统计预测和讲义决策自适应过滤法创新
- 格式:ppt
- 大小:1.37 MB
- 文档页数:32


一、名词解释第一章①预测:根据过去和现在估计预测未来。
②统计预测:属于预测方法研究的范畴,即如何利用科学的统计方法对事物的未来发展进行③定量推测,并计算概率置信区间。
第二章①定性预测:是指预测者依靠熟悉业务知识、具有丰富经验和综合分析能力的人员与专家,根据已掌握的历史资料和直观材料,运用个人的经验和分析判断能力,对事物的未来发展做出性质和程度上的判断,然后再通过一定形式综合各方面的意见,作为预测未来的主要依据。
②主观概率:是人们对根据几次经验结果所做的主观判断的主观判断的量度。
③客观概率:是根据事件发展的客观性统计出来的一种概率。
④相互影响法:是从分析各个事件之间由于相互影响而引起的变化,以及变化发生的概率,来研究各个事件在未来发生的可能性的一种预测方法。
第三章①残差:预测值与真实值的离差②可绝系数:衡量自变量与因变量关系密切程度的指标,表示自变量解释因变量变动的百分百比。
③相关系数:测定拟合优度的指标,相关系数平方等于可绝系数。
④非线性回归预测法:在社会现实经济活动中,很多现象之间的关系并不是线性的,这时就要选配适当类型的曲线,即非线性回归预测。
⑤拟合优度:衡量回归直线拟合效果的指标⑥自相关系数:是衡量同一变量不同时期的数据之间相关程度的指标。
⑦D-W:检验模型是否存在自相关的一个有效方法,其计算公式为:D—W=∑(ui-ui-1)^2/∑ui^2,其中ui=yi-^yi.根据经验D-W统计量在1.5~2.5之间表示没有显著自相关问题。
第四章①不规则变动因素:又称随机变动,它是受各种偶然因素影响所形成的不规则变动。
②趋势外推法:用时间t为自变量,时序数值y为因变量,建立合适的趋势模型,并赋予时间变量t所需要的值,从而得到相应时刻的时间序列未来值。
③图形识别法:通过绘制以时间t为横轴,时序数据为y轴的散点图形,并将其与各种函数曲线模型比较,选择最为合适的模型。
④差分法:利用差分把数据修匀,使非平稳的序列达到平稳序列。


第六章 自适应过滤法教学目标:通过本章学习,使学生能掌握自适应过滤法的基本原理及其应用过程。
教学内容:第一节 自适应过滤法的基本原理自适应过滤法与移动平均法、指数平滑法一样,也是一种时间序列预测技术,即它是建立在时间序列的原始数据基础之上,通过对历史观察值进行某种加权平均来预测的。
这种方法在原始数据的基本模式比较复杂时使用(具有长期趋势性变动或季节性变动的确定型时间序列),常常可以取得优于指数平滑法和移动平均法的预测结果。
一、自适应过滤法的基本原理设t x x ,,1 为某一时间序列,则有如下有关时间序列的一般预测模型:11211+--+∧+++=p t p t t t x x x x φφφ 6-1式中,1+∧t x 是1+t 期的预测值,1+-i t x 是第1+-i t 期的观察值,i φ(p i ,,1 =)是权数,p 是权数的个数。
第五章中所讨论的移动平均法和指数平滑法以及本章所讨论的自适应过滤法,实际上都可以用上述模式来概括,如:对于一次移动平均法:pi 1=φ (p i ,,1 =) 对于一次指数平滑法:1)1(--=i i ααφ不同的是,上述两种方法的权数都是固定的,而自适应过滤法中的权数i φ则是根据预测误差i e 的大小不断调整修改而获得的最佳权数。
自适应过滤法的基本原理就在于通过其反复迭代以调整加权系数的过程,“过滤”掉预测误差,选择出“最佳”加权系数用于预测。
整个计算过程从选取一组初始加权系数开始,然后计算得到预测值及预测误差(预测值与实际值之差),再根据一定公式调整加权系数以减少误差,经过多次反复迭代,直至选择出“最佳”加权系数。
由于整个过程与通信工程中过滤传输噪声的过程极为接近,故被称为“自适应过滤法”。
运用自适应过滤法调整权数的计算公式为:112+-++='i t t i i x ke φφ 6-2式中i φ'(p i ,,1 =)是调整后的权数;i φ(p i ,,1 =)是调整前的权数,k 为调整系数,也称学习常数;111+∧++-=t t t x x e 是第1+t 期的预测误差;1+-i t x 是第1+-i t 期的观测值。

