出租汽车保有量的自适应过滤法预测
- 格式:pdf
- 大小:224.19 KB
- 文档页数:3

自适应小波过滤自适应小波过滤是一种信号处理方法,它利用小波变换的多尺度分析特性,能够有效地去除信号中的噪声和干扰,从而提取出信号的有效信息。
本文将从原理、应用和优势等方面介绍自适应小波过滤。
一、原理自适应小波过滤是基于小波变换的信号处理方法,它将信号分解为不同尺度的小波系数,通过对小波系数的阈值处理和重构,实现信号的去噪和降噪。
具体步骤如下:1. 对信号进行小波变换,得到小波系数。
2. 对小波系数进行阈值处理,将小于阈值的系数置零。
3. 对处理后的小波系数进行逆小波变换,得到去噪后的信号。
二、应用自适应小波过滤在信号处理领域有着广泛的应用。
以下是一些常见的应用场景:1. 语音信号去噪:在语音通信和语音识别等应用中,常常会受到噪声的干扰,使用自适应小波过滤可以有效去除噪声,提高语音信号的质量和识别准确度。
2. 图像去噪:在数字图像处理中,自适应小波过滤可以用于去除图像中的噪声,提升图像的清晰度和细节信息。
3. 生物信号处理:在生物医学工程领域,如心电信号、脑电信号等的处理中,自适应小波过滤可以去除噪声和干扰,提取出有效的生物信号。
4. 振动信号分析:在机械故障检测和诊断中,自适应小波过滤可以用于提取故障信号,帮助判断设备的工作状态和故障类型。
三、优势相比于传统的滤波方法,自适应小波过滤具有以下优势:1. 多尺度分析:小波变换可以将信号分解成不同频率的小波系数,能够更好地捕捉信号的细节信息。
2. 自适应阈值:自适应小波过滤可以根据信号的特点自动调整阈值,避免了手动选择阈值的主观性。
3. 高效性:自适应小波过滤使用快速小波变换算法,计算速度较快,适用于实时处理和大规模数据处理。
4. 鲁棒性:自适应小波过滤对信号的幅度变化和噪声的影响较小,能够有效处理各种复杂信号。
自适应小波过滤是一种有效的信号处理方法,具有广泛的应用前景。
它可以在语音、图像、生物医学和机械故障等领域中去除噪声和干扰,提取出信号的有效信息。

城市出租汽车保有量影响因素分析出租汽车是城市客运的重要组成部分,是城市常规公共交通的重要补充。
出租汽车作为城市交通的一种方式,以其灵活、便利、安全等特性受到越来越多出行者的青睐,并由此促进了出租汽车行业的迅速发展,但同时也给城市客运交通带来了新的问题和挑战。
出租车客运行业在城市道路运输中占有十分重要的地位,是城市人口必不可少的运输方式。
标签:出租汽车保有量影响因素1 出租汽车运输需求影响因素分析影响出租汽车客运需求的因素包括城市性质、规模及自然条件、城镇居民收入水平等,影响供给的因素包括政府的行业管理政策、运输成本等,而出租汽车的运价、空驶率及城市社会经济发展水平则对出租汽车客运需求和供给均产生一定的影响。
1.1 社会经济发展水平城市经济的发展使得人们的收入增加,在吃穿住医疗这些基本的需要满足后必有旅游、探亲、访友等产生的交通需要。
城市经济发展水平的高低、速度的快慢直接影响着因公务出行的流动人口的多少,而这部分人的出行主要是出租汽车,间接影响到了出租汽车的需求。
交通行业的发展促进了城市经济的发展,城市经济的发展又对交通行业提出新的要求——方便、准时、快捷、舒适,而出租汽车恰恰满足了这些要求。
经济较为发达的城市中,居民出行选择出租汽车交通方式明显大幅度增加,由此可以说明:随着社会经济的发展、人民生活水平的提高以及现代化生活和工作节奏的加快,人们对出行方式质量的要求越来越高,在经济条件许可的情况下,出租汽车作为一种舒适、快捷的出行方式越来越受到人们日常出行的喜爱。
1.2 城市人口规模及居民收入人们普遍认为,技术特别是交通运输和通讯技术的革新,是城市生产和城市化发展的重要动力。
随着城市规模的扩大及城市空间的延伸,城市居民的出行距离呈线性增长。
然而,现有常规公交线网密度较低,需要进站停靠,不能很好地满足人们的出行需求,迫使一部分人转向出租汽车这种运输速度相对较快、直接提供“门到门”服务的运输方式。
城市人口数量越多,城市居民出行次数越多,对出租汽车的需求就会相应的提高。

基于系统动力学的大连市出租车保有量预测
左忠义;王克
【期刊名称】《大连交通大学学报》
【年(卷),期】2015(036)004
【摘要】采用系统动力学模型,找出影响出租车规模内外因素间的因果关系,包括经济、人口、机动车保有量、出行需求、政策等.在系统结构分析和因果反馈分析的
基础上建立了出租车系统,以大连市出租车相关统计数据进行仿真计算,分析了不同的发展政策对出租车系统的影响,提出相应的建议和对策.
