spss-统计描述
- 格式:ppt
- 大小:467.00 KB
- 文档页数:29

统计描述符合正态分布或近似正态分布资料的统计描述统计量:(一)描述平均水平的常用统计量——算术均数(二)描述变异水平(离散程度)的常用统计量——离均差平方和(SS)、平均方差(方差:MS)、标准差(SD)(三)描述抽样误差大小的统计量——标准误(SE)。
SPSS操作:对某1变量(如time)进行统计描述:正态性检验:Analyze→nonparametric tests→1-sample K-S→调入某变量和激活Nomal→OK。
正态的统计描述:analyze→descriptive statistics→descriptives→调入某变量,点击option…→点击mean、SE、SD→OK。
分析结果:表descriptive statistics(可看N、min、max、mean、SD);Z=0.649;P=0.794>0.05.说明time服从近似正态分布。
对某一变量分组进行统计描述(如按男、女分别做time的统计描述):文件分割:data→split file;注意:计算机有记忆功能,文件分割后需要把它还原,才不会影响后续操作。
统计描述(操作同上):analyze→descriptive statistics→descriptives→调入某变量,点击option…→点击mean、SE、SD→OK。
非正态资料的统计描述统计量:(一)描述集中位置——中位数(二)描述变异水平(离散程度)——四分位数间距=P75-P25。
SPSS操作:对某1变量(红血球体积hct)进行统计描述:正态性检验(同上):Analyze→nonparametric tests→1-sample K-S→调入某变量和激活Nomal→OK。
非正态的统计描述:analyze→descriptive statistics→frequencies→调入某变量,点击statistics…→点击median和quartiles。
编制频数分布表和绘制频数分布直方图一、对数据进行重新编码(recod e)SPSS操作:统计描述:Recode:Transform→recode into different variables…(表示recode后存入新的变量名中,原始数据还在)→调入变量进入“input→output”中,在右侧output框中输入新的变量名,可label→点击change→点击框下的old and new values…→根据手工分组,确定组距后:lowest:1→range→higest:最后一组→OK。

SPSS统计分析数据特征的描述统计分析SPSS(Statistical Package for the Social Sciences)是一种常用的统计分析软件,用于对数据进行描述统计分析。
描述统计分析旨在帮助研究人员对数据进行简单的整理、描述和总结,以便更好地理解数据的特征和趋势。
下面将说明几种常用的描述统计分析方法。
1.频数统计频数统计是指对数据中各个变量的不同取值进行计数。
通过统计每个取值出现的次数,可以了解数据的分布情况和变量的特点。
SPSS提供了多种方式来进行频数统计,包括直方图、饼图等。
通过这些图表,可以清晰地看到变量的取值分布。
2.中心趋势测量中心趋势测量是描述数据集合中心位置的统计方法,常用的测量指标包括平均数、中位数和众数。
平均数是所有数据的算术平均值,中位数是将数据按大小排列后处于中间位置的数值,众数是出现次数最多的数值。
SPSS提供了计算这些测量指标的功能,以便更好地了解数据的中心位置。
3.离散程度测量离散程度测量是描述数据变异程度的方法,常用的度量指标包括标准差、方差和极差。
标准差是数据与平均数之间的平均偏差,方差是标准差的平方,表示数据的离散程度,极差是最大值与最小值之间的差异。
通过这些指标,可以判断数据的离散程度,以及是否存在异常值等问题。
