SPSS操作与数值变量统计描述
- 格式:ppt
- 大小:80.50 KB
- 文档页数:23



3⃞统计目标:实用为主⃞心法口诀:变量选方法、设计看类型、目的定乾坤3.1变量就是观察单位的某项特征,简单点就是我们研究的指标。
变量可分为:数值变量、名义变量和等级变量,每种变量的属性和特征都是不同的,所采用的统计分析方法也不同。
(1)数值变量(连续变量、计量变量)测大小。
采用定量的方法测得其数值的大小。
如,身高、体重。
(2)等级变量(顺序变量)比高低。
从变量取值可见,可以比较出程度的关系。
如,年级、职称。
(3)名义变量(反映不同的属性和类别,无高低大小之分)数数目。
受试对象按照属性分类后,对不同组进行数一数计数就可以了。
如,性别、生源地。
注:一般来说,心理测量时在顺序量表上进行的,因为对于人的智力、性格、兴趣、态度等来说,绝对零点是难以确定的,而且,在心理测量中,相等单位也是很难获得的。
不过,利用某种统计方法,可以把顺序量表得到的数据换算为等距数据来进行统计。
变量类型是每类分析方法的基石,区分好变量类型,便可找到合适的分析方法。
了解基本统计名词概念,可有助于理解分析结果指标意义。
例如,后面我们要提到的差异检验,主要包括T 检验、单因素方差分析和卡方检验。
三种检验对变量类型的要求是不一样的,T 检验和单因素方差分析适用于检验分类数据和连续数据之间的差异(T 检验要求分类数据仅有两个水平,单因素方差分析要求有三个或三个以上水平),而卡方检验适用于分类数据与分类数据之间的差异。
图3- 1注:这里的分类变量特指名义变量(计数变量)。
根据数据所反映的测量水平,可以将数据分为称名数据、顺序数据、等距数据和等比数据。
四种数据的特点如下:(一)称名数据(名义变量)又称名义数据,按事物的某种属性对其进行平行的分类或分组。
(只能测度事物之间的类别差,其他差别无法得知)例如,按照性别将人口分为男、女两类,按肤色分为白种人、黄种人、棕种人、黑种人四类,按洲别分为亚洲人、欧洲人、美洲人、非洲人、澳洲人五类。
(二)顺序数据(顺序变量、等级变量)又称等级数据,是对事物之间等级差别和顺序差别的一种测度。



spss语法总结归纳SPSS(Statistical Package for the Social Sciences)是一种常用的统计分析软件,被广泛应用于社会科学领域的数据处理和分析中。
SPSS语法是一种命令式的语言,通过编写语法脚本来完成各种数据处理和统计分析任务。
本文将对SPSS语法进行总结归纳,帮助读者更好地掌握SPSS语法的基本使用方法。
一、数据导入与整理在开始进行数据处理和分析前,需要将原始数据导入SPSS软件,并进行必要的整理和清洗。
1. 数据导入使用"GET DATA"命令可以导入各种数据格式的文件,如Excel、CSV等。
可以指定文件路径和名称,也可以通过对话框选择文件。
导入后的数据将被自动命名为默认的数据集名称。
2. 变量定义在导入数据后,需要对变量进行定义和设置。
使用"VARIABLES"命令可以完成变量定义。
可以指定变量名称、变量类型(如数值型、字符型等)、缺失值定义等信息。
3. 数据整理对于数据集中的无效数据或缺失值,可以使用SPSS语法进行处理。
例如,可以使用"SELECT IF"命令根据某个变量的条件进行数据筛选;使用"RECODE"命令对变量进行重编码;使用"COMPUTE"命令计算新的变量等。
二、数据分析与统计SPSS语法有丰富的统计分析功能,下面将介绍常用的一些统计分析命令。
1. 描述统计描述统计是对数据进行概括和总结的方法。
使用"DESCRIPTIVES"命令可以计算变量的均值、标准差、最小值、最大值等统计量;使用"FREQUENCIES"命令可以计算变量的频数和频率分布。
2. 参数检验参数检验是对样本数据与总体进行比较的方法,主要用于推断性统计分析。
使用"T-TEST"命令可以进行两组样本均值的差异检验;使用"ONEWAY"命令可以进行多组样本均值的差异检验。