【总页数】4页(P10-13)
【作者】左忠义;王克
【作者单位】大连交通大学交通运输工程学院,辽宁大连116028;大连交通大学交通运输工程学院,辽宁大连116028
【正文语种】中文
【中图分类】A
【相关文献】
1.基于GRNN的出租车保有量预测算法的应用 [J], 丁舒平;夏楷
2.基于系统动力学的武汉市私车保有量预测 [J], 胡斌祥;李娜;刘勇;郑丽
3.出租车保有量评价与预测 [J], 宋安;刘琦
4.基于随机森林的出租车保有量预测方法研究——以内蒙古通辽市主城区为例 [J], 赵楠; 姚宝珍
5.基于系统动力学模型的北京新能源汽车私人保有量预测 [J], 王瑞庭
因版权原因,仅展示原文概要,查看原文内容请购买。

基于神经网络BP算法的出租汽车保有量预测法
夏钰;陈学武
【期刊名称】《交通信息与安全》
【年(卷),期】2005(023)005
【摘要】介绍了出租车保有量神经网络预测模型的建立.以南京市的实际数据为检测依据,论证了该模型应用于城市出租汽车保有量预测的可行性,并对该市2005~2008年的出租汽车保有量进行了预测;该预测模型与传统模型进行预测对比的结果表明,由于神经网络在处理非线性系统方面的优越性,该预测模型在交通预测方面具有较高的计算精度.
【总页数】3页(P35-37)
【作者】夏钰;陈学武
【作者单位】东南大学,南京,210096;东南大学,南京,210096
【正文语种】中文
【中图分类】U491
【相关文献】
1.基于遗传BP算法的我国汽车保有量预测 [J], 程赐胜;苏玲利
2.基于遗传BP算法的我国汽车保有量预测 [J], 程赐胜;苏玲利
3.基于灰色关联和 BP 神经网络的汽车保有量预测 [J], 王栋
4.基于NARX神经网络的城市汽车保有量区间估计及灵敏度分析 [J], 黄中祥;任涛;张生
5.基于混合模型的城市出租汽车保有量建模 [J], 种鹏云;计斌;王璐;陈瑶
因版权原因,仅展示原文概要,查看原文内容请购买。
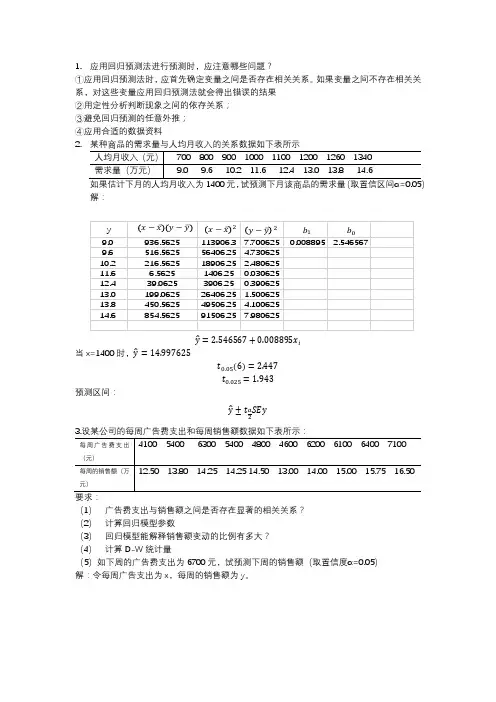
1. 应用回归预测法进行预测时,应注意哪些问题? ①应用回归预测法时,应首先确定变量之间是否存在相关关系。
如果变量之间不存在相关关系,对这些变量应用回归预测法就会得出错误的结果 ②用定性分析判断现象之间的依存关系; ③避免回归预测的任意外推; ④应用合适的数据资料
2.