4.偏度和峰度测量偏度和峰度是描述数据分布形态的指标。
偏度测量的是数据分布的偏斜程度,正偏斜表示分布右侧的极端值较多,负偏斜表示分布左侧的极端值较多。
峰度测量的是数据分布的尖峰程度,正峰度表示尖峰较高且尾巴较短,负峰度表示尖峰较低且尾巴较长。
通过偏度和峰度的测量,可以判断数据的分布形态是否符合正态分布。
5.相关分析相关分析旨在研究两个或多个变量之间的关系。
相关系数是用来衡量变量之间线性相关程度的指标,取值范围从-1到+1、接近-1的相关系数表示负相关,接近+1的相关系数表示正相关,接近0的相关系数表示无相关。
通过相关分析,可以了解不同变量之间的关系,以及它们对研究问题的影响程度。

SPSS数据分析—描述性统计分析描述性统计分析是一种针对数据本身的分析方法,通过使用统计学指标来描述数据的特征。
这种分析方法看似简单,但实际上却是许多高级分析的基础工作。
很多高级分析方法都对数据有一定的假设和适用条件,这些可以通过描述性统计分析来判断。
我们也会发现,许多分析方法的结果中都会穿插一些描述性分析的结果。
描述性统计主要关注数据的三个方面:集中趋势、离散趋势和数据分布情况。
描述集中趋势的指标包括均值、众数和中位数,其中均值包括截尾均值、几何均值和调和均值等。
描述离散趋势的指标包括频数、相对数、方差、标准差、标准误、全距、四分位间距、四分位数、百分位数和变异系数等。
需要注意的是,连续型变量和离散型变量的指标有所不同。
由于许多统计分析都有一个正态分布的假设,因此我们经常关注数据的分布特征。
常用峰度系数和偏度系数来描述数据偏离正态分布的程度。
也可以使用Bootstrap方法计算出结果与经典统计学方法计算出的结果进行对比,如果差异明显,则说明原数据呈偏态分布或存在极值。
SPSS用于描述性统计分析的过程大部分都在分析-描述统计菜单中,另有一个在比较均值-均值菜单。
虽然这几个过程用途不同,但基本上都可以输出常用的指标结果。
分析-描述统计-频率过程可以输出连续型变量集中趋势和离散趋势的主要指标,还可以输出判断分布的直方图、峰度值和偏度值。
此外,该过程最主要的作用是输出频数表。
分析-描述统计-描述过程输出的内容并不多,也没有统计图可以调用,唯一特别的是该过程可以对数据进行标准化变换,并保存为新变量。
分析-描述统计-探索过程是在原有数据进行描述性统计的基础上,更进一步的描述数据。
与前两种过程相比,它能提供更详细的结果。
分析-描述统计-比率过程主要用于对两个连续变量间的比率进行描述分析。
输出的结果比较简单,只是指标的汇总表格。
分析-描述统计-交叉表过程主要用于分类变量的描述性统计。
它可以完成频数分布和构成比的分析,也经常被用来做列联表的推断分析。


SPSS统计分析—描述性统计分析描述性统计分析(Descriptive statistics analysis)简介描述性统计分析是统计学的一个领域,主要目的是通过对样本数据进行总结、整理和分析,揭示数据中的模式、趋势和关联。
它可以通过计算和展示各种统计指标来帮助我们更好地理解和解释数据。
SPSS(Statistical Package for the Social Sciences)是一种常用的统计分析软件,可以用于进行各种描述性统计分析。
本文将介绍一些常用的描述性统计分析方法和在SPSS中的应用。
1.数据摘要数据摘要是描述性统计分析的基础,主要目的是对数据进行概括性的总结。
常用的数据摘要方法包括计数、频数、百分比、均值、中位数、标准差等。
在SPSS中,可以使用“Frequencies”命令对数据进行频数分析。
该命令可以列出每个变量的频数、百分比以及累积百分比。
此外,使用“Descriptives”命令可以计算各个变量的均值、中位数、标准差等统计量。
2.绘制图表图表可以帮助我们更好地理解和展示数据的特征和分布。
常用的图表包括直方图、饼图、箱线图等。
在SPSS中,可以使用“Graphs”菜单下的不同选项来绘制各种图表。
