How to configure job scheduler (OpenPBS) for computer cluster
- 格式:doc
- 大小:191.50 KB
- 文档页数:32


Torque + Maui配置手册之抛砖引玉篇本文将以应用于实际案例(南航理学院、复旦大学物理系、宁波气象局)中的作业调度系统为例,简单介绍一下免费开源又好用的Torque+Maui如何在曙光服务器上进行安装和配置,以及针对用户特定需求的常用调度策略的设定情况,以便可以起到抛砖引玉的作用,使更多的人关注MAUI这个功能强大的集群调度器(后期将推出SGE+MAUI版本)。
本文中的涉及的软件版本Torque 版本:2.1.7 maui版本:3.2.6p17。
1. 集群资源管理器Torque1.1.从源代码安装Torque其中pbs_server安装在node33上,TORQUE有两个主要的可执行文件,一个是主节点上的pbs_server,一个是计算节点上的pbs_mom,机群中每一个计算节点(node1~node16)都有一个pbs_mom负责与pbs_server通信,告诉pbs_server该节点上的可用资源数以及作业的状态。
机群的NFS共享存储位置为/home,所有用户目录都在该目录下。
1.1.1.解压源文件包在共享目录下解压缩torque# tar -zxf torque-2.1.17.tar.gz假设解压的文件夹名字为: /home/dawning/torque-2.1.71.1.2.编译设置#./configure --enable-docs --with-scp --enable-syslog其中,默认情况下,TORQUE将可执行文件安装在/usr/local/bin和/usr/local/sbin下。
其余的配置文件将安装在/var/spool/torque下默认情况下,TORQUE不安装管理员手册,这里指定要安装。
默认情况下,TORQUE使用rcp来copy数据文件,官方强烈推荐使用scp,所以这里设定--with-scp.默认情况下,TORQUE不允许使用syslog,我们这里使用syslog。
1.正文1.1.配置计划表配置Schedule之前需要创建计划表,通过计划表Schedule可以获得关于Schedule Jobs的信息。
这表储存一个Jobs的初始化信息,参数和计划信息。
他们分别是S_NQ_ERR_MSG, S_NQ_INSTANCE, S_NQ_JOB, and S_NQ_JOB_PARAM。
计划表可以创建在任意的schema中。
创建这些对象的脚本被保存在%Oracle_BI_Home\server\Schema下SAJOBS.xxxx.sql这个文件,xxxx是你要保存对象的数据库类型,打开文件夹下的SAJOBS.Oracle.sql 并且执行他的代码创建表,打开文件夹下的SAACCT.Oracle.sql 并且执行他创建Accounting 表。
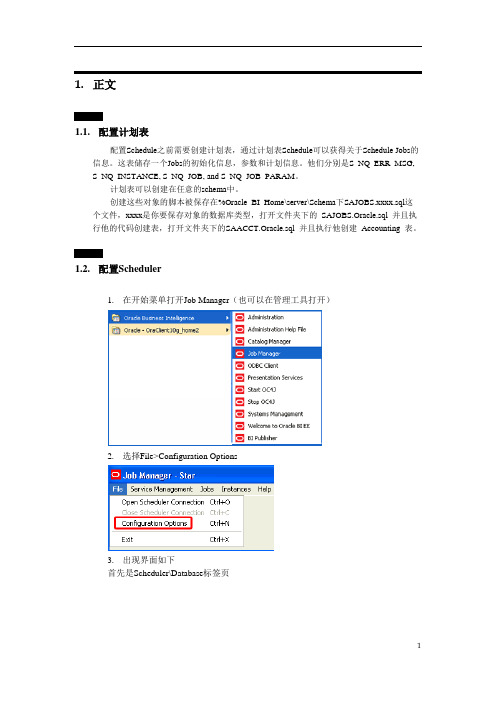
1.2.配置Scheduler1.在开始菜单打开Job Manager(也可以在管理工具打开)2.选择File>Configuration Options3.出现界面如下首先是Scheduler\Database标签页其中的数据库和用户名和下面的4个表名是对应的。
这四张表就建在这个数据库的用户下。
下来是General标签页检查一下Scheduler的脚本是不是在那个地址,一般情况下,如果是用默认安装BIEE 的话,就不用改这个地方的地址了,然后设置一下管理员密码。
其实配置到这一步就可以点击OK,Oracle BI Scheduler服务就可以启动了接下来在Mali标签页配置发件人邮箱其中要注意正确设置SMTP服务项。
转到iBots界面,在这个界面只要确认一下Log就可以了最后还有一点配置,添加一段对用户的密码验证文件:打开D:\OracleBIData\web\config\instanceconfig.xml,看有没有一段代码<Alerts><ScheduleServer>localhost</ScheduleServer></Alerts>中间是你的主机名,在它下面添加代码<CredentialStore><CredentialStorage type="file" path="D:\OracleBIData\web\config\credentialstore.xml"/> </CredentialStore>保存后打开命令提示符,执行下面语句cryptotools credstore -add -infile d:/OracleBIData/web/config/credentialstore.xml回车后在alias项输入Admin,回车后提示是否要对文件加密,可以选择N,提示是否替换源文件,选择Y。

如何使用Android的JobScheduler进行后台任务调度Android的JobScheduler是一个用于调度和管理后台任务的系统服务。
它能够帮助开发者有效地管理应用程序的后台任务,提高应用程序的性能和电池寿命。
本文将介绍如何使用Android的JobScheduler进行后台任务调度。
一、什么是JobSchedulerJobScheduler是Android系统为了更好地管理后台任务而引入的一个系统服务。