解:
̂=2.546567+0.008895 i̇
当x=1400时, ̂=
14.997625
t . 5(6)=2.447
t . 5=1.943
预测区间:
̂±t a
SE
(1) 广告费支出与销售额之间是否存在显著的相关关系? (2) 计算回归模型参数
(3) 回归模型能解释销售额变动的比例有多大? (4) 计算D-W 统计量
(5)如下周的广告费支出为6700元,试预测下周的销售额(取置信度α=0.05) 解:令每周广告支出为x ,每周的销售额为y 。
每周的广告支出费与销售量的相关系数r=。
两者存在显著的相关关系。
(2)设回归模型为:
̂i=+i
=∑(x−x )(y−y)
=0.001072885,==8.303927492
∑(x−x )2
(3)每周的广告支出费占销售量的75%。


机场出租车运力需求预测技术研究机场出租车运力需求预测技术研究一、引言随着全球经济的快速发展,人民出行需求日益增长。
机场作为人们出行的重要交通枢纽,其承载的旅客流量也不断攀升。
出租车作为机场交通的重要组成部分之一,对于满足旅客的出行需求至关重要。
然而,出租车运力的合理配置一直是机场管理者面临的挑战,如何精确预测机场出租车运力需求成为了解决这一问题的关键。
二、机场出租车运力需求预测的重要性1. 促进机场交通的高效流动合理预测机场出租车运力需求,有助于提前安排出租车数量,确保人员流动的顺利进行。
过多或过少的出租车运力都会导致机场交通的拥堵或浪费,无法满足旅客的出行需求,影响机场运营效率。
2. 优化出租车的运营成本准确预测机场出租车运力需求,可以避免出租车资源的浪费。
合理调配出租车数量,可以减少司机空驶的情况,提高出租车的运营效率,同时减少对环境的负面影响。
三、机场出租车运力需求预测方法1. 基于历史数据的统计分析法该方法通过对历史的出租车运力需求数据进行统计分析,预测未来的需求量。
首先,收集机场历史出租车运力需求数据,并分析其与各种影响因素(如天气、航班量、旅游季节等)的关系。
然后,建立相关数学模型,进行数据拟合和预测。
最后,根据预测结果调整出租车数量。
2. 基于机器学习的预测方法机器学习技术在预测领域具有广泛应用,能够自动发现数据中的模式和规律,并预测未来的趋势。
在机场出租车运力需求预测中,可以利用机器学习算法对各类数据进行训练和预测,以提高预测的精确度。
四、机场出租车运力需求预测技术研究的挑战1. 数据获取的困难机场出租车运力需求预测需要大量的历史数据作为依据,然而,机场数据的获取相对困难,涉及到多个部门的数据共享和数据隐私问题。
解决这一问题,需要政府和机场管理者的支持和合作。
2. 预测模型的复杂性机场出租车运力需求受多种因素影响,预测模型必须考虑这些因素的相互关系。
因此,预测模型的建立相对复杂,需要综合运用数学、统计学和机器学习等多种技术,进行合理的模型选择与建立。

私家车保有量的增长的预测及调控摘要本文针对私家车保有量的增长的预测及调控问题的几个要求,建立了多个模型进行解答。
由于该问题总体上是一个确定性离散问题,无法通过分析问题对象的因果关系建立合乎机理规律的模型。
因此,我们从数据处理入手,通过对数据的合理处理找寻其内部关系。
对于问题一,由于题目中给出的影响因素过于繁多,对模型的建立造成干扰,同时又因为数据形式是一个时间序列数据,各因素间可能会产生自相关现象,影响模型预测的准确度,因此我们先对数据进行了相关性分析,排除了部分因素。
,因为私家车保有量与各剩余因素间的关系是非线性的,我们对私家车保有量取自然对数,使之变为线性关系,然后采用逐步回归的办法,继续排除部分因素,确定最终的主要影响因素。
接着对选取的主要影响因素进行数据拟合,并对相关数据建立多元线性回归模型,求得最终结果。
我们也可以主成份分析,要综合评价和分析各种可能对私人汽车保有量的影响因素,我们可首先要对评价的指标进行分析,将各指标进行无纲量化,然后根据已知数据计算各指标的权重,即各因素对考察量的影响程度;也可以用spss求出他们的相关性矩阵,来观察各因素对私家车保有量的影响。
对于预测未来私家车的保有量我们可以进行主成分分析,算出综合得分与私家车保有量的关系进行预测。
对于问题二,:考虑到环境因素(即汽车排污量)对私人汽车保有量的约束,且以后一段时间内相关因素变量都是未知的,可以考虑通过统计分析模拟,得到以后一段时间内其预测值,然后以此为以知条件,以排污量最小为目标函数,通过建立一个线性优化模型,来到到对未来一段时间该地区公交车及私人小汽车保有量的一个合理调控方案。
问题一的结果:影响该地区私家车保有量的主要因素有人均国内生产总值,全社会消费品零售总额,运营公交车辆数和居民储蓄款余额;2010年该地区的私家车保有量约为239.5767万辆。
问题二的结果:最终优化结果为调控后的公家车的数目为:8696辆,私家车的数目为:239.5399万辆。

