBE:列出数据表的属性DROP:删除数据表、视图或索引INSERT:对数据表插入数据RESET:没用过,不知道什么意思SELECT:选择列进行打印UPDATE:对已存在的数据集的列的值进行修改2 SQL基本查询功能SELECT语句基本语法介绍SELECT <DISTINCT> object-item <, ...object-item>FROM from-list<WHERE sql-expression><GROUP BY group-by-item <, ... group-by-item>><HAVING sql-expression><ORDER BY order-by-item <, ... order-by-item>>;这里SELECT:指定被选择的列FROM:指定被查询的表名WHERE:子数据集的条件GROUP BY:将数据集通过group进行分类HAVING:根据GROUP BY的变量得到数据子集ORDER BY:对数据集进行排序SELECT语句的特征选择满足条件的数据、数据分组、对数据进行排序、对数据指定格式、一次最多查询32个表。

MSSQL语句大全和常用SQL语句命令的作用
1.SELECT:用于从数据库中检索数据,可以选择特定的列和行。
2.INSERTINTO:用于向数据库表中插入数据。
3.UPDATE:用于更新数据库表中的数据。
4.DELETEFROM:用于从数据库表中删除数据。
5.CREATEDATABASE:用于创建新的数据库。
6.CREATETABLE:用于创建新的数据表。
7.ALTERTABLE:用于修改数据库表的结构,如添加、修改或删除列。
8.DROPDATABASE:用于删除整个数据库及其相关的对象。
9.DROPTABLE:用于删除数据库中的数据表。
10.TRUNCATETABLE:用于删除表中的所有数据,但不删除表结构。
11.ORDERBY:用于对结果集进行排序。
12.GROUPBY:用于将结果集按照一个或多个列进行分组。
13.WHERE:用于筛选结果集,只返回符合指定条件的行。
14.HAVING:用于筛选分组后的结果集,只返回符合指定条件的分组。
15.JOIN:用于将两个或多个表根据一个或多个共同的字段进行连接。
16.UNION:用于合并两个或多个SELECT语句的结果集。
17.LIKE:用于在WHERE子句中进行模糊匹配。
18.IN:用于指定一个条件范围。
以上是一些常用的SQL语句命令,通过这些命令可以实现对数据库的增删改查操作,并对结果集进行排序、分组、连接等处理。

SAS中用到的SQL语法及结构在SAS中使用SQL语言,可以对数据进行查询、插入、更新和删除等操作。
以下是SAS中常用的SQL语法及结构的详细介绍。
1.SELECT语句:用于查询数据表中的数据。
SELECT column1, column2, ...FROM table_nameWHERE condition;示例:SELECT*FROM employeesWHERE department = 'HR';2.INSERTINTO语句:用于向数据表中插入新的记录。
INSERT INTO table_name (column1, column2, ...)VALUES (value1, value2, ...);示例:INSERT INTO employees (name, age, department)VALUES ('John Smith', 35, 'Finance');3.UPDATE语句:用于更新数据表中的记录。
UPDATE table_nameSET column1 = value1, column2 = value2, ...WHERE condition;示例:UPDATE employeesSET department = 'IT'WHERE name = 'John Smith';4.DELETE语句:用于从数据表中删除记录。
DELETE FROM table_nameWHERE condition;示例:DELETE FROM employeesWHERE age > 50;5.DISTINCT关键字:用于查询唯一的记录。
SELECT DISTINCT column1, column2, ...FROM table_nameWHERE condition;示例:SELECT DISTINCT departmentFROM employees;6.ORDERBY关键字:用于对查询结果进行排序。

sas sql count 条件
SAS SQL中可以使用COUNT函数进行条件统计。
基本语法如下: SELECT COUNT(*) FROM 表名 WHERE 条件;
这个语句会统计满足WHERE条件的记录数。
例如,统计class表中性别为'M'的学生人数:
SELECT COUNT(*) FROM class WHERE sex = 'M';
统计class表中年龄大于20岁的学生人数:
SELECT COUNT(*) FROM class WHERE age > 20;
COUNT函数也可以与GROUP BY结合使用,对不同分组进行统计: SELECT sex, COUNT(*) FROM class GROUP BY sex;
这个语句会统计class表中男性和女性学生的人数。
通过在COUNT函数中添加DISTINCT,可以统计不同值的个数: SELECT COUNT(DISTINCT sex) FROM class;
SAS SQL中的COUNT函数非常有用,可以快速进行条件统计。
需要注意的是NULL值不会被统计,如果要统计全部记录数,使用COUNT(*)而不是COUNT(字段名)。

sql命令语句嘿,朋友!你知道 SQL 命令语句吗?这玩意儿可太重要啦!就好比是一把神奇的钥匙,能打开数据库那神秘宝库的大门。
比如说,当你想要从一个超级大的数据库里找出特定的信息,这时候 SQL 的 SELECT 语句就派上用场啦!“SELECT * FROM table_name”,就像你在茫茫人海中精准地找到你要找的那个人一样神奇!你能想象没有它该怎么办吗?还有啊,INSERT 语句,那简直就是给数据库添加新东西的魔法棒呀!“INSERT INTO table_name (column1, column2, column3) VALUES (value1, value2, value3)”,这不就像是给一个空房间里添置新家具嘛,一下子就让它丰富起来了。