通过JobScheduler,开发者可以在特定的条件下执行后台任务,例如设备连接到充电器、设备连接到WiFi网络等。
JobScheduler主要用于解决在Android系统中的后台任务调度问题,以减少对电池寿命和设备性能的影响。
二、如何使用JobScheduler1. 添加依赖库在项目的build.gradle文件中,添加如下依赖库:```groovyimplementation 'com.firebase:firebase-jobdispatcher:0.8.5'```2. 创建JobServiceJobService是一个继承自android.app.job.JobService的抽象类,需要实现抽象方法onStartJob()和onStopJob()。
onStartJob()方法用于执行后台任务,onStopJob()方法用于取消后台任务。
下面是一个示例:```javapublic class MyJobService extends JobService {@Overridepublic boolean onStartJob(JobParameters params) {// 在这里执行后台任务return false;}@Overridepublic boolean onStopJob(JobParameters params) {// 在这里取消后台任务return false;}}```3. 创建Job在应用程序的代码中,创建一个Job实例,指定需要执行的任务细节、执行条件等。

python的scheduler用法scheduler(调度器)是Python中常用的一个模块,可以用于定时执行任务。
它非常适用于一些需要定时执行的操作,例如定时发送电子邮件、定时备份数据、定时爬取网页等。
本文将详细介绍python 的scheduler用法。
一、安装scheduler模块在开始使用scheduler之前,我们需要先安装该模块。
可以使用pip命令在命令行中进行安装,具体命令如下:pip install scheduler二、引入scheduler模块在编写Python代码时,我们需要引入scheduler模块,以便可以使用该模块提供的功能。
引入scheduler模块的代码如下:```pythonimport scheduler三、创建scheduler对象在使用scheduler模块之前,我们需要先创建一个scheduler对象,以便进行后续的任务调度。
创建scheduler对象的代码如下:```pythons=scheduler.scheduler()四、定义任务函数在使用scheduler进行任务调度时,我们需要定义要执行的任务。
可以通过定义函数的方式来实现。
下面是一个示例:```pythondef task():print("执行任务...")五、添加任务在scheduler对象中,我们可以通过调用`add_job`方法来添加任务。
该方法接受两个参数,第一个参数是要执行的函数名称,第二个参数是触发器类型(可以是日期时间、间隔时间等)。
```pythons.add_job(task,'interval',seconds=10)上述代码表示每隔10秒执行一次task函数。
六、开始调度任务在添加完任务后,我们需要调用scheduler对象的`start`方法来开始执行任务调度。
代码如下:```pythons.start()七、结束调度任务如果我们想要手动结束任务调度,可以调用scheduler对象的`shutdown`方法。

调度工具odi使用流程英文回答:ODI (Oracle Data Integrator) is a powerful data integration and ETL (Extract, Transform, Load) tool developed by Oracle. It allows users to efficiently manage and execute data integration processes, such as extracting data from various sources, transforming it into a desired format, and loading it into a target system.The process of using ODI typically involves the following steps:1. Designing the Data Integration Process: This involves creating a data integration project in ODI Studio, which is a graphical development environment. In this step, you define the source and target systems, map the data elements between them, and create the necessary transformations and mappings.2. Setting up the Connectivity: ODI supports various types of data sources, such as databases, files, and