厦门市机动车保有量的预测方法张东军;邓丽娟;马龙俊;姜伟【摘要】为了预测厦门市未来5年、15年的机动车保有量,以厦门市历年机动车保有量为研究对象,选取地区GDP、财政总收入、人均可支配收入、燃料零售价格指数、常住人口、公路通车里程等6个影响较大的数据指标.采用传统的非线性回归方法,主成份分析与Logistic模型相结合的方法,综合考虑两种预测方法及其结果,预测厦门市2020年、2030年的机动车保有量分别约为220万辆、530万辆.【期刊名称】《集美大学学报(自然科学版)》【年(卷),期】2016(021)001【总页数】7页(P42-48)【关键词】机动车保有量;非线性回归;因子分析;Logistic模型【作者】张东军;邓丽娟;马龙俊;姜伟【作者单位】集美大学航海学院,福建厦门361021;集美大学航海学院,福建厦门361021;集美大学航海学院,福建厦门361021;重庆交通大学交通运输学院,重庆400074【正文语种】中文【中图分类】U491.14随着社会经济的发展,人们的生活越来越离不开交通,交通需求的增长使得机动车的保有量日益增长,机动车在带给人民便利的同时,也带来了一系列的问题:交通拥挤,大气污染,交通事故等.机动车保有量的预测可为政府制定经济发展规划提供参考,对实施节能环保政策,提升居民生活品质有重要意义[1].机动车保有量的预测方法有回归分析法、趋势外推法、人工神经网络及Logictle分析法[2].前两种预测方法相对比较简单,人工神经网络作为一类高级机器学习算法,尚有许多不成熟的地方,在样本学习过程中可能存在学习不足或过度学习的不稳定性.目前,作为基本预测算法加以利用的是非线性回归方法,这种方法较简单,特别是在样本数量充足的情况下.近年,还有学者利用降维的思想,运用主成份分析(因子分析)与Logistic模型相结合的方法,去求解一些预测性问题[3].本文分别运用传统的非线性回归方法和主成份分析与Logistic模型结合的方法[4],对2020年、2030年厦门市的机动车保有量分别进行预测,并对两种方法所得出的预测值进行比较,从而确定厦门市未来5年、15年的机动车保有量情况.一个地区或城市的机动车保有量受到城市人口及城市社会经济发展水平及需求等因素的影响[5].本文结合实际情况,选取了6个影响指标,并统计了2001年—2014年厦门市机动车保有量及6个影响指标的变化情况,见表1.2.1 非线性回归模型构建与验证根据表1的统计数据,绘制机动车保有量与时间的曲线关系,如图1所示.由图1可以看出机动车保有量(纵坐标)随着年度(横坐标)逐年急剧增加,且曲线走势较光滑,具有二次曲线的特征.根据这一特点,假定历年机动车保有量(Y)与时间(X)为二次曲线关系,其回归方程可设为:Y=a+b1X+b2X2令:X=X1,X2=X2,则,上式为:Y=a+b1X1+b2X2式中的参数a,b1,b2待定.为计算参数,列表计算见表2.根据交通运输系统工程回归模型的相关计算方法[6],结合表2中数据,可以确定回归预测模型中的系数:.再将上述计算结果代入式:得,解上述方程组得:b1=0.185 004 313 186 813 2;b2=0.414 126 510 989 011. 根据公式(2),则可将其变形为:.根据表2,可计算为为为72.5,则:a=51.281 528 57-0.185 004 313 186 813 2×7.5-0.414 126 510 989011×72.5=19.869 824 174 395 603 5.将参数a,b1,b2的值带入公式(1),即可得到所求回归方程:Y=19.869 824 174 395 603 5+0.185 004 313 186 813 2X+0.414 126 510 989 011X22.2 非线性回归模型验证利用所求的回归方程,计算理论预测值,并与实际Y值进行比较,见表3.由表3可见,用所求的回归方程式计算的预测值与实际值非常接近,说明在其他条件不变的情况下,此方程是可信的.2.3 非线性回归法预测结果如果要求厦门市2020年、2030年的机动车保有量,则分别将X=20,X=30代入公式(4),得:Y(X=20)=19.869 824 174 395 603 5+0.185 004 313 186 813 2×20+0.414 126 510 989 011×202=19.869 824 174 395 603 5+3.700 086 263 736264+165.650 604 395 604 4≈189.220 5(万辆)Y(X=30)=19.869 824 174 395 603 5+0.185 004 313 186 813 2×30+0.414 126 510 989 011×302 =19.869 824 174 395 603 5+5.550 129 395 604396+372.713 859 890 109 9≈398.133 8(万辆)由此法计算可知,厦门市2020年、2030年的机动车保有量分别是189万辆、398万辆.3.1 主成份分析与Logistic模型的构建主成份分析是利用降维的思想,通过原始指标的线性组合,产生一系列互不相关的综合性指标,从中选出少数几个综合指标,并使它尽可能多地反映原始指标的信息,进而用这较少的几项综合性指标来刻画整体[7].此方法可以克服多个影响因素模拟预测时收敛速度较慢的缺点.首先,利用SPSS.22软件可得到因子分析共同度[8],见表4.表4中第二行是因子分析初始解下的变量共同度,表示对原6个变量如果采用主成份分析法提取所有6个特征根,那么原有的变量方差都可以被解释,变量的共同度均为1.第三行列出了按指定提取条件提取特征根时的共同度.可以看到,除公路通车里程外的变量的绝大部分信息可被因子解释,即变量信息丢失较少.对上文中确定的6个影响因素进行建模分析,然后利用标准化后的数据计算因素相关系数矩阵;求解相关系数矩阵R的特征值和特征矢量,确定主成份;选取m(m<6)个主成份,使得累积方差贡献率超过某一定值[9].