UPDATE 语句呢,就像是给已有的东西做个小改造,让它更符合你的需求。
“UPDATE table_name SET column1 = value1 WHERE condition”,这多像给一件衣服换个扣子或者改个颜色呀!DELETE 语句,哎呀,这可有点厉害咯!它就像是把不需要的东西直接清理掉。
“DELETE FROM table_name WHERE condition”,这就像你清理房间时扔掉那些没用的杂物一样果断。
我之前和一个朋友一起做项目,他对 SQL 命令语句不太熟悉,结果在处理数据的时候那叫一个手忙脚乱啊!我就跟他说:“嘿,你得好好学学 SQL 命令语句呀,不然这工作可没法干啦!”他还不信,后来吃了不少苦头才意识到重要性。
SQL 命令语句真的是太实用啦!它是我们和数据库沟通的桥梁,没有它,我们怎么能在数据的海洋里畅游呢?所以呀,一定要好好掌握它,让它为我们的工作和生活带来便利!这就是我的观点,SQL 命令语句,不可或缺!。

S A S中的S Q L语句大全标准化管理处编码[BBX968T-XBB8968-NNJ668-MM9N]SAS中的SQL语句完全教程之一:SQL简介与基本查询功能本系列全部内容主要以《SQL Processing with the SAS System (Course Notes)》为主进行讲解,本书是在网上下载下来的,但忘了是在哪个网上下的,故不能提供下载链接了,需要的话可以发邮件向我索取,我定期邮给大家,最后声明一下所有资料仅用于学习,不得用于商业目的,否则后果自负。
1 SQL过程步介绍SQL过程步可以实现下列功能:查询SAS数据集、从SAS数据集中生成报表、以不同方式实现数据集合并、创建或删除SAS数据集、视图、索引等、更新已存在的数据集、使得SAS系统可以使用SQL语句、可以和SAS的数据步进行替换使用。
注意,SQL过程步并不是用来代替SAS数据步,也不是一个客户化的报表工具,而是数据处理用到的查询工具。
SQL过程步的特征SQL过程步并不需要对每一个查询进行重复、每条语句都是单独处理、不需要print过程步就能打印出查询结果、也不用sort过程步进行排序、不需要run、要quit来结束SQL 过程步SQL过程步语句SELECT:查询数据表中的数据ALTER:增加、删除或修改数据表的列CREATE:创建一个数据表DELETE:删除数据表中的列DESCRIBE:列出数据表的属性DROP:删除数据表、视图或索引INSERT:对数据表插入数据RESET:没用过,不知道什么意思SELECT:选择列进行打印UPDATE:对已存在的数据集的列的值进行修改2 SQL基本查询功能SELECT语句基本语法介绍SELECT <DISTINCT> object-item <, ...object-item> FROM from-list<WHERE sql-expression><GROUP BY group-by-item <, ... group-by-item>> <HAVING sql-expression><ORDER BY order-by-item <, ... order-by-item>>;这里SELECT:指定被选择的列FROM:指定被查询的表名WHERE:子数据集的条件GROUP BY:将数据集通过group进行分类HAVING:根据GROUP BY的变量得到数据子集ORDER BY:对数据集进行排序SELECT语句的特征选择满足条件的数据、数据分组、对数据进行排序、对数据指定格式、一次最多查询32个表。
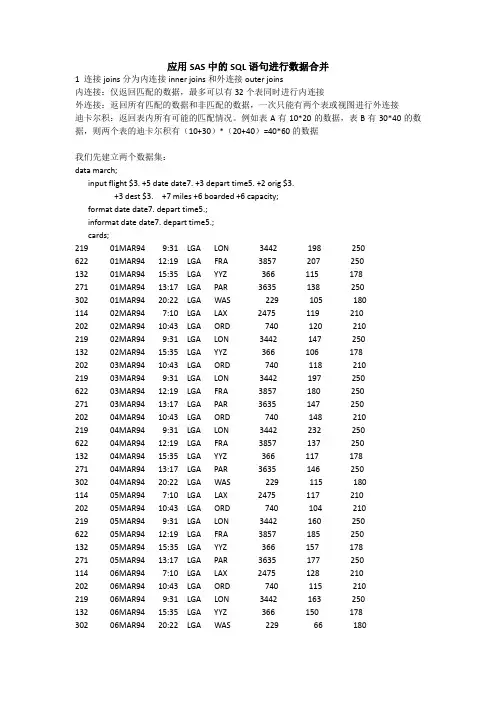
应用SAS中的SQL语句进行数据合并1 连接joins分为内连接inner joins和外连接outer joins内连接:仅返回匹配的数据,最多可以有32个表同时进行内连接外连接:返回所有匹配的数据和非匹配的数据,一次只能有两个表或视图进行外连接迪卡尔积:返回表内所有可能的匹配情况。
例如表A有10*20的数据,表B有30*40的数据,则两个表的迪卡尔积有(10+30)*(20+40)=40*60的数据我们先建立两个数据集:data march;input flight $3. +5 date date7. +3 depart time5. +2 orig $3.+3 dest $3. +7 miles +6 boarded +6 capacity;format date date7. depart time5.;informat date date7. depart time5.;cards;219 01MAR94 9:31 LGA LON 3442 198 250622 01MAR94 12:19 LGA FRA 3857 207 250132 01MAR94 15:35 LGA YYZ 366 115 178271 01MAR94 13:17 LGA PAR 3635 138 250302 01MAR94 20:22 LGA WAS 229 105 180114 02MAR94 7:10 LGA LAX 2475 119 210202 02MAR94 10:43 LGA ORD 740 120 210219 02MAR94 9:31 LGA LON 3442 147 250132 02MAR94 15:35 LGA YYZ 366 106 178202 03MAR94 10:43 LGA ORD 740 118 210219 03MAR94 9:31 LGA LON 3442 197 250622 03MAR94 12:19 LGA FRA 3857 180 250271 03MAR94 13:17 LGA PAR 3635 147 250202 04MAR94 10:43 LGA ORD 740 148 210219 04MAR94 9:31 LGA LON 3442 232 250622 04MAR94 12:19 LGA FRA 3857 137 