web services. To connect to these sources, you need toconfigure the necessary connection information, such as the server name, username, password, and port number.3. Defining the Data Flows: Once the connectivity is established, you can define the data flows in ODI Studio. This involves creating mappings, which specify how the data should be transformed from the source to the target. Youcan use ODI's built-in transformation functions, or create custom transformations using SQL or PL/SQL.4. Testing and Debugging: After defining the data flows, it is important to test and debug them to ensure they work as expected. ODI provides various debugging tools, such as data preview, breakpoints, and error handling, to help identify and fix any issues.5. Executing the Data Integration Process: Once thedata flows are tested and debugged, you can execute thedata integration process in ODI. This can be done manuallyor scheduled to run at specific times. ODI provides a scheduling tool called the ODI Scheduler, which allows you to define the execution frequency, dependencies, and other parameters.6. Monitoring and Maintenance: After the data integration process is executed, it is important to monitor its progress and performance. ODI provides various monitoring and logging features, such as real-time status updates, error logs, and performance metrics, to help you track and optimize the data integration process.Overall, ODI is a comprehensive data integration tool that simplifies the process of extracting, transforming, and loading data. It provides a user-friendly interface, powerful transformation capabilities, and robust scheduling and monitoring features. Whether you are a data integration developer or a data analyst, ODI can greatly streamline your data integration workflows.中文回答:ODI(Oracle Data Integrator)是由Oracle开发的一款强大的数据集成和ETL(Extract, Transform, Load)工具。
Python定时任务框架APScheduler详解APScheduler最近想写个任务调度程序,于是研究了下 Python 中的任务调度⼯具,⽐较有名的是:Celery,RQ,APScheduler。
Celery:⾮常强⼤的分布式任务调度框架RQ:基于Redis的作业队列⼯具APScheduler:⼀款强⼤的任务调度⼯具RQ 参考 Celery,据说要⽐ Celery 轻量级。
在我看来 Celery 和 RQ 太重量级了,需要单独启动进程,并且依赖第三⽅数据库或者缓存,适合嵌⼊到较⼤型的 python 项⽬中。
其次是 Celery 和 RQ ⽬前的最新版本都不⽀持动态的添加定时任务(celery 官⽅不⽀持,可以使⽤第三⽅的或者实现),所以对于⼀般的项⽬推荐⽤ APScheduler,简单⾼效。