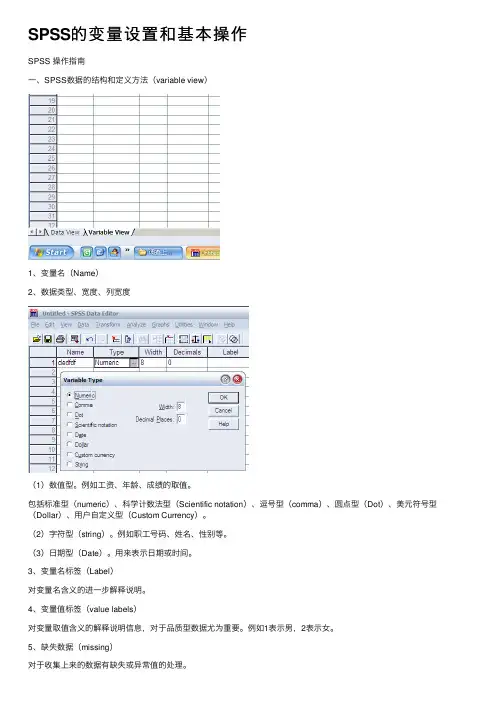
SPSS的变量设置和基本操作SPSS 操作指南⼀、SPSS数据的结构和定义⽅法(variable view)1、变量名(Name)2、数据类型、宽度、列宽度(1)数值型。
例如⼯资、年龄、成绩的取值。
包括标准型(numeric)、科学计数法型(Scientific notation)、逗号型(comma)、圆点型(Dot)、美元符号型(Dollar)、⽤户⾃定义型(Custom Currency)。
(2)字符型(string)。
例如职⼯号码、姓名、性别等。
(3)⽇期型(Date)。
⽤来表⽰⽇期或时间。
3、变量名标签(Label)对变量名含义的进⼀步解释说明。
4、变量值标签(value labels)对变量取值含义的解释说明信息,对于品质型数据尤为重要。
例如1表⽰男,2表⽰⼥。
5、缺失数据(missing)对于收集上来的数据有缺失或异常值的处理。
字符型变量或数值型变量,可以是1⾄3个特定的离散值(discrete missingvalues)数值型变量,哟过户缺失值可以在⼀个连续的闭区间内并同时再附加⼀个区间以外的离散值(Range plus one optional discrete)6、度量尺度(measure)定距型数据(Scale),通常是指诸如⾝⾼、体重、收⼊等的连续型数据。
也包括诸如⼈数、商品件数等离散型数据。
包括了等距量表和等⽐量表。
定序型数据(ordinal)具有内在的固有⼤⼩或⾼低顺序,不同于定距型数据,⼀般可以⽤数值或字符表⽰。
如职称变量可以有低级、中级、⾼级三个取值,可以分别为1、2和3表⽰。
定类型数据(norminal)没有内在固有⼤⼩或⾼低顺序,⼀般以数值或字符表⽰的分类数据。
如性别、民族等。
操作:仔细看看居民储蓄的数据,理解数据结构的含义。
⼆、分类汇总的操作界⾯调整⾄左下⾓的data view。
1、分类汇总按照某分类进⾏分类汇总计算。
例如想知道不同户⼝的居民取款⾦额是否较⼤差距。


在教育技术研究过程中收集到大量的资料数据,但从这些杂乱无章的资料中,很难对其总体水平与分布状况做出评价判断。
因此,必须采用一些适当的方法对这些资料进行处理,使之简约化、分类化、系统化,从中发现它们的分布规律,掌握总体的特征,以便对其水平做出客观的评价。
统计描述方法,是研究简缩数据并描述这些数据的统计方法。
将搜集来的大量数据资料,加以整理、归纳和分组,简缩成易于处理和便于理解的形式,并计算所得数据的各种统计量,如平均数、标准差、以及描述有关事物或现象的分布情况、波动范围和相关程度等,以揭示其特点和规律。
(一)数据资料的整理和表示在教育技术研究中,我们用各种方法搜集来的资料,一般是零散的,它只反映个别现象的个别特征,必须经过整理加工,使之系统化,才能计算统计指标,进行统计分析,为进一步研究提供有用的信息,首先要进行的是统计整理,它包含以下几部分内容:1.数据检查主要检查数据的完整性与正确性。
统计资料完整性的检查,就是要根据调查项目检查是否填写齐全,避免遗漏,删去重复。
正确性检查,就是检查搜集的资料是否真实可靠。
特别是统计数字的真实性是统计工作的生命,统计资料的检查整理必须抓紧这一环。
数据检查可分为逻辑检查和计算检查两种方法。
逻辑检查,是从理论和一般常识上来检查资料内容是否合理,指标之间是否矛盾。
计算检查是检查统计数字在计算方法和计算结果上有否错误。
2.数据分类数据分类就是把搜集来的数据进行分组归类。
数据分类要做到既不重复、不遗漏,又不混淆,一般又可分为品质分类和数量分类。
品质分类:是按事物性质划分为不同的组别、种类。
如以性别为标志可分为男与女;按“理解能力”、“学习态度”等为标志,又可分为好、较好、一般、差等几种水平,每种水平可看成类,每一类可给以相当的数量。
可以通过各类所包含的数据再进行数量化的比较和分析。
