自组织神经网络SOM
- 格式:pptx
- 大小:979.86 KB
- 文档页数:44


数据分类是一种重要的数据分析技术,其目的是根据数据的特征和属性,将其划分为不同的类别或组群,以便更好地理解和利用这些数据。
数据分类在各个领域都有广泛的应用,如商业、医疗、金融、科研等。
一、数据分类的目的1. 数据理解和组织:通过数据分类,人们可以更好地理解数据的内在结构和关系,将数据组织成有序的形式,方便后续的数据分析和处理。
2. 数据挖掘和预测:通过对历史数据进行分类,可以发现数据中的模式和趋势,为未来的数据分析和预测提供依据。
数据分类有助于识别数据的特征和规律,从而进行更深入的数据挖掘。
3. 决策支持:数据分类可以为决策提供有力支持。
通过对数据进行分类,可以识别出不同类别的数据特征和属性,为决策者提供有价值的参考信息。
4. 提高数据处理效率:通过对数据进行分类,可以针对不同类别的数据采用不同的处理方法,从而提高数据处理的效率和准确性。
二、数据分类的方法数据分类的方法主要分为监督学习和非监督学习两类。
监督学习是指在数据分类前已经知道数据的标签或类别,而非监督学习则是在没有先验知识的情况下,根据数据之间的相似性和关联性进行分类。
1. 监督学习方法:(1)决策树分类:决策树是一种常用的监督学习分类方法。
它通过构建一棵决策树,将数据按照不同的特征和属性进行划分,从而达到分类的目的。
决策树分类方法简单易懂,可视化效果好,但在处理高维度和大规模数据时可能会受到限制。
(2)支持向量机(SVM):SVM 是一种基于统计学习理论的分类方法。
它通过寻找一个最优超平面,将数据划分为不同的类别。
SVM 在处理高维度和非线性数据时表现出色,且具有较好的泛化能力。
(3)神经网络:神经网络是一种模仿生物神经元结构和功能的信息处理技术。
通过多层的神经网络模型对数据进行逐层的学习和训练,最终实现数据的分类。
神经网络具有强大的学习能力和复杂的模式识别能力,在处理复杂数据分类问题上具有很好的性能。
(4)K近邻(KNN):KNN 是一种基于实例的学习算法。

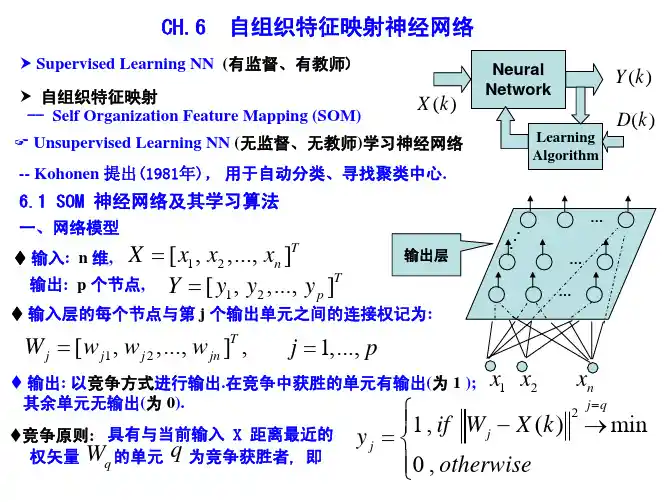
第4章 SOM自组织特征映射神经网络生物学研究表明,在人脑的感觉通道上,神经元的组织原理是有序排列的。
当外界的特定时空信息输入时,大脑皮层的特定区域兴奋,而且类似的外界信息在对应的区域是连续映像的。
生物视网膜中有许多特定的细胞对特定的图形比较敏感,当视网膜中有若干个接收单元同时受特定模式刺激时,就使大脑皮层中的特定神经元开始兴奋,输入模式接近,与之对应的兴奋神经元也接近;在听觉通道上,神经元在结构排列上与频率的关系十分密切,对于某个频率,特定的神经元具有最大的响应,位置相邻的神经元具有相近的频率特征,而远离的神经元具有的频率特征差别也较大。
大脑皮层中神经元的这种响应特点不是先天安排好的,而是通过后天的学习自组织形成的。
据此芬兰Helsinki大学的Kohonen T.教授提出了一种自组织特征映射网络(Self-organizing feature Map,SOM),又称Kohonen网络[1-5]。
Kohonen认为,一个神经网络接受外界输入模式时,将会分为不同的对应区域,各区域对输入模式有不同的响应特征,而这个过程是自动完成的。
SOM网络正是根据这一看法提出的,其特点与人脑的自组织特性相类似。
4.1 竞争学习算法基础[6]4.1.1 自组织神经网络结构1.定义自组织神经网络是无导师学习网络。
它通过自动寻找样本中的内在规律和本质属性,自组织、自适应地改变网络参数与结构。
2.结构层次型结构,具有竞争层。
典型结构:输入层+竞争层。
如图4-1所示。
竞争层图4-1 自组织神经网络结构输入层:接受外界信息,将输入模式向竞争层传递,起“观察”作用。
