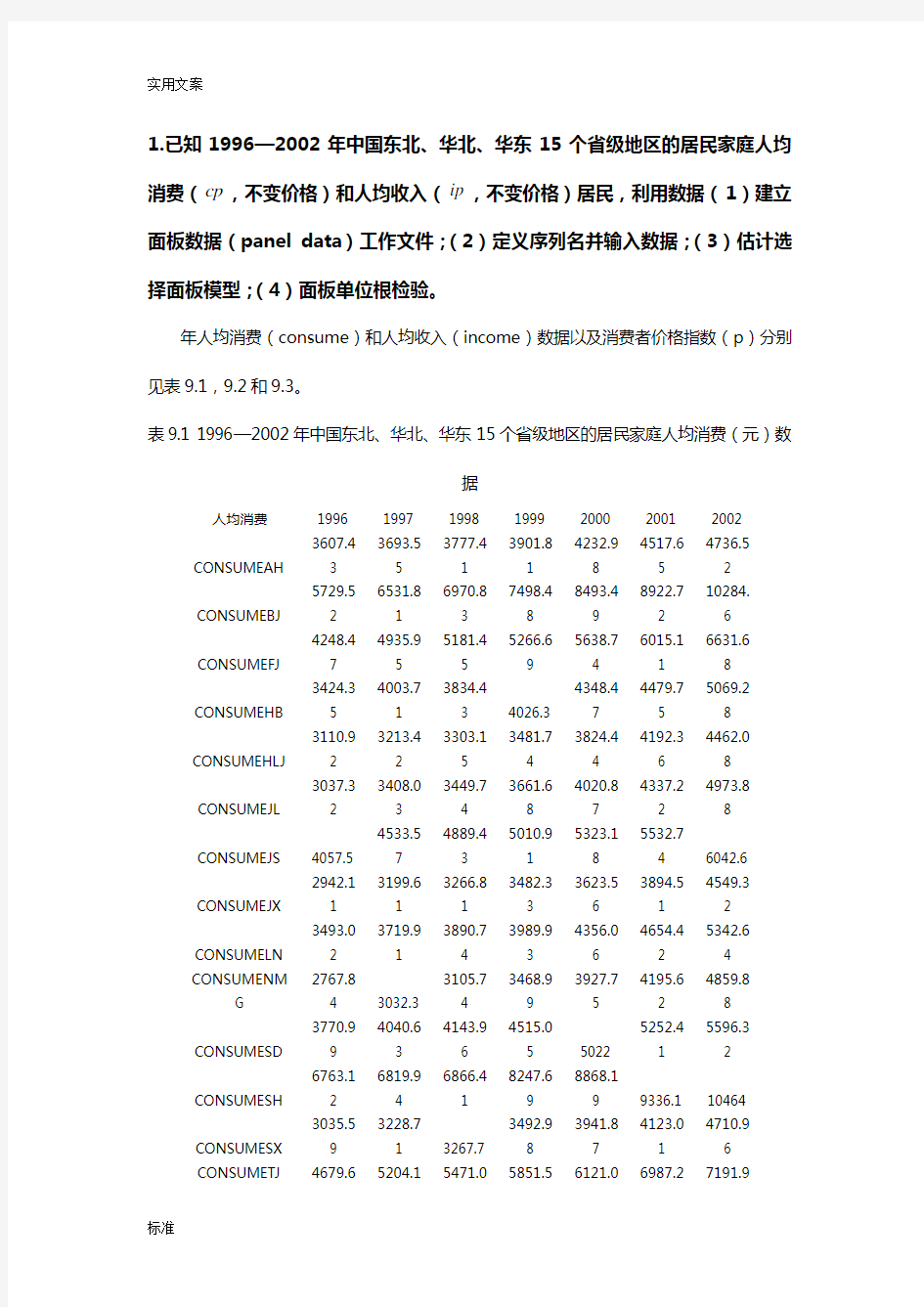

1.已知1996—2002年中国东北、华北、华东15个省级地区的居民家庭人均消费(cp,不变价格)和人均收入(ip,不变价格)居民,利用数据(1)建立面板数据(panel data)工作文件;(2)定义序列名并输入数据;(3)估计选择面板模型;(4)面板单位根检验。
年人均消费(consume)和人均收入(income)数据以及消费者价格指数(p)分别见表9.1,9.2和9.3。
表9.1 1996—2002年中国东北、华北、华东15个省级地区的居民家庭人均消费(元)数
据
人均消费1996 1997 1998 1999 2000 2001 2002
CONSUMEAH 3607.4
3
3693.5
5
3777.4
1
3901.8
1
4232.9
8
4517.6
5
4736.5
2
CONSUMEBJ 5729.5
2
6531.8
1
6970.8
3
7498.4
8
8493.4
9
8922.7
2
10284.
6
CONSUMEFJ 4248.4
7
4935.9
5
5181.4
5
5266.6
9
5638.7
4
6015.1
1
6631.6
8
CONSUMEHB 3424.3
5
4003.7
1
3834.4
3 4026.3
4348.4
7
4479.7
5
5069.2
8
CONSUMEHLJ 3110.9
2
3213.4
2
3303.1
5
3481.7
4
3824.4
4
4192.3
6
4462.0
8
CONSUMEJL 3037.3
2
3408.0
3
3449.7
4
3661.6
8
4020.8
7
4337.2
2
4973.8
8
CONSUMEJS 4057.5 4533.5
7
4889.4
3
5010.9
1
5323.1
8
5532.7
4 6042.6
CONSUMEJX 2942.1
1
3199.6
1
3266.8
1
3482.3
3
3623.5
6
3894.5
1
4549.3
2
CONSUMELN 3493.0
2
3719.9
1
3890.7
4
3989.9
3
4356.0
6
4654.4
2
5342.6
4
CONSUMENM
G 2767.8
4 3032.3
3105.7
4
3468.9
9
3927.7
5
4195.6
2
4859.8
8
CONSUMESD 3770.9
9
4040.6
3
4143.9
6
4515.0
5 5022
5252.4
1
5596.3
2
CONSUMESH 6763.1
2
6819.9
4
6866.4
1
8247.6
9
8868.1
9 9336.1 10464
CONSUMESX 3035.5
9
3228.7
1 3267.7
3492.9
8
3941.8
7
4123.0
1
4710.9
6
CONSUMETJ 4679.65204.15471.05851.56121.06987.27191.9
1 5 1 3 4
2 6
CONSUMEZJ 5764.2
7
6170.1
4
6217.9
3
6521.5
4
7020.2
2
7952.3
9
8713.0
8
表9.2 1996—2002年中国东北、华北、华东15个省级地区的居民家庭人均收入(元)数
据
人均收入1996 1997 1998 1999 2000 2001 2002
INCOME
AH 4512.7
7
4599.2
7
4770.4
7 5064.6 5293.55 5668.8 6032.4
INCOME
BJ 7332.0
1
7813.1
6
8471.9
8 9182.76
10349.6
9
11577.7
8
12463.9
2
INCOME
FJ 5172.9
3
6143.6
4
6485.6
3 6859.81 7432.26 8313.08 9189.36
INCOME
HB 4442.8
1
4958.6
7
5084.6
4 5365.03 5661.16 5984.82 6679.68
INCOME HLJ 3768.3
1
4090.7
2 4268.5 4595.14 4912.88 5425.87 6100.56
INCOME
JL 3805.5
3
4190.5
8
4206.6
4 4480.01 4810 5340.46 6260.16
INCOME
JS 5185.7
9 5765.2
6017.8
5 6538.2 6800.23 7375.1 8177.64
INCOME
JX 3780.2 4071.3
2
4251.4
2 4720.58 5103.58 5506.02 6335.64
INCOME
LN 4207.2
3 4518.1
4617.2
4 4898.61 5357.79 5797.01 6524.52
INCOME NMG 3431.8
1
3944.6
7
4353.0
2 4770.5
3 5129.05 5535.89 6051
INCOME
SD 4890.2
8
5190.7
9
5380.0
8 5808.96 6489.97 7101.08 7614.36
INCOME
SH 8178.4
8
8438.8
9 8773.1
10931.6
4
11718.0
1
12883.4
6 13249.8
INCOME
SX 3702.6
9
3989.9
2
4098.7
3 4342.61 4724.11 5391.05 6234.36
INCOME
TJ 5967.7
1
6608.3
9
7110.5
4 7649.83 8140.
