32位微处理器
- 格式:docx
- 大小:23.45 KB
- 文档页数:2

32 位处理器之争,Cortus 用安全核叫板ARM
ARM 一直在微处理器和微控制器IP 核市场占着主导地位。
与此同时,32 位微处理器供应商Cortus 却在深度嵌入式市场与ARM Cortex M0 抗衡了9 年,此外Cortus 也坚信极简主义的方式是在连接器件市场立足的关键。
日前,Cortus 增添了基于第二代(v2)指令系统的产品。
而该公司表示代码密度的提升可以满足目前全新的连接器件需求。
为进一步降低SoC 设计的功耗,Cortus 已经研发出一套新指令集,可以减少指令存储器系统的尺寸。
第二代指令集的首个产品APS23 应用于低功耗系统,比如低功耗蓝牙(BLE)一类的时钟频率无苛刻要求的系统。
APS23 子系统
第二代指令集在第一代上提升了16%的代码密度,大大的减少了指
令寄存器的空间。




1前言传统的低功耗MCU设计都是以8位MCU为主,因为8位内核阈门相对较少,运行或泄露电流低,售价也相对低廉。
但是,随着物联网、5G、云计算、大数据以及智慧城市、智慧家庭、智慧园区的应用,8位内处理效率已经不能满足市场需求。
近年来,鉴于以下缘由,32位低功耗MCU得以兴起。
①手持式消费性电子产品与无线功能的需求越来越高、设计越来越复杂,要提高性能的同时又要兼顾低功耗,需要有一高性能低功耗的主控MCU来作为平台。
②工业上的智能化也在展开,如远程监控、数字化、网络化等。
简单说来,就是人物之连结(云端应用)、物物之连结(物联网)需求越来越多,导致产品功能越来越复杂,运算量越来越高,③制程微缩技术的进步,嵌入式闪存制程普及化及降价,主要成本来自内存大小及模拟外围和I/O管脚数量,CPU内核的成本差异已大幅缩短,更促进了高性价比32位低功耗MCU的快速发展。
应该看到,随着集成电路制造技术的不断进步,单个芯片上集成的晶体管越来越多。
这使得大规模集成电路(VLSI)的功耗成为芯片设计的关键问题,尤其是,当工艺发展到深亚微米时,功耗对电路的影响使它成为集成电路设计中必须考虑的因素。
低功耗设计对提高电路可靠性和降低成本有着非常积极的作用。
就数字CMOS电路功耗主要由动态开关功耗、漏电功耗和短路功耗三部分组成,其中动态开关功耗占据了总功耗的绝大部分,因此降低功耗主要通过降低动态开关功耗实现,而降低动态开关功耗又可以通过减小翻转率、减小负载电容和降低芯片供电电压等手段实现。
今天,不管是通用MCU,还是低功耗MCU对于国产MCU产业面临的现实困境,想要在通用MCU 领域和国外企业直面竞争,是非常不现实的。
我们更倾向于在细分领域形成差异化优势,根据客户实际的需求对产品的功能、外围电路、模拟特性等进行定制化设计,以此打开市场。
与此同时,航顺芯片也在加快32位MCU产品系列的扩充,其量产的通用8位MCU(HK32S003XX 家族),32位MCU-M3家族(HK32F103)和M0家族(HK32F030/031)已有近百个单品型号,功耗更低,稳定性可以通过车规级测试标准。

x86是多少位x86,亦称为x86架构或x86体系结构,是一种32位和64位微处理器架构。
它是Intel于1978年首次引入的一种基于CISC (Complex Instruction Set Computer,复杂指令集计算机)的处理器架构。
自那时以来,x86架构已经成为市场上最为广泛使用的计算机架构之一。
x86架构的第一个处理器是Intel 8086,它是一款16位处理器。
然而,由于对内存限制的需求以及市场的发展,Intel随后推出了Intel 80286(i286)处理器,后者是一款32位处理器,向后兼容8086指令集。
这是x86架构的第一个32位处理器,为今后的发展奠定了基础。
随着计算机技术的进步和市场需求的推动,x86架构建立了其领导地位。
Intel在后续的产品中引入了更先进的处理器,如80386(i386),80486(i486)和Pentium系列,将x86架构推向新的高度。
这些处理器通过增加处理器位宽度并改进指令集来提高计算能力和效率。
虽然32位x86架构在市场上非常成功,但随着技术的进步,对更高计算能力和内存访问的需求也越来越迫切。
为了应对这一需求,x86架构进一步演变为64位架构。
Intel在2003年推出了第一款x86 64位处理器,称为Intel Itanium。