例如,使用“Bar Chart”选项可以绘制柱状图,使用“Pie Chart”选项可以绘制饼图,使用“Boxplot”选项可以绘制箱线图。
3.相关分析相关分析可以帮助我们研究数据之间的关联关系。
它可以通过计算相关系数来评估两个变量之间的线性关系。
在SPSS中,可以使用“Correlations”命令进行相关分析。
该命令可以计算出各个变量之间的相关系数,并提供了相关系数矩阵和散点图来展示结果。
4.因素分析因素分析是一种常用的数据降维方法,可以帮助我们理解并提取潜在的数据结构和变量之间的关系。
在SPSS中,可以使用“Factor Analysis”命令进行因素分析。
该命令可以根据指定的变量,自动提取主成分或因子,并计算出因子载荷矩阵和因子得分。

描述性统计分析是针对数据本身而言,用统计学指标描述其特征的分析方法,这种描述看似简单,实际上却是很多高级分析的基础工作,很多高级分析方法对于数据都有一定的假设和适用条件,这些都可以通过描述性统计分析加以判断,我们也会发现,很多分析方法的结果中,或多或少都会穿插一些描述性分析的结果。
描述性统计主要关注数据的三大内容:1.集中趋势2.离散趋势3.数据分布情况描述集中趋势的指标有均值、众数、中位数,其中均值包括截尾均值、几何均值、调和均值等。
描述离散趋势的指标有频数、相对数、方差、标准差、标准误、全距、四分位间距、四分位数、百分位数、变异系数等。
注意:连续型变量和离散型变量的指标有所不同。
由于很多统计分析都有一个正态分布的假设,因此我们经常也会关注数据的分布特征,常用峰度系数和偏度系数来描述数据偏离正态分布的程度,也可以使用Bootstrap方法计算出结果与经典统计学方法计算出的结果进行对比,如果差异明显,则说明原数据呈偏态分布或存在极值SPSS用于描述性统计分析的过程大部分都在分析—描述统计菜单中,另有一个在比较均值—均值菜单,虽然这几个过程用途不同,但是基本上都可以输出常用的指标结果。
一、分析—描述统计—频率此过程可以输出连续型变量集中趋势和离散趋势的主要指标,还可以输出判断分布的直方图、峰度值和偏度值,此外,该过程最主要的作用是输出频数表,结果举例如下:二、分析—描述统计—描述看起来似乎这个过程才是正统的描述统计分析过程,实际上该过程输出的内容并不多,也没有统计图可以调用,唯一特别的是该过程可以对数据进行标准化变换,并保存为新变量。
三、分析—描述统计—探索探索性分析是对原有数据进行描述性统计的基础上,更进一步的描述数据,和前两种过程相比,它能提供更详细的结果。
四、分析—描述统计—比率该过程主要用于对两个连续变量间的比率进行描述分析输出的结果比较简单,只是指标的汇总表格,在此略去五、分析—描述统计—交叉表分类变量的描述性统计比较简单,主要就是看频数分布和构成比,基本用交叉表一个过程就可以完成,该过程虽然放在描述统计中,但是由于功能丰富,也经常被用来做列联表的推断分析。

spss描述统计实验报告SPSS描述统计实验报告引言SPSS(Statistical Package for the Social Sciences)是一种用于数据分析和统计建模的软件工具。
它可以帮助研究人员对数据进行描述统计分析,从而得出结论并做出预测。
本实验旨在利用SPSS软件对实验数据进行描述统计分析,以探究数据的特征和规律。
实验设计本实验选取了一组包括性别、年龄、身高和体重等信息的样本数据,共计100个样本。
通过SPSS软件对这组数据进行描述统计分析,包括均值、标准差、频数分布等指标,以便对样本数据进行全面的了解。
结果分析首先,我们对样本数据中的性别进行了频数分布分析。
结果显示,样本中有55%的男性和45%的女性,性别分布相对均衡。
接着,我们对年龄、身高和体重等连续变量进行了均值和标准差的分析。
结果显示,样本的平均年龄为30岁,标准差为5岁;平均身高为170厘米,标准差为8厘米;平均体重为65公斤,标准差为10公斤。