5 8958.7 9337.56
INCOME
ZJ 6955.7
9
7358.7
2
7836.7
6 8427.95 9279.16
10464.6
7 11715.6
表9.3 1996—2002年中国东北、华北、华东15个省级地区的消费者物价指数
(1)建立面板数据工作文件
首先建立工作文件。打开工作文件后,过程如下:
物价指数 1996
1997 1998
1999
2000 2001 200
2
PAH 109.
9 101.3 100 97.8 100.7 100.5 99 PBJ 111.6 105.3 102.4
100.6
103.5 103.1
98.2 PFJ 105.9 101.7 99.7
99.1
102.1
98.7 99.5
PHB 107.1 103.5 98.4 98.1
99.7
100.5 99 PHLJ 107.1 104.4 100.4
96.8
98.3
100.8 99.3 PJL 107.2 103.7 99.2
98
98.6 101.3 99.5 PJS 109.3 101.7
99.4
98.7
100.1 100.8
99.2 PJX 108.4 102 101
98.6
100.3
99.5
100.1 PLN 107.9 103.1 99.3
98.6
99.9 100 98.9 PNMG 107.6 104.5 99.3
99.8
101.3 100.6 100.2
PSD 109.6 102.8 99.4
99.3 100.2 101.8
99.3 PSH 109.2 102.8 100 101.5
102.5 100 100.5 PSX 107.9 103.1 98.6
99.6
103.9
99.8 98.4
PTJ 109 103.1 99.5
98.9
99.6
101.2
99.6 PZJ
107.9
102.8
99.7
98.8
101
99.8
99.1
建立面板数据库。
在窗口中输入15个不同省级地区的标识。
(2)定义序列名并输入数据
产生3*15个尚未输入数据的变量名。这样可以通过键盘输入或黏贴的方法数据数据。
(3)估计、选择面板模型
打开一个pool窗口,先输入变量后缀(所要使用的变量)。点击Estimate,打开估计窗口。
A.混合模型的估计方法
左边的Common表示相同系数,即表示不同个体有相同的斜率。
得到如下输出结果:
相应的表达式是:
?129.630.76it it
CP IP =+ (2.0)
(79.7)
20.98,4824588r R SSE ==
上式表示15个省级地区的城镇人均指出平均占收入的76%。
B.个体固定效应回归模型的估计方法
将截距项选择区选Fixed effects (固定效应)
得到如下输出结果:
相应的表达式为:
1215
?515.60.7036.3537.6...198.6it it CP IP D D D =+-+++ (6.3) (55) 2
0.99,2270386r R SSE ==
其中虚拟变量1215,,...,D D D 的定义是:
1,1,2,...,150,i i i D =?=??如果属于第个个体
,其他
15个省级地区的城镇人均指出平均占收入70%。从上面的结果可以看出北京市
居民的自发性消费明显高于其他地区。
接下来用F 统计量检验是应该建立混合回归模型,还是个体固定效应回归模型。
0H :i αα=。模型中不同个体的截距相同(真实模型为混合回归模型)。 1H :模型中不同个体的截距项i α不同(真实模型为个体固定效应回归模型)。
F 统计量定义为:
()/[(1)()]()/(1)
/()/()
r u r u u u SSE SSE NT k NT N k SSE SSE N F SSE NT N k SSE NT N k --------=
=----
其中r SSE 表示约束模型,即混合估计模型的残差平方和,u SSE 表示非约束模型,即个体固定效应回归模型的残差平方和。非约束模型比约束模型多了1N -个被估参数。
所以本例中:
0.05(4824588227386)/(151)
8.1(14,89) 1.82270386/(105151)
F F --=
==--f
所以推翻原假设,建立个体固定效应回归模型更合理。
C.时点固定效应回归模型的估计方法 将时间选择为固定效应。
得到如下输出结果:
相应的表达式为:
127
? 2.60.78105.9134.1...93.9it it CP IP D D D =++++- (76.6) 2
0.987,4028843R SSE ==
其中虚拟变量127,,...,D D D 的定义是:
1,0,t D ?=??如果属于第t 个截面,t=1996,...,2002其他
D.个体随机效应回归模型估计
截距项选择Random effects(个体随机效应)
得到如下部分输出结果:
相应的表达式是:
1215
?345.20.72 2.6367.0...106.1it it CP IP D D D =+-+++ (68.5) 2
0.98,2979246R SSE ==
其中虚拟变量1215,,...,D D D 的定义是:
1,0,i D ?=??