紧接着,Intel又发布了x86架构的64位版本,称为Intel EM64T。
AMD还引入了自己的64位架构,称为AMD64或x86-64。
这些64位处理器不仅可以兼容运行32位操作系统和应用程序,还可以运行64位操作系统和应用程序,提供更高的内存寻址能力。
x86架构的位数指的是处理器的寻址能力和寄存器的位宽度。
在32位x86架构中,处理器能够寻址32位内存地址,这意味着它最多可以寻址2^32(大约4GB)的内存。
而在64位x86架构中,处理器能够寻址64位内存地址,最多可以寻址2^64(约16EB)的内存,实现了更高的内存寻址能力。




Pentium系列微处理器字长为多少?与数据线有关系吗?解答:从80386到Pentium 4的处理器字长都是32位。
与数据线有一定关系。
一般来说字长与数据线的个数相等,例如8086/80286/80386/80486。
但也存在不相等的情况,都有原因。
例如8088的字长为16位,但为了与当时8位的主流外设配合,所以其数据线也设计为8位。
再如,Pentium以后的Intel 80x86微处理器的数据线设计为64位,为的是与存储器交换数据具有更快的速度;但是其内部寄存器等结构是32位的,所以Pentium 仍然是字长为32位的微处理器。
机器的“字长”和地址线无关,和数据线紧密相关。
386到pentium 4的字长都是32位,都是“32位机”而从pentium 2开始,地址线变成了36根,可以直接寻址64GB的空间。
其他非IA - 32架构的机器我没有了解,猜想在intel 的64 bits处理器itantium上,int == 64 bitsCPU的相关技术参数1.主频主频也叫时钟频率,单位是MHz,用来表示CPU的运算速度。
CPU的主频=外频×倍频系数。
很多人以为认为CPU的主频指的是CPU运行的速度,实际上这个认识是很片面的。
CPU的主频表示在CPU内数字脉冲信号震荡的速度,与CPU 实际的运算能力是没有直接关系的。
当然,主频和实际的运算速度是有关的,但是目前还没有一个确定的公式能够实现两者之间的数值关系,而且CPU的运算速度还要看CPU的流水线的各方面的性能指标。
由于主频并不直接代表运算速度,所以在一定情况下,很可能会出现主频较高的CPU实际运算速度较低的现象。
因此主频仅仅是CPU性能表现的一个方面,而不代表CPU的整体性能。
2.外频外频是CPU的基准频率,单位也是MHz。
外频是CPU与主板之间同步运行的速度,而且目前的绝大部分电脑系统中外频也是内存与主板之间的同步运行的速度,在这种方式下,可以理解为CPU的外频直接与内存相连通,实现两者间的同步运行状态。
Cortex-M4F是ARM公司推出的一款适用于嵌入式控制应用的32位微控制器处理器核,它采用了先进的Thumb-2指令集,并加入了浮点运算单元。
该处理器核在嵌入式系统中具有广泛的应用,能够满足对性能和低功耗有较高要求的场景。
在实际应用中,我们经常需要对自然对数进行计算,这就需要对Cortex-M4F处理器核的浮点运算能力有一定的了解。
1. Cortex-M4F浮点运算能力在Cortex-M4F处理器核中,浮点运算单元(FPU)采用了ARM 的单精度浮点运算指令集,能够支持单精度浮点数的加、减、乘、除等基本运算,同时还支持取余数、开平方、求平方根等其他运算。
这为我们在Cortex-M4F处理器核上进行自然对数的计算提供了便利。
2. 自然对数的计算方法自然对数是数学中常见的一个概念,通常表示为e的x次方,其中e约等于2.xxx。
在实际应用中,我们经常需要对自然对数进行计算,如在概率统计、信号处理、控制系统等领域。
对于Cortex-M4F处理器核来说,可以通过数值计算的方式来近似求解自然对数,常用的方法包括泰勒级数展开、牛顿迭代法等。
3. 泰勒级数展开法泰勒级数展开法是一种常见的数值计算方法,可以利用多项式来近似表示函数。
对于自然对数函数ln(x)而言,其泰勒级数展开形式如下:ln(x) = (x-1) - (x-1)^2/2 + (x-1)^3/3 - (x-1)^4/4 + ...我们可以通过截取泰勒级数的前几项来近似计算ln(x),当x的取值范围在(0,2]时,泰勒级数展开法的近似结果较为精确。
4. 牛顿迭代法牛顿迭代法是一种常用的数值计算方法,可以通过迭代的方式逐渐逼近函数的零点,从而求解函数的根。