250132 04MAR94 15:35 LGA YYZ 366 117 178271 04MAR94 13:17 LGA PAR 3635 146 250302 04MAR94 20:22 LGA WAS 229 115 180114 05MAR94 7:10 LGA LAX 2475 117 210202 05MAR94 10:43 LGA ORD 740 104 210219 05MAR94 9:31 LGA LON 3442 160 250622 05MAR94 12:19 LGA FRA 3857 185 250132 05MAR94 15:35 LGA YYZ 366 157 178271 05MAR94 13:17 LGA PAR 3635 177 250114 06MAR94 7:10 LGA LAX 2475 128 210202 06MAR94 10:43 LGA ORD 740 115 210219 06MAR94 9:31 LGA LON 3442 163 250132 06MAR94 15:35 LGA YYZ 366 150 178302 06MAR94 20:22 LGA WAS 229 66 180114 07MAR94 7:10 LGA LAX 2475 160 210132 07MAR94 15:35 LGA YYZ 366 164 178271 07MAR94 13:17 LGA PAR 3635 155 250302 07MAR94 20:22 LGA WAS 229 135 180;run;data delay;input flight $3. +5 date date7. +2 orig $3. +3 dest $3. +3delaycat $15. +2 destype $15. +8 delay;informat date date7.;format date date7.;cards;114 01MAR94 LGA LAX 1-10 Minutes Domestic 8 202 01MAR94 LGA ORD No Delay Domestic -5 622 01MAR94 LGA FRA No Delay International -5 132 01MAR94 LGA YYZ 11+ Minutes International 14 302 01MAR94 LGA WAS No Delay Domestic -2 114 02MAR94 LGA LAX No Delay Domestic 0 202 02MAR94 LGA ORD 1-10 Minutes Domestic 5 219 02MAR94 LGA LON 11+ Minutes International 18 622 02MAR94 LGA FRA No Delay International 0 132 02MAR94 LGA YYZ 1-10 Minutes International 5 271 02MAR94 LGA PAR 1-10 Minutes International 4 302 02MAR94 LGA WAS No Delay Domestic 0 114 03MAR94 LGA LAX No Delay Domestic -1 202 03MAR94 LGA ORD No Delay Domestic -1 219 03MAR94 LGA LON 1-10 Minutes International 4 622 03MAR94 LGA FRA No Delay International -2 132 03MAR94 LGA YYZ 1-10 Minutes International 6 271 03MAR94 LGA PAR 1-10 Minutes International 2 302 03MAR94 LGA WAS 1-10 Minutes Domestic 5 114 05MAR94 LGA LAX No Delay Domestic -2 202 06MAR94 LGA ORD No Delay Domestic -3 219 06MAR94 LGA LON 11+ Minutes International 27 132 06MAR94 LGA YYZ 1-10 Minutes International 7 302 06MAR94 LGA WAS 1-10 Minutes Domestic 1 622 07MAR94 LGA FRA 11+ Minutes International 21 132 07MAR94 LGA YYZ No Delay International -2 271 07MAR94 LGA PAR 1-10 Minutes International 4 302 07MAR94 LGA WAS No Delay Domestic 0 ;run;1.1 内连接proc sql;create table innerjoins asselect a.*,b.*from March a,Delay bwhere a.flight=b.flight and a.date=b.date;quit;1.2 外连接1.2.1 左连接left joinproc sql;create table leftjoins asselect *from March aleft join Delay bon a.flight=b.flight and a.date=b.date;quit;1.2.2 右连接right joinproc sql;create table rightjoins asselect *from March aright join Delay bon a.flight=b.flight and a.date=b.date;quit;1.2.3 全连接full joinproc sql;create table fulljoins asselect *from March afull join Delay bon a.flight=b.flight and a.date=b.date;quit;1.3 迪卡尔积proc sql;create table cartesian asselect a.*,b.*from March a,Delay b;quit;这里再大概说明一下内外连接的实现的基本原理:首先生成两个数据表的迪卡尔积,然后再根据where语句来选择符合条件的数据作为输出结果。