如果属于第i 个个体,i=1,2,...,15其他
接下来利用Hausman 统计量检验应该建立个体随机效应回归模型还是个体固定效应回归模型。
0H :个体效应与回归变量(it IP )无关(个体随机效应回归模型) 1H :个体效应与回归变量(it IP )相关(个体固定效应回归模型)
分析过程如下:
得到如下检验结果:
由检验输出结果的上半部分可以看出,Hausman统计量的值是14.79,相对应的概率是0.0001,即拒接原假设,应该建立个体固定效应模型。
检验结果的下半部分是Hausman检验中间结果比较。个体固定效应模型对参数的估计值为0.697561,随机效应模型对参数的估计值为0.724569。两个参数的估计量的分布方差的差为0.000049。
综上分析,1996—2002年中国东北、华北、华东15个省级地区的居民家庭人均消费和人金收入问题应该建立个体固定效应回归模型。人均消费平均占人均收入的70%。随地区不同,自发消费(截距项)存在显著性差异。
(4)面板单位根检验
以cp序列为例。
首先在工作文件窗口中打开cp变量的15个数据组。
单位根检验过程如下:
计量经济学E v i e w s多重共线性实验报告 Company Document number:WUUT-WUUY-WBBGB-BWYTT-1982GT
实验报告课程名称计量经济学 实验项目名称多重共线性 班级与班级代码 专业 任课教师 学号: 姓名: 实验日期: 2014 年 05 月 11日 广东商学院教务处制 姓名实验报告成绩 评语: 指导教师(签名) 年月日 说明:指导教师评分后,实验报告交院(系)办公室保存。 计量经济学实验报告 一、实验目的:掌握多元线性回归模型的估计方法、掌握多重共线性模型的识别和修正。 二、实验要求:应用教材第127页案例做多元线性回归模型,并识别和修正多重共线性。 三、实验原理:普通最小二乘法、简单相关系数检验法、综合判断法、逐步回归法。
四、预备知识:最小二乘法估计的原理、t检验、F检验、2R值。 五、实验步骤 1、选择数据 理论上认为影响能源消费需求总量的因素主要有经济发展水平、收入水平、产业发展、人民生活水平提高、能源转换技术等因素。为此,收集了中国能源消费标准煤总量、国民总收入、国内生产总值GDP、工业增加值、建筑业增加值、交通运输邮电业增加值、人均生活电力消费、能源加工转换效率等1985——2007年的统计数据。本题旨在通过建立这些经济变量的线性模型来说明影响能源消费需求总量的原因。主要数据如下: 1985~2007年统计数据
资料来源:《中国统计年鉴》,中国统计出版社2000、2008年版。 为分析Y 与X1、X2、X3、X4、X5、X6、X7之间的关系,做如下折线图: 能源消费Y 在1986到1996年间缓慢增长,在96至98年有短暂的下跌,但是98至02年开始缓慢回升,02年到06年开始快速增长。 国民总收入X1和国内生产总值X2以相同的趋势逐年缓慢增长。 工业增加值X3在1985年-1999年期间一直是缓慢增长,但在2000年出现了急剧下降的现象,2001年又急剧增长,达到下降前的水平,2001年以后开始缓慢增长。建筑业增长值x4、交通运输邮电业增加值x5、人均生活电力消费x6、能源加工转换效率x7数值较低,但都以较平缓的方式增长。 2、设定并估计多元线性回归模型 t t t t t t t u X X X X X Y ++++++=66554433221ββββββ () 录入数据,得到图。 2.2.1)采用OLS 估计参数 在主界面命令框栏中输入 ls y c x1 x2 x3 x4 x5 x6 x7回车,即可得到参数的估计结果。 由此可见,该模型的可决系数为,修正的可决系数为,模型拟和很好,F 统计量为,回归方程整体上显着。 可是其中的lnX3、lnX4、lnX6对lnY 影响不显着,不仅如此,lnX2、lnX5的参数为负值,在经济意义上不合理。所以这样的回归结果并不理想。 3、多重共线性模型的识别
大连海事大学 实验报告 实验名称:计量经济学软件应用 专业班级:财务管理2013-1 姓名:安妮 指导教师:赵冰茹 交通运输管理学院 二○一六年十一月 一、实验目标 学会常用经济计量软件的基本功能,并将其应用在一元线性回归模型的分析中。具体包括:Eview的安装,样本数据基本统计量计算,一元线性回归模型的建立、检验及结果输出与分析,多元回归模型的建立与分析,异方差、序列相关模型的检验与处理等。二、实验环境 WINDOWSXP或2000操作系统下,基于EVIEWS5.1平台。 三、实验模型建立与分析 案例1:
我国1995-2014年的人均国民生产总值和居民消费支出的统计资料(此资料来自中华人民共和国统计局网站)如表1所示,做回归分析。 表1我国1995-2014年人均国民生产总值与居民消费水平情况
(1)做出散点图,建立居民消费水平随人均国内生产总值变化的一元线性回归方程,并解释斜率的经济意义; 利用eviews软件输出结果报告如下: Dependent Variable: CONSUMPTION Method: Least Squares Date: 06/11/16 Time: 19:02 Sample: 1995 2014 Included observations: 20
Variable Coeffici ent Std. Error t-Statisti c Prob.?? C691.0225113.3920 6.0941040.0000 AVGDP0.3527700.00490871.880540.0000 R-squared0.996528????Mean dependent var7351.300 Adjusted R-squared0.996335????S.D. dependent var4828.765 S.E. of regression292.3118????Akaike info criterion14.28816 Sum squared resid1538032.????Schwarz criterion14.38773 Log likelihood -140.881 6 ????Hannan-Quinn criter.14.30760 F-statistic5166.811????Durbin-Watson stat0.403709 Prob(F-statistic)0.000000 由上表可知财政收入随国内生产总值变化的一元线性回归方程为:
统计分析报告 基于eviews软件的湖北省人均GDP时间序列模型构建与预测 姓名:刘金玉 学院:经济管理学院 学号:20121002942 指导教师:李奇明 日期:2014年12月14日
