最新整理监督学习概述hustoj.ppt
- 格式:ppt
- 大小:1.14 MB
- 文档页数:4


监督学原理在实际工作中的应用一、概述监督学(Supervised Learning)是机器学习领域的一个重要分支,其原理和方法在实际工作中有着广泛的应用。
监督学的基本思想是利用已知输入和输出的数据来训练模型,从而使其能够对新的输入给出准确的输出。
监督学可以应用于各种领域,包括医疗、金融、电子商务、智能制造等,为实际工作带来了巨大的便利和效益。
本文将从监督学的原理出发,探讨其在实际工作中的应用,以期为相关领域的从业者提供一些借鉴与启发。
二、监督学原理概述1. 监督学的基本概念监督学是指从标记好的训练数据中学习一个模型,然后利用学习到的模型对新的数据进行预测。
在监督学中,我们通常会将训练数据划分为输入变量(特征)和输出变量(目标)。
通过训练数据,我们可以学习到输入和输出之间的映射关系,从而得到一个能够准确预测输出的模型。
2. 监督学的主要方法监督学的主要方法包括回归分析和分类分析。
在回归分析中,我们尝试预测连续型的输出变量,例如预测房价、股票价格等;而在分类分析中,我们尝试预测离散型的输出变量,例如判断一封电流新箱是否为垃圾邮件、判断一张图片中的物体是什么等。
3. 监督学的模型监督学中常用的模型包括线性回归、逻辑回归、决策树、支持向量机、神经网络等。
每种模型都有其适用的场景和特点,我们需要根据具体的问题和数据选择合适的模型进行建模和训练。
三、监督学在医疗领域的应用1. 疾病预测医疗领域是监督学应用广泛的一个领域之一。
利用监督学的方法,我们可以通过病人的临床特征来预测其患某种疾病的风险,例如心脏病、糖尿病等。
通过建立预测模型,医生可以更早地发现患病的可能性,并采取相应的预防和治疗措施。
2. 药物研发在药物研发领域,监督学可以应用于药物筛选、分子设计等方面。
通过挖掘已知的化合物与生物活性的关系,监督学可以帮助研究人员预测新的化合物的生物活性,从而加速药物研发的过程。
3. 医学影像诊断监督学也可以应用于医学影像诊断领域。
监督学习1基本概念监督学习又称为分类(Classification)或者归纳学习(Inductive Learning)。
几乎适用于所有领域,包括文本和网页处理。
给出一个数据集D,机器学习的目标就是产生一个联系属性值集合A和类标集合C的分类/预测函数(Classification/Prediction Function),这个函数可以用于预测新的属性集合的类标。
这个函数又被称为分类模型(Classification Model)、预测模型(Prediction Model)。
这个分类模型可以是任何形式的,例如决策树、规则集、贝叶斯模型或者一个超平面。
在监督学习(Supervised Learning)中,已经有数据给出了类标;与这一方式相对的是无监督学习(Unsupervised Learning),在这种方式中,所有的类属性都是未知的,算法需要根据数据集的特征自动产生类属性。
算法用于进行学习的数据集叫做训练数据集,当使用学习算法用训练数据集学习得到一个模型以后,我们使用测试数据集来评测这个模型的精准度。
机器学习的最基本假设是:训练数据的分布应该与测试数据的分布一致。
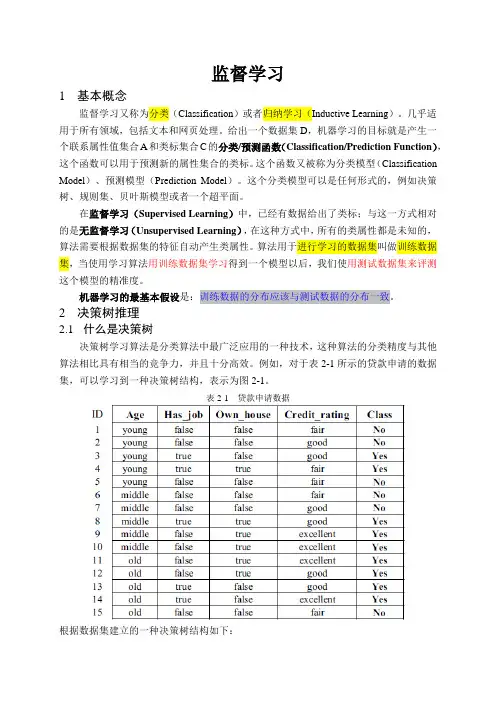
2决策树推理2.1什么是决策树决策树学习算法是分类算法中最广泛应用的一种技术,这种算法的分类精度与其他算法相比具有相当的竞争力,并且十分高效。
例如,对于表2-1所示的贷款申请的数据集,可以学习到一种决策树结构,表示为图2-1。
表2-1 贷款申请数据根据数据集建立的一种决策树结构如下:图2-1 对应与表2-1的决策树树中包含了决策点和叶子节点,决策点包含针对数据实例某个属性的一些测试,而一个叶子节点则代表了一个类标。
一棵决策树的构建过程是不断的分隔训练数据,以使得最终分隔所得到的各个子集尽可能的纯。
一个纯的子集中的数据实例类标全部一致。
决策树的建立并不是唯一的,在实际中,我们希望得到一棵尽量小且准确的决策树。
2.2学习算法学习算法就是使用分治策略,递归的对训练数据进行分隔,从而构造决策树。

