第五章 虚拟变量模型和滞后变量模型
- 格式:doc
- 大小:546.00 KB
- 文档页数:17



第五章经典单方程计量经济学模型:专门问题一、内容提要本章主要讨论了经典单方程回归模型的几个专门题。
第一个专题是虚拟解释变量问题。
虚拟变量将经济现象中的一些定性因素引入到可以进行定量分析的回归模型,拓展了回归模型的功能。
本专题的重点是如何引入不同类型的虚拟变量来解决相关的定性因素影响的分析问题,主要介绍了引入虚拟变量的加法方式、乘法方式以及二者的组合方式。
在引入虚拟变量时有两点需要注意,一是明确虚拟变量的对比基准,二是避免出现“虚拟变量陷阱”。
第二个专题是滞后变量问题。
滞后变量包括滞后解释变量与滞后被解释变量,根据模型中所包含滞后变量的类别又可将模型划分为自回归分布滞后模型与分布滞后模型、自回归模型等三类。
本专题重点阐述了产生滞后效应的原因、分布滞后模型估计时遇到的主要困难、分布滞后模型的修正估计方法以及自回归模型的估计方法。
如对分布滞后模型可采用经验加权法、Almon多项式法、Koyck方法来减少滞项的数目以使估计变得更为可行。
而对自回归模型,则根据作为解释变量的滞后被解释变量与模型随机扰动项的相关性的不同,采用工具变量法或OLS法进行估计。
由于滞后变量的引入,回归模型可将静态分析动态化,因此,可通过模型参数来分析解释变量对被解释变量影响的短期乘数和长期乘数。
第三个专题是模型设定偏误问题。
主要讨论当放宽“模型的设定是正确的”这一基本假定后所产生的问题及如何解决这些问题。
模型设定偏误的类型包括解释变量选取偏误与模型函数形式选取取偏误两种类型,前者又可分为漏选相关变量与多选无关变量两种情况。
在漏选相关变量的情况下,OLS估计量在小样本下有偏,在大样本下非一致;当多选了无关变量时,OLS估计量是无偏且一致的,但却是无效的;而当函数形式选取有问题时,OLS估计量的偏误是全方位的,不仅有偏、非一致、无效率,而且参数的经济含义也发生了改变。
在模型设定的检验方面,检验是否含有无关变量,可用传统的t检验与F检验进行;检验是否遗漏了相关变量或函数模型选取有错误,则通常用一般性设定偏误检验(RESET检验)进行。



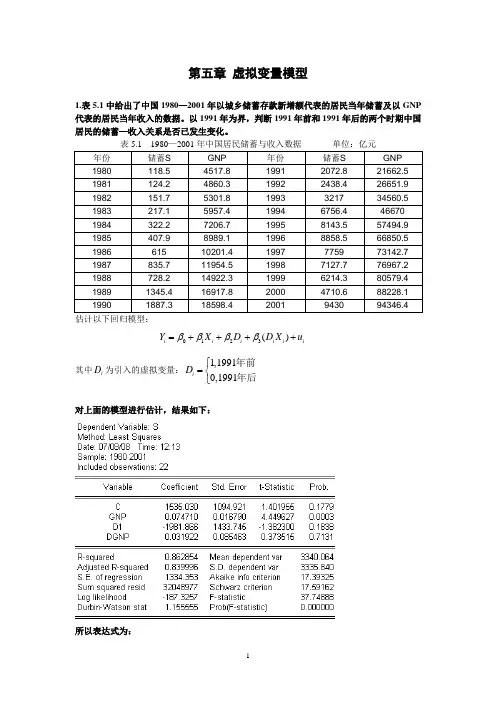
第五章虚拟变量模型1.表5.1中给出了中国1980—2001年以城乡储蓄存款新增额代表的居民当年储蓄及以GNP 代表的居民当年收入的数据。
以1991年为界,判断1991年前和1991年后的两个时期中国居民的储蓄—收入关系是否已发生变化。
年份储蓄S GNP 年份储蓄S GNP 1980 118.5 4517.8 1991 2072.8 21662.5 1981 124.2 4860.3 1992 2438.4 26651.9 1982 151.7 5301.8 1993 3217 34560.5 1983 217.1 5957.4 1994 6756.4 46670 1984 322.2 7206.7 1995 8143.5 57494.9 1985 407.9 8989.1 1996 8858.5 66850.5 1986 615 10201.4 1997 7759 73142.7 1987 835.7 11954.5 1998 7127.7 76967.2 1988 728.2 14922.3 1999 6214.3 80579.4 1989 1345.4 16917.8 2000 4710.6 88228.1 1990 1887.3 18598.4 2001 9430 94346.4 估计以下回归模型:0123()i i i i i iY X D D X uββββ=++++其中iD为引入的虚拟变量:1,19910,1991iD⎧=⎨⎩年前年后对上面的模型进行估计,结果如下:所以表达式为:15350.0751981.90.032()i i i i i Y X D D X =+-+(1.40) (4.45) (-1.38) (0.37)从2β和3β的t 检验值可以知道,这两个参数显著的为0,所以1991年前和1991年后两个时期的回归结果是相同的。