基于eviews软件的湖北省人均GDP时间序列 模型构建与预测 1、选题背景 改革开放以来,中国的经济得到飞速发展。1978年至今,中国GDP年均增长超过9%。中国的经济实力明显增强。2001年GDP超过1.1万亿美元,排名升到世界第六位。外汇储备已达2500亿美元。市场在资源配置中已经明显地发挥基础性作用。公有、私有、外资等多种所有制经济共同发展的格局基本形成。宏观调控体系初步建立。我国社会生产力、综合国力、地区发展、产业升级、所有制结构、商品供求等指标均反映出我国经济运行质量良好,为实现第三步战略。在全国的经济飞速发展的大环境下,各省GDP的增长也是最能反映其经济发展状况的指标。而人均 GDP 是最能体现一个省的经济实力、发展水平和生活水准的综合性指标,它不仅考虑了经济总量的大小,而且结合了人口多少的因素,在国际上被广泛用于评价和比较一个地区经济发展水平。尤其是我们这样的人口大国,用这一指标反映经济增长和发展情况更加准确、深刻和富有现实意义。深入分析这一指标对于反映我国经济发展历程、探讨增长规律、研究波动状况,制定相应的宏观调控政策有着十分重要的意义。 本文是以湖北省人均GDP作为研究对象。湖北省人均GDP的增长速度在上世纪90年代增长率有下滑的趋势(见表1)。进入21世纪,继东部沿海地区先发展起来,并涌现出环渤海、长三角、珠三角等城市群,以及中共中央提出“西部大开发”的战略后,中部地区成了“被遗忘的区域”,中部地区经济发展严重滞后于东部沿海地区,为此,中共中央提出了“中部崛起”的重大战略决策。自2004年提出“中部崛起”的重要战略构思后,山西、河南、安徽、湖北、湖南、江西六个省都依托自己的资源和地理优势来扩大地区竞争力,湖北省尤为突出。那么,研究湖北省人均GDP的统计规律性和变动趋势,对于了解湖北省的经济增长规律以及地方政策的制定有特别重要的意义。因此本文试图以湖北省1978-2013年人均GDP 历史数据为样本,通过ARMA 模型对样本进行统计分析,以揭示湖北省人均GDP变化的内在规律性,建立计量经济模型,并在此基础上进行短期外推预测,作为湖北未来几年经济发展的重要参考依据。
第4章图形和统计量分析 EViews软件提供了序列(Series)和序列组(Group)等对象的各种视图、统计分析方法和过程。当序列对象中输入数据后,就可对序列对象中输入的数据进行统计分析,并且可以通过图、表等形式进行描述。本章将介绍序列和序列组对象图形的生成和描述性统计量及其检验。 4.1 图形对象 图形(Graph)对象可以形成序列和序列组等对象的各种视图,如线图(Line)、散点图(Scatter)以及饼图(Pie)等。通过图形可以进一步观察和分析数据的变化趋势和规律。下面介绍图形对象的基本操作。 4.1.1 图形(Graph)对象的生成 图形对象也是工作文件中的基本对象之一。要生成图形对象需首先打开序列对象窗口或序列组对象窗口,选择对象窗口工具栏中的“View”|“Graph”选项。选择的对象类型不同,将弹出不同的窗口。如果在序列对象窗口下选择“View”|“Graph”选项,将弹出如图4-1所示的界面。
. . 图4-1 序列窗口下图形对象的生成 此时“Graph”弹出的菜单中有6种图形可供选择。“Line”表示生成的是折线图,如图4-2所示,其横轴表示时间或序列的顺序,纵轴表示序列对象观测值的大小。“Area”表示生成面积图,其图形的形状与“Line”(折线图)相同,不同的是“Area”(面积图)曲线下方是被填满的,而“Line”(折线图)下方是空白。 图4-2 “Line”折线图 “Bar”表示为条形图,用条状的高度表示观测值的大小。“Spike”表示尖峰图,由竖线组成,每根竖线的高度代表观测值的大小。“Seasonal Stacked Line”表示生成的是季节性堆叠图,“Seasonal Split Line”表示生成的是季节性分割线。 如果在序列组(群)对象窗口下选择“View”|“Graph”选项,将弹出如图4-3所示的界面。这里有9种图形可供选择。其前4种与上面讲述的相同。 图4-3 序列组(群)窗口下图对象的生成
实验四虚拟变量 【实验目的】 掌握虚拟变量的基本原理,对虚拟变量的设定和模型的估计与检验,以及相关的Eviews操作方法。 【实验内容】 试根据1998年我国城镇居民人均收入与彩电每百户拥有量的统计资料建立 我国城镇居民彩电需求函数。 【实验步骤】 1、相关图分析 根据表中数据建立人均收入X与彩电拥有量Y的相关图(SCAT X Y)。从相关图可以看出,前3个样本点(即低收入家庭)与后5个样本点(中、高收入)的拥有量存在较大差异,
因此,为了反映“收入层次”这一定性因素的影响,设置虚拟变量如下: ?? ?=低收入家庭 中、高收入家庭 1D 2、构造虚拟变量 构造虚拟变量 1D (DATA D1),并生成新变量序列: GENR XD=X*D1 3、估计虚拟变量模型 LS Y C X D1 XD 得到估计结果: 我国城镇居民彩电需求函数的估计结果为: XD D X Y 009.0873.31012.0611.571-++=∧ (16.25) (9.03) (8.32) (-6.59) 366,066.1..,9937.02===F e s R 再由t 检验值判断虚拟变量的引入方式,并写出各类家庭的需求函数。 虚拟变量的回归系数的t 检验都是显著的,且模型的拟合优度很高,说明我国城镇居民低收入家庭与中高收入家庭对彩电的消费需求,在截距和斜率上都存在着明显差异,所以以加法和乘法方式引入虚拟变量是合理的。
低收入家庭与中高收入家庭各自的需求函数为: 低收入家庭: ∧ . 57+ = 611 X Y012 .0 中高收入家庭: ∧ 611 . 873 31 . 57 (+ + + - = = 012 .0 484 ) X X . Y003 .0( .0 009 ) 89 由此可见我国城镇居民家庭现阶段彩电消费需求的特点: 对于人均年收入在3300元以下的低收入家庭,需求量随着收入水平的提高而快速上升,人均年收入每增加1000元,百户拥有量将平均增加12台;对于人均年收入在4100元以上的中高收入家庭,虽然需求量随着收入水平的提高也在增加,但增速趋缓,人均年收入每增加1000元,百户拥有量只增加3台。 事实上,现阶段我国城镇居民中国收入家庭的彩电普及率已达到百分之百,所以对彩电的消费需求处于更新换代阶段。
e v i e w s统计分析报告 IMB standardization office【IMB 5AB- IMBK 08- IMB 2C】
统计分析报告 基于eviews软件的湖北省人均GDP时间序 列模型构建与预测 姓名:刘金玉 学院:经济管理学院 学号: 指导教师:李奇明 日期:2014年12月14日
基于eviews软件的湖北省人均GDP时间序列 模型构建与预测 1、选题背景 改革开放以来,中国的经济得到飞速发展。1978年至今,中国GDP年均增长超过9%。中国的经济实力明显增强。2001年GDP超过万亿美元,排名升到世界第六位。外汇储备已达2500亿美元。市场在资源配置中已经明显地发挥基础性作用。公有、私有、外资等多种所有制经济共同发展的格局基本形成。宏观调控体系初步建立。我国社会生产力、综合国力、地区发展、产业升级、所有制结构、商品供求等指标均反映出我国经济运行质量良好,为实现第三步战略。在全国的经济飞速发展的大环境下,各省GDP的增长也是最能反映其经济发展状况的指标。而人均GDP是最能体现一个省的经济实力、发展水平和生活水准的综合性指标,它不仅考虑了经济总量的大小,而且结合了人口多少的因素,在国际上被广泛用于评价和比较一个地区经济发展水平。尤其是我们这样的人口大国,用这一指标反映经济增长和发展情况更加准确、深刻和富有现实意义。深入分析这一指标对于反映我国经济发展历程、探讨增长规律、研究波动状况,制定相应的宏观调控政策有着十分重要的意义。 本文是以湖北省人均GDP作为研究对象。湖北省人均GDP的增长速度在上世纪90年代增长率有下滑的趋势(见表1)。进入21世纪,继东部沿海地区先发展起来,并涌现出环渤海、长三角、珠三角等城市群,以及中共中央提出“西部大开发”的战略后,中部地区成了“被遗忘的区域”,中部地区经济发展严重滞后于东部沿海地区,为此,中共中央提出了“中部崛起”的重大战略决策。自2004年提出“中部崛起”的重要战略构思后,山西、河南、安徽、湖北、湖南、江西六个省都依托自己的资源和地理优势来扩大地区竞争力,湖北省尤为突出。那么,研究湖北省人均GDP的统计