SAS中的SQL语句完全教程之三:SQL过程步的其它特征本系列全部内容主要以《SQL Processing with the SAS System (Course Notes)》为主进行讲解,本书是在网上下载下来的,但忘了是在哪个网上下的,故不能提供下载链接了,需要的话可以发邮件向我索取,我定期邮给大家,最后声明一下所有资料仅用于学习,不得用于商业目的,否则后果自负。
转载请注明出处:/s/blog_5d3b177c0100cn8v.html前面两部分内容都比较简单,本节内容才是本系列要介绍的重点。
不过这里装的内容都是点到即止,如果以后有时间,会进行更详细地讲解。
1 SQL过程步选项SQL过程步选项的作用主要是可以从更细节的方式去控制SQL过程步,并且可以在不执行过程的情况下对程序进行测试等。
下面介绍一下列出来的选项,这些选项大多经常用到,更多的选项可以参考SAS帮助。
INOBS:进行一个查询时,对每个源数据表进行N行限制,仅对这N行的数据进行查询。
OUTOBS:指定查询输出结果的观测数LOOPS:指定SQL过程步内循环的次数(此选项我用得比较少,谁明白的可以讲一下,多谢)NOPROMPT和PROMPT:修改上述三个选项的效果,从而让你选择是否继续或停止选项的效果。
PRINT和NOPRINT:控制是否打印选择的数据结果NONUMBER和NUMBER:控制是否在第一列打印观测值编号DOUBLE和NOBOUBLE:输入报表是否隔行显示NOFLOW和FLOW和FLOW=n和FLOW=n m :指定列宽,n指定列宽,m指定行宽???1.1 double选项proc sql double;select flight,datefrom MarchUNIONselect flight,datefrom Delay;quit;1.2 inobs选项注意:这里inobs选项只读取每个源表前10条数据进行后续的操作,如下面的日志所示。

as sql用法AS SQL用法AS SQL是结构化查询语言中的一个关键字,其作用是给查询结果集中的字段指定别名,以便于查询结果的清晰易懂。
以下是AS SQL的常用用法分析。
1. AS SQL基本语法AS SQL的语法格式如下:SELECT column_name AS alias_nameFROM table_name;其中,column_name代表需要查询的字段名,alias_name是字段别名,table_name代表查询的表名。
2. 实际应用AS SQL主要用来改变列标题或列名,或者将列或计算列(公式列)赋予别名,易于理解和使用。
示例1:更改列名SELECT prod_name AS product_name, prod_price AS price FROM products;以上示例中,“prod_name”和“prod_price”是查询的字段名,使用AS关键字分别指定了它们的别名为“product_name”和“price”。
示例2:计算列(公式列)赋予别名SELECT order_id, prod_name, prod_price,prod_price*quantity AS total_priceFROM order_items;以上示例中,prod_price*quantity作为计算列,使用AS关键字将其指定别名为“total_price”,以此展示订单的总价。
3. 有助于查询时的数据处理AS SQL也可以用于创建子查询并为其命名别名。
SELECTcust_name,REPLACE(address, '\n', '') AS full_addressFROMcustomers;以上示例中,使用AS关键字为查询到的该客户的“address”字段数据创建了别名“full_address”,并将其指定为该查询结果集的一部分,方便后续操作。
4. 总结AS SQL是结构化查询语言中一个十分重要的使用技巧,可让查询结果更清晰易懂,更适合数据处理与结果分析。


数据库SQL经典语句1.创建表:CREATE TABLE table_namecolumn1 datatype constraint,column2 datatype constraint,...2.插入数据INSERT INTO table_name (column1, column2, ...) VALUES (value1, value2, ...);3.查询数据SELECT column1, column2, ...FROM table_nameWHERE conditionORDER BY columnLIMIT number;4.更新数据UPDATE table_nameSET column1 = value1, column2 = value2, ...WHERE condition;5.删除数据DELETE FROM table_nameWHERE condition;6.创建索引CREATE INDEX index_nameON table_name (column1, column2, ...);7.删除索引DROP INDEX index_name ON table_name;8.修改表结构ALTER TABLE table_nameADD column datatype constraint;9.删除表DROP TABLE table_name;10.聚合函数(求和、平均值、最大值、最小值等) SELECT aggregate_function(column)FROM table_nameWHERE conditionGROUP BY column;11.连接表FROM table1INNER JOIN table2 ON condition;12.子查询SELECT column1, column2, ...FROM table1WHERE column IN (SELECT column FROM table2 WHERE condition);13.