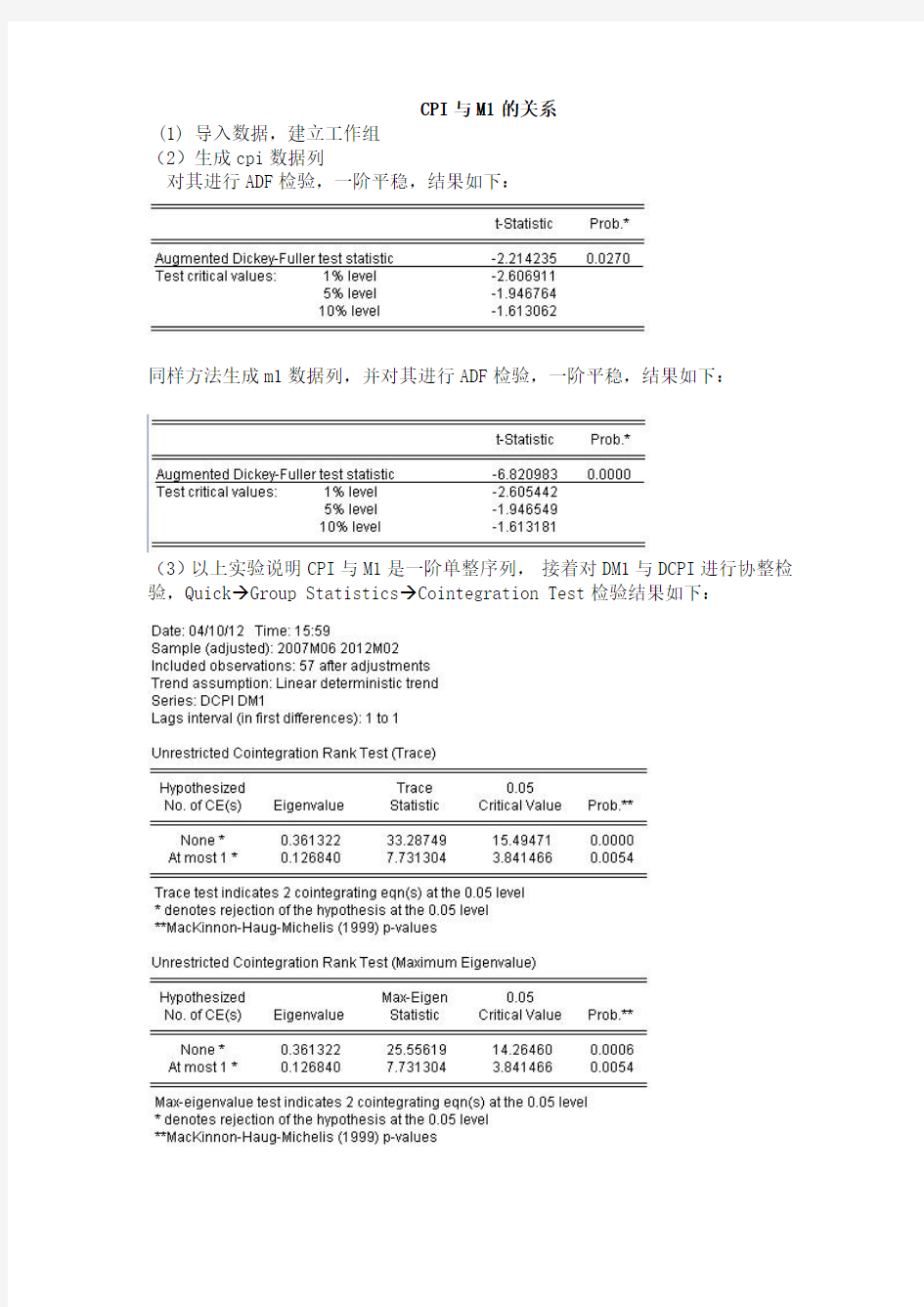
CPI与M1的关系
(1) 导入数据,建立工作组
(2)生成cpi数据列
对其进行ADF检验,一阶平稳,结果如下:
同样方法生成m1数据列,并对其进行ADF检验,一阶平稳,结果如下:
(3)以上实验说明CPI与M1是一阶单整序列,接着对DM1与DCPI进行协整检验,Quick→Group Statistics→Cointegration Test检验结果如下:
说明存在2个协整关系。
(4)对其一阶差分序列进行格兰杰因果检验,Quick→Group Statistics→Granger Causality Test检验结果如下:
说明M1是CPI变动的格兰杰原因,而CPI不是M1变动的格兰杰原因。
综上所述,CPI与M1存在协整关系,且M1的变动引起CPI的变动。
沪深股市收益率波动性分析
一沪深股市收益率的波动性研究
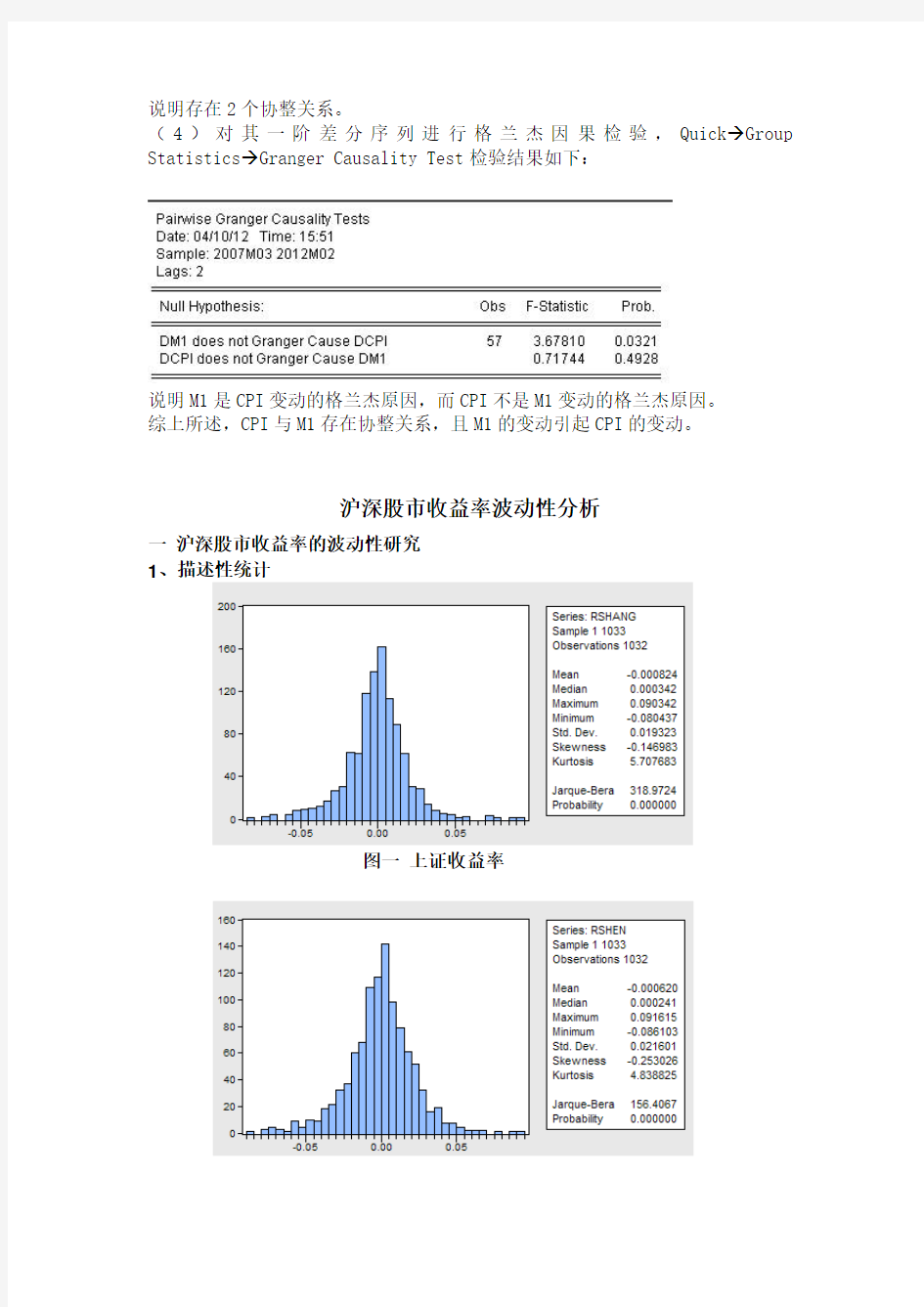
1、描述性统计
图一上证收益率
图二深证收益率
从图一可以发现,样本期内沪市收益率均值为-0.000824,标准差为0.019323,偏度为-0.146983,峰度为5.707683,远高于正态分布的峰度值3,说明收益率r t具有尖峰和厚尾特征。JB正态性检验也证实了这点,统计量为318.9724,说明在极小置信概率下,收益率显著异于正态分布;从图二可以发现,样本期内深市收益率均值为-0.00062,标准差为0.021601,偏度为-0.253026,峰度为4.838825,收益率同样具有尖峰厚尾特征。深市收益率的标准差大于沪市,说明深圳股市的波动更大。
析。
3、均值方程的确定及残差序列自相关检验
图三上证收益率自相关检验
图四 深证收益率自相关检验
从图三和图四可以看出上证收益率和深证收益率都不存在自相关性,因此我们选择以下模型作为波动率模型的均值方程:
it it it u r ε+= 2,1=i
其中t r 1表示上证收益率,t r 2表示深证收益率。
对沪深市场收益率分别作如上模型的回归,结果如图五和图六所示:
图五上证收益率回归分析
图六深证收益率回归分析
4、用Ljung-Box Q 统计量对均值方程拟和后的残差及残差平方做自相关检验
图七 上证收益率回归模型 图八 上证收益率回归模型残差
残差的自相关检验 平方的自相关检验
图九 深证收益率回归模型 图十 深证收益率回归模型残差
残差的自相关检验 平方的自相关检验
从图七和图八可以发现,上证收益率回归模型的残差不存在自相关性,而上证收益率回归模型的残差平方存在很强的自相关,即模型残差存在条件异方差。从图九和图十可以发现,深证收益率回归模型的残差不存在自相关性,而深证收益率回归模型的残差平方存在很强的自相关,即模型残差存在条件异方差。
5、ARCH-LM 检验
图十一上证收益率回归残差的ARCH检验
图十二上证收益率回归残差的ARCH检验
从图十一和图十二可以看出上证收益率与深证收益率的残差都具有ARCH效应,因此有必要进行GARCH建模来改善模型。
6、GARCH类模型建模
(1)GARCH(1,1)建模
图十三上证收益率GARCH(1,1)模型
图十四深证收益率GARCH(1,1)模型
从图十三和十四可见,沪深股市收益率条件方差方程中ARCH项和GARCH项都是高度显著的,表明收益率序列具有显著的波动集簇性。沪市中ARCH项和GARCH项系数之和为0.988,深市也为0.986,均小于1。因此GARCH(1,1)过程是平稳的,其条件方差表现出均值回复(MEAN-REVERSION),即过去的波动对未来的影响是逐渐衰减。
(2)GARCH-M (1,1)
图十五上证收益率GARCH-M(1,1)模型
图十六深证收益率GARCH-M(1,1)模型
从图十五和十六可见,沪深两市均值方程中条件方差项GARCH的系数估计分别为0.070689和2.379279,这反映了收益与风险的正相关关系,说明收益有正的风险溢价。但是
两者都没有在5%的置信水平下显著,这可能是因为中国股票市场没有很完善,投机成份大,导致高收益未必高风险。
( 二) 股市收益波动非对称性的研究
1、TGARCH
图十七上证收益率TGARCH模型
图十八 深证收益率TGARCH 模型
在TARCH 中,2
11t t d ε--项的系数估计值都大于0,而且在5%的置信水平下都是显著的。
这说明沪深股市中坏消息引起的波动比同等大小的好消息引起的波动要大,沪深股市都存在杠杆效应。
2、 EGARCH
图十九 上证收益率EGARCH 图二十 深证收益率EGARCH 模型
图二十一上证信息冲击曲线图二十二深证信息冲击曲线
在估计结果中沪市为-0.055011,深
在EGARCH中,
市为-0.045740,而且都是显著的,这也说明了沪深股市中都存在杠杆效应。并且在图二十一和图二十二的信息冲击曲线可以看出,小于0的曲线比大于0的曲线更加陡峭,即在收益率为负时的波动大于收益率为正时的波动,因此沪深股市确实存在杠杆效应。
(三)沪深股市波动溢出效应的研究
当某个资本市场出现大幅波动的时候,就会引起投资者在另外的资本市场的投资行为的
改变,将这种波动传递到其他的资本市场。这就是所谓的“溢出效应”。例如9.11恐怖袭击
后,美国股市的大震荡引起欧洲及亚洲股市中投资者的恐慌,从而引发了当地资本市场的大动荡。接下来我们将检验深沪两市之间的波动是否存在“溢出效应”。利用GARCH-M模型回归结果,导出相应的方差,并对方差进行格兰杰因果检验(从一阶到10阶分别计算),图二十三是滞后二阶结果,
图二十三波动溢出效应分析
从图二十三可以发现,在5%的置信水平下,上证股市的波动会引起到深证股市的波动,即存在波动溢出效应,而深证股市的波动不会引起到上证股市的波动,即不存在波动溢出效应。
(三) 总结
我们运用GARCH类模型,对沪深股市收益率的波动性、波动的非对称性,以及波动之间的溢出效应做了全面的分析。通过分析,基本可以得出了以下结论:
第一,沪深股市收益率都存在明显的GARCH效应。
第二,沪深股市不存在明显的GARCH-M效应,
第三,沪深股市都存在明显的杠杆效应,反映了在我国股票市场上坏消息引起的波动要大于好消息引起的波动。