这些数据表明样本中的年龄、身高和体重分布较为集中,且具有一定的变异性。
结论通过对样本数据的描述统计分析,我们得出了对样本特征和规律的初步认识。
样本中男女比例相对均衡,年龄、身高和体重分布较为集中且具有一定的变异性。
这些结果为我们进一步的数据分析和研究提供了重要参考。
总结SPSS软件作为一种强大的数据分析工具,可以帮助研究人员对数据进行描述统计分析,从而深入了解数据的特征和规律。
本实验利用SPSS对样本数据进行了描述统计分析,得出了对样本特征和规律的初步认识,为后续的研究工作奠定了基础。
希望本实验能够对SPSS软件的应用和描述统计分析方法有所启发,为相关研究工作提供参考。

第讲 SPSS 描述性统计分析1. 简介SPSS(Statistical Package for the Social Sciences)是一款功能强大的统计分析软件,在社会科学、医学和商业等领域中广泛应用。
本文将介绍 SPSS 中的描述性统计分析方法,帮助用户更好地理解和解读数据。
2. 描述性统计分析概述描述性统计分析是对数据进行和组织的过程。
它可以帮助人们更好地理解数据的特性和分布情况。
SPSS 中的描述性统计分析主要包括以下内容:2.1 中心趋势中心趋势是指数据在数轴上的中心位置。
SPSS 中常用的中心趋势指标包括:平均数、中位数和众数。
平均数是指所有数据的总和除以数据的个数。
它能够反映数据的总体水平,但会受到极端值的影响。
中位数是指数据按大小排序后位于中间位置的数值。
它能够反映数据的分布情况,不会受到极端值的影响。
众数是指出现次数最多的数值。
它能够反映数据的典型值,但在数据分布不均匀时可能不够准确。
2.2 离散程度离散程度是指数据相对于中心趋势的差异程度。
SPSS 中常用的离散程度指标包括:标准差、方差和极差。
标准差是指数据与平均数的差异程度的平均值。
它能够反映数据的分散程度,越大表示数据越分散。
方差是指数据与平均数的差异程度的平方的平均值。
它可以用来比较不同数据集的分散程度。
极差是指数据最大值和最小值之间的差异。
它不能反映数据的分布情况,但可以用来描述数据范围。
2.3 数据分布数据分布是指数据在数轴上的分布情况。
SPSS 中常用的数据分布指标包括:偏度、峰度和频数分布表。
偏度是指数据分布的不对称程度。
正偏态分布表示数据分布向左偏,负偏态分布表示数据分布向右偏。
峰度是指数据分布的峰度程度。
正态分布峰度值为 0,大于 0 表示峰度更高,小于 0 表示峰度更低,称为尖峰态和扁平态。
频数分布表是指数据中每个值出现的次数。
它可以用来了解数据的分布情况,如是否存在异常值或集中现象。
3. SPSS 描述性统计分析操作步骤SPSS 中的描述性统计分析可以通过以下步骤进行:Step 1:导入数据。


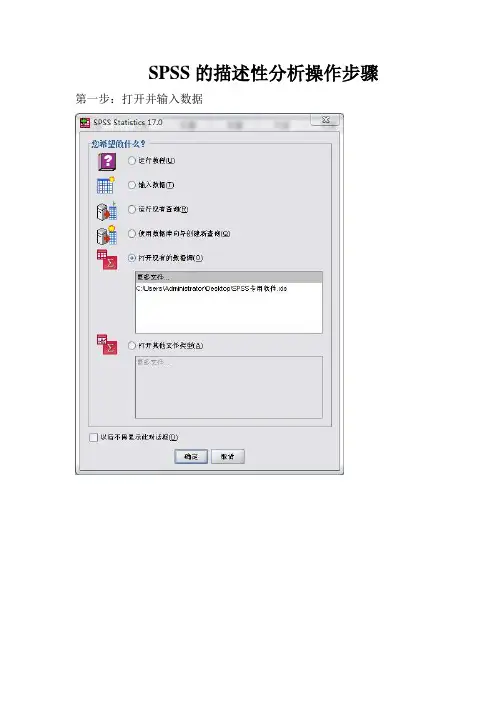
SPSS的描述性分析操作步骤第一步:打开并输入数据
SPSS的打开方式有以上几种选择“打开现有的数据库”点击确定。
结果如下图显示。
第二步:在菜单栏里选择分析—描述统计—描述如下:选择左侧栏里需要统计的变量双击到右侧变量栏里。
如下
在右上角的选项里选择你需要的统计量:如下点击继续—确定—就可以得到数据量如下图所示
单样本的T检验在选项里分析—比较均值—单样本T检验如下图所示在右上角的选项里可以选择置信区间如下
点击继续—确定就可以得到我们想要的单样本t检验
心理1203班周昱衡
20120223189
2014年6月10号。
第二节常用的数据描述统计本节拟讲述如何通过SPSS菜单或命令获得常用的统计量、频数分布表等。
1.数据这部分所用数据为第一章例1中学生成绩的数据,这里我们加入描述学生性别的变量“sex”和班级的变量“class”,前几个数据显示如下(图2-2),将数据保存到名为“2-6-1.sav”的文件中。