Apscheduler是⼀个基于Quartz的python定时任务框架,相关的 api 接⼝调⽤起来⽐较⽅便,⽬前其提供了基于⽇期、固定时间间隔以及corntab类型的任务,并且可持久化任务;同时它提供了多种不同的调⽤器,⽅便开发者根据⾃⼰的需求进⾏使⽤,也⽅便与数据库等第三⽅的外部持久化储存机制进⾏协同⼯作,⾮常强⼤。
安装最简单的⽅法是使⽤ pip 安装:$ pip install apscheduler或者下载源码安装:$ python setup.py install⽬前版本:3.6.3基本概念APScheduler 具有四种组件:triggers(触发器)jobstores (job 存储)executors (执⾏器)schedulers (调度器)triggers:触发器管理着 job 的调度⽅式。
jobstores:⽤于 job 数据的持久化。
默认 job 存储在内存中,还可以存储在各种数据库中。
除了内存⽅式不需要序列化之外(⼀个例外是使⽤ ProcessPoolExecutor),其余都需要 job 函数参数可序列化。
PBS是功能最为齐全,历史最悠久,支持最广泛的本地集群调度器之一。
PBS的目前包括openPBS,PBS Pro和T orque三个主要分支。
其中OpenPBS是最早的PBS系统,目前已经没有太多后续开发,PBS pro 是PBS的商业版本,功能最为丰富。
T orque是Clustering公司接过了OpenPBS,并给与后续支持的一个开源版本。
下面是本人安装torque的过程。
一、Torque安装在master(管理结点上)1、解压安装包[root@master tmp]# tar zxvf torque-2.3.0.tar.gz2、进入到解压后的文件夹./configure --with-default-server=mastermakemake install3、(1)[root@master torque-2.3.0]#./torque.setup <user><user>必须是个普通用户(2)[root@master torque-2.3.0]#make packages把产生的 tpackages , torque-package-clients-linux-x86-64.sh,torque-package-mom-linux-x86-64.sh 拷贝到所有节点。
(3)[root@master torque-2.3.0]# ./torque-package-clients-linux-x86_64.sh --install[root@master torque-2.3.0]# ./torque-package-mom-linux-x86_64.sh --install(4)编辑/var/spool/torque/server_priv/nodes(需要自己建立)加入如下内容master np=4node01 np=4........node09 np=4(5)启动pbs_server,pbs_sched,pbs_mom,并把其写到/etc/rc.local里使其能开机自启动。
Hootsuite - Magento Plugin User Guide This document explains how to correctly configure theHootsuite - Magento Product Catalog Synchronization withFacebook plugin.The plugin appears in the Magento Admin Main Menu.There are 2 Menu Options:1)Facebook Product Feed Settings shows a grid withthe different feeds configured.2)Facebook Product Feed Auto Scheduler shows FTPconfiguration of the remote server, the local path inMagento to save the Feeds XML and theconfiguration of scheduler.Facebook Product Feed Settings:The Grid displays all of your FeedsFrom this Grid, you can make changes to an existing Feed or Create new FeedsThe following actions are available for each Feed:●Edit - modify the selected Feed.●Delete - remove the selected Feed.●Duplicate - clone the selected Feed and edit it.●Process - runs the Feed and generates an XML file in real time.The following bulk action options are available for multiple Feeds:●Delete - remove all selected Feeds.