下面用邹式检验来验证上面对于两个时期的回归结果相同的结论是否正确。




第五章经典单方程计量经济学模型:专门问题一、内容提要本章主要讨论了经典单方程回归模型的几个专门题。
第一个专题是虚拟解释变量问题。
虚拟变量将经济现象中的一些定性因素引入到可以进行定量分析的回归模型,拓展了回归模型的功能。
本专题的重点是如何引入不同类型的虚拟变量来解决相关的定性因素影响的分析问题,主要介绍了引入虚拟变量的加法方式、乘法方式以及二者的组合方式。
在引入虚拟变量时有两点需要注意,一是明确虚拟变量的对比基准,二是避免出现“虚拟变量陷阱”。
第二个专题是滞后变量问题。
滞后变量包括滞后解释变量与滞后被解释变量,根据模型中所包含滞后变量的类别又可将模型划分为自回归分布滞后模型与分布滞后模型、自回归模型等三类。
本专题重点阐述了产生滞后效应的原因、分布滞后模型估计时遇到的主要困难、分布滞后模型的修正估计方法以及自回归模型的估计方法。
如对分布滞后模型可采用经验加权法、Almon多项式法、Koyck方法来减少滞项的数目以使估计变得更为可行。
而对自回归模型,则根据作为解释变量的滞后被解释变量与模型随机扰动项的相关性的不同,采用工具变量法或OLS法进行估计。
由于滞后变量的引入,回归模型可将静态分析动态化,因此,可通过模型参数来分析解释变量对被解释变量影响的短期乘数和长期乘数。
第三个专题是模型设定偏误问题。
主要讨论当放宽“模型的设定是正确的”这一基本假定后所产生的问题及如何解决这些问题。
模型设定偏误的类型包括解释变量选取偏误与模型函数形式选取取偏误两种类型,前者又可分为漏选相关变量与多选无关变量两种情况。
在漏选相关变量的情况下,OLS估计量在小样本下有偏,在大样本下非一致;当多选了无关变量时,OLS估计量是无偏且一致的,但却是无效的;而当函数形式选取有问题时,OLS估计量的偏误是全方位的,不仅有偏、非一致、无效率,而且参数的经济含义也发生了改变。
在模型设定的检验方面,检验是否含有无关变量,可用传统的t检验与F检验进行;检验是否遗漏了相关变量或函数模型选取有错误,则通常用一般性设定偏误检验(RESET检验)进行。
1. 表5.1中给出了中国1980—2001年以城乡储蓄存款新增额代表的居民当年储蓄及以GNP 代表的居民当年收入的数据。
以1991年为界,判断1991年前和1991年后的两个时期中国居民的储蓄—收入关系是否已发生变化。
表5.1 1980—2001年中国居民储蓄与收入数据 单位:亿元年份 储蓄S GNP 年份 储蓄S GNP 1980 118.5 4517.8 1991 2072.8 21662.5 1981 124.2 4860.3 1992 2438.4 26651.9 1982 151.7 5301.8 1993 3217 34560.5 1983 217.1 5957.4 1994 6756.4 46670 1984 322.2 7206.7 1995 8143.5 57494.9 1985 407.9 8989.1 1996 8858.5 66850.5 1986 615 10201.4 1997 7759 73142.7 1987 835.7 11954.5 1998 7127.7 76967.2 1988 728.2 14922.3 1999 6214.3 80579.4 1989 1345.4 16917.8 2000 4710.6 88228.1 19901887.318598.42001943094346.4估计以下回归模型:0123()i i i i i i Y X D D X u ββββ=++++其中i D 为引入的虚拟变量:1,19910,1991i D ⎧=⎨⎩年前年后对上面的模型进行估计,结果如下:所以表达式为:15350.0751981.90.032()i i i i i Y X D D X =+-+(1.40) (4.45) (-1.38) (0.37)从2β和3β的t 检验值可以知道,这两个参数显著的为0,所以1991年前和1991年后两个时期的回归结果是相同的。
下面用邹式检验来验证上面对于两个时期的回归结果相同的结论是否正确。
