淘宝性能测试白皮书V0.3
- 格式:pdf
- 大小:424.17 KB
- 文档页数:18

技术白皮书本文档所有内容均为科来独立完成,未经科来做出明确书面许可,不得为任何目的、以任何形式或手段(包括电子、机械、复印、录音或其他形式)对本文档的任何部分进行复制、修改、存储、引入检索系统或者传播。
版权所有© 2014 - 2015 成都科来软件有限公司。
保留所有权利。
科来电话:400-6869-069网址:邮箱:目录1 前言读者对象本文档主要适用于以下工程师:●系统工程师●技术支持工程师2 系统简介科来业务性能管理系统(以下简称为“UPM”)是成都科来软件有限公司全新推出的业务性能管理方案。
2.1 系统概述用户的业务活动从来没有像现在这样依赖于网络系统,并且核心业务和网络系统的融合已经成为一个趋势。
核心业务的发展和支撑业务系统的网络系统的发展都很迅速,这种发展相互促进,同时互相影响,系统也在发展中变得越来越庞大,越来越复杂。
支撑核心业务系统的网络系统的运维工作,包括网络基础设施、相关的应用系统、数据库以及安全保障系统的运维已经变成一个至关重要的工作,网络系统的运维终将和企业的核心业务活动完全融合起来。
UPM是真正的基于业务网络的性能管理系统,能让网络的运维和业务的保障紧密结合起来,帮助用户提升以业务为核心的主动网络运维能力,提升业务保障工作和故障处置的效率。
2.2 系统组成UPM由前端回溯分析服务器(以下简称为“前端”)和UPM分析中心(以下简称为“UPM中心”)这两部分组成。
前端前端设备可分布式部署在业务系统通讯传输的各个重要汇聚节点,通过交换机端口镜像或使用流量分流设备采集业务通信数据。
前端实时采集分析的性能指标参数和应用报警信息,并通过管理接口上报到UPM中心进行汇总分析。
UPM中心UPM中心部署在数据中心用于集中管理配置前端设备,集中收集前端设备采集的业务性能指标及报警信息进行汇总展现。
UPM中心和前端采用了B/S(Browser/Server)架构,通过定期的心跳进行数据交互,从而完成对全局网络的集中监控和管理。


中国移动能力开放白皮书(V1版)中国移动2016年12月目录1前言 (1)1.1 范围 (1)1.2中国移动十三五“大连接”战略 (1)2中国移动能力开放愿景 (2)3中国移动能力开放 (2)3.1 能力开放概览 (2)3.2基础通信能力 (3)3.2.1 短信/语音验证码 (3)3.2.2 超级短信 (4)3.2.3 云端群呼 (4)3.2.4 语音/视频会议 (5)3.2.5 来电身份提示 (6)3.2.6 拨打验证 (7)3.2.7 后向流量 (8)3.2.8 融合通信 (9)3.2.9 典型案例 (12)3.3互联网能力 (15)3.3.1 和通行证 (15)3.3.2 互联网计费 (18)3.3.3 数据分析服务 (21)3.3.4 消息推送 (23)3.3.5 互联网广告 (24)3.3.6 139邮箱能力 (26)3.4 物联网能力 (29)3.4.1 应用开发能力 (29)3.4.2 BaaS支撑能力 (30)3.4.3 多源接入及存储能力 (32)3.4.4 通信状态数据服务 (34)3.4.5 流量信息服务 (36)3.4.6 SIM卡信息数据服务 (38)4结束语 (39)1前言1.1 范围本白皮书立足中国移动十三五期间“大连接”战略,详细介绍中国移动能力开放愿景,旨在汇聚中国移动的优质资源、能力为合作伙伴提供全方位服务,与合作伙伴共同构建开放生态,实现互利互赢。
第一版重点推出基础通信能力、互联网能力和物联网能力。
1.2中国移动十三五“大连接”战略中国移动将牢固树立“创新、协调、绿色、开放、共享”的发展理念,准确把握万物互联时代特征,立足当前,布局长远,全面实施大连接战略。
中国移动在厚植用户优势的基础上,不断拓展连接广度和深度,着力做大连接规模,做优连接服务,做强连接应用,努力开拓大市场、打造大网络、夯实大能力、构建大协同,在确保发展质量的基础上持续提升连接价值,到2020年实现连接数量“翻一番”。


5G 时代光传送网技术白皮书目录1 引言 (3)2 5G 技术发展及承载需求 (4)2.1 5G 新业务的关键性能需求 (4)2.2 5G RAN 架构的演进趋势 (5)2.3 5G 核心网架构的演进趋势 (6)2.3.1 核心网架构的云化和下移 (6)2.3.2 核心网云化数据中心的互联 (8)2.4 5G 承载网需求分析 (9)2.4.1 大带宽需求 (9)2.4.2 低时延需求 (10)2.4.3 高精度时间同步需求 (11)2.4.4 灵活组网的需求 (11)2.4.5 网络切片需求 (12)3 面向5G 的光传送网承载方案 (14)3.1 5G 前传承载方案 (14)3.1.1 5G 前传典型组网场景 (14)3.1.2 光纤直连方案 (15)3.1.3 无源WDM 方案 (16)3.1.4 有源WDM/OTN 方案 (18)3.1.5 5G 前传承载方案小结 (19)3.2 5G 中传/回传承载方案 (19)3.2.1 中传/回传承载网络架构 (19)淘宝店铺“Vivian研报”收集整理获取最新报告及后续更新服务请淘宝搜索“Vivian研报”3.2.2 网络切片承载方案 (21)3.3 5G 云化数据中心互联方案 (23)3.3.1 大型数据中心互联方案 (23)3.3.2 中小型数据中心互联方案 (23)3.4 5G 光传送网承载方案小结 (24)4 5G 时代的光传送网关键技术演进 (27)4.1 低成本大带宽传输技术 (27)4.1.1 短距非相干技术 (27)4.1.2 中长距低成本相干技术 (27)4.2 低时延传输与交换技术 (28)4.2.1 ROADM 全光组网调度技术 (29)4.2.2 超低时延OTN 传送技术 (30)4.3 高智能的端到端灵活调度技术 (31)4.3.1 ODUflex 灵活带宽调整技术 (31)4.3.2 FlexO 灵活互联接口技术 (32)4.3.3 传送SDN 快速业务随选发放技术 (34)5 总结与展望 (35)6 缩略语 (36)1 引言第五代通信技术(5G)致力于构建信息与通信技术的生态系统,是目前业界最热的课题之一。

淘宝⽹应⽤场景分析系统的质量属性主要分为:可⽤性,可修改性,性能,安全性,可测试性,易⽤性。
系统质量属性------可⽤性可⽤性指在系统在发⽣故障时的运⾏时间和系统正常运⾏时间⽐例。
淘宝⽹作为⼀个相对成熟的系统,⽀持Windows,苹果系统,Android,iOS,既⽀持⽹页也⽀持APP。
场景部分值刺激源系统外部刺激时间制品系统处理器,进程环境正常模式响应将其记录下来,通知⽤户和其他系统,在⼀段时间间隔内不可⽤响应度量修复时间为10分钟系统质量属性------可修改性可修改性要关注的点在于:可以修改什么?何时进⾏变更以及由于谁进⾏变更。
淘宝的地区设置以及语⾔设置都是独⽴于⼿机系统的。
场景部分值刺激源⽤户刺激希望改变功能,改变地区,改变语⾔制品系统⽤户界⾯环境在运⾏时响应仅修改地区或语⾔,不影响别的功能响应度量该修改对其他功能没有影响。
系统质量属性------性能性能与时间有关,事件发⽣时系统对其做出的反应,淘宝的货物信息量是很⼤的,能够快速的检索出⽤户需要的货物是它性能的体现,同时在节⽇时,他能够⽀持⼤量⽤户的同时操作也是性能的⼀个⽅⾯。
场景部分可能的值刺激源⽤户刺激随机启动的⽤户登录制品系统环境正常模式响应检索和操作数据库响应度量2秒内显⽰出物品信息或者登录成功系统质量属性------安全性安全性指衡量系统在向合法⽤户提供服务的同时,阻⽌⾮授权使⽤的能⼒。
在淘宝⽹中出现的安全性问题就在于⿊客的恶意攻击,以致于导致系统的崩溃和瘫痪。
场景部分可能的值刺激源⿊客刺激试图降低系统服务的可⽤性制品系统服务环境直接连接到⽹络上响应阻⽌对服务的访问响应度量检测到攻击并拒绝访问响应度量检测到攻击并拒绝访问系统质量属性------可测试性可测试性是指通过测试来揭⽰软件缺陷的容易程度。
淘宝⽹在上线初进⾏系统整体的测试。
场景部分可能的值刺激源系统验证⼈员刺激所交付的系统制品完整的应⽤环境部署时响应准备测试环境响应度量执⾏测试的时间系统质量属性------易⽤性易⽤性关注的是对⽤户来说完成某个期望任务的容易程度和系统所提供的⽤户⽀持的种类。

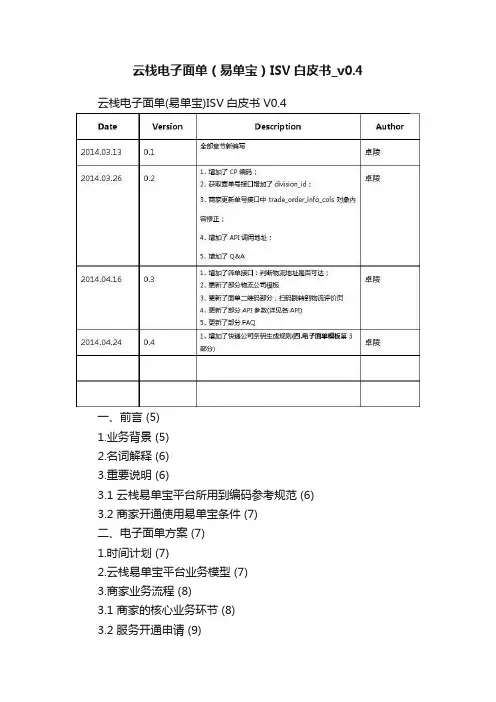