统计预测与决策讲课稿统计预测与决策1、德尔菲法有哪些特点?又有哪些优点和缺点?答:(1)德尔菲法(Delphi method),是采用背对背的通信方式征询专家小组成员的预测意见,经过几轮征询,使专家小组的预测意见趋于集中,最后做出符合市场未来发展趋势的预测结论。
(2)德尔菲法本质上是一种反馈匿名函询法。
其大致流程是:在对所要预测的问题征得专家的意见之后,进行整理、归纳、统计,再匿名反馈给各专家,再次征求意见,再集中,再反馈,直至得到一致的意见。
其过程可简单表示如下:匿名征求专家意见-归纳、统计-匿名反馈-归纳、统计……若干轮后停止。
由此可见,德尔菲法是一种利用函询形式进行的集体匿名思想交流过程。
它有三个明显区别于其他专家预测方法的特点,即匿名性、多次反馈、小组的统计回答。
(一)匿名性因为采用这种方法时所有专家组成员不直接见面,只是通过函件交流,这样就可以消除权威的影响。
这是该方法的主要特征。
匿名是德尔菲法的极其重要的特点,从事预测的专家彼此互不知道其他有哪些人参加预测,他们是在完全匿名的情况下交流思想的。
后来改进的德尔菲法允许专家开会进行专题讨论。
(二)反馈性该方法需要经过3~4轮的信息反馈,在每次反馈中使调查组和专家组都可以进行深入研究,使得最终结果基本能够反映专家的基本想法和对信息的认识,所以结果较为客观、可信。
小组成员的交流是通过回答组织者的问题来实现的,一般要经过若干轮反馈才能完成预测。
(三)统计性最典型的小组预测结果是反映多数人的观点,少数派的观点至多概括地提及一下,但是这并没有表示出小组的不同意见的状况。
而统计回答却不是这样,它报告1个中位数和2个四分点,其中一半落在2个四分点之内,一半落在2个四分点之外。
这样,每种观点都包括在这样的统计中,避免了专家会议法只反映多数人观点的缺点。
[1] (3)优点:1、可以避免群体决策的一些可能缺点,声音最大或地位最高的人没有机会控制群体意志,因为每个人的观点都会被收集,另外,管理者可以保证在征集意见以便作出决策时,没有忽视重要观点。

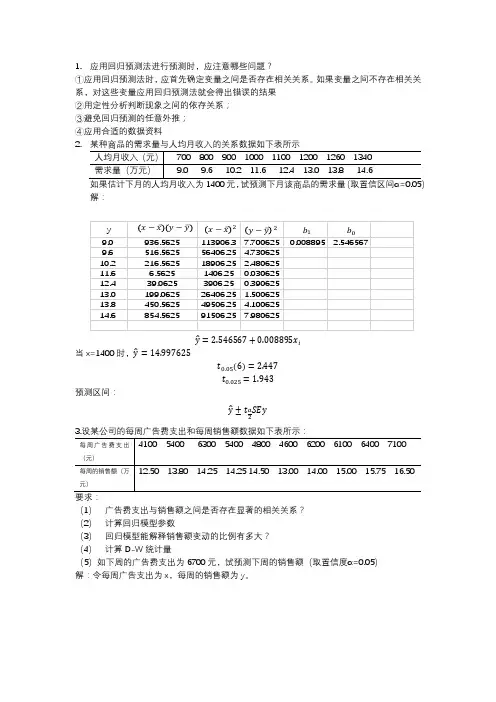
1. 应用回归预测法进行预测时,应注意哪些问题? ①应用回归预测法时,应首先确定变量之间是否存在相关关系。
如果变量之间不存在相关关系,对这些变量应用回归预测法就会得出错误的结果 ②用定性分析判断现象之间的依存关系; ③避免回归预测的任意外推; ④应用合适的数据资料
2.
解:
̂=2.546567+0.008895 i̇
当x=1400时, ̂=
14.997625
t . 5(6)=2.447
t . 5=1.943
预测区间:
̂±t a
SE
(1) 广告费支出与销售额之间是否存在显著的相关关系? (2) 计算回归模型参数
(3) 回归模型能解释销售额变动的比例有多大? (4) 计算D-W 统计量
(5)如下周的广告费支出为6700元,试预测下周的销售额(取置信度α=0.05) 解:令每周广告支出为x ,每周的销售额为y 。
每周的广告支出费与销售量的相关系数r=。
两者存在显著的相关关系。
(2)设回归模型为:
̂i=+i
=∑(x−x )(y−y)
=0.001072885,==8.303927492
∑(x−x )2
(3)每周的广告支出费占销售量的75%。


