降到最小BCJR算法是利用最大后验概率准则把
- 格式:doc
- 大小:1.22 MB
- 文档页数:36

LS,MMSE,LMMSE,ML,MAP,LMS,AR,MSE误差等算法做⼀个⽐较清晰的介。
/s/blog_8afae2970101cz9d.htmlQ:是否有朋友能对LS,MMSE,LMMSE,ML,MAP,LMS,AR,MSE误差等算法做⼀个⽐较清晰的介绍呢S:谈谈我的理解,不当之处欢迎⼤家指正:这⼀系列算法都可以是基于接收数据来对⽬标数据进⾏估计,1。
LS⽤于接收到的数据块长度⼀定,并且数据、噪声(⼲扰)的统计特性未知或者⾮平稳的情况,其优化⽬标是使得基于该数据块的估计与⽬标数据块间加权的欧⼏⾥德距离最⼩,当有多个数据块可⽤时,可⽤其递归算法RLS减⼩计算量;2。
MMSE的优化⽬标是为了使基于接收数据的估计值和⽬标数据的均⽅误差最⼩化,LMMSE算是MMSE的特例,在这种情况下,基于接收数据的估计值是接收数据的线性变换,在数据统计特性已知的情况下,某些时候可以直接求解,⽐如维纳解;在数据统计特性未知但是平稳的时候,可以通过递归迭代的算法求解,诸如:LMS算法。
3。
ML和MAP顾名思义,前者是为了使似然概率最⼤后者是为了使得后验概率最⼤,具体说来就是,假设接收数据为rx,⽬标数据为tx,在已知rx的情况下,ML就是求使得p(rx|tx)最⼤的tx,MAP就是求使得p(tx|rx)最⼤的tx。
4。
AR(⾃回归),这是假设⽬标数据满⾜⾃回归模型,这时我们需要求解的就是相应的模型的系数了。
5。
MSE?如果是指均⽅误差,就可参见前⾯的叙述。
我记得有种算法是MOE,即最⼩化输出能量,结合⼀定的约束,它可以使得输出信号中⽬标信号成分不变,但是⼲扰最⼩化。
我先来谈谈ML(Maximum Likelihood,最⼤似然)和MAP(Maximum a posteriori Probability,最⼤后验概率)算法的区别在MAP算法中,后验概率由似然函数和先验概率组成。
由于引⼊了数据源的先验统计特性,理论上MAP算法⽐最⼤似然估计算法(ML)估计得要准确(如果输⼊的数据先验概率不等的话,如果先验概率相等的话性能是相当的)。

aic和bic准则AIC和BIC准则是用于评估不同模型的标准,它们可以帮助选择最佳模型。
AIC和BIC准则都是评估模型的工具,它们需要在模型被拟合之前就定义好,并且它们能够衡量模型的质量,即使在模型中没有定义显式的目标函数时也能够有效地衡量模型的质量。
AIC准则(Akaike Information Criterion)是由日本统计学家晓秋·赤池于1974年提出的,它基于最大似然法,以减小模型的自由参数而设计,并且用来评估模型的好坏。
AIC的模型优化度量方法是将数据集中的观测数据和模型参数的准确度作为模型的衡量标准,以最大化数据的准确性为目标,从而得到最优模型。
AIC准则的模型选择原则是:当模型参数个数不同时,AIC越小,模型越好。
AIC准则可以用如下公式表示:AIC=−2lnL+2K其中,L为模型最大似然估计,K为模型参数的个数。
AIC准则的一个优点是它可以用来衡量未来数据集上模型表现的可预测性,因此它可以用来比较不同模型的预测能力。
BIC准则(Bayesian Information Criterion)是由美国数学家George Box提出的,它也是一种模型优化度量方法,它的思想是对模型的参数估计更加保守,同时考虑模型的实际参数个数。
BIC准则的模型优化度量方法是将模型参数的估计和参数个数的准确度作为模型的衡量标准,以最大化模型参数估计和参数个数准确度为目标,从而得到最优模型。
BIC准则的模型选择原则是:当模型参数个数不同时,BIC越小,模型越好。
BIC准则可以用如下公式表示:BIC=−2lnL+KlogN其中,L为模型最大似然估计,K为模型参数的个数,N为样本数。
BIC准则与AIC准则相比,它更加看重模型的参数估计,同时考虑模型的实际参数个数,因此它能够更加有效地筛选出最优的模型。
综上所述,AIC和BIC准则是一种用于评估模型的工具,它们可以帮助选择最佳模型,AIC准则可以用来衡量模型的预测能力,而BIC准则则可以更加有效地筛选出最优的模型。

编号:课程设计说明书题目:RS(255,223)纠错编码的MATLAB仿真目录1引言·····················错误!未指定书签。
1.1信道编码理论与技术的发展历程及应用·····错误!未指定书签。
1.2纠错编码简介················错误!未指定书签。