数量分类:是按数量的属性分类。
有顺序排列法、等级排列法和次数分布法等。
⒊数据的排序数据排序:将各数据从大到小或从小到大进行排列。

在SPSS 中进行实验一的基本统计方法包括描述统计和推论统计两个方面。
描述统计用于对实验数据的整体特征进行描述,而推论统计则用于对样本数据进行推断,从而得出总体的结论。
以下是在SPSS 中进行实验一时常用的基本统计方法:描述统计:1. 均值(Mean):计算数据的平均值,反映数据的集中趋势。
2. 标准差(Standard Deviation):衡量数据的离散程度。
3. 频数统计(Frequencies):统计分类变量的频数分布。
4. 中位数(Median):数据的中间值,不受极端值影响。
5. 最大最小值(Minimum, Maximum):显示数据的最大值和最小值。
6. 百分位数(Percentiles):显示数据的分位数,如四分位数等。
推论统计:1. 相关分析(Correlation):分析两个连续变量之间的关系。
2. t检验(Independent Samples T-Test, Paired Samples T-Test):比较两组样本均值是否存在显著差异。
3. 方差分析(ANOVA):比较两个或多个组之间均值是否存在显著差异。
4. 卡方检验(Chi-Square Test):用于比较分类变量之间的关联性。
5. 线性回归(Linear Regression):分析自变量和因变量之间的线性关系。
6. 非参数检验(Mann-Whitney U Test, Kruskal-Wallis Test):适用于非正态分布数据或秩次数据的假设检验。
以上是在SPSS 中常用的实验一基本统计方法,通过这些方法可以对实验数据进行全面的描述和分析,从而得出科学、客观的结论。
在使用这些方法时,需要根据实际情况选择合适的统计方法,并正确解读结果。

SPSS描述性统计分析SPSS是一种常用的统计分析软件,可以进行各种描述性统计分析。
描述性统计分析是对数据进行整体性的描述和总结,从中提取出关键的统计指标,包括数据的中心趋势、离散程度、分布形态和相关性等。
首先,数据的中心趋势是统计数据中心部分分布位置的指标。
常见的中心趋势统计指标有均值、中位数和众数等。
均值是将所有数据相加后除以总数,可以反映数据的平均水平;中位数是将数据按大小排列后处于中间位置的数,可以反映数据的中间位置;众数是数据中出现最频繁的数值,可以反映数据的集中趋势。
其次,数据的离散程度是统计数据分布的分散程度的指标。
常见的离散程度统计指标有标准差、方差和极差等。
标准差衡量数据与平均值的离散程度,数值越大表示数据越分散;方差是标准差的平方,也可以用于衡量数据的离散程度;极差是最大值与最小值之间的差异,可以反映数据的全局差异。
此外,还可以对数据的分布形态进行分析,以了解数据分布的形状。
常见的分布形态统计指标有偏度和峰度。
偏度反映数据分布的对称性,偏度为正表示数据右偏,为负表示左偏;峰度衡量数据分布的尖锐程度,峰度为正表示数据分布较为陡峭,为负表示较为平缓。
最后,还可以进行变量的相关性分析,以了解变量之间的相关关系。
常见的相关性统计指标有皮尔逊相关系数和斯皮尔曼等级相关系数。
皮尔逊相关系数是衡量变量之间线性相关关系的指标,取值范围为-1到1,数值越接近于1或-1表示相关性越强;斯皮尔曼等级相关系数则可以反映变量之间的单调相关关系,适用于非线性关系的变量。
在SPSS中进行描述性统计分析非常简单。
首先,打开SPSS软件并导入数据文件。
然后,在"分析(Analyze)"菜单中选择"描述性统计(Descriptive Statistics)",再选择"统计量(Descriptives)"。
在该对话框中,选择要进行统计分析的变量,并选择所需的统计指标,最后点击"确定"按钮即可。
SPSS的变量设置和基本操作SPSS(Statistical Package for the Social Sciences)是一款常用的统计分析软件,可帮助研究者在社会科学领域进行数据分析。