云栈电子面单(易单宝)ISV白皮书V0.4一、前言 (5)1.业务背景 (5)2.名词解释 (6)3.重要说明 (6)3.1 云栈易单宝平台所用到编码参考规范 (6)3.2 商家开通使用易单宝条件 (7)二、电子面单方案 (7)1.时间计划 (7)2.云栈易单宝平台业务模型 (7)3.商家业务流程 (8)3.1 商家的核心业务环节 (8)3.2 服务开通申请 (9)三. 核心接口 (11)1.获取电子面单号 (11)1.1 应用场景 (11)1.2 规则 (11)1.3 API内容 (11)2.更新电子面单号 (14)2.1 应用场景 (14)2.2 规则 (14)2.3 API介绍 (14)3.获取发货地&CP开通状态&面单号余额 (15)3.1 应用场景 (15)3.2规则 (16)3.3 API介绍 (16)4.筛单接口1:判断收件地址是否可达 (17)4.1 应用场景 (17)4.2规则 (17)4.3 API介绍 (17)5.筛单接口2:查询支持起始地到目的地的物流公司 (18)5.1 应用场景 (18)5.2规则 (18)5.3 API介绍 (18)四、电子面单模板 (18)1.通用电子面单模板 (18)2.各快递公司电子面单模板 (18)五、电子面单二维码 (21)六、FAQ (23)一、前言1. 业务背景随着电子商务平台和物流服务信息化飞速发展,面单号(或称之为运单号)成为物流服务商串联快递单、订单、商家、商品等各种信息的枢纽。
相比之下,传统纸质面单价格高、信息录入效率低、信息安全隐患等方面的劣势已愈发凸显。
近一年来,电子面单的普及已是大势所趋。
究其原因,是因为电子面单具备的独特优势:a.效率更高⏹打印效率比纸质面单提升60%-90%,每小时可打印数千张;⏹对于商家,运单和拣货单可选用一张热敏纸,提高拣选效率;商家甚至在打包完成后的确认环节再去实时打印面单,高速打印确保订单能快速准确完成。

阿里巴巴数字NPS体系建设白皮书随着互联网的高速发展,人们的生活方式也在发生着巨大的变化。
无论是个人还是企业,都在不断地追求更加完美的用户体验,而高效的反馈机制是实现用户体验优化的一个重要途径。
近年来,NPS(Net Promoter Score)作为一种测量客户忠诚度和满意度的指标,已经得到了越来越广泛的应用。
阿里巴巴作为中国领先的数字经济平台,也广泛运用NPS指标来评估用户体验,并建立了数字NPS体系,以进一步提高用户满意度和忠诚度。
一、数字NPS体系的概念和目标数字NPS体系是阿里巴巴在数字化时代下,针对消费者使用体验而设计的,以数字形式呈现,主要通过数据科技支撑进行快速响应、智能分析和及时反馈的满意度评价体系。
数字NPS体系的目标是以客户为中心,全面提高用户体验质量,以此增强用户忠诚度和引导用户口碑宣传,以进一步巩固和提高品牌形象。
数字NPS体系主要包括四个方面:搭建数字化评价框架、构建高效指标体系、实现快速反馈、持续优化用户体验。
二、数字NPS体系的理论基础和应用方法数字NPS体系的理论基础是NPS指标,这是一种由弗雷德·赫里森(FredReichheld)在2003年提出的忠诚度评价指标。
NPS通过问卷调查或者其他方式,询问参与者对一个品牌或者产品的评价,主要涉及到参与者的满意度、忠诚度和推荐意愿。
NPS评分主要分为三类:促进型、中立型和危机型。
在具体应用中,数字NPS体系主要通过以下三个流程来实现:1、数据收集和整理:数字NPS主要依靠海量的数据来源,通过用户的操作记录、客服对话、在线问卷等多种形式的渠道,采集用户的评价数据。
然后通过算法分析,将这些数据分类、整理、统计,形成反映用户体验的定量数据。
2、快速反馈机制:数字NPS体系实现了持续的全方位实时快速反馈机制。
当出现用户体验问题时,通过数字NPS体系可以迅速采集数据进行分析,并尽快调整产品和服务方案,以满足客户的需求,为用户提供优质的使用体验。


WhitepaperDeep Learning Performance Scale-outRevision: 1.2Issue Date: 3/16/2020AbstractIn this whitepaper we evaluated the training performance of Scale-out implementation with the latest software stack and compared it with the results obtained in our previous paper [0]. Using TensorFlow as the primary framework and tensorflow benchmark models, the performance was compared in terms of throughput images/sec on ImageNet dataset, at a single node and multi-node level. We tested some of the more popular neural networks architectures for this comparison and demonstrated the scalability capacity of Dell EMC PowerEdge Servers powered by NVIDIA V100 Tensor Core GPUs.RevisionsDate Description3/16/2020Initial release AcknowledgementsThis paper was produced by the following:NameVilmara Sanchez Dell EMC - Software EngineerBhavesh Patel Dell EMC - Distinguished EngineerJosh Anderson Dell EMC - System Engineer (contributor)We would like to acknowledge:❖Technical Support Team - Mellanox Technologies❖Uber Horovod GitHub Team❖Nvidia Support teamTable of ContentsMotivation (4)Test Methodology (4)PowerEdge C4140-M Details (6)Performance Results - Short Tests for Parameter Tuning (8)Performance Results - Long Tests Accuracy Convergence (16)Conclusion (17)Server Features (18)Citation (19)References (19)Appendix: Reproducibility (20)MotivationWith the recent advances in the field of Machine Learning and especially Deep Learning, it’s becoming more and more important to figure out the right set of tools that will meet some of the performance characteristics for these workloads. Since Deep Learning is compute intensive, the use of accelerators like GPU become the norm, but GPUs are premium components and often it comes down to what is the performance difference between a system with and without GPU. In that sense Dell EMC is constantly looking to support the business goals of customers by building highly scalable and reliable infrastructure for Machine Learning/Deep Learning workloads and exploring new solutions for large scale distributed training to optimize the return on investment (ROI) and Total Cost of Ownership (TCO).Test MethodologyWe have classified TF benchmark tests in two categories: short and long tests. During the development of the short tests, we experimented with several configurations