2Reed–Solomon编码概述············错误!未指定书签。
3Reed–Solomon编码抽象代数基础········错误!未指定书签。
3.1群·····················错误!未指定书签。
3.2环和域···················错误!未指定书签。
3.3有限域···················错误!未指定书签。
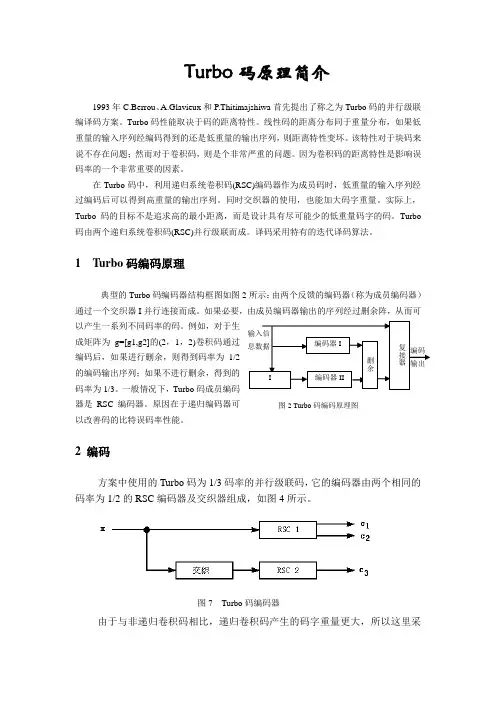
Turbo 码原理简介1993年C.Berrou 、A.Glavieux 和P.Thitimajshiwa 首先提出了称之为Turbo 码的并行级联编译码方案。
Turbo 码性能取决于码的距离特性。
线性码的距离分布同于重量分布,如果低重量的输入序列经编码得到的还是低重量的输出序列,则距离特性变坏。
该特性对于块码来说不存在问题;然而对于卷积码,则是个非常严重的问题。
因为卷积码的距离特性是影响误码率的一个非常重要的因素。
在Turbo 码中,利用递归系统卷积码(RSC)编码器作为成员码时,低重量的输入序列经过编码后可以得到高重量的输出序列。
同时交织器的使用,也能加大码字重量。
实际上,Turbo 码的目标不是追求高的最小距离,而是设计具有尽可能少的低重量码字的码。
Turbo 码由两个递归系统卷积码(RSC)并行级联而成。
译码采用特有的迭代译码算法。
1 Turbo 码编码原理典型的Turbo 码编码器结构框图如图2所示:由两个反馈的编码器(称为成员编码器)通过一个交织器I 并行连接而成。
如果必要,由成员编码器输出的序列经过删余阵,从而可以产生一系列不同码率的码。
例如,对于生成矩阵为g=[g1,g2]的(2,1,2)卷积码通过编码后,如果进行删余,则得到码率为1/2的编码输出序列;如果不进行删余,得到的码率为1/3。
一般情况下,Turbo 码成员编码器是RSC 编码器。
原因在于递归编码器可以改善码的比特误码率性能。
2 编码方案中使用的Turbo 码为1/3码率的并行级联码,它的编码器由两个相同的码率为1/2的RSC 编码器及交织器组成,如图4所示。
由于与非递归卷积码相比,递归卷积码产生的码字重量更大,所以这里采图7 Turbo 码编码器输入信 息数据编码器II编码器II删余复接器编码 输出图2 Turbo 码编码原理图用了两个相同的系统递归卷积码(RSC)。
信息序列分成相同的两路,第一路经过RSC 编码器1,输出系统码1c 及校验码2c 。

高功率下光纤中的非线性效应抑制方法的研究一、引言随着语音、图像和数据等信息量爆炸式的增长, 尤其是因特网的迅速崛起,人们对于信息获取的需求呈现出供不应求的态势。
这对通信系统容量和多业务平台的服务质量提出了新的挑战,也反过来推动了通信技术的快速发展。
1966年,美籍华人高锟博士提出可以通过去杂质降低光纤损耗至20dB/km,使光纤用于通信成为可能,从而开启了人类通信史的新纪元。
与传统的电通信相比,光纤通信以其损耗低、传输频带宽、容量大、抗电磁干扰等优势备受业界青睐,已成为一种不可替代的支撑性传输技术。
新型激光器和调制格式、波分复用(WDM)技术、宽带光放大技术的不断涌现,大幅提高了光通信能力[15]。
光纤通信的传输容量在1980~2000年间增加了近10000倍,传输速率在过去的10年中提高了约100 倍。
目前,单信道40Gbit/s的光传输系统已经广泛商用,100Gbit/s的WDM/OTN(Optical Transmission Network,光传输网)链路也开始在欧美地区进行商用部署,400Gbit/s 的传输技术成为未来的研究方向。
众所周知,信号在光纤通信系统中的传输性能会受到光纤的损耗、色散和非线性效应的制约,而且传输速率越高、距离越长,上述效应越严重,对系统性能的劣化十分明显。
因此,对这些制约因素的削弱甚至消除是进一步提高信息传输容量的关键,也一直是光纤传输技术的重点研究方向,并已取得了一系列卓有成效的进展。
二、光纤损伤及补偿技术光纤损伤主要包含上节所述的损耗、色散和非线性效应。
光放大器技术,包括EDFA(Erbium Doped Fiber Amplifier,掺铒光纤放大器)、FRA(Fiber Raman Amplifier,光纤拉曼放大器)和参量放大器的出现已经完美地解决了光纤损耗问题。
光纤色散补偿技术也已十分成熟。
色散作为一种线性损伤,其补偿原理是利用光电元件实现波长或偏振相关的延时功能。


BPSK调制信道卷积码的BCJR译码过程1. 引言在数字通信系统中,为了提高可靠性和传输效率,通常会采用调制和编码技术。