图2-2:数据输入格式示例1.Frequencies语句(1)操作打开数据文件“2-6-1.sav”,单击主菜单Analyze /Descriptive Statistics / F requencies…,出现频数分布表对话框如图2-3所示。
图2-3:Frequencies定义窗口把score变量从左边变量表列中选到右边,并请注意选中下方的Display frequency table复选框(要求显示频数分布表)。
如果您只要求得到一个频数分布表,那么就可以点OK按钮了。
如果您想同时获得一些统计量,及统计图表,还需要进一步设置。
①Statistics选项单击Statistics按钮,打开对话框,请按图2-4自行设置。
有关说明如下:(ⅰ)在定义百分位值(percentile value)的矩形框中,选择想要输出的各种分位数,SPSS提供的选项有:●Quartiles四分位数,即显示25%、50%、75%的百分位数。
●Cut points equal 把数据平均分为几份。
如本例中要求平均分为3份。
●Percentile显示用户指定的百分位数,可重复多次操作。
本例中要求15%、50%、85%的百分位数。
(ⅱ) 在定义输出集中趋势(Central Tendency)的矩形框中,选择想要输出的集中统计量,常用的选项有:●Mean 算术平均数●Median 中数●Mode 众数●Sum 算术和(ⅲ)在定义输出离散统计量(Dispersion)的矩形框中,选择想要输出的离散统计量,常用的选项有:●Std. Deviation 标准差●Variance 方差●Range 全距●Minimum 最小值●Maximum 最大值●S.E. mean 平均数的标准误(ⅳ)描述数据分布(Distribution)的统计量●Skewness 偏度,非对称分布指数。
SPSS描述性统计分析SPSS是一种常用的统计分析软件,可以进行各种描述性统计分析。
描述性统计分析是对数据进行整体性的描述和总结,从中提取出关键的统计指标,包括数据的中心趋势、离散程度、分布形态和相关性等。
首先,数据的中心趋势是统计数据中心部分分布位置的指标。
常见的中心趋势统计指标有均值、中位数和众数等。
均值是将所有数据相加后除以总数,可以反映数据的平均水平;中位数是将数据按大小排列后处于中间位置的数,可以反映数据的中间位置;众数是数据中出现最频繁的数值,可以反映数据的集中趋势。
其次,数据的离散程度是统计数据分布的分散程度的指标。
常见的离散程度统计指标有标准差、方差和极差等。
标准差衡量数据与平均值的离散程度,数值越大表示数据越分散;方差是标准差的平方,也可以用于衡量数据的离散程度;极差是最大值与最小值之间的差异,可以反映数据的全局差异。
此外,还可以对数据的分布形态进行分析,以了解数据分布的形状。
常见的分布形态统计指标有偏度和峰度。
偏度反映数据分布的对称性,偏度为正表示数据右偏,为负表示左偏;峰度衡量数据分布的尖锐程度,峰度为正表示数据分布较为陡峭,为负表示较为平缓。
最后,还可以进行变量的相关性分析,以了解变量之间的相关关系。
常见的相关性统计指标有皮尔逊相关系数和斯皮尔曼等级相关系数。
皮尔逊相关系数是衡量变量之间线性相关关系的指标,取值范围为-1到1,数值越接近于1或-1表示相关性越强;斯皮尔曼等级相关系数则可以反映变量之间的单调相关关系,适用于非线性关系的变量。
在SPSS中进行描述性统计分析非常简单。
首先,打开SPSS软件并导入数据文件。
然后,在"分析(Analyze)"菜单中选择"描述性统计(Descriptive Statistics)",再选择"统计量(Descriptives)"。
在该对话框中,选择要进行统计分析的变量,并选择所需的统计指标,最后点击"确定"按钮即可。
描述统计及数据个案加权1.个案加权及描述统计分析个案加权:常出现在实验、医学类。
对观测量进行加权,体现出该数值不是数而是个案数。