计算得到相关系数矩阵的特征值、累加方差贡献率,结果见表5.第一个因子的特征根值为5.762,解释了原有6个变量总方差的96.027%.因此,可以只选取第一个因子作为主因子即可[10].其中,下文所指的“元件”是SPSS工具语言,而其概念与上文的“影响指标”相同.在SPSS软件中输入指令,则可得到因子碎石图,如图2所示.由图2可见,第一个特征值明显大于后面的特征值,说明提取第一个因子是合适的.通过载荷系数大小可以分析不同公共因子的主要指标的区别,表6显示第一个元件的相关指标载荷系数.由于第一个元件在6个指标上的载荷值都很大,说明它综合反映了该地区综合经济发展值,可以作为综合经济发展值看待.在原数据浏览窗口中新增了变量“FAC1_1”,表示不同年份的综合经济发展值.采用主成份分析法可以得出因子得分系数.其中,模型的整体拟合优度值R2为0.981,统计量F为612.040,概率P值小于显著性水平0.05,说明该模型有统计学意义,利用统计学知识,得到的统计方程:其中:x为“FAC1_1”(综合经济发展变量)值;y为机动车保有量;U为上限默认值1 000;b0,b1参数分别为0.021,0.557.3.2 Logistic模型的模拟与预测输入拟合步骤,可直接得出图3.由图3可见,实际数据的散点分布、线性模拟以及Logisitic方法的拟合情况.相比之下,Logistic回归方程的预测曲线更能诠释各年的机动车保有量数值,另一方面也进一步说明Logistic方程较线性回归拟合效果更好.选择曲线估计中的线性回归选项,得到综合经济发展变量“FAC1_1”时间序列的同时,可以直接导出综合经济发展变量与时间关系的预测方程:FAC1_1=-476.52+0.237 4×t,其中t代表年份.于是,可以利用公式(6),可分别求得t为2020和2030的“FAC1_1”值;FAC1_1(t=2020)=-476.52+0.2374×t=3.028;FAC1_1(t=2030)=-476.52+0.2374×t=5.402.分别将对应2020年、2030年的“FAC1_1”值代入公式(5),则:y(2020)=1/(1/1000+0.021×0.557x)=1/(1/1000+0.021×0.5573.028)=218.819 1(万辆);y(2030)=1/(1/1000+0.021×0.557x)=1/(1/1000+0.021×0.5575.402)=529.136 5(万辆).由此方法计算可知,厦门市2020年、2030年的机动车保有量分别是219万辆、529万辆.由于机动车保有量增加会带来诸多问题,为预测机动车保有量,本文采用了非线性回归模型、主成份分析与Logistic相结合的方法,利用2001年至2014年的相关数据分别进行了预测.非线性回归模型只考虑时间与厦门市机动车保有量的关系,得出了到2020年、2030年的机动车保有量将分别达到189.2205万辆、398.1338万辆.这种方法使用简单,需要原始数据较少,但考虑的影响因素有限,对多因素影响下的问题处理效果不佳.而采用主成份分析与Logistic模型相结合的方法是为了更充分的运用数据所表达的信息.先利用因子分析法,得出了因子累计贡献率、因子碎石图、因子载荷图,因子得分系数.由上述信息可以产生一个新的综合经济发展变量FAC1_1,它相当于将6个影响因素进行归一.然后,对这一变量进行曲线拟合,得出模型描述表与估计;再结合Logistic模型得出预测方程,对机动车保有量进行预测.该法所得到的厦门市2020年、2030年的机动车保有量分别是218.8191万辆、529.1365万辆.Logistic模型利用降维的方法,将众多的经济指标综合为少量的公共因子,能代表尽可能多的数据的意义,即用数据指标对复杂问题加以细化,使步骤化繁为简,模型预测精度比较高,较非线性模型而言,具有更高的可信度.随着厦门自由贸易试验区、东南航运中心、厦门高铁等项目的落成,笔者认为机动车的保有量将与时间脱离线性关系,所以仅从时间序列考虑是不恰当的.综合比较两种方法,主成份分析与Logistic模型相结合的方法更能贴合现实,因此预测厦门市2020年、2030年的机动车保有量分别为220万辆、530万辆左右.但由于样本的选取有限,不可控(变量)因素存在,也不能对预测值给予充分地验证.所以,预测的数据准确性只能有待未来的检验.希望在以后的预测中,可以考虑其他外部条件的特殊变化,如交通政策的改变、环境的变化等,希望文中预测的结果能为政府和城市道路交通规划,以及相关部门制定相应的规划政策时提供一定的参考.【相关文献】[1]徐亚丹.基于状态趋势预测方法的城市机动车保有量预测.科技通报,2012,28(9):11-14.[2]王立颖.机动车保有量预测方法综述.辽宁警专学报,2015(1):74-78.[3] 赖国毅.SPSS 17.0中文版常用功能与应用实例精讲.北京:电子工业出版社,2010.[4]蒋艳梅,赵文平.Logistic模型在我国私人汽车保有量预测中的应用研究.工业技术经济,2010(11):99-104.[5]许伶俐.我国汽车保有量的预测研究—基于主成份分析与协整回归模型分析.大连:东北财经大学,2011.[6]刘舒燕.交通运输系统工程.北京:人民交通出版社,2012.[7] 杨维忠.SPSS统计分析与行业应用案例详解.北京:清华大学出版社,2011.[8]杨光霞.SPSS数据统计与分析.北京:清华大学出版社,2014.[9]牟振华,李美玲,赵庆双.基于神经网络的山东省机动车保有量预测.山东建筑大学学报,2009,24(3):229-232.[10]王璐.SPSS统计分析基础、应用与实战精粹.北京:化学工业出版社,2012.。