大连海事大学 实验报告Array 实验名称:计量经济学软件应用专业班级:财务管理2013-1 姓名:安妮 指导教师:赵冰茹 交通运输管理学院 二○一六年十一月
一、实验目标 学会常用经济计量软件的基本功能,并将其应用在一元线性回归模型的分析中。具体包括:Eview的安装,样本数据基本统计量计算,一元线性回归模型的建立、检验及结果输出与分析,多元回归模型的建立与分析,异方差、序列相关模型的检验与处理等。 二、实验环境 WINDOWSXP或2000操作系统下,基于EVIEWS5.1平台。 三、实验模型建立与分析 案例1: 我国1995-2014年的人均国民生产总值和居民消费支出的统计资料(此资料来自中华人民共和国统计局网站)如表1所示,做回归分析。 表1我国1995-2014年人均国民生产总值与居民消费水平情况
(1)做出散点图,建立居民消费水平随人均国内生产总值变化的一元线性回归方程,并解释斜率的经济意义; 利用eviews软件输出结果报告如下:
Dependent Variable: CONSUMPTION Method: Least Squares Date: 06/11/16 Time: 19:02 Sample: 1995 2014 Included observations: 20 Variable Coefficient Std. Error t-Statistic Prob. C 691.0225 113.3920 6.094104 0.0000 AVGDP 0.352770 0.004908 71.88054 0.0000 R-squared 0.996528 Mean dependent var 7351.300 Adjusted R-squared 0.996335 S.D. dependent var 4828.765 S.E. of regression 292.3118 Akaike info criterion 14.28816 Sum squared resid 1538032. Schwarz criterion 14.38773 Log likelihood -140.8816 Hannan-Quinn criter. 14.30760 F-statistic 5166.811 Durbin-Watson stat 0.403709 Prob(F-statistic) 0.000000 由上表可知财政收入随国内生产总值变化的一元线性回归方程为: (令Y=CONSUMPTION,X=AVGDP(此处代表人均GDP)) Y = 691.0225+0.352770* X 其中斜率0.352770表示国内生产总值每增加一元,人均消费水平增长0.35277元。 检验结果R2=0.996528,说明99.6528%的样本可以被模型解释,只有0.3472%的样本未被解释,因此样本回归直线对样本点的拟合优度很高。 (2)对所建立的回归方程进行检验: (5%显著性水平下,t(18)=2.101) 对于参数c假设: H 0: c=0. 对立假设:H 1 : c≠0 对于参数GDP假设: H 0: GDP=0. 对立假设:H 1 : GDP≠0 由上表知: 对于c,t=6.094104>t(n-2)=t(18)=2.101 因此拒绝H 0: c=0,接受对立假设:H 1 : c≠0 对于GDP, t=71.88054﹥t(n-2)=t(18)=2.101
1.已知1996—2002年中国东北、华北、华东15个省级地区的居民家庭人均消费(cp,不变价格)和人均收入(ip,不变价格)居民,利用数据(1)建立面板数据(panel data)工作文件;(2)定义序列名并输入数据;(3)估计选择面板模型;(4)面板单位根检验。 年人均消费(consume)和人均收入(income)数据以及消费者价格指数(p)分别见表9.1,9.2和9.3。 表9.1 1996—2002年中国东北、华北、华东15个省级地区的居民家庭人均消费(元)数 据 人均消费1996 1997 1998 1999 2000 2001 2002 CONSUMEAH 3607.4 3 3693.5 5 3777.4 1 3901.8 1 4232.9 8 4517.6 5 4736.5 2 CONSUMEBJ 5729.5 2 6531.8 1 6970.8 3 7498.4 8 8493.4 9 8922.7 2 10284. 6 CONSUMEFJ 4248.4 7 4935.9 5 5181.4 5 5266.6 9 5638.7 4 6015.1 1 6631.6 8 CONSUMEHB 3424.3 5 4003.7 1 3834.4 3 4026.3 4348.4 7 4479.7 5 5069.2 8 CONSUMEHLJ 3110.9 2 3213.4 2 3303.1 5 3481.7 4 3824.4 4 4192.3 6 4462.0 8 CONSUMEJL 3037.3 2 3408.0 3 3449.7 4 3661.6 8 4020.8 7 4337.2 2 4973.8 8 CONSUMEJS 4057.5 4533.5 7 4889.4 3 5010.9 1 5323.1 8 5532.7 4 6042.6 CONSUMEJX 2942.1 1 3199.6 1 3266.8 1 3482.3 3 3623.5 6 3894.5 1 4549.3 2 CONSUMELN 3493.0 2 3719.9 1 3890.7 4 3989.9 3 4356.0 6 4654.4 2 5342.6 4 CONSUMENM G 2767.8 4 3032.3 3105.7 4 3468.9 9 3927.7 5 4195.6 2 4859.8 8 CONSUMESD 3770.9 9 4040.6 3 4143.9 6 4515.0 5 5022 5252.4 1 5596.3 2 CONSUMESH 6763.1 2 6819.9 4 6866.4 1 8247.6 9 8868.1 9 9336.1 10464 CONSUMESX 3035.5 9 3228.7 1 3267.7 3492.9 8 3941.8 7 4123.0 1 4710.9 6 CONSUMETJ 4679.65204.15471.05851.56121.06987.27191.9