描述统计分析:主要用来对连续变量做描述性分析,可以输出很多类型的统计量。
一般展示:个案数、最小值、最大值、平均值、标准差、偏度和峰度。
平均数:也称为均值,是一组数据相加后除以数据的个数的结果。
标准差:方差的平方根。
方差:是各个变量值与其平均数离差平方的平均数。
偏度:对数据分布对称性的测量。
峰度:对数据分布平峰或者尖峰程度的测量。
图1描述统计在spss软件中勾选情况2.描述统计第一步,将数据导入spss软件后点击分析、描述统计、描述。
图2描述统计分析步骤一第二步,将对应变量放入对应变量框中,点击选项勾选分布里的偏度和峰度。
图3描述统计分析第二步然后描述统计的结果就出来了。
图4描述统计结果展示将结果粘贴复制到Excel表格中进行整理,后将整理好的结果粘贴复制到Word文档中进行表格的制作和文字描述。
图5描述统计结果整理3.个案加权个案加权:如果说数据为总合结果数据时,如图6所示,这样情况下还需进行数据分析就应进行个案加权操作。
图6数据形式第一步、点击数据、个案加权。
图7个案加权步骤一第二步、图中人数为个案数因此需要对人数进行加权处理,将人数放入频率变量框中点击确定,出现图中下方语法表明个案加权成功,可以进行接下的数据分析了。
图8个案加权第二步4.多重响应分析第一步、首先需要定义变量集,点击分析、多重响应、定义变量集。
图9多重响应分析第一步第二步、进入下方对话框后、将多选题选项题项放入集合中的变量框中、后在二分法后的值里填入1,定义好变量名称。
图10多重响应分析第二步第三步、定义完成后就可以进行多重响应分析:点击分析、多重响应、频率。
图11多重响应分析第三步进入图中对话框后将定义好的变量放入点击确定图12多重响应分析第四步然后多重响应分析的结果就出来了图13多重响应分析结果将结果粘贴赋值到Excel表格中进行整理,后将整理好的结果粘贴到Word 文档中进行表格的制作和文字解释。
SPSS 描述性统计分析SPSS描述性统计分析,集中在Descriptive Statistics菜单中,最常用的是列在最前面的四个过程:Frequencies过程:产生频数表和百分位数;Descriptives过程:进行一般性的统计描述,用于服从正态分布的资料,计算产生均数、标准差等;Explore过程:用于对数据概况不清时的探索性分析;Crosstabs过程:完成计数资料和等级资料的统计描述和一般的统计检验,我们常用的X2检验也在其中完成。
1 频数分布分析(Frequencies过程)频数分布表是描述性统计中最常用的方法之一,Frequencies过程就是专门为产生频数表而设计的。
它不仅可以产生详细的频数表,还可以按要求给出某百分位点的数值,以及常用的条图,圆图等统计图.注:SPSS给出详细频数表,即并不按某种要求确定组段数和组距,而是按照数值精确列表。
Frequencies界面说明Frequencies对话框的界面如下所示:以下介绍各部分的功能:1、【Display frequency tables复选框】确定是否在结果中输出频数表.2、【Statistics钮】单击后弹出Statistics对话框如下,用于定义需要计算的其他描述统计量.现将各部分解释如下:1、Percentile Values复选框组: 定义需要输出的百分位数,可计算四分位数(Quartiles)、每隔指定百分位输出当前百分位数(Cut points for equal groups)、或直接指定某个百分位数(Percentiles),如直接指定输出P2.5和P97.5。
2、Central tendency复选框组用于定义描述集中趋势的一组指标:均数(Mean)、中位数(Median)、众数(Mode)、总和(Sum).3、Dispersion复选框组用于定义描述离散趋势的一组指标:标准差(Std.deviation)、方差(Variance)、全距(Range)、最小值(Minimum)、最大值(Maximum)、标准误(S。