成绩:徐州师范大学数学科学学院实验报告课程:统计预测与决策班级:08数41姓名:朱虹学号:08214015教师:朱元泽实验一:多元线性回归模型实验目的与要求:熟练掌握建立多元线性回归模型的方法。
实验内容:问题:国际旅游外汇收入是国民经济发展的重要组成部分,影响一个国家或地区旅游收入的因素包括自然、文化、社会、经济、交通等多方面的因素,本例研究第三产业对旅游外汇收入的影响。
《中国统计年鉴》把第三产业划分为12个组成部分,分别为1x 农林牧渔服务业,2x 地质勘查水利管理业,3x 交通运输仓储和邮电通信业,4x 批发零售贸易和餐饮业,5x 金融保险业,6x 房地产业,7x 社会服务业,8x 卫生体育和社会福利业,9x 教育文化艺术和广播,10x 科学研究和综合艺术,11x 党政机关,12x 其他行业。
选取1998年我国31个省、市、自治区的数据(见实验一数据.xls )。
自变量单位为亿元人民币,以国际旅游外汇收入为因变量y (百万美元)。
试建立线性回归模型。
(要求用MATLAB 的stepwise 函数解决问题。
取05.0=进α,1.0=出α。
) 解:Matlab 程序如下: %回归分析 clear;clc;load('shuju1.mat','A'); [n,m]=size(A); y=A(:,m); X=A(:,1:m-1); ain=0.05; aout=0.1;stepwise(X,y,[],ain,aout)故由此得到的线性回归模型为31011ˆ177.497 4.975121.478611.2644yx x x =-++-实验二:时间序列分解法建模实验目的与要求:熟练掌握运用时间序列分解法建模。
实验内容:问题:当将时间序列分解成长期趋势、季节变动、周期变动和不规则变动四个因素后,可以认为时间序列{}t Y 是这四个因素的函数,即: ),,,(t t t t t I C S T f Y =时间序列分解方法有很多,相对而言,乘法模型(t t t t t I C S T Y ⋅⋅⋅=)应用得比较广泛。


试卷一一、单项选择题(共 10 小题,每题 1 分,共 10 分)1 统计预测方法中,以逻辑判断为主的方法属于( ) 。
A 回归预测法B 定量预测法C 定性预测法D 时间序列预测法2 下列哪一项不是统计决策的公理( ) 。
A 方案优劣可以比较B 效用等同性C 效用替换性D 效用递减性3根据经验 D-W 统计量在( )之间表示回归模型没有显著自相关问题。
A 1.0- 1.5B 1.5-2.5C 1.5-2.0D 2.5-3.54 当时间序列各期值的二阶差分相等或大致相等时 ,可配合( )进行预测。
A 线性模型B 抛物线模型C 指数模型D 修正指数模型5 ( )是指国民经济活动的绝对水平出现上升和下降的交替。
A 经济周期B 景气循环C 古典经济周期D 现代经济周期6 灰色预测是对含有( )的系统进行预测的方法。
A 完全充分信息B 完全未知信息C 不确定因素D 不可知因素7 状态空间模型的假设条件是动态系统符合( ) 。
A 平稳特性B 随机特性C 马尔可夫特性D 离散性8 不确定性决策中“乐观决策准则”以( )作为选择最优方案的标准。
A 最大损失B 最大收益C 后悔值D α系数9 贝叶斯定理实质上是对( )的陈述。
A 联合概率B 边际概率C 条件概率D 后验概率10 景气预警系统中绿色信号代表( ) 。
A 经济过热B 经济稳定C 经济萧条D 经济波动过大二、多项选择题(共 5 小题,每题 3 分,共 15 分)1 构成统计预测的基本要素有( ) 。
A 经济理论B 预测主体C 数学模型D 实际资料2 统计预测中应遵循的原则是( ) 。
A 经济原则B 连贯原则C 可行原则D 类推原则3 按预测方法的性质,大致可分为( )预测方法。
A 定性预测B 情景预测C 时间序列预测D 回归预测4 一次指数平滑的初始值可以采用以下( )方法确定。
A 最近一期值B 第一期实际值C 最近几期的均值D 最初几期的均值5 常用的景气指标的分类方法有( ) 。