to determine the one that yielded the highest throughput in terms of images/second, then we selected that configuration to run the long tests to reach certain accuracy targets.Short TestsThe tests consisted of 10 warmup steps and then another 100 steps which were averaged to get the actual throughput. The benchmarks were run with 1 NVIDIA GPU to establish a baseline number of images/sec and then increasing the number of GPUs to 4 and 8. These tests allow us to experiment with the parameter tuning of the models in distributed mode.Long TestsThe tests were run using 90 epochs as the standard for ResNet50. This criterion was used to determine the total training time on C4140-M servers in distributed mode with the best parameter tuning found in the short tests and using the maximum number of GPUs supported by the system. In the section below, we describe the setup used, and Table 1gives an overall view on the test configuration.Testing SetupCommercial Application Computer Vision - Image classificationBenchmarks code▪TensorFlow Benchmarks scriptsTopology ▪ Single Node and Multi Node over InfiniBandServer ▪ PowerEdge C4140-M (4xV100-16GB-SXM2)Frameworks▪ TensorFlow with Horovod library for Distributed Mode[1] Models ▪ Convolutional neural networks: Inception-v4, vgg19,vgg16, Inception-v3, ResNet-50 and GoogLeNetBatch size ▪ 128-256GPU’s▪ 1-8Performance Metrics▪ Throughput images/second▪ Training to convergence at 76.2% TOP-1 ACCURACY Dataset ▪ ILSVRC2012 - ImageNetEnvironment ▪ DockerSoftware StackThe Table shows the software stack configuration used to build the environment to run the tests shown in paper [0] and the current testsSoftware Stack Previous Tests Current TestsTest Date February 2019 January 2020OS Ubuntu 16.04.4 LTS Ubuntu 18.04.3 LTSKernel GNU/Linux 4.4.0-128-genericx86_64GNU/Linux 4.15.0-69-genericx86_64nvidia driver 396.26 440.33.01CUDA 9.1.85 10.0 cuDNN 7.1.3 7.6.5 NCCL 2.2.15 2.5.6 TensorFlow 1.10 1.14 Horovod 0.15.2 0.19.0 Python 2.7 2.7 Open MPI 3.0.1 4.0.0 Mellanox OFED 4.3-1 4.7-3 GPUDirect RDMA 1.0-7 1.0-8Single Node - Docker Container TensorFlow/tensorflow:nightly-gpu-py3nvidia/cuda:10.0-devel-ubuntu18.04Multi Node -Docker Container built from nvidia/cuda:9.1-devel-ubuntu16.04nvidia/cuda:10.0-devel-ubuntu18.04Benchmark scripts tf_cnn_benchmarks tf_cnn_benchmarksDistributed SetupThe tests were run in a docker environment. Error! Reference source not found. 1 below shows the different logical layers involved in the software stack configuration. Each server is connected to the InfiniBand switch; has installed on the Host the Mellanox OFED for Ubuntu, the Docker CE, and the GPUDirect RDMA API; and the container image that was built with Horovod and Mellanox OFED among other supporting libraries. To build the extended container image, we used the Horovod docker file and modified it by adding the installation for Mellanox OFED drivers [2]. It was built from nvidia/cuda:10.0-devel-ubuntu18.04Figure 1: Servers Logical Design. Source: Image adapted fromhttps:///docs/DOC-2971Error! Reference source not found.2 below shows how PowerEdge C4140-M is connected via InifniBand fabric for multi-node testing.Figure 2: Using Mellanox CX5 InfiniBand adapter to connect PowerEdge C4140 in multi-nodeconfigurationPowerEdge C4140-M DetailsThe Dell EMC PowerEdge C4140, an accelerator-optimized, high density 1U rack server, is used as the compute node unit in this solution. The PowerEdge C4140 can support four NVIDIA V100 Tensor Core GPUs, both the V100-SXM2 (with high speed NVIDIA NVLink interconnect) as well as the V100-PCIe models.Figure 3: PowerEdge C4140 ServerThe Dell EMC PowerEdge C4140 supports NVIDIA V100 with NVLink in topology ‘M’ with a high bandwidth host to GPU communication is one of the most