内连接SELECT column1, column2, ...FROM table1JOIN table2 ON condition;14.外连接SELECT column1, column2, ...FROM table1LEFT JOIN table2 ON condition;SELECT column1, column2, ...FROM table1RIGHT JOIN table2 ON condition;15.独立查询FROM table1WHERE EXISTS (SELECT column FROM table2 WHERE condition);16.分组查询SELECT column1, aggregate_function(column2)FROM table_nameWHERE conditionGROUP BY column1;17.排名查询SELECT column1, column2, ..., RANK( OVER (ORDER BY column DESC)FROM table_name;以上是一些数据库SQL经典语句,覆盖了创建、插入、查询、更新、删除、索引、表结构修改、聚合函数、连接表、子查询、内连接、外连接、独立查询、分组查询、排名查询等常见的操作语言。
神通数据库sql语句的使用全文共四篇示例,供读者参考第一篇示例:神通数据库是一个功能强大的关系型数据库管理系统,它提供了丰富的SQL语句来实现数据的查询、更新、删除等操作。
SQL (Structured Query Language)是用于与数据库通信的标准化语言,是数据库管理系统的核心。
在神通数据库中,SQL语句的使用是非常重要的,它可以帮助用户实现对数据库中数据的高效管理。
下面我们来详细介绍一些常用的SQL语句及其用法。
1. 查询数据:SELECT语句是SQL中最常用的语句之一,它用于从数据库中检索数据。
可以使用以下语句查询表中所有数据:```sqlSELECT * FROM table_name;```这条语句会返回指定表中的所有数据,其中"*"表示所有列。
如果想查询特定列的数据,可以将列名替换成具体列名。
2. 更新数据:UPDATE语句用于更新数据库中的数据。
可以使用以下语句更新表中指定条件的数据:```sqlUPDATE table_name SET column_name = new_value WHERE condition;```这条语句会将符合条件的数据的指定列更新为新的值。
5. 排序数据:ORDER BY语句用于对数据进行排序。
可以使用以下语句按照指定列对数据进行降序排序:这条语句会按照指定列的值,对数据进行降序排序。
8. 连接表:JOIN语句用于将多个表连接在一起。
可以使用以下语句连接两个表:9. 聚合数据:聚合函数如SUM、AVG、COUNT等用于对数据进行聚合计算。
可以使用以下语句计算表中某列的总和:SQL语句在神通数据库中是非常重要的,它提供了丰富的功能,可以帮助用户对数据库中的数据进行高效的管理。
通过熟练掌握SQL 语句的使用,用户可以更加方便地进行数据库操作,提高工作效率。
神通数据库提供了完善的SQL语句支持,用户可以根据自己的需求灵活地进行数据查询、更新、删除等操作,实现数据库管理的自动化和高效。
sas proc sql语言什么是SAS Proc SQL语言?SAS Proc SQL是一种基于结构化查询语言(SQL)的过程语言。
它是由SAS公司开发的一种数据库管理系统,与传统的SQL相比,SAS Proc SQL 具有更强大的功能和更高效的性能。
它可以用于处理和管理大量的数据,并进行数据分析和报告生成。
步骤1:了解SAS Proc SQL的基础知识在开始使用SAS Proc SQL之前,首先需要了解一些基本的概念和术语。
下面是一些重要的术语的解释:- 数据库:一个数据库是一个组织和存储数据的集合。
SAS Proc SQL可以使用多种不同类型的数据库,如SAS库、Oracle、DB2等。
- 表格:一个表格是数据库中数据的组织形式。
它由行和列组成,行表示记录,列表示字段。
- 查询:一个查询是从一个或多个表格中检索数据的请求。
查询语句由一个或多个SQL子句组成。
- SQL子句:SQL子句是SQL查询语句的组成部分。
常见的子句包括SELECT、FROM、WHERE、GROUP BY、HAVING和ORDER BY。
步骤2:连接到数据库在使用SAS Proc SQL之前,需要首先连接到数据库。
可以使用LIBNAME 语句来定义数据库的位置和访问权限。
下面是一个连接到SAS库的示例:sasLIBNAME mydb SASLIB 'C:\SASData';步骤3:查询数据查询是SAS Proc SQL的核心功能。
可以使用SELECT语句来检索需要的数据。
下面是一个简单的SELECT语句示例:sasPROC SQL;SELECT *FROM mydb.mytable;QUIT;上述代码将从mydb数据库的mytable表格中检索所有列的数据。
步骤4:过滤数据在查询中,可以使用WHERE子句来根据特定的条件过滤数据。
下面是一个使用WHERE子句的示例:sasPROC SQL;SELECT *FROM mydb.mytableWHERE age > 30;QUIT;上述代码将从mydb数据库的mytable表格中检索所有age字段大于30的记录。
CREATE PUBLICATION 语句说明此语句用于创建发布。
在MobiLink 中,发布标识UltraLite 或Adaptive Server Anywhere 远程数据库中的同步数据。
在SQL Remote 中,发布标识统一数据库和远程数据库中的复制数据。
语法CREATE PUBLICATION [ owner.]publication-name(TABLE article-description, ... )ow ner, publication-name : identifierarticle-description :table-name [ (column-name, ... ) ][ WHERE search-condition ][ SUBSCRIBE BY expression ]权限必须具有DBA 权限。