监督学习与⾮监督学习前⾔机器学习分为:监督学习,⽆监督学习,半监督学习(强化学习)等。
在这⾥,主要理解⼀下监督学习和⽆监督学习。
监督学习(supervised learning)从给定的训练数据集中学习出⼀个函数(模型参数),当新的数据到来时,可以根据这个函数预测结果。
监督学习的训练集要求包括输⼊输出,也可以说是特征和⽬标。
训练集中的⽬标是由⼈标注的。
监督学习就是最常见的分类(注意和聚类区分)问题,通过已有的训练样本(即已知数据及其对应的输出)去训练得到⼀个最优模型(这个模型属于某个函数的集合,最优表⽰某个评价准则下是最佳的),再利⽤这个模型将所有的输⼊映射为相应的输出,对输出进⾏简单的判断从⽽实现分类的⽬的。
也就具有了对未知数据分类的能⼒。
监督学习的⽬标往往是让计算机去学习我们已经创建好的分类系统(模型)。
监督学习是训练神经⽹络和决策树的常见技术。
这两种技术⾼度依赖事先确定的分类系统给出的信息,对于神经⽹络,分类系统利⽤信息判断⽹络的错误,然后不断调整⽹络参数。
对于决策树,分类系统⽤它来判断哪些属性提供了最多的信息。
(预先已经有的分类器来对未知数据进⾏分类)常见的有监督学习算法:回归分析和统计分类。
最典型的算法是KNN和SVM。
有监督学习最常见的就是:regression&classificationRegression:Y是实数vector。
回归问题,就是拟合(x,y)的⼀条曲线,使得价值函数(costfunction) L最⼩Classification:Y是⼀个有穷数(finitenumber),可以看做类标号,分类问题⾸先要给定有lable的数据训练分类器,故属于有监督学习过程。
分类过程中cost function l(X,Y)是X属于类Y的概率的负对数。
其中fi(X)=P(Y=i/X)。
⽆监督学习(unsupervised learning)输⼊数据没有被标记,也没有确定的结果。






什么是监督学习?如何理解分类和回归?监督学习是机器学习中的一种训练方式/学习方式:监督学习需要有明确的目标,很清楚自己想要什么结果。
比如:按照“既定规则”来分类、预测某个具体的值...监督并不是指人站在机器旁边看机器做的对不对,而是下面的流程:1.选择一个适合目标任务的数学模型2.先把一部分已知的“问题和答案”(训练集)给机器去学习3.机器总结出了自己的“方法论”4.人类把'新的问题'(测试集)给机器,让他去解答上面提到的问题和答案只是一个比喻,假如我们想要完成文章分类的任务,则是下面的方式:1.选择一个合适的数学模型2.把一堆已经分好类的文章和他们的分类给机器3.机器学会了分类的“方法论”4.机器学会后,再丢给他一些新的文章(不带分类),让机器预测这些文章的分类监督学习的2个任务:回归、分类监督学习有2个主要的任务:1.回归2.分类回归:预测连续的、具体的数值。
比如:支付宝里的芝麻信用分数(下面有详细讲解)分类:对各种事物分门别类,用于离散型(什么是离散?)预测。
比如:「回归」案例:芝麻信用分是怎么来的?下面要说的是个人信用评估方法——FICO。
他跟芝麻信用类似,用来评估个人的信用状况。
FICO 评分系统得出的信用分数范围在300~850分之间,分数越高,说明信用风险越小。
下面我们来模拟一下 FICO 的发明过程,这个过程就是监督学习力的回归。
步骤1:构建问题,选择模型我们首先找出个人信用的影响因素,从逻辑上讲一个人的体重跟他的信用应该没有关系,比如我们身边很讲信用的人,有胖子也有瘦子。
而财富总额貌似跟信用有关,因为马云不讲信用的损失是非常巨大的,所以大家从来没有听说马云会不还信用卡!而一个乞丐不讲信用的损失是很小的,这条街混不下去了换一条街继续。
所以根据判断,找出了下面5个影响因素:•付款记录•账户总金额•信用记录跨度(自开户以来的信用记录、特定类型账户开户以来的信用记录...)•新账户(近期开户数目、特定类型账户的开户比例...)•信用类别(各种账户的数目)这个时候,我们就构建了一个简单的模型:f 可以简单理解为一个特定的公式,这个公式可以将5个因素跟个人信用分形成关联。