advantageous topologies for deep learning. Most of the competitive systems, supporting either a 4-way, 8-way or 16-way NVIDIAVolta SXM, use PCIe bridges and this limits the total available bandwidth between CPU to GPU. See Table 2 with the Host-GPU Complex PCIe Bandwidth Summary.ConfigurationLink Interface b/n CPU-GPU complex Total BandwidthNotesM4x16 Gen3128GB/sEach GPU has individual x16 Gen3 to Host CPUTable 2: Host-GPU Complex PCIe Bandwidth SummarySXM1SXM2SXM4SXM3CPU2CPU1x16x16x16x16UPI Configuration MX16 IO SlotX16 IO SlotFigure 4: C4140 Configuration-MNVLinkPCIePerformance Results - Short Tests for Parameter Tuning Below are the results for the short tests using TF 1.14. In this section we tested all the models in multi node mode and compared the results obtained with TF 1.10 in 2019. Throughput CNN Models TF 1.10 vs TF 1.14The Figure 5 several CNN models comparing results with TF 1.10 vs TF 1.14. In Figure 6 we notice that the performance gain is about 1.08X (or 8%) between the two releases.Figure 5: Multi Node PowerEdge C4140-M – Several CNN Models TF 1.10 vs TF 1.14Figure 6 Multi Node PowerEdge C4140-M – Several CNN Models TF 1.10 vs TF 1.14 (Speedup factor)Performance Gain with XLASince there was not much performance gain with the basic configuration, we decided to explore the limits of GPU performance using other parameters. We looked at XLA (Accelerated Linear Algebra) [3], by adding the flag –xla=true at the script level. By default, the TensorFlow graph executor “executes” the operations with individual kernels, one kernel for the multiplication, one kernel for the addition and one for the reduction. With XLA, these operations are “fused” in just one kernel; keeping the intermediate and final results in the GPU, reducing memory operations, and therefore improving performance.See below Figure 7 for results and Figure 8 for speedup factors across the models. The models inception-v4, inception-v3 and ResNet-50 showed much better performance using XLA, with speedup factors from 1.35X up to 1.43X. Since the ResNet-50 model is most widely used, we used it to continue the rest of the tests.Figure 7: Multi Node PowerEdge C4140-M. Several CNN Models TF 1.10 vs TF 1.14 + XLAFigure 8: Multi Node PowerEdge C4140-M. Several CNN Models TF 1.10 vs TF 1.14 + XLA (Speedupfactor)ResNet-50’s Performance with TF 1.14 + XLAIn this section, we evaluated the performance of ResNet-50 model trained with TF 1.14 and TF 1.14 with XLA enabled. The tests were run with 1 GPU, 4 GPUs, and 8 GPUs and the results were compared with those obtained for version TF 1.10 from our previous paper [0]. Also, we explored the performance using batch size of 128 and 256. See Figure 9 and Figure 10.Figure 9: Multi Node PowerEdge C4140-M. ResNet-50 BS 128 TF 1.10 vs TF 1.14 vs TF 1.14 + XLAAs we saw in the previous section ResNet-50 with batch size 128 with 8 GPUs had a performance gain of ~3% with TF 1.10 vs TF 1.14, and ~35% of performance gain with TF 1.10 vs TF 1.14 with XLA enabled, see Figure 9. On the other hand, ResNet-50 with batch size 256 with 8 GPUs had a performance gain of ~2% with TF 1.10 vs TF 1.14, and ~46% of performance gain with TF 1.10 vs TF 1.14 with XLA enabled, see Figure 10. Due to the higher performance of ResNet-50 with batch size 256, we have selected it to further optimize performance.Figure 10: Multi Node PowerEdge C4140-M. ResNet-50 BS 256 TF 1.10 vs TF 1.14 vs TF 1.14 + XLAResNet-50 with TF 1.14 + XLA + GPUDirect RDMAAnother feature explored in our previous paper was GPUDirect RDMA which provides a direct P2P (Peer-to-Peer) data path between GPU memory using a Mellanox HCA device between the nodes. In this test, we enabled it by adding the NCCL flag – x NCCL_NET_GDR_LEVEL=3 at the script level (this