●Process - runs all selected Feeds, and generate distinct XML in real time.Feed Management:●Facebook Catalog Product Feed option lets you manage the Feed details○Title (Required) - unique short description.○Description - long text that describes the function of the feed.○Store (Required) - generates a Feed based on underlying Store catalog.○Status (Required) - flag to enable or disable the Feed for processing.●Filter Configuration lets Users set the selection criteria for what products for aparticular store catalog are included in the resulting XML file generated.●Attribute Mapping lets Users specify what Magento store Product attributes to bemapped to Facebook Attributes on the resulting XML file. Facebook Requiredattributes cannot be updated and must be mapped to a choice Magento Attribute.Optional Attributes may be exempt if desired and if included will need to be mapped to a corresponding Magento store product attribute.Scheduling the Facebook Product Feed:The following need to be defined to schedule a process to auto generate the Feed XML file●Remote Path Setting, allows you to configure the FTP remote server in which thefeeds will be uploaded.○Server - FTP host domain.○Path - remote directory onFTP server where thegenerated XML file will besent.○Test Connection - toconfirm connect criteriaprovided is accurate.●Local Path Setting, lets a User specify adirectory under the Magento rootdirectory where the generated XML filewill be sent.●Scheduler, lets a User configure thefrequency of the background processto auto generate the Feed XML file。
blockingscheduler用法blockingscheduler是Python中一个用于调度阻塞任务的模块,它允许你在多线程或多进程环境中运行阻塞任务,并且能够在任务之间自动切换,提高程序的运行效率。
以下是blockingscheduler的使用方法:1. 安装blockingscheduler模块使用pip命令进行安装:```pip install blockingscheduler```2. 导入blockingscheduler模块```pythonimport blockingscheduler```3. 创建一个Scheduler对象```pythonscheduler = blockingscheduler.Scheduler()```4. 向Scheduler对象添加任务使用add_task方法向Scheduler对象添加任务。
add_task方法接受一个函数作为参数,并返回一个Task对象。
```pythontask = scheduler.add_task(func, *args, **kwargs)```函数func是要执行的任务,*args和**kwargs是用于传递给任务函数的参数。
5. 运行Scheduler对象调用Scheduler对象的run方法,开始运行所有的任务。
run 方法将会阻塞当前线程或进程,直到所有任务完成。
```pythonscheduler.run()```6. 配置Scheduler对象调用Scheduler对象的configure方法,可以配置Scheduler的一些属性,例如调度间隔、并发数量等。
```pythonscheduler.configure(interval=1, max_workers=4)```interval参数指定了调度间隔的时间(单位为秒),max_workers参数指定了并发数量。