第四,沪深股市之间波动存在溢出效应,而且是单向的,沪市的波动将引起深市的波动。
计量经济学E v i e w s多重共线性实验报告 Company Document number:WUUT-WUUY-WBBGB-BWYTT-1982GT
实验报告课程名称计量经济学 实验项目名称多重共线性 班级与班级代码 专业 任课教师 学号: 姓名: 实验日期: 2014 年 05 月 11日 广东商学院教务处制 姓名实验报告成绩 评语: 指导教师(签名) 年月日 说明:指导教师评分后,实验报告交院(系)办公室保存。 计量经济学实验报告 一、实验目的:掌握多元线性回归模型的估计方法、掌握多重共线性模型的识别和修正。 二、实验要求:应用教材第127页案例做多元线性回归模型,并识别和修正多重共线性。 三、实验原理:普通最小二乘法、简单相关系数检验法、综合判断法、逐步回归法。
四、预备知识:最小二乘法估计的原理、t检验、F检验、2R值。 五、实验步骤 1、选择数据 理论上认为影响能源消费需求总量的因素主要有经济发展水平、收入水平、产业发展、人民生活水平提高、能源转换技术等因素。为此,收集了中国能源消费标准煤总量、国民总收入、国内生产总值GDP、工业增加值、建筑业增加值、交通运输邮电业增加值、人均生活电力消费、能源加工转换效率等1985——2007年的统计数据。本题旨在通过建立这些经济变量的线性模型来说明影响能源消费需求总量的原因。主要数据如下: 1985~2007年统计数据
资料来源:《中国统计年鉴》,中国统计出版社2000、2008年版。 为分析Y 与X1、X2、X3、X4、X5、X6、X7之间的关系,做如下折线图: 能源消费Y 在1986到1996年间缓慢增长,在96至98年有短暂的下跌,但是98至02年开始缓慢回升,02年到06年开始快速增长。 国民总收入X1和国内生产总值X2以相同的趋势逐年缓慢增长。 工业增加值X3在1985年-1999年期间一直是缓慢增长,但在2000年出现了急剧下降的现象,2001年又急剧增长,达到下降前的水平,2001年以后开始缓慢增长。建筑业增长值x4、交通运输邮电业增加值x5、人均生活电力消费x6、能源加工转换效率x7数值较低,但都以较平缓的方式增长。 2、设定并估计多元线性回归模型 t t t t t t t u X X X X X Y ++++++=66554433221ββββββ () 录入数据,得到图。 2.2.1)采用OLS 估计参数 在主界面命令框栏中输入 ls y c x1 x2 x3 x4 x5 x6 x7回车,即可得到参数的估计结果。 由此可见,该模型的可决系数为,修正的可决系数为,模型拟和很好,F 统计量为,回归方程整体上显着。 可是其中的lnX3、lnX4、lnX6对lnY 影响不显着,不仅如此,lnX2、lnX5的参数为负值,在经济意义上不合理。所以这样的回归结果并不理想。 3、多重共线性模型的识别
《计量经济学》实验报告一元线性回归模型 一、实验内容 (一)eviews 基本操作 (二)1、利用EViews 软件进行如下操作: (1)EViews 软件的启动 (2)数据的输入、编辑 (3)图形分析与描述统计分析 (4)数据文件的存贮、调用 2、查找2000-2014年涉及主要数据建立中国消费函数模型 中国国民收入与居民消费水平:表1 年份X(GDP)Y(社会消费品总量) 2000 99776.3 39105.7 2001 110270.4 43055.4 2002 121002.0 48135.9 2003 136564.6 52516.3 2004 160714.4 59501.0 2005 185895.8 68352.6 2006 217656.6 79145.2 2007 268019.4 93571.6 2008 316751.7 114830.1 2009 345629.2 132678.4 2010 408903.0 156998.4 2011 484123.5 183918.6 2012 534123.0 210307.0 2013 588018.8 242842.8 2014 635910.0 271896.1 数据来源:https://www.doczj.com/doc/ac2304909.html, 二、实验目的 1.掌握eviews的基本操作。 2.掌握一元线性回归模型的基本理论,一元线性回归模型的建立、估计、检验及预测的方 法,以及相应的EViews软件操作方法。
三、实验步骤(简要写明实验步骤) 1、数据的输入、编辑 2、图形分析与描述统计分析 3、数据文件的存贮、调用 4、一元线性回归的过程 点击view中的Graph-scatter-中的第三个获得 在上方输入ls y c x回车得到下图
我国旅游收入的计量分析 一、经济理论陈述 在研读了大量统计和计量资料的基础上,选择了三个大方面进行研究,既包括旅游人数,人均旅游花费和基本交通建设。其中,在旅游人数这个解释变量的划分上,我们考虑到随着全球经济一体化的发展,越来越多的外国游客来中国旅游消费。中国旅游的国际市场是个有发展潜力的新兴市场,尽管外国游客前来旅游的方式包罗万象而且消费能力也不尽相同,但从国际服务贸易的角度出发,我们在做变量选择时,运用国际营销的知识进行市场细分,划分了国际和国内两个市场。这样,在旅游人数这个解释变量的最终确定上,我们选择了2X国内旅游人数,3X入境旅游人数。这点选择除了理论支持外,在现实旅游业发展中我们也看到很多景区包括成都的近郊也有不少外国游客的身影。所以,我们选取这两个解释变量等待下一步进行模型设计和检验。 另外,对于人均旅游花费,我们在进行市场细分时,没有延续前两个变量的选择模式,有几个原因。首先,外国游客前来旅游的形式和消费方式各异且很难统计。我们在花大力气收集数据后,仍然没有比较权威的统计数据资料。其次,随着国家对农业的不断重视和扶持,我国农业有了长足发展。农村居民纯收入增加,用于旅游的花费也有所上升。而且鉴于农村人口较多,前面的市场细分也不够细化,在这个解释变量的确定上,我们选择农村人均旅游花费,既是从我国基本国情出发,也是对第一步研究分析的补充。所以我们确定了4X城镇居民人均旅游花费和5X农村居民人均旅游花费。 旅游发展除了对消费者市场的划分研究,还应考虑到该产业的基础硬件设施。