《监督学》课程讲义张会刚编写文法学院二O一O年七月《监督学》课程简介《监督学》是中央广播电视大学行政管理专业开放教育专科的一门必修课。
本课程72学时,4学分,开设一个学期。
本课程教材以毛昭晖主编《监督学》(中央广播电视大学2008年版)为固定的课本,以教师授课时的文字教材、上传网络的多媒体课件为辅。
学生应在教材、教学大纲的指导下,在认真学习掌握课上授课内容的同时,充分利用网上多媒体课件的教学资源。
《监督学》是近年行政管理学随着实践发展而产生的一门重要专业课程。
该课程系统介绍中西方监督制度及其形成的基本环境,具体涵盖监督监督与腐败的关系、监督思想与监督理论、中国监督制度的演进过程以及中国具体的监督系统构成等内容。
本课程的培养目标是向学员介绍各类监督方面的理论和实践内容。
学生通过学习能了解监督理论的主要知识,并了解国内外公共管理学对于监督理论及实践领域研究的最新成果和发展趋势。
该课程在阐释监督学的同时,力求将抽象的理论与现实生活中各种具体实际问题联系起来,从根本上提高学员的理论素养和解决应用问题的能力,使其了解和掌握处理日常生活中腐败、勤政、廉政等时政问题的实际情况并从中逐渐掌握一定的管理技能,注重培养学生面对实际管理问题所需具备的创新能力和应变能力。
本课程采用平时形成性考核和期末终结性考试相结合的方式。
考核总分为100分,平时形成性考核占总分20%;期末终结性考试占总分80%。
总成绩60分为及格。
平时成绩占总成绩40分。
平时成绩考核内容包括:在授课教师安排下完成两次课上习题,在责任教师设定的题目内完成两篇小论文。
平时考勤作为平时成绩的参照指数,分值为5分,按缺勤次数扣掉相应分数。
期末考试为集中统一考核,卷面为100分,占总成绩60分。
考试是对教与学的全面验收,是不可缺少的重要环节。
考试题目要符合大纲要求,既要做到全面验收,又要体现重点,难度适中,题量适度。
第一章监督学概述本讲主要内容摘要本部分主要讲了监督的基本内涵和特征,监督的功能和监督的分类,监督原则的基本内涵,腐败产生的根源,决策失误、不依法行政的表现及其危害。
监督学重点知识第一篇:监督学重点知识《监督学》重点知识镇海电大第一章监督学概述教学要求1、了解监督的基本内涵和特征2、理解监督的功能和监督的分类3、掌握监督原则的基本内涵4、对腐败产生的根源有清醒的认识5、对决策失误、不依法行政的表现及其危害有清醒的认识内容要点第一节监督与腐败的涵义与特征一、监督的涵义和特征二、腐败的涵义和特征三、腐败产生的根源与条件第二节监督的功能一、校正功能二、制约功能三、预防功能四、反馈功能第三节监督的分类一、监督主体的分类二、监督客体的分类三、监督与被监督关系的分类四、监督形式的分类五、监督阶段的分类第四节监督的基本原则一、依法监督原则二、独立监督原则三、全面监督原则四、分类监督原则五、过程监督原则第五节监督学的学科特点与研究现状一、监督学研究的对象二、监督学与相关学科的关系三、我国监督学研究的现状重点难点1、重点:着重把握2、难点:腐败产生的根源分析教学建议1、从监督主体与监督对象的关系层面分析监督的基本内涵2、从具体案例的视角来分析理解监督的功能,以及监督原则的运用3、从既得利益集团的视角分析腐败产生的根源【考核知识点】一、监督的含义及其特征 P3 P4二、廉政与勤政的基本内涵 P7三、腐败的含义、腐败行为的基本特征、腐败产生的根源 P9 P11 P13四、监督的功能 P15五、监督的分类 P18六、监督的基本原则 P25七、监督学的学科特点与研究对象 P28 名词:腐败(P9)寻租腐败(P10)组织腐败(P11)决策腐败(P11)监督制约功能(P16)监督预防功能(P17)监督反馈功能(P17)执政党的监督(P18)权力机关的监督(P19)职务犯罪监督(P19)社会民主监督(P19)公民的制约权(P21)事前监督(P23)事中监督(P24)事后监督(P24)监督学(P29)第二章监督思想与监督理论教学要求1、了解中外主要监督思想的形成与发展的基本脉络2、理解不同监督理论对监督制度的影响以及监督制度建构的理论基础内容要点第一节监督思想一、中国古代与近代的监督思想二、当代中国的监督思想三、国外监督思想综述四、中外监督思想的比较分析第二节监督理论一、人民主权理论二、议行合一理论三、三权分立理论四、利益多元理论五、预防为主理论重点难点1、重点:当代中国监督制度的理论基础2、难点:中外监督思想与监督理论的比较分析教学建议1、从历史渊源的视角理解监督思想的形成与政治制度演变的关系2、对各种监督理论的利弊进行比较分析【考核知识点】一、监督思想 