译码方法最大后验概率译码
- 格式:ppt
- 大小:401.50 KB
- 文档页数:25

资料范本本资料为word版本,可以直接编辑和打印,感谢您的下载信息论与编码理论习题答案地点:__________________时间:__________________说明:本资料适用于约定双方经过谈判,协商而共同承认,共同遵守的责任与义务,仅供参考,文档可直接下载或修改,不需要的部分可直接删除,使用时请详细阅读内容第二章信息量和熵2.2 八元编码系统,码长为3,第一个符号用于同步,每秒1000个码字,求它的信息速率。
解:同步信息均相同,不含信息,因此每个码字的信息量为 2=23=6 bit因此,信息速率为 61000=6000 bit/s2.3 掷一对无偏骰子,告诉你得到的总的点数为:(a) 7; (b) 12。
问各得到多少信息量。
解:(1) 可能的组合为 {1,6},{2,5},{3,4},{4,3},{5,2},{6,1} ==得到的信息量 ===2.585 bit(2) 可能的唯一,为 {6,6}=得到的信息量===5.17 bit2.4 经过充分洗牌后的一副扑克(52张),问:(a) 任何一种特定的排列所给出的信息量是多少?(b) 若从中抽取13张牌,所给出的点数都不相同时得到多少信息量?解:(a) =信息量===225.58 bit(b)==信息量==13.208 bit2.9 随机掷3颗骰子,X表示第一颗骰子的结果,Y表示第一和第二颗骰子的点数之和,Z表示3颗骰子的点数之和,试求、、、、。
解:令第一第二第三颗骰子的结果分别为,,,相互独立,则,,==6=2.585 bit===2(36+18+12+9+)+6=3.2744 bit=-=-[-]而=,所以= 2-=1.8955 bit或=-=+-而= ,所以=2-=1.8955 bit===2.585 bit=+=1.8955+2.585=4.4805 bit2.10 设一个系统传送10个数字,0,1,…,9。
奇数在传送过程中以0.5的概率错成另外一个奇数,其余正确接收,求收到一个数字平均得到的信息量。

3线性分组码的几种最大似然译码算法本章系统地介绍了最大似然译码的原理和方法,并介绍了目前国内外出现的几种最大似然译码算法。
在已知接受值R的条件下,找出所有发送码字Ci中可能性最大的发送码字作为译码估值C‘,即C’=maxP(Ci|R)。
这种译码方法叫做最大后验概率译码,它是一种通过经验与归纳,由接收值推测发送码字的方法,是我们认为的最优译码算法。
但在实际译码时,后验概率的定量确定是很难的。
在已知R的条件下,使似然概率最大的译码算法叫做最大似然译码(MLD),即C'=maxP(R|Ci)。
在每个码字等概发送的条件下,根据Bayes准则很容易知道,最大似然译码等价于最大后验概率译码,因此也是最优的。
令R表示接收序列,c1表示可能的发送序列之一,P(R/C1)为发送C1时接收到R的概率,按照使P(R/C1)最大的准则进行译码。
1、所谓最大似然译码是指当所有码字的发送概率一样时,译码的错误概率达到最小的译码,软判决译码是指接收序列为实数序列(如与信号相匹配的滤波器的模拟输出)时的译码,亦即译码利用了信道的度量信息文献来源分阶统计译码算法(OSD)和Chase算法等都是一类最大似然译码算法(MLD)。
OSD分阶统计译码算法(OSD)【3】和盒匹配算法(BMA)等都是一类最大似然译码算法(MLD)本文主要研究了线性分组码的各种最大似然译码算法,内容包括通用最小码距译码算法、Chase译码算法、WED、PFS、RLSD、OSD、BMA等译码算法。
主要研究内容如下:1、充分研究了分组码的各种最大似然译码算法,比较详细地分析了其译码原理及纠错能力。
第三章介绍了线性分组码的各种最大似然译码算法。
3.3基于LRP的最大似然译码算法3.3.1 GMI)译码算法Chase译码算法WED(weighted erasure decoding)算法 (NIH算法本章系统地介绍了最大似然译码的原理和方法,并介绍了目前国内外出现的几种最大似然译码算法。