在众多可选择对象中我们经分析研究结合大量文献资料决定从交通建设着手。在我国,交通一般分布为公路,铁路,航班,航船等。由于考虑到我国一般大众的旅游交通方式集中在公路和铁路上,为了避免解释变量的过多过繁以及可能带来的多重共线形等问题,我们只选取了前二者。即确定了6X公路长度和7X铁路长度这两个解释变量。其中,考虑到我国旅游业不断发展过程中,高速公路的修建也不断增多,在6X的确定过程中,我们已经将其拟合,尽量保证解释变量的完整和真实。 二、相关数据 三、计量经济模型的建立 Y=c(1)+c(2)*X2+c(3)*X3+c(4)*X4+c(5)*X5+c(6)*X6+U 我们建立了下述的一般模型:
实验四虚拟变量 【实验目的】 掌握虚拟变量的基本原理,对虚拟变量的设定和模型的估计与检验,以及相关的Eviews操作方法。 【实验内容】 试根据1998年我国城镇居民人均收入与彩电每百户拥有量的统计资料建立 【实验步骤】 1、相关图分析 根据表中数据建立人均收入X与彩电拥有量Y的相关图(SCAT X Y)。从相关图可以看出,前3个样本点(即低收入家庭)与后5个样本点(中、高收入)的拥有量存在较大差异,
因此,为了反映“收入层次”这一定性因素的影响,设置虚拟变量如下: ?? ?=低收入家庭 中、高收入家庭 1D 2、构造虚拟变量 构造虚拟变量 1D (DATA D1),并生成新变量序列: GENR XD=X*D1 3、估计虚拟变量模型 LS Y C X D1 XD 得到估计结果:
我国城镇居民彩电需求函数的估计结果为: XD D X Y 009.0873.31012.0611.571-++=∧ (16.25) (9.03) (8.32) (-6.59) 366,066.1..,9937.02===F e s R 再由t 检验值判断虚拟变量的引入方式,并写出各类家庭的需求函数。 虚拟变量的回归系数的t 检验都是显著的,且模型的拟合优度很高,说明我国城镇居民低收入家庭与中高收入家庭对彩电的消费需求,在截距和斜率上都存在着明显差异,所以以加法和乘法方式引入虚拟变量是合理的。 低收入家庭与中高收入家庭各自的需求函数为: 低收入家庭: X Y 012.0611.57+=∧ 中高收入家庭: X X Y 003.0484.89)009.0012.0()873.31611.57(+=-++=∧ 由此可见我国城镇居民家庭现阶段彩电消费需求的特点: 对于人均年收入在3300元以下的低收入家庭,需求量随着收入水平的提高而快速上升,人均年收入每增加1000元,百户拥有量将平均增加12台;对于人均年收入在4100元以上的中高收入家庭,虽然需求量随着收入水平的提高也在增加,但增速趋缓,人均年收入每增加1000元,百户拥有量只增加3台。
大连海事大学 实验报告 实验名称:计量经济学软件应用 专业班级:财务管理2013-1 姓名:安妮 指导教师:赵冰茹 交通运输管理学院 二○一六年十一月 一、实验目标 学会常用经济计量软件的基本功能,并将其应用在一元线性回归模型的分析中。具体包括:Eview的安装,样本数据基本统计量计算,一元线性回归模型的建立、检验及结果输出与分析,多元回归模型的建立与分析,异方差、序列相关模型的检验与处理等。二、实验环境 WINDOWSXP或2000操作系统下,基于EVIEWS5.1平台。 三、实验模型建立与分析 案例1:
我国1995-2014年的人均国民生产总值和居民消费支出的统计资料(此资料来自中华人民共和国统计局网站)如表1所示,做回归分析。 表1我国1995-2014年人均国民生产总值与居民消费水平情况
(1)做出散点图,建立居民消费水平随人均国内生产总值变化的一元线性回归方程,并解释斜率的经济意义; 利用eviews软件输出结果报告如下: Dependent Variable: CONSUMPTION Method: Least Squares Date: 06/11/16 Time: 19:02 Sample: 1995 2014 Included observations: 20
Variable Coeffici ent Std. Error t-Statisti c Prob.?? C691.0225113.3920 6.0941040.0000 AVGDP0.3527700.00490871.880540.0000 R-squared0.996528????Mean dependent var7351.300 Adjusted R-squared0.996335????S.D. dependent var4828.765 S.E. of regression292.3118????Akaike info criterion14.28816 Sum squared resid1538032.????Schwarz criterion14.38773 Log likelihood -140.881 6 ????Hannan-Quinn criter.14.30760 F-statistic5166.811????Durbin-Watson stat0.403709 Prob(F-statistic)0.000000 由上表可知财政收入随国内生产总值变化的一元线性回归方程为:
房价的计量经济分析 引言:近改革开放20多年来,从来没有哪一个行业像房地产业这样盛产亿万富翁,各种富豪排行榜上,房地产富豪连年占据半壁江山;“中国十大暴利行业”中,房地产业每年都是“第一名”。是什么造就了这样的状况。房地产的问题,在开发商,政府,购房者三者来看,就是一场完完全全的博弈。而这场博弈的焦点则是房价问题。如果说开发商与政府之间的博弈是围绕“土地”这个关键词,那么整个房地产市场则在价格上开展了新一轮的对峙。先是开发商与购房者在房价涨跌上僵持不下;再有开发商与政府之间的土地成本论;最后则是关于房地产是否归为暴利行业的争执,“价格”成了市场关注的焦点。而对于房价的构成因素,至今仍然是不透明的。公布房价成本成为另政府极为头疼的一件事。房价成本是一个非常复杂的集合体,并且项目间差异性较大,同时还有软资产、品牌等组成部分,特别是现在的商品房,追求品质、功能完善以及个性化成本构成越来越难衡量。 写作目的:通过对一系列影响房价的基本因素的分析,了解对其主要因素和次要因素。并对这些因素进行统计推断和经济意义上的检验。选择拟和效果最好的最为结论。在一定层面上分析房地产如此暴利的因素。当然笔者的能力有限,并不能全面的分析这一问题。仅仅就几个因素进行分析。 写作方法:理论分析及计量分析方法,将会用到Eviews软件进行帮助分析。 关键词:房价成本计量假设检验最小二乘法拟合优度 现在我们以2003年的数据,选取30个省市的数据为例进行分析。在Eviews软件中选择建立截面数据。现在我们以2003年的数据,选取31个省市的数据为例进行分析。令Y=各地区建筑业总产值。(万元)X1=各地区房屋竣工面积。(万平方米)X2=各地区建筑业企业从业人员。(人)X3=各地区建筑业劳动生产率。(元/人)X4=各地区人均住宅面积。(平方米)X5=各地区人均可支配收入。(元) 数据如下: Y X1 X3 X2 X4 X5 12698521 4254.800 569767.0 129961.0 24.77140 13882.62 5208402. 1465.800 238957.0 147063.0 23.09570 10312.91 7799313. 4748.300 989317.0 70048.00 23.16710 7239.060 5401279. 1313.300 591276.0 89151.00 22.99680 7005.030 2576575. 1450.700 265953.0 61074.00 20.05310 7012.900 10170794 3957.100 966790.0 82496.00 20.23510 7240.580 3469281. 1626.800 303837.0 77486.00 20.70590 7005.170 4401878. 2181.300 441518.0 68033.00 20.49200 6678.900 11958034 3609.200 505185.0 153910.0 29.34530 14867.49
计量经济学案例分析1 一、研究的目的要求 居民消费在社会经济的持续发展中有着重要的作用。居民合理的消费模式和居民适度的消费规模有利于经济持续健康的增长,而且这也是人民生活水平的具体体现。改革开放以来随着中国经济的快速发展,人民生活水平不断提高,居民的消费水平也不断增长。但是在看到这个整体趋势的同时,还应看到全国各地区经济发展速度不同,居民消费水平也有明显差异。例如,2002年全国城市居民家庭平均每人每年消费支出为元, 最低的黑龙江省仅为人均元,最高的上海市达人均10464元,上海是黑龙江的倍。为了研究全国居民消费水平及其变动的原因,需要作具体的分析。影响各地区居民消费支出有明显差异的因素可能很多,例如,居民的收入水平、就业状况、零售物价指数、利率、居民财产、购物环境等等都可能对居民消费有影响。为了分析什么是影响各地区居民消费支出有明显差异的最主要因素,并分析影响因素与消费水平的数量关系,可以建立相应的计量经济模型去研究。 二、模型设定 我们研究的对象是各地区居民消费的差异。居民消费可分为城市居民消费和农村居民消费,由于各地区的城市与农村人口比例及经济结构有较大差异,最具有直接对比可比性的是城市居民消费。而且,由于各地区人口和经济总量不同,只能用“城市居民每人每年的平均消费支出”来比较,而这正是可从统计年鉴中获得数据的变量。所以模型的被解释变量Y选定为“城市居民每人每年的平均消费支出”。 因为研究的目的是各地区城市居民消费的差异,并不是城市居民消费在不同时间的变动,所以应选择同一时期各地区城市居民的消费支出来建立模型。因此建立的是2002年截面数据模型。 影响各地区城市居民人均消费支出有明显差异的因素有多种,但从理论和经验分析,最主要的影响因素应是居民收入,其他因素虽然对居民消费也有影响,但有的不易取得数据,如“居民财产”和“购物环境”;有的与居民收入可能高度相关,如“就业状况”、“居民财产”;还有的因素在运用截面数据时在地区间的差异并不大,如“零售物价指数”、“利率”。因此这些其他因素可以不列入模型,即便它们对居民消费有某些影响也可归入随即扰动项中。为了与“城市居民人均消费支出”相对应,选择在统计年鉴中可以获得的“城市居民每人每年可支配收入”作为解释变量X。 从2002年《中国统计年鉴》中得到表的数据: 表 2002年中国各地区城市居民人均年消费支出和可支配收入
EVIEWS实验报告 专业:金融学 班级:10907 学号:1090723 姓名:侯文隽
一、选题 自1949年新中国成立以后,我国国债发行基本分为两个阶段:20世纪50年代是第一阶段,为了支援人民解放战争,恢复和发展经济,我国先后发行过人民胜利折实公债和国家经济建设公债。80年代以来是第二阶段,进入20世纪80年代以后,随着改革开放的不断深入,我国国民收入分配格局发生了变化,国债的发行量也逐年扩大。本次实验出发点是根据1980-2005年的国债规模和可能的相关因素进行分析,同时达到掌握使用EVIEWS进行经济问题分析的目的。二、建立模型 影响国债规模的因素是多方面的、多层次的,我们暂且不去考虑微观上国债的管理水平与结构、筹资成本、期限安排、偿还方式等因素,因为这些因素的影响是个别的,并且难以计量。所以从宏观经济角度出发,引入财政赤字、国内生产总值(GDP)、年还本付息支出等指标,并建立多元线性回归模型。以国债发行量作为被解释变量Y,财政赤字、GDP、还本付息支出作为解释变量分别用X1、X2、X3表示。建立模型如下: Y=b0+b1*X1+b2*X2+b3*X3 三、数据来源 下表列出了1980-2005年间历年国债发行规模及各相关因素的具体数据表1 单位:亿元