实验报告 一、实验数据:1994至2009年天津市城镇居民人均全年可支配收入数据 1994至2009年天津市城镇居民人均全年消费性支出数据 1994至2009年天津市居民消费价格总指数 二、实验内容:对搜集的数据进行回归,研究天津市城镇居民人均消费和人均可支配收入的关系。 三、实验步骤: 1、百度进入“中华人民共和国国家统计局”中的“统计数据”,找到相关数据并输入Excel,统计结果如下表1: 表1 1994年--2009年天津市城镇居民消费支出与人均可支配收 入数据
2、先定义不变价格(1994=1)的人均消费性支出(Yt)和人均可支配收入(Xt) 令:Yt=consum/price Xt=income/price 得出Yt与Xt的散点图,如图1.很明显,Yt和Xt服从线性相关。
图1 Yt和Xt散点图 3、应用统计软件EViews完成线性回归 解:根据经济理论和对实际情况的分析也都可以知道,城镇居民人均全年耐用消费品支出Yt依赖于人均全年可支配收入Xt的变化,因此设定回归模型为 Yt=β0+β?Xt﹢μt (1)打开EViews软件,首先建立工作文件,File new Workfile ,然后通过Object建立Y、X系列,并得到相应数据。 (2)在工作文件窗口输入命令:ls y c x,按Enter键,回归结果如表2 : 表2 回归结果
根据输出结果,得到如下回归方程: Yt=977.908+0.670Xt s=(172.3797) (0.0122) t=(5.673) (54.950) R2=0.995385 Adjusted R2=0.995055 F-statistic=3019.551 残差平方和Sum squared resid =1254108 回归标准差S.E.of regression=299.2978 (3)根据回归方程进行统计检验: ?拟合优度检验 由上表2中的得知,样本可决系数与修 正样本可决系数分别为0.995385和0.995055,计算结果表明,估计
天津外国语大学国际商学院本科生课程论文(设计) 题目:一元回归分析居民收入和支出的关系姓名: 学号: 专业: 年级: 班级: 任课教师: 2014 年 4 月
内容摘要 随着本文中的收集数据参考了中国统计年鉴以及书本《计量经济学》中的相关统计结果,对我国各地区城镇居民家庭人均全年可支配收入与人均全年消费性支出进行分析。利用EVIEWS软件对计量模型进行参数评估和检验,最终得出相关结论。 关键词:居民消费;居民收入;EVIEWS;一元回归分析
目录 一、引言 (1) (一)研究背景 (1) (二)研究意义 (1) 二、研究综述 (2) (一)模型设定 (2) 1.定义变量 (2) 2.数据来源 (2) (二)作散点图 (3) 三、估计参数 (4) (一)操作步骤 (4) (二)回归结果 (4) 四、模型检验 (5) (一)经济意义检验 (5) (二)拟合优度和统计检验 (5) (三)回归预测 (5) 五、结论 (5) 参考文献: (6)
一元回归分析居民收入与支出的关系 一、引言 (一)研究背景 随着近年来我国成为世界第二大经济体,居民的高生活水平也日益显著。我国人口正在高速城镇化,2011年中国大陆城镇人口为69079万人,城镇人口占总人口比重达到51.27%。因此城镇居民作为消费主体,研究城镇居民人均可支配收入以及人均可支配消费性支出之间的关系,可以有效的了解到我国各地区的人民生活水平以及经济状况,因此能更好的的带动我国GDP的飙升,改善居民的生活水平。 (二)研究意义 居民消费在社会经济的持续发展中有着重要的作用。居民合理的消费模式和居民适度的消费规模有利于经济持续健康的增长,而且这要是人民生活水平的具体体现。改革开饭以来随着中国经济的快速发展,人民生活水平不断提高,居民的消费水平也不断增长。但是在看到这个整体趋势的同时,还应看到全国各地区经济发展速度不同,居民消费水平也有明显差异。例如,2007年的城市居民家庭平均每人每年消费支出,最高的是上海市达人均20667.91元,最低的则是新疆,人均只有8871.27元,上海是新疆的2.33倍。为了研究全国居民消费水平及其变动的原因,需要做具体的
实验报告 课程名称计量经济学 实验项目名称多重共线性 班级与班级代码 专业 任课教师 学号: 姓名: 实验日期: 2014 年 05 月 11日 广东商学院教务处制 姓名实验报告成绩 评语: 指导教师(签名) 年月日 说明:指导教师评分后,实验报告交院(系)办公室保存。 计量经济学实验报告 一、实验目的:掌握多元线性回归模型的估计方法、掌握多重共线性模型的识别和修正。 二、实验要求:应用教材第127页案例做多元线性回归模型,并识别和修正多重共线性。 三、实验原理:普通最小二乘法、简单相关系数检验法、综合判断法、逐步回归法。 四、预备知识:最小二乘法估计的原理、t检验、F检验、2R值。 五、实验步骤 1、选择数据 理论上认为影响能源消费需求总量的因素主要有经济发展水平、收入水平、产业发展、人民生活水平提高、能源转换技术等因素。为此,收集了中国能源消费标准煤总量、国民
总收入、国内生产总值GDP、工业增加值、建筑业增加值、交通运输邮电业增加值、人均生活电力消费、能源加工转换效率等1985——2007年的统计数据。本题旨在通过建立这些经济变量的线性模型来说明影响能源消费需求总量的原因。主要数据如下: 1985~2007年统计数据 资料来源:《中国统计年鉴》,中国统计出版社2000、2008年版。
为分析Y 与X1、X2、X3、X4、X5、X6、X7之间的关系,做如下折线图: 能源消费Y 在1986到1996年间缓慢增长,在96至98年有短暂的下跌,但是98至02年开始缓慢回升,02年到06年开始快速增长。 国民总收入X1和国内生产总值X2以相同的趋势逐年缓慢增长。 工业增加值X3在1985年-1999年期间一直是缓慢增长,但在2000年出现了急剧下降的现象,2001年又急剧增长,达到下降前的水平,2001年以后开始缓慢增长。建筑业增长值x4、交通运输邮电业增加值x5、人均生活电力消费x6、能源加工转换效率x7数值较低,但都以较平缓的方式增长。 2、设定并估计多元线性回归模型 t t t t t t t u X X X X X Y ++++++=66554433221ββββββ (2.1) 2.1录入数据,得到图。 2.2.1)采用OLS 估计参数 在主界面命令框栏中输入 ls y c x1 x2 x3 x4 x5 x6 x7回车,即可得到参数的估计结果。 由此可见,该模型的可决系数为0.989801,修正的可决系数为0.985041,模型拟和很好,F 统计量为386.2196,回归方程整体上显著。 可是其中的lnX3、lnX4、lnX6对lnY 影响不显著,不仅如此,lnX2、lnX5的参数为负值,在经济意义上不合理。所以这样的回归结果并不理想。 3、多重共线性模型的识别 点击Eviews 主画面的顶部的Quick/Group Statistics/Correlatios 弹出对话框在对话框中输入解释变量x1、x2、 x3、 x4、 x5、 x6、x7,点击OK ,即可得出相关系数矩阵(同图2.2.3)。 从相关系数矩阵可以看出,解释变量x1、x2、 x3、 x4、 x5、 x6、x7相互之间的相关系数较高,解释变量之间存在多重共线性。