BPSK调制是一种常用的数字调制方式,而卷积码则是一种常用的编码方式。
BCJR (Bahl, Cocke, Jelinek, Raviv)算法是一种经典的软判决译码算法,广泛应用于卷积码的解码过程中。
本文将详细介绍BPSK调制信道卷积码的BCJR译码过程,包括相关理论背景、算法原理、步骤和实现方法等内容。
2. 背景知识2.1 BPSK调制BPSK(Binary Phase Shift Keying)是一种二进制相位调制方式,使用两个不同的相位表示二进制数据0和1。
具体而言,在BPSK调制中,将二进制数据0映射为相位为0°的载波信号,将二进制数据1映射为相位为180°(或π)的载波信号。
2.2 卷积码卷积码是一种线性时不变系统,在编码过程中利用一个或多个寄存器进行状态转移,并通过线性组合生成输出。
卷积码的编码过程是一种冗余度增加的操作,可以提高系统的抗干扰和纠错能力。
卷积码由三个参数表示:n、k和m。
其中,n表示每个码字的比特数,k表示信息比特数,m表示寄存器数。
通过这些参数,可以得到一个(n, k, m)卷积码。
2.3 BCJR算法BCJR算法是一种基于概率图模型的软判决译码算法,适用于线性时不变系统中的序列译码问题。
它利用前向和后向变量计算路径概率,并通过最大后验概率准则进行判决。
3. BCJR译码算法原理BCJR译码算法是一种迭代解码算法,主要包括前向过程、后向过程和路径更新三个步骤。
3.1 前向过程前向过程用于计算给定观测序列下每条路径的前向变量α。
首先,定义t时刻状态为s_i(i为状态索引),观测为o_t,则前向变量α在t时刻、状态s_i下的定义如下:α(t, s_i) = P(o_1, o_2, …, o_t, s_t = s_i)接着,根据递推关系计算前向变量α(t, s_i):α(t, s_i) = Σ[α(t-1, s_j) * a_ij * b_j(o_t)] (j为状态索引)其中,a_ij表示状态转移概率,b_j(o_t)表示观测到o_t时处于状态s_j的概率。

Turbo码简介一、Turbo码概述纠错码技术在过去的八年中发生了翻天覆地的改变。
从1993 年,Turbo 码被C.Berrou 等人提出以来,Turbo 码就以其优异的性能和相对简单可行的编译码算法吸引了众多研究者的目光。
如果采用大小为65535 的随机交织器,并且进行18 次迭代,码率为1/2 的Turbo 码在AWGN 信道上的误比特率(BER)≤10-5的条件下,Turbo 码离Shannon 限仅相差0.7dB,而传统的编译码方案要与Shannon 限相差3-6dB,从中可以看出Turbo 编码方案的优越性,如图1。
图1 加性高斯信道中的shannon限各种码的性能比较图Turbo 码的实质是并行级联的卷积码,它与以往所有的码的不同之处在于它通过一个交织器的作用,达到接近随机编码的目的,并且使等效分组长度很大。
Shannon 指出“随机码”是一种好码,因此Turbo 码也是一种好码。
此外它所采用的迭代译码策略,使得译码复杂性大大降低。
它采用两个子译码器通过交换称为外信息的辅助信息,相互支持,从而提高译码性能。
外信息的交换是在迭代译码的过程中实现的,前一次迭代产生的外信息经交换后将作为下一次迭代的先验信息。
人们将Turbo 码中子译码器互换信息以相互支持的思想称为“Turbo 原理”。
这种思想可运用于其他场合,如信道均衡,码调制,多用户检测,信源、信道联合译码等。
二、Turbo码编码Turbo 码编码器是由两个反馈系统卷积码(RSC)编码器通过一个随机交织器分开并行级联而成的。
所以Turbo 码也被称作并行级联卷积码(Parallel Concatenated Convolutional Codes)。
编码后的校验位经过截余矩阵,从而产生不同码率的码字,如图2所示。
图2 turbo码编码器结构框图图2 所示的是典型的Turbo 码编码器结构框图,信息序列u ={u 1,u 2,…,u N }经过一个N 位交织器,形成一个新序列u 1= {u ’1,u ’2,…,u ’N }(长度与内容没变,但比特位置经过重新排列)。

无人驾驶车辆_北京理工大学中国大学mooc课后章节答案期末考试题库2023年1.2007年 DARPA举办的城市挑战赛,冠军是斯坦福大学的无人车。
参考答案:错误2.相机与激光雷达数据融合主要是指空间数据融合。
()参考答案:错误3.关于激光雷达slam,以下描述正确的有()参考答案:Gmapping 采用粒子滤波的方法,在二维激光雷达slam中使用广泛。