默认值为1和4。
7. 更高级的使用方法blockingscheduler还提供了其他的一些功能,例如取消任务、获取任务的结果等。
Portable Batch SystemOpenPBS Release 2.3Administrator GuideTranslator: 裴建中(北京工业大学)Email: pjz0311@QQ: 250386348注:翻译这一管理员指南仅仅是想和大家共同学习和交流与集群相关的知识,并无他意。
文中带有下划线的句子是我觉得理解的不好的地方,其后同时保留了原来的英文以便大家理解,请留意。
文中翻译不当的地方敬请各位批评更正。
1.介绍此文档用来为系统管理员提供构建、安装、配置并且管理PBS所需的一些信息。
很可能有一些重要的信息项被漏掉了。
这类文档中没有更加完善的了,到目前为止,它已经被好几个不同的管理员在不同的站点进行了更新,当然仍是比较欠缺。
1.1. 什么是PBS?PBS是一个批处理作业和计算机系统资源管理软件包。
它原本是按照POSIX 1003.2d批处理环境来开发的。
这样,它就可以接受批处理作业、shell脚本和控制属性,作业运行前对其储存并保护,然后运行作业,并且把输出转发回提交者。
PBS可以被安装并配置运行在单机系统或多个系统组来支持作业处理。
由于PBS的灵活性,多个系统可以以多种方式组合。
1.2. PBS的组件PBS包括四个主要的组件:命令组件、作业服务器、作业执行组件和作业调度器。
这里给出每一部分的简要描述来帮助你在安装过程中做出决定。
命令组件:PBS支持与POSIX1003.2d相一致的命令行和图形接口两种命令方式。
这些命令用于提交、监视、修改和删除作业。
命令可以被安装在任何PBS支持的系统类型上,并且不需要在本地安装任何其它的PBS组件。
共有三种类型的命令:任何已授权用户可以使用的命令;操作员命令;管理员命令;操作员和管理员命令需要不同的访问权限。
作业服务器:作业服务器是PBS的中心。
在本文档中,它一般被称作服务器或被称为可执行文件的名字pbs_server。
所有命令和其它守护进程都通过IP网络和服务器通信。
服务器的主要功能就是提供基本的批处理服务,例如接收/创建一个批处理作业,修改作业,保护作业免受系统宕机的影响并运行作业。
作业执行器:作业执行器是一个守护进程,它真正地把作业放入执行队列。
这一进程,pbs_mon,被非正式地命名为Mom,正如它是所有正在执行的作业的母亲(mother)一样。
当Mom从一个服务器那里接收一个作业拷贝时就将它放入执行队列。
Mom创建一个和用户登陆会话尽可能一致的新的会话。
例如,如果用户的登陆shell是csh,那么Mom就创建一个会话,在此会话中.login和.cshrc一样运行。
当服务器指示需要那么做时,Mom也负责把作业的输出返回给用户。
作业调度器:作业调度器是另一个守护进程,这一进程包括site’policy[1],这一策略控制着哪一个作业被运行,在那个节点运行,什么时候运行。
因为每一个site对于什么是好的或者有效的策略都有它自己的想法,PBS允许每一个site来创建它自己的调度器。
当运行的时候,调度器就可以和不同的Moms进行通信来获知系统资源的状态;和服务器进行通信来获知要执行的作业的有效性。
与服务器之间的接口是通过和命令组件一样的API。
实际上,调度器仅仅作为服务器的批处理管理器出现的。
除了上面主要的部分之外,PBS也提供了一个应用编程接口,API,命令组件用它来和服务器进行通信。
这一API在和PBS一起完成的第三部分的man pages中描述。
A site[1]如果愿意可以利用这些API来实现新的命令。
1.3.发布信息1.3.1.T ar文件PBS是以一个单一的tar文件来提供的。
这个tar文件包括:以后记和文本两种形式提供的本文档一个“配置”脚本,所有的源码,头文件和用于构建并安装PBS的make文件。
当解压tar文件时,将会在上面的信息之上创建一个顶层目录。
这一顶层目录将被命名为发布版本加补丁级别。
例如,对于发布版本 2.1和补丁级别13,这一目录将被命名为pbs_v2.1p13。
建议这些文件在解压时带上-p参数以便保留权限位。
1.3.2.附加要求PBS使用一个由GNU的autoconf生成的配置脚本来产生make文件。
如果你有一个POSIX make程序,那么由配置脚本生成的make文件将尝试利用POSIX的make特性。
当构建时如果你的make不能够处理这个make文件那么你可能用的是一个被破坏的make。
要是在构建时make失败,就试一下GNU的make。
如果使用了基于GUI的Tcl或基于调度器的Tcl,就需要有Tcl的头文件和库。
Tcl的官方网站是:/, ftp:///pub/tcl/tcl8_0PBS已经不再使用Tcl8.0之前的版本。
必须使用Tcl和Tk8.0或更高的版本。
如果使用了BaSL调度器,将需要yacc和lex(或者GNU bison和flex)。
对于bison和flex 的有关站点是:/software/software.html :/pub/gnu为了格式化包含在这一发布版本的这一文档,我们强烈推荐使用GNU groff包。
最新的groff版本1.11.1,它可以在这里找到:/software/groff/groff.html2.安装这一部分试图来解释构建和安装PBS的步骤。