竞争层:负责对输入模式进行“分析比较”,寻找规律,并归类。
4.1.2 自组织神经网络的原理1.分类与输入模式的相似性分类是在类别知识等导师信号的指导下,将待识别的输入模式分配到各自的模式类中,无导师指导的分类称为聚类,聚类的目的是将相似的模式样本划归一类,而将不相似的分离开来,实现模式样本的类内相似性和类间分离性。


![[医学]自组织神经网络(SOM)方法及其应用](https://uimg.taocdn.com/94ede3855022aaea998f0fb3.webp)



自组织映射(SOM)也被称作Kohonen网络,它是非监督的、竞争学习的聚类网络,在其中一次仅有一个神经元(或一组中仅有一个神经元)“激活”。
自组织映射是模仿在大脑中发生的某些映射的人工系统。
这类自组织神经网络的基本思想是(从原始事件空间)输入被自适应单元的简单网络接受。
信号表示以一种使得响应保持原始事件相同的拓扑排序的方式(自动)映射为一系列输出。
因此,网络能获得可观察时间属性的正确拓扑映射的自动形成。
换言之,自组织映射以拓扑有序的方式将(任意维)输入模式变换为一维或二维的特征映射。
例如,当某类模式输入时,其输出层某一节点得到最大刺激而获胜,获胜节点周围的一些节点因侧向作用也受到较大刺激。
这时网络进行一次学习操作,获胜节点及其周围节点的连接权矢量向输入模式的方向作相应的修正。
当输入模式类别发生变化时,二维平面上的获胜节点也从原来节点转移到其它节点。
这样,网络通过自组织方式用大量训练样本数据来调整网络的连接权值,最后使得网络输出层特征图能够反映样本数据的分布情况。
自组织映射的缺点主要有:
(1)因为要将输入数据映射到一个低维、规则的数据网格上,因此数据网格的大小是已知的;
(2)神经网络只有一层,无法体现数据本身的层次结构;
(3)输入数据较少时,训练的结果通常依赖于样本的输入顺序,并且训练中有些神经元始终不能获胜并最终成为“死神经元”;
(4)应用于矢量量化具有收敛速度慢、计算量大的缺点;
(5)网络连接权的初始状态、神经元个数等参数选择对网络的收敛性和分类效果有较大影响。

自组织映射神经网络(SOM)降尺度方法对江淮流域逐日降水量的模拟评估周璞;江志红【摘要】利用1961~2002年ERA-40逐日再分析资料和江淮流域56个台站逐日观测降水量资料,引入基于自组织映射神经网络(Self-Organizing Maps,简称SOM)的统计降尺度方法,对江淮流域夏季(6~8月)逐日降水量进行统计建模与验证,以考察SOM对中国东部季风降水和极端降水的统计降尺度模拟能力.结果表明,SOM通过建立主要天气型与局地降水的条件转换关系,能够再现与观测一致的日降水量概率分布特征,所有台站基于概率分布函数的Brier评分(Brier Score)均近似为0,显著性评分(Significance Score)全部在0.8以上;模拟的多年平均降水日数、中雨日数、夏季总降水量、日降水强度、极端降水阈值和极端降水贡献率区域平均的偏差都低于11%;并且能够在一定程度上模拟出江淮流域夏季降水的时间变率.进一步将SOM降尺度模型应用到BCC-CSM 1.1(m)模式当前气候情景下,评估其对耦合模式模拟结果的改善能力.发现降尺度显著改善了模式对极端降水模拟偏弱的缺陷,对不同降水指数的模拟较BCC-CSM1.1(m)模式显著提高,降尺度后所有台站6个降水指数的相对误差百分率基本在20%以内,偏差比降尺度前减小了40%~60%;降尺度后6个降水指数气候场的空间相关系数提高到0.9,相对标准差均接近1.0,并且均方根误差在0.5以下.表明SOM降尺度方法显著提高日降水概率分布,特别是概率分布曲线尾部特征的模拟能力,极大改善了模式对极端降水场的模拟能力,为提高未来预估能力提供了基础.