_Karto SLAM采用图优化的方法计算更新激光雷达的位姿。
_Cartographer以子地图为单位构建全局地图,以消除构图过程中产生的累积误差。
_Hector SLAM采用基于扫描匹配的方法,在传感器精度高的情况下,定位建图效果好。
4.视觉里程计的目的是根据拍摄的图像估计相机的运动,其关键步骤包括()参考答案:特征提取_局部优化_运动估计_特征匹配5.以下哪些曲线可以用于状态空间采样()参考答案:Dubins曲线_Reeds-shepp曲线_B样条曲线_高次多项式曲线6.单层感知机无法解决异或问题,这是因为异或问题是一个非线性问题,而单层感知机属于一种线性分类器。
参考答案:正确7.LPA*算法是一种实时、增量式的规划算法。
参考答案:错误8.通过卫星播发导航电文的方式可以将电离层时间误差、对流层时间误差、多路径延迟误差和卫星位置j等信息提供给用户。
参考答案:正确9.拓扑地图模型选用节点来表示道路上的特定位置,用节点与节点间的关系来表示道路间联系。
这种地图表示方法结构简单、存储方便、全局连贯性好,适合于大规模环境下的路径规划。
参考答案:正确10.相机成像时,像素点是离散的,像素值是连续的。
参考答案:错误11.假如激光雷达坐标系到车体坐标系的旋转矩阵为[0.83, -0.26, 0.49; 0.36, 0.93,-0.11; -0.42, 0.27, 0.87;],平移向量为[-0.1, -0.6, 0.6],激光雷达坐标系中坐标为[1.6, -1.5, 1.5]的点,在车体坐标系中的坐标是()参考答案:[2.35, -1.58, 0.83]12.Dijkstra算法只能求出起点到终点的最短路径,不能得到起点到其它各节点的最短路径。

基于SOVA与BCJR算法的CPM信号改进译码算法作者:傅蕾王雷王亮来源:《软件导刊》2017年第01期摘要摘要:BCJR算法是一种最优译码算法,但是计算量大、译码复杂;SOVA算法译码简单,但是性能稍差。
针对这两种算法的缺点,在连续相位调制信号系统中,提出一种基于减少搜索T-BCJR与SOVA算法的改进译码算法。
该算法能在减少迭代译码时的搜索路径数量、降低译码复杂度的同时达到比较好的译码性能。
经过实验仿真,验证了该算法的可行性与优越性。
关键词关键词:SOVA;T-BCJR;连续相位调制;迭代译码DOIDOI:10.11907/rjdk.162309中图分类号:TP312文献标识码:A文章编号文章编号:16727800(2017)001003503引言连续相位调制CPM(Continuous Phase Modulation)信号是一种恒包络且相位连续的调制信号,与其它调制方法相比,具有很高的频谱和功率利用率。
由于信号的包络恒定,对功放的非线性特性不敏感,可以使用C类(非线性)功率放大器。
另外,信号相位连续,带外辐射小,产生的邻道干扰也比较小。
因此,CPM调制技术近年来受到广泛关注。
G.Ungerboeck[1]提出了网格编码调制TCM (Trellis Coded Modulation)的设计方法,将线性调制技术与信道编码结合,很大程度上提高了系统的性能。
C.Berrou[2]提出了Turbo码,迭代解码的结构被应用到串行级联CPM系统的译码中。
孙锦华[3]提出了一种基于RSSD思想的减状态译码算法,降低了译码复杂度。
本文主要探讨连续相位调制信号在高斯白噪声信道下的译码算法,并提出一种基于Turbo 译码算法的改进结构,该算法结合了Turbo码译码的SOVA与BCJR算法的优点。
通过仿真实验,验证了该算法的可行性,可以在减少算法复杂度的同时改善系统的译码性能。
1基本概念1.1CPM概念与分解模型CPM信号的一般表达式为: S(t,α)=2ETcos(2πfct+φ(t,α)+φ0)(1)其中,fc是载波频率,φ0是载波的初始相位,T为码元周期,E是一个码元周期T内的信号能量,φ(t,α)是携带信息的相位,表示如下:φ(t,α)=2πh∑nk=-∞αkq(t-kT)nT≤t≤(n+1)T(2)其中,αk是M进制的信息符号,取值范围是αk∈{±1,±3,…,±(M-1)};h=K/P(K,P为互斥正整数)是调制指数;q(t)为相位响应函数,定义为脉冲函数g(t)的积分:q(t)=∫τ0g(τ)dτ(3)常见的脉冲函数有L-REC方波、L-RC升余弦和L-GMSK高斯成形脉冲。