(来源于中国统计年鉴2006,1980-2005年数据) 四、实验结果 通过普通最小二乘法对变量进行回归估计,得到结果如下: Dependent Variable: Y Method: Least Squares Date: 10/02/11 Time: 13:09 Sample: 1980 2005 Included observations: 26 Variable Coefficient Std. Error t-Statistic Prob. C -82.30505 63.20978 X1 0.816282 0.075733 X2 0.671558 0.414988 X3 0.980645 0.160403 R-squared 0.994963 Mean dependent var 2015.208 Adjusted R-squared 0.994276 S.D. dependent var 2355.453 S.E. of regression 178.2087 Akaike info criterion 13.34443 Sum squared resid 698683.5 Schwarz criterion 13.53798 Log likelihood -169.4775 F-statistic Durbin-Watson stat 1.141533 Prob(F-statistic) Y=-82.3051+0.8163X1+0.6716X2+0.9806X3 五、模型检验 1、从回归估计的结果看,可决系数R2=0.9949,模型拟合较好。方程的显著性检 验中F的伴随概率等于0,小于0.05,说明所有的待估参数不全为零,方程总体上的线性关系是显著成立的。在变量的显著性检验中,X1和X3的t检
实验一Eviews的基本操作与一元线性回归模型的最小二乘估计实验目的: 1、熟悉Eviews的窗口与界面 2、掌握Eviews的命令与菜单的操作 3、掌握用Eviews估计与检验一元线性回归模型 实验内容: 1、启动Eviews 双击Eviews图标,出现Eviews窗口,它由以下部分组成:标题栏“Eviews”、主菜单“File,Edit,…,Help”、命令窗口(空白处)和工作区域。 命令窗口 工作区域 图1-1 2、产生文件 Eviews的操作在工作文件中进行,故首先要有工作文件,然后进行数据输入、分析等等操作。 (1)读已存在文件:File→Open→Workfile。 (2)新建文件:File→New→Workfile,出现对话框“工作文件范围”,选取或填上数据类型、起止时间。OK后,得到一个无名字的工作文件,其中有:时间范围、当前工作文件样本范围、filter 、默认方程、系数向量C、序列RESID。 在主菜单上依次点击File/New/Workfile,即选择新建对象的类型为工作文件,将弹出一个对话框(如图所示),由用户选择数据的时间频率(frequency)、
起始期和终止期。 图1-2工作文件对话框 其中, Annual——年度 Monthly——月度 Semi-annual——半年 Weekly——周 Quarterly——季度 Daily——日 Undated or irregular——非时序数据 选择时间频率为Annual(年度),再分别点击起始期栏(Start date)和终止期栏(End date),输入相应的日前1985和1998。然后点击OK按钮,将在EViews 软件的主显示窗口显示相应的工作文件窗口(如图所示)。 图1-3工作文件窗口 工作文件窗口是EViews的子窗口,工作文件一开始其中就包含了两个对象,一个是系数向量C(保存估计系数用),另一个是残差序列RESID(实际值与拟合值之差)。 (3)命令方式新建文件 在EViews软件的命令窗口中直接键入CREATE命令,也可以建立工作文件。
我国限额以上餐饮企业营业额的 影响因素分析 班级: 姓名: 学号: 指导老师:
我国限额以上餐饮企业营业额的影响因素分析 摘要:本文收集了1999—2009共11年的相关数据,选取餐饮企业的数量、城镇居民人均年消费性支出、全国城镇人口数以及公路里程数作为解释变量构建模型,对我国限额以上餐饮企业营业额的影响因素进行分析。并利用Eviews软件对模型进行参数估计和检验,且加以修正,最后根据模型的最终结果进行经济意义分析,然后提出自己的看法。 关键词:餐饮企业营业额、影响因素、计量分析 一、研究背景 近十年来,投资者进入餐饮企业的数量一直持递增趋势。在他们进入一个行业之前,势必要对该行业的营业额、营业利润等进行估计,当这些因素的估计值能够达到他们的预期的时候,他们才会对其进行投资。由于餐饮企业的营业额是影响投资者是否进入餐饮业的一个重要因素,那么对于我国餐饮企业的营业额问题的深入研究就相当的有必要,这有助于投资者作出合理的决策。下面即进行了对我国限额以上餐饮企业营业额的计量模型研究。 二、变量的选取 影响餐饮企业营业额的因素有很多,包括餐饮企业的数量、营业面积、从业人员、城镇居民人均年消费性支出、全国城镇人口数、餐饮企业的平均价格水平及公路里程数(表示交通状况),但综合考虑后,选取了其中的一部分变量(企业数、城镇居民人均年消费性支出、全国城镇人口数、公路里程数)进行研究,并对各个变量对餐饮企业营业额的影响进行预测。 1.企业数
本文认为餐饮企业营业额与餐饮企业的数量有关,并预测两者之间呈正相关2. 城镇居民人均年消费性支出 本文认为餐饮企业营业额与城镇居民人均年消费性支出有关,并预测两者之间呈正相关 3. 全国城镇人口数 本文认为餐饮企业营业额与全国城镇人口数有关,并预测两者之间呈正相关4. 公路里程数 本文认为餐饮企业营业额与公路里程数有关,并预测两者之间呈正相关三、相关数据:其中营业额(单位:亿元),企业数(单位:个),人均年消费性 支出(单位:元),全国城镇人口数(单位:万人),公路里程数(单位:万公里) 年度 营业额 (Y)企业数(x1) 人均年消费性 支出(x2) 全国城镇人口 数(x3) 公路里程 数(x4) 1999351955932664615.9143748135.2 200040524453508499845906140.3 2001489894341325309.0148064169.8 2002624247150216029.8850212176.5 2003747000059356510.9452376181 200411605000100677182.154283187.1 20051260200099227942.8856212334.5