P34二、中国古代监督思想 P34三、中国近代监督思想 P39四、中国当代监督思想 P42五、国外主要监督思想 P48六、中外监督思想的比较分析 P51七、监督理论 P53八、人民主权理论 P54九、议行合一理论 P57 十、三权分立理论 P59十一、多元民主理论 P59十二、协商民主理论 P63 名词:监督辅政思想(P34)君臣并提思想(P36)监督权权重而独立思想(P37)监督专才思想(P38)监察权独立(P39)党政分察(P40)弹惩一体(P41)政治原罪思想(P49)法治主义监督思想(P49)自由主义监督思想(P51)人民主权理论(P54)议行合一理论(P57)三权分立理论(P59)多元民主理论(P61)协商民主理论(P63)第三章中国监察制度的演进教学要求1、了解中国古代监察机关的领导体制与职权2、理解中国古代监察制度的特点内容要点第一节中国古代监察制度一、中国古代监察制度概述二、中国古代监察机关的领导体制三、中国古代监察机关的监察权四、中国古代监察法规建设五、中国古代的谏诤制度六、中国古代监察制度的特点第二节中国近代监察制度一、中华民国的监察制度二、革命根据地和解放区的监察制度第三节当代中国监察制度一、当代中国行政监察制度的演进二、香港特区以廉政公署为核心的监督制度三、澳门特别行政区的监督制度四、中国台湾地区的监察制度重点难点1、重点:中国古代监察制度的特点2、难点:中国古代监察机关领导体制的比较分析教学建议1、比较分析中国不同朝代的监察制度的特点及其对我国廉政建设与反腐败斗争的借鉴意义2、通过对中国古代监察事例的分析,让学生理解监察制度对政权长治久安的意义【考核知识点】一、中国古代监察体制的演进 P67二、中国古代监察机关的职权 P75三、中国古代监察法规建设 P81四、中国古代谏诤制度 P85五、中国古代监察制度的特点 P88六、中华民国的监察制度 P92七、革命根据地和解放区的监察制度 P96八、当代中国行政监察制度的演进 P96九、香港廉政公署 P101十、澳门廉政公署 P103十一、中国台湾地区的监察制度P105 名词:御史府(P67)一台三院(P72)弹劾权(P75)唐太宗时期的十道监察区(P71)都察院(P75)纠举权(P76)检查权(P77)一定的司法权(P78)侦破权(P78)谏诤君主权(P79)谏诤(P85)风闻奏事(P91)中华民国的五院(P93)第四章国外反腐败与监督制度教学要求1、了解国际间反腐败合作体系以及存在的问题2、发达国家反腐败与监督制度的特点3、《联合国反腐败公约》的核心内涵内容要点第一节国际反腐败运动一、国际反腐败现状与特点的分析二、国际间反腐败合作体系的基本架构三、国际反腐败立法与联合国《反腐败公约》第二节国际反腐败与监督的基本模式一、前苏联人民监察委员会监督模式二、瑞典监察专员监督模式三、美国议会与司法监督模式四、日本模式五、韩国模式六、新加坡模式重点难点1、重点:国际反腐败与监督的基本模式2、难点:发达国家监督制度对我国廉政建设与反腐败斗争可借鉴性的具体表现教学建议1、从立法监督与司法监督的视角,引导学生对中外监督体制的差异性进行理性分析2、从中外监督制度及其政治制度背景的差异性的视角进行比较分析,引导学生思考国际间反腐败合作的基本途径【考核知识点】一、中国廉政监督的含义及其运行机制 P109 P111二、中国廉政监督的基本战略 P113三、中国廉政监督的预警机制 P117四、中国廉政监督的防范机制 P124五、中国廉政监督的惩戒机制 P133六、效能型政府的构建 P135七、中国效能监督机制 P138八、中国效能监察制度 P142九、效能监督的考评制度 P144 