无线通信协议802.11n中Turbo码译码在我国发展历程Turbo码采用迭代的过程,而且采用的算法本身也比较复杂。
这些算法的关键是不但要能够对每比特进行译码,而且还要伴随着译码给出每比特译出的可靠性信息,有了这些信息,迭代才能进行下去。
用于Turbo码译码的具体算法有:MAP(Maximum A Posterori)Max-Log-MAP、Log-MAP和SOVA(Soft Output Viterbi Algorithm)算法。
MAP算法是1974年被用于卷积码的译码,但用作Turbo码的译码还是要做一些修改;Max-Log-MAP与Log-MAP是根据MAP算法在运算量上做了重大改进,虽然性能有些下降,但使得Turbo码的译码复杂度大大的降低了,更加适合于实际系统的运用;Viterbi算法并不适合Turbo码的译码,原因就是没有每比特译出的可靠性信息输出,修改后的具有软信息输出的SOVA算法,就正好适合了Turbo码的译码。
这些算法在复杂度上和性能上具有一定的差异,系统地了解这些算法的原理是对Turbo码研究的基础,同时对这些算法的复杂度和性能的比较研究也将有助于Turbo的应用研究。
Turbo码的仿真一般参考吴宇飞的经典程序。
此外,要想在移动无线系统中成功的使用Turbo码,首先要考虑在语音传输中最大延迟的限制。
在短帧情况下的仿真结果表明短交织Turbo码在AWGN 信道和Rayleigh衰落下仍然具有接近信道容量的纠错能力,从而显示出Turbo 码在移动无线通信系统中非常广阔的应用前景。
Turbo码(Turbo Code)Turbo 码(Turbo Code)是一类应用在外层空间卫星通信和设计者寻找完成最大信息传输通过一个限制带宽通信链路在数据破坏的噪声面前的其它无线通信应用程序的高性能纠错码。
有两类Turbo 码在那里,块Turbo 码和卷积Turbo 码(CTCs),它们是相当不同的,因为它们使用不同的构件码,不同的串联方案和不同的SISO 算法。

极码:主要概念和实用译码算法摘要极码代表一类新兴的纠错码,他的功率接近一个离散无记忆信道的容量。
本文旨在说明其生成与解码技术的原则。
与传统能力编码策略不同,它试图让代码尽可能随机,极性代码遵循不同的原理,这也是由香农通过创建一个典型共同组提出的。
信道极化,一个概念的核心,就是极性代码,在数字世界中的马太效应之中被直观地阐述,对极性编码的构造方法进行了详细的概述。
极性码蝴蝶结构介绍中,源位相关,证明SC算法的使用为有效的解码。
从概念和实践的角度研究了供应链解码技术。
最先进的解码算法,如BP和一些广义的SC解码,也在一个广泛的框架下解释了。
仿真结果表明,极性码的级联与CRC码的性能优于Turbo码和LDPC码。
一些在实际情况下有前途的研究方向在最后也被讨论。
摘要 (1)引言 (1)通道极化 (2)编码和结构 (4)编码原则 (5)通道选择 (6)连续取消解码 (7)解码原理 (8)简单SC译码过程 (9)更有力的译码算法 (10)提高的SC译码过程 (10)CRC-AIDED解码 (12)置信传播解码 (12)ML或MAP解码 (12)优点和缺点 (13)极性码的缺点 (14)未来的研究方向 (15)结论 (16)附录 (16)引言在过去的六年中见证了数字通信编码理论的成功。
克劳德·香农著名的信道编码定理断言代码的存在,信息可以在可靠的噪声信道上传输速率信道容量。
三个基本想法背后的信道编码定理的证明是:(1).随机选择的代码(2).对于大型代码长度的联合渐近等分(AEP)之间的传输码字和接收序列。
(3).最优最大似然(ML)解码或次优联合典型的解码。
联合AEP在证明过程中扮演着重要的角色,在某种意义上,它保证接收到的序列与共同典型传输码字相似,并且共同典型解码错误的概率消失。
当然随机编码也很重要,但只是为了便于数学证明好的代码的存在。
逼近能力与实际编/解码复杂度是编码理论的一个主要挑战。
幸运的是,在过去的二十年里许多“turbo-like”代码家族,如涡轮码和低密度奇偶校验(LDPC)码,已经被发现实现这一目标。