第23卷第1期2021年1月Vol.23No.1Jan.2021交通科技与经济Technology1Economy in Areas of Communications引用著录:杜丹丰,贾金航•基于改进Compertz-PCA的汽车保有量联合预测交通科技与经济,2021,23(1):47-53.DOI:10.19348/ki.issnl008-5696.2021.01.008基于改进Compertz-PCA的汽车保有量联合预测杜丹丰,贾金航(东北林业大学交通学院,黑龙江哈尔滨150040)摘要:立足汽车行业,整理我国2005—2019年有关汽车保有量的相关面板数据,使用PCA方法分析,确定营运公交数、轨道交通公里数、公路里程数、城市化率、汽车报废量、社会消费品零售总额、汽车销售量、人均GDP、国民生产总值9项因素为汽车保有量影响因素。
利用PCA分析后得出的7项主要影响因素构建汽车保有量综合影响指标M,借鉴国际上通用的饱和指标,结合Compertz曲线模型对我国未来20年汽车保有量的发展趋势进行预测,结合实际情况测算出我国汽车保有量。
该模型由于引入综合影响指标M,所以在预测过程中考虑到更多的参数影响,提高预测精度。
结果显示:我国汽车保有量已经在沿着Compertz曲线的轨迹发展,但并没有达到饱和点,即将处于成熟期,2031年汽车保有量将达到3.5亿辆。
关键词:汽车保有量*Compertz模型*PCA算法*综合影响指标M;预测分析中图分类号:U491;F426文献标识码:A文章编号:1008-5696(2021)01-0047-07Joint prediction of car ownership based on improved Compertz-PCADU Danf e ng,JIA J inhang(College of Transportation,Northeast Forestry University,Harbinl50040,China)Abstract:Basedontheperspectiveoftheautomotiveindustry"thispaperhascompiledrelevantpaneldata on the number of vehicles in China in the past15years from2005to2019,and analyzed the PCA method <ode<ermine<henumberofoperaingbuses,mileageofrail<ransi,highway miles,urbanizaionra<e, <o<alre<ailsalesofconsumergoods,carsalevolume,volumeofinusevehicles,realpercapiaGDP,and grossnaionalproduc<,are<heinfluencingfac<orsofcarownership.And<heseven maininfluencing fac<orsob<ained af<er PCA analysis are used<o cons<ruc<a comprehensiveimpac<index M forcar ownership.In view of the internationally-used saturation indicators,a Compertz curve model is used to predict the development trend of China's car ownership in the next20years,calculating China's car ownership based on Chinas actual conditions.The model introduces a comprehensive influence index M, wh4chcantake4ntoaccountthe4nfluenceofmoreparameters4ntheforecastngprocessand4mprovethe accuracy of forecasting.The result shows that China's car ownership has been developing along the Comper<zcurve"bu<i hasno<reached<hesa<uraionpoin<"andiisabou<<obeinama<ureperiod.The car ownership wi l reach350mi l ion in2031.Keywords:carownership*Comper<z model*PCA algorihm*comprehensiveimpac<index M*forecas< analysis随着我国经济实力的迅猛提髙,到2019年底,我国民用汽车保有量已达到26150万辆,相较十年收稿日期:2020-0911基金项目:国家自然科学基金资助项目(51972050)第一作者简介:杜丹丰(1972—)男,教授,博士,研究方向:汽车节能减排.前增加了近5倍)随着汽车保有量的增加,出现了城市拥堵、配套设施发展不足、能源短缺、环境污染等众多问题口3)因此,预测我国未来汽车保有量对城市发展战略布局具有重要指导意义。