通信最大后验概率准则知乎摘要:1.通信最大后验概率准则的定义2.通信最大后验概率准则的应用3.通信最大后验概率准则的优点和局限性正文:通信最大后验概率准则(MAP)是一种在通信系统中广泛应用的准则,主要用于信号检测和估计。
在实际通信中,由于各种原因,接收到的信号可能受到噪声、衰减等因素的影响,导致信号质量下降。
通信最大后验概率准则就是在这种情况下,通过计算各种可能信号的概率,选择最可能的信号,从而实现对原始信号的恢复。
通信最大后验概率准则的应用主要体现在以下几个方面:首先,在信号检测中,通信最大后验概率准则可以用于判断接收到的信号是否包含有用信息。
通过计算信号的概率,可以有效区分有用信号和噪声,从而提高信号检测的准确性。
其次,在信号估计中,通信最大后验概率准则可以用于对受到噪声干扰的信号进行恢复。
通过对各种可能的信号进行概率计算,选择最可能的信号,从而实现对原始信号的估计。
通信最大后验概率准则的优点主要体现在以下几个方面:首先,通信最大后验概率准则考虑了信号的概率信息,可以更准确地判断信号是否有用。
其次,通信最大后验概率准则具有较强的鲁棒性,即使在信号受到较大噪声干扰的情况下,也能较好地进行信号检测和估计。
然而,通信最大后验概率准则也存在一定的局限性:首先,通信最大后验概率准则的计算复杂度较高,需要计算各种可能信号的概率,对于复杂的信号处理问题,计算量可能较大。
其次,通信最大后验概率准则在某些情况下可能存在误判的风险,例如当信号和噪声之间的差异较小时,可能会选择错误的信号。
总的来说,通信最大后验概率准则是一种在通信系统中非常有用的准则,通过计算信号的概率,可以有效检测和估计信号,提高通信系统的性能。
贝叶斯估计最小最大原理1.引言1.1 概述贝叶斯估计和最小最大原理是概率论和统计学中两个重要的概念和方法。
它们在不同的领域和问题中具有广泛的应用,并且相互关联和影响。
贝叶斯估计是统计推断的一种方法,是基于贝叶斯定理的思想发展而来的。
其核心思想是在已知观测数据的情况下,通过计算参数的后验概率分布来进行参数估计。
贝叶斯估计可以将先验知识和观测数据进行有效的结合,提供了一种更加准确和全面的参数估计方法。
最小最大原理是决策论中的一种方法,用于确定最优的决策策略。
最小最大原理的核心思想是在面临不确定性和风险的情况下,通过最小化最大损失来选择最佳策略。
该原理要求在任何可能的情况下,所选择的策略都能使最坏情况下的损失最小化。
本文将围绕贝叶斯估计和最小最大原理展开详细阐述。
首先,我们将介绍贝叶斯估计的基本原理,包括贝叶斯定理和后验概率的计算方法。
然后,我们将介绍最小最大原理的概念和应用,包括最小最大损失和最优策略的确定方法。
最后,我们将着重探讨贝叶斯估计与最小最大原理之间的关系,探讨它们在统计推断和决策制定中的相互作用和互补。
通过对贝叶斯估计和最小最大原理的深入理解和研究,我们可以更好地应对不确定性和风险,并进行更准确和有效的参数估计和决策制定。
本文将为读者提供有关贝叶斯估计和最小最大原理的全面介绍和理解,并为进一步研究和应用这两种方法奠定基础。
在未来的研究中,我们还可以思考和展望贝叶斯估计和最小最大原理的更多潜在应用和改进方向。
1.2文章结构文章结构的目的是为了清晰地呈现文章的逻辑结构和内容框架,帮助读者更好地理解文章的主旨和论证过程。
通过准确的文章结构,读者可以迅速找到所需信息,并更好地理解文章的脉络。
本文将分为引言、正文和结论三个部分。
在引言部分,将对贝叶斯估计最小最大原理的背景和意义进行概述,并介绍文章的结构和目的。
在正文部分,将深入讨论贝叶斯估计的基本原理,以及最小最大原理的概念和应用。
在此基础上,将探讨贝叶斯估计与最小最大原理之间的关系,并展望贝叶斯估计最小最大原理未来的发展方向。
最小化原则梯度下降算法
最小化原则梯度下降算法是一种优化算法,用于最小化目标函数。
它的基本原理是利用目标函数的梯度信息,通过不断迭代更新参数,使得目标函数逐渐减小,最终达到最小值。
具体来说,梯度下降算法在每一次迭代中,都会沿着目标函数的负梯度方向(即下降最快的方向)进行搜索,并更新参数。
这个过程会一直持续到算法收敛,即目标函数达到最小值或足够小的值。
梯度下降算法有很多变种,包括批量梯度下降、随机梯度下降和小批量梯度下降等。
这些变种的区别主要在于计算目标函数梯度时所用的数据量不同。
在应用梯度下降算法时,需要注意选择合适的学习率和迭代次数,以及避免陷入局部最小值等问题。
同时,梯度下降算法也适用于各种机器学习模型,如线性回归、逻辑回归、神经网络等。
数据仓库与数据挖掘_北京理工大学中国大学mooc课后章节答案期末考试题库2023年1.假设属性income的最大最小值分别是12000元和98000元。