variable replaced the variable NCCL_IB_CUDA_SUPPORT in NCCL v 2.4.0). NCCL_NET_GDR_LEVEL variable allows you to control when to use GPUDirect RDMA between a NIC and a GPU. Example level 3 indicates to use GPUDirect RDMA when GPU and NIC are on the same PCI root complex [4].Figure 11: Multi Node PowerEdge C4140-M. ResNet-50 with TF 1.14 + XLA + GPUDirect RDMA Figure 11shows the results of ResNet-50 with TF 1.14 w/XLA enabled, with and without GPUDirect RDMA. We did not observe much performance gains using GPUDirect RDMA across nodes i.e. the performance remained the same and hence we did not explore it further in our testing. This is not to say that GPUDirect RDMA does not help when using scale-out, all we are saying is we did not see the performance gains; hence we are not exploring it further in this paper.ResNet-50’s configuration for better performanceFigure 12 summarizes the results of different configurations explored for the short tests and based on the tests we found that the best performance was achieved using the combination below:ResNet-50 + BS 256 + TF 1.14 + XLA enabledFigure 12: Multi Node PowerEdge C4140-M - ResNet-50’s Configuration for Best PerformanceResNet-50’s Scale-outPowerEdge C4140 using Nvidia 4x NVLink architecture scales relatively well when using Uber Horovod distributed training library and Mellanox InfiniBand as the high-speed link between nodes. It scales ~3.9x times within the node and ~6.9x using scale-out for ResNet-50 with batch size 256. See Figure 13.Figure 13: Multi Node PowerEdge C4140-M - ResNet-50’s Scale-out vs Scale-upFigure 14: Multi Node PowerEdge C4140-M vs CompetitorThe above benchmarks shown in Figure 14 are done on 2 servers C4140 x4 V100 GPUs, each connected by Mellanox ConnectX-5 network adapter with 100Gbit/s over IPoIB. The Dell EMC distributed mode with Horovod achieved 85% of scaling efficiency for ResNet-50 batch size 256 compared with the ideal performance; on the other hand, it achieved 95% of scaling efficiency versus a test run by TF team on 2018 with a VM (virtual machine) instance on GCP(Google cloud) with 8x V100 GPUs and batch size=364 [5].Performance Results - Long Tests Accuracy Convergence Our final tests were to determine the total training time for accuracy convergence with the latest tensorflow version.In this section we decided to include all the batch sizes we tested in our previous paper and compared it with ResNet-50 using batch size 256.Figure 15shows the total training time achieved when running ResNet-50 with different batch sizes and both versions of tensorflow (TF 1.10 vs TF 1.14 with XLA enabled).On average using TF 1.14 +XLA was ~1.3X faster than our previous tests.Figure 15: Multi Node PowerEdge C4140-M - ResNet-50’s Long Training for Accuracy Conv.Conclusion•The performance with TF 1.14 among the models was just slightly superior (~1%-8%) versus TF 1.10. On the other hand, TF 1.14 with XLA boosted the performance up to~46% among the models ResNet-50, Inception-v3 and Inception-v4.•In the case of ResNet-50 model, its performance improved up to ~ 3% with TF 1.14, and up to ~46% with TF 1.14 and XLA enabled. ResNet-50 batch size 256 scaled better(1.46X) versus ResNet-50 BS 128 (1.35X).•The configuration with the highest throughput (img/sec) was ResNet-50 batch size 256 trained with distributed Horovod + TF 1.14 + XLA enabled.•Dell EMC PowerEdge C4140 using Nvidia 4x NVLink architecture scales relatively well when using Uber Horovod distributed training library and Mellanox InfiniBand as the high-speed link between nodes. It scale-out ~3.9X times within the node and ~6.9X across nodes for ResNet-50 BS 256.•On average, the training time for the long tests to reach accuracy convergence were ~ 1.3 X faster using distributed Horovod + TF 1.14 + XLA enabled.