2008年第11期上(总第184期) 产业经济与管理 目适匝 预测 沈士军 .贾炜z (1.浙江省嘉兴市交通工程建设管理处,浙江嘉兴314001;2.陕西省城乡规划设计研究院.陕西西安714000) 摘要:为了提高出租汽车公司的效益.减少城市路面交通量.降低空气污染,通过运用自适应过滤法对出租汽车保有 量进行较为准确的预测。其结果可为出租汽车合理规模的确定与管理决策的制定提供科学依据。 关键词:交通量;自适应过滤法;合理规模;预测 中图分类号:U469.12 文献标识码:A 文章编号:1002—4786(2008)l1-0173—03
Self-adaptive Filter Method Prediction 0f Taxi Traffic Quantity
SHEN Shi-jun ,JIA Wei (1.Jiaxing City Transportation Engineering Construction Management Department of Zhejiang Province,Jiaxing 3 14001,China; 2.Shaanxi Provincial Town and Country Planning Design&Research Institute,Xi an 714000,China)
Abstract:In order to increase the benefit of taxi company.decrease the urban traffic and alleviate air pollution,the self-adaptive filter method is used to predict the taxi quantity exactly.The result provides scientific criterion for the determining and decision—making of logical taxi scale. Key words:traffic volume;self-adaptive filter method;reasonable scale;prediction
至于人员判读误差,由于现在使用的各种测速 路、车辆、车速表、驾驶人个体等不同原因引起的 仪、证眼雷达都已经采用了先进的数字显示和自动 车辆测速误差是必然存在的.有关人员除了要在以 记录方式.大大地减少了操作人员错误判读数据的 上提到的几个方面尽量减少误差以外,更重要的 可能性,因此,只要操作人员加强责任心,执法人 是,在实践中,应根据客观存在的原因,将测量结 员的判读误差是可以避免的。 果适当增加一定的余量,以抵消车辆行驶以及驾驶 3.4爱护仪器,定期检定 人和其他环境造成的综合误差。至于设置多大的余 测速仪作为机动车超速违法行为的取证工具, 量.各地可根据具体情况在进行分析试验后适当设 必须按规定定期参加计量检定.保证其合法性和准 定,同时,在有关法律文书中告知此测速结果的考 确性。在使用和保管时.操作人员应爱护测速仪, 量,以保证执法取证的准确性和科学性,以及执法 轻拿轻放,并放置于安全、清洁、无干扰的地方, 过程的人性化。 以保证仪器的正常使用 参考文献 机动车测速既是一种计量行为.也是一个采集 交通违法证据的过程 正确认识和分析机动车测速 过程中产生的误差.并采取相应的措施避免和减少 误差.科学地处理有关测量数据.才能保证执法的 公正性和准确性.有效地保障道路交通安全和秩 序。 综上所述。在进行机动车超速检测时,由于道 [1]GB 7258—2004,机动车运行安全技术条件[S]. [2]LDR一5,证眼雷达使用说明书【S】.
作者简介:卢玫(1963一),女,浙江嵊州人,1985年毕业于西 安公路交通大学(现名长安大学)汽车系,工学学士,现任浙 江警察学院交通管理教研室副教授。 收稿日期:2008—06—04 产业经济与管理 1 引言 随着经济的发展和人民生活水平的提高,使得 出租汽车这种能够充分根据乘客的需要提供灵活、 便捷、舒适运输服务的交通方式越来越受到出行者 的青睐 统计数据显示,自1990 2004年间,全国 出租汽车保有量由11.1xlOnveh增长到90.4xl04Veh, 年平均增长率达16%以上。于是,国内许多大中城 市都不同程度地出现了出租汽车供给量大于客运需 求量的现象。其直接表现就是出租车空驶率偏高, 这在一定程度上造成了道路资源浪费、交通拥堵、 空气污染加剧等不良后果。 出租汽车的规模是否合理不仅仅关系到出租汽 车公司的利益.更重要的是合理的出租汽车规模可 以更好地为市民服务,提高整个城市的交通运行效 率 出租汽车保有量的科学预测可为城市交通管理 部门制定合理的出租汽车行业发展政策提供科学依 据。 2 自适应过滤法的基本原理 自适应过滤法也是以时间序列的历史观测值进 行某种加权平均来预测的,所不同的是它需要寻找 一组“最佳”权数。自适应过滤预测法的基本思路 是:先用给定的权数来计算一个预测值,然后计算 预测误差.再根据预测误差调整权数以减小误差, 这样反复进行.直至找出一组“最佳”权数,使误差 减小到最低限度。 2.1 自适应过程预测的基本模型 设{yil为某一经济现象观测值构成的时间序列 { }:yl,y2,…,yt,则自适应过滤法的预测模型为: N yt+l ̄wly£+w2yt一1+..・+wNyt ̄+J= w,y削 (1) i=1 式中,zt) , ,…, 为权数,可通过迭代求出;