利用最大最小规范化的方法将属性的值映射到0至1的范围内。
对属性income的73600元将被转化为:()参考答案:0.7162.数据的可视化是将数据以各种图表的形式展现在用户的面前,使用户能观察数据,并在较高的层次上找出数据间可能的关系。
参考答案:正确3.数据挖掘和可视化都是知识提取的方式。
参考答案:正确4.面向应用场景的可视化交互式数据挖掘方法是以数据挖掘算法和模型为主,并不针对具体应用场景或数据类型参考答案:错误5.将原始数据进行集成、变换、维度规约、数值规约是以下哪个步骤的任务?()参考答案:数据预处理6.数据仓库的数据ETL过程中,ETL软件的主要功能包括()参考答案:数据抽取_数据加载_数据转换7.数据挖掘的主要任务是从数据中发现潜在规则,从而能更好的完成描述数据、预测数据的任务。
参考答案:正确8.传统数据仓库包括数据仓库数据库、数据抽取/转换/加载、元数据、访问工具、数据集市、和信息发布系统七个部分组成。
参考答案:数据仓库管理9.关联规则挖掘过程是发现满足最小支持度的所有项集代表的规则。
参考答案:错误10.假定你现在训练了一个线性SVM并推断出这个模型出现了欠拟合现象。
在下一次训练时,应该采取下列什么措施?()参考答案:增加特征11.下面哪一项关于CART的说法是错误的()参考答案:CART输出变量只能是离散型。
12.以下哪种方法不是常用的数据约减方法()参考答案:关联规则挖掘13.假设12个销售价格记录组已经排序如下:5, 10, 11, 13, 15,35, 50, 55, 72, 92,204, 215 使用如下每种方法将它们划分成四个箱。
等频(等深)划分时,15在第几个箱子内? ()参考答案:第二个14.下表是一个购物篮,假定支持度阈值为40%,其中()是频繁闭项集。
bcjr算法原理
哎,兄弟,今儿咱来聊聊这个bcjr算法原理嘛。
虽然咱是四川人,但咱也得学点新鲜玩意儿,不是?这个bcjr算法啊,就像咱们贵州的酸汤鱼一样,味道独特,做法精细。
首先啊,你得明白这个算法是干啥子的。
说白了,它就是一种解码算法,就像咱陕西人吃的油泼面,面条筋道,调料得当,才能吃出那个味儿。
bcjr 算法就是用来解码卷积码的,把一堆乱码给咱整成能看懂的信息。
那它是咋工作的呢?这就好比咱北京炸酱面的制作过程,得一步步来,不能急。
首先,它得有个初始状态,就像炸酱面得准备好面条和酱一样。
然后,它就开始根据接收到的信号,一步步地进行解码。
这就像炸酱面开始烹饪,面条煮熟,酱也炒得喷香。
在这个过程中,bcjr算法会不断地计算路径度量,就像咱四川人做火锅,得掌握好各种调料的比例,才能让火锅味道恰到好处。
这些路径度量就是帮助算法判断哪条路径是最有可能的,从而找到正确的解码结果。
最后啊,这个算法就能给咱输出解码后的信息了,就像端上一碗香喷喷的炸酱面,咱就能大快朵颐了。
这就是bcjr算法原理的简要介绍,虽然咱说得有点土气,但道理是一样的,都是为了让大家能更容易理解。
所以说啊,学习这个bcjr算法原理,就像咱们学习各地的美食文化一样,得用心去感受,去体会其中的奥妙。
只有这样,咱才能真正掌握它,让它为咱的生活增添一份色彩。
引言未来的无线通信系统必须能为用户提供高速率、高质量、实时的多媒体业务,然而无线信道,特别是移动无线信道是典型的随机时变信道,其在时间域、频率域以及空间角域均存在着随机性的扩散,这些扩散将造成接收信号在相对应的频率域、时间域以及空间域产生严重的衰落现象,衰落将严重地恶化无线通信系统的传输可靠性及频谱效率。
为了实现高效、可靠的无线数据传输,两种手段是必要的:①利用各种分集对抗衰落,②利用信道编码实现差错控制。
频率分集、时间分集、空间分集是主要的分集手段,充分利用这些分集方法将衰落信道尽可能地改造为AWGN信道,然后利用信道编码进行检错和纠错。
一般的信道编译码方案,难以在无线通信中以较低的信噪比达到数据业务的服务质量(QoS)(例如一般要求误比特率 BER≤10-6),即使在以前的无线移动通信系统中通常采用的RS码与卷积码串行级联的信道编码方案,与香农(C.E. Shannon)界有较大的差距,直到1993年出现的Turbo码的性能与香农界的差距仅为0.5dB。
他们发明的Turbo码的创新之处在于:用两个递归系统卷积成员码并行级联编码,这两个系统递归卷积成员码之间用一个伪随机交织器相连接,并且采用软入软出(SISO, Soft-In-Soft-Out)的迭代译码算法。
从此,Turbo 码就成为编码界的一个研究热点。