要求可以对语句中涉及的所有表进行独占访问。
示例下面的语句发布两个表中的所有列和行。
CREATE PUBLICATION pub_contact (TABLE contact,TABLE company)下面的语句仅发布一个表中的一些列。
CREATE PUBLICATION pub_customer (TABLE customer ( id, company_name, city ))下面的语句通过包括一个测试customer 表的状态列的WHERE 子句,仅发布活动客户行。
CREATE PUBLICATION pub_customer (TABLE customer ( id, company_name, city, state ) WHERE status = 'active')下面的语句通过提供预订者值,仅发布一些行。
此方法只能用于SQL Remote。
CREATE PUBLICATION pub_customer (TABLE customer ( id, company_name, city, state ) SUBSCRIBE BY state)创建SQL Remote 预订时,按如下所示使用预订者值。
sas中的sql(4)多表操作,内连接,外连接(leftrightfulljoin),In。
Understanding Joins1.Joins combine tables horizontally (side by side) by combining rows. The tables being joined are not required to have the same number of rows or columns. (被join的表不需要⾏或列与join表的相同)2.When any type of join is processed, PROC SQL starts by generating a Cartesian product, which contains all possible combinations of rows from all tables.In all types of joins, PROC SQL generates a Cartesian product first, and then eliminates rows that do not meet any subsetting criteria that you have specified.(在所有的join过程中都是先建⽴笛卡尔积,再去⼀个个按照你表明的条件去删除!表中重复的列在join中是不会⾃动合并的,需⼿动合并)。
3.连接最多包括32张表,不计算视图数量,只计算视图中的表的数量。
4.连接必须要类型相同,变量名不⼀定的相同2.最简单的join,不指定where选择⼦集,则会⽣成⼀个最基本的笛卡尔积(包括两个表所有可能的join)理解连接的过程!!!!!!For all tablebuilds a Cartesian product of rows from the indicated tablesevaluates each row in the Cartesian product, based on the join conditions specified inthe WHERE clause (along with any other subsetting conditions), and removes any rowsthat do not meet the specified conditionsif summary functions are specified, summarizes the applicable rowsreturns the rows that are to be displayed in output.有这个过程后,就能完全了解⼀对多,多对多,多对⼀连接后的结果了反正全部都是进⾏⼀次所有⾏的笛卡尔积的⽣成,然后再按条件进⾏筛选,⽽笛卡尔积的⽣成过程是主表对应附表⾏对⾏的⼀⼀对应(扫描)连接。
MSSQL语句大全和常用SQL语句命令的作用1、SELECT:返回表中的数据。
2、UPDATE:更新表中的数据。
3、INSERTINTO:向表中插入新的数据。
4、DELETE:从表中删除记录。
5、CREATEDATABASE:创建数据库。
6、ALTERDATABASE:修改数据库。
7、CREATETABLE:创建表。
8、ALTERTABLE:修改表结构。
9、DROPTABLE:删除表。
10、CREATEINDEX:创建索引。
11、DROPINDEX:删除索引。
12、RENAMETABLE:重命名表。
13、JOIN:连接多个表。
14、UNION:结合多个结果集。
15、BACKUPDATABASE:备份数据库。
16、RESTOREDATABASE:恢复数据库。
17、TRUNCATETABLE:清空数据表。
常用SQL语句命令的作用:1、SELECT:用于从数据库检索数据。
2、INSERTINTO:用于向表中插入新的记录。
3、UPDATE:用于更新表中的数据。
4、DELETE:用于从表中删除记录。
5、CREATETABLE:用于创建新的表。
6、DROPTABLE:用于删除表。
7、ALTERTABLE:用于修改表中的列或约束。
8、CREATEINDEX:用于创建索引。
9、DROPINDEX:用于删除索引。
10、RENAMETABLE:用于重命名表。
11、JOIN:用于查询连接多个表中的数据。
12、UNION:用于结合两个或多个SELECT语句的结果集。
13、BACKUPDATABASE:用于备份数据库。
14、RESTOREDATABASE:用于恢复数据库。
15、TRUNCATETABLE:用于清空表中的数据。
proc sql as语句
PROC SQL是SAS(统计分析系统)中用于执行SQL查询和操作的过程。
它允许用户在SAS环境中直接使用SQL语句来操作数据,而无需导出到其他数据库管理系统中。
PROC SQL语句通常以如下格式开始:
sas.