PBS安装可以通过GNU的autoconf过程来完成。
这一安装过程与其他许多“典型”软件包相比需要更多的手工配置。
因为有一些涉及site policy的选项,所以安装就不能被自动的决定。
如果PBS运行在基于intel x86的红帽Linux上,可以使用RPM包来安装。
对于安装说明请看2.4.9部分。
为了获得一个可用的PBS安装,需要有下面的步骤:1. 阅读这一指南并为主机和PBS的大概配置做一个计划。
见1.2节和3.0到3.2节。
2. 决定PBS源码和(构建)目标文件的放置位置。
见2.2节。
3. 把发布的文件解压为源码树。
见2.2节。
4. 选择“配置”选项并从目标书的顶层来运行configure。
见2.2到2.4节。
5. 在目标树的顶层通过make来编译PBS。
见2.2到2.3部分。
6. 在目标树的顶层通过make install来安装PBS的模块。
需要root权限。
见2.2节。
7. 如果PBS正在管理一个多个节点的联合体或者像IBM SP这样的并行系统时,创建一个节点描述文件。
见第3章批处理系统配置。
节点可以在服务器通过qmgr命令启动之后加入,即使这时节点文件还没有创建。
8. 启动(bring up)并配置服务器。
见3.1到3.5节。
9. 配置并启动Moms。
见3.6节。
10.通过调度一些作业来测试。
见qrun(8B)man page.11.配置并启动调度程序。
通过授权(enabling)调度来设置服务器为活动状态。
见第四章2.1.计划PBS能够支持很广泛的配置。
它可以被安装并用于控制简单或大型系统中的作业。
它可以在多个系统之间用于作业负载均衡。
可以用于把一个集群或并行系统的节点分配给并行和串行作业。
或者它能够处理上述的混合情况。
在进一步介绍之前,我们需要定义一些术语。
PBS如何使用这些术语和你可能期望的有所区别。
节点:一个带有一个单操作系统映像(image),一个统一虚拟内存映像,一个或多个cpu和一个或多个IP地址的计算机系统。
通常,术语执行机被用作节点。
一个像SGI Origin 2000这样在一个单一操作系统拷贝下运行的多个处理单元的盒子对PBS来说就是一个节点而不管SGI的术语是什么。
一个像IBM SP这样包含多个单元的盒子,每一个都有它自己的操作系统的拷贝,就是多个节点的集合。
(A box like the SGI Origin 2000, with contains multiple processing units running under a single OS copy is one node to PBS regardless of SGI’s terminology. A bos like the IBM SP which contains many units, each w ith their own copy of the OS, is a collection of many nodes.)一个机群节点声明为包含一个或多个虚拟处理器。
使用术语“虚拟”是因为在一个物理节点中声明的虚拟处理器的数量可以等于或大于或小于实际处理器的数量。
现在分配的是这些虚拟处理器而不是整个的物理节点。
一个机群节点的虚拟处理器(VPs)可以以独占的方式或临时共享的方式分配。
分时节点不会被认为包含有虚拟节点并且这些节点没有分配作业也没有被作业所使用。
联合体(Complex):由一个批处理系统管理的主机的集合。
一个联合体可以由在某一时间仅分配有一个作业的节点组成或者由分配有多个马上要执行的作业的节点组成,或者是两者的组合。
集群:由多个集群节点组成的联合体。
集群节点:一个这样的节点——它的虚拟处理器在某一时间专门分配给一个作业(见独占节点部分),或者多个作业(见临时共享节点)。
这一节点类型也可以被称作空间共享。
如果一个集群节点有多于一个虚拟处理器,这些虚拟节点可以被分配给不同的作业或者用于满足单个作业的需要。
然而,单个节点上的所有处理器将被按照同一种方式来分配,例如,所有虚拟处理器将被分配为独占的或者临时共享的。
在多个作业中分时共享的主机被称为“timeshared”。
独占节点:一个独占节点就是在某一时间只能用于一个并且只能是一个作业。
对于一个作业的整个持续时间,一个节点集可以以独占的方式分配给这个作业。
这是提高消息传递程序性能的典型做法。
临时共享节点:一个临时共享节点,它的虚拟处理器被多个作业临时共享。
如果几个作业需要多个临时共享节点,某些虚拟处理器可能分配给两个作业,某些可能对其中一个作业是唯一的(some VPs may be allocated commonly to both jobs and some may be unique to one of the jobs)。
当一个虚拟处理器以分时共享为基础分配时,它将一直保持分时共享状态直到所有使用它的作业都终止为止。
然后这个虚拟处理器就可以以分时共享或者独占的使用方式再一次分配。
分时共享:在我们的上下文中,分时共享总是允许多个作业同时在一个执行主机或节点上运行。
一个分时共享节点就是作业可以分时共享的节点。
通常使用术语主机与分时共享相联接而不是节点,正如分时共享主机。
如果使用了术语节点而没有分时前缀,这个节点就是可以以独占方式或者分时共享方式分配的集群节点。
如果一个主机或节点被指示为分时共享,它将永远不会被服务器分配为独占的或者临时共享的。