第5章 有噪信道编码5.1 基本要求通过本章学习,了解信道编码的目的,了解译码规则对错误概率的影响,掌握两种典型的译码规则:最佳译码规则和极大似然译码规则。
掌握信息率与平均差错率的关系,掌握最小汉明距离译码规则,掌握有噪信道编码定理(香农第二定理)的基本思想,了解典型序列的概念,了解定理的证明方法,掌握线性分组码的生成和校验。
5.2 学习要点5.2.1 信道译码函数与平均差错率5.2.1.1 信道译码模型从数学角度讲,信道译码是一个变换或函数,称为译码函数,记为F 。
信道译码模型如图5.1所示。
5.2.1.2 信道译码函数信道译码函数F 是从输出符号集合B 到输入符号集合A 的映射:*()j j F b a A =∈,1,2,...j s =其含义是:将接收符号j b B ∈译为某个输入符号*j a A ∈。
译码函数又称译码规则。
5.2.1.3 平均差错率在信道输出端接收到符号j b 时,按译码规则*()j j F b a A =∈将j b 译为*j a ,若此时信道输入刚好是*j a ,则称为译码正确,否则称为译码错误。
j b 的译码正确概率是后验概率:*(|)()|j j j j P X a Y b P F b b ⎡⎤===⎣⎦ (5.1)j b 的译码错误概率:(|)()|1()|j j j j j P e b P X F b Y b P F b b ⎡⎤⎡⎤=≠==-⎣⎦⎣⎦ (5.2)平均差错率是译码错误概率的统计平均,记为e P :{}1111()(|)()1()|1(),1()|()s se j j j j j j j ssj j j j j j j P P b P e b P b P F b b P F b b P F b P b F b ====⎡⎤==-⎣⎦⎡⎤⎡⎤⎡⎤=-=-⎣⎦⎣⎦⎣⎦∑∑∑∑ (5.3)5.2.2 两种典型的译码规则两种典型的译码规则是最佳译码规则和极大似然译码规则。