过程如下:输入要验证的突变点,本例为1991年。
输出结果如下:从伴随概率值可以看出,邹式检验的结果是接受原假设,即方程结构没有发生变化,1991年不是突变点。
与设定虚拟变量的结果是一样的。
2.表4是1982:1—1985:4中国季度酒销量(y,万吨)。
t画序列图如下得到序列图如下:这是一个季节时间序列数据,呈明显的季节变化特征,通过加入季节虚拟变量来描述季节特征建立模型。
表4 全国酒销量(t y ,万吨) 季节数据年月 Y D1 D2 D3 1982:1 92.7 1 0 0 1982:2 79.3 0 1 0 1982:3 80.1 0 0 1 1982:4 86.7 0 0 0 1983:1 104.1 1 0 0 1983:2 89.7 0 1 0 1983:3 90.2 0 0 1 1983:4 90.2 0 0 0 1984:1 107.9 1 0 0 1984:2 96.7 0 1 0 1984:3 97.8 0 0 1 1984:4 93.6 0 0 0 1985:1 111.5 1 0 0 1985:2 98.4 0 1 0 1985:3 97.7 0 0 1 1985:494 0 0 0定义虚拟变量1,1,1,1230,0,0,t t t D D D t t t ===⎧⎧⎧===⎨⎨⎨≠≠≠⎩⎩⎩第一季度第二季度第三季度,,第一季度第二季度第三季度Eviews 操作如下按上述过程依次定义D2和D3。
定义过虚拟变量后,建立模型,进行估计。
有上面的输出结果可以看出,D2和D3的相伴概率分别为0.3020和0.4939,可知,D2和D3的回归参数并不显著,所以从模型中剔除虚拟变量D2和D3。
重新进行参数估计:相应估计式为:80.94 1.2815.421t y t D =++(48.5) (7.3) (8.3)20.89,52,0.8R F DW ===1982年第二季度令t=1。
对于这组数据,只把第一季度区别于其他3个季度就可以了。
3. 表5.2给出了总过电力基本建设投资X 与发电量Y 的相关资料,拟建立一多项式分布滞后模型来考察两者的关系。
表5.2 中国电力工业基本建设投资与发电量年份基本建设投资(亿元)X 发电量(亿千瓦时)Y年份基本建设投资(亿元)X发电量(亿千瓦时)Y1975 30.65 1958 1986 161.6 4495 1976 39.98 2031 1987 210.88 4973 1977 34.72 2234 1988 249.73 5452 1978 50.91 2566 1989 267.85 5848 1979 50.99 2820 1990 334.55 6212 1980 48.14 3006 1991 377.75 6775 1981 40.14 3093 1992 489.69 7539 1982 46.23 3277 1993 675.13 8395 1983 57.46 3514 1994 1033.42 9218 1984 76.99 3770 1995 1124.15 10070 1985 107.86 4107由于无法预知电力行业基本建设投资对发电量影响的时滞期,需取不同的滞后期试算。
经过试算发现,在2阶阿尔蒙多项式变换下,滞后期数取到第6期,估计结果的经济意义比较合理。
估计过程如下:输出结果如下:输出结果的下边部分给出了分布滞后模型的各滞后期的参数。
最后得到分布滞后模型估计式为:1234563319.50.323 1.777 2.69 3.061 2.891 2.180.927t t t t t t t t Y X X X X X X X ------=+++++++(13.62) (0.19) (2.14) (1.88) (1.86) (1.96) (1.1) (0.24)4. 表5.3给出了中国1978—2000年按当年价测度的GDP 与居民消费CONS 数据,检验两者的因果关系。