对于自然对数函数ln(x)而言,可以通过牛顿迭代法来逼近其零点,进而得到ln(x)的近似值。
牛顿迭代法的迭代公式如下:Xn+1 = Xn - f(Xn)/f'(Xn)其中Xn代表第n次迭代的近似解,f(Xn)代表函数在Xn处的取值,f'(Xn)代表函数在Xn处的导数值。
stm32程序架构STM32是一种由意法半导体(STMicroelectronics)开发的32位微控制器系列,广泛应用于各种嵌入式系统和物联网设备。
本文将介绍STM32的程序架构,包括处理器核心、存储器、外设以及软件开发工具等方面的内容。
STM32微控制器的处理器核心采用了ARM Cortex-M系列架构,这是一种低功耗、高性能的处理器架构。
常见的Cortex-M系列核心包括Cortex-M0、Cortex-M3和Cortex-M4等。
这些处理器核心具有高效的指令集和丰富的外设接口,能够满足各种应用的需求。
STM32微控制器内置了不同类型和容量的存储器,包括闪存(Flash)、随机存取存储器(RAM)和EEPROM等。
闪存用于存储程序代码和常量数据,RAM用于存储变量和堆栈等临时数据,而EEPROM用于存储持久化数据。
存储器的容量和类型可以根据具体的应用需求进行选择。
STM32微控制器还集成了丰富的外设,以满足不同应用的需求。
常见的外设包括通用输入输出口(GPIO)、通用串行总线(USART)、通用同步异步收发器(UART)、SPI接口、I2C接口、定时器、模拟数字转换器(ADC)、数字模拟转换器(DAC)、以太网控制器等。
这些外设提供了丰富的接口和功能,可用于连接传感器、执行通信、控制执行器等。
针对STM32微控制器的软件开发,意法半导体提供了一套完整的工具链,包括集成开发环境(IDE)、编译器、调试器和软件库等。
其中,常用的IDE是基于Eclipse平台开发的STM32CubeIDE,它提供了丰富的功能和工具,方便开发者进行代码编写、调试和固件下载等操作。
编译器方面,常用的是基于GNU工具链的arm-none-eabi-gcc,它支持C和C++语言的编译。
此外,意法半导体还提供了一系列的软件库,如标准外设库(StdPeriph Library)和HAL库(Hardware Abstraction Layer Library),用于简化外设的配置和驱动编程。
计算机专业基础综合(中央处理器)-试卷1(总分62,考试时间90分钟)1. 单项选择题单项选择题1-40小题。
下列每题给出的四个选项中,只有一个选项是最符合题目要求的。
1. 通常所说的32位微处理器是指( )。
A. 地址总线的宽度为32位B. 处理的数据长度只能为32位C. CPU字长为32位D. 通用寄存器数目为32个2. 在微程序控制方式中,机器指令、微程序和微指令的关系是( )。
A. 每一条机器指令由一条微指令来解释执行B. 每一条机器指令由一段(或一个)微程序来解释执行C. 一段机器指令组成的工作程序可由一条微指令来解释执行D. 一条微指令由若干条机器指令组成3. 一个单周期处理器,各主要功能单元的操作时间为:指令存储器和数据存储器为0.3 ns,ALU为0.2ns,寄存器文件为0.1ns,则该CPU的时钟周期最少应该是( )。
A. 0.4nsB. 0.3nsC. 0.2nsD. 1ns4. 微程序存放在( )。
A. 主存中B. 堆栈中C. 只读存储器中D. 磁盘中5. 下列关于并行微程序控制器的说法中,正确的是( )。
A. 现行微指令的执行与取下一条微指令的操作并行B. 现行微指令的执行与取下一条微指令的操作串行C. 两条或更多微指令的执行在时间上并行D. 两条或更多微指令的取微指令操作在时间上并行6. 下列说法中正确的是( )。
A. 取指周期一定等于机器周期B. 指令字长等于机器字长的前提下,取指周期等于机器周期C. 指令字长等于存储字长的前提下,取指周期等于机器周期D. 取指周期与机器周期没有必然联系7. 在微程序控制方式中,以下说法中正确的是( )。
Ⅰ.采用微程序控制器的处理器称为微处理器Ⅱ.每一条机器指令由一个微程序来解释执行Ⅲ.在微指令的编码中,执行效率最低的是直接编码方式Ⅳ.水平型微指令能充分利用数据通路的并行结构A. Ⅰ和ⅡB. Ⅱ和ⅣC. Ⅰ和ⅢD. Ⅱ、Ⅲ和Ⅳ8. 下列几项中,流水线相关包括( )。
32位微处理器(1)
按Intel的定义,0~32个中断是CPU出错用的,称为异常。
32~255是给系统自己定义使用的。