名词:廉政监督(P111)廉政监督运行机制(P112)预警功能(P117)腐败风险预测功能(P117)财产申报制度(P119)廉政公积金(P120)政务公开(P121)反洗钱(P123)党政领导干部任职回避制度(P126)党代会常任制(P127)金融实名制(P130)政府集中采购(P132)惩戒机制(P132)党风廉政建设责任制(P133)引咎辞职(P134)职务犯罪(P134)行政处分(P135)经济性(P137)效率性(P137)效果性(P138)公共服务的制度体系(P139)首问责任制、一次性告知制度、限时办结制度、办事预约制度、否决报备制度、失职追究制度、AB岗工作制度(P139)效能考评机制(P140)过错责任(P140)效能监察(P142)效能监督考评(P144)第五章当代中国监督运行机制教学要求1、了解我国监督运行体系的基本架构2、理解廉政监督与效能监督的基本内涵3、了解我国监督制度完善的主要做法内容要点第一节廉政监督的运行机制一、中国廉政监督的基本架构二、中国廉政监督的基本战略三、中国廉政监督的预警机制四、中国廉政监督的防范机制五、中国廉政监督的问责机制第二节效能监督的运行机制一、中国效能型政府的构建二、中国公共决策的效能监督机制三、中国政策执行的效能监督机制四、中国政府的绩效考评机制五、中国行政效能监察制度六、中国政府依法行政的监督制度重点难点1、重点:预防为主的监督制度的构建2、难点:廉政监督机制与效能监督机制的整合四、教学建议1、引导学生关注和思考如何构建廉政监督与效能监督相结合的监督体系2、运用具体的案例,引导学生思考还应当从那些方面完善监督制度【考核知识点】一、人民代表大会监督的含义和特征 P150二、人民代表大会监督的基本原则 P152三、人民代表大会监督制度的基本架构 P154四、人民代表大会及其常务委员会监督的内容 P156五、人民代表大会及其常务委员会的监督权 155六、人大代表的监督权 P166七、改革和完善人大代表工作 P168 名词:人民代表大会的监督(P150)一府两院(P150)人大专门委员会(P155)人大专门委员会是全国人大的常设机构,由全国人民代表大会产生,受全国人民代表大会的领导,对全国人民代表大会负责,其特点具有专业化和经常化。
监督学习、无监督学习、强化学习,机器学习的常用算法总结一简介机器学习的知识树,来源GitHub:简单的翻译一下这个树:二监督学习监督学习可以看作是原先的预测模型,有基础的训练数据,再将需要预测的数据进行输入,得到预测的结果(不管是连续的还是离散的)决策树是一种树形结构,为人们提供决策依据,决策树可以用来回答yes和no问题,它通过树形结构将各种情况组合都表示出来,每个分支表示一次选择(选择yes还是no),直到所有选择都进行完毕,最终给出正确答案。
决策树(decision tree)是一个树结构(可以是二叉树或非二叉树)。
在实际构造决策树时,通常要进行剪枝,这时为了处理由于数据中的噪声和离群点导致的过分拟合问题。
剪枝有两种:•先剪枝——在构造过程中,当某个节点满足剪枝条件,则直接停止此分支的构造。
•后剪枝——先构造完成完整的决策树,再通过某些条件遍历树进行剪枝。
2、朴素贝叶斯分类器(Naive Bayesian Model,NBM)朴素贝叶斯分类器基于贝叶斯定理及其假设(即特征之间是独立的,是不相互影响的),主要用来解决分类和回归问题。
具体应用有:•标记一个电子邮件为垃圾邮件或非垃圾邮件;•将新闻文章分为技术类、政治类或体育类;•检查一段文字表达积极的情绪,或消极的情绪;•用于人脸识别软件。
学过概率的同学一定都知道贝叶斯定理,这个在250多年前发明的算法,在信息领域内有着无与伦比的地位。
贝叶斯分类是一系列分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。
朴素贝叶斯算法(Naive Bayesian) 是其中应用最为广泛的分类算法之一。
朴素贝叶斯分类器基于一个简单的假定:给定目标值时属性之间相互条件独立。
3、最小二乘法(Least squares)你可能听说过线性回归。
最小均方就是用来求线性回归的。
如下图所示,平面内会有一系列点,然后我们求取一条线,使得这条线尽可能拟合这些点分布,这就是线性回归。