S. Ten Brink在[2]得到的Turbo码的性能与香农界的差距仅为0.1dB。
一、3G 移动通信系统的特点&Turbo 码的应用1.13G 移动通信系统的特点第三代移动通信系统的数据速率可从几kbps 到2 Mbps ;高速移动时为144 kbps ;慢速移动时为384 kbps ;静止时为2 Mbps 。
多媒体化:提供高质量的多媒体业务,如话音、可变速率数据、活动视频和高清晰图像等多种业务,实现多种信息一体化。
全球性:公用频段, 全球漫游, 大市场。
在设计上具有高度的通用性,该系统中的业务以及它与固定网之间的业务可以兼容,拥有足够的系统容量和强大的多种用户管理能力,能提供全球漫游。
是一个覆盖全球的、具有高度智能和个人服务特色的移动通信系统。
综合化:多环境、灵活性,能把现存的寻呼、无绳、蜂窝(宏蜂窝、微蜂窝、微微蜂窝)、卫星移动等通信系统综合在统一的系统中(具有从小于50m 的微微小区到大于500km 的卫星小区) ,与不同网络互通,提供无缝漫游和业务一致性。
网络终端具有多样性。
平滑过渡和演进:与第二代系统的共存和互通,开放结构,易于引入新技术。
智能化:主要表现在优化网络结构方面(引入智能网概念)和收发信机的软件无线电化。
个人化:用户可用唯一个人电信号码(PTN )在任何终端上获取所需要的电信业务,这就超越了传统的终端移动性,真正实现个人移动性目前,Turbo 码的理论和应用研究仍在进行,这些研究将主要集中在如下几个方面:1)最优分量码与交织器的联合设计。
2)低复杂性译码算法。
3)译码迭代过程的优化,收敛性以及迭代停止准则的设计。
4)联合信道估计/多用户检测/均衡和译码算法。
5)Turbo 码与高阶调制技术的结合。
6)Turbo 编译码器的硬件实现。
7)Turbo 码在无线通信,移动通信以及多媒体通信中的应用, 特别是在移动通信网络,IMT-2000及加密系统中的应用等等。
1.2 Turbo 码在第三代移动通信中的中的应用WCDMA 和cdma2000都同时采用了卷积码和并行级联卷积Turbo 码(PCCC)作为纠错编码。
Turbo 码主要用于对时延要求不高的高速数据业务。
并行级联卷积码Turbo 码的对应的两个相同的递归系统卷积成员码的生成多项式如[34]中所规定的321)(1D D D g ++=, 31)(2D D D g ++=。
在cdma2000-1XHDR 中, 串行级联卷积Turbo 码(SCCC)作为信道编码方案,其内码是递归系统卷积码,生成多项式是21)(1D D D g ++=,21)(2D D g +=,外码是非递归卷积码,生成多项式是21)(1D D D g ++=, 21)(2DD g +=。
由于移动环境的复杂性,为了保证数据业务的QoS, WCDMA 和cdma2000都引入了重传机制,如HSDPA 中的利用基于RCPT(Rate Compatible Punctured Turbo Code)的HARQ 解决方案。
二、 Turbo 码的分类现在广义的Turbo 码是指采用级联或乘积编码方法并利用迭代译码方法的编译码方案。
迭代译码的基本思想是将一个的复杂的长的译码步骤分解为多个相对简单的迭代译码步骤而且在迭代译码步骤之间信息概率的转移或者是软信息的传递确保几乎没有信息损失。
根据其成员码和级联的方法的不同,Turbo 码的分类♦ P_SCR 并行级联卷积Turbo 码(Parallel Serial Concatenated Convolutional code)♦ SCC 串行级联卷积Turbo 码(Serial Concatenated Convolutional code)♦ HCC 混合级联卷积Turbo 码(Hybrid Concatenated Convolutional code)♦ SCC 分组码卷积码串行级联编码 (Serial Concatenated Convolutional and Block code) ♦ 分组码Turbo 码通用的实现迭代译码 的“SISO”译码模块的输入包括信道的软信息和先验信息,这种“SISO”译码模块的输出信息可以分解为三部分: 信道的软信息、先验信息和外部信息(又称边信息),而外部信息可以作为下一次迭代译码的先验信息。
各种迭代译码算法的主要差别就在于输出软信息的计算,实际上也就是外部信息的度量。