【期刊名称】《气候与环境研究》【年(卷),期】2016(021)005【总页数】13页(P512-524)【关键词】统计降尺度;SOM(Self-Organizing Maps);江淮流域;极端降水【作者】周璞;江志红【作者单位】南京信息工程大学气象灾害教育部重点实验室/气候与环境变化国际联合实验室/气象灾害预报预警与评估协同创新中心,南京210044;南京信息工程大学气象灾害教育部重点实验室/气候与环境变化国际联合实验室/气象灾害预报预警与评估协同创新中心,南京210044【正文语种】中文【中图分类】P468周璞,江志红. 2016. 自组织映射神经网络(SOM)降尺度方法对江淮流域逐日降水量的模拟评估[J]. 气候与环境研究,21 (5): 512-524. Zhou Pu,Jiang Zhihong. 2016. Simulation and evaluation of statistical downscaling of regional daily precipitation over Yangtze-Huaihe River basin based on self-organizing maps [J]. Climatic and Environmental Research (in Chinese),21 (5): 512-524,doi:10.3878/j.issn.1006-9585.2016.16097.在全球变暖背景下,地表蒸发加剧,全球和区域水循环加剧,造成极端降水事件增多(Trenberth,1998; Trenberth et al.,2003)。
基于SOM神经网络的教学认知诊断模型研究1. 内容概括本论文深入探讨了基于自组织映射(SOM)神经网络的教学认知诊断模型的研究。
SOM作为一种无监督学习方法,擅长从高维数据中提取关键特征,并将数据组织成拓扑结构相似的聚类。
在教学领域,这种能力使得SOM能够有效揭示学生的学习模式、识别知识盲点,并为个性化教学提供有力支持。
认知诊断旨在评估学生的学习状态和理解程度,是教学过程中的重要环节。
传统诊断方法往往依赖于教师的主观判断,缺乏客观性和全面性。
本研究引入SOM神经网络,构建了一个自动化、高效的诊断系统。
论文首先介绍了SOM神经网络的基本原理和教学应用现状,阐述了其在教学认知诊断中的潜力和价值。
通过理论分析和实证研究,详细探讨了模型的构建过程、学习算法以及优化策略。
实证研究部分,选取了某小学的数学课程作为研究对象,收集了学生的课堂表现、作业成绩等数据,并运用SOM神经网络进行了诊断分析。
研究结果表明,基于SOM神经网络的教学认知诊断模型能够准确识别学生的学习水平、掌握程度和知识盲点,为教师提供了有针对性的教学建议。
该模型还具有操作简便、成本低廉等优点,有望在教育领域得到广泛应用。
论文总结了研究成果,指出了研究的局限性和未来研究方向。
随着人工智能技术的不断发展和教育信息化的深入推进,基于SOM神经网络的智能诊断系统将在教育评价和教学指导方面发挥更加重要的作用。
1.1 研究背景在21世纪的教育领域,教学方法和手段的创新成为了教育改革的核心。
随着信息技术的发展,计算机科学与人工智能技术逐渐渗透到各个学科领域,为教育带来了新的机遇。
自组织映射(SOM)神经网络作为一种强大的学习工具,已经在图像识别、语音识别等领域取得了显著的成果。
研究者们开始将SOM神经网络应用于教育领域,以期提高教学质量和效果。
教学认知诊断模型是一种通过对学生学习过程中产生的数据进行分析,从而对学生的认知过程进行评估和优化的教学辅助工具。
SOM自组织映射1 定义无监督系统是基于竞争性学习,其中输出神经元之间竞争激活,结果是在任意时间只有一个神经元被激活。