实验一异方差性 【实验目的】 掌握异方差性问题出现的来源、后果、检验及修正的原理,以及相关的Eviews操作方法。 【实验内容】 以《计量经济学学习指南与练习》补充习题4-16为数据,练习检查和克服模型的异方差的操作方法。 【4-16】表4-1给出了美国18个行业1988年研究开发(R&D)费用支出Y与销售收入X的数据。请用帕克(Park)检验、戈里瑟(Gleiser)检验、G-Q检验与怀特(White)检验来检验Y关于X的回归模型是否存在异方差性?若存在 【实验步骤】 一检查模型是否存在异方差性 1、图形分析检验 (1)散点相关图分析 做出销售收入X与研究开发费用Y的散点相关图(SCAT X Y)。观察相关图可以看出,随着销售收入的增加,研究开发费用的平均水平不断提高,但离散程度也逐步扩大。这说明变量之间可能存在递增的异方差性。
(2)残差图分析 首先对数据按照解释变量X 由小至大进行排序(SORT X ),然后建立一元线性回归方程(LS Y C X )。 因此,模型估计式为: X Y *032.0507.187+=∧ ----------(*) (0.17) (2.88) R 2=0.31 s.e.=2850 F=0.011 建立残差关于X 的散点图,可以发现随着X 增加,残差呈现明显的扩大趋势,表明存在递增的异方差。
2、Park检验 建立回归模型(LS Y C X),结果如(*)式。 生成新变量序列:GENR LNE2 = LOG(RESID^2) GENR LNX = LOG(X) 生成新残差序列对解释变量的回归模型(LS LNE2 C LNX)。从下图所示的回归结果中可以看出,LNX的系数估计值不为0且能通过显著性检验,即随机误差项的方差与解释变量存在较强的相关关系,即认为存在异方差性。
小学期作业 影响财政收入的主要因素 学院:经济学院 班级:统计学班 姓名:梁语丝 学号:2011407036
影响财政收入的主要因素 摘要: 财政收入是一国政府实现政府职能的基本保障,主要有资源配置、收入再分配和宏观经济调控三大职能。财政收入的增长情况关系着一个国家经济的发展和社会的进步。我国财政收入主要受国民经济发展、预算外资金收入、税收收入等因素的影响。本文针对我国财政收入影响因素建立了计量经济模型,并利用Eviews软件对收集到的数据进行相关回归分析,排除简单多元回归模型存在的严重多重共线性等问题,建立财政收入影响因素更精确的模型,分析了影响财政收入主要因素及其影响程度,预测我国财政收入增长趋势。 二、模型设定 研究财政收入的影响因素离不开一些基本的经济变量。大多数相关的研究文献中都把总税收、国内生产总值这两个指标作为影响财政收入的基本因素,还有一些文献中也提出了其他一些变量, 比如其他收入、经济发展水平等。影响财政收入的因素众多复杂, 但是通过研究经济理论对财政收入的解释以及对实践的观察, 对财政收入影响的因素主要是税收收入。下面我们就以税收收入、能源消费总量、和预算外资金收入作为影响财政收入的主要研究因素。 从中国统计局网站上可以查询到1993年至2008年的相关数据,对其进行计算整理可得:
4.、模型的建立 根据1978—2008年每年的财政收入Y( 亿元) , 能源消费总量X1( 亿元),预算外资金收入X2( 亿元) ,税收收入X3( 亿元) 的统计数据,由E-views软件得到y,x1,x2,x3的线性图,如下:
由图可知,y,x1, x3都是逐年增长的,但增长速率有所变动,而x2呈现水平波动,说明变量间不一定是线性关系,可探索将模型设定为以下形式: lnY=β 0+β 1 lnX1+β 2 X2+β 3 lnX3+U 三,模型估计与调整 利用Eviews软件对模型进行最小二乘法全回归,结果如下: 第一步,进行模型的检验。 (一),进行多重共线性的检验 方程的修正后的R平方值很高,说明变量对因变量的拟合程度很好,但是应该注意到c,lnx1,x2三者的t值很低(在此选择置信度为0.05),未通过检
实验题目 异方差的诊断与修正 一、实验目的与要求: 要求目的:1、用图示法初步判断是否存在异方差,再用White 检验异方差; 2、用加权最小二乘法修正异方差。 二、实验内容 根据1998年我国重要制造业的销售利润与销售收入数据,运用EV 软件,做回归分析,用图示法,White 检验模型是否存在异方差,如果存在异方差,运用加权最小二乘法修正异方差。 三、实验过程:(实践过程、实践所有参数与指标、理论依据说明等) (一) 模型设定 为了研究我国重要制造业的销售利润与销售收入是否有关,假定销售利润与销售收入之间满足线性约束,则理论模型设定为: i Y =1β+2βi X +i μ 其中,i Y 表示销售利润,i X 表示销售收入。由1998年我国重要制造业的销售收入与销售利润的数据,如图1: 1988年我国重要制造业销售收入与销售利润的数据 (单位:亿元)
(二) 参数估计 1、双击“Eviews ”,进入主页。输入数据:点击主菜单中的File/Open /EV Workfile —Excel —异方差数据 ; 2、在EV 主页界面的窗口,输入“ls y c x ”,按“Enter ”。出现OLS 回归结果,如图2: 估计样本回归函数 Dependent Variable: Y Method: Least Squares Date: 10/19/05 Time: 15:27 Sample: 1 28 Included observations: 28 Variable Coefficient Std. Error t-Statistic Prob. C X R-squared Mean dependent var Adjusted R-squared . dependent var . of regression Akaike info criterion Sum squared resid Schwarz criterion Log likelihood F-statistic Durbin-Watson stat Prob(F-statistic) 估计结果为: i Y ? = + i X () t=() () 2R = 2R = .= DW=1.212859 F= 这说明在其他因素不变的情况下,销售收入每增长1元,销售利润平均增长元。 2R = , 拟合程度较好。在给定 =时,t= > )26(025.0t = ,拒绝原假设,说明销售收入对 销售利润有显著性影响。F= > )6,21(F 05.0= ,表明方程整体显著。
EViews图像与及结果分析报告 EViews软件提供了序列(Series)和序列组(Group)等对象的各种视图、统计分析方法和过程。当序列对象中输入数据后,就可对序列对象中输入的数据进行统计分析,并且可以通过图、表等形式进行描述。本章将介绍序列和序列组对象图形的生成和描述性统计量及其检验。 4.1 图形对象 图形(Graph)对象可以形成序列和序列组等对象的各种视图,如线图(Line)、散点图(Scatter)以及饼图(Pie)等。通过图形可以进一步观察和分析数据的变化趋势和规律。下面介绍图形对象的基本操作。 4.1.1 图形(Graph)对象的生成 图形对象也是工作文件中的基本对象之一。要生成图形对象需首先打开序列对象窗口或序列组对象窗口,选择对象窗口工具栏中的“View”|“Graph”选项。选择的对象类型不同,将弹出不同的窗文案大全