江西农业大学经济贸易学院学生实验报告 课程名称:计量经济学 专业班级:经济1201班 姓名: 学号: 指导教师:徐冬梅 职称:讲师 实验日期: 2014.12.11
学生实验报告 一、实验目的及要求 1、目的 会使用EVIEWS对计量经济模型进行分析 2、内容及要求 (1)对经典线形回归模型进行参数估计、参数的检验与区间估计,对模型总体进行显著性检验; (2)异方差的检验及其处理; (3)自相关的检验及其处理; (4)多重共线性检验及其处理; 二、仪器用具 三、实验方法与步骤 (一)数据的输入、描述及其图形处理; (二)方程的估计; (三)参数的检验、违背经典假定的检验; (四)模型的处理与预测
四、实验结果与数据处理 实验一:中国城镇居民人均消费支出模型 数据散点图: 通过Eviews 估计参数方程 回归方程: Dependent Variable: Y Method: Least Squares Date: 11/27/14 Time: 15:02 Sample: 1 31 Included observations: 31 Variable Coefficien t Std. Error t-Statistic Prob. X 1.359477 0.043302 31.39525 0.0000 C -57.90655 377.7595 -0.153289 0.8792 R-squared 0.971419 Mean dependent var 11363.69 Adjusted R-squared 0.970433 S.D. dependent var 3294.469 S.E. of regression 566.4812 Akaike info criterion 15.57911 Sum squared resid 9306127. Schwarz criterion 15.67162 Log likelihood -239.4761 F-statistic 985.6616 Durbin-Watson stat 1.294974 Prob(F-statistic) 0.000000 5000 10000 15000 20000 25000 6000 800010000120001400016000 X Y
计量经济学案例分析 一、问题背景 高新区自开始设立至今短短十多年的时间,以其惊人的经济发展速度为世人所关注。随着我国经济发展模式的逐步转变,高新区已经成为我国依靠科技进步和技术创新推动经济社会发展、走中国特色自主创新道路的一面旗帜。“十二五”时期,面对新的机遇和挑战,国家高新区应注重提升五种能力,努力成为加快转变经济发展方式的排头兵。为了探索高新经济发展的内在规律性,本文采用截面数据对高新区的投入产出进行分析,力求能够增进对高新区经济发展的了解,对高新区的进一步发展有所帮助。 二、模型设定 本文研究的是高新区投入对产出的影响,所以本模型的被解释变量Y 即为高新区的产出。就目前对高新区数据的统计来看,反映高新区产出的主要有“工业总产值”、“工业增加值”、“技工贸总收入”、“利润”和“上缴税额”几个总量指标。按照生产函数理论,产出利用增加值,所以模型中我们将使用“工业增加值”指标数据来估计各高新区的总产出。 从高新区的投入来看,对产出有重要影响的因素主要包括以下几个方面: 资本K ,劳动力L ,技术投入T ,此外,体制改革,管理模式创新也可以看作是投入的要素,但因其不可量化,因此归入模型的扰动项中。 这样,按照科布道格拉斯形式的生产函数,我们设定函数形式为: u T L AK Y γβα= 两边取自然对数得:u T L K A Y ln ln ln ln ln ln ++++=γβα 其中,资本数据K 我们利用的是当年的年末净资产来进行估计,即当年年末资产减去当年年末负债后得到的数据;用当年年末从业人员来估计劳动力L ;用当年技术研发投入来估计技术投入T 。数据选用的是截面数据。 从《国家高新技术产业开发区十年发展报告(1991-2000年)》得到1999年全国53个高新区各项指标统计数据: 园区 工业增加值(千 元)Y 净资产(千元)K 年末从业人员(人) L 技术开发费(千 元)T 北京 246422 天津 4138312 106970 1004739 石家庄 1428436 8427194 40404 437677 保定 1320169 5564045 35743 78798 太原 1261311 4755833 39469 254922 包头 877062 3798540 19793 56816 沈阳 3835694 21547 525425 大连 2099833 9922822 61713 328710
案例分析一关于计量经济学方法论的讨论 问题:利用计量经济学建模的步骤,根据相关的消费理论,刻画我国改革开放以来的边际消费倾向。 第一步:相关经济理论。首先了解经济理论在这一问题上的阐述,宏观经济学中,关于消费函数的理论有以下几种:①凯恩斯的绝对收入理论,认为家庭消费在收入中所占的比例取决于收入的绝对水平。②相对收入理论,是由美国经济学家杜森贝提出的,认为人们的消费具有惯性,前期消费水平高,会影响下一期的消费水平,这告诉我们,除了当期收入外,前期消费也很可能是建立消费函数时应该考虑的因素。关于消费函数的理论还有持久收入理论、生命周期理论,有兴趣的同学可以参考相应的参考书。毋庸置疑,收入和消费之间是正相关的。 第二步:数据获得。在这个例子中,被解释变量选择消费,用cs表示;解释变量为实际可支配收入,用inc表示(用GDP减去税收来近似,单位:亿元);变量均为剔除了价格因素的实际年度数据,样本区间为1978~2002年。 第三步:理论数学模型的设定。为了讨论的方便,我们可以建立下面简单的线性模型: 第四步:理论计量经济模型的设定。根据第三步数学模型的形式,可得 式中:cs=CS/P,inc=(1-t)*GDP/P,其中GDP是当年价格的国内生产总值,CS代表当年价格的居民消费值,P代表1978年为1的价格指数,t=TAX/GDP代表宏观税率,TAX是税收总额。u t表示除收入以外其它影响消费的因素。 第五步:计量经济模型的参数估计 根据最小二乘法,可得如下的估计结果: 常数项为正说明,若inc为0,消费为414.88,也就是自发消费。总收入变量的系数 为边际消费倾向,可以解释为城镇居民总收入增加1亿元导致居民消费平均增加0.51亿元。 另外,根据相对收入理论,我们可以得到下面的估计结果:
实验报告 课程名称计量经济学 实验项目名称多重共线性 班级与班级代码 专业 任课教师 学号: 姓名: 实验日期:2014 年05 月11日
广东商学院教务处制 姓名实验报告成绩 评语: 指导教师(签名) 年月日
说明:指导教师评分后,实验报告交院(系)办公室保存。 计量经济学实验报告 一、实验目的:掌握多元线性回归模型的估计方法、掌握多重共线性模型的识别和修正。 二、实验要求:应用教材第127页案例做多元线性回归模型,并识别和修正多重共线性。 三、实验原理:普通最小二乘法、简单相关系数检验法、综合判断法、逐步回归法。 R值。 四、预备知识:最小二乘法估计的原理、t检验、F检验、2 五、实验步骤 1、选择数据 理论上认为影响能源消费需求总量的因素主要有经济发展水平、收入水平、产业发展、人民生活水平提高、能源转换技术等因素。为此,收集了中国能源消费标准煤总量、国民总收入、国内生产总值GDP、工业增加值、建筑业增加值、交通运输邮电业增加值、人均生活电力消费、能源加工转换效率等1985——2007年的统计数据。本题旨在通过建立这些经济变量的线性模型来说明影响能源消费需求总量的原因。主要数据如下: 1985~2007年统计数据
资料来源:《中国统计年鉴》,中国统计出版社2000、2008年版。 为分析Y 与X1、X2、X3、X4、X5、X6、X7之间的关系,做如下折线图: 能源消费Y 在1986到1996年间缓慢增长,在96至98年有短暂的下跌,但是98 至02年开始缓慢回升,02年到06年开始快速增长。 国民总收入X1和国内生产总值X2以相同的趋势逐年缓慢增长。 工业增加值X3在1985年-1999年期间一直是缓慢增长,但在2000年出现了急剧下降的现象,2001年又急剧增长,达到下降前的水平,2001年以后开始缓慢增长。建筑业增长值x4、交通运输邮电业增加值x5、人均生活电力消费x6、能源加工转换效率x7数值较低,但都以较平缓的方式增长。 2、设定并估计多元线性回归模型 t t t t t t t u X X X X X Y ++++++=66554433221ββββββ (2.1) 2.1录入数据,得到图。
计量经济学课程案例分析论文 本小组案例:影响税收收入的因素 摘要:我国经济增长与税收增长之间是正相关的,经济增长是税收增长的源泉,而税收又是国家财政收入的主要来源,国家把税收收入用于经济建设,发展科学、教育、文化、卫生等事业,反过来又促进经济的进一步增长。 关键字:税收国内生产总值财政支出商品零售价格指数 一、引言:改革开放以来,随着经济体制的改革的深化和经济的快速增长,中国的财政收支状况发生很大的变化,为了研究中国税收收入增长的主要原因,分析中央和地方税收收入的增长规律,预测中国税收未来的增长趋势,需要建立计量经济学模型。 二、经济理论分析:影响中国税收收入增长的主要因素可能有: 【1】从宏观经济上看经济增长是税收增长的基本源泉 【2】社会经济的发展和社会保障等对公共财政提出要求,公共财政的需求可能对当年的税收入可能会有一定的影响。 【3】物价水平。中国的税制结构以“流转税”为主,以现行价格计算的GDP和经营者的收入水平都与物价水平有关。 【4】税收政策因素 三、建立模型:以各项税收收入Y作为解释变量 以GDP表示经济增长水平 以财政支出表示公共财政的需求 以商品零售价格指数表示物价水平 税收政策因素较难用数量表示,暂时不予考虑 模型设定为Y=β1X1+β2X3+β3X3+C 其中:Y—各项税收收入(亿元)
X1—国内生产总值(亿元) X2—财政支出(亿元) X3—商品零售价格指数(%) 四、数据收集: 年份x1 x2 x3 y 1978 3645.20 1122.09 100.70 519.28 1979 4062.60 1281.79 102.00 537.82 1980 4545.60 1228.83 106.00 571.70 1981 4891.60 1138.41 102.40 629.89 1982 5323.40 1229.98 101.90 700.02 1983 5962.70 1409.53 101.50 775.59 1984 7208.10 1701.02 102.80 947.35 1985 9016.00 2004.25 108.80 2040.79 1986 10275.20 2204.91 106.00 2090.73 1987 12058.60 2262.18 107.30 2140.36 1988 15042.80 2491.21 118.50 2390.47 1989 16992.30 2823.78 117.80 2727.40 1990 18667.80 3083.59 102.10 2821.86 1991 21781.50 3386.62 102.90 2990.17 1992 26923.50 3742.20 105.40 3296.91 1993 35333.90 4642.30 113.20 4255.30 1994 48197.90 5792.62 121.70 5126.88 1995 60793.70 6823.72 114.80 6038.04 1996 71176.60 7937.55 106.10 6909.82 1997 78973.00 9233.56 100.80 8234.04 1998 84402.30 10798.18 97.40 9262.80 1999 89677.10 13187.67 97.00 10682.58 2000 99214.60 15886.50 98.50 12581.51 2001 109655.20 18902.58 99.20 15301.38 2002 120332.70 22053.15 99.70 17636.45 2003 135822.80 24649.95 99.90 20017.31 2004 159878.30 28486.89 102.80 24165.68 2005 184937.40 33930.28 100.80 28778.54 2006 216314.40 40422.73 101.00 34809.72 2007 265810.30 49781.35 103.80 45621.97 2008 314045.40 62592.66 105.90 54223.79 2009 340902.80 76299.90 98.80 59521.59 2010 401202.00 89874.16 103.10 73210.79 回归分析: 相关分析