在DOS中,系统使用被分成了两个部分,一个部分是硬件的IRQ,IRQ就是级连的中断控制器。
其他的则被分配给软件使用。
现在64位的CPU中,中断扩充成16位,则理论上可有64KB个中断。
80286芯片能在实模式和保护模式两种方式下工作。
在实模式下,80286与8086芯片一样,与操作系统DOS和绝大部分硬件系统兼容;在保护模式下,每个同时运行的程序都在分开的空间内独自运行。
286的保护模式还是有很多不兼容缺陷,到了386才算有真正的改革,操作系统才真正进一步发挥作用,从16位真正跨入32位程序。
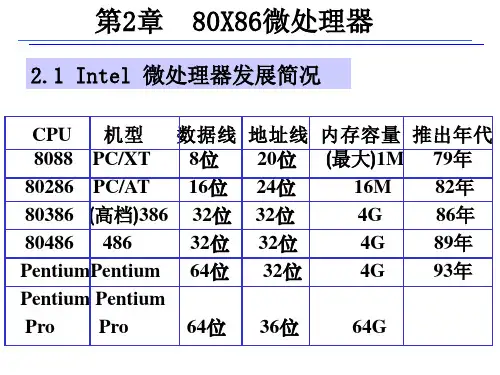
2.3 32位微处理器
1985年,真正的32位微处理器80386DX诞生,为32位软件的开发提供了广阔的舞台。
1989年,Intel推出80486芯片,把387的浮点运算器合于486之中,并且采用流水线技术,令CPU每个周期可以执行一条指令,速度上突破100 MHz,超过了RISC的CPU。
1992年,Intel 发布奔腾芯片,采用多流水线技术及并行执行的能力,从此,CPU可以每个周期执行多个指令。
1995年的奔腾Pro能力上再进了一步,产生动态执行技术,使CPU可以乱序执行。
我们知道,从80386开始到现在的P4的CPU,它们的体系结构一直都是相同的,增加的只是内部的实现方式,所以,这些体系结构对大多数程序员来说就是透明的。
2.3.1 寄存器组成
80386寄存器的宽度大多是32位,可分为如下几组:通用寄存器、段寄存器、指令指针及标志寄存器、系统地址寄存器、调试寄存器、控制寄存器和测试寄存器。
应用程序主要使用前面三组寄存器,只有系统才会使用其他寄存器。
这些寄存器是8080、8086、80286寄存器的超集,所以,80386包含了先前处理器的全部16位寄存器。
80386的部分寄存器如图2.6所示。
图2.6 80386的部分寄存器
1. 通用寄存器
80386有8个通用寄存器,这8个寄存器分别定名为EAX、EBX、ECX、EDX、ESP、EBP、ESI 和EDI。
它们都由原先的16位寄存器扩展而成。
这些通用寄存器的低16位还是可以作为16位寄存器存取,并不受影响。
以前的AX、BX、CX、DX这4个寄存器还可以单独使用这16位中的高8位和低8位,即分别是AH、AL、BH、BL、CH、CL、DH和DL。
在80386中,8个32位通用寄存器都可以作为指针寄存器使用,所以32位通用寄存器更加通用。
2. 段寄存器
80386中有6个16位的段寄存器,分别命名为CS、SS、DS、ES、FS和GS。
其中,FS和GS 是80386新增加的寄存器。
在实模式下,内存的逻辑地址仍是“段值:偏移”形式,而在保护模式下,情况就复杂很多了。
它总体上是通过可见部分寄存器指向不可见的内存部分。
有关内容将在2.3.2节中介绍。
所有这些寄存器的可见的部分和不可见的部分在IA64中可以直接处理IA 32位的一切,就像80386中的VM86一样,即如在Windows上执行DOS窗一样。
3. 指令指针和标志寄存器
80386的指令指针寄存器扩展到了32位,记为EIP。
EIP的低16位是16位的指令指针IP,与以前的X86系统相同。
由于在实模式下,段的最大范围是64KB,所以EIP的高16位必须全是0,仍相当于16位的IP作用。
80386中,标志寄存器也扩展到了32位,记为EFLAG,如图2.7所示。
图2.7 80386的标志寄存器
其中,增加了IO特权标志IOPL(I/O Privilege Level)、嵌套任务标志NT(Nest Task)、重启动标志RF(Reset Flag)、虚拟8086方式标志VM(Virtual 8086 Mode)。
AMD采用了X86架构并将之扩展至64位,开创了X86-64架构。
(1)处理器在32位的X86位纯模式下工作,可以
运行现在的32位操作系统和应用软件。
(2)处理器在“长模式”下工作,运行64位的操作系统,既能执行32位应用程序,又能执行64位应用程序。
(3)只有在“64位模式”下,才能进行64位寻址和访问64位寄存器。
(4)扩展是简单并且兼容的,所以处理器可以以最高的速度和性能支持X86和X86-64。
32位兼容性的情况下迁移至64位的寻址和数据类型,沿用主流PC架构的发展而不是重新创作。
AMD-64寄存器如上图所示。