•There is a lot of performance improvement being added continuously either at the GPU level, library level or framework level. We are continuously looking at how we can improve our performance results by experimenting with different hyper parameters.•TensorFlow in multi-GPU/multi-node with Horovod Distributed and XLA support improve model performance and reduce the training time, allowing customers to do more with no additional hardware investment.Server FeaturesCitation@article {sergeev2018horovod,Author = {Alexander Sergeev and Mike Del Balso},Journal = {arXiv preprint arXiv: 1802.05799},Title = {Horovod: fast and easy distributed deep learning in {TensorFlow}}, Year = {2018}}References•[0] https:///manuals/all-products/esuprt_solutions_int/esuprt_solutions_int_solutions_resources/servers-solution-resources_white-papers52_en-us.pdf•[1] Horovod GitHub, “Horovod Distributed Deep Learning Training Framework” [Online].Available: https:///horovod/horovod•[2] Mellanox Community, “How to Create a Docker Container with RDMA Accelerated Applications Over 100Gb InfiniBand Network” [Online]. Available:https:///docs/DOC-2971•[3] TensorFlow, “XLA: Optimizing Compiler for Machine Learning” [Online] Available: https:///xla•[4] NCCL 2.5, “NCCL Environment Variables” [Online]. Available:https:///deeplearning/sdk/nccl-developer-guide/docs/env.html#nccl-ib-cuda-support•[5] TensorFlow, “Pushing the limits of GPU performance with XLA” [Online]. Available: https:///tensorflow/pushing-the-limits-of-gpu-performance-with-xla-53559db8e473Appendix: ReproducibilityThe section below walks through the setting requirements for the distributed Dell EMC system and execution of the benchmarks. Do this for both servers:•Update Kernel on Linux•Install Kernel Headers on Linux•Install Mellanox OFED at local host•Setup Password less SSH•Configure the IP over InfiniBand (IPoIB)•Install CUDA with NVIDIA driver•install CUDA Toolkit•Download and install GPUDirect RDMA at the localhost•Check GPUDirect kernel module is properly loaded•Install Docker CE and nvidia runtime•Build - Horovod in Docker with MLNX OFED support•Check the configuration status on each server (nvidia-smi topo -m && ifconfig && ibstat && ibv_devinfo -v && ofed_info -s)•Pull the benchmark directory into the localhost•Mount the NFS drive with the ImageNet dataRun the system as:On Secondary node (run this first):$ sudo docker run --gpus all -it --network=host -v /root/.ssh:/root/.ssh --cap-add=IPC_LOCK -v /home/dell/imagenet_tfrecords/:/data/ -v/home/dell/benchmarks/:/benchmarks -v /etc/localtime:/etc/localtime:ro --privileged horovod:latest-mlnxofed_gpudirect-tf1.14_cuda10.0 bash -c "/usr/sbin/sshd -p 50000; sleep infinity"On Primary node:$ sudo docker run --gpus all -it --network=host -v /root/.ssh:/root/.ssh --cap-add=IPC_LOCK -v /home/dell/imagenet_tfrecords/:/data/ -v/home/dell/benchmarks/:/benchmarks -v /etc/localtime:/etc/localtime:ro --privileged horovod:latest-mlnxofed_gpudirect-tf1.14_cuda10.0•Running the benchmark in single node mode with 4 GPUs:$ python /benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --device=gpu --data_format=NCHW --optimizer=sgd --distortions=false --use_fp16=True --local_parameter_device=gpu --variable_update=replicated --all_reduce_spec=nccl --data_dir=/data/train --data_name=imagenet --model=ResNet-50 --batch_size=256 --num_gpus=4 --xla=true•Running the benchmark in multi node mode with 8 GPUs:$ mpirun -np 8 -H 192.168.11.1:4,192.168.11.2:4 --allow-run-as-root -xNCCL_NET_GDR_LEVEL=3 -x NCCL_DEBUG_SUBSYS=NET -x NCCL_IB_DISABLE=0 -mcabtl_tcp_if_include ib0 -x NCCL_SOCKET_IFNAME=ib0 -x NCCL_DEBUG=INFO -xHOROVOD_MPI_THREADS_DISABLE=1 --bind-to none --map-by slot --mca plm_rsh_args "-p 50000" python /benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --device=gpu --data_format=NCHW --optimizer=sgd --distortions=false --use_fp16=True --local_parameter_device=gpu --variable_update=horovod --horovod_device=gpu --datasets_num_private_threads=4 --data_dir=/data/train --data_name=imagenet --display_every=10 --model=ResNet-50 --batch_size=256 --xla=True。