在使用SPSS进行分析之前,需要对变量进行设置和进行一些基本操作。
本文将介绍SPSS的变量设置和基本操作。
一、变量设置在使用SPSS之前,必须先进行变量设置,包括变量属性和数据类型的定义。
变量属性可以是数值型、字符型或日期型;数据类型可以是连续型、离散型或自定义型。
以下是一些常见的变量设置步骤:1. 打开SPSS软件并新建数据文件(Data Editor)。
2. 在数据文件中选择“变量视图”(Variable View),可以看到一个表格,每一行代表一个变量。
3.在第一列输入变量名。
变量名应具有描述性且易于理解。
4. 在第二列选择变量类型。
可以选择数值型(Numeric)、字符型(String)或日期型(Date)。
5. 在第三列选择变量宽度(Width),即变量所占的字符数或数字位数。
根据实际需要进行设置。
6. 在第四列选择小数位数(Decimals)。
对于数值型变量,可以设置其精度。
二、变量操作除了变量设置之外,还需要进行一些基本的变量操作,如变量输入、导入、导出、修改和删除等。
以下是一些常见的变量操作步骤:2. 变量导入:可以将数据从其他文件导入到SPSS中进行分析。
选择“文件”(File)→“打开”(Open),然后选择需要导入的数据文件。
3. 变量导出:可以将分析结果导出到其他文件格式中,如Excel、CSV等。
选择“文件”→“导出”→“数据”(Export)。
5. 变量删除:可以删除不需要的变量。
选择相应的变量列,右键点击,并选择“删除”(Delete)。
三、变量操作技巧除了基本的变量设置和操作之外,还有一些变量操作的技巧可以提高效率和准确性。
2. 变量筛选:对于大量变量的数据文件,可以使用变量筛选功能,只显示需要的变量。
描述统计及数据个案加权1.个案加权及描述统计分析个案加权:常出现在实验、医学类。
对观测量进行加权,体现出该数值不是数而是个案数。
描述统计分析:主要用来对连续变量做描述性分析,可以输出很多类型的统计量。
一般展示:个案数、最小值、最大值、平均值、标准差、偏度和峰度。
平均数:也称为均值,是一组数据相加后除以数据的个数的结果。
标准差:方差的平方根。
方差:是各个变量值与其平均数离差平方的平均数。
偏度:对数据分布对称性的测量。
峰度:对数据分布平峰或者尖峰程度的测量。
图1描述统计在spss软件中勾选情况2.描述统计第一步,将数据导入spss软件后点击分析、描述统计、描述。
图2描述统计分析步骤一第二步,将对应变量放入对应变量框中,点击选项勾选分布里的偏度和峰度。
图3描述统计分析第二步然后描述统计的结果就出来了。
图4描述统计结果展示将结果粘贴复制到Excel表格中进行整理,后将整理好的结果粘贴复制到Word文档中进行表格的制作和文字描述。
图5描述统计结果整理3.个案加权个案加权:如果说数据为总合结果数据时,如图6所示,这样情况下还需进行数据分析就应进行个案加权操作。
图6数据形式第一步、点击数据、个案加权。
图7个案加权步骤一第二步、图中人数为个案数因此需要对人数进行加权处理,将人数放入频率变量框中点击确定,出现图中下方语法表明个案加权成功,可以进行接下的数据分析了。
图8个案加权第二步4.多重响应分析第一步、首先需要定义变量集,点击分析、多重响应、定义变量集。
图9多重响应分析第一步第二步、进入下方对话框后、将多选题选项题项放入集合中的变量框中、后在二分法后的值里填入1,定义好变量名称。
图10多重响应分析第二步第三步、定义完成后就可以进行多重响应分析:点击分析、多重响应、频率。
图11多重响应分析第三步进入图中对话框后将定义好的变量放入点击确定图12多重响应分析第四步然后多重响应分析的结果就出来了图13多重响应分析结果将结果粘贴赋值到Excel表格中进行整理,后将整理好的结果粘贴到Word 文档中进行表格的制作和文字解释。