这个激活的神经元被称为胜者神经元(winner-takes-all neuron)。
这种竞争可以通过在神经元之间具有横向抑制连接(负反馈路径)来实现。
其结果是神经元被迫对自身进行重新组合,这样的网络我们称之为自组织映射(Self-Organizing Map,SOM)。
2 有关拓扑映射神经生物学研究表明,不同的感觉输入(运动,视觉,听觉等)以有序的方式映射到大脑皮层的相应区域。
这种映射我们称之为拓扑映射,它具有两个重要特性:1、在表示或处理的每个阶段,每一条传入的信息都保存在适当的上下文(相邻节点)中2、处理密切相关的信息的神经元之间保持密切,以便它们可以通过短突触连接进行交互,以神经生物学激励的方式通过自组织进行学习。
3 建立自组织映射SOM的主要目标是将任意维度的输入信号模式转换为一维或二维离散映射,并以拓扑有序的方式自适应地执行这种变换。
从这里的描述感觉这是超越了PCA的极限降维。
只不过需要满足的限定条件比较多。
在竞争性学习过程中,神经元有选择性地微调来适应各种输入模式(刺激)或输入模式类别。
如此调整的神经元(特指获胜神经元),使得这部分获胜神经元顺序变得有序,并且在该网格上创建对于输入特征有意义的坐标系。
因此,SOM形成输入模式所需的拓扑映射。
我们可以将其视为主成分分析(PCA)的非线性推广。
3.1映射的组织结构输入空间中的点x映射到输出空间中的点I(x),如图所示本质上是一种只有输入层--隐藏层的神经网络。
隐藏层中的一个节点代表一个需要聚成的类。
训练时采用“竞争学习”的方式,每个输入的样例在隐藏层中找到一个和它最匹配的节点,称为它的激活节点,也叫“winning neuron”。
紧接着用随机梯度下降法更新激活节点的参数。
同时,和激活节点临近的点也根据它们距离激活节点的远近而适当地更新参数。
自组织映射(self-organizing feature mapping)自组织神经网络SOM(self-organization mapping net)是基于无监督学习方法的神经网络的一种重要类型。
自组织映射网络理论最早是由芬兰赫尔辛基理工大学Kohen于1981年提出的。
此后,伴随着神经网络在20世纪80年代中后期的迅速发展,自组织映射理论及其应用也有了长足的进步。
它是一种无指导的聚类方法。
它模拟人脑中处于不同区域的神经细胞分工不同的特点,即不同区域具有不同的响应特征,而且这一过程是自动完成的。
自组织映射网络通过寻找最优参考矢量集合来对输入模式集合进行分类。
每个参考矢量为一输出单元对应的连接权向量。
与传统的模式聚类方法相比,它所形成的聚类中心能映射到一个曲面或平面上,而保持拓扑结构不变。
对于未知聚类中心的判别问题可以用自组织映射来实现。
[1]自组织神经网络是神经网络最富有魅力的研究领域之一,它能够通过其输入样本学会检测其规律性和输入样本相互之间的关系,并且根据这些输入样本的信息自适应调整网络,使网络以后的响应与输入样本相适应。
竞争型神经网络的神经元通过输入信息能够识别成组的相似输入向量;自组织映射神经网络通过学习同样能够识别成组的相似输入向量,使那些网络层中彼此靠得很近的神经元对相似的输入向量产生响应。
与竞争型神经网络不同的是,自组织映射神经网络不但能学习输入向量的分布情况,还可以学习输入向量的拓扑结构,其单个神经元对模式分类不起决定性作用,而要靠多个神经元的协同作用才能完成模式分类。
学习向量量化LVQ(learning vector quantization)是一种用于训练竞争层的有监督学习(supervised learning)方法。
竞争层神经网络可以自动学习对输入向量模式的分类,但是竞争层进行的分类只取决于输入向量之间的距离,当两个输入向量非常接近时,竞争层就可能把它们归为一类。