并行级联卷积码的软入软出(SISO )迭代译码算法有:♦ MAP (Maximum A Posteriori 最大后验概率, 基于网格图) ♦ LOG-MAP♦ MAX-LOG-MAP♦ SOVA (Soft-Output-Viterbi-Algorithm)其中对于卷积级联Turbo 码中研究的最多的是并行级联卷积Turbo 码,其次是串行级联卷积Turbo 码;在分组码Turbo 码中,Turbo 乘积码(Turbo Product Code)和LDPC 码(Low-Density Parity-Check codes)是研究较多的两种。
三、 Turbo 码编译码原理Turbo 码编码器是由两个或两个以上的子编码器(又称组成编码器)并行连接形成的,其中的子编码器最开始是一种递归系统卷积码(RSC)。
两个码率均为R=1/2的RSC 编码器通过交织器(Interleaver)分隔开,分别对输入的数据并行处理,如图3(a)所示。
这种编码器属于系统编码器,因为编码器1#的上面一部分输出就是输入的数据(与之对应的编码器2#的输出被取消)。
图中,若Turbo 码未进行收缩(Puncturing, 即通过MUX 多路选择器有选择地删除校验输出位),则总的码率为r=1/3。
由于有交织器,进入下面那个编码器的数据与输入数据的顺序不同,因此,Turbo 码的最优(最大似然)译码相当复杂,是不实用的。
然而,文[3]中提出的次最优(Suboptimal)迭代译码算法大大降低了译码的复杂性,而且取得了好的性能。
其译码的思想是:将整个译码问题分成更小的问题——对其中的每个码进行译码,获得局部最优解,并以迭代(Iterative)的方式共享信息。
译码器以后验比特概率(APP, A posteriori bit probabilities)的形式产生软输出信息。
Turbo 码译码器的结构如图1(b)所示。
图中,译码器1接收数据信息,译码输出软判决信息,经交织后,将此信息送至译码器2。
译码器2则将输出的软判决信息反馈给译码器1,作为下一次迭代的先验信息,同时,译码器2输出硬比特判决结果。
就这样,迭代译码继续进行下去,直到获得所需要的性能为止。
一般,迭代5-10次即可得到很好的结果。
然而,随着迭代的进行,后一次迭代产生的附加编码增益比前一次要小,以至达到一个极限,因此,并不是迭代次数越多性能就会有相应多的改善。
Turbo 译码一般使用软判决译码方法,软比特判决一般用后验对数似然比(LLR)的形式表示:L i = log ]|0[]|1[y m P y m P i i ==在输入端接收先验信息、在输出端产生后验信息的译码算法称为软输入软输出(SISO, Soft-input and soft-output)译码算法。
Viterbi 算法和MAP 算法经过改造可以成为SISO 算法。
设有一个码率为1/2、由RSC 码构成的SISO 译码器,它接收3个输入:系统通过噪声信道接收到的系统比特x i (未编码)、通过噪声信道接收到的校验输入比特y i 和接收比特的先验信息L a(i) (来自于另一个译码器的输出),产生LLR 输出L i 。
对于二元相移键控(BPSK)形式的调制,其输入输出之间的关系为:y' = a sE (2x-1) + n'式中,a 为衰落幅度,sE (2x-1)是BPSK 已调码元符号,E s 是每个码元符号的能量(若码率为r ,则它与每比特的能量符号E b 的关系是:E s = r E b ),n'为零均值、方差2σ= N 0/2的Gaussian 随机变量。
若a 为常数,则为加性白高斯噪声(AWGN)信道。
否则,称为慢衰落信道,不同的衰落类型a 有不同的分布,常见的是Rayleigh 分布和Rician 分布。
上式有另一种更为方便的表示形式:y = a(2x-1) + n式中,噪声n 的方差成为2 = N 0/2E s利用此信道模型在SISO 译码器输出端的对数似然输出为:L i = i s i x N Ea 04 + L a (i) + L e (i)式中,x i 为通过噪声信道接收到的未编码系统比特;L a(i)为先验信息,它来自于另一个译码器;L e(i)为外部信息,它表示当前译码得到的“新息(new information)”。
对于第一次迭代译码,第一个译码器没有先验信息,即L a1(i) = 0于是,得到:L i1 = i si x N E a 04 + L e1(i) 对于第二个译码器,第一次译码的先验信息L a2(i)为来自于第一个译码器的外部信息L e1(i),因此有L i2 = i s i x N Ea 04 + L e1(i) + L e2(i)对于第二次迭代,L e2(i)又作为第一个译码器的先验信息,就这样进行迭代循环。