proc sql;
然后是SQL查询语句,例如:
sas.
select.
from dataset_name.
where condition;
在这个例子中,`select `表示选择所有列,`from
dataset_name`表示从特定数据集中进行查询,`where condition`
表示设定查询条件。
除了基本的SELECT语句之外,PROC SQL还支持其他SQL功能,比如JOIN操作、子查询、排序、聚合函数等。
用户可以在PROC
SQL中使用这些功能来完成复杂的数据操作和分析。
另外,PROC SQL还提供了一些特殊的选项和语法,如`quit;`
用于结束PROC SQL过程、`create table`用于创建新的数据表等。
总之,PROC SQL作为SAS中的SQL执行过程,为用户提供了在SAS环境中直接操作数据的便利,同时也支持多种SQL功能,使得
数据查询和处理更加灵活和高效。
S A S中的S Q L语句完全教程之一:S Q L简介与基本查询功能本系列全部内容主要以《SQLProcessingwiththeSASSystem(CourseNotes)》为主进行讲解,本书是在网上下载下来的,但忘了是在哪个网上下的,故不能提供下载链接了,需要的话可以发邮件向我索取,我定期邮给大家,最后声明一下所有资料仅用于学习,不得用于商业目的,否则后果自负。
1SQL过程步介绍过程步可以实现下列功能:查询SAS数据集、从SAS数据集中生成报表、以不同方式实现数据集合并、创建或删除SAS数据集、视图、索引等、更新已存在的数据集、使得SAS系统可以使用SQL 语句、可以和SAS的数据步进行替换使用。
注意,SQL过程步并不是用来代替SAS数据步,也不是一个客户化的报表工具,而是数据处理用到的查询工具。
过程步的特征SQL过程步并不需要对每一个查询进行重复、每条语句都是单独处理、不需要print 过程步就能打印出查询结果、也不用sort过程步进行排序、不需要run、要quit来结束SQL过程步过程步语句SELECT:查询数据表中的数据ALTER:增加、删除或修改数据表的列CREATE:创建一个数据表DELETE:删除数据表中的列DESCRIBE:列出数据表的属性DROP:删除数据表、视图或索引RESET:没用过,不知道什么意思SELECT:选择列进行打印UPDATE:对已存在的数据集的列的值进行修改2SQL基本查询功能语句基本语法介绍SELECT<DISTINCT>object-item<,...object-item>FROMfrom-list<WHEREsql-expression><GROUPBYgroup-by-item<,...group-by-item>><HAVINGsql-expression><ORDERBYorder-by-item<,...order-by-item>>;这里SELECT:指定被选择的列FROM:指定被查询的表名WHERE:子数据集的条件GROUPBY:将数据集通过group进行分类HAVING:根据GROUPBY的变量得到数据子集ORDERBY:对数据集进行排序语句的特征选择满足条件的数据、数据分组、对数据进行排序、对数据指定格式、一次最多查询32个表。
这里还要提到的就是,在SAS系统中,对于表名和变量名一般不超过32个字符,对于库名,文件引用名,格式等不能超过8个字符关键字Validate关键字只存在于select语句中、可以在不运行查询的情况下测试语句的语2validate3selectRegion,Product,Sales45whereRegion='Africa';NOTE:PROCSQL语句有有效语法。
6quit;此外,我们还可以用noexec选项也可以用来进行语法测试。
例:7procsqlnoexec;8selectRegion,Product,Sales910whereRegion='Africa';NOTE:由于NOEXEC选项,未执行语句。
11quit;这里提示未执行,未提示错误,说明该语句没有语法错误。
但是如果加入一个表里没有字段,这里就会出现错误,例:12procsqlnoexec;13selectRegion,Product,Sales,test1415whereRegion='Africa';ERROR:以下这些列在起作用的表中没有找到:test.16quit;查询列;quit;这里我们可以用feedback选项来查看到底我们选择了哪些列:17procsqlfeedback;18select*19;NOTE:Statementtransformsto:,,,,,,;20quit;这时,我们可以看到从表中选择了8个列消除重复值我们可以用distinct选项来消除重复值。
例如,我们要得到没有重复的所有地区的名称:procsql;selectdistinctRegionquit;子集查询比较运算符先列出where语句用到的比较运算符:LE<=小于或等于GE>=大于或等于NE^=不等于例如,我们要查询sales大于100000的所有数据:procsql;select*wheresales>100000;quit;:只要满足in里的任意一个值,表达式即为真,例如,我们要选择Region在Africa 和EasternEurope的所有数据:procsql;select*whereRegionin('Africa','EasternEurope');quit;逻辑运算符OR|或AND&是NOT^非例如,选择Region在Africa和EasternEurope,且销售额大于100000的所有数据:whereRegionin('Africa','EasternEurope')andsales>100000;quit;或:判断某列是否包含指定字符串例如,选择列Region包含’Afr’的数据:procsql;select*whereRegion'Afr';quit;或ISMISSING:判断某列数据是否为空例如,如果找出Region为空的数据:procsql;select*whereRegionismissing;quit;注意,这里我们还可以用以下表达式对where语句进行替换。