均值(平均值、平均数):表示的是某变量所有取值的集中趋势或平均水平。
例如,学生某门学科的平均成绩、公司员工的平均收入、某班级学生的平均身高等。
计算公式如下。
中位数:定义:把一组数据按递增或递减的顺序排列,处于中间位置上的变量值就是中位数。
它是一种位置代表值,所以不会受到极端数值的影响,具有较高的稳健性计算公式:一个大小为的数列,要求其中位数,首先应把该数列按大小顺序排列好,如果为奇数,那么该数列的中位数就是位置上的数;如果N为偶数,中位数则是该数列中第与第+1位置上两个数值的平均数众数:定义:众数是指一组数据中,出现次数最多的那个变量值。
众数在描述数据集中趋势方面有一定的意义。
例如,制鞋厂可以根据消费者所需鞋的尺码的众数来安排生产。
计算公式:手工计算众数比较麻烦,需要统计数据的次数分布。
全距:定义:全距也称为极差,是数据的最大值与最小值之间的绝对差。
在相同样本容量情况下的两组数据,全距大的一组数据要比全距小的一组数据更为分散。
计算公式:最大值-最小值。
方差(Variance)和标准差(Standard Deviation):定义:方差是所有变量值与平均数偏差平方的平均值,它表示了一组数据分布的离散程度的平均值。
标准差是方差的平方根,它表示了一组数据关于平均数的平均离散程度。
方差和标准差越大,说明变量值之间的差异越大,距离平均数这个“中心”的离散趋势越大。
频数(Frequency):定义:频数就是一个变量在各个变量值上取值的个案数。
如要了解学生某次考试的成绩情况,需要计算出学生所有分数取值,以及每个分数取值有多少个人,这就需要用到频数分析。
变量的频数分析正是实现上述分析的最好手段,它可以使人们非常清楚地了解变量取值的分布情况。
峰度(Kurtosis):定义:峰度是描述某变量所有取值分布形态陡缓程度的统计量。
这个统计量是与正态分布相比较的量,峰度为0表示其数据分布与正态分布的陡缓程度相同;峰度大于0表示比正态分布高峰要更加陡峭,为尖顶峰;峰度小于0表示比正态分布平顶峰。
SPSS描述性分析统计操作步骤SPSS是一个非常强大的数据处理和统计分析软件,它广泛应用于社会科学、医学、生物、商业等领域。
描述性分析是SPSS中常用的数据分析方法之一,具体涉及的操作步骤可以分为如下几个部分:一、数据录入和数据检查在运行SPSS前,需要先进行数据录入,将现场采集的数据输入到计算机中。
在录入数据之后,需要对数据进行检查,确认数据的完整性、正确性和一致性。
具体包括以下几个方面:1.检查数据是否按照规定的格式录入,比如数值型数据是否为数字,字符型数据是否为字符等;2.检查数据是否有重复、缺失、异常等情况,并针对这些情况进行相应处理;3.检查变量的名称、标签是否与实际意义一致,需要根据实际情况进行修改。
二、数据分布分析1.单变量分析单变量分析是指针对单个变量进行分析,主要关注该变量的基本统计信息和分布情况。
常用的描述性统计指标包括均值、中位数、众数、标准差、方差、最大值、最小值等。
如需对单个变量作更加细致的分析,可以生成直方图、箱线图、概率密度图等图形。
在SPSS 中,可以通过点和菜单或者语法来进行单变量分析。
三、数据检验1.正态性检验正态性检验是指检验变量是否符合正态分布,通常采用Kolmogorov-Smirnov检验、Shapiro-Wilk检验、Anderson-Darling检验等方法。
在SPSS中,可以通过点和菜单或者语法来进行正态性检验。
2.均值比较均值比较是指比较两个或多个组的均值是否存在显著差异,通常采用t检验和方差分析等方法。
在SPSS中,可以通过点和菜单或者语法来进行均值比较。
四、分组分析分组分析是指将数据按照某一变量进行分组,比较不同组之间的差异。
常用的分组变量包括性别、年龄、学历、职业等。
在SPSS中,可以通过点和菜单或者语法来进行分组分析。
以上就是SPSS描述性分析统计操作步骤的一些基本内容,因为需要考虑数据的来源、数据类型、研究目的等多方面的因素,所以具体操作步骤可能会有所不同。