口。如果在序列对象窗口下选择“View”|“Graph”选项,将弹出如图4-1所示的界面。 图4-1 序列窗口下图形对象的生成 此时“Graph”弹出的菜单中有6种图形可供选择。“Line”表示生成的是折线图,如图4-2所示,其横轴表示时间或序列的顺序,纵轴表示序列对象观测值的大小。“Area”表示生成面积图,其图形的形状与“Line”(折线图)相同,不同的是“Area”(面积图)曲线下方是被填满的,而“Line”(折线图)下方是空白。
图4-2 “Line”折线图 “Bar”表示为条形图,用条状的高度表示观测值的大小。“Spike”表示尖峰图,由竖线组成,每根竖线的高度代表观测值的大小。“Seasonal Stacked Line”表示生成的是季节性堆叠图,“Seasonal Split Line”表示生成的是季节性分割线。 如果在序列组(群)对象窗口下选择“View”|“Graph”选项,将弹出如图4-3所示的界面。这里有9种图形可供选择。其前4种与上面讲述的相同。 图4-3 序列组(群)窗口下图对象的生成 其中,“Scatter”表示生成散点图。在“Scatter”弹出的菜单中有5个选项,分别是“Simple Scatter”(简单散点图)、“Scatter with Regression”(带有回归线的散点图)、“Scatter with Nearest
计量经济学e v i e w s实 验报告 标准化管理处编码[BBX968T-XBB8968-NNJ668-MM9N]
大连海事大学 实验报告 实验名称:计量经济学软件应用 专业班级:财务管理2013-1 姓名:安妮 指导教师:赵冰茹 交通运输管理学院 二○一六年十一月 一、实验目标 学会常用经济计量软件的基本功能,并将其应用在一元线性回归模型的分析中。具体包括:Eview的安装,样本数据基本统计量计算,一元线性回归模型的建立、检验及结果输出与分析,多元回归模型的建立与分析,异方差、序列相关模型的检验与处理等。二、实验环境 WINDOWSXP或2000操作系统下,基于平台。 三、实验模型建立与分析 案例1:
我国1995-2014年的人均国民生产总值和居民消费支出的统计资料(此资料来自中华人民共和国统计局网站)如表1所示,做回归分析。 表1我国1995-2014年人均国民生产总值与居民消费水平情况
(1)做出散点图,建立居民消费水平随人均国内生产总值变化的一元线性回归方程,并解释斜率的经济意义; 利用eviews软件输出结果报告如下: Dependent Variable: CONSUMPTION Method: Least Squares Date: 06/11/16 Time: 19:02 Sample: 1995 2014 Included observations: 20
Variable Coeffici ent Std. Error t- Statistic Prob. C AVGDP R-squared Mean dependent var Adjusted R- squared. dependent var . of regression Akaike info criterion Sum squared resid1538032.Schwarz criterion Log likelihood Hannan-Quinn criter. F-statistic Durbin-Watson stat Prob(F-statistic) 由上表可知财政收入随国内生产总值变化的一元线性回归方程为: (令Y=CONSUMPTION,X=AVGDP(此处代表人均GDP)) Y = +* X 其中斜率表示国内生产总值每增加一元,人均消费水平增长元。
《计量经济学》eviews实验报告一元线性回归模型
————————————————————————————————作者:————————————————————————————————日期:
《计量经济学》实验报告一元线性回归模型 一、实验内容 (一)eviews 基本操作 (二)1、利用EViews 软件进行如下操作: (1)EViews 软件的启动 (2)数据的输入、编辑 (3)图形分析与描述统计分析 (4)数据文件的存贮、调用 2、查找2000-2014年涉及主要数据建立中国消费函数模型 中国国民收入与居民消费水平:表1 年份X(GDP)Y(社会消费品总量) 2000 99776.3 39105.7 2001 110270.4 43055.4 2002 121002.0 48135.9 2003 136564.6 52516.3 2004 160714.4 59501.0 2005 185895.8 68352.6 2006 217656.6 79145.2 2007 268019.4 93571.6 2008 316751.7 114830.1 2009 345629.2 132678.4 2010 408903.0 156998.4 2011 484123.5 183918.6 2012 534123.0 210307.0 2013 588018.8 242842.8 2014 635910.0 271896.1 数据来源:https://www.doczj.com/doc/4817907520.html, 二、实验目的 1.掌握eviews的基本操作。 2.掌握一元线性回归模型的基本理论,一元线性回归模型的建立、估计、检验及预测的方 法,以及相应的EViews软件操作方法。
《计量经济学》实验报告多元线性回归模型 一、实验内容 建立2000-2014年北京市民用汽车拥有量模型。 调查北京市民用汽车拥有量数据见表1。观测变量分别是民用汽车拥有量y t(万辆),北京市年末人口数x it (万人)和城镇人均可支配收入x2t (千元)。 表1 某城市拥有量样本数据 t y t(拥有量)X1t(年末人数)X2t (人均收入) 2000 104.12 1113.53 10349.7 2001 114.47 1127.89 11577.8 2002 133.93 1142.83 12463.9 2003 163.07 1154.06 13882.6 2003 182.42 1167.76 15637.8 2005 182.42 1184.14 17653 2006 239.12 1199.96 19977.5 2007 273.36 1216.25 21988.5 2008 313.68 1232.28 24724.9 2009 368.11 1247.52 26738.5 2010 449.72 1258 29072.9 2011 470.53 1277.92 32903 2012 493.56 1297.46 36468.8 2013 517.11 1316.34 40321
2014 530.83 1333.4 43910
要求: (1)试建立二元线性回归销售模型。 (2)考虑北京地区有人口万人,人均年收入为元,试北京市汽车拥有量做出预测。 二、实验目的 掌握多元线性回归模型的原理,多元线性回归模型的建立、估计、检验及预测的方法, 以及相应的EViews软件操作方法。 三、实验步骤(简要写明实验步骤) (1 )建立二元线性回归销售模型 (2)预测 点击view 中的Graph-scatter- 中的第三个获得