第十三章T u r b o码Shannon理论证明,随机码是好码,但是它的译码却太复杂。
因此,多少年来随机编码理论一直是作为分析与证明编码定理的主要方法,而如何在构造码上发挥作用却并未引起人们的足够重视。
直到1993年,Turbo码的发现,才较好地解决了这一问题,为Shannon 随机码理论的应用研究奠定了基础。
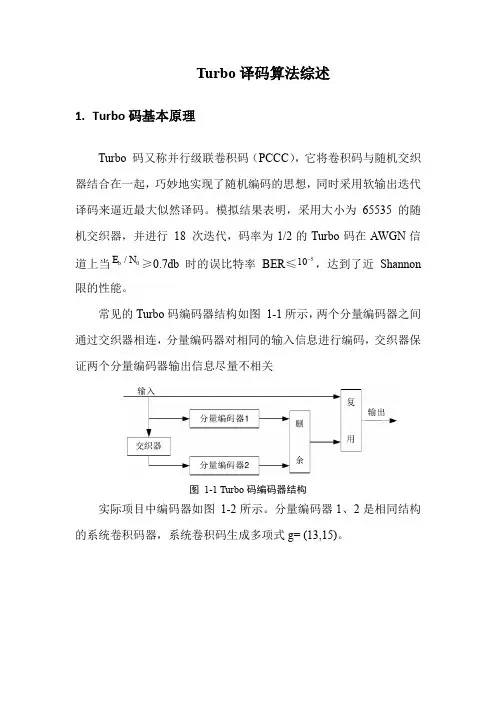
Turbo码,又称并行级连卷积码(PCCC),是由C. Berrou等在ICC’93会议上提出的。
码R史。
需要说明的是,由于原Turbo编译码方案申请了专利,因此在有关Turbo码的第一篇文章中,作者没有给出如何进行迭代译码的实现细节,只是从原理上加以说明。
此后,P. Robertson对此进行了探讨,对译码器的工作原理进行了详细说明。
人们依此进行了大量的模拟研究。
Turbo码的提出,更新了编码理论研究中的一些概念和方法。
现在人们更喜欢基于概率的软判决译码方法,而不是早期基于代数的构造与译码方法,而且人们对编码方案的比较方法也发生了变化,从以前的相互比较过渡到现在的均与Shannon限进行比较。
同时,也使编码理论家变成了实验科学家。
图13-1 AWGN信道中的码率与Shannon限关于Turbo码的发展历程,C. Berrou等在文[4]中给出了详细的说明。
因为C. Berrou 主要从事的是通信集成电路的研究,所以他们将SOVA译码器看作是“信噪比放大器”,从码的发N余(puncturing)技术从这两个校验序列中周期地删除一些校验位,形成校验位序列X p。
X p与未编码序列X s经过复用调制后,生成了Turbo码序列X。
例如,假定图13-2中两个分量编码器的码率均是1/2,为了得到1/2码率的Turbo码,可以采用这样的删余矩阵:P [1 0, 0 1],即删去来自RSC1的校验序列X p1的偶数位置比特与来自RSC2的校验序列X p2的奇数位置比特。
图13-2 Turbo码编码器结构框图为交织器后信息序列变为:)1101010(~=c第二个分量码编码器所输出的校验位序列为:)1000000(2=v 则Turbo 码序列为:§13.3 Turbo 码的译码一.Turbo 码的迭代译码原理由于Turbo 码是由两个或多个分量码对同一信息序列经过不同交织后进行编码,对任何单个传统编码,通常在译码器的最后得到硬判决译码比特,然而Turbo 码译码算法不应限制在译码器中通过的是硬判决信息,为了更好的利用译码器之间的信息,译码算法所用的应当是软判决信息而不是硬判决。

卷积码的维特比译码卷积编码器自身具有网格构造,基于此构造我们给出两种译码算法:Viterbi 译码算法和BCJR 译码算法。
基于某种准那么,这两种算法都是最优的。
1967 年,Viterbi 提出了卷积码的Viterbi 译码算法,后来Omura 证明Viterbi 译码算法等效于在加权图中寻找最优途径问题的一个动态规划〔Dynamic Programming〕解决方案,随后,Forney 证明它实际上是最大似然〔ML,Maximum Likelihood〕译码算法,即译码器选择输出的码字通常使接收序列的条件概率最大化。
BCJR 算法是1974 年提出的,它实际上是最大后验概率〔MAP,Maximum A Posteriori probability〕译码算法。
这两种算法的最优化目的略有不同:在MAP 译码算法中,信息比特错误概率是最小的,而在ML 译码算法中,码字错误概率是最小的,但两种译码算法的性能在本质上是一样的。
由于Viterbi 算法实现更简单,因此在实际应用比较广泛,但在迭代译码应用中,例如逼近Shannon 限的Turbo 码,常使用BCJR 算法。
另外,在迭代译码应用中,还有一种Viterbi 算法的变种:软输出Viterbi 算法〔SOV A,Soft-Output Viterbi Algorithm〕,它是Hagenauer 和Hoeher 在1989 年提出的。
为了理解Viterbi 译码算法,我们需要将编码器状态图按时间展开〔因为状态图不能反映出时间变化情况〕,即在每个时间单元用一个分隔开的状态图来表示。
例如〔3,1,2〕非系统前馈编码器,其生成矩阵为:G(D)=[1+D1+D21+D+D2]〔1〕图1 〔a〕〔3,1,2〕编码器〔b〕网格图〔h=5〕假定信息序列长度为h=5,那么网格图包含有h+m+1=8 个时间单元,用0 到h+m=7 来标识,如图1〔b〕所示。
假设编码器总是从全0 态S0 开始,又回到全0 态,前m=2 个时间单元对应于编码器开始从S0“启程〞,最后m=2 个时间单元对应于向S0“返航〞。