如果region为数值型变量,则可以用region=.,如果region为字符型变量,则可以用region=‘’进行替换。
:选择某一区间的数据例如选择sales大于100000,但小于200000的所有数据:wheresalesbetween100000and200000;quit;:判断是否能匹配某些字符例如,选择以region以A开头的所有地区procsql;select*whereRegionlike'A%';quit;这里注意有两类通配符,‘%’可以通配任意个任意字符,‘_’只能通配一个任意字符:类似匹配这里由于里没有符合要求的数据,所有就用书上的例子说明一下吧:Wherelastname=*‘smith’,出来的结果可能是:smith,smythe等表达式我们可以通过已有的列进行计算来得到新的列,这时用关键词as来给新的列赋列名,例如:procsql;selectRegion,Product,Sales,Stores,Sales/Storesassalesperstoresquit;量。
这里要注意的是,在创建表达式时,我们还可以在SQL里用到SAS中的除LAG 和DIFF之外的所有函数。
这里我们还可以用表达式计算出来的结果来进行子集查询,但一定要记住用calculated关键词。
例如我们要找出商店平均销售量大于5000的数据:方法一:procsql;selectRegion,Product,Sales,Stores,Sales/StoresassalesperstoreswhereSales/Stores>5000;quit;方法二:procsql;selectRegion,Product,Sales,Stores,Sales/Storesassalesperstoreswherecalculatedsalesperstores>5000;quit;查询结果展示数据排序默认的排序方式是升序,我们可以用DESC关键词来进行降序排列。
例如以sales降序排列数据:procsql;select*quit;这里提示一下,我们可以用任意多列进行排序,包括表达式结果(不用calculated),但最好是选择的列。
与FORMATLABEL:改变输出变量名的内容FORMAT:改变列的值的输出方式例如,改变salesperstores的label和formatprocsql;selectRegion,Product,Sales,Stores,Sales/Storesassalesperstoreslabel='salesperstores'format=;quit;处理SQL常用函数MEAN或AVG:均值COUNT或N或FREQ:非缺失值个数MAX:最大值MIN:最小值NMISS:缺失值个数STD:标准差SUM:求和VAR:方差procsql;selectRegion,Product,Sales,Stores, sum(Sales,Inventory,Returns)astotal ;quit;求均值avgprocsql;selectRegion,Product,Sales,Stores, avg(Sales)assalesavg;quit;分组求均值groupbyprocsql;selectRegion,avg(Sales)assalesavggroupbyRegion;quit;计数countprocsql;selectRegion,count(*)ascount groupbyRegion;数据子集procsql;selectRegion,count(*)ascountgroupbyRegionhavingcount(*)>50;quit;其它的就不多作介绍了,多用用就熟悉了子查询找出regions平均sales大于全部平均sales的regionprocsql;selectRegion,avg(Sales)assalesavggroupbyRegionhavingavg(Sales)>(selectavg(Sales);quit;关键词介绍>ANY(20,30,40)最终效果:>20<ANY(20,30,40)最终效果:<40=ANY(20,30,40)最终效果:=20or=30or=40例如,选择出region为unitedstate的sales小于任意region为africa的salesprocsql;selectRegion,SaleswhereRegion='UnitedStates'andSales<any='Africa');quit;这个例子没有多少意义,只是说明一下any的用法关键词介绍>ALL(20,30,40)最终效果:>40<ALL(20,30,40)最终效果:<20例如,选择出region为unitedstate的sales小于所有region为africa的sales 的数据procsql;selectRegion,SaleswhereRegion='UnitedStates'andSales<all='Africa');quit;与NOTEXISTSprocsql;select*whereexists(select*;quit;SAS中的SQL语句完全教程之二:数据合并与建表、建视图SAS中的SQL语句完全教程之二:数据合并与建表、建视图索引等本系列全部内容主要以《SQLProcessingwiththeSASSystem(CourseNotes)》为主进行讲解,本书是在网上下载下来的,但忘了是在哪个网上下的,故不能提供下载链接了,需要的话可以发邮件向我索取,我定期邮给大家,最后声明一下所有资料仅用于学习,不得用于商业目的,否则后果自负。