姓名学号实验题目异方差的诊断与修正 一、实验目的与要求: 要求目的:1、用图示法初步判断是否存在异方差,再用White检验异方差; 2、用加权最小二乘法修正异方差。
估计结果为: i Y ? = 12.03564 + 0.104393i X (19.51779) (0.008441) t=(0.616650) (12.36670) 2R =0.854696 R =0.849107 S.E.=56.89947 DW=1.212859 F=152.9353 这说明在其他因素不变的情况下,销售收入每增长1元,销售利润平均增长0.104393元。 2R =0.854696 , 拟合程度较好。在给定 =0.0时,t=12.36670 > )26(025.0t =2.056 ,拒 绝原假设,说明销售收入对销售利润有显著性影响。F=152.9353 > )6,21(F 05.0= 4.23 ,
表明方程整体显著。 (三) 检验模型的异方差 ※(一)图形法 6、判断 由图3可以看出,被解释变量Y 随着解释变量X 的增大而逐渐分散,离散程度越来越大; 同样,由图4可以看出,残差平方2 i e 对解释变量X 的散点图主要分布在图形中的下三角部分,大致看出残差平方2 i e 随i X 的变动呈增大趋势。因此,模型很可能存在异方差。但是否确实存在异方差还应该通过更近一步的检验。
※ (二)White 检验 White 检验结果 White Heteroskedasticity Test: F-statistic 3.607218 Probability 0.042036 Obs*R-squared 6.270612 Probability 0.043486 Test Equation: t 界值5.002 χ (2) =5.99147。比较计算的2χ统计量与临界值,因为n 2R = 6.270612 > 5 .002 χ(2)=5.99147 ,所以拒绝原假设,不拒绝备择假设,这表明模型存在异方差。 (四) 异方差的修正 在运用加权最小二乘法估计过程中,分别选用了权数t 1ω=1/t X ,t 2ω=1/2 t X ,t 3ω=1/t X 。 用权数t 1ω的结果
大连海事大学 实验报告Array 实验名称:计量经济学软件应用专业班级:财务管理2013-1 姓名:安妮 指导教师:赵冰茹 交通运输管理学院 二○一六年十一月
一、实验目标 学会常用经济计量软件的基本功能,并将其应用在一元线性回归模型的分析中。具体包括:Eview的安装,样本数据基本统计量计算,一元线性回归模型的建立、检验及结果输出与分析,多元回归模型的建立与分析,异方差、序列相关模型的检验与处理等。 二、实验环境 WINDOWSXP或2000操作系统下,基于EVIEWS5.1平台。 三、实验模型建立与分析 案例1: 我国1995-2014年的人均国民生产总值和居民消费支出的统计资料(此资料来自中华人民共和国统计局网站)如表1所示,做回归分析。 表1我国1995-2014年人均国民生产总值与居民消费水平情况
(1)做出散点图,建立居民消费水平随人均国内生产总值变化的一元线性回归方程,并解释斜率的经济意义; 利用eviews软件输出结果报告如下:
Dependent Variable: CONSUMPTION Method: Least Squares Date: 06/11/16 Time: 19:02 Sample: 1995 2014 Included observations: 20 Variable Coefficient Std. Error t-Statistic Prob. C 691.0225 113.3920 6.094104 0.0000 AVGDP 0.352770 0.004908 71.88054 0.0000 R-squared 0.996528 Mean dependent var 7351.300 Adjusted R-squared 0.996335 S.D. dependent var 4828.765 S.E. of regression 292.3118 Akaike info criterion 14.28816 Sum squared resid 1538032. Schwarz criterion 14.38773 Log likelihood -140.8816 Hannan-Quinn criter. 14.30760 F-statistic 5166.811 Durbin-Watson stat 0.403709 Prob(F-statistic) 0.000000 由上表可知财政收入随国内生产总值变化的一元线性回归方程为: (令Y=CONSUMPTION,X=AVGDP(此处代表人均GDP)) Y = 691.0225+0.352770* X 其中斜率0.352770表示国内生产总值每增加一元,人均消费水平增长0.35277元。 检验结果R2=0.996528,说明99.6528%的样本可以被模型解释,只有0.3472%的样本未被解释,因此样本回归直线对样本点的拟合优度很高。 (2)对所建立的回归方程进行检验: (5%显著性水平下,t(18)=2.101) 对于参数c假设: H 0: c=0. 对立假设:H 1 : c≠0 对于参数GDP假设: H 0: GDP=0. 对立假设:H 1 : GDP≠0 由上表知: 对于c,t=6.094104>t(n-2)=t(18)=2.101 因此拒绝H 0: c=0,接受对立假设:H 1 : c≠0 对于GDP, t=71.88054﹥t(n-2)=t(18)=2.101