Ⅳ是权数个数.按经验确定。 自适应过滤法模型中的未知参数 称为“权 数”,是因为其形式是加权平均数,在实际迭代后, N 权数之和∑Wi就不一定保持为1。因此,这里的 =l “权数”并不是传统意义上的权数。自适应过滤法也 不是加权平均法 事实上,传统的移动平均法和指 数平滑法常出现滞后误差,就是由权数之和等于1 的约束造成的 2.2权数估计 在式(1)中, ,, :,…, 是未知权数,可利用 2008年第11期上(总第184期) 自适应迭代法求出。寻求这种最佳权数的方法是给 定一组初始权数,计算预测值,再与同期的实际值 作一比较并计算误差,然后利用误差调整权数力求 减小误差.直至预测误差降至最低程度,这时的权 数就是最佳权数。 权数调整公式为: 蚍㈣: +2ke州yt叶+1 (2) 式中,i=1,2,…,N;t=N,Ⅳ+l,…,n,n为序列数 据的个数; )为前一次权数或调整前权数; 为学 习常数:et+l为第抖1期的预测误差。 式(2)表示.调整后的一组权数应等于旧的权 数加上误差调整项。这个调整项包括预测、观察值 和学习常数3个因素。学习常数k的大小决定权数调 整的速度。 为保证误差不断减小.学习常数k的取值有一 定条件 美国加利福利亚斯坦福大学的学者威屈罗 (B.Wid0w)证明,按照上式调整权数的自适应过滤 迭代法收敛的充分条件是: k≤ r N max{∑ l 、 l 1≤ ≤n} 式中,n为数据个数; 为权数的个数。 另外.以上权数调整公式实际上是按照最优化 原理中最速下降法而建立的。设e2t+l为第t+l期误差 的平方.即: e2t+l=( +广夕 1) =( l一 1u —w2q 一1一・一 .Jv+1) 篆 :2 ・ 一2e~ly刊 则: )_ c )=wiq ̄'+2ke,+lyt_i+ 2.3 N、 值和初始权数的确定 在开始调整权数时.首先要确定权的个数j7\,和 学习常数k。一般说来,当时序观察值是季节变动 时,Ⅳ应取季节性长度值:如序列以一年为周期变 动,若数据为月的数据, ̄tJN=12;若数据为季度, 则取N=4。如果时序无明显周期变动,就可用相关 系数法确定.即用最高相关系数的滞后时期数为Ⅳ (Ⅳ值大则过滤能力强,但速度慢)。 对于k值一般可取为1/N.也可用不同的k值进 行试算 确定一个最佳的k值时,自适应过滤法相 当于移动平均法;而当 =Or(1一 ) 时,则相当于指 数平滑法。
0 lcJ盯 DI C小 1 址 2008年第11期上(总第184期) 自适应过滤的优点在于:预测模型简单:使用 全部历史数据寻求最佳权系数:可在计算上进行数 据处理:能克服传统的移动平均法和指数平滑法常 出现的滞后误差的缺陷,所以这种方法应用较广。 3实例分析 现以北京市出租汽车的一些资料为例.说明自 适应过滤法预测的全过程 北京市客运出租汽车统 计资料如表1所示
产业经济与管理 y4;然后按照步骤b)所示的方法计算 最后,按 照步骤c)计算W1 、W2 和 3 。 依次递进,直到进行到f=9时,Y t+l=夕。0mW + W Y8+ 3 y7,但由于没有t=10 ̄的观测值Y。。,因此,
et+lme 。=y 。一 。无法计算。这时,第一轮的调整就此 结束。 接着.将现有的新权数作为初始权数.重新开 始拄3的过程。如此反复下去,直到预测误差(指一 轮预测的总误差)没有多大改进时.就认为获得了 一组“最佳”权数.使其用来预测第10期的预测取 值,以此类推直至算到预测年份的客运需求量。本 例在调整过程中.可使误差降低到0.而权数达到 稳定不变,最后得到的最佳权数、出租汽车客运需 求量如表2所示 表2预测年份权数值及出租汽车客运需求量 \\ 项目 客运需求量 \\ I W2 W3 (10 人)
2006正 0.412 3 0.405 8 0.204 3 1E—l3 60193
2010正 0.4024 0.401 7 0.201 5 1E—l3 63 601
2020矩 0.41O7 O.4O64 0.205 5 lE一13 68 690
4结语 本文结合北京市出租汽车的一些资料.采用自 适应过滤法对出租汽车保有量进行了预测。该方法 的最佳“权数”不同于传统的权数计算方法。提高了 预测的准确性,且易于操作,实用性强。但本预测 模型完全是定量的,有一定的局限性.因此,城市 交管部1]在做计划、决策时,还可加入一定的定性 分析,从而使得预测结果能更加切合实际。由于笔 者水平有限.所提出的理论及方法主要是从实用的 角度出发,有待于在实践中检验和进一步完善。 参考文献 『11李明捷.基于供需平衡的出租汽车合理规模研究 『D1.西安:长安大学,2007. 【2]吴清烈,蒋尚华.预测与决策分析【M】.南京:东 南大学出版社.2004. f3]吴野.北京市出租汽车发展定位研究[D】.北京: 北京工业大学.2001.
作者简介:沈士军(1982一),男,安徽人,工学学士,毕业于 长安大学公路学院交通工程专业。 收稿日期:2008—03—11