表5.3 中国GDP与消费支出单位:亿元年份CONS GDP 年份CONS GDP 1978 1759.100 3605.600 1990 9113.200 18319.50 1979 2005.400 4074.000 1991 10315.90 21280.40 1980 2317.100 4551.300 1992 12459.80 25863.70 1981 2604.100 4901.400 1993 15682.40 34500.70 1982 2867.900 5489.200 1994 20809.80 46690.70 1983 3182.500 6076.300 1995 26944.50 58510.50 1984 3674.500 7164.400 1996 32152.30 68330.40 1985 4589.000 8792.100 1997 34854.60 74894.20 1986 5175.000 10132.80 1998 36921.10 79003.30 1987 5961.200 11784.70 1999 39334.40 82673.10 1988 7633.100 14704.00 2000 42911.90 89112.50 1989 8523.500 16466.00取两阶滞后,过程如下:输入要检验的变量。
输入滞后阶数。
输出结果如下:从上面的输出结果可以看出,根据伴随概率值知道,在5%的显著水平下:拒绝GDP不是CONS的格兰杰检验,即GDP是CONS的格兰杰检验。
接受CONS不是GDP的格兰杰检验。
5.以深圳成指(SZ)和上海综指(SH)序列为例进行非因果性检验步骤。
1999年1月4日—2001年10月15日深圳成指(SZ)和上海综指(SH)序列如下图:进行格兰杰检验,过程如下:建立工作文件,打开数据租窗口。
输入滞后期,本例选择滞后5期得到如下结果:对上述分析结果进行分析:由对应的概率可以看出:接受“上海综指不是深圳成指变化的原因”的假设;拒绝“深圳成指不是上海综指变化的原因”,即深圳成指是上海综指变化的原因。
分别进行滞后5,10,15,20,25期的检验,均得到上述结论。
6.已知1970—1991年美国制造业固定厂房设备投资Y和销售量X的相关数据如表5.4所示。
(1)假定销售量对厂房设备支出有一个分部滞后效应,使用4期滞后和2次多项式去估计此分布滞后模型。
(2)检验销售量与厂房设备支出的Granger因果关系,使用直至6期为止的滞后并评述结果。
表5.4 单位:10亿美元年份厂房开支Y 销售额X 年份厂房开支Y 销售额X 1970 36.99 52.805 1981 128.68 168.129 1971 33.6 55.906 1982 123.97 163.351 1972 35.42 63.027 1983 117.35 172.547 1973 42.35 72.931 1984 139.61 190.682 1974 52.48 84.79 1985 152.88 194.538 1975 53.66 86.589 1986 137.95 194.657 1976 68.53 98.797 1987 141.06 206.326 1977 67.48 113.201 1988 163.45 223.547 1978 78.13 126.905 1989 183.8 232.724 1979 95.13 143.936 1990 192.61 239.459 1980 112.6 154.391 1991 182.81 235.142估计分布滞后模型,过程如下:估计结果如下:对应的分布滞后模型的表达式为:123430.830.830.320.010.160.11t t t t t t Y X X X X X ----=-++---做格兰杰检验,以一阶滞后为例,过程如下:结果如下:从上面F检验的伴随概率值可以知道,X与Y互为因果关系。
按上述过程分别做从1直到6期滞后的Granger因果关系检验,结果分别如下:2阶:3阶:4阶:5阶:6阶:从上述结果可以看出,随着滞后期的增加,Y月X的Granger因果关系有所变化。
在不超过4期滞后的检验中,两者互为因果关系;而滞后期为5和6的检验结果说明,两者不互为因果关系。