云栈电子面单(易单宝)ISV白皮书_v0.4 云栈电子面单(易单宝)ISV白皮书V0.4一、前言 (5)1.业务背景 (5)2.名词解释 (6)3.重要说明 (6)3.1 云栈易单宝平台所用到编码参考规范 (6)3.2 商家开通使用易单宝条件 (7)二、电子面单方案 (7)1.时间计划 (7)2.云栈易单宝平台业务模型 (7)3.商家业务流程 (8)3.1 商家的核心业务环节 (8)3.2 服务开通申请 (9)三. 核心接口 (11)1.获取电子面单号 (11)1.1 应用场景 (11)1.2 规则 (11)1.3 API内容 (11)2.更新电子面单号 (14)2.1 应用场景 (14)2.2 规则 (14)2.3 API介绍 (14)3.获取发货地&CP开通状态&面单号余额 (15)3.1 应用场景 (15)3.2规则 (16)3.3 API介绍 (16)4.筛单接口1:判断收件地址是否可达 (17)4.1 应用场景 (17)4.2规则 (17)4.3 API介绍 (17)5.筛单接口2:查询支持起始地到目的地的物流公司 (18)5.1 应用场景 (18)5.2规则 (18)5.3 API介绍 (18)四、电子面单模板 (18)1.通用电子面单模板 (18)2.各快递公司电子面单模板 (18)五、电子面单二维码 (21)六、FAQ (23)一、前言1. 业务背景随着电子商务平台和物流服务信息化飞速发展,面单号(或称之为运单号)成为物流服务商串联快递单、订单、商家、商品等各种信息的枢纽。
相比之下,传统纸质面单价格高、信息录入效率低、信息安全隐患等方面的劣势已愈发凸显。
近一年来,电子面单的普及已是大势所趋。
究其原因,是因为电子面单具备的独特优势:a.效率更高打印效率比纸质面单提升60%-90%,每小时可打印数千张;对于商家,运单和拣货单可选用一张热敏纸,提高拣选效率;商家甚至在打包完成后的确认环节再去实时打印面单,高速打印确保订单能快速准确完成。
你和日赚百万的淘宝店主之间只差一个套路!专注互联网教育,主攻时代潮流行业技能,新华互联网科技始终与时俱进,培养专业互联网技能型人才。
8月9日,由新华互联网科技联合优酷土豆强强推出的大型线上演讲节目《老师来了》第二季石家庄站强势开讲,电商行业美女大V吴蚊米老师亲临《老师来了》大讲堂,教授新华学子如何玩转电商,玩转淘宝直播。
吴蚊米,蚊子会创始人,蚊子会达人学院院长,电商行业最具影响力大V。
十年淘宝电商从业经验,三年电商媒体从业经验。
擅长淘宝店铺运营实操,行业同仁称之为“电商人中最懂媒体,媒体人中最懂电商”,其著作有:《玩转电商,赢在淘宝》、《蚊子会电商白皮书》等,在电商行业中拥有很好的口碑和影响力。
讲课过程中,吴蚊米老师首先分享了淘宝直播的发展史,包括从2016年的横向扩张到2017年的纵向扩张。
在这期间,淘宝直播也发生了质的变化,从简单有趣有料的生活消费类直播走到了引入大数据的新生态大直播。
吴老师通过蚊子会旗下会员的出色直播案例阐述了淘宝直播的魅力,揭开了现代淘宝直播中涉及到的人群、内容、流量、玩法、内容结构化等升级过程,让新华学子清晰的认识到了电商运营中淘宝直播的奥秘。
此外,吴蚊米老师还通过真实的案例为新华学子讲授了如何做好一场出彩的淘宝直播,这让新华学子懂得了如何将自己在新华学到的电商专业技能应用到淘宝直播这个全新的电商模式中,从而在将来的工作岗位中脱颖而出。
在讲解的过程中,吴老师还渗透了很多关于淘宝直播的基础知识,包括淘宝直播间的装修、主播的基本素质等。
更让新华学子惊喜的是,吴老师还将淘宝直播冲热门的技巧现场传授给了新华学子,引得现场掌声不断!用网红的要求来做直播,用运营总监的要求来做直播,主播定位是服务者角色,服务好粉丝和商家,这是吴蚊米老师对现代电商中的淘宝直播最精确的总结。
讲课过程中,吴蚊米老师还多次与新华学子互动,了解学生目前的学习状况,帮助学生解答目前在学习过程中的各种疑惑,包括电商专业技能和未来就业行业前景等。
奇门标准化协议白皮书V2.2阿里巴巴集团商家业务事业部20151版本记录2目录1版本记录 (2)2目录 (4)3前言 (9)3.1业务背景 (9)3.2名词解释 (9)4奇门对接方案 (10)4.1奇门对接方式 (10)4.2奇门标准化对接构架 (11)4.3系统调用流程 (12)4.4联调、测试方式 (12)4.4.1ERP端 (13)4.4.2WMS端 (14)5接口规范 (15)5.1ERP与奇门的通信协议 (15)5.1.1协议描述 (15)5.1.2访问授权 (15)5.1.3请求参数说明 (16)5.1.4响应参数 (16)5.2奇门与WMS的通信协议 (16)5.2.1协议描述 (16)5.2.2请求参数 (17)5.2.3响应参数 (18)6接口说明 (18)6.1商品同步接口 (18)6.1.2入参规范 (18)6.1.3出参规范 (20)6.2商品组合接口 (21)6.2.1接口介绍 (21)6.2.2入参规范 (21)6.2.3出参规范 (21)6.3入库单创建接口 (21)6.3.1接口介绍 (21)6.3.2入参规范 (22)6.3.3出参规范 (24)6.4入库单确认接口 (24)6.4.1接口介绍 (24)6.4.2入参规范 (25)6.4.3出参规范 (26)6.5退货入库单创建接口 (26)6.5.1接口介绍 (26)6.5.2入参规范 (26)6.5.3出参规范 (28)6.6退货入库单确认接口 (28)6.6.1接口介绍 (28)6.6.2入参规范 (28)6.6.3出参规范 (30)6.7出库单创建接口 (30)6.7.1接口介绍 (30)6.7.2入参规范 (30)6.7.3出参规范 (32)6.8出库单确认接口 (33)6.8.2入参规范 (33)6.8.3出参规范 (35)6.9发货单创建接口 (35)6.9.1接口介绍 (35)6.9.2入参规范 (35)6.9.3出参规范 (39)6.10发货单确认接口 (39)6.10.1接口介绍 (39)6.10.2入参规范 (39)6.10.3出参规范 (42)6.11发货单查询接口 (42)6.11.1接口介绍 (42)6.11.2入参规范 (42)6.11.3出参规范 (42)6.12订单流水查询接口 (45)6.12.1接口介绍 (45)6.12.2入参规范 (45)6.12.3出参规范 (45)6.13订单流水通知接口 (46)6.13.1接口介绍 (46)6.13.2入参规范 (47)6.13.3出参规范 (47)6.14发货单缺货通知接口 (48)6.14.1接口介绍 (48)6.14.2入参规范 (48)6.14.3出参规范 (48)6.15单据取消接口 (49)6.15.2入参规范 (49)6.15.3出参规范 (49)6.16库存查询接口 (50)6.16.1接口介绍 (50)6.16.2入参规范 (50)6.16.3出参规范 (50)6.17库存盘点通知接口 (51)6.17.1接口介绍 (51)6.17.2入参规范 (51)6.17.3出参规范 (52)6.18仓内加工单创建接口 (52)6.18.1接口介绍 (52)6.18.2入参规范 (53)6.18.3出参规范 (54)6.19仓内加工单确认接口 (54)6.19.1接口介绍 (54)6.19.2入参规范 (54)6.19.3出参规范 (56)6.20库存异动接口 (56)6.20.1接口介绍 (56)6.20.2入参规范 (56)6.20.3出参规范 (57)7附录 (58)7.1sign签名算法: (58)7.1.1输入参数为 (58)7.1.2按首字母升序排列 (58)7.1.3连接字符串 (59)7.1.5拼装URL请求 (59)3前言3.1业务背景随着电子商务发展,商家所使用到的各类软件越来越多,各个软件之间没有相互打通,形成一个个信息孤岛,给商家的使用带来种种不便,商家要求各个系统之间的对接需求已经越来越迫切;目前在行业内已经有部分系统直接由服务商之间完成了系统软件的对接,但是由于没有统一的接入标准,导致接入较混乱,对接接口的版本也参差不齐,往往这样的系统对接不具有可复制性,多个系统之间的对接,需要多次开发,给商家的使用和功能迭代升级带来了诸多的不便,同时也给服务商带来额外的维护、开发成本;为了满足商家需求,让商家能够突破各个业务系统之间的信息孤岛,提升商家在各个系统之间的操作效率,解决各个系统之间标准化对接的痛点,我们推出了奇门项目;奇门项目一期支持ERP、WMS之间的系统标准化对接,通过构建ERP、WMS系统之间标准通信协议来实现不同系统之间的打通;对商家来说,省去了更换系统软件所带来的额外开发成本;对ISV来说,省去了与多家ERP、WMS系统对接难的问题,ERP通过一次对接奇门项目,打通与所有WMS之间的通信,WMS通过一次对接奇门项目,可以适配所有ERP软件;后期我们也将加入更多系统的支持,例如CRM与ERP的标准化对接,CRM与在线订购类营销工具的标准化对接;敬请期待!3.2名词解释4奇门对接方案4.1奇门对接方式目前商家使用的各个业务系统之间依靠ISV帮助实现ERP到WMS的对接,如果有多仓需求的商家还需要使用到2套以上的第三方仓储服务所提供的WMS软件,ERP、WMS各自对接,对接的总工作量为N*N倍,不但给ISV的开发带来了极大的成本,对于后期维护,也将是一项艰巨的任务,如下图所示:通过奇门项目后可使原有的网状对接结构变为一对一的对接方式,ERP、WMS只需要与奇门数据总线对接一次即可完成所有系统的适配(特殊场景可能采用扩展字段的方式给与支持),如下图:奇门项目后继接口升级方式将采用字段升级方式,在原有基础上加入更多的业务字段,同时业务接口向下兼容,开发过一次,后继如需更多的业务字段只需在原有接口层面加入业务字段即可,无需重新开发业务逻辑;4.2奇门标准化对接构架前端ERP系统通过TOP平台与奇门应用进行对接,ERP系统通过标准化通信协议、字段访问奇门系统,ERP在此需要进行改造;奇门应用主要提供字段映射、数据翻译、数据路由、账号权限、流控、数据打点等功能,能够让双方的请求通过奇门进行正常的传输,奇门还提供商家自定义扩展字段,通过奇门项目的通用数据通道进行传输,在标准协议不能完全支持的情况下,可以采用扩展字段的方式进行补充;后端WMS系统通过TOP平台与奇门应用进行对接,WMS系统通过标准化通信协议、字段调用奇门系统,WMS在此也需要进行改造;(可选)WMS系统需要提供出能够在系统中新建用户、查询用户的API,以供奇门项目应用调用,新商家接入时,奇门项目可以直接调用该API创建新的用户;4.3系统调用流程正向调用:前端ERP系统通过TOP接口与奇门项目应用进行交互,对于想要发送到WMS的请求首先发送到奇门应用,由奇门负责数据的解析、字段映射、数据翻译,再将处理后的数据通过ERP系统所请求的目的地发送至WMS系统;WMS系统收到请求后,将返回结果送回至奇门应用,由奇门应用统一返回至ERP系统;反向调用:WMS系统主动向ERP系统发出状态更新请求也是类似以上的访问步骤;以下是简版软件流程图:正向流程反向流程4.4联调、测试方式奇门项目支持ERP系统的正向调用以及WMS系统的反向调用,所以对于ERP系统以及WMS系统的测试方法并不一致,以下分别介绍ERP系统以及WMS系统的联调、测试方法:配置信息确认阶段:提前与WMS厂商进行沟通,根据商家的在WMS端的用户信息获取以下配置信息,并提供给奇门项目组,由奇门项目组完成在奇门当中的配置:开发接口阶段:奇门项目当中ERP端支持正向调用也支持反向调用,正向调用的API接口由TOP平台提供,ERP端直接发起对沙箱环境的调用即可完成接口的测试工作,沙箱环境调用地址如下 (只需修改红色标示的method方法字段和test_type字段,test_type值可以取normal和error,normal会返回该请求成功的应答,error会返回该请求失败的应答) :/top/router/qimen/service?method=taobao.qime n.itemlack.report×tamp=2015-04-26%2000:00:07&format=xml&test_type=normal&app_key=testerp_appkey&v=1.0&si gn=abc&sign_method=md5&customerId=stub-cust-code&uid=123456789反向调用的API接口由ERP端提供,奇门会直接向ERP端发起调用,在此类型的API接口测试的过程当中,需要由服务商使用一个Http Restful接口的客户端向奇门发起反向调用;(推荐使用Chrome浏览器下的REST Console插件)系统联调阶段:依次完成正向请求的开发与反向接口的工作后,与奇门项目组共同进行联调,在测试环境当中依次测试之前开发接口的业务逻辑;系统发布阶段:与WMS端服务商共同确认正式环境的配置值,ERP端直接发起对奇门正式环境的调用,需要将原有访问地址与具体配置地址切换成正式环境地址,奇门项目正式环境地址如下:/router/qimen配置信息确认阶段:WMS厂商需提前提供商家的在WMS端的用户信息以及如下的配置信息,提供给奇门项目组以及ERP端进行配置:开发接口阶段:奇门项目当中WMS端支持正向调用也支持反向调用,反向调用的API 接口由TOP平台提供,WMS端直接发起对沙箱环境的调用即可完成接口的测试工作,沙箱环境调用地址如下 (只需修改红色标示的method方法字段和test_type字段,test_type值可以取normal和error,normal会返回该请求成功的应答,error会返回该请求失败的应答) :/router/qimen/service?method=taobao.qimen.ite mlack.report×tamp=2015-04-26%2000:00:07&format=xml&test_type=normal&app_key=stub_appkey&v=1.0&sign =abc&sign_method=md5&customerId=stub-cust-code&uid=123456789正向调用的API接口由WMS端提供,奇门会直接向WMS端发起调用,在此类型的API 接口测试的过程当中,需要由服务商使用一个Http Restful接口的客户端向奇门发起正向调用;(推荐使用Chrome浏览器下的REST Console插件)系统联调阶段:依次完成正向请求的开发与反向接口的工作后,与奇门项目组共同进行联调,在测试环境当中依次测试之前开发接口的业务逻辑;系统发布阶段:WMS服务商与奇门共同确认正式环境的配置值,WMS端直接发起对奇门正式环境的调用,需要将原有访问地址与具体配置地址切换成正式环境地址,奇门项目正式环境地址如下:/router/qimen5接口规范5.1ERP与奇门的通信协议5.1.1协议描述接口遵循REST规范,使用HTTP POST方式进行通讯。
淘宝网仓储配送中心服务白皮书2010-2-5目录一、前言 (2)二、业务模式 (2)三、合作模式 (3)四、供应商入驻资质要求 (4)五、关键服务流程 (4)1.商品收货入库、上架 (4)2.仓储服务 (5)3.订单处理服务 (6)4.费用结算 (6)六、服务流程标准 (6)1.收货及时率 (6)2.发货准确性 (7)3.发货及时性 (7)4.库存准确性 (7)七、资源配置标准 (8)1.配送中心硬件设施 (8)2.IT系统设备 (8)3.作业人员配置 (9)4.作业能力冗余 (9)八、IT系统标准 (9)九、责任保障 (11)1.仓储服务供应商管理责任; (11)2.灾害等不可抗力风险; (11)3.重大经营风险与道德风险; (11)一、前言在当前淘宝网为代表的电子商务蓬勃发展的大环境下,中小网商迅速成长,传统线下品牌纷纷进军电子商务。
原本直接由快递接轨电子商务的模式已经无法满足现今网商的需求,他们需要多元化的物流服务,包括仓储,订单执行,快递一体化的服务,或者由此衍生出更多个性化的,模块化的服务需求。
淘宝网作为第三方的交易平台,本着为网商们创造更好的交易环境,为买家提供更好的购买体验的宗旨,联合各仓储服务供应商共同打造配送中心物流服务。
通过本文的说明,让大家了解配送中心物流服务的概况和要求,以便我们的合作达到双方预期的效果。
二、业务模式淘宝网的配送中心物流服务是由淘宝(中国)软件有限公司(以下简称“淘宝”)、仓储服务供应商联合向用户提供的仓储物流服务及(或)附随的仓储物流的技术、中介服务。
配送中心物流服务是配送中心物流服务平台的重要组成部分。
它是由仓储服务供应商提供仓储设施及人员配置,通过淘宝网的系统对接,完成对淘宝网的个体/企业卖家客户(以下简称卖家)订单信息流转并完成从商品收货入库到根据订单发货的全过程服务。
卖家能通过该服务解决其商品在全国各地的库存分布、仓储管理、满足订单的分拣/配货/打包、发货、从仓库到买家的终端